Сравнительный анализ измерителей редкости невзаимозаменяемых токенов

Автор: Белоусов Д.А., Янович Ю.А.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Информатика и управление
Статья в выпуске: 4 (68) т.17, 2025 года.
Бесплатный доступ
Невзаимозаменяемые токены (NFT) утвердились как новый класс цифровых активов с уникальными свойствами владения, верифицируемыми через блокчейнтехнологии. Их применение в цифровом искусстве породило NFT-коллекции, где каждый токен, созданный смарт-контрактом, сочетает уникальные визуальные характеристики и метаданные. Редкость как ключевой фактор стоимости анализируется через призму современных методов оценки, включая платформенные решения (OpenSea, Rarity.tools) и научные подходы. В работе представлены результаты сравнения шести популярных метрик редкости (Rarity.tools, OpenRarity, GoRarity и др.) с использованием бенчмарков ROAR и DIT на данных 100 крупнейших коллекций. Эксперименты демонстрируют различия в вычислительной сложности алгоритмов и корреляции с рыночными ценами, выявляя преимущества гибридных методов, комбинирующих анализ признаков и оптимизацию по историческим сделкам.
Блокчейн, невзаимозаменяемые токены, редкость
Короткий адрес: https://sciup.org/142247113
IDR: 142247113 | УДК: 004.051
Comparing NFT rarity meters and benchmarks
Non-fungible tokens (NFTs) have established themselves as a new class of digital assets with unique ownership properties verified through blockchain technology. Their application in digital art has given rise to NFT collections where each token, generated by smart contracts, combines distinctive visual characteristics with embedded metadata. Rarity as a critical value determinant is examined through modern evaluation methods, encompassing platform-native solutions (OpenSea, Rarity.tools) and scientific methodologies. This work presents a comparative analysis of six prominent rarity metrics (Rarity.tools, OpenRarity, GoRarity, etc.) using ROAR and DIT benchmarks on data from 100 major collections. The experimental results reveal significant differences in computational complexity and market price correlations, demonstrating the superiority of hybrid approaches that synergize trait analysis with historical transaction-based optimization.
Текст научной статьи Сравнительный анализ измерителей редкости невзаимозаменяемых токенов
За последнее десятилетие невзаимозаменяемые токены (NFT) трансформировали цифровой арт-рынок, создав новые механизмы установления уникальности и владения цифровыми активами [1,2]. Согласно данным DappRadar, совокупный объем торгов NFT превысил $25 млрд в 2024 году, при этом 72% транзакций приходятся на генеративные коллекции,
(с) Белоусов Д. А., Янович Ю. А., 2025
@ Федеральное государственное автономное образовательное учреждение высшего образования «Московский физико-технический институт (национальный исследовательский университет)», 2025
где редкость отдельных характеристик становится ключевым фактором ценообразования. Однако отсутствие стандартизированных методов оценки редкости создает существенные сложности для участников рынка: от расхождений в ранжировании токенов на маркет-плейсах до ошибок в прогнозировании инвестиционной привлекательности.
Существующие подходы к измерению редкости можно разделить на три категории. К первой относятся статистические методы, основанные на анализе частотности признаков, например Rarity.tools и OpenRarity. Вторая категория — это топологические подходы, учитывающие сходство между токенами, такие как GoRarity. Наконец, третью категорию составляют оптимизационные модели, например KRAMER и ROAR, которые адаптируют веса признаков под рыночные данные.
Несмотря на активное развитие методов, сохраняются фундаментальные проблемы, включая разрыв между теоретическими метриками и фактической ценностью токенов, экспоненциальный рост вычислительной сложности для крупных коллекций, а также отсутствие универсальных бенчмарков для сравнительного анализа.
Основной вклад данной работы включает:
• систематизацию шести ключевых методов оценки редкости и двух методов сравнения измерителей редкости с формализацией их математического аппарата;
• экспериментальное доказательство эффективности гибридных подходов, сочетающих частотный анализ с оптимизацией по историческим сделкам (увеличение корреляции с ценами на 37% по сравнению с базовыми методами);
• практические рекомендации по выбору метрик в зависимости от размера коллекции и требований к производительности вычислений.
2. Измерители редкости и их эффективность
2.1. Бенчмарк ROAR
Исследование основано на анализе 100 крупнейших NFT-коллекций Ethereum-сети, охватывающих 2.1 млн токенов и 4.8 млн транзакций.
Измерение редкости - один из основных инструментов торговли коллекционными NET, который позволяет участнику рынка оценить токен [3]. Поэтому важным представляется исследование принципов устройства измерителей редкости, их полезности и эффективности. Оценка интерпретируемых измерителей зачастую зависит от признаков токена или их визуальной репрезентации [4].
Обозначим Xv = {ХГ1} ^ =1 коллекцию из N токенов с Т атрибутами, т.е. ее токен представим в виде Хп = (хп , 1 ,..., хп ,т ). Тогда измерителем редкости этой коллекции можно назвать функцию R : Xv ^ [0, от), ставящую в соответствие более редкому токену более высокую оценку. Существует множество подходов к измерению редкости токена. Оценка интерпретируемых методов зачастую является результатом оценки отдельных признаков токена: rt : Х ^ [0, от), t = 1,..., Т. Эффективностью измерителя редкости R на коллекции Xv будем считать функцию F(R; X v ), которая показывает, насколько хорошо измеритель редкости соответствует рынку. Вводя это понятие, мы исходим из того, что более редкие токены являются также и более ценными, а эффективный измеритель способен отражать эту взаимосвязь [5-7].
Пусть в рамках рассматриваемой коллекции Xv было со вершено D сделок. Тогда каждая транзакция может быть описана индексом торгуемого токена id, его ценой pd и временем сделки td, г де d = 1,...,D. Авторы бенчмарка ROAR [8] вводят функции относительной редкости: p(R1,R2) = ln (1+^1), относительной цены: ^(pi,p2) = ln (eQ, а также функцию весов, основанную на ядре Епанечникова:
|
k(t d i1 ,t d 21 ) = < |
4
(i — ' ’ /, \щ —
t,y 0, |td11 — td21 \ > h. |
Рассматривая все пары сделок (dy ,dy), j = 1,...,J, где ,J = ( D 2 1 D , формируются векторы относительных редкостей, относительных цен и весов:
|
■ p (R(X d i1 ) , R(X d 21 ))! Г ^(P d i1 ,P d 21 )! Ф = ф(R') = \ , ф = : , k = _p(R(X d i J ), R(X d 2 j ))_| k(Pdi7 , P d 2 j )] |
’k(t d4 ,t d 21 У • • • . k(tdlj ,td2j у |
Также вводятся следующие обозначения:
-
• 1j G RJx1 — вектор из единиц,
T
-
* a k = k T ij • 1 J — средшш вектор а е весами k.
-
• a k = а — a k — пептриров;шний вектор а.
-
• K = kl K G RKxK — диагональная матрица с элементами вектора, k.
Это позволяет записать взвешенную корреляцию в следующем виде:
р ( ф, Ф; k ) =
________ Ф T • K • ф k ________ у/ Ф T • K • ф k • у/ф T • K • ф k
В качестве показателя эффективности измерителя редкости R на кол лекции Х м предлагается брать значение взвешенной корреляции между векторами относительной редкости этого измерителя и относительной цены сделок данной коллекции:
FWC(R; X N ) = p&(R) ф; k ).
Сложность: О (D4).
2.2. Бенчмарк DIT
В контексте снижения размерности оценка редкости походит на задачу одномерного шкалирования [9]. Так, под наблюдаемыми различиями токенов можно понимать разницу в их стоимости, а под конфигурацией точек в одномерном пространстве - оценки их редкости. Действительно, рассмотрев все сделки пары токенов (i,j ), мы можем получить различие токенов 5у с соответствующим весом W ij:
W ij
^ ij
^dl ,t d 2 ), di ,d 2 : ( i d 1 ,i d 2 )=( i,j )
— E
k(tdl ,td2 ) In —
P d
Wij , , d i ,d- 2 : ( i d 1 ,i d2 ) = (ij)
Расстояние между токенами в одномерном пространстве, в свою очередь, может быть записано в виде dij(R) = \R(Xi) — R(Xj )|.
Насколько хорошо одномерная конфигурация приближает наблюдаемые различия между токенами можно выразить стресс-функцией, характерной для задачи неметрического взвешенного одномерного шкалирования. Ее же предлагается принять в качестве показателя эффективности измерителя редкости:
Сложность: O(N 2).
FUSR X N )
Е^ W j (d jj (R) - 6д )2
\ Ei,j=i Wi i di j (R)2
2.3. Измеритель редкости Rarity.tools
Измеритель одноименной платформы определяет редкость токена X k G X n через показатели редкости его признаков: Rrt(X k ) = ^^ 1 г^Х ь ) [10]. Дополнительно к имеющимся, вводится мета-признак - признак, изначально не присутствующий в коллекции - количество признаков, который равен числу признаков каждого токена. Введём обозначение вероятности встретить токен с определённым признаком в коллекции:
P t (X k ) =
#{X G X N,t lx — X k,t }
N
*
В качестве оценки редкости признака авторы предлагают брать число, обратно пропорциональное его вероятности: r r t(X k ) — рууД 1^1'
Сложность: O(NT ).
2.4. Измеритель редкости OpenRarity
Команда маркетплейса OpenSea предложила собственный подход по измерению редкости [12]. В его разработке они основывались на том, что определять редкость токена как сумму редкостей его признаков не вполне корректно. Действительно, если редкость признака зависит от вероятности обладания им, то редкость токена должна зависеть от вероятности обладания всеми его признаками. Предложенный измеритель основан на оценке собственной информации токена:
гД (Xk) — - log 2 ( P t (X k )) ------,
EN =1 P t (Xn) • log 2 (P t (Xn))
T +1
%!' (Xk) — £ r'f (Xk) — t=1
I (X k ) E I (X ) ’
Авторы также вводят мета-признаки количество признаков и количество уникальных признаков. Последний равен числу признаков токена, уникальных для всей коллекции, и участвует в ранжировании токенов двойной сортировкой: вначале по оценке редкости токена, а затем по количеству его уникальных признаков. Итоговый показатель редкости токена может быть записан в виде
1^ (X k ) — R ^ (X k ) + X k, 0 • (T ^Xg N
*
Сложность: O(NT ).
2.5. Измеритель редкости GoRarity Платформа NFTGo разработала измеритель редкости, основываясь на коэффициенте Жаккара - мере сходства в пространстве признаков [13]. Для токенов Xk, Xn G Xn коэффициент равен К(Xk, Xn) = EL1 [xk,t = Xn,t] 2T - EL[^k,t = Xn,t] .
Показатель токена в коллекции равен среднему расстоянию до остальных токенов в кол лекции:
n
R0°(X k ) = £ (1 - К(X k ,X n )) .
n=1
Для учёта размера коллекции оценки редкости токенов нормализуются:
R^°(X k ) = 100 • RxX-R m in,
Rmax Rmin где Rmin = min({Rg°(Xj)}N=i), Rmax = max({R^°(Xj)[^).
Сложность: O(N 2 T ).
2.6. Измеритель редкости KRAMER
На примере NFT-коллекции Kanaria блокчейна Kusama был предложен новый подход к измерению редкости, рассматривающий признаки в их совокупности [14]. Так, рассматривая отдельно каждый атрибут, N токенов коллекции можно разбить на подмножества по совпадающим значениям g этого атрибута. Количество элементов таких подмножеств будет соответствовать числу токенов с определённым признаком: Ef=i Ng = N■ Путем сравнения подмножеств N i , N j (i = j ) каждому признаку присваивается следующее количество баллов:
Nj . Ni i ^ N+Nj, j ^ N n .
После проведения всех сравнений оценка признака t равна усредненному числу набранных баллов:
1 1 v n 9
St = G - 1 ^ I 2 + N + Ng I ,
\ 9=1 t ' 9
где — 2 убирает сравнение подмножества. соответствутощего признаку t. с самим собой. Далее, она будет учитываться с весом, равным среднему по соответствующему атрибуту:
r k (X k ) =
N • s t E i=i N i • S i .
Итоговая оценка редкости токена равна взвешенной сумме оценок его признаков:
т
Rkr(Xk) = £at • rt?(Xk), t=i где веса ai,... ат находятся из решения задачи максимизации эффективности измерителя редкости:
F(Rkr ; X n ) ^ max .
R kr eR a
Сложность: O(V 2 + (NT + F ) • Iopt), где
• V = maxt(#{XN,t}),
• Iopt- количество итераций в процессе оптимизации,
• F - сложность одного вычисления показателя эффективности, т.е. F = O(D4) для ROAR ii F = O(N2) для DIT.
2.7. Измеритель редкости ROAR
Данный измеритель редкости предлагает совместить описанные выше подходы. Для этого находится такая взвешенная комбинация оценок признаков предыдущих измерителей, которая максимизирует показатель эффективности:
Т +1 2 Т +3 3Т+4
R tf (X k ) = £ a t • r tf X )+ £ a t • r tf (Х к )+ £ a t • r tf (Х к ) + а з т +5 • R9°(X k ), t =1 t = T +2 t =2 T +4
F (R tf ; X N ) ^ max .
R e^“
Причем итоговая оценка редкости токена определяется наиболее эффективным измерителем для данной коллекции:
Rrr(Xk) = arg^ax F(R; XN), где Rrr = {Rrt, Ro, R9, Rkr, Rtf }.
Сложность: O(V2 + (NT2 + F ) • Iopt).
2.8. Измеритель редкости DIT
Оценка коллекции происходит путем подбора такой конфигурации показателей редкости, которая максимизирует эффективность, выраженную через стресс-функцию:
Fus(Rdt ; X n ) ^ min .
Rdt
Минимизация стресса происходит следующим итеративным методом:
7+1
X i =
Е = W ij ^х9 - d ij U£(x9 - х9 E N =i W i,
U i (t) = I
I
(2 - I)
,
И
Sigil (t), |t| > E.
Далее, необходимо продолжить оценку на всю коллекцию [15]. Те токены, что не попали в обучающую выборку торгов, оцениваются непараметрически [16]:
Rk(x ) =
^ N ddtfv 1 | R (^ " )- R (^)I
Xn =1 R (X' К ( £k ( X ; X n ) )
—
—
v n | R(x n ) - R(x ) | ч
^"=1 Л ( e k ( X ; X n ) )
—
—
где
• R - интерпретируемый измеритель редкости,
• К (a) = e-a - экспоненциальное ядро,
• Ek(X; Xn) _ расстояние от токена X до его k-ro со<-еда в Xn-Сложность: O(N2Iopt).
3. Численные эксперименты
Упомянутые выше измерители редкости, а также бенчмарки были протестированы на даннв1х 100 NFT-коллекций из списка крупнейших по объемам торгов платформы DappRadar [17]. Для каждой из выбранных коллекций были собраны метаданные ее токенов и совершённые с ними продажи на момент осени 2024 года. Полученные таким образом данные составили более 4,1 млн транзакций, совокупный объем которых превышает 47 млрд долларов США [18]. Количество токенов в отобранных коллекциях варвируется от 2027 до 28 170. а количество признаков — от 2 до 67.
С целью практического сравнения сложности описанных алгоритмов в ходе их выполнения были проведены измерения ключевых этапов.
Все эксперименты проводились на серверной платформе со следующей конфигурацией:
• CPU: AMD Ryzen 9 7950Х (5.9 Ггц, 16 ядер); • RAM: 40 Гб DDR5; • Версия Python: 3.12.10; • Версии фреймворков: NumPy 2.1.1, SciPy 1.14.1, Pandas 2.2.2. 3.1. Классические измерители редкости
В этом эксперименте проводится оценка всех коллекций каждым из измерителей редкости. Сравнение времени, затраченного на оценку коллекций различными измерителями, приводится на рис. 1.
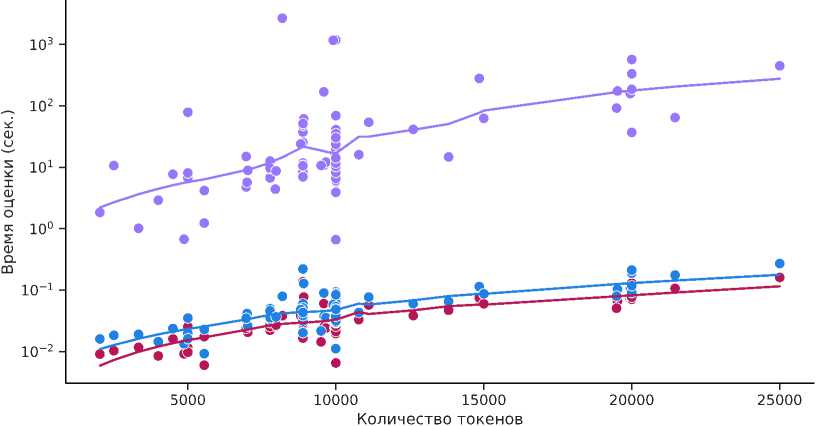
Рис. 1. Время, затраченное классическими измерителями редкости па оценку всех токенов каждой из коллекций
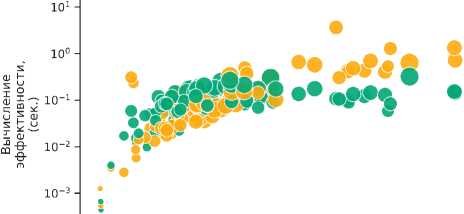
Достаточно сильная дисперсия времени работы измерителя GoRarity, даже на схожих по размеру коллекциях, объясняется его архитектурой. А именно, при увеличении числа уникальных признаков растет сложность вычисления коэффициента Жаккара, как видно из рис. 2.
io2
Количество признаков
• 2000 • 4000 • 6000 • 8000 • 10000
S ю1 со
10°

10000 15000
Количество токенов
Рис. 2. Время, затраченное измерителем редкости GoRarity па оценку всех токенов каждой из коллекций. Размер маркеров пропорциоиалеи количеству уникальных признаков в соответствующей коллекции
3.2. Оптимизируемые измерители редкости
Данная категория подразумевает учет рыночных данных измерителями редкости при оценке коллекции. В нее вошли измерители KRAMER, ROAR и DIT. Доля торгов, формирующих обучающую выборку, варьировалась в зависимости от измерителя. Как видно на рис. 3, измеритель DIT способен учитывать гораздо больше рыночных данных при сопоставимом времени работы.
Количество токенов
• 1000 • 4000 • 7000 • 11000 • 15000


20000 40000 60000 80000
Количество сделок для обучения
• KRAMER • ROAR • DIT
Рис. 3. Среднее время итерации оптимизируемых измерителей редкости, затраченное па работу с обучающей выборкой каждой из коллекций. Размер маркеров пропорционален количеству токенов в выборке
3.3. Бенчмарки
В процессе оценки эффективности можно выделить следующие ключевые этапы: подготовку данных коллекции, подготовку данных измерителя и вычисление показателя эффективности. Так, первый этап не зависит от измерителя и, выполнив его единожды, можно производить оценку различных измерителей на данной коллекции. В качестве примера такого этапа можно вспомнить построение вектора относительных цен бенчмарка ROAR или матрицы различий токенов бенчмарка DIT. Второй этап, в свою очередь, необходимо выполнять для каждого измерителя в отдельности, как например подсчет вектора относительных редкостей или начальной конфигурации. Результат сравнения бенчмарков представлен на рис. 4.
Бенчмарк
ROAR DIT
Токены
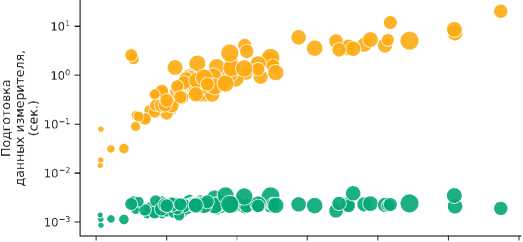
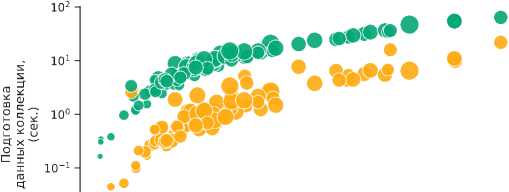
IO’2 -
0 5000 10000 15000 20000 25000 30000
Количество сделок
Рис. 4. Время, затраченное бенчмарками па оценку эффективности измерителя Rarity.tools па каждой из выбранных коллекций. В процессе оценки эффективности выделены этапы подготовки данных коллекции, подготовки данных измерителя и вычисления целевого показателя. Размер маркеров пропорционален количеству токенов в выборке
4. Выводы
Исследование вычислительных характеристик методов оценки редкости NFT выявило существенные различия в их временной эффективности. Наибольшее влияние на производительность оказывает архитектура алгоритмов: гибридные подходы, совмещающие анализ признаков с оптимизационными процедурами, требуют дополнительных вычислительных ресурсов по сравнению с базовыми статистическими методами.
Анализ асимптотической сложности продемонстрировал принципиальное различие между классами алгоритмов. Методы, основанные на попарном сравнении токенов, проявляют квадратичную зависимость времени выполнения от размера коллекции, тогда как подходы, использующие частотный анализ атрибутов, остаются в классе линейной сложности. Эксперименты подтвердили выраженную чувствительность топологических методов к увеличению числа уникальных признаков, в отличие от статистических подходов, демонстрирующих более стабильное поведение.
Практические рекомендации по выбору методов формулируются в терминах масштабируемости: для задач, требующих оперативной обработки, предпочтительны алгоритмы с линейной зависимостью от размера данных, тогда как ресурсоёмкие методы целесообразно применять в сценариях, допускающих фоновые вычисления. Специализированные подходы, основанные на матричных операциях, требуют особых условий развертывания.
Перспективы развития связаны с оптимизацией временных характеристик методов за счёт архитектурных улучшений. Ключевыми направлениями представляются адаптация алгоритмов под векторные и распределённые вычисления и модификация процедур предварительной обработки данных для снижения вычислительной нагрузки.
