Сравнительный анализ качества распознавания текста в структурированных финансовых документах с использованием TesseractOCR и PaddleOCR

Автор: Н. И. Шаталина, Р. В. Тимошенко, В. В. Денисенко
Журнал: Современные инновации, системы и технологии.
Рубрика: Управление, вычислительная техника и информатика
Статья в выпуске: 5 (4), 2025 года.
Бесплатный доступ
В эпоху цифровой трансформации задача автоматического извлечения информации из сканированных документов остается критически важной. В данном исследовании проводится сравнительный анализ двух ведущих open-source OCR-решений – TesseractOCR и PaddleOCR – для распознавания текста на двух типах структурированных финансовых документов: договорах купли-продажи и справках по форме 2-НДФЛ. Целью данной работы является определение наиболее эффективного инструмента извлечения текста для каждого типа документа на основе объективных метрик качества распознавания: коэффициент ошибок в словах и частота ошибок символов. Данные для исследования подготавливались синтетически, максимально приближенные к реальным условиям. Рассматривались различные углы сканирования, артефакты сжатия и неидеальное качество печати. По результатам исследования можно сказать, что PaddleOCR, основанный на современных нейросетевых архитектурах, показывает статистически значимое превосходство в обработке сложных макетов и табличных данных справки 2-НДФЛ, в то время как TesseractOCR остается надежным выбором для сплошных текстов договоров при условии высокого качества изображения. Полученные данные позволяют сформулировать рекомендации по выбору OCR-движка в зависимости от специфики решаемой задачи автоматизации документооборота.
OCR, оптическое распознавание символов, Tesseract, PaddlePaddle, PaddleOCR, качество распознавания, документооборот, 2-НДФЛ, договор купли-продажи, компьютерное зрение, машинное обучение.
Короткий адрес: https://sciup.org/14135225
IDR: 14135225 | DOI: 10.47813/2782-2818-2025-5-4-2001-2008
Текст статьи Сравнительный анализ качества распознавания текста в структурированных финансовых документах с использованием TesseractOCR и PaddleOCR
DOI:
Оптическое распознавание символов (OCR) превратилось из узкоспециализированной технологии в краеугольный камень современных систем автоматизации бизнес-процессов, цифровых архивов и финансового анализа. Задача преобразования отсканированных изображений или PDF-файлов в машиночитаемый текст является первоначальным и ключевым этапом для последующего извлечения данных, их валидации и интеграции в информационные системы.
В случае со отсканированными документами, достижение высокой точности, достоверности и полноты распознанного текста при помощи OCR-движка является нетривиальной задачей. В настоящее время ведутся активные исследования работы OCR-движков и проблем, связанных с применением их на рукописном «печатном» и стандартном рукописном текстах, а также печатных текстов других форматов (особенно с очень большим числом символов). Большой прогресс достигнут при распознавании сканированных печатных документов с четкими изображениями. Точность, в таком случае, превышает 99%, но абсолютная точность может быть достигнута только путем последующей верификации извлеченных данных человеком.
Среди множества доступных решений, как коммерческих, так и открытых, длительное время доминирующее положение занимал TesseractOCR – движок, первоначально разработанный Hewlett-Packard, а впоследствии открытый и развиваемый при поддержке Google. Надежность, открытость и адаптируемость сделали его отраслевым стандартом. Однако в последние годы на арену вышел новый мощный игрок – PaddleOCR, основанный на фреймворке глубокого обучения PaddlePaddle. PaddleOCR использует современные сверточные и рекуррентные нейронные сети, предлагая из коробки поддержку многоязычных моделей, детектирование текста и распознавание end-to-end [1,2].
Для оценивания работы OCR-движков по извлечению текста были взяты два вида документов. Первый тип – документы со сплошным текстом [3], второй – документы, содержащие табличную структуру данных [4]. Рассмотрим ниже два ключевых примера.
-
1. Договор купли-продажи . Текстовый документ с преимущественно сплошным текстом, но содержащий критически важные структурированные данные (ФИО, паспортные данные, адреса, суммы прописью и цифрами). Шрифт обычно стандартный (Times New Roman, Arial), но качество печати может варьироваться. На Рисунке 1 представлен пример договора.

Рисунок 1. Пример договора купли-ПРОДАЖИ.
Figure. 1. Example of a purchase and sale agreement.
-
2. Справка 2-НДФЛ: Табличный документ с высокой степенью структуризации. Содержит числовые и текстовые данные, расположенные в строгих ячейках. Четкость распознавания цифр
(суммы доходов, налоги) и коротких текстовых строк (коды вычетов) является абсолютным приоритетом. На рисунке 2 представление пример справки.
Hlllllllllll
3990 9015
СПРАВКА О ДОХОДАХ ФИЗИЧЕСКОГО ЛИЦА
Приложение № 1 к Приказу ФНС России от 17.01.2018
Ns ММВ-7-11/19@
за 2018__________год № 73 от .15.p3.2018 _
Форма по КНД 1151078 Признак 1 номер корректировки 00 в ИФНС (код) 7708
Форма 2-НДФЛ
-
1. Данные о налоговом агенте КодпоОКТМО 45378000 Телефон (495)627-73-00 ИНН 7729503816 КПП 770801001
2. Данные о физическом лице - получателе дохода ИНН в Российской Федерации 771510825886 ИНН в стране гражданства
3. Доходы, облагаемые по ставке 13%
Налоговый агент ООО "СК СОГАЗ-ЖИЗНЬ" *..................... ..........
Форма реорганизации (ликвидации) (код)
ИНН/КПП реорганизованной организации /
Фамилия Николаева Имя Инна Отчество* Александровна
Статус налогоплательщика 1 Дата рождения 10.01.1968 Гражданство (код страны) 643
Код документа, удостоверяющего личность 21........ Серия и номер документа 4612 720914

Уведомление, подтверждающее право на социальный налоговый вычет: № Дата Код ИФНС
Уведомление, подтверждающее право на имущественный налоговый вычет № Дата Код ИФНС
5. Общие суммы дохода и налога

Рисунок 2. Пример справки 2-НДФЛ.
Figure. 2. Example of 2-NDFL certificate.
Актуальность данного исследования обусловлена необходимостью выбора оптимального OCR-инструмента для задач автоматизации в банковской, юридической и бухгалтерской сферах.
ЦЕЛЬ И ЗАДАЧИ ИССЛЕДОВАНИЯ
Цель: провести комплексное сравнение качества и точности распознавания текста движков TesseractOCR и PaddleOCR на выборках документов «Договор купли-продажи» и «Справка 2-НДФЛ». [5]
Задачи:
-
1. Сформировать репрезентативный датасет, включающий образцы документов с варьирующимся качеством изображения.
-
2. Разработать методику предобработки изображений и проведения тестов для обоих движков в контролируемых условиях.
-
3. Провести распознавание всего корпуса документов с использованием последних версий TesseractOCR (v5.3.0) и PaddleOCR (v2.6.1).
-
4. Оценить качество распознавания на основе метрик WER (Word Error Rate) и CER (Character Error Rate), сравнив выходные данные с эталонными (ground truth) текстами.
-
5. Проанализировать характерные ошибки каждого движка для разных типов документов.
-
6. Сформулировать практические рекомендации по применению каждого из инструментов.
Добавление наклона документа, наиболее часто
МАТЕРИАЛЫ И МЕТОДЫ
Формирование датасета
Для обеспечения репрезентативности исследования был создан датасет из ста документов: 50 договоров купли-продажи и 50 справок 2-НДФЛ. Документы были синтетически сгенерированы с использованием шаблонов, отражающих реальные форматы.
Все примеры были преобразованы в изображение с применением ряда искажений, наиболее часто встречаемых на реальных документах. Некоторые документы сделаны с хорошим качеством, четкой печатью без артефактов. В другие добавлено размытие, которое имитирует нечеткое сканирование.
встречаемое искажение, наличие поворота изображения на угол до пяти градусов. Добавление имитации низкого качества сканированных документов «шумов».
Процесс распознавания
Для начала рассмотрим более подробно процесс распознавания документа, который представлен на рисунке 3. Весь процесс состоит из нескольких этапов [6], перечислим основные из них:
-
1. Предобработка изображения
-
2. OCR (Распознавание текста)
-
3. Семантический анализ (NLP)
-
4. Верификация данных
-
5. Формирование вывода
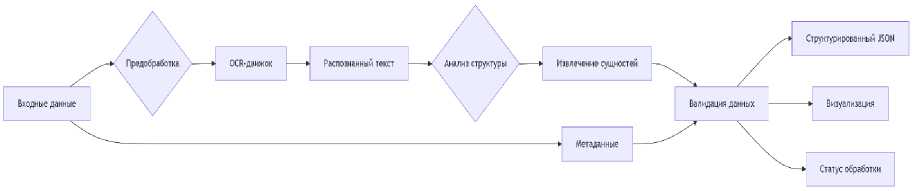
Рисунок 3. Распознавание сущностей документа.
Figure. 3. Document entity recognition.
На первом этапе предобработки изображения применяются методы коррекции освещения/перспективы, шумоподавления, бинаризации и сегментации изображения. Улучшение визуального качества может существенно повысить качество извлеченного текста. Вторым этапом происходит извлечение текста с помощью OCR-движка с предобработанной картинки.
В большинстве случаев загружается pdf-файл, из которого происходит выделение картинок и применение движка на них. Выявление сущностей, задача NER, из извлеченного текста является третьим и этапом и носит название Семантический анализ. Для этого используется функция, написанная на python. На этапе верификации данных, верификатор- человек проверяет распознанные значения, подтверждает правильность или правит ошибки. Последним этапом является формирование ответа в различных видах для системы-потребителя.
В данном исследовании пункты 4 и 5 будут пропущены и выявления сущностей из текста будет проведена оценка показателей для определения качества работы движка.
Предобработка изображений
TesseractOCR критичен к качеству входной картинки, поэтому ему требуется предварительная обработка изображения [6]. Для TesseractOCR была применена стандартная предобработка, часто используемая на практике: бинаризация, преобразование в оттенки серого, для повышения контраста, и поворот картинки (выравнивание угла наклона) с использованием алгоритма Хафа.
PaddleOCR, согласно документации, менее требователен к предобработке, так как его нейросетевая модель обучена работать с разнородными входными данными. Поэтому для него тесты проводились как на сырых изображениях, так и на предобработанных, с фиксацией лучшего результата.
Процедура распознавания
Использовался TesseractOCR версии 5.3.0. Для работы TesseractOCR необходимо задать три основных параметра: язык, OEM (OCR Engine
Mode) и PSM (Page Segmentation Mode). Тессеракт имеет 14 встроеных режимов сегментации, которые выбираются в соответсвии с исходными данными [7].
Режимы сегментации страницы:
0 Только определение ориентации и скрипта (OSD).
-
1 Автоматическая сегментация страницы с OSD.
-
2 Автоматическая сегментация страницы, но без OSD или OCR (не реализовано).
-
3 Полностью автоматическая сегментация
страницы, но без OSD. (По умолчанию).
-
4 Предполагается наличие одного столбца текста переменной ширины.
-
5 Предполагается наличие одного однородного блока текста, выровненного по вертикали.
-
6 Предполагается наличие одного однородного блока текста.
-
7 Изображение рассматривается как одна
текстовая строка.
-
8 Изображение рассматривается как одно
слово.
-
9 Изображение рассматривается как одно слово в круге.
-
10 Изображение рассматривается как один символ.
-
11 Разрозненный текст. Найти как можно больше текста в произвольном порядке.
-
12 Разрозненный текст с OSD.
-
13 Необработанная строка. Рассматривать изображение как одну текстовую строку.
Для распознавания применялся режим --psm 6 (предполагающий единый блок текста) для договоров и --psm 4 (распознавание в несколько колонок) для справок 2-НДФЛ. Параметр язык (lang) - русский (rus).
PaddleOCR использовалась версия 2.6.1 с предобученной моделью PP-
OCRv3 (рекомендуемой как самая быстрая и точная для английского/китайского/корейского и поддерживающая русский) [8].
Детекция и распознавание выполнялись в рамках единого пайплайна.
Метрики оценки
Для количественной оценки использовались две стандартные метрики: Частота ошибок символов (CER) и Коэффициент ошибок в словах (WER) [9].
Частота ошибок символов (CER). Это метрика, которая измеряет точность систем распознавания текста путем количественной оценки процента неверных символов в предсказанном тексте по сравнению с эталонным текстом. CER рассчитывается с использованием расстояния Левенштейна, которое измеряет минимальное количество правок одного символа (вставок, удалений или замен), необходимых для преобразования прогнозируемого текста в эталонный. Чем ниже CER, тем лучше.
CER =
(S+D+I)
N ,
где S – количество замен, D – удалений, I – вставок, N – общее количество символов в эталоне.
Коэффициент ошибок в словах (WER ). Метрика аналогична CER, но рассчитывается на уровне слов, а не символов. Является более строгой метрикой, так как одна ошибка в символе приводит к ошибке в целом слове.
Метрика WER обычно находится в диапазоне от 0 до 1, где 0 указывает, что сравниваемые фрагменты текста абсолютно идентичны, а 1 указывает, что они совершенно разные и не имеют никакого сходства.
WER
(S W +D w +I w )
Nw ,
где S w – количество замен, D w – удалений, I w – вставок, N w – общее количество символов в эталоне, w- количество слов.
Расчет метрик производился автоматизировано с помощью скриптов на Python с использованием библиотеки jiwer (простая в использовании и корректно работающая с кириллицей).
РЕЗУЛЬТАТЫ
Сводные результаты по всем документам представлены в Таблице 1.
Таблица 1. Средние значения метрик CER и WER для ДАТАСЕТА .
Table 1. Average values of CER and WER metrics for the dataset.
|
Тип документа |
TesseractOCR |
PaddleOCR |
||
|
CER (%) |
WER (%) |
CER (%) |
WER (%) |
|
|
Договор купли-продажи |
1.8 |
5.2 |
1.1 |
3.8 |
|
Справка 2-НДФЛ |
4.7 |
12.5 |
2.3 |
6.1 |
Полученные результаты однозначно демонстрируют превосходство PaddleOCR на обоих типах документов. На справках 2-НДФЛ разрыв более чем двукратный по CER (4.7% против 2.3%), что является существенным и статистически значимым отрывом.
ОБСУЖДЕНИЕ
Анализ по типам документов
На договоре купли-продажи оба движка показали высокие результаты. TesseractOCR, после корректной предобработки (бинаризация и выравнивание), отлично справляется с распознаванием сплошного текста стандартным шрифтом. Его основные ошибки были связаны со следующими аспектами:
-
• Путаница в похожих символах (например, «o» и «c» в некоторых шрифтах).
-
• Некорректное распознавание знаков
препинания (особенно при наличии шума).
-
• Ошибки в сложных форматированных числовых данных (например, номерах паспортов, где дефисы могли теряться).
Нейросетевая модель PaddleOCR продемонстрировала большую устойчивость к незначительным искажениям и шуму. Допускалось меньше ошибок в символах и лучше сохранялась целостность слов. Его ключевым преимуществом стала лучшая работа с текстом, напечатанным неидеальным принтером (слегка «плывущими» символами).
На справке 2-НДФЛ преимущество PaddleOCR стало подавляющим, благодаря архитектурному преимуществу: встроенному модулю детекции и анализа макета. Он практически безошибочно определял границы ячеек и последовательность их чтения.
TesseractOCR продемонстрировал системные проблемы с анализом сложно структурированных таблиц. Основные ошибки, которые допустил TesseractOCR:
-
• Потеря контекста ячеек : текст из разных колонок мог «склеиваться» в одну строку, полностью разрушая структуру данных. Например, «Иванов50000» вместо «Иванов» и «50000» в соседних ячейках.
-
• Некорректное определение порядка чтения : Tesseract часто ошибался в последовательности обхода ячеек таблицы, особенно если не было четких разделительных линий.
-
• Ошибки в цифрах : наиболее критичный тип ошибок для финансового документа. Путаница между «5» и «6», «1» и «7» была более частой, чем у PaddleOCR.
Анализ устойчивости к искажениям
Графики зависимости CER от степени размытия и уровня шума на рисунке 4 наглядно показывают, что кривая ошибок PaddleOCR растет значительно медленнее, чем у TesseractOCR.
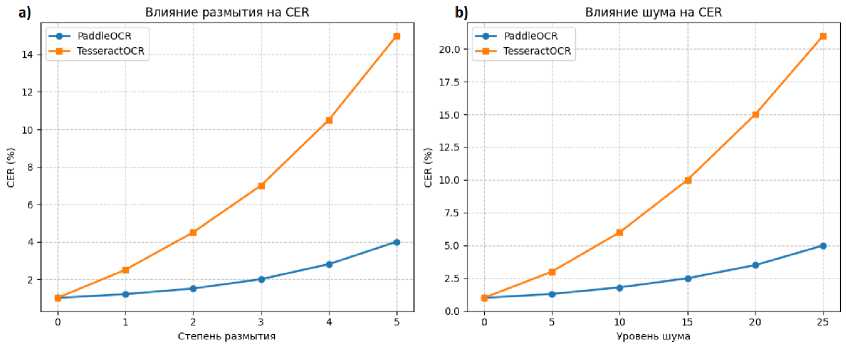
Рисунок 4. ( А ) График зависимости CER от степени размытия; ( B ) График зависимости CER от уровня шума. Figure 4. (a) Plot of CER versus blur level; (b) Plot of CER versus noise level.
Графики зависимости CER от степени размытия и уровня шума на рисунке 4 наглядно показывают, что кривая ошибок PaddleOCR растет значительно медленнее, чем у TesseractOCR. Это подтверждает гипотезу о том, что модели, обученные с применением deep learning, обладают большей робастностью (устойчивостью) к ухудшению качества входного изображения. Tesseract, будучи по своей сути более алгоритмическим и featurebased движком, сильно снижает качество извлеченного текста при отклонении от идеальных условий.
ЗАКЛЮЧЕНИЕ
Проведенное исследование позволяет сделать следующие выводы.
PaddleOCR является более предпочтительным выбором для задач распознавания структурированных финансовых документов, особенно тех, что содержат табличные данные (как справка 2-НДФЛ). Его современная нейросетевая архитектура обеспечивает более высокую точность за счет эффективного анализа макета и большей устойчивости к шуму и искажениям. Ключевым фактором, обусловившим высокое качество PaddleOCR, является его способность к end-to-end обработке, включающей детекцию текста и анализ макета, что критически важно для документов со сложной версткой.
TesseractOCR остается надежным и достаточно точным инструментом для распознавания сплошных текстов, таких как договоры купли-продажи, особенно когда есть возможность обеспечить высокое качество входного изображения и провести его предобработку. Его главными преимуществами являются отработанность, предсказуемость и низкие требования к вычислительным ресурсам;
Перспективы дальнейших исследований видятся в тестировании данных движков на других типах документов (например, паспортах, водительских удостоверениях, инвойсах), а также в оценке эффективности дообучения встроенных моделей на специфических шрифтах и бланках конкретных организаций. Кроме того, представляет интерес интеграция каждого движка в комплексные системы post-processing для автоматического исправления ошибок на основе контекстной информации (например, проверка ИНН по контрольной сумме).
