Способ определения кепстральных маркеров речевых сигналов при психогенных расстройствах

Автор: Алимурадов А.К., Тычков А.Ю., Зарецкий А.П., Кулешов А.П.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Информатика
Статья в выпуске: 4 (36) т.9, 2017 года.
Бесплатный доступ
На сегодняшний день для обнаружения психогенных расстройств применяются раз- личные дистанционные экспериментально-статистические методы, наиболее адаптив- ными из которых являются способы на основе анализа речевых сигналов. Низкая точ- ность обнаружения является одной из основных проблем практической реализации си- стем дистанционного мониторинга психогенных расстройств. Основная причина низкой точности и больших погрешностей связана с использованием неэффективных и неадап- тивных методов обработки нестационарных речевых сигналов. В данной статье предла- гается автоматизированный способ определения кепстральных маркеров речевых сиг- налов при психогенных расстройствах на основе метода улучшенной полной множе- ственной декомпозиции на эмпирические моды с адаптивным шумом (ПМДЭМАШ). Суть способа заключается в разложении речевого сигнала с помощью улучшенной ПМДЭМАШ на частотные составляющие с последующим формированием набора ин- формативных компонент (концентрации информации о психогенных расстройствах) и определением их кепстральных маркеров. Представлена блок-схема разработанного способа и подробное математическое описание. Проведено исследование с использова- нием сформированной верифицированной базы сигналов здоровых пациентов и паци- ентов с психогенными расстройствами мужского и женского пола, в возрасте от 18 до 60 лет. В соответствии с результатами исследования, следует, что психогенные расстрой- ства в большей степени влияют на вокализованные характеристики речевого тракта и достаточно полно отображаются в кепстральных маркерах. Предложенный автома- тизированный способ может быть использован в системах дистанционного мониторин- га психогенных расстройств и внедрен в клиническую практику врача-психиатра для ускорения процесса лечения.
Речевой сигнал, психогенные расстройства, кепстральные ха- рактеристики, мел-частотные кепстральные коэффициенты (мчкк), улучшенная пол- ная множественная декомпозиция на эмпирические моды с адаптивным шумом
Короткий адрес: https://sciup.org/142215000
IDR: 142215000 | УДК: 612.789.4
Текст научной статьи Способ определения кепстральных маркеров речевых сигналов при психогенных расстройствах
Психогенное расстройство является наиболее распространенным аффективным расстройством, риск возникновения которого в течение жизни наблюдается у 10-20 % женщин и 5-12 % мужчин [1]. За последние 20 лет численность людей, страдающих психогенными расстройствами, стремительно возрастает. В настоящее время диагностика психогенных расстройств осуществляется посредством наблюдения врачей - профессионалами, имеющими значительный клинический опыт. Однако из-за растущего количества пациентов, возникает вероятность ошибок в клинической практике врачей (как человеческого фактора), что может привести к назначению некорректного курса лечения. По этой причине возникает необходимость разработки новых способов обнаружения маркеров психогенных расстройств [2, 3]. В настоящее время для обнаружения психических расстройств применяются различные дистанционные экспериментально-статистические методики обработки сигналов по доступным каналам регистрации реакций организма человека [4-6]. Наиболее адаптивным, работающим в режиме реального времени и свободной активности является способ на основе анализа речевых сигналов [7-9]. Вид и степень выраженности психических расстройств кодируются в определенные информативные параметры речевых сигналов - сигнальные маркеры [10]. Характеристики речи, способные служить маркерами психогенных состояний, можно разделить на три основные группы: спектрально-временные, амплитудно-частотные и кепстральные. В отличие от первых двух групп кепстральные маркеры характеризуют речевой сигнал с точки зрения частотной характеристики речевого тракта, отбрасывая при этом характеристики сигнала возбуждения. Кепстральные меркеры отображают информацию в частотной области речевого тракта более подробно и компактно, обеспечивая лучшее разделение сегментов речевого потока. Известно, что точность определения кепстральных маркеров зависит от корректной обработки речевых сигналов, которая определяется правильностью измерения его амплитудных, временных, частотных и энергетических характеристик. Основная причина низкой точности и больших погрешностей при измерениях связана с использованием неэффективных и неадаптивных методов обработки нестационарных речевых сигналов.
В области обработки речевых сигналов кепстральный анализ получил широкую практическую популярность, объясняемую достоинством сжатия информации о сигнале при переходе в частотную область обработки [11]. Кепстральный анализ основан на выделении кепстральных коэффициентов на мел-шкале, называемых мел-частотными кепстральными коэффициентами (МЧКК). МЧКК включают в себя два основных понятия: кепстр и мел-шкала. Кепстр - это дискретно-косинусное преобразование амплитудного спектра сигнала в логарифмическом масштабе. Кепстр сигнала определяется по формуле (2.1):
с(п) = DCT [log(X (|x(n)|2))], (2.1)
где DCT - дискретно-косинусное преобразование, X - спектральное представление сигнала x(n),n - дискретный о течет времени (0 < п 6 N,N - количество дискретных отсчетов в сигнале). Метод получения МЧКК основан на модели функционирования органов слуха человека и использует частотную шкалу в мелах, которая моделирует частотную чувствительность человеческого уха [11].
-
2.2. Декомпозиция на эмпирические моды
Исследования методов обработки речевых сигналов выявили перспективность использования адаптивной технологии анализа нестационарных сигналов - декомпозиции на эмпирические моды (ДЭМ) [12]. ДЭМ - это адаптивный метод анализа нестационарных сигналов, возникающих в нелинейных системах. ДЭМ обеспечивает локальное разложение сигнала на быстрые и медленные колебательные функции. В результате разложения исходный сигнал может быть представлен в виде суммы амплитудных и частотных модулированных функций, называемых эмпирическими модами (ЭМ). Аналитическое выражение ДЭМ выглядит следующим образом (2.2):
I
x(п) = ^ IMFi + Тг(п), (2.2)
г =1
где x(п) - исходивій сигнал, IMFi(n) - ЭМ, тДп) - конечный остаток, г = 1, 2,...,I -номер ЭМ. В настоящее время для адаптивного разложения речевого сигнала перспективным является применение усовершенствованной полной множественной ДЭМ с адаптивным шумом [13]. Основная идея метода заключается в добавлении к исходному сигналу контролируемого шума для создания новых экстремумов.
В методе ПМДЭМАШ решаются все основные недостатки существующих разновидностей декомпозиции:
-
- явление смешивания ЭМ;
-
- наличие остаточного шума в ЭМ;
-
- наличие «паразитных» ЭМ на ранних этапах декомпозиции.
Алгоритм и математическое описание метода улучшенной ПМДЭМАШ:
Шаг 1. С помощью аппарата ДЭМ, выражая из формулы (E 1 (xj (п))) = = (xj (п)) — (M (xj (п))) локальные средние значения шумовых копий исходного сигнала (xj (п) = x(n) + 3 o E 1 (wj (п))), определяется первый остаток (2.3):
ri (п) = (M (xj (п))), (2.3)
где Е^(^) - аппарат извлечешьi ЭМ методом ДЭМ (г - номер моды), xj (п) = x(п) + Wj (п) - шумовые копии исходного сигнала (x(п) - исходный речевой сигнал, Wj (п) - реализации белого шума с нулевой средней единичной дисперсией), M (•) - аппарат, создающий локальное среднее значение применяемого сигнала, Зг = Eistd(ri) - коэффициент, допускающий выбор различных значений отношения сигнал/шум.
Шаг 2. На первом этапе для г = 1 вычисляется первая мода: IMF1(n) = x(п)-гДп).
Шаг 3. Вычисляется второй остаток как усредненное локальное среднее значение шумовых копий первого остатка тДп) + 3 i E 2 (wj (п)) и определяется вторая мода:
IMF 2(п) = гДп) — Г2(п) = гДп) — (M (Г 1 (п) + 3 1 E 2 (Wj (п)))).
Шаг 4. На последующих этапах для г = 3,..., I вычисляется Тй остаток:
Ті(п) = (М (Ті- 1 (п) + 3i— i Ei(wj ( п )))).
Шаг 5. Вычисляется г-я мода:
IMFі(п) = Ті- і (п) - Ті(п).
Шаг 6. Переход к шагу 4 для следующего значения г. Константы Зі выбираются так, чтобы получить желаемое отношение сигнал/шум между добавленным шумом и остатком, к которому добавляется шум.
3. Описание способа
На рис. 1 представлена упрощенная блок-схема автоматизированного способа определения кепстральных маркеров речевых сигналов для обнаружения пограничных психических расстройств. Суть предложенного способа заключается в разложении с помощью усовершенствованной ПМДЭМАШ речевого сигнала на частотные составляющие с формированием набора информативных компонент (концентрации информации о психогенных расстройствах) и определением МЧКК. Рассмотрим каждый этап разработанного способа подробнее.
Блок 1. Ввод осуществляется со следующими параметрами: частота дискретизации 8000 Гц, разрядность квантования 16 бит.
Блок 2. В рамках предварительной обработки осуществляется: удаление постоянной составляющей, фильтрация речевого сигнала с помощью ФВЧ Чебышева четвертого порядка частот ниже 130 Гц и коррекция естественных искажений спектра (минус б дБ на октаву), возникающих в речевом аппарате человека при произнесении речи.
Блок 3. Сегментация речевого сигнала на информативные участки представляет собой обнаружение границ вокализованных и невокализованных участков в общем речевом потоке. Сегментация осуществлялась на основе вычисления следующих параметров в скользящем окне [14]: скорость пересечения сигнала через нулевое значение (Zero-Crossing Rate, ZCR), автокорреляционная функция (Autocorrelation Function, ACR), энергия/мощ-ность (PWR), линейно-частотные кепстральные коэффициенты (Linear-Frequency Cepstral Coefficients, LFCC).
Вокализованные участки (сформированные с участием голосовых связок - гласные звуки и звуки сонорных согласных) определяются на основе следующего решающего правила, с учетом физиологических аспектов формирования речевых сигналов: сегменты длительностью меньше, чем 30 мс классифицируются как участки, не содержащие вокализации (сформированные без участия голосовых связок), но сегменты, не содержащие вокализации длительностью меньше, чем 20 мс, классифицируются как вокализованные, так как такой кратковременный переход между вокализованными и невокализованными сегментами невозможен. Вокализованные участки идентифицируются, как сегменты с самыми высокими средними значениями PWR и ACR и самым низким значением ZCR.
Невокализованные участки, представленные невокализованными согласными, отделяются от участков паузы (тишины) из общего потока участков, сформированных без участия голосовых связок, на основе следующего решающего правила: сегменты длительностью больше, чем 300 мс классифицируются как участки невокализованных согласных, но сегменты невокализованных согласных длительностью меньше, чем 5 мс и сегменты, находящиеся на расстоянии от вокализованных участков более чем на 30 мс, не используются. Для идентификации невокализованных участков используются первые пять коэффициентов LFCC. Невокализованные участки идентифицировались как сегменты с самым высоким средним значением первого коэффициента LFCC, что связано с громкостью произношения. Участки паузы (тишины), включая время, необходимое для дыхания, отделяются от невокализованных участков (сформированные без участия голосовых связок) на основе следующего решающего правила: сегменты длительностью больше, чем 30 мс, обладающие минимальным средним значением первого коэффициента LFCC, классифицируются как участки паузы (тишины). На рис. 2 представлена графическая иллюстрация работы этапа сегментации.
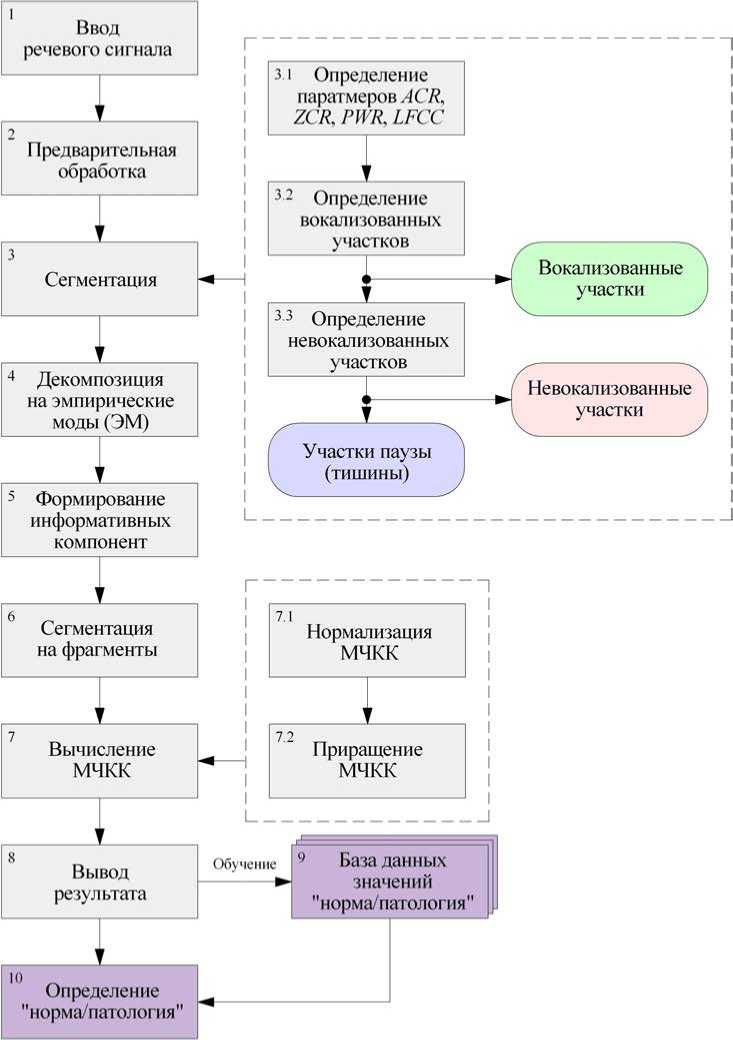
Рис. 1. Блок-схема, способа.
Блок 4. В представленном способе разложение речевых сигналов на. частотные составляющие для последующего формирования информативных компонент осуществляется на. основе улучшенной ПМДЭМАШ. Использование улучшенной ПМДЭМАШ обеспечит:
-
- адаптивное разложение, так как базисные функции, используемые при декомпозиции, извлекаются непосредственно из исходного речевого сигнала, и позволяют учитывать только ему свойственные особенности (скрытые модуляции, области концентрации энергии и т.п.);
-
- минимальный уровень остаточного шума;
-
- отсутствие паразитных ЭМ, возникающих на ранних этапах декомпозиции вследствие перекрытия масштабно-энергетических пространств мод.
На рис. 3 и 4 представлены результаты разложения вокализованного и невокализованного участков речевого сигнала.
Блок 5. Основным понятием при формировании информативных компонент является концентрация информации о психогенных расстройствах в отдельные компоненты.
Для абсолютно произвольного сигнала все ЭМ можно разбить на две категории [10]: информативные ЭМ с шумовыми и сигнальными составляющими; неинформативные ЭМ с трендовыми составляющими.
В основе формирования информативных компонент заложено предположение, что информативные ЭМ имеют большую энергию, чем неинформативные. Амплитудное распределение ЭМ хорошо описывается с помощью функции кратковременной энергии. В разработанном способе для сжатия амплитуды сигнала в большом динамическом диапазоне применяется логарифмирование энергии, максимально приближая работу способа к работе слухового аппарата человека. На рис. 5 представлены кривые зависимости логарифмов энергии от номера ЭМ для вокализованных и невокализованных участков речевого сигнала.
Формирование информативных компонент заключается в вычитании из исходного сигнала информативных шумовых и неинформативных ЭМ. Информативными шумовыми обычно являются первые две или три ЭМ, в зависимости от интенсивности присутствующего в сигнале шума. Неинформативными являются последние три или четыре ЭМ, в зависимости от общего количества мод (число ЭМ примерно равно двоичному логарифму от числа дискретных отсчетов в сигнале). Как видно из рисунков 3-5, информативными модами (выделенными областью зеленого цвета) для вокализованного участка являются ЭМ2-ЭМ5, а для невокализованного участка ЭМ1-ЭМ5. Во втором случае учитывается, что невокализованные согласные звуки состоят из шумовых компонент, например шумовые согласные: п, б, ф, в, т, д, с, з, ц, ч, ш, ж, к, г, х.
Целью формирования информативных компонент является сбор информации, отражающей нарушения работы органов речевого аппарата вследствие психогенного расстройства. Формирование набора информативных компонент осуществляется по формуле (3.1):
ЖцД-М = ж(п) - (а * ^ ІМҒі+і(п) + Ь * ^ ІМҒі-1(п)),(3.1)
-
-=0
где aca,b,-i('ri') ~ информативная компонента, а,Ь- коэффициенты, определяющие участие ЭМ в формировании информативных компонент.
Блок 6. Сегментация на фрагменты ЭМ - это линейное деление на составляющие отрезки. Разработанный способ основан на предположении о том, что свойства речевого сигнала с течением времени изменяются медленно. Это предположение приводит к кратковременному анализу, в котором фрагменты ЭМ выделяются и обрабатываются так, как если бы они были короткими участками с отличающимися свойствами.
Блок 7. Как отмечалось ранее, в качестве кепстальных характеристик в способе вычисляются МЧКК. Основными этапами вычисления МЧКК являются [15]:
-
- перевод сигнала из шкалы герц в шкалу мелов;
-
- спектральное преобразование и определение периодограммы сигнала;
-
- фильтрация периодограммы сигнала набором мел-фильтров;
-
- логарифмирование энергии сигнала в каждом мел-фильтре;
-
- дискретно-косинусного преобразования логарифма энергии.
Итогом вычисления являются МЧКК ( МҒСС (с), г де с = 1, 2, ..., С - номер МЧКК, С - желаемое количество коэффициентов).
В представленном способе используются 24 МЧКК, так как чем выше индекс коэффициента, тем быстрее изменяется энергия в наборе фильтров [15]. Также в результате экспериментальных исследований выяснилось, что первый коэффициент в основном несет информацию об интенсивности речевых сигналов.
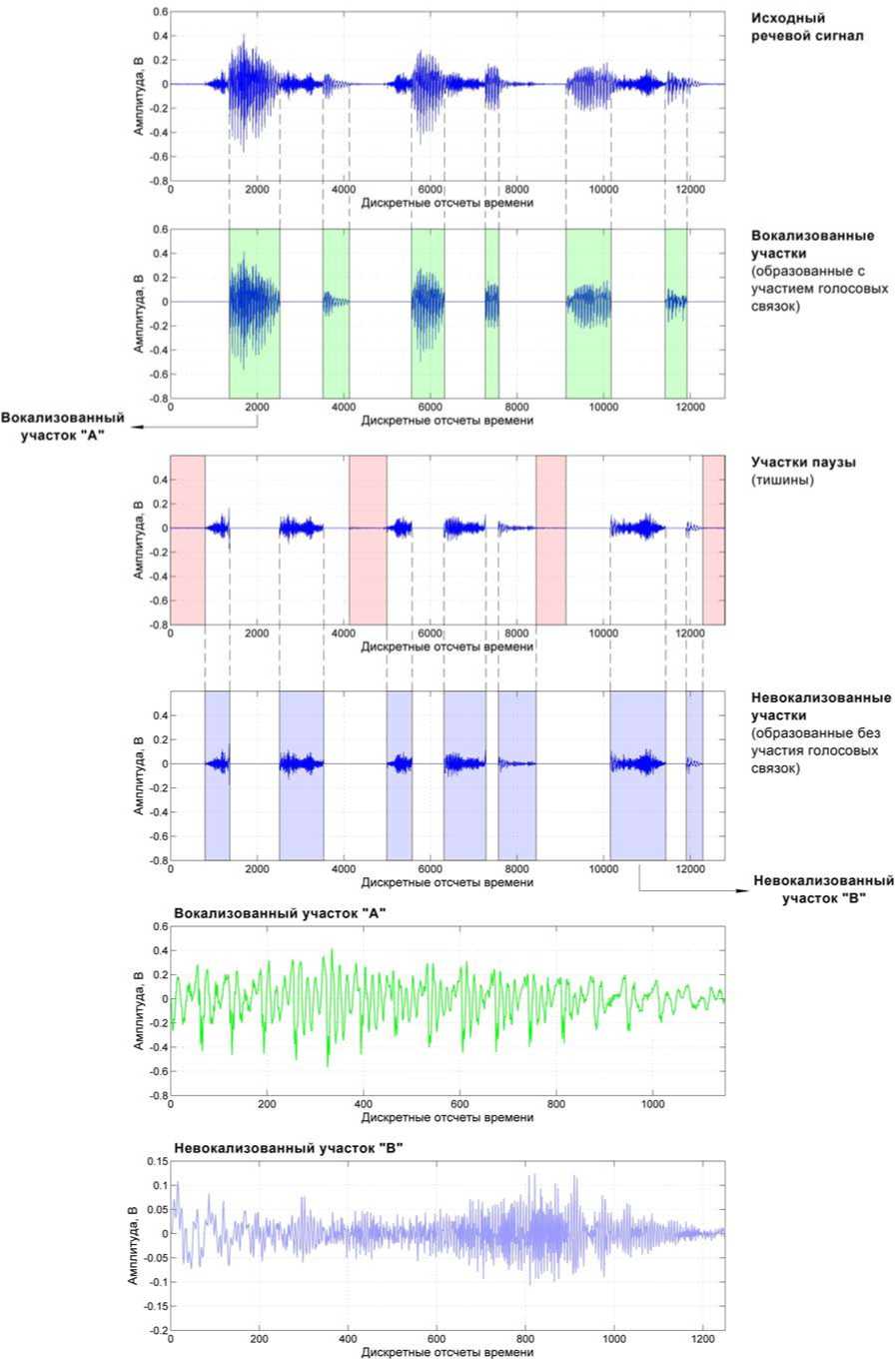
Рис. 2. Работа, способа, па. этапе сегментации
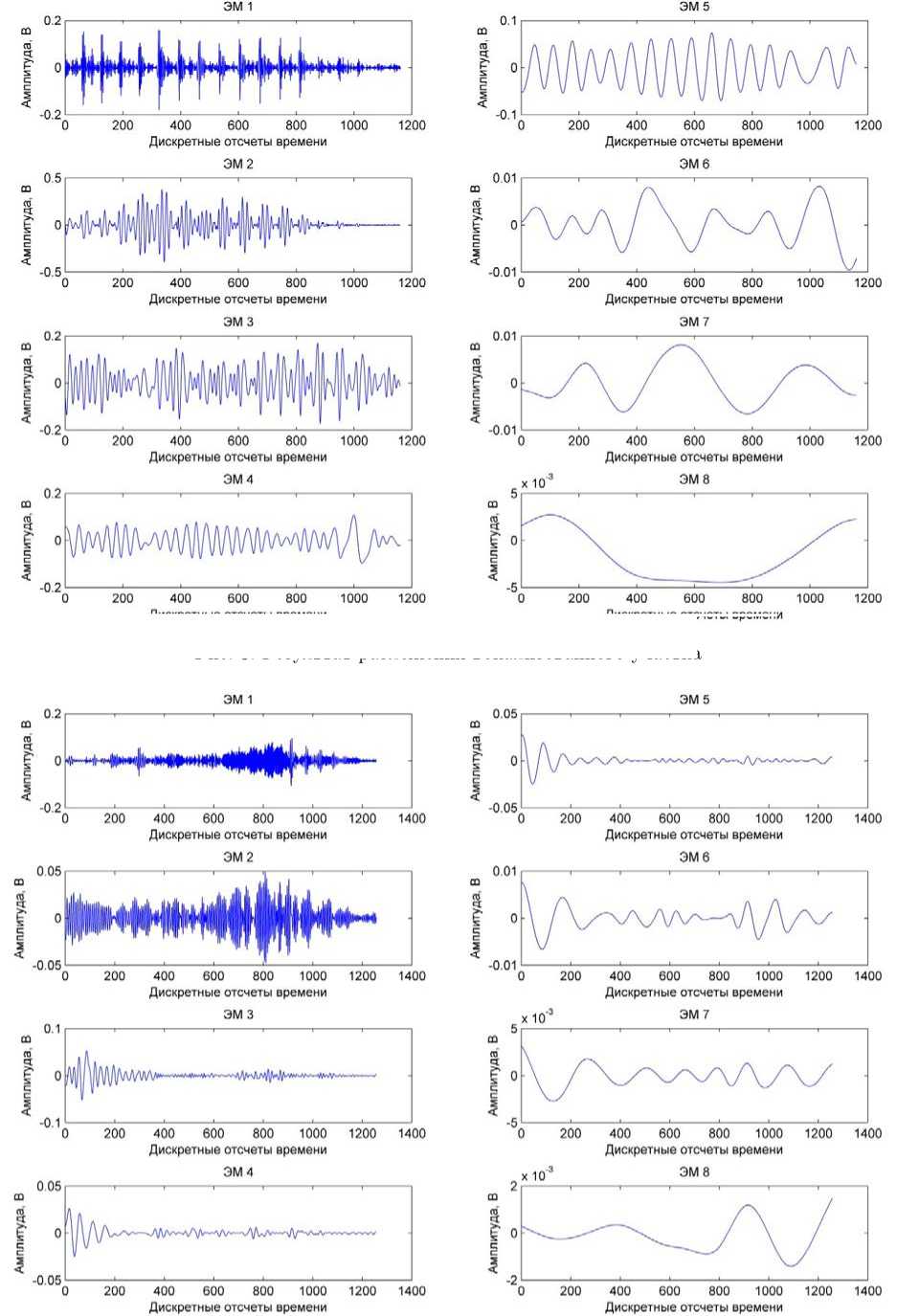
Рис. 4. Результат разложения певокализоваппого участка.
Дискретные отсчеты времени
Дискретные отсчеты времени
Рис. 3. Результат разложения вокализованного участка
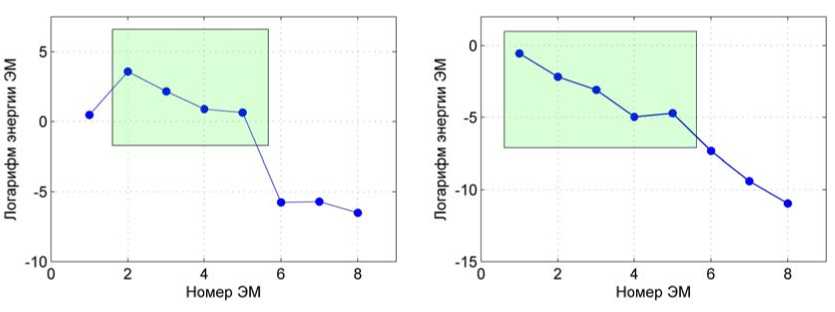
а. - вокализованный участок б - невокализованный участок
Рис. 5. Логарифм энергии ЭМ
Операция нормализации используется для придания равнозначности каждому МЧКК во фрагменте. Как известно, высокие частоты менее восприимчивы, и МЧКК на этих частотах менее информативны по сравнению с МЧКК на низких частотах. Нормализация МЧКК - это умножение каждого коэффициента на число, которое увеличивается с номером коэффициента. Таким образом, первые коэффициенты по уровню уменьшаются, а последние коэффициенты увеличиваются. Для этой операции используется следующая формула (3.2):
MFCC_N (с) = MFCC (с) * (1 + ^sin( у)), (3.2)
где L - величина, подбираемая эмпирически и равна 22 [15]. Вычисление первого и второго приращений значений МЧКК позволяет получить динамическую информацию о коэффициентах. Вектор коэффициентов описывает фиксированную спектральную огибающую одного фрагмента, но, очевидно, что речевые сигналы несут информацию и о динамике в виде незначительного изменения коэффициентов с течением времени [15]:
МРГГ ША -KMFCC(с + d)) - MFCC ( с - d
(3.3)
(3.4)
M f CC U\C) — ------------------77------------------
" 2 d 2
^1 <MFCC-D(c + d)) - MFCC_D(с - d)
MFCC DD(C) — ------------------ 77------------------
" 2 d 2
где MFCC d D ( c ) MFCC d D ( c ) - первое и второе приращения МЧКК, MFCC (с) - статические МЧКК, D - типовое значение приращения, равное 2.
Блок 8. На данном этапе работы способа осуществляется формирование вектора полученных МЧКК (первичных, нормализованных и после приращения), удобного для дальнейшего определения «норма/патология».
-
4. Исследование способа
-
4.1. Описание базы данных речевых сигналов
-
-
4.2. Результаты исследования
Для проведения исследований разработанного способа сформированы группа пациентов и верифицированная база сигналов при поддержке Областной клинической больницы им. К.Р. Евграфова (г. Пенза, Российская Федерация) и Пензенского государственного университета. Группа пациентов сформирована в соответствии с клинической картиной расстройства следующих диагностических рубрик международной классификации болезней (МКБ-10): F48.0, F45.3 , F43.2, F41.2.
В группу пациентов с психогенными расстройствами отобрано 100 человек мужского и женского пола в возрасте от 18 до 60 лет, поступившие с явно выраженной симптоматикой. В том же количестве, 100 человек, сформирована база контрольной группы пациентов без признаков пограничных психических расстройств (условно здоровые). Средний возраст в экспериментальной группе пациентов с пограничными психическими расстройствами составил 40,2 года, в контрольной группе сравнения - 35,4 года.
В обеих группах преобладали женщины (75%), возраст преимущественно для женщин от 40 до 59 лет, для мужчин от 50 до 59 лет. Большинство пациентов были работающими (90,8%), среди которых выделялись по численности служащие предприятий и организаций (65,0%). Меньшие доли приходились на рабочих (14,2%), творческих работников (12,5%) и единицы - на учащихся, студентов и не работающих. Большинство пациентов имели высшее или неоконченное высшее образование (69,2%).
Для оценки эффективности разработанного способа использовался параметр - ошибки первого и второго рода. В рамках исследования главной задачей являлось определение маркеров психогенных расстройств, поэтому ошибкой первого рода будет ложное присваивание статуса «норма» речевому сигналу, произнесенному человеком с психогенным расстройством, а ошибкой второго рода - ложное присваивание статуса «патология» речевому сигналу, произнесенному здоровым человеком.
Исследование кепстальных маркеров речевых сигналов, отражающих нарушения работы органов речевого аппарата вследствие психогенного расстройства, проводилось для:
-
- сигналов, состоящих только из вокализованных участков (сформированных с участием голосовых связок);
-
- сигналов, состоящих из невокализованных участков (сформированных без участия голосовых связок);
-
- сигналов, состоящих из вокализованных и невокализованных участков.
Для каждой группы сигналов сформированы наборы из трех информативных компонент, полученных вследствие вычитания из исходного сигнала информативных шумовых и неинформативных ЭМ.
В таблице 1 представлены результаты определения психических расстройств на основе вычисления кепстральных маркеров для трех сигналов.
Таблица!
Результаты определения пограничных психических расстройств
|
Прогнозируемый результат |
Результат определения |
Ошибки первого рода и второго рода, % |
||
|
Патология |
Норма |
|||
|
Информативная компонента № 1 (вычитание ЭМ6, ЭМ7, ЭМ8) |
||||
|
Патология |
78 чел. |
22 чел. |
1-го |
22 |
|
Норма |
16 чел. |
84 чел. |
2-го |
16 |
|
Информативная компонента № 2 (вычитание ЭМ1, ЭМ6, ЭМ7, ЭМ8) |
||||
|
Патология |
19 чел. |
81 чел. |
1-го |
81 |
|
Норма |
51 чел. |
49 чел. |
2-го |
51 |
|
Информативная компонента № 3 (вычитание ЭМ1, ЭМ2, ЭМ6, ЭМ7, ЭМ8) |
||||
|
Патология |
83 чел. |
17 чел. |
1-го |
17 |
|
Норма |
15 чел. |
85 чел. |
2-го |
15 |
В табл. 2 представлены результаты определения пограничных психических расстройств на основе вычисления кепстральных маркеров для информативных компонент сигнала, состоящего из вокализованных участков.
Т а б л и ц а 2
Результаты определения пограничных психических расстройств информативных компонент сигнала, состоящего из вокализованных участков
|
Прогнозируемый результат |
Результат определения |
Ошибки первого рода и второго рода, % |
||
|
Патология |
Норма |
|||
|
Информативная компонента № 1 (вычитание ЭМб, ЭМ7, ЭМ8) |
||||
|
Патология |
81 чел. |
19 чел. |
1-го |
19 |
|
Норма |
11 чел. |
89 чел. |
2-го |
11 |
|
Информативная компонента № 2 (вычитание ЭМ1, ЭМб, ЭМ7, ЭМ8) |
||||
|
Патология |
86 чел. |
14 чел. |
1-го |
14 |
|
Норма |
10 чел. |
90 чел. |
2-го |
10 |
|
Информативная компонента № 3 (вычитание ЭМ1, ЭМ2, ЭМб, ЭМ7, ЭМ8) |
||||
|
Патология |
44 чел. |
56 чел. |
1-го |
56 |
|
Норма |
39 чел. |
61 чел. |
2-го |
39 |
Т а б л и ц а 3
Результаты определения пограничных психических расстройств для информативных компонент сигнала, состоящего из невокализованных участков
|
Прогнозируемый результат |
Результат определения |
Ошибки первого рода и второго рода, % |
||
|
Патология |
Норма |
|||
|
Информативная компонента № 1 (вычитание ЭМб, ЭМ7, ЭМ8) |
||||
|
Патология |
21 чел. |
79 чел. |
1-го |
79 |
|
Норма |
56 чел. |
44 чел. |
2-го |
56 |
|
Информативная компонента № 2 (вычитание ЭМ1, ЭМб, ЭМ7, ЭМ8) |
||||
|
Патология |
16 чел. |
84 чел. |
1-го |
84 |
|
Норма |
71 чел. |
29 чел. |
2-го |
71 |
|
Информативная компонента № 3 (вычитание ЭМ1, ЭМ2, ЭМб, ЭМ7, ЭМ8) |
||||
|
Патология |
9 чел. |
81 чел. |
1-го |
81 |
|
Норма |
79 чел. |
21 чел. |
2-го |
79 |
Т а б л и ц а 4
Результаты определения пограничных психических расстройств для информативных компонент сигнала, состоящего из вокализованных и невокализованных участков
|
Прогнозируемый результат |
Результат определения |
Ошибки первого рода и второго рода, % |
||
|
Патология |
Норма |
|||
|
Информативная компонента № 1 (вычитание ЭМб, ЭМ7, ЭМ8) |
||||
|
Патология |
86 чел. |
14 чел. |
1-го |
14 |
|
Норма |
13 чел. |
87 чел. |
2-го |
13 |
|
Информативная компонента № 2 (вычитание ЭМ1, ЭМб, ЭМ7, ЭМ8) |
||||
|
Патология |
89 чел. |
11 чел. |
1-го |
11 |
|
Норма |
12 чел. |
88 чел. |
2-го |
12 |
|
Информативная компонента № 3 (вычитание ЭМ1, ЭМ2, ЭМб, ЭМ7, ЭМ8) |
||||
|
Патология |
48 чел. |
52 чел. |
1-го |
52 |
|
Норма |
37 чел. |
63 чел. |
2-го |
37 |
В табл. 3 представлены результаты определения пограничных психических расстройств на основе вычисления кепстральных маркеров для информативных компонент сигнала, состоящего из невокализованных участков.
В табл. 4 представлены результаты определения пограничных психических расстройств на основе вычисления кепстральных маркеров для информативных компонент сигнала, состоящего из вокализованных и невокализованных участков.
5. Обсуждение и выводы
В соответствии с полученными данными можно сделать вывод, что в сравнении между двумя сигналами, состоящими из вокализованных и невокализованных участков соответственно, первые отражают больше информации о нарушениях работы органов речевого аппарата и значит, психических расстройствах человека. Это объясняется тем, что психогенные расстройства в большей степени влияют на вокализованные характеристики речевого тракта и достаточно полно отображаются в кепстральных маркерах.
Данные результаты позволяют сделать вывод, что разработанный автоматизированный способ определения кепстральных маркеров речевых сигналов на основе метода улучшенной ПМДЭМАШ может быть успешно использован в системах дистанционного мониторинга психогенных расстройств с целью упрощения задачи диагностики и внедрения в клиническую практику врача-психиатра для ускорения процесса лечения. Авторы благодарят Российский научный фонд за финансовую поддержку проекта «Поиск скрытых паттернов пограничных психических расстройств и разработка системы экспресс оценки состояния психического здоровья человека», № 17-71-20029.
Список литературы Способ определения кепстральных маркеров речевых сигналов при психогенных расстройствах
- Schwartz T.L., Petersen, T.J. Depression: Treatment Strategies and Management (Medical Psychiatry Series). CRC Press. Boca Raton, 2009.
- Тычков А.Ю., Агейкин А.В., Алимурадов А.К., Чураков П.П., Тычкова А.Н. Анализ и оценка сигнальных систем диагностики пограничных психических расстройств//Биотехносфера. 2017. № 1(49). С. 35-39.
- Tychkov A.Yu., Alimuradov A.K., Churakov P.P. Adaptive signal processing method for speech organ diagnostics//Meas. Tech. 2016. 59(5), 485-490.
- Koelstra S., Pantic M., Patras I. A dynamic texture-based approach to recognition of facial actions and their temporal models//IEEE TPAMI. 2010. V. 32. P. 1940-1954.
- Zaboleeva-Zotova A.V., Orlova Yu.A., Rozaliev V.L., Bobkov A.S. A task of creating a system of automated recognition of emotions//International Conference on Open Semantic Technology for intelligent Systems (OSTIS). 2012. P. 347-350.
- Barabanschikov V.A., Zhegallo A.V. Methods of eye tracking in psychology: educational program//Exp. Psych. 2014. V. 7(1). P. 132-137.
- Filatova N.N., Sidorov K.V. The model for the interpretation of sign of emotions on natural speech//Izvestiya SFedU. Eng. Sci. 2012. V. 9(134). P. 39-45.
- Davydov A.G., Kiselev V.V., Kochetkov D.S., Tkachenya A.V. A choice for the optimal set of informative signs for classification of the speaker’s emotional state by voice//International Conference on Computational Linguistics and Intellectual Technologies (Dialogue-2012). 2011. V. 1(11). 122-128.
- Williamson J.R., Quatieri T.F., Helfer B.S., Ciccarelli G., Mehta D.D. Vocal and facial biomarkers of depression based on motor incoordination and timing//4th International Workshop on Audio/Visual Emotional Challenge (AVEC). 2014. P. 65-72.
- Darley F.L., Aronson A.E., Brown J.R. Differential diagnostic patterns of dysarthria//J. Speech Lang. Hear. R. 1969. V. 12. P. 47-57.
- Huang X., Acero A., Hon H.-W. Spoken Language Processing. Guide to Algorithms and System Development. Prentice Hall, Upper Saddle River. 2001.
- Huang N.E., Zheng Sh., Steven R.L. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis//Proc. R. Soc. Lond. 1998. A 454. P. 903-995.
- Colominasa M.A., Schlotthauera G., Torres M.E. Improved complete ensemble EMD: a suitable tool for biomedical signal processing//Biomed. Signal Proces. 2014. V. 14. P. 19-29.
- Hlavnicka J., Cmejla R., Tykalova T., Sonka K., Ruzicka E., Rusz J. Automated analysis of connected speech reveals early biomarkers of Parkinson’s disease in patients with rapid eye movement sleep behaviour disorder//Sci. Rep. 2017. V. 7(12). P. 13.
- Алимурадов А.К., Муртазов Ф.Ш. Методы повышения эффективности распознавания речевых сигналов в системах голосового управления//Измерительная техника. 2015. № 10. С. 20-24.
