Сравнение производительности PostgreSQL и ее расширения TimescaleDB

Автор: А. И. Платонова
Журнал: Современные инновации, системы и технологии.
Рубрика: Управление, вычислительная техника и информатика
Статья в выпуске: 4 (3), 2024 года.
Бесплатный доступ
В данной статье рассмотрена база данных PostgreSQL и ее расширение TimescaleDB. Целью данной работы является сравнение производительности баз данных при работе с большими данными. Так как в настоящее время при разработке приложений одним из первых вопросов, над которым задумывается разработчик, является выбор базы данных и время работы с ней, то данная тема остается актуальной. Для развертывания обеих баз данных использовано облачное хранилище, так как оно имеет ряд преимуществ перед развертыванием на локальной машине, и пользовательский интерфейс pgAdmin 4. Для проведения тестов сгенерирован тестовый набор данных, представляющий из себя временные ряды со значениями климатических показателей за 2011-2023 года. В статье описана структура тестовых данных, представлены параметры настройки баз данных и листинги SQL-запросов. Для каждой базы данных представлены результаты времени выполнения одного и того же запроса. Эти результаты представлены в виде гистограмм для каждого SQL-запроса, загрузки и выгрузки всего набора данных. После их анализа, представлена их интерпретация. В заключении предложены рекомендации по выбору базы данных под определенные цели.
База данных, временные ряды, PostgreSQL, TimescaleDB, SQL-запрос, время выполнения запроса, большие данные, климатические данные, pgAdmin 4
Короткий адрес: https://sciup.org/14131296
IDR: 14131296 | DOI: 10.47813/2782-2818-2024-4-3-0121-0133
Текст статьи Сравнение производительности PostgreSQL и ее расширения TimescaleDB
DOI:
PostgreSQL – это объектно-реляционная система управления базами данных (ОРСУБД), базирующая на языке SQL ( англ. Structured Query Language – структурированный язык запросов), с открытым исходным кодом [1, 2]. Она имеет ряд возможностей, как встроенных, так и тех, которые можно установить дополнительно. К основных преимуществам PostgreSQL можно отнести:
-
• большой набор типов данных (числовые, символьные, бинарные, геометрические, логический, типы данных для работы с денежными единицами, типы данных для работы с датой и временем, типы данных для представления интернет-адресов, типы данных для хранения данных JSON, UUID и XML);
-
• пользователь может добавить новые типы данных, реализовывать свои дополнительные функции и процедуры на многих языках программирования (Python, PHP, Ruby, R, Java, Go и другие);
-
• так как база данных объектно-реляционная, она поддерживает концепции объектно-ориентированных языков программирования. Например, наследование, которое позволяет быстро создавать новые таблицы на основе существующих;
-
• партицирование (секционирование) таблиц – разбиение таблиц на несколько по какому-либо параметру;
-
• создание триггеров (процедур для выполнения определенной сохраненной инструкции);
-
• механизмы транзакций (операция и набор операций, которые выполняются либо все, либо ни одна из них) и репликации (создание копий на разных серверах);
-
• ODBS (Open DataBase Connectivity – программный интерфейс (API) доступа к базам данных), JDBS (Java DataBase Connectivity – соединение с базами данных на Java);
-
• пользовательский интерфейс pgAdmin 4.
Помимо основных возможностей в PostgreSQL можно установить дополнительные расширения. Самые используемые из них [3]:
-
• расширение pg_stat_statements направлено на мониторинг метрик состояния базы данных, поиск узких мест и в дальнейшем помогает оптимизировать базу данных;
-
• расширение pgcrypto предоставляет функции для шифрования данных;
-
• расширение btree_gist позволяет использовать другие индексы, такие как:
o B-tree – B-дерево, которое позволяет сортировать индексы, используя операторы сравнения;
o GiST – это сбалансированное дерево поиска. Позволяет описать принцип распределения данных, к которым нельзя применять операторы сравнения, по сбалансированному дереву (например, геоданные); для таких данных можно описать операторы пересечения или вхождения в определенный диапазон;
-
• расширение hstore демонстрирует еще одну схожесть с объектноориентированным программированием: оно позволяет хранить пары ключей и значений в одном поле данных, что помогает разгрузить базу данных;
-
• расширение TimescaleDB направлено на работу с временными рядами (большой объем данных, имеющих временные метки) [4], в том числе возможна работа с видеокадрами, имеющими метаданные в виде времени [5], экономическими [6] или климатическими данными [7], также рассмотренными в данной статье.
Цель статьи: изучить показатели производительности работы базы данных при работе с большим объемом данных.
МАТЕРИАЛЫ И МЕТОДЫ
Так как тестирование будет также производится для расширения TimescaleDB, которое направлено на работу с временными рядами, в качестве тестового набора был выбран набор данных с климатическими показателями за 2011 – 2023 год [8]. Этот набор данных как раз представляет из себя временные ряды. Данные представлены с шагом в одну минуту (timestamp) по следующим показателям:
-
• средняя температура (meantemp);
-
• влажность (humidity);
-
• скорость ветра (wind_speed);
-
• среднее давление (meanpressure).
Пример представления части тестового набора данных в графическом интерфейсе pgAdmin 4 показан на рисунке 1.
|
timestamp timestamp without time zone e |
meantemp double precision ° |
humidity double precision ° |
wind_speed double precision ° |
me an pressure double precision “ |
|
|
1 |
2011-01-01 00:00:00 |
15.91304347826037 |
85.8695652173913 |
2.743478260869565 |
59 |
|
2 |
2011-01-01 00:01:00 |
18.5 |
77.22222222222223 |
2.8944444444444444 |
1018 2777777777778 |
|
3 |
2011-01-01 00:02:00 |
17.11111111111111 |
81.88888888888889 |
4.016666666666667 |
1018 3333333333334 |
|
4 |
2011-01-01 00:03:00 |
18.7 |
70.05 |
4.545 |
1015.7 |
|
5 |
2011-01-01 00:04:00 |
18.38888888888889 |
74.94444444444444 |
3.3000000000000003 |
1014 3333333333334 |
|
6 |
2011-01-01 00:05:00 |
19.318181818181817 |
79.31818181818181 |
8.681818181818182 |
1011 7727272727273 |
Рисунок 1. Представление части тестового набора данных.
Figure 1. Presentation of a part of the test dataset.
Одним из простых способов сравнения производительности базы данных – сравнение времени выполнения SQL-запросов к этой базе данных. Далее будут представлены и описаны несколько SQL-запросов к базам данных PostgreSQL и TimescaleDB.
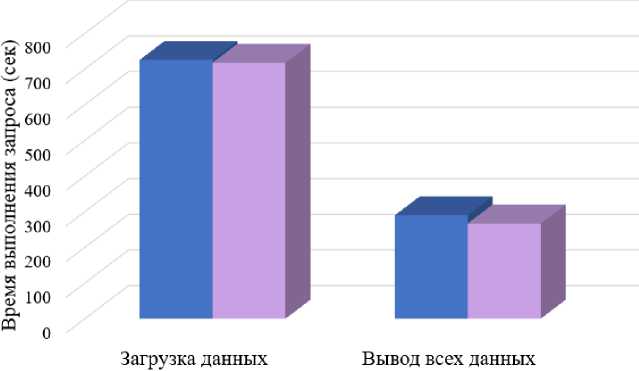
Первое время, которое необходимо оценить – время загрузки данных в базу данных. В случае PostgreSQL для загрузки 6,8 миллионов строк потребовалось 725,46 секунд. Для выполнения аналогичного действия TimescaleDB – 717,43 секунд.
Результаты загрузки данных представлены на рисунке 2. Тестирование выполнялось на сервере баз данных с параметрами:
-
• версия PostgreSQL – 16.2;
-
• версия TimescaleDB – 2.14.2;
-
• 8 CPU;
-
• память – 32 Гб;
-
• использование хранилища – 2,42 Гб.
Некоторые настройки для базы данных TimescaleDB (в основном заданы по умолчанию):
-
• максимальное количество одновременных подключений (max_connections) – 200;
-
• максимальное количество блокировки на транзакцию
(max_locks_per_transation) – 1024;
-
• максимальное количество параллельных рабочих процессов
(max_worker_processes) – 27;
-
• максимальное количество фоновых рабочих процессов, выделенных для TimescaleDB (timescaledb.max_background_workers) – 16;
-
• максимальный объем памяти, который используется для запроса (work_mem) –
5242 Кб.
Все параметры для PostgreSQL заданы по умолчанию.
|
PID |
Type Server Object |
Start Time v |
Status |
Time Taken (sec) |
||
|
о |
18436 |
Import Data postgresql (txarhiac99.hgiie... tsdb/public.dailyclimate |
19.04.2024,20:53:39 |
Finished |
725.46 |
|
|
о |
а |
22788 |
Import Data timescaledb (prOcwldo8w.h... tsdb/public.dailyclimatetest |
19.04.2024,20:40:31 |
Finished |
717.43 |
Рисунок 2. Время загрузки данных в PostgreSQL и TimescaleDB.
Figure 2. Data loading time in PostgreSQL and TimescaleDB.
Как видно из рис. 2, загрузка большого объема данных быстрее у TimescaleDB и с увеличением объема это разница будет только возрастать.
Обе базы данных развернуты на облачном сервере, так как он имеет ряд преимуществ перед развертыванием на локальной машине, таких как [9]:
-
• более высокая производительность, так как уменьшается использование вычислительных ресурсов;
-
• позволяет хранить больше данных и не думать об их размере, чего нельзя не учитывать на локальной машине, так как там есть ограничение размера дискового пространства;
-
• дополнительный встроенный dashboard для анализа трафика, запросов и другой детализации работы базы данных.
Далее сравним запрос, который выводит все данные. Он представлен на листинге 1.
SELECT * FROM public."DailyClimate"
Листинг 1. SQL-запрос для вывода всех данных в таблице.
Listing 1. SQL query to output all data in the table.
Результаты для PostgreSQL – 4 минуты 50 секунд, для TimescaleDB – 4 минуты 27 секунд. Так как объем данных большой, то обе базы данных достаточно долго выполняли запрос, но TimescaleDB все же выполнила его быстрее. Это происходит за счет того, что при загрузке данных PostgreSQL обновляет индексы и когда индексы становятся слишком большими, базе данных необходимо совершить дополнительные действия для выделения памяти, из-за чего она проигрывает по времени TimescaleDB, у которой благодаря секционированию нет таких проблем.
Далее в листинге 2 приведен простой запрос, который возвращает значение средней температуры меньше 18 °C и выводит первые 100 строк, отсортированных перед этим по возрастанию.
SELECT meantemp AS meantemp
FROM public."dailyclimate"
WHERE meantemp < 18
ORDER BY meantemp ASC
LIMIT 100
Листинг 2. SQL-запрос для вывода значения средней температуры меньше 18 °C.
Listing 2. SQL query to output the value of average temperature less than 18 ℃.
В данном случае лучшие результаты показала база данных PostgreSQL – 560 мсек. TimescaleDB потребовалось 605 мсек для выполнения запроса. Так же был проведен аналогичный SQL-запрос только для вывода влажности, при этом PostgreSQL также была быстрее на несколько мсек. Таким образом, можно сделать вывод, что простые запросы, занимающие в основном меньше одной секунды, PostgreSQL обрабатывает быстрее, чем TimescaleDB. Это связано с тем, что TimescaleDB тратит время на планирование и перебор данных в разных секциях, а PostgreSQL в свою очередь просто перебирает каждую запись в таблице.
Следующий запрос используется для вывода скорости ветра во временном промежутке за один месяц (листинг 3).
SELECT timestamp AS time, wind_speed AS wind_speed
FROM public."dailyclimatetest"
WHERE timestamp >= '2020-01-01 00:00:00' AND timestamp <= '202002-01 00:00:00'
ORDER BY time ASC
Листинг 3. SQL-запрос для вывода скорости ветра за промежуток времени один месяц.
Listing 3. SQL query to output the wind speed for a time interval of one month.
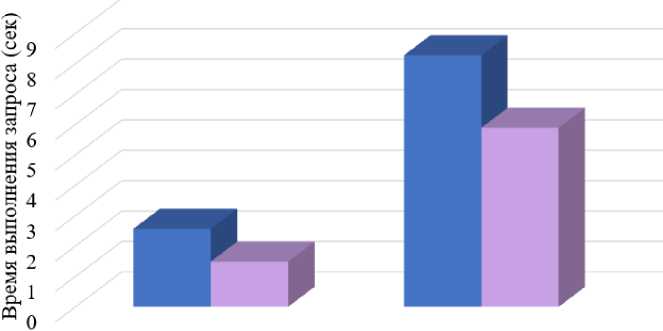
В результате для вывода 44641 строк PostgreSQL потребовалось 2 сек 570 мсек, а TimescaleDB – 1 сек 486 мсек. Из приведённых данных видно, что TimescaleDB выполнила запрос быстрее в 1,73 раза быстрее, чем PostgreSQL. Этот результат достигается за счет секционирования таблиц в TimescaleDB. Изначально при настройке базы данных TimescaleDB была создана гипертаблица, которая разбивает одну таблицу на несколько виртуальных таблиц по месяцам. При этом у каждой таблице свое индексирование. Поэтому при запросе с определенным временным интервалом, поиск происходит быстрее, чем перебор всех данных в одной большой таблице.
Теперь усложним предыдущий запрос и выведем скорость ветра за больший промежуток времени (листинг 4).
SELECT timestamp AS time, wind_speed AS wind_speed
FROM public."dailyclimate"
WHERE timestamp >= '2020-01-01 00:00:00' AND timestamp <= '202101-01 00:00:00'
ORDER BY time DESC
Листинг 4. SQL-запрос для вывода скорости ветра за промежуток времени один год. Listing 4. SQL query to output the wind speed for a time interval of one year.
Количество выводимых строк увеличилось до 527041, а время выполнения запроса до 8,28 секунд для PostgreSQL и 5,89 секунд для TimescaleDB. Таким образом, при увеличении количества обрабатываемых данных увеличивается время запроса для обеих баз данных. Но TimescaleDB все равно работает быстрее в 1,4 раза.
Теперь проверим время выполнения запроса с агрегированием по времени. Выведем среднее значение скорости ветра за каждый день в течении года (листинг 5).
SELECT DATE(timestamp) AS day, avg(wind_speed) AS wind_speed_hour
FROM public."dailyclimatetest"
WHERE timestamp >= '2020-01-01' AND timestamp <= '2021-01-01'
GROUP BY day
Листинг 5. SQL-запрос для вывода среднего значения скорости ветра в день в течении года.
Listing 5. SQL query to output the average wind speed per day during the year.
Время выполнения запроса PostgreSQL превышает время выполнения запроса TimescaleDB в 2,25 раза. Для вывода 367 строк (2020 год был високосным и плюс 1
января 2021 года, поэтому получаем 367 строк) PostgreSQL потребовалось 479 мсек, TimescaleDB – 213 мсек.
Последний запрос, который необходимо рассмотреть – запрос на удаление данных до определенной даты. В TimescaleDB предусмотрена специальная функция drop_chunks(), которая позволяет удалять данные порциями (чанками), на которые они были разбиты при создании гипертаблицы. Листинг SQL-запроса и результат его выполнения представлен на рисунке 3.
Query Query History
1 SELECT drop.chunksfdailycb'matetest1 , 12012-01-011 ::date)
Data Output Messages Notifications
?+ i v o v s sqq drop_chunks text ®
-
1 _timescaledb_internal._hyper_1_1_chunk
-
2 _timescaledb_internal._hyper_1_2_chunk
-
3 _timescaledb_internal._hyper_1_3_chunk
-
4 _timescaledb_internal._hyper_1_4_chunk
-
5 _timescaledb_internalLhyper_1_5_chunk
-
6 _timescaledb_internal._hyper_1_6_chunk
-
7 _timescaledb_internal._hyper_1_7_chunk
-
8 _timescaledb_internal._hyper_1_8_chunk
-
9 _timescaledb_internal._hyper_1_9_chunk
-
10 _timescaledb_internal.Jiyper_1_10_chunk
-
11 _timescaledb_internal._hyper_1_11_chunk
-
12 _timescaledb_internal._hyper_1_12_chunk
Рисунок 3. Листинг SQL-запроса и результат его выполнения.
-
Figure 3. SQL query listing and its execution result.
Как видно, было удалено 12 чанков, так как гипертаблица создавалась по месяцам. Для выполнения запроса TimescaleDB потребовалось 237 мсек.
Для удаления этого же интервала времени в PostgreSQL использовалась стандартная функция delete() (листинг 6).
delete from "dailyclimate"
WHERE timestamp <= '2012-01-01'::date
Листинг 6. Удаление данных за 2011 год.
Listing 6. Deleting data for 2011.
Время выполнения для PostgreSQL составило 1 сек 769 мсек, что больше, чем у TimescaleDB в 7,46 раз. Кроме того, TimescaleDB имеет дополнительные возможности сжатия старых данных, создания политик обновления непрерывного агрегирования и политик хранения данных, что существенно упрощает работу с временными рядами.
РЕЗУЛЬТАТЫ
Далее на рисунках 4 - 6 представлены гистограммы сравнения времени запросов, описанных выше.
Загрузка н вывод данных
■ PostgreSQL I TimescaleDB
Рисунок 4. Загрузка и вывод всех данных.
-
Figure 4. Loading and output of all data.
Запросы с определенным временным промежутком
Запрос за один месяц Запрос за год
■ PostgreSQL ■ TimescaleDB
Рисунок 5. SQL-запросы с выводом параметра за временные промежутки – месяц и год.
Figure 5. SQL queries with parameter output for time intervals - month and year.
Сортировка данных, агрегирование по времени и удаление
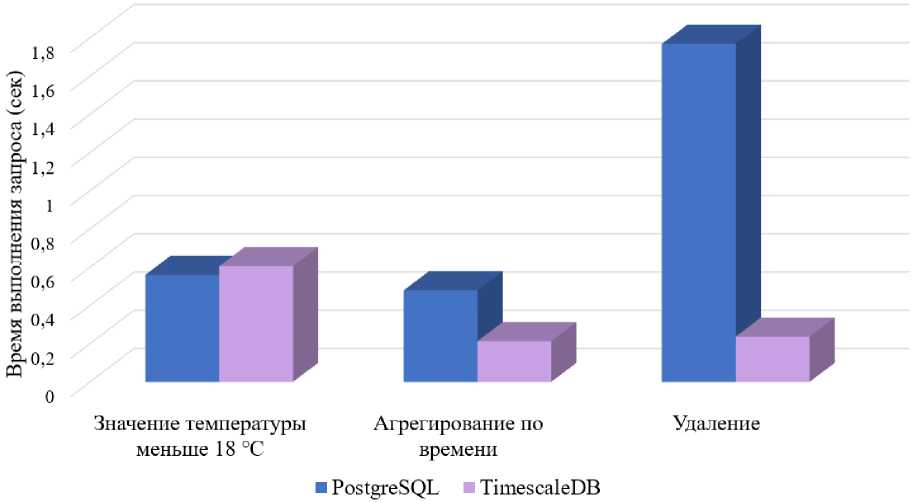
Рисунок 6. SQL-запрос вывода значения, отсортированного по определенному признаку, запрос с агрегированием по времени и удаление данных за определенный промежуток времени.
Figure 6. SQL query to output a value sorted by a certain attribute, a query with time aggregation and deletion of data for a certain period of time.
ОБСУЖДЕНИЕ
В результате можно сделать вывод, что при работе с большими объемами данных TimescaleDB в 1,5-2 раза работает быстрее, чем PostgreSQL. При этом, увеличивая объем данных, производительность TimescaleDB также будет возрастать. Это достигается за счет секционирования, сжатия, настраиваемых политик хранения данных и других встроенных дополнительных функций для работы с временными рядами (например, работа с чанками). Кроме того, эти функции позволяют упростить большие сложные запросы, которых не избежать в PostgreSQL. Единственным выявленным случаем, когда TimescaleDB проигрывает PostgreSQL по времени, являются небольшие запросы, которые выполняются, проверяя каждую строку в таблице. За счет того, что TimescaleDB необходимо проверить каждую секцию, тратится время еще и на планирование. По всем остальным параметрам для работы с временными рядами или другими большими данными, например теми, которые лучше делить на секции, TimescaleDB подходит больше.
ЗАКЛЮЧЕНИЕ
Таким образом, в ходе подготовки данной статьи были сделаны следующие шаги для сравнения производительности баз данных:
-
• развертывание обеих баз данных на облаке;
-
• генерация тестового набора данных с временными рядами;
-
• формирование SQL-запросов;
-
• получение результатов времени выполнения каждого запроса к базам данных;
-
• представление результатов в виде гистограмм;
-
• интерпретация результатов и формулирование рекомендаций по использованию баз данных под определенные цели.
В результате можно сказать, что и PostgreSQL и TimescaleDB отлично справляются с поставленными целям. Только если, например в приложении, необходимо работать с динамически обновляющимися данными или время доступа к базе данных имеет большое значение для корректной работы приложения, то лучше использовать TimescaleDB, так как она больше направлена на работу с такими типами данных и в большинстве случаях имеет более высокую скорость выполнения запросов.
