Сравнительный анализ методов машинного обучения «без учителя» в задачах выявления аномалий в сетях интернета вещей

Автор: Карташевская Е.С.
Журнал: Инфокоммуникационные технологии @ikt-psuti
Рубрика: Новые информационные технологии
Статья в выпуске: 4 т.20, 2022 года.
Бесплатный доступ
Рассматриваются такие классические методы машинного обучения «без учителя», как метод к-ближайших соседей, оценка выбросов на основе гистограммы, изолирующий лес, кластерный локальный коэффициент выбросов, для выявления наиболее результативного среди них с целью определения возможности использования в качествеосновы для системы выявления аномалий в трафике Интернета вещей. В качестве данных для исследования используется открытый набор данных IoT-23 Dataset. Набор размечен и содержит 23 фактора. Также рассматривается метод обучения «без учителя» на основе копул, использование которого помогает в полной мере раскрыть зависимость между анализируемыми факторами, что может быть успешно использовано при анализе сетевого трафика на предмет выявления аномалий. В результате приводится сравнение точности использования указанных методов для выявления аномалий в сетях Интернета вещей.
Машинное обучение, интернет вещей, аномалии сетевого трафика, копулы
Короткий адрес: https://sciup.org/140302042
IDR: 140302042 | УДК: 004.056.53 | DOI: 10.18469/ikt.2022.20.4.10
Comparative analysis of methods of unsupervised machine learning for anomaly detection in the IoT systems
Classical unsupervised machine learning methods such as k-nearest neighbor method, histogram-based outlier estimation, isolating forest, cluster local outlier factor are considered in order to identify the most efficient one to be used as the basis for anomaly detection system in IoT traffic. The IoT-23 Dataset, an open-source dataset, is used as the data for the study. The dataset is dimensioned and consists of 23 factors. The study considers an unsupervised learning method «with no teacher» based on copulas, the use of which helps to fully reveal interaction between evaluated factors, which can be successfully used in network traffic analysis in order to detect anomalies. As a result, the accuracy levels of these IoT network anomaly detection methods are compared.
Текст научной статьи Сравнительный анализ методов машинного обучения «без учителя» в задачах выявления аномалий в сетях интернета вещей
Обнаружение сетевых вторжений является динамичной областью исследований, поскольку злоумышленники участили атаки на все виды сетевых устройств. Системой обнаружения вторжений по факту является устройство или программное приложение, которое отслеживает различные действия в сети и анализирует их на наличие вредоносных действий или угроз безопасности и сигнализирует о таких действиях сетевому администратору, либо принимает решение самостоятельно. В зависимости от метода развертывания такие системы можно разделить на системы на основе хоста (Host–based intrusion detection system, HIDS) и системы на основе сети (network intrusion detection system, NIDS). HIDS работает на отдельных устройствах в сети и отслеживает входящий и исходящий трафик только на этом конкретном устройстве. NIDS размещается в узле внутри сети, откуда она может отслеживать входящий и исходящий трафик всех устройств в сети.
Аномалия или выброс – это нетипичный или странный паттерн трафика, который значительно отличается от нормального паттерна на основе анализа некоторой меры. В некоторых приложениях выбросы рассматриваются как шум и удаляются на этапе предварительной обработки, тогда как в других приложениях выбросы – это элементы, несущие важную информацию. Важно иметь возможность обнаруживать и классифицировать вредоносные потоки сетевого трафика, например, участие устройства в DDoS–атаках (Distributed denial of service), из безопасных потоков. Обычно задача выполняется с использованием контролируемых алгоритмов классификации. В этой статье анализируется использование алгоритмов обнаружения аномалий для задачи классификации сетевого трафика.
В многочисленных исследованиях анализировались стратегии обнаружения сетевых угроз с использованием алгоритмов классификации [1–3]. Хотя эти методы достигли большого успеха, они страдают от проблемы несбалансированности набора данных [4] и отсутствия обнаружения аномальных потоков, а не точечных аномалий. Например, эти методы почти не могут обнаружить новый метод угрозы, паттернов использования которого не было в наборе данных, используемых для обучения. Алгоритмы обнаружения аномалий [5] пытаются отличить точки выбросов от обычных данных трафика, следовательно, данные методы могут выполняться без обучения [6], что особенно ценно для сетей Интернета вещей. Высокая скорость работы, невысокая требовательность к ресурсам могут позволить разместить программное обеспечение в качестве HIDS, т.е. на самом устройстве IoT.
Используемые методы обучения
Рассмотрим популярные методы обучения «без учителя», используемые для обнаружения аномалий.
Метод k –ближайших соседей. Метод ближайших соседей – простейший метрический классификатор, основанный на оценивании сходства объектов. Классифицируемый объект относится к тому классу, которому принадлежат ближайшие к нему объекты выборки. Данный метод опирается на одно важное предположение, называемое гипотезой компактности: если мера сходства объектов введена достаточно удачно, то схожие объекты гораздо чаще лежат в одном классе, чем в разных. Классификация в данном методе происходит на основе большего числа ближайших соседей каждой точки [7].
Изолирующий лес. Данный алгоритм является техникой машинного обучения без учителя, основанной на принципе Монте–Карло. Термин «изоляция» означает процесс отделения рассматриваемого экземпляра от остальных экземпляров выборки. Поскольку предполагается, что аномалий мало и они разные, поэтому они более подвержены изоляции. В ходе работы алгоритма пространство признаков разделяется случайным образом. Метод отсекает изолированные точки от нормальных кластеризованных данных. Результат работы алгоритма представляет собой усредненную оценку, полученную в ходе запуска стохастического алгоритма несколько раз. Работа алгоритма заключается в построении случайного бинарного дерева, в котором корень – все пространство признаков, а узел представлен случайным признаком и порогом разбиения. Порог разбиения выбирается из равномерного распределения на отрезке от минимального до максимального значения выбранного признака. При тождественном совпадении объектов в узле работа алгоритма завершается [8].
Оценка выбросов на основе гистограммы (Histogram–based outlier score, HBOS). Этот метод предполагает независимость между переменными для построения гистограммы и оценки одномерных выбросов. N оценок одномерных выбросов наблюдения можно суммировать, чтобы получить оценку выбросов на основе гистограммы (рисунок 1).
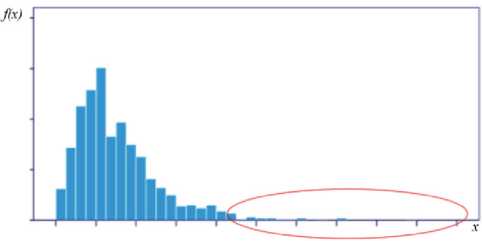
Рисунок 1. Метод HBOS
HBOS строит гистограммы независимо для всех N переменных. Высота столбца гистограммы (количество попаданий в заданный интервал) используется для измерения выбросов. Большинство наблюдений относятся к столбцам, характеризующим высокую частоту попаданий, а выбросы принадлежат столбцам низкой частоты (выделено красным на рисунке 1). Оценка одномерного выброса определяется как величина, обратная высоте ячейки.
HBOS формально определяется как:
N
HBOS (p) = £ log i=1
hist i ( p ) J ’
где histi ( p ) – это высота интервала переменной i, к которой принадлежит наблюдение p , а
– одномерная оценка выброса.
histi ( p )
Если переменная является категориальной, гистограмма представляет собой количество по категориям. Если переменная является числовой, она должна быть сначала дискретизирована в ячейки одинаковой ширины для получения статистики подсчета. Максимальная высота каждой гистограммы нормализована до значения 1,0. Это гарантирует, что все одномерные оценки могут быть суммированы одинаково для получения оценки HBOS.
Кластерный фактор локального выброса (Cluster–based local outlier factor, CBLOF). Он определяет аномалии как комбинацию локаль- ных расстояний до ближайших кластеров и размера кластеров, к которым принадлежит точка данных. Сначала он группирует точки данных в большие или маленькие кластеры. Точки данных небольшого кластера рядом с соседним большим кластером идентифицируются как выбросы. Локальные выбросы могут быть не особой точкой, а небольшой группой изолированных точек [9].
На рисунке 2 C2 и C4 – большие кластеры, а C1 и C3 – маленькие кластеры. Кластеры C1 и C3 являются выбросами, поскольку они не принадлежат двум большим кластерам C2 и C4. Визуально определяя локальное соседство, можно сказать, что данные в кластере C1 являются локальными выбросами для кластера C2, а данные в кластере C3 – локальными выбросами для кластера C4.

Рисунок 2. Метод CBLOF
Аномалии в данном случае – это любые точки данных небольшого кластера рядом с соседним более крупным кластером. Это определение отражает идею «локальных выбросов» и идею кластеров в любых методах кластеризации. CBLOF учитывает как размер кластера, к которому принадлежит точка данных, так и расстояние между точкой данных и ближайшим к ней кластером.
Метод обнаружения на основе использования копул. Предложен в [10]. Дадим для начала определение копулы. Функция C ( x , y ) называется копулой двух переменных x и y , определенных на множестве [ 0,1 ] x [ 0,1 ] , если она удовлетворяет следующим условиям:
C ( x ,0) = 0, C (0, y ) = 0;
C ( x ,1) = x , C (1, y ) = y ;
C ( x 2 , y 2 ) + C ( X i , У 1 ) - C ( x 2 , У 1 ) -
- C ( X i , y 2 ) > 0 ;
где ( X i , y 1 ) e [ 0,1 ] x [ 0,1 ] , ( x 2 , y 2 ) e [ 0,1 ] x [ 0,1 ]
и x 1 < x 2 , y 1 < y 2 ;
0 < C ( x , y ) < 1.
Для любой копулы справедливо:
max( x + y - 1,0) < C ( x , y ) < min( x , y ).
Для любых ( x 1 ,y 1 ) e [ 0,1 ] x [ 0,1 ] ,
( x 2 ,y 2 ) e [ 0,1 ] x [ 0,1 ] справедливо
|C ( x 2 , y 2 ) - C ( x 1 , y i)| < | x 2 - x 1| +| y 2 - y i .
Согласно теореме Склара [11] функция совместного (интегрального) распределения WXY ( x , y ) случайных величин X и Y определяется копулой от одномерных распределений WX ( x ) и WY ( y ) :
W xy ( x , y ) = C (W x ( x ), W y ( y )) . (1)
Копулы позволяют рассматривать зависимость между случайными величинами по выборке вне контекста одномерных распределений. Суть состоит в том, что, даже не зная одномерных функций распределения случайных величин, можно рассматривать различные зависимости между ними.
Обнаружение выбросов с помощью данного метода осуществляется в три шага. На первом шаге вычисляются эмпирические функции плотности вероятностей на основе интересующего набора данных X =[ X 1i ,...,X di] , i = 1,..., n . На втором шаге эти функции плотности вероятностей используются для создания эмпирической функции копулы (в соответствии с выбранным видом копулы). И, наконец, используется копула для аппроксимации вероятности хвостовой части распределения на основе соотношения (1).
Описание набора данных
Для анализа работы приведенных методов используем набор данных, представленный в [12]. IoT–23 Dataset – это набор данных о сетевом трафике устройств Интернета вещей (Internet of things, IoT). Впервые он был опубликован в январе 2020 года, а захваты проводились в период с 2018 по 2019 год. Сетевой трафик IoT был зафиксирован в лаборатории Stratosphere Чешского технического университета (Czech technical university, CTU). Набор данных IoT–23 состоит из двадцати трех записей (называемых сценариями) различного сетевого трафика IoT. Эти сценарии разделены на двадцать сетевых захватов (файлов *.pcap) с зараженных устройств IoT (которые имеют имя образца вредоносного программного обеспечения, выполняемого в каждом сценарии) и три сетевых захвата сетевого трафика реальных устройств IoT (с именами устройств, на которых трафик был захвачен).
Набор содержит размеченные данные об участии зараженного устройства в DDoS–атаке, в виде индикации подключений к таким ботнетам как Mirai, Okiru, Torii и др.
В данной работе использовался набор данных, ко- торый содержит 10447787 записей, которым присвоены метки «DDoS» или «Benign» (штатная работа).
Трафик «DDoS» содержит чуть больше 20% всего набора данных (2185302 элементов). Чтобы оценить точность алгоритмов обнаружения выбросов, были созданы разные наборы данных с различным содержанием пакетов, помеченных как «DDoS» в диапазоне от 0,01 до 0,99.
Сравнение точности работы алгоритмов
Теперь проанализируем работу представленных методов на сформированном наборе данных с точки зрения двух метрик. Первая – AUC (Area Under Curve, площадь под кривой) является количественной интерпретацией кривой ошибок, т.е. площадью, ограниченной кривой ошибок и осью доли ложных положительных классификаций. Вторая метрика – точность, показывающая количество правильно идентифицированных аномалий от общего количества событий, для каждого алгоритма. Анализ проведен на основе приложения, написанного на языке Python 3.8 с использованием библиотеки pyOD. Также исходные данные поделены в соотношении на две выборки – «обучающую» и «тестовую» в соотношении 0.3–0.7. Поскольку используются методы машинного обучения, не предполагающие обучения, т.е. методы «без учителя», это разделение является формальным и призвано оценить эффективность работы алгоритмов на выборках разных объемов. Результаты приведены на рисунках 3–7.
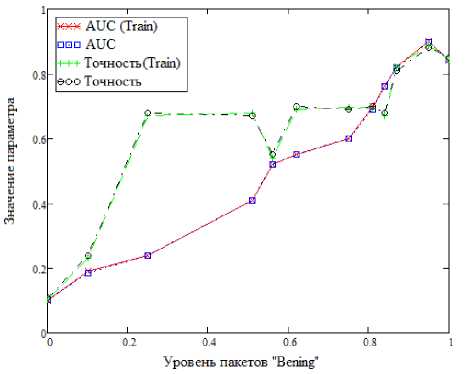
Рисунок 3. Метод CBLOF
Можно заметить, что с увеличением количества пакетов, размеченных, как «Benign», т.е. не участвующих в DDoS–атаках, увеличивается и точность для всех алгоритмов. Различные резкие выбросы, встречающиеся на рисунке 3, рисунке 4, рисунке 6 можно объяснить несбалансированностью набора данных, т.е. неравномерным распределением пакетов, размеченных как DDoS– атака. Другое важное наблюдение заключается в том, что значения метрик оценки точности алгоритмов очень схожи при сравнении между «обучающим» и «тестовым» набором. Тут причина кроется в использовании обучения «без учителя».
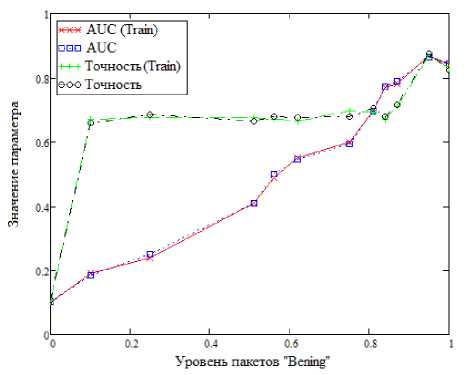
Рисунок 4. Метод HBOS
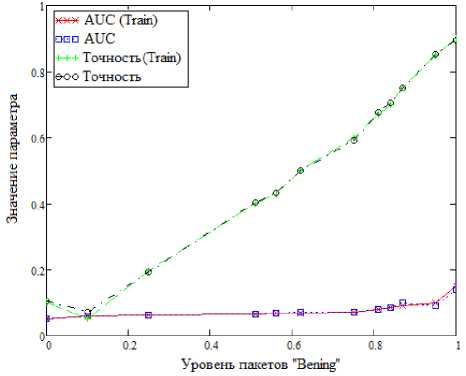
Рисунок 5. Метод k-ближайших соседей
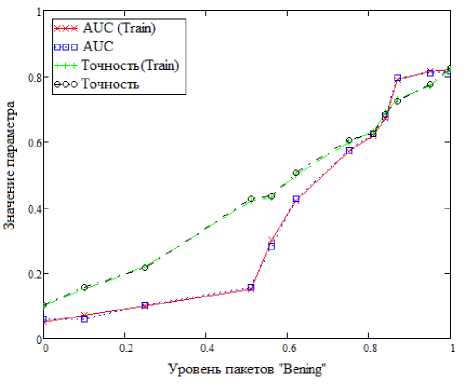
Рисунок 6. Метод изолирующего леса
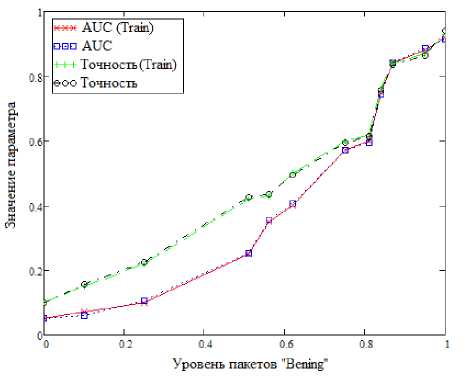
Рисунок 7. Метод на основе копул
Заключение
В качестве более точного алгоритма из рассмотренных можно рассматривать алгоритм на основе копул, как имеющий наименьшее расхождение между показателями метрик и имеющий наибольшую точность при существенном увеличении количества пакетов, характеризующих штатную работу устройства. Рассмотренные методы могут выполняться без обучения, что особенно ценно для сетей Интернета вещей.
Дальнейшая работа в данном направлении будет заключаться в получении оценки эффективности работы данных алгоритмов на устройствах IoT, не обладающих достаточной вычислительной мощностью. Предполагается, что высокая скорость работы (на исходном наборе данных, объемом 2185302 элементов, по методу на основе использования копул время выполнения составило 8.4432841 с. на процессоре AMD Athlon Gold 3150U 2.4 GHz) может позволить оптимизировать и разместить программное обеспечение в качестве HIDS, т.е. на самом устройстве IoT.
Список литературы Сравнительный анализ методов машинного обучения «без учителя» в задачах выявления аномалий в сетях интернета вещей
- Fouladi R.F., Kayatas C.E., Anarim E. Frequency based DDoS attack detection approach using naive Bayes classification // 39th International Conference on Telecommunications and Signal Processing (TSP), Vienna, Austria, 2016, pp. 104–107.
- A new multi classifier system using entropy–based features in DDoS attack detection / A. Koay [et al.] // 2018 International Conference on Information Networking (ICOIN), Chiang Mai, Thailand, 2018, pp. 162–167.
- Alsirhani A., Sampalli S., Bodorik P. DDoS Attack Detection System: Utilizing Classification Algorithms with Apache Spark // 9th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 2018, pp. 1–7.
- Krawczyk B. Learning from imbalanced data: open challenges and future directions // Progress in Artificial Intelligence. 2016. Vol.5. P.221–232.
- Aggarwal C.C. Outlier Analysis. 2nd ed. Springer International Publishing, 2017. 481 p.
- On the evaluation of unsupervised outlier detection: measures, datasets, and an empirical study / G.O. Campos [et al.] // Data Mining Knowledge and Discovery. 2016. Vol.30. P.891–927.
- Метод ближайших соседей. URL: https://github.com/ElvinaYakubova/machine–learning/blob/master/NearestNeighbors/readme.md (дата обращения: 11.12.2022).
- Ho T.K. Random Decision Forests // Proceedings of the 3rd International Conference on Document Analysis and Recognition. Montreal.1995. P. 278–282.
- He Z., Xu X., Deng S. Discovering cluster–based local outliers // Pattern Recognition Letters. 2003. Vol.24(9–10). P.1641–1650.
- Copod: Copula-Based Outlier Detection / Z. Li [et al.] // 2020 IEEE International Conference on Data Mining (ICDM). Sorrento, Italy. 2020. P. 1118–1123. DOI: 10.1109/ICDM50108.2020.00135
- Фантаццини Д. Моделирование многомерных распределений с использованием копула-функций. II / Прикладная эконометрика. 2011. №3 (23). C. 98–132.
- Garcia S., Parmisano A., Erquiaga M.J. IoT–23: A labeled dataset with malicious and benign IoT network traffic (Version 1.0.0). URL: http://doi.org/10.5281/zenodo.4743746 (дата обращения: 29.10.2022).
