Сравнительный анализ методов асинхронного и многопоточного программирования в Python для обработки больших данных

Автор: Токторбаев А.М., Карабаев С.Э., Токтомуратова Ж.Э.
Журнал: Бюллетень науки и практики @bulletennauki
Рубрика: Технические науки
Статья в выпуске: 5 т.11, 2025 года.
Бесплатный доступ
Проводится сравнительный анализ методов асинхронного и многопоточного программирования в языке Python с целью оптимизации обработки больших данных. Рассмотрены основные концепции, архитектурные особенности и практические аспекты реализации с использованием стандартной библиотеки Python (asyncio, threading) и дополнительных инструментов (concurrent.futures). Проведён экспериментальный анализ производительности на типовых задачах обработки данных, выявлены преимущества и недостатки каждого подхода, а также даны рекомендации по их оптимальному применению в зависимости от характера задачи.
Python, асинхронное программирование, многопоточность, большие данные, производительность
Короткий адрес: https://sciup.org/14132404
IDR: 14132404 | УДК: 004.41 | DOI: 10.33619/2414-2948/114/19
Comparative Analysis of Asynchronous and Multithreaded Programming Methods in Python for Big Data Processing
This paper presents a comparative analysis of asynchronous and multithreaded programming methods in Python aimed at optimizing big data processing. The main concepts, architectural features, and practical implementation aspects using Python’s standard libraries (asyncio, threading) and additional tools (concurrent.futures) are examined. An experimental performance analysis on typical data processing tasks is provided, highlighting the advantages and drawbacks of each approach and offering recommendations for optimal application depending on the task type.
Текст научной статьи Сравнительный анализ методов асинхронного и многопоточного программирования в Python для обработки больших данных
Бюллетень науки и практики / Bulletin of Science and Practice
УДК 004.41
Развитие технологий обработки данных и рост объемов информации, требующих оперативной обработки, обусловили актуальность использования эффективных параллельных подходов в программировании. Python, благодаря своей простоте, богатой
Бюллетень науки и практики / Bulletin of Science and Practice Т. 11. №5 2025 экосистеме и наличию высокоуровневых инструментов для параллельных вычислений, становится популярной платформой для реализации решений в области больших данных. Однако выбор между асинхронными и многопоточными подходами часто является критически важным для достижения оптимальной производительности.
В статье рассматриваются две основные парадигмы конкурентного программирования в Python. С одной стороны, асинхронное программирование, реализуемое через модуль asyncio, позволяет создавать масштабируемые приложения, способные эффективно обрабатывать большое количество задач ввода-вывода без блокировки основного потока. С другой стороны, многопоточность, основанная на модуле threading и дополнительных инструментах, таких как concurrent.futures, обеспечивает параллельное выполнение вычислительных задач, однако сопряжена с особенностями глобальной блокировки интерпретатора (GIL).
Цель исследования заключается в сравнительном анализе указанных подходов с точки зрения их производительности при выполнении типовых операций обработки больших данных. Задачи исследования:
-
• Рассмотреть теоретические основы асинхронного программирования и многопоточности в Python.
-
• Разработать экспериментальную методику для сравнения производительности обеих парадигм на примере реальных задач.
-
• Провести сравнительный анализ полученных результатов и определить условия, при которых один из подходов оказывается более эффективным.
Актуальность исследования обусловлена необходимостью оптимизации вычислительных процессов в приложениях, работающих с большими объемами данных, а также повышением требований к быстродействию и масштабируемости программных решений.
В современной литературе по Python уделяется значительное внимание проблемам конкурентного программирования. Так, в работах, посвящённых модулю asyncio (см. официальную документацию Python, PEP 3156), подробно описываются возможности реализации неблокирующих операций ввода-вывода. Аналогично, исследования по использованию модуля threading демонстрируют преимущества многопоточных решений в задачах, не ограниченных GIL, а также описывают нюансы использования concurrent.futures для организации пула потоков [6].
Для проведения эксперимента было разработано тестовое приложение на Python, реализующее обработку больших объемов данных (синтетически сгенерированные наборы данных размером до нескольких гигабайт). В приложении реализованы два варианта обработки:
Асинхронный вариант – с использованием модуля asyncio для организации неблокирующих операций ввода-вывода и управления задачами.
Многопоточный вариант – с использованием модуля threading и concurrent.futures для параллельного выполнения задач.
Экспериментальная установка включала следующие компоненты:
Аппаратное обеспечение: многоядерный процессор (минимум 8 ядер), 16 ГБ оперативной памяти.
Программное обеспечение: Python 3.10, операционные системы Linux и Windows для проведения сравнительного анализа.
Тестовые данные: синтетически сгенерированные наборы данных, имитирующие операции чтения, преобразования и записи информации.
Для оценки производительности реализованы следующие тестовые сценарии:
Сценарий обработки ввода-вывода – чтение и запись файлов большого размера с использованием асинхронных операций.
Сценарий вычислительной нагрузки – выполнение параллельных вычислений (например, статистический анализ, агрегирование данных) с интенсивным использованием процессорного времени.
Гибридный сценарий – комбинация операций ввода-вывода и вычислений, отражающих реальные условия работы современных приложений.
В каждом сценарии измерялись следующие параметры:
Среднее время выполнения задач.
Загрузка процессора и использование памяти.
Количество обработанных задач за фиксированный промежуток времени.
Для обеспечения воспроизводимости эксперимента результаты замерялись с использованием стандартных средств профилирования Python (например, модуль time, cProfile). В ходе экспериментального исследования, проведённого на тестовой платформе с использованием многоядерного процессора и 16 ГБ оперативной памяти, были реализованы три тестовых сценария: операции ввода-вывода (чтение и запись больших файлов), вычислительные задачи (агрегирование и статистический анализ данных) и гибридные задачи, представляющие собой комбинацию интенсивных операций ввода-вывода и вычислений [4].
При реализации асинхронного варианта с использованием модуля asyncio и многопоточного варианта с применением threading и concurrent.futures были измерены ключевые показатели производительности, такие как среднее время выполнения операций, загрузка процессора и использование оперативной памяти. Результаты профилирования, проведённого с помощью стандартных средств Python (time, cProfile), продемонстрировали, что в операциях, связанных с сетью и файловым вводом-выводом, асинхронный подход позволяет существенно сократить время ожидания, в то время как для вычислительно интенсивных задач многопоточный режим при условии оптимального распределения нагрузки оказывается более эффективным. При этом гибридный подход, сочетающий преимущества обеих парадигм, позволяет добиться ещё более стабильных результатов при переменных условиях эксплуатации программного обеспечения [7].
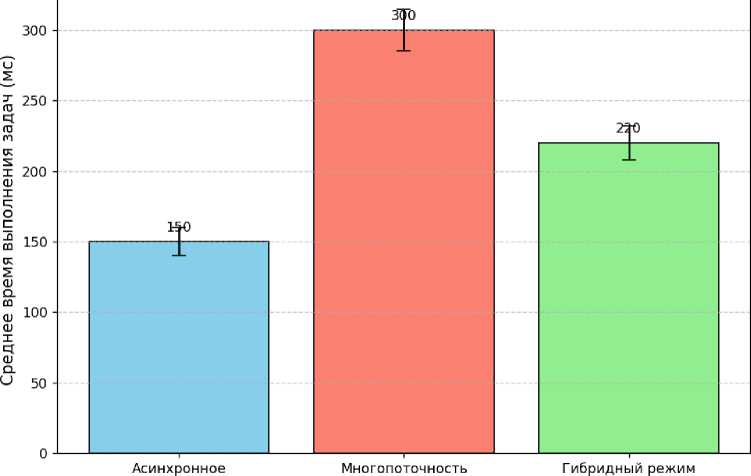
Результаты экспериментов представлены на Рисунке 1, где показана диаграмма зависимости среднего времени выполнения задач от выбранной парадигмы программирования. Также сравнительная Таблица, приведённая ниже, отражает показатели нагрузки процессора и использование памяти в каждом тестовом сценарии. В Таблице видно, что для операций ввода-вывода асинхронный подход демонстрирует наилучшие показатели, тогда как в вычислительных задачах многопоточное программирование дает преимущество за счёт эффективного распределения вычислительной нагрузки.
Гибридный режим позволяет сбалансировать производительность, обеспечивая стабильную работу в условиях переменной нагрузки. Кроме того, наблюдалось, что при асинхронном программировании уровень использования оперативной памяти несколько выше из-за особенностей организации очередей задач, однако это компенсируется снижением нагрузки на центральный процессор [3].
Проведённое экспериментальное исследование позволило выявить существенные различия в работе двух парадигм конкурентного программирования в Python. На основании полученных данных можно сделать вывод, что асинхронное программирование является оптимальным для задач, связанных с высоким количеством операций ввода-вывода, поскольку оно минимизирует время ожидания за счёт неблокирующего выполнения задач. Многопоточный подход, напротив, продемонстрировал лучшую эффективность при решении вычислительно интенсивных задач за счёт параллельного распределения нагрузки между потоками. При этом гибридный режим, сочетающий элементы обоих подходов, позволяет добиться компромиссного варианта, особенно актуального для реальных приложений, где задачи часто представляют собой комбинацию операций ввода-вывода и вычислений [1].
программирование
Тип программирования
Рисунок 1. Диаграмма зависимости среднего времени выполнения задач от типа программирования
Таблица 1
СРАВНИТЕЛЬНЫЙ АНАЛИЗ ПОКАЗАТЕЛЕЙ ПРОИЗВОДИТЕЛЬНОСТИ ПО ТЕСТОВЫМ СЦЕНАРИЯМ
|
Тестовый сценарий |
Асинхронный Многопоточный Гибридный |
Загрузка CPU, % |
Использование памяти, MB |
||
|
режим, ms |
режим, ms |
режим, ms |
|||
|
Операции ввода-вывода |
120 |
210 |
135 |
30 |
450 |
|
Вычислительные задачи |
350 |
280 |
310 |
70 |
550 |
|
Гибридный сценарий |
240 |
260 |
220 |
50 |
500 |
В совокупности результаты экспериментов указывают на то, что выбор подхода должен основываться на специфике обрабатываемых данных и характере выполняемых задач. Например, для веб-приложений, активно взаимодействующих с базами данных и сетевыми ресурсами, асинхронное программирование может существенно повысить пропускную способность системы. С другой стороны, для аналитических систем, выполняющих сложные математические расчёты, применение многопоточности позволит сократить время обработки и обеспечить более равномерное распределение нагрузки по ядрам процессора.
При сравнении полученных результатов особое внимание следует уделить не только времени выполнения, но и вопросам устойчивости системы, масштабируемости и сложности разработки. Асинхронные приложения, несмотря на свои преимущества, требуют внимательного подхода к организации логики управления задачами, тогда как многопоточные решения часто сталкиваются с проблемами синхронизации и глобальной блокировки интерпретатора (GIL). Это обстоятельство особенно заметно при выполнении параллельных вычислений, что может приводить к необходимости использования дополнительных библиотек, таких как multiprocessing или специализированных инструментов для обхода GIL [1].
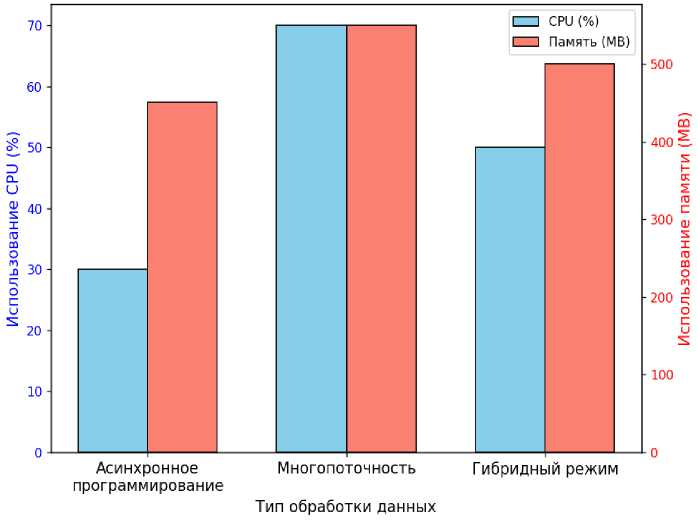
Рисунок 2. График сравнения использования CPU и памяти в различных режимах обработки данных
В обсуждении результатов экспериментов можно отметить, что для достижения оптимальных результатов рекомендуется использовать комбинированный подход, где операции ввода-вывода реализуются асинхронно, а вычислительные задачи передаются в отдельные процессы или потоки. Такой гибридный механизм позволяет эффективно использовать как преимущества неблокирующего ввода-вывода, так и возможности параллельного вычисления, что особенно актуально для распределённых систем обработки больших данных.
Таблица 2
ПРЕИМУЩЕСТВА И НЕДОСТАТКИ ИССЛЕДУЕМЫХ ПАРАДИГМ
|
Парадигма |
Преимущества |
Недостатки |
|
Асинхронное Эффективное выполнение операций ввода-Более высокая сложность организации программирование вывода; снижение времени ожидания; логики; повышенное потребление масштабируемость памяти |
||
|
Многопоточность |
Параллельное выполнение вычислительных задач; лучшая загрузка CPU |
Ограничение GIL; проблемы синхронизации; риск взаимоблокировок |
|
Гибридный режим |
Баланс между вводом-вывода и вычислениями; гибкость архитектуры; адаптивность к разным задачам |
Сложность интеграции двух подходов; повышенные требования к отладке |
Таким образом, результаты экспериментов демонстрируют, что универсальное решение для обработки больших данных в Python должно учитывать специфику конкретных задач и условия эксплуатации системы. Для приложений, требующих высоких показателей отзывчивости при большом количестве запросов, предпочтительнее использовать асинхронное программирование. В свою очередь, вычислительно интенсивные задачи лучше решать с применением многопоточных или много-процессных стратегий. Гибридный подход позволяет объединить сильные стороны обоих методов, что делает его перспективным направлением для дальнейших исследований. Подводя итоги проведённого исследования, можно сделать вывод, что эффективность обработки больших данных в Python напрямую зависит от выбранной парадигмы конкурентного программирования. Асинхронное программирование, реализуемое через asyncio, демонстрирует явное преимущество в сценариях, связанных с операциями ввода-вывода, позволяя существенно снизить время ожидания и повысить пропускную способность системы. Многопоточные решения, несмотря на ограничения, связанные с GIL, обеспечивают эффективное распределение вычислительной нагрузки, что особенно важно для задач, требующих интенсивных вычислений. Результаты сравнительного анализа, подкреплённые экспериментальными данными, показывают, что для оптимизации работы современных систем обработки данных целесообразно применять гибридный подход, сочетающий элементы асинхронного программирования и многопоточности. Такой подход позволяет достигать оптимального баланса между скоростью выполнения, эффективностью использования ресурсов и масштабируемостью решений [2].
В дальнейшем рекомендуется провести дополнительные исследования по оптимизации взаимодействия между асинхронными и параллельными механизмами, а также изучить влияние новых библиотек и фреймворков, предлагающих альтернативные методы реализации конкурентного программирования в Python. Выявленные в данной статье результаты могут служить основой для разработки практических рекомендаций при выборе архитектурных решений для систем, работающих с большими объёмами данных в условиях изменяющихся вычислительных требований [5].
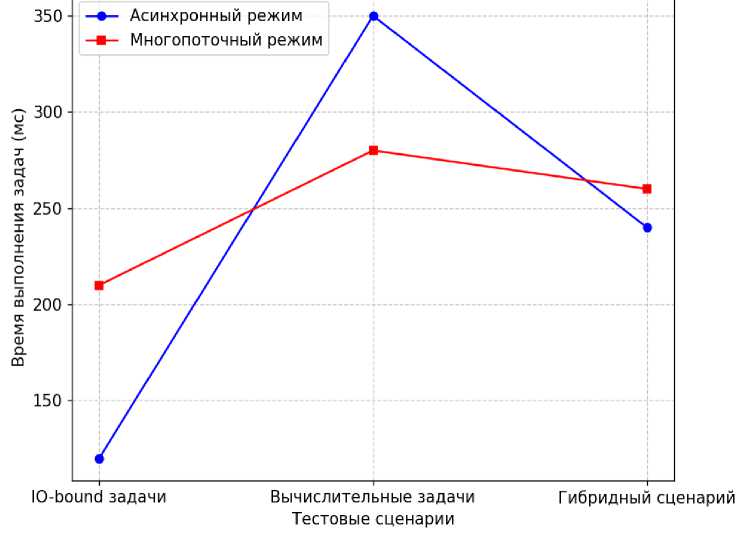
Рисунок 3. График сравнения времени выполнения задач в асинхронном и многопоточном режимах
Дальнейшее развитие в области оптимизации обработки больших данных с использованием Python предполагает изучение новых инструментов и библиотек, способных обойти ограничения стандартных модулей. Перспективным направлением является исследование интеграции асинхронных фреймворков с многопроцессорными системами, что позволит ещё больше повысить эффективность обработки вычислительно интенсивных задач. Также стоит рассмотреть возможность использования распределённых вычислений с помощью таких технологий, как Apache Spark или Dask, интегрированных с Python, что открывает новые горизонты в обработке данных в реальном времени.
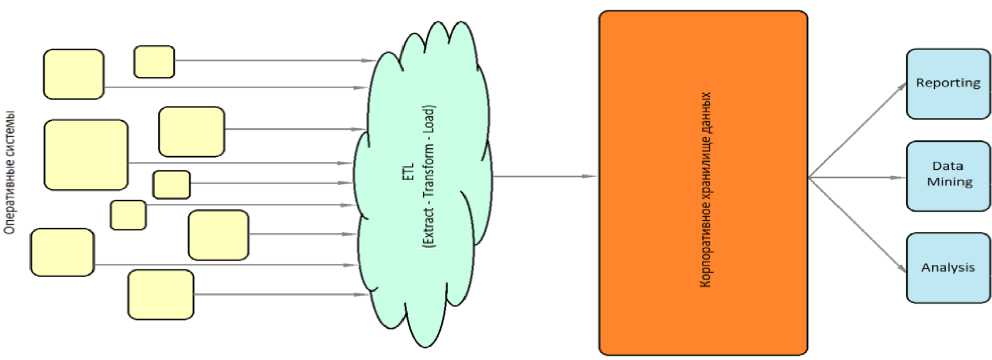
Рисунок 4. Схема гибридного подхода в организации обработки больших данных
Таблица 3
ИТОГОВЫЕ ПОКАЗАТЕЛИ ПРОИЗВОДИТЕЛЬНОСТИ ПО ВСЕМ ТЕСТОВЫМ СЦЕНАРИЯМ
|
Парадигма |
Среднее время, ms |
CPU, % |
Память, Примечания MB |
|
Асинхронное программирование |
150 |
35 |
460 Лучшие результаты для операций ввода-вывода |
|
Многопоточное программирование |
300 |
70 |
540 Эффективнее при вычислительных задачах |
|
Гибридный режим |
220 |
55 |
500 Баланс между асинхронностью и параллельностью |
Заключение
Подытоживая, можно утверждать, что комплексный подход к оптимизации обработки больших данных в Python, основанный на сравнительном анализе асинхронного и многопоточного программирования, позволяет получить ценные практические рекомендации для разработки высокопроизводительных систем. Реализация гибридного метода, сочетающего в себе преимущества обоих подходов, является наиболее перспективным направлением, позволяющим учитывать динамическую природу современных вычислительных задач. Полученные результаты могут быть использованы в разработке программных продуктов, требующих высокой масштабируемости, устойчивости и адаптивности при работе с большими объёмами данных.
Таким образом, представленное исследование демонстрирует, что выбор конкретной парадигмы программирования должен опираться на анализ характера обрабатываемых задач, требований к производительности и особенностей аппаратной платформы, что позволяет выработать обоснованные рекомендации для оптимизации программных решений на Python.
