Сравнительный анализ методов машинного обучения для оценки рыночной стоимости подержанных автомобилей

Автор: Чижов А.С., Миролюбова А.А., Смирнова О.П.
Журнал: Теория и практика общественного развития @teoria-practica
Рубрика: Экономика
Статья в выпуске: 4, 2026 года.
Бесплатный доступ
В статьеисследуется проблема высокоточного прогнозирования цен на вторичном рынке Индии с использованием алгоритмов машинного обучения. Авторами проведено сравнение классической линейной регрессии и ансамблевых методов: случайного леса и градиентного бустинга. Методика исследования основана на комплексном подходе машинного обучения, включая очистку и преобразование данных, логарифмирование целевой переменной, прогнозирование на базе поэтапного сравнения моделей по сложности и интерпретацию для бизнеса. Современные библиотеки Python, такие как Pandas, Numpy, Matplotlib, Seaborn, Scikit-learn Xgboost, Joblib, предоставляют широкие возможности для анализа и прогнозирования больших и разнородных данных, характерных для автомобильного рынка, а также гибкой настройки и интерактивной визуализации. В ходе работы аргументирована необходимость логарифмического преобразования целевой переменной для минимизации асимметрии данных. Результаты показали преимущество модели градиентного бустинга, обеспечивающего значение R2 = 0,94 и снижение абсолютной ошибки MAE до 1,387 лакха индийских рупий. Проведен анализ важности признаков, выявивший доминирующую роль мощности двигателя и года выпуска в ценообразовании.
Машинное обучение, градиентный бустинг, прогнозирование цены, вторичный рынок автомобилей, линейная регрессия, случайный лес
Короткий адрес: https://sciup.org/149150978
IDR: 149150978 | УДК: 004.021:330.133.2 | DOI: 10.24158/tipor.2026.4.20
A Comparative Analysis of Machine Learning Methods for Estimating the Market Value of Used Cars
This article examines the problem of high-precision price forecasting in the Indian secondary market using machine learning algorithms. The authors compare classical linear regression with ensemble methods: random forest and gradient boosting. The research methodology is based on a comprehensive machine learning approach, including data cleaning and transformation, logarithmization of the target variable, forecasting based on step-by-step comparison of models by complexity, and business interpretation. Modern Python libraries such as Pandas, Numpy, Matplotlib, Seaborn, Scikit-learn, XGBoost, Joblib provide extensive capabilities for analyzing and forecasting large and heterogeneous data typical of the automotive market, as well as flexible customization and interactive visualization. The study argued for the need for a logarithmic transformation of the target variable to minimize data skewness. The results demonstrated the advantage of the gradient boosting model, yielding an R2 value of 0,94 and reducing the MAE absolute error to INR 1,387 lakh. A feature importance analysis was conducted, revealing the dominant role of engine power and year of manufacture in pricing.
Текст научной статьи Сравнительный анализ методов машинного обучения для оценки рыночной стоимости подержанных автомобилей
Прогнозирование рыночной стоимости активов является фундаментальной задачей в финансовой эконометрике и бизнес-аналитике. В контексте вторичного рынка автомобилей эта задача приобретает особую актуальность, поскольку ценообразование находится под влиянием множества факторов, включая техническое состояние, маркетинговые усилия и субъективные оценки. Вследствие этого актуальность исследования обусловлена необходимостью создания объективного и высокоточного инструмента для автоматизированной оценки стоимости. Существующая асимметрия информации между продавцом и покупателем часто приводит к неэффективному ценообразованию, а традиционные методы оценки, основанные на линейной регрессии, не способны учесть сложные нелинейные взаимодействия между признаками, например такими, как год выпуска, мощность двигателя и пробег. Высокая точность прогноза критически важна для страховых компаний, банков при выдаче кредитов и платформ электронной коммерции, где ошибка в оценке напрямую влияет на финансовые риски и доверие клиентов.
Вопросам прогнозирования рыночной стоимости автомобилей посвящено значительное количество исследований. Среди них выделяются работы, анализирующие влияние характеристик на цену подержанных автомобилей. Например, в одной из наших статей рассмотрены методы машинного обучения для оценки воздействия физических характеристик автомобиля, конструкционных особенностей, показателей работы двигателя и технических и финансовых критериев (Миролюбова и др., 2025). Аналогичные подходы реализованы и в других работах (Андриенко, 2024; Колобовникова, 2025; Топоривский, Пономарев, 2024; Щерба, Нестеренков, 2024).
Цель данного исследования состояла в разработке и верификации робастной модели машинного обучения, обеспечивающей минимальную погрешность прогнозирования стоимости транспортных средств. Для достижения цели были решены следующие задачи: проведены предобработка и очистка данных; осуществлено логарифмирование целевой переменной; проведено сравнительное тестирование линейных и ансамблевых моделей; выявлены ключевые детерминанты ценообразования. Методы машинного обучения и сравнительного анализа реализовывались на бесплатной платформе Google Colab с использованием языка программирования Python версии 3.9. В качестве основных библиотек применялись следующие:
-
1) Pandas1 и Numpy2 – для обработки и анализа табличных данных;
-
2) Matplotlib3 и Seaborn4 – для построения графиков и визуализации результатов;
-
3) Scikit-learn5 – для реализации алгоритмов случайного леса (Random Forest), Linear Regression;
-
4) XGBoost6 – для градиентного бустинга;
-
5) Joblib7 – для сохранения обученных моделей.
Методология исследования основана на комплексном подходе машинного обучения8, включая очистку и преобразование данных, логарифмирование целевой переменной, прогнозирование на базе поэтапного сравнения моделей по сложности и интерпретацию для бизнеса (рис. 1).
Поиск и предобработка исходных данных

Корреляционный анализ
Преобразование целевой переменной

Прогнозирование на основе поэтапного сравнения моделей по сложности

Интепретация: I анализ важности признаков по лучшей модели J
Рис. 1 . Поэтапная схема исследования на основе машинного обучения1
Fig. 1 . Step-by-Step Flow Chart of a Machine Learning-Based Research Project
В качестве исходных данных использовался репрезентативный набор сведений о подержанных автомобилях со вторичного рынка Индии, содержащий 7253 записи с 14 атрибутивными характеристиками. Датасет был взят из открытого источника на платформе Kaggle2. В рамках исследования рынка подержанных автомобилей предобработка данных представляет собой критически важный этап, предшествующий аналитическому моделированию. Методологическая значимость этого этапа заключается в устранении систематических ошибок, минимизации влияния аномальных наблюдений и стандартизации форматов для последующего статистического анализа.
Исходный массив данных характеризовался гетерогенной структурой, включающей как количественные, так и качественные переменные. Количественные признаки представлены метриками технического состояния (пробегом, мощностью и объемом двигателя, годом производства и т. п.) и экономическими (стоимостью). Качественные переменные включают номинальные характеристики (тип топлива, трансмиссия, число предыдущих владельцев и т. п.) и географическую локацию.
Структурный анализ выявил следующие главные атрибуты:
-
– идентификационные параметры (порядковый номер, наименование автомобиля);
-
– технические характеристики (год выпуска, пробег, тип топлива, трансмиссия);
-
– двигательные параметры (мощность, объем, расход топлива);
-
– комфортные характеристики (количество мест);
-
– экономические показатели (ориентировочная стоимость нового автомобиля в момент его выхода на рынок, текущая цена).
Исследование полноты данных показало неоднородное распределение пропусков по разным признакам. Наиболее существенные лакуны обнаружены в следующих переменных:
-
1) новая цена (New_Price) – 6247 пропущенных значений, или 86,0 % от общего объема данных;
-
2) текущая цена (Price) – 1234 пропуска (17,0 %);
-
3) количество мест (Seats) – 53 пропуска (0,7 %);
-
4) параметры двигателя (Engine, Power) – по 46 пропусков (0,6 %);
-
5) расход топлива (Mileage) – 2 пропуска (0,03 %).
Для устранения этих проблем была применена стратегия дифференциации обработки данных. Признак «новая цена» исключен из анализа ввиду критического уровня неполноты информации. Строки с пропущенными значениями текущей цены были удалены, поскольку указанный параметр относится к целевой переменной. Пропуски в технических характеристиках заполнены медианными значениями соответствующих распределений. Пропуски в количестве мест замещены модальным значением. Результатом реализации указанных процедур стала репрезентативная выборка объемом 6019 наблюдений с 13 признаками.
Для обеспечения совместимости данных с алгоритмами машинного обучения проведена трансформация типов данных. Все количественные переменные приведены к единому формату с плавающей точкой или целочисленному представлению в зависимости от характера измерений. Категориальные признаки подвергнуты процедуре порядкового кодирования (Label Encoding), которая присваивает уникальные числовые идентификаторы каждому дискретному значению. Подобный подход был применен к таким переменным, как географическая локация, тип топлива, вид трансмиссии и количество предыдущих владельцев. Исключение составил признак «наименование автомобиля», сохраненный в исходном текстовом формате ввиду уникальности большинства наименований.
Дескриптивный статистический анализ выявил экстремальные значения для нескольких ключевых переменных:
-
– пробег (Kilometers_Driven) – максимальное значение 6,5 млн км существенно превышает физически возможные пределы эксплуатации;
-
– расход топлива (Mileage) – нулевые значения противоречат физической природе явления;
-
– объем двигателя (Engine) – значения до 5998 см3 соответствуют характеристикам спортивных автомобилей, нерепрезентативных для общей популяции;
-
– мощность (Power) – экстремальные значения до 560 л. с. свойственны ограниченному сегменту рынка;
-
– цена (Price) – значения ниже 1 лакха индийских рупий (INR) статистически аномальны и маловероятны.
Поэтому для обеспечения репрезентативности выборки было принято решение об установлении пороговых значений: пробег – верхний предел 500 тыс. км; расход топлива – исключение нулевых значений; объем двигателя –верхний предел 5000 см3; мощность – верхний предел 500 л. с.; цена – диапазон от 1 до 160 лакхов индийских рупий.
Таким образом, реализованный комплекс процедур предобработки данных обеспечил формирование качественного аналитического массива со сбалансированной структурой, минимальным уровнем шума, соответствующего критериям полноты, непротиворечивости, репрезентативности и аналитической пригодности. В ходе предобработки данных и предварительного анализа предметной области (Апалькова, Левченко, 2023; Груздев, 2023) датасет уменьшился до чуть больше 5800 записей и 9 признаков (рис. 2).

Количественные признаки

Категориальные признаки
Год выпуска (Year)
□ Мощность двигателя (Power)
Пробег (Kilometers_Driven)
Расход топлива (Mileage)
Количество мест (Seats)
Тип топлива (Fuel_Type)
Тип трансмиссии (Transmission)
Количество владельцев (Owner_Type)
Местоположение автомобиля (Location)
Рис. 2 . Типология признаков набора данных по автомобилям1
-
Fig. 2 . Typology of Features of the Car Dataset
На этапе корреляционного анализа проведено изучение структуры взаимосвязей между количественными предикторами. В целях выявления тесноты и направления линейной зависимости между переменными использован метод парной корреляции Пирсона. Визуализация полученных результатов в формате тепловой карты позволила структурировать информацию о влиянии технических характеристик транспортных средств на их рыночную стоимость (рис. 3).
Интерпретация полученных статистических данных позволяет сделать следующие выводы. Наиболее выраженная положительная связь с целевой переменной наблюдается у признаков «мощность» (r = 0,77) и «объем двигателя» (r = 0,65). Данная закономерность подтверждает гипотезу о том, что тягово-динамические характеристики автомобиля являются определяющими факторами позиционирования в высоком ценовом сегменте. Обнаружен высокий уровень мультиколлинеарности между мощностью и объемом двигателя (r = 0,85), что обусловлено естественной инженерной зависимостью. Год выпуска демонстрирует умеренную положительную корреляцию с ценой (r = 0,30), в то время как пробег – слабую отрицательную связь (r = –0,17). Такие значения свидетельствуют о том, что фактор новизны автомобиля вносит более весомый вклад в стоимость, нежели фактический пробег, который в рамках выборки имеет нелинейный характер влияния. Отрицательная корреляция между расходом топлива и ценой (r = –0,33), а также ее обратная связь с техническими параметрами (объем двигателя – r = –0,65, мощность – r = –0,56) отражают классический рыночный компромисс. Бюджетные модели с высокими показателями экономичности характеризуются более низким мощностным потенциалом. Количество посадочных мест не оказывает статистически значимого влияния на стоимость (r = 0,07), что позволяет классифицировать этот признак как вторичный при решении задачи регрессионного моделирования1.
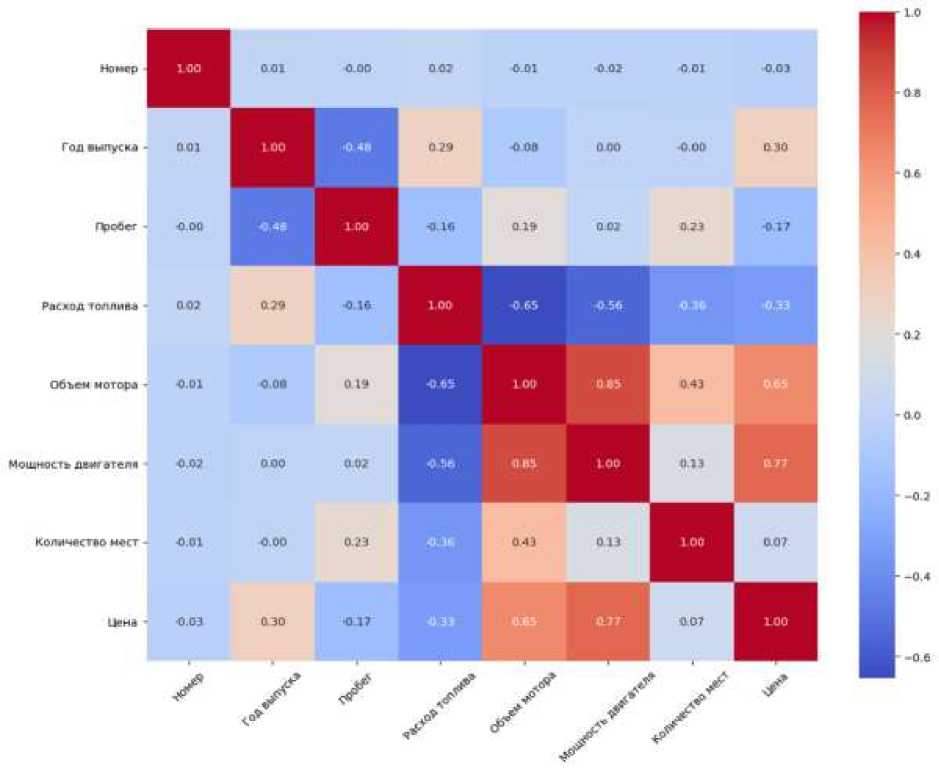
Рис. 3 . Корреляционная матрица взаимосвязи технических характеристик транспортных средств и их рыночной стоимости2
-
Fig. 3 . Correlation Matrix of the Relationship Between Technical Characteristics of Vehicles and Their Market Value
Для обеспечения объективной оценки прогностических способностей разработанных моделей, а также предотвращения переобучения очищенный и преобразованный набор данных разделен на обучающую (train) и тестовую (test) выборки в соотношении 80 к 20 %. Выборка была разбита с помощью функции train_test_split из библиотеки Scikit-learn. Нормирование количественных признаков являлось заключительным этапом обработки, который необходим для обеспечения одинакового вклада в модель всех признаков, вне зависимости от их масштаба. Например, пробег измеряется сотнями тысяч, а количество мест– единицами. Для данной задачи был выбран метод StandartScaler: количественные признаки преобразуются так, что получают среднее значение, равное 0, и стандартное отклонение, равное 1 (z-score). Нормированию подвергались только пять количественных признаков (год выпуска, пробег, мощность, расход топлива и количество мест). Закодированные категориальные признаки (местоположение, тип трансмиссии, тип топлива и число владельцев) не масштабировались.
В качестве целевой переменной (Y) в нашем исследовании выступала цена автомобиля (Price), выраженная в лакхах. Установлено, что распределение цены имеет значительную положительную асимметрию (коэффициент 3,26). Для корректного прогнозирования применено логарифмическое преобразование (ln(Ptice)) (рис. 4). С математической точки зрения это обосновано тем, что в ценообразовании влияние факторов часто носит не аддитивный, а мультипликативный характер. Например, год выпуска снижает стоимость автомобиля на определенную долю в процентах, а не на фиксированную сумму. Логарифмирование позволяет линейным и древовидным моделям эффективнее улавливать эти относительные зависимости, а также снижает чувствительность модели к выбросам в премиальном сегменте. Заметим, что на этапе прогнозирования использовалось обратное преобразование (exp(Y)) для получения предсказанной цены в исходной валюте.
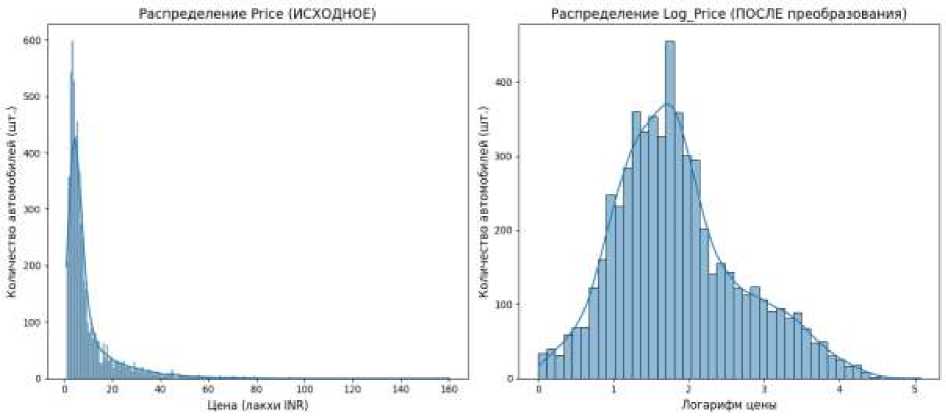
Рис. 4 . Преобразование целевой переменной на основе логарифмирования
Fig. 4 . Transformation of the Target Variable Based on Logarithm
Исследование было построено на принципе поэтапного сравнения моделей по сложности. Для решения задачи прогнозирования цены на автомобиль выбраны однофакторные регрессионные модели и многофакторное моделирование. На первом этапе проверена гипотеза о возможности адекватного прогнозирования стоимости автомобиля с помощью одного предиктора. Признаки отобраны, исходя из общепринятой экономической логики ценообразования на рынке подержанных автомобилей. Результаты, представленные в таблица 1, однозначно подтверждают непригодность однофакторного подхода.
Таблица 1 . Метрики точности прогнозирования по однофакторным регрессионным моделям1
Table 1 . Forecast Accuracy Metrics for Single-Factor Regression Models
|
Признак |
R2 |
MAE (Log) |
RMSE (Log) |
MAE (INR) |
|
Год выпуска |
0,2224 |
0,5955 |
0,7385 |
5,573 |
|
Мощность двигателя |
0,6111 |
0,4126 |
0,5223 |
4,334 |
|
Пробег |
0,0266 |
0,6587 |
0,8263 |
5,842 |
|
Тип трансмиссии |
0,3809 |
0,5306 |
0,6589 |
4,868 |
Признак «мощность двигателя» (Power) показал наибольшую долю объясненной дисперсии (R2 = 0,61), но даже в этом случае средняя абсолютная ошибка (MAE) в денежном эквиваленте составила 4,334 INR. Такой уровень ошибки является неприемлемо высоким для коммерческого использования. Удивительно, что на индийском рынке в отличие от российского2 фактор «пробег» оказывает минимальное влияние на стоимость автомобиля (R2 = 0,026). Это означает преобладание других технических характеристик над степенью износа в процессе ценообразования.
Неудовлетворительные результаты однофакторного анализа послужили основанием для перехода к многофакторному моделированию. Сравнение проводилось между линейной регрессией и двумя ансамблевыми методами – случайный лес1 и градиентный бустинг2.
В качестве базовой модели использовалась классическая линейная регрессия. Она предполагает линейную зависимость между целевой переменной Y (цена автомобиля) и набором независимых признаков Х. Математически это выражается формулой:
Y = α0 + α1X1 + α2X2 + ⋯ + αkXk + ε , (1) где α i – коэффициенты регрессии, определяющие вклад каждого признака (год, объем двигателя, тип топлива и т. п.) в итоговую стоимость;
ε – случайная ошибка.
Главное преимущество данной модели заключается в высокой интерпретируемости каждого признака, вес которого показывает, как изменится цена при увеличении параметра на единицу. Однако линейная регрессия чувствительна к мультиколлинеарности и не способна улавливать нелинейные зависимости без предварительной сложной трансформации признаков.
Случайный лес представляет собой ансамблевый алгоритм, основанный на методе бэггинга. Его суть состоит построении большого количества независимых деревьев решений на случайных подвыборках данных и признаков, а затем усреднении их индивидуальных прогнозов для получения финального результата. Каждое дерево строится на случайном подмножестве признаков, что обеспечивает декорреляцию моделей. Алгоритм эффективно справляется с пропусками в данных и не требует нормализации признаков. В контексте цен на автомобили модель случайного леса хорошо фиксирует категориальные зависимости, например влияние бренда или типа трансмиссии, минимизируя риск переобучения за счет усреднения ответов множества деревьев.
Градиентный бустинг (eXtreme Gradient Boosting, XGBoost) является наиболее современным и эффективным инструментом для работы с табличными данными. Встроенные механизмы штрафования за сложность модели позволяют избежать переобучения на специфических выбросах рынка, (например, аномально дорогие раритетные авто). Использование алгоритма аппроксимации для поиска лучших разбиений в деревьях ускоряет обучение на больших датасетах. Бустинг способен выявлять сложные взаимодействия признаков, в частности когда влияние пробега на цену существенно меняется в зависимости от возраста автомобиля. Таким образом, в отличие от случайного леса деревья строятся последовательно, где каждое последующее дерево исправляет ошибки предыдущих деревьев, постепенно улучшая общую прогностическую силу ансамбля. Этот метод идеально подходит для сложных, нелинейных взаимосвязей между признаками, характерных для ценообразования на рынке подержанных автомобилей.
Три выбранные модели – линейная регрессия, случайный лес и градиентный бустинг – были последовательно обучены на матрице признаков Xtrain и векторе целевой переменной Ytrain(ln(Price)). Древовидные ансамблевые модели обучены с разумными, стандартными параметрами: n_estimators = 100,00 для модели случайного леса и n_estimators = 300,00, learning_rate = 0,05 для модели градиентного бустинга. Эти настройки обеспечивают высокую прогностическую силу при минимальном риске чрезмерно долгого обучения.
Для анализа адекватности моделей проведена оценка не только на обучающей, но и на тестовой выборке по всем основным метрикам (таблица 2). Оценка включала метрики в логарифмическом масштабе: коэффициент детерминации (R2), среднюю абсолютную ошибку (MAE), корень из среднеквадратичной ошибки (RMSE) и среднюю абсолютную ошибку, пересчитанную обратно в исходный масштаб цены (лакхи INR).
Таблица 2 . Метрики точности прогнозирования по многофакторным моделям
Table 2 . Metrics of Forecasting Accuracy for Multivariate Models
|
Модель |
Выборка |
R2 |
MAE |
RMSE |
MAE, лакх INR |
|
Линейная регрессия |
train |
0,8700 |
0,2248 |
0,3008 |
|
|
test |
0,8740 |
0,2278 |
0,2973 |
2,332 |
|
|
Случайный лес |
train |
0,9893 |
0,0583 |
0,0862 |
|
|
test |
0,9288 |
0,1583 |
0,2234 |
1,497 |
|
|
Градиентный бустинг |
train |
0,9799 |
0,0881 |
0,1183 |
|
|
test |
0,9405 |
0,1471 |
0,2042 |
1,387 |
1 Захаренко Е. Бэггинг и случайный лес. Ключевые особенности и реализация с нуля на Python [Электронный ресурс] // Хабр. 2024. 19 марта. URL: (дата обращения: 29.04.2026).
2 Захаренко Е. Градиентный бустинг. Реализация с нуля на Python и разбор особенностей его модификаций (XGBoost, CatBoost, LightGBM) [Электронный ресурс] // Там же. 2024. URL: (дата обращения: 29.04.2026).
Значительный разрыв в метриках, например высокое значение R2 на train- и низкое значение на test-выборке, указывает на переобучение. Коэффициенты детерминации линейной регрессии практически одинаковы. Это свидетельствует о том, что модель не переобучилась, но при этом имеет слабые прогностические свойства по сравнению с двумя другими.
Анализ полученных результатов показывает кардинальное превосходство ансамблевых методов над линейной регрессией. Обе модели продемонстрировали высокие результаты на train-выборке, но зафиксировано ожидаемое снижение производительности на test-выборке, что является результатом переобучения. Однако если для модели случайного леса характерно значительное снижение R2 с 0,9893 до 0,9288, то для градиентного бустинга оно в 1,5 раза меньше. В целом модель градиентного бустинга показала наилучшую прогностическую силу, достигнув R2 = 0,94 на тестовой выборке. Это означает, что 94 % вариации стоимости автомобиля объясняются моделью. По абсолютной ошибке градиентный бустинг также продемонстрировал наименьшую ошибку (0,140 и 1,387 лакха INR), что указывает на минимальное среднее отклонение.
Как видно на рис. 5, в основном ценовом диапазоне до 30 лакхов INR предсказания практически полностью совпадают с реальными значениями. Небольшой разброс в премиальном сегменте (выше 40 лакхов INR) объясняется малым количеством таких примеров в выборке и высокой индивидуальностью цен на дорогие авто. В целом график подтверждает высокую точность модели.
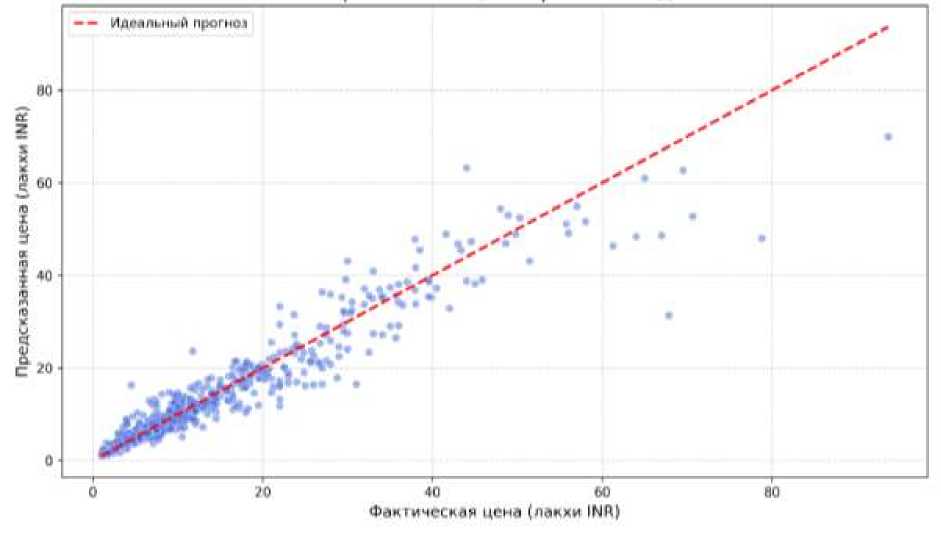
Рис. 5 . Сравнение фактических и предсказанных цен по модели градиентного бустинга
-
Fig. 5 . Comparison of Actual and Predicted Prices Using the Gradient Boosting Model
На этапе интерпретации – анализа важности признаков, проведенного для лучшей модели (в нашем случае градиентного бустинга), – выявлены ключевые факторы, влияющие на ценообразование подержанного автомобиля. С помощью метода F-score определена относительная важность (сколько раз конкретный признак использовался для разделения данных во всех узлах всех деревьев модели). Чем чаще признак выбирался для разбиения, тем выше его показатель важности (рис. 6).
Таким образом, все факторы, определяющие стоимость продажи автомобиля на индийском рынке, можно разделить на три группы. Первая – это доминирующие факторы, являющиеся ключевыми рыночными рычагами и совокупно объясняющие 83 % важности. Среди них мощность двигателя с коэффициентом важности 47 %, год выпуска – 19 %, тип трансмиссии – 17 %. Мощность двигателя сохраняет покупательскую премию за высокую производительность и более дорогие комплектации; значение года выпуска отражает влияние амортизации; тип трансмиссии на индийском рынке – это не просто опция, а критический структурный признак, разделяющий рынок на сегменты. Автоматическая трансмиссия часто ассоциируется с более высоким классом и удобством, сохраняя высокую стоимость.
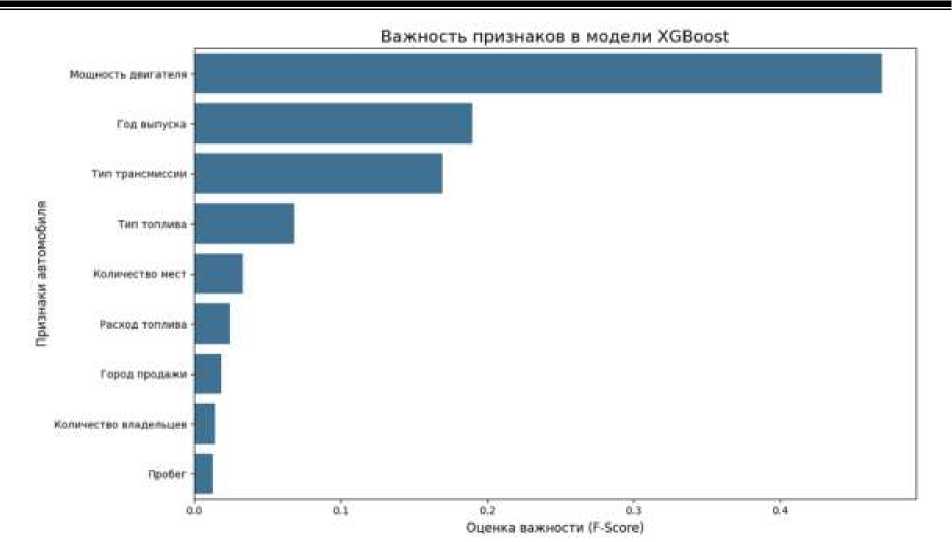
Рис. 6 . Важность признаков, влияющих на стоимость подержанного автомобиля на индийском рынке, по модели градиентного бустинга
-
Fig. 6 . Importance of Attributes influencing the Price of a Used Car in the Indian Market Using the Gradient Boosting Model
Вторая группа – факторы комплектации и рыночной сегментации, значимые для тонкой настройки цены в пределах сегмента. Тип топлива – 7 % – важен в условиях колебаний цен на горючее и экологических предпочтений рынка. Количество мест в автомобиле имеет маргинальное воздействие (5 %) на цену автомобиля, определяя ее разницу между стандартными (5-местными) и крупными семейными (7-местными) автомобилями.
Наконец, третья группа – второстепенные факторы с общим коэффициентом важности 4 %: пробег и расход топлива. Вопреки интуитивному ожиданию, что пробег будет в тройке лидеров, он оказался среди наименее важных факторов. Возможно, это связано с тем, что информация о нем уже в значительной степени учтена в годе выпуска. После того как модель определила мощность и возраст автомобиля, фактический пробег вносит минимальный дополнительный вклад в прогноз его цены.
Таким образом, результаты сравнительного анализа различных моделей машинного обучения позволяют сформулировать ряд выводов:
-
1) процесс формирования цены на подержанные автомобили носит выраженный нелинейный характер, требующий ансамблевых подходов;
-
2) мощность двигателя – ключевой детерминант стоимости в условиях специфического вторичного рынка Индии;
-
3) модель градиентного бустинга продемонстрировала наиболее сбалансированные показатели точности и устойчивости к переобучению;
-
4) система F-score позволяет бизнесу понять, какие параметры (мощность, тип КПП и т. п.) приносят наибольшую маржинальность;
-
5) предложенная модель может быть интегрирована в автоматизированные системы оценки для дилерских центров и онлайн-агрегаторов.
