Сравнительный анализ архитектур backbone для инстанс-сегментации объектов на аэрофотоснимках с использованием Mask R-CNN

Автор: Винокуров И.В., Фролова Д.А., Ильин А.И., Кузнецов И.Р.
Журнал: Программные системы: теория и приложения @programmnye-sistemy
Рубрика: Искусственный интеллект и машинное обучение
Статья в выпуске: 4 (67) т.16, 2025 года.
Бесплатный доступ
В работе проведено сравнительное исследование моделей Mask R-CNN с различными предобученными backbone-архитектурами для реализации инстанс-сегментации объектов недвижимости на аэрофотоснимках. Модели дообучались на специализированном наборе данных ППК «Роскадастр». Анализ точности детектирования ограничивающих рамок и масок сегментации объектов выявил предпочтительные архитектуры — трансформеры Swin (Swin-S и Swin-T) и свёрточная сеть ConvNeXt-T. Высокая точность этих моделей объясняется их способностью учитывать глобальные контекстные зависимости между элементами изображения. Результаты исследования позволяют сформулировать следующие рекомендации по выбору архитектуры backbone: для систем мониторинга в реальном времени, где критична скорость работы, целесообразно применение легковесных моделей (EfficientNet-B3, ConvNeXt-T, Swin-T), для offline задач, требующих максимальной точности (таких как картирование объектов недвижимости), рекомендована крупномасштабная модель Swin-S.
Инстанс-сегментация, backbone, Mask R-CNN, ResNet, DenseNet, EfficientNet, ConvNeXt, Swin
Короткий адрес: https://sciup.org/143185201
IDR: 143185201 | УДК: 004.932.75’1, 004.89 | DOI: 10.25209/2079-3316-2025-16-4-173-216
Comparative Analysis of Backbone Architectures for Instance Segmentation of Objects in Aerial Imagery Using Mask R-CNN
This paper compares Mask R-CNN models with various pretrained backbone architectures for implementing instance segmentation of real estate objects in aerial images. The models were fine-tuned on a specialized dataset provided by the PLC « Roskadastr». Analysis of the accuracy of detecting bounding boxes and object segmentation masks revealed the preferred architectures: Swin transformers (Swin-S and Swin-T) and the ConvNeXt-T convolutional network. The high accuracy of these models is explained by their ability to account for global contextual dependencies of the image. The results of the study allow us to formulate the following recommendations for choosing a backbone architecture: for real-time monitoring systems where performance is critical, lightweight models (EfficientNet-B3, ConvNeXt-T, Swin-T) are advisable; for offline tasks requiring maximum accuracy (such as real estate mapping), the large-scale Swin-S model is recommended.
Текст научной статьи Сравнительный анализ архитектур backbone для инстанс-сегментации объектов на аэрофотоснимках с использованием Mask R-CNN
The automation of aerial imagery analysis is one of the key tasks in modern geoinformatics, urban studies, environmental monitoring, and land management. Among the multitude of tasks in this field, instance segmentation, which involves detecting and precisely segmenting each object in an image at the pixel level ( pixel-wise ), holds a central place. Its solution enables the automatic identification and mapping of ob jects such as buildings, elements of road infrastructure, agricultural facilities, etc., on aerial photographs obtained using aircraft.
The relevance of this work is driven by the growing volume of aerial photography data and the acute need for its operational analysis. However, the development of automatic methods faces a number of challenges inherent to aerial imagery – high dynamic range, significant variability in scales and shooting angles, complex weather conditions, optical distortions, as well as often limited volumes of expertly annotated data for training machine learning models. These factors impose special requirements on the reliability and generalization ability of segmentation models.
In recent years, the Mask R-CNN model [1] has established itself as a de facto standard for solving instance segmentation tasks, consistently demonstrating high results in simultaneous object detection and the construction of their precise binary masks. Its architecture, which extends Faster R-CNN [2] by adding a parallel branch for mask prediction, provides an effective combination of localization accuracy and semantic segmentation quality. This feature makes Mask R-CNN particularly valuable in applications requiring not only detection but also precise contour description of complex-shaped ob jects.
The final effectiveness of this model is largely determined by the choice of feature extractor architecture or backbone – a deep convolutional or transformer network responsible for extracting hierarchical features from the image. For a considerable time, backbone architectures from the ResNet family [3] dominated.
However, the emergence of more modern and efficient CNNs such as DenseNet [4] , EfficientNet [5] , and ConvNeXt [6] , as well as the revolutionary breakthrough of transformer-based architectures, particularly Swin [7] , has radically changed the landscape and expanded researchers’ choices. In this context, conducting a systematic comparative analysis of these architectures for the specific and significant task of segmentation on aerial imagery is of considerable practical and scientific interest.
The scope of this study does not include some modern and promising architectures, such as Vision Transformer [8] in its basic configuration, as well as the latest efficient models like MobileOne [9] , EdgeNeXt [10] , or recurrent network structures focused on sequential feature processing.
Furthermore, hybrid approaches combining convolutional layers with attention mechanisms within a single block, for example, models from the CoAtNet family [11] , were also beyond the scope of this work. This is due to the focus on widely adopted and practically proven architectures, as well as the need to ensure the representativeness and comparability of results. These directions represent potential avenues for future research in the context of optimizing accuracy and computational efficiency for aerial imagery analysis tasks.
The research conducted in this work continues and develops the approaches formulated in [12] and [13] , offering an alternative solution to the problem considered in [13] . In [12] , the target object classes for identification on aerial photography materials were systematized, and a comprehensive methodology for forming a representative dataset with detailed semantic annotation was developed.
The work [13] implemented an approach to improve the accuracy of ob ject mask generation based on Generative Adversarial Networks (GANs), focusing on the task of post-processing segmentation results and subpixel refinement of ob ject contour characteristics. In contrast to this approach, the present work proposes an alternative methodology based on a comparative analysis of different backbone architectures for the Mask R-CNN model, aimed at improving segmentation accuracy at the primary prediction stage, rather than through subsequent post-processing of the results.
The aim of this study is to conduct a comparative analysis of the accuracy and efficiency of seven different pre-trained backbone architectures (ResNet-50, ResNet-101, DenseNet-121, EfficientNet-B3, ConvNeXt-T, Swin-T, Swin-S) within the Mask R-CNN framework for the task of instance segmentation of objects in aerial imagery.
The selection of these backbone architectures for comparative analysis is motivated by the need to cover a representative spectrum of modern approaches to designing deep neural networks, ensuring the comparability of results and testing key research hypotheses.
ResNet-50 and ResNet-101 [3] implement the residual learning framework that addresses the vanishing gradient problem by introduction skip-connections. They ensure stable gradient flow during training and allow for effective scaling of network depth. They are included as the widely accepted baseline standard in computer vision for assessing the impact of network depth on segmentation quality.
DenseNet-121 [4] utilizes a dense-connection paradigm, in which each layer directly accesses the feature maps of all preceding layers. This approach promotes intensive feature reuse, parameter reduction, and improved gradient flow throughout the network.
EfficientNet-B3 [5] employs a compound scaling strategy that optimizes the depth, width, and resolution of the input data, achieving an optimal balance between prediction accuracy and computational complexity under given resource constraints.
ConvNeXt-T [6] is a modern interpretation of the classical convolutional architecture that incorporates the most successful solutions from the transformer domain. The architecture utilizes an increased convolution kernel size, improved normalization, and activation methods, which together provide competitive performance. The architecture utilizes an increased convolution kernel size, improved normalization, and activation methods, which together provide competitive performance.
Swin-T and Swin-S [7] are hierarchical transformers that utilize selfattention within local windows with subsequent window shifting. This approach allows for efficient modeling of global context dependencies while maintaining linear computational complexity relative to image size, which is particularly important for processing high-resolution aerial photography data.
This selection ensures coverage of both classical and modern paradigms, allowing for a systematic assessment of the impact of architectural innovations on the accuracy and effectiveness of instance segmentation in aerial photography conditions.
1. Definition of Research Aims and Objectives
Analysis of recent publications reveals a variety of approaches to using these architectures within the Mask R-CNN model. The work [14]
demonstrates the advantage of transformer-based backbones for precise segmentation tasks, reflecting a trend towards attention-based architectures capable of effectively modeling global contextual dependencies [15 , 16] . Conversely, [17] shows the effectiveness of modern CNNs for solving many practical problems; this finding is supported by works dedicated to optimizing lightweight architectures for real-time tasks [18] .
A comparative analysis in [19] reveals a trade-off between accuracy and computational complexity among different architectures, aligning with the methodology of comprehensive evaluation of modern models that considers not only accuracy metrics but also inference speed, memory consumption, and computational complexity [20] . However, assessing the effectiveness of different backbones for aerial imagery analysis tasks, characterized by high scale variability and the need for small object segmentation, remains insufficiently explored.
The main objectives of this work are:
(1) To adapt the Mask R-CNN model for use with various backbone architectures.
(2) To implement fine-tuning of each model configuration on a custom dataset of aerial imagery.
(3) To compute standard metrics (loss_bbox, loss_mask, bbox_mAP, and segm_mAP) for each model.
(4) To analyze the obtained results, identifying patterns between the architecture type and detection accuracy.
2. Experiment Methodology
The computational experiment for conducting a comparative analysis of the performance of different backbone architectures in the Mask R-CNN model was organized using the MMDetection framework – an open-source toolbox for ob ject detection and instance segmentation based on PyTorch.
The dataset compiled for model training and validation consisted of 435 aerial images obtained by quadcopter. The dataset includes an equal number of JSON files in LabelMe format, containing arrays of polygon contour point coordinates and ob ject names (labels) of 5 types: summer house (label ’building’, 12.470 instances), greenhouse (label ’greenhouse’, 6.450 instances), outbuilding (label ’outbuilding’, 2.150 instances), vehicle (label ’vehicle’, 1.516 instances), and swimming pool (label ’swimming’, 490 instances) [12]. The dataset was partitioned into training and validation subsets with a 75% and 25% split, respectively. The training procedure was carried out on a single NVIDIA A100 80GB GPU.
Base configuration files for each backbone were taken from the official MMDetection (v3.3.0) repository. In all configuration files, the data_root and metainfo parameters were overridden (configured). The former specified the root folder name of the dataset, while the latter contained information about the 5 target classes. The num_classes parameters in bbox_head and mask_head were set to 5, corresponding to the number of target classes.
For correct transfer learning, models were initialized with pre-trained weights from the COCO dataset. The weights were loaded from the MMDetection repository (version 2 or 3). The fine-tuning strategy consisted of two stages: during the first five epochs, the backbone layers were frozen, and only the model’s head were trained ( lr = 1e-3 ). This allowed the classification layers to adapt to the target classes. This was followed by full fine-tuning of all layers with a reduced learning rate ( lr = 1e-4 ) for up to 100 epochs. The stopping criterion was the absence of improvement in the bbox_mAP metric on the validation set for 15 consecutive epochs.
For optimization, AdamW was used with weight_decay = 0.05 (the default value in MMDetection) and gradient clipping with a threshold of 1.0 to stabilize training. Validation was performed after each epoch, and the best model was saved automatically upon improvement of the bbox_mAP metric on the validation set. All experiments were conducted on identical hardware configuration with a fixed random seed = 42 .
Performance evaluation was carried out on the dedicated validation set using COCO metrics bbox_mAP and segm_mAP for IoU thresholds from 0.5 to 0.95 with a step of 0.05. The values of these metrics were calculated for large ( mAP_l ), medium ( mAP_m ), and small ( mAP_s ) objects. The area of small objects is less than 32 2 pixels (< 1024 px2), medium objects range from 32 2 to 96 2 pixels (1024 — 9216 px2), and large objects exceed 96 2 pixels (> 9216 px2); mAP represents the average value of the metrics for detected objects of all sizes.
( a ) ResNet-50
0 20 40 60 80
Epoch
ф
76 л
0 20 40 60 80
Epoch
( b ) ResNet-101
0 20 40 60 80
Epoch
( c ) DenseNet-121
( d ) EfficientNet-B3
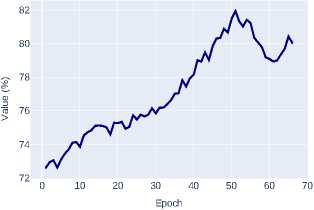
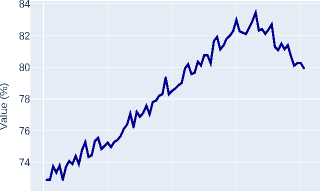
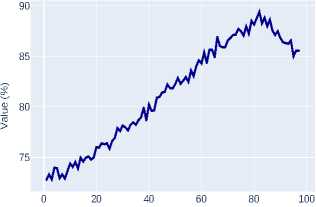
Figure 1. ROI classification accuracy on the validation dataset for classical CNN architectures
3. Experiment Results 3.1. ROI Classification Accuracy Analysis
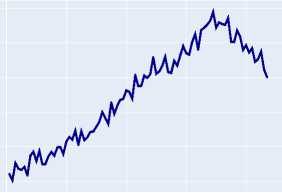
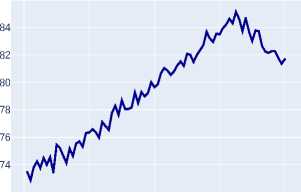
A Region of Interest (ROI) is a selected region on the feature maps generated by the model’s backbone. In object detection and segmentation pipelines, these regions are further processed for object classification (predicting segmentation masks) and bounding box regression. The conducted analysis of experimental data reveals a pronounced trend towards improved ROI classification accuracy when transitioning to modern transformer architectures (Swin-T, Swin-S) and advanced CNN architectures (ConvNeXt-T), as clearly demonstrated by their training dynamics plots on Figure 1 and Figure 2 .
<в
20 40 60 80
Epoch
0 20 40 60 80
Epoch
-
( a ) ConvNeXt-T
-
( b ) Swin-T
-
3.2. Analysis of Bounding Box and Mask Detection Losses
Epoch
( c ) Swin-S
Figure 2. ROI classification accuracy on the validation dataset for transformer and advanced CNN architectures
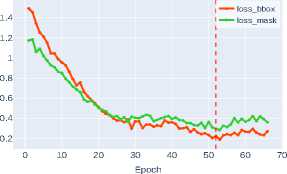
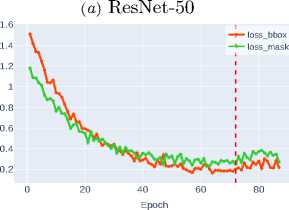
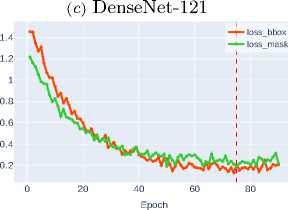
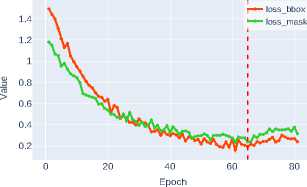
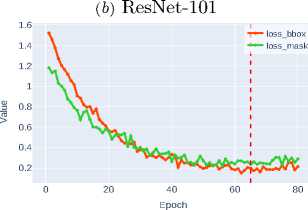
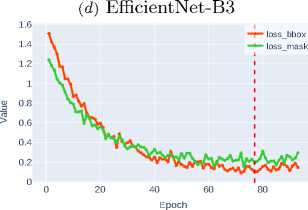
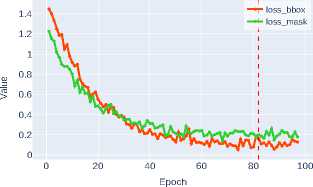
The loss functions for bounding box regression ( loss_bbox ) and mask detection ( loss_mask ) are critically important components of the composite optimization function in instance segmentation tasks. Loss_bbox ensures precise object positioning by minimizing the discrepancy between predicted and ground truth bounding box coordinates. In turn, loss_mask is responsible for the accuracy of pixel-wise classification within each ROI, guaranteeing that the predicted mask matches the object’s contour.
Figure 3 shows that modern architectures, particularly Swin-T and Swin-S transformers, demonstrate high efficiency in optimizing loss functions. The Swin-S architecture achieves the minimum values for both metrics, indicating its clear advantage due to its ability to effectively model
Value Value Value
( e ) ConvNeXt-T ( f ) Swin-T
( g ) Swin-S
Figure 3. Bounding box regression and object mask detection losses for various CNN architectures
Table 1. Loss function values on the validation dataset for different backbone architectures
The superior performance of Swin-S confirms the promise of transformerbased approaches for instance segmentation tasks, where both localization accuracy and pixel-level classification quality are critically important.
Meanwhile, Table 1 show comparable to DenseNet-121 efficiency of Swin-T and ConvNeXt-T models, ranking among the most balanced solutions for optimizing both metrics.
-
3.3. Bounding Box Detection Accuracy Analysis
Below, in Figure 4 and Figure 5, the graphs of bounding box detection accuracy metrics bbox_mAP obtained from experimental studies for ob jects of different sizes – mAP_s , mAP_m , and mAP_l (see Section 2) are presented.
Analysis of the experimental data reveals a consistent improvement in the mAP metric across the studied architectures, as shown in Table 2 . The last column indicates the epoch at which the backbone architecture with the best weights for bounding box detection is formed.
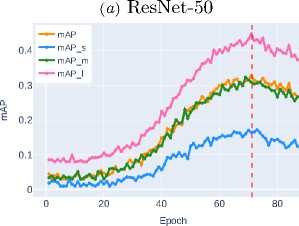
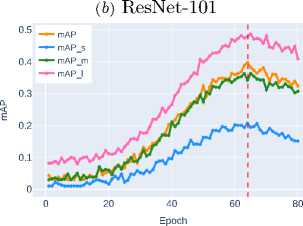
ResNet-50 demonstrates the baseline accuracy level ( mAP ∼0.3236 ), while DenseNet-121, thanks to its dense connection mechanism, shows a noticeable improvement ( mAP ∼0.3800 ). ResNet-101, despite its increased depth, shows only moderate improvement ( mAP ∼0.4080 ) compared to DenseNet-121, highlighting the limitations of simply increasing network depth.
Table 2. Bounding box detection accuracy metrics for different backbone architectures
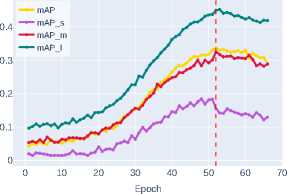
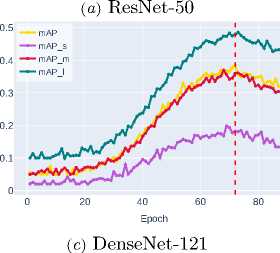
Figure 4. Bounding box detection accuracy on the validation dataset for classical CNN architectures
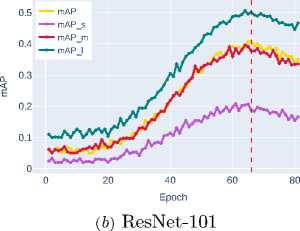
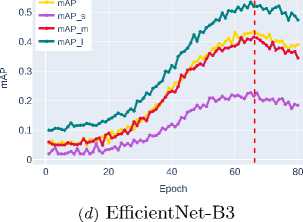
The significant performance jump with EfficientNet-B3 ( mAP ∼0.4340 ) demonstrates the effectiveness of the compound scaling strategy. The increased accuracy of the ConvNeXt-T architecture ( mAP ∼0.4300 )
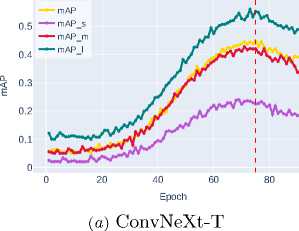
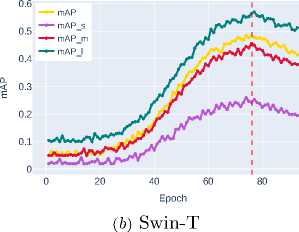
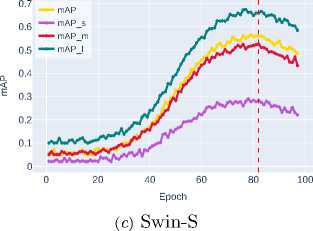
Figure 5. Bounding box detection accuracy on the validation dataset for transformer and advanced CNN architectures
indicates the potential of convolutional networks with an enhanced ability to model complex spatial-contextual dependencies.
Further improvement is shown by Swin-T ( mAP ∼0.4702 ), which uses a window attention mechanism to efficiently model global contextual interactions while maintaining linear computational complexity. The best result is demonstrated by Swin-S ( mAP ∼0.5606 ), clearly illustrating the advantages of transformer architectures and their exceptional effectiveness in accurately localizing objects of all size categories, especially small ob jects, where the most significant performance gain is observed.
-
3.4. Segmentation Mask Detection Accuracy Analysis
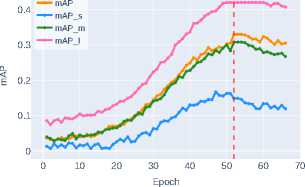
Figure 6 and Figure 7 present graphs of segmentation mask detection accuracy metrics segm_mAP for objects of different sizes, see Section 2 .
The initial level of detection accuracy is demonstrated by ResNet-50 ( mAP ∼0.3000 ). DenseNet-121 achieves some improvement in metrics
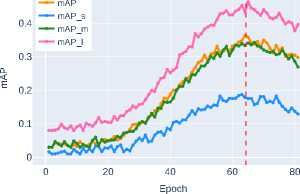
( c ) DenseNet-121
Figure 6. Segmentation mask detection accuracy on the validation dataset for classical CNN architectures
( d ) EfficientNet-B3
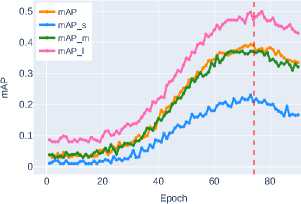
( mAP ∼0.3121 ) through efficient feature reuse via dense connections. Increasing network depth, as implemented in ResNet-101, provides only a slight improvement in segmentation quality ( mAP ∼0.3561 ), indicating the limitations of this approach. The application of compound scaling in EfficientNet-B3 stabilizes the metrics at the level of mAP ∼0.3795 , but a true qualitative leap is observed when transitioning to modern architectural solutions.
The advanced CNN architecture ConvNeXt-T demonstrates significant improvement ( mAP ∼0.3948 ), surpassing traditional approaches by optimizing the spatial feature extraction process. The transformer architecture Swin-T with its window attention mechanism shows further improvement ( mAP ∼0.4332 ), effectively combining local and global contextual dependencies.
The highest effectiveness in the instance segmentation task is achieved by the transformer architecture Swin-S ( mAP ∼0.5030 ), setting a new
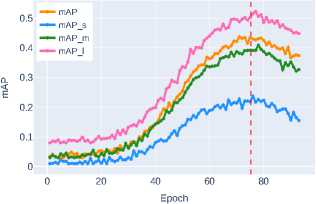
( a ) ConvNeXt-T ( b ) Swin-T
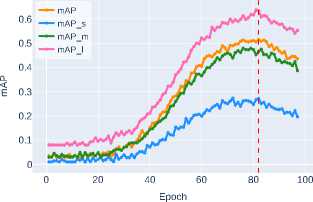
( c ) Swin-S
Figure 7. Segmentation mask detection accuracy on the validation dataset for transformer and advanced CNN architectures
standard of accuracy for objects of all size categories. Particularly significant results are observed for small object segmentation, where this approach demonstrates the most substantial advantage over other architectures, see Table 3 . The last column indicates the epoch at which the backbone architecture with the best weights for segmentation mask detection is formed.
-
3.5. Analysis of mAP Metrics for Different Architectures
The results of the comparative analysis of detection accuracy metrics for bounding boxes and instance segmentation masks on aerial imagery reveal significant performance differences among the models, as shown in Figure 8. Classical convolutional networks (ResNet-50, ResNet-101, DenseNet-121) demonstrate the lowest metric values, while modern architectures (ConvNeXt-T, Swin-T) provide a substantial gain in accuracy. The Swin-S architecture outperforms all considered models on both metrics.
Table 3. Segmentation mask detection accuracy metrics for different backbone architectures
|
Backbone |
mAP |
mAP_s |
mAP_m |
mAP_l |
Epoch |
|
ResNet-50 |
0.3000 |
0.1200 |
0.2800 |
0.4200 |
52 |
|
ResNet-101 |
0.3561 |
0.1900 |
0.3600 |
0.5100 |
67 |
|
DenseNet-121 |
0.3121 |
0.1600 |
0.3300 |
0.4800 |
73 |
|
EfficientNet-B3 |
0.3795 |
0.2000 |
0.3700 |
0.5200 |
65 |
|
ConvNeXt-T |
0.3948 |
0.2300 |
0.4000 |
0.5500 |
75 |
|
Swin-T |
0.4332 |
0.2400 |
0.4100 |
0.5600 |
78 |
|
Swin-S |
0.5030 |
0.2800 |
0.4700 |
0.6300 |
82 |
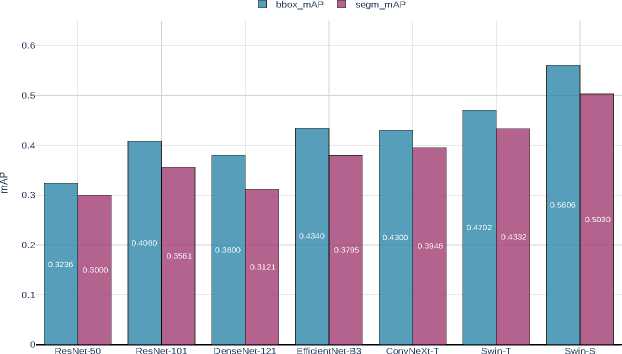
Figure 8. Comparison of bbox_mAP and segm_mAP metrics for different backbone architectures of the Mask R-CNN model
All architectures exhibit a consistent pattern where the bbox_mAP value exceeds the segm_mAP value, which aligns with theoretical expectations – the task of precise pixel-wise object delineation is more challenging compared to bounding box detection.
The magnitude of the gap between metrics varies depending on the architecture. The smallest relative deviation is observed for Swin-S ( ∼0.0576 ), indicating its balanced effectiveness in solving both tasks. Conversely, the largest gap is characteristic of ResNet-50 ( 0.0236 ) and
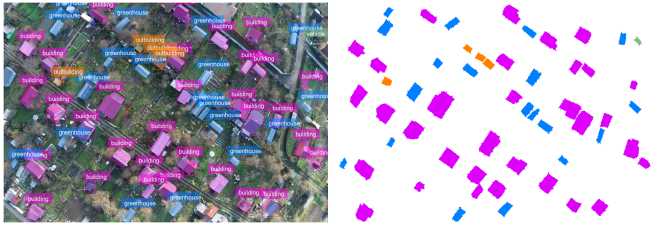
Figure 9. ResNet-50 (contour detection error ∼15%)
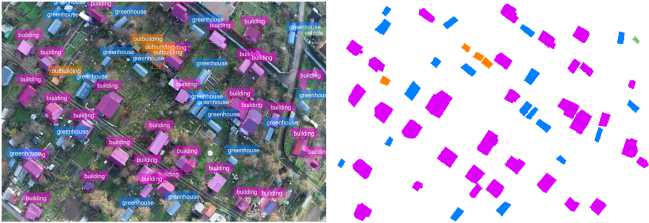
Figure 10. ResNet-101 (contour detection error ∼10–11%)
DenseNet-121 ( 0.0679 ), suggesting their suboptimal adaptation to the instance segmentation task.
Thus, the obtained data confirms the promise of using transformerbased and modern convolutional architectures for processing aerial imagery that requires simultaneous achievement of high accuracy in both object detection and segmentation.
-
3.6. Comparative Visualization of Object Segmentation Mask Contours
Figure 9 –15 present object detection results on a fragment of an aerial image using the Mask R-CNN model with different backbones. The practical significance of effectively solving this task is described in [13] .
Analysis of segmentation mask contour detection error revealed a direct dependence between the backbone architecture and segmentation accuracy. Classical CNN architectures demonstrate the highest error: ResNet-50 ( ∼ 15%), ResNet-101 ( ∼ 10–11%) and DenseNet-121 ( ∼ 12%).
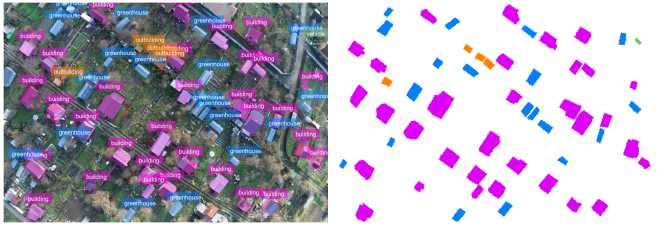
Figure 11. DenseNet-121 (contour detection error ∼12%)
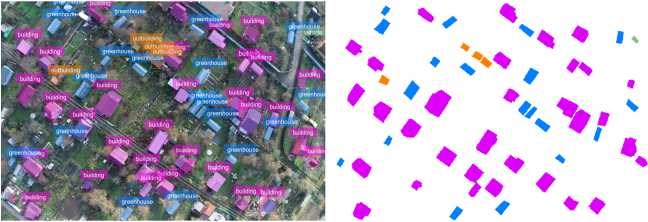
Figure 12. EfficientNet-B3 (contour detection error ∼10– 11%)
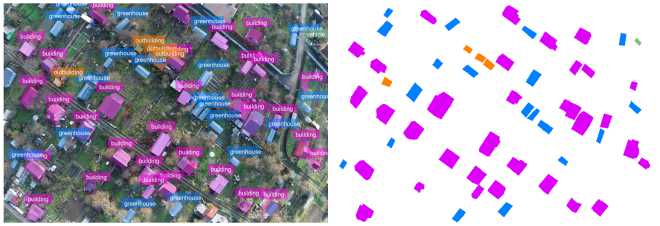
Figure 13. ConvNeXt-T (contour detection error ∼7%)
EfficientNet-B3 shows a result ( ∼ 10–11%) comparable to ResNet-101 and DenseNet-121, which may indicate a performance plateau for this class of traditional convolutional architectures. Lower error values were obtained for modern architectures ConvNeXt-T ( ∼ 7%) and Swin-T ( ∼ 3–5%). The
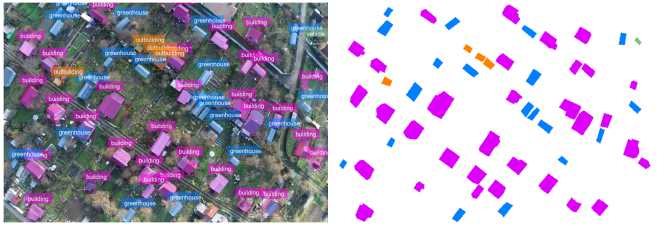
Figure 14. Swin-T (contour detection error ∼3–5%)
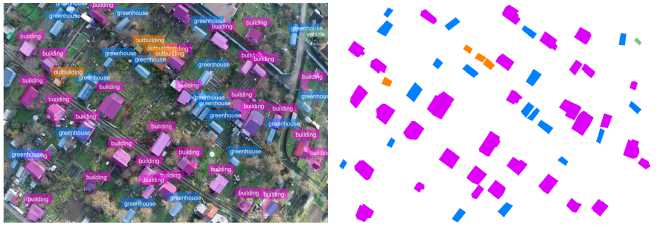
Figure 15. Swin-S (contour detection error ∼1–2%) lowest segmentation mask contour detection error was recorded for the transformer architecture Swin-S ( ~ 1-2%), Figure 15.
The obtained results indicate that using modern architectures, particularly transformers, significantly improves the accuracy of object boundary positioning compared to classical CNN approaches. This is especially important for solving applied tasks requiring high segmentation accuracy, such as mapping or cadastral registration [12, 13] . The improved accuracy opens up opportunities for automating aerial image processing with minimal human involvement.
-
3.7. Model Training and Inference Time Evaluation
Experimental studies of Mask R-CNN models with different backbone architecture types were conducted using an NVIDIA A100 80GB GPU. The model training times and their inference times for images with an average size of 1010 x 750 px are presented in Table 4.
Table 4. Model Training and Inference Times
|
Backbone |
Training Time |
Inference Time |
|
|
ResNet-50 |
12–18 |
min. |
0.05–0.1 sec. |
|
DenseNet-121 |
20–30 |
min. |
0.08–0.15 sec. |
|
ResNet-101 |
18–25 |
min. |
0.07–0.12 sec. |
|
EfficientNet-B3 |
22–35 |
min. |
0.09–0.16 sec. |
|
ConvNeXt-T |
15–22 |
min. |
0.06–0.1 sec. |
|
Swin-T |
30–45 |
min. |
0.1–0.2 sec. |
|
Swin-S |
1.5–2 hours |
0.2–0.4 sec. |
|
Conclusion
This work presents a comparative analysis of the effectiveness of seven backbone architectures within the Mask R-CNN model for the task of instance segmentation of objects in aerial imagery. The experimental results demonstrate the advantage of attention-based architectures (Swin-T and Swin-S) and the advanced CNN (ConvNeXt-T) over classical convolutional networks.
It has been established that the model’s ability to capture global contextual dependencies is a significant factor for achieving high segmentation accuracy under aerial photography conditions. The Swin-S architecture showed the highest values of the metrics bbox_mAP (0.5606) and segm_mAP (0.5030) , especially for segmenting small-sized ob jects. However, achieving maximum accuracy is associated with significant computational costs, which limits the use of Swin-S to off-line processing tasks. For real-time scenarios, the use of Swin-T and ConvNeXt-T models is more appropriate, providing an acceptable compromise between accuracy and performance.
The research provides empirical data for selecting a backbone architecture depending on the requirements of a specific application. The research results are currently being used in the mapping information system of the PLC «Roscadastr». A promising direction for future work is the development of methods for optimizing the accuracy-performance trade-off, including the creation of hybrid architectures.
