Сравнительный анализ моделей машинного обучения для оценки стоимости недвижимости

Автор: Баланев К.С., Федосов А.Н., Сало А.А.
Рубрика: Информатика и вычислительная техника
Статья в выпуске: 4, 2025 года.
Бесплатный доступ
В статье представлен сравнительный анализ моделей машинного обучения, применяемых для прогнозирования рыночной стоимости объектов жилой недвижимости. Исследование основано на анализе данных, включающих количественные и качественные параметры объектов, такие как площадь, расположение, транспортная доступность и уровень ремонта. Для обработки категориальных признаков использовано номинальное шкалирование, а для выявления значимых факторов и устранения избыточности информации применены методы корреляционного и факторного анализа. В работе выполнено построение и оценка четырёх прогнозных моделей: линейной регрессии, случайного леса, градиентного бустинга и нейронных сетей. Показано, что модель на основе алгоритма случайного леса демонстрирует наилучшее качество прогноза.
Рынок недвижимости, стоимость, корреляционный анализ, факторный анализ, коэффициент детерминации, линейная регрессия, случайный лес, градиентный бустинг, нейронные сети
Короткий адрес: https://sciup.org/148332830
IDR: 148332830 | УДК: 332.6 | DOI: 10.18137/RNU.V9187.25.04.P.78
A Comparative analysis of machine learning models for real estate valuation
This article presents a comparative analysis of machine learning models used to forecast the market value of residential real estate. The study is based on data analysis, including quantitative and qualitative parameters of properties, such as area, location, transport accessibility, and level of repair. Nominal scaling was used to process categorical features, while correlation and factor analysis were employed to identify significant factors and eliminate information redundancy. The paper constructs and evaluates four forecasting models: linear regression, random forest, gradient boosting, and neural networks. It is shown that the random forest-based model demonstrates the best forecast quality.
Текст научной статьи Сравнительный анализ моделей машинного обучения для оценки стоимости недвижимости
Оценка и прогнозирование стоимости объектов жилой недвижимости представляет собой одну из задач в сфере городского планирования и инвестиционного анализа. Рыночная стоимость формируется под влиянием совокупности факторов, как объективных, так и субъективных, степень влияния которых варьируется в зависимости от конкретного сегмента рынка.
В общей структуре факторов, определяющих стоимость недвижимости, принято выделять две основные группы: количественные (формализуемые) и качественные (субъективные). К первой категории относятся параметры, поддающиеся измерению и статистическому анализу (площадь, этажность, транспортная доступность и др.) [1]; ко второй категории – характеристики, требующие применения экспертных и социологических методов (оценка состояния объекта, престижность района, восприятие инфраструктуры и др.) [2]. В ряде случаев качественные признаки могут быть преобразованы в количественные с использованием процедур преобразования данных.
Несмотря на широкое применение в практике, известные методы оценки стоимости недвижимости, преимущественно основанные на линейных моделях, обладают рядом ограничений. В частности, они не в полной мере отражают сложные нелинейные зависимости между переменными, а также не учитывают эффекты взаимодействия между факторами, которые могут существенно изменять вклад отдельных признаков в формирование итоговой стоимости.
В связи с этим актуальность приобретает применение методов интеллектуального анализа данных и машинного обучения, позволяющих выявлять скрытые закономерности в данных, учитывать взаимодействие между факторами и нелинейную природу взаимосвязей. Настоящее исследование направлено на сравнительный анализ моделей прогнозирования стоимости недвижимости с использованием современных алгоритмов машинного обучения, а также на выявление наиболее значимых факторов, влияющих на его ценовые характеристики.
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 4
Исходные данные
В работе использован открытый набор данных о жилой недвижимости в Москве, размещённый на платформе Kaggle 1 . В выборке представлены сведения о ценовых характеристиках объектов и ряде факторов, потенциально влияющих на формирование их рыночной стоимости.
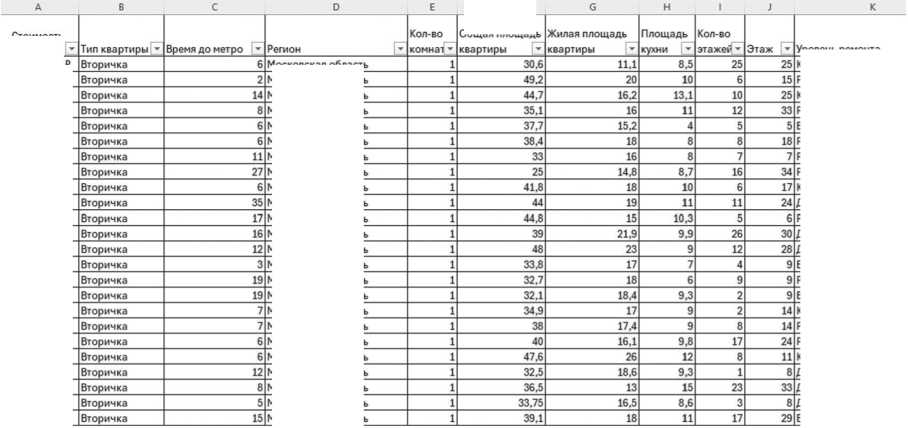
В качестве целевой переменной выступает показатель стоимости объекта недвижимости, выраженный в рублях. В качестве признаков, подлежащих анализу (см. Рисунок 1), выделены следующие десять факторов:
-
• тип квартиры;
-
• время до метро;
-
• регион;
-
• количество комнат;
-
• общая площадь квартиры;
-
• жилая площадь квартиры;
-
• площадь кухни;
-
• количество этажей в доме;
-
• этаж;
-
• уровень ремонта.
Общая площадь
Стоимость
Рисунок 1. Исходные данные
Источник: здесь и далее рисунки выполнены авторами
Анализ структуры данных показал, что признаки «регион», «тип квартиры» и «уровень ремонта» имеют категориальный характер и не поддаются прямому количественному анализу. Для их обработки была применена процедура номинального шкалирования [3], обеспечивающая преобразование качественных признаков в числовой формат с сохранением информационной значимости. Примеры трансформации данных представлены на Рисунке 2.
6 300 000,00 ₽ 9 000 000,00 ₽
11090 000,00 ₽ 8 300 000,00 ₽
6 450 000,00₽ 7150 000,00₽
7 400 000,OOP 7 500 000,00 Р
7 800 000,00 Р
7 999 999,00 Р
9 000 000,00 Р
12 300 000,00 ₽
14 000 000,00 Р 6 000 000,00 Р 6 200 000,00Р
6 300 000,OOP
6 500 000,00 Р
6 800 000,00 Р
7 350 000,00 Р 8100 000,00Р
8 200 000,00 Р
8 600 000,00 Р 9 200 000,00 Р
9 300 000,00 Р
Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область Московская область
Уровень ремонта Косметический ремон Ремонт в европейском Косметический ремон Ремонт в европейском Без ремонта
Ремонт в европейском Ремонт в европейском Ремонт в европейском Косметический ремон Дизайнерский ремонт Ремонт в европейском Дизайнерский ремонт Дизайнерский ремонт Без ремонта
Ремонт в европейском Без ремонта
Косметический ремон Ремонт в европейском Ремонт в европейском Косметический ремон Дизайнерский ремонт Дизайнерский ремонт Дизайнерский ремонт Без ремонта
Сравнительный анализ моделей машинного обучения для оценки стоимости недвижимости
|
Стоимость Тип |
квартиры Время до метро |
Регион |
... Площадь кухни Кол-во |
этажей |
Этаж Уровень ремонта |
||
|
6300000,00 |
1,00 |
6,00 |
1,00 |
... 8,50 |
25,00 |
25,00 |
1,00 |
|
9000000,00 |
1,00 |
2,00 |
1,00 |
... 10,00 |
6,00 |
15,00 |
2,00 |
|
11090000,00 |
1,00 |
14,00 |
1,00 |
... 13,10 |
10,00 |
25,00 |
1,00 |
|
8300000,00 |
1,00 |
8,00 |
1,00 |
... 11,00 |
12,00 |
33,00 |
2,00 |
|
6450000,00 |
1,00 |
6,00 |
1,00 |
... 4,00 |
5,00 |
5,00 |
3,00 |
|
4768792,00 |
2,00 |
8,00 |
1,00 |
... 5,00 |
4,00 |
17,00 |
1,00 |
|
5900000,00 |
2,00 |
25,00 |
1,00 |
... 12,20 |
11,00 |
15,00 |
1,00 |
|
3700000,00 |
2,00 |
30,00 |
1,00 |
... 8,10 |
17,00 |
17,00 |
1,00 |
|
5768869,00 |
2,00 |
14,00 |
1,00 |
... 6,60 |
12,00 |
14,00 |
1,00 |
|
6839157,00 |
2,00 |
8,00 |
1,00 |
... 5,00 |
10,00 |
17,00 |
1,00 |
Рисунок 2. Преобразование качественных данных в количественные
На этапе предварительной обработки осуществлена проверка выборки на наличие дубликатов, пропущенных значений и аномальных наблюдений (выбросов). Были удалены повторяющиеся строки, а отсутствующие значения обработаны в соответствии с типом признака (удаление или замена статистически обоснованными значениями).
Для дальнейшего анализа взаимосвязей между факторами и целевой переменной были использованы методы корреляционного анализа и факторного анализа. Выбор указанных методов обусловлен необходимостью установления степени влияния отдельных признаков на стоимость объектов.
Предварительная обработка данных
Корреляционный анализ
Для выявления связей между переменными и определения значимых факторов, влияющих на стоимость недвижимости, был применён корреляционный анализ [4–6]. Основной целью данного этапа стало установление направленности и силы взаимосвязей между признаками и целевой переменной. Расчёт осуществлялся с использованием коэффициента линейной корреляции Пирсона, значения которого интерпретировались согласно общепринятой градации (см. Таблицу 1).
Таблица 1
Теснота связи в зависимости от коэффициента корреляции
|
Теснота связи |
Коэффициент корреляции |
|
Слабая |
±0,00 до ±0,3 |
|
Умеренная |
±0,3 до ±0,5 |
|
Заметная |
±0,5 до ±0,7 |
|
Высокая |
±0,7 до ±0,9 |
|
Весьма высокая |
±0,9 до ±0,99 |
Результаты анализа корреляционной матрицы:
-
• сильная положительная связь обнаружена у признаков «общая площадь квартиры», «жилая площадь»;
-
• заметная положительная корреляция – «площадь кухни»;
-
• умеренная положительная связь – «количество комнат», «уровень ремонта»;
-
• слабая отрицательная корреляция – «время до метро», «этаж расположения квартиры»;
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 4
-
• слабая положительная корреляция – «регион», «число этажей в доме»;
-
• признак «тип квартиры» демонстрирует граничные значения между слабой и умеренной отрицательной связью.
Корреляционная матрица представлена на Рисунке 3. Также было зафиксировано наличие признаков с высокой взаимной корреляцией (мультиколлинеарность), что необходимо учитывать при выборе моделей машинного обучения.
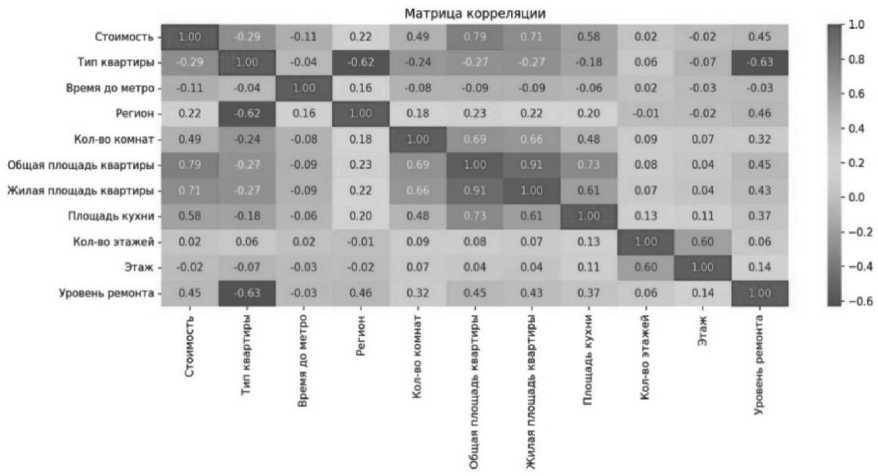
Рисунок 3. Матрица корреляций
Визуализация парных графиков (см. Рисунок 4) позволяет утверждать, что основная часть признаков демонстрирует линейную направленность влияния на целевую переменную. При этом наблюдаются отдельные случаи нелинейных взаимодействий между факторами. Так, например, значение признака «жилая площадь» оказывает различное влияние на итоговую стоимость в зависимости от количества комнат: для однокомнатных квартир прирост жилой площади значимо увеличивает стоимость, тогда как для четырёхкомнатных объектов аналогичный прирост не оказывает сопоставимого эффекта.
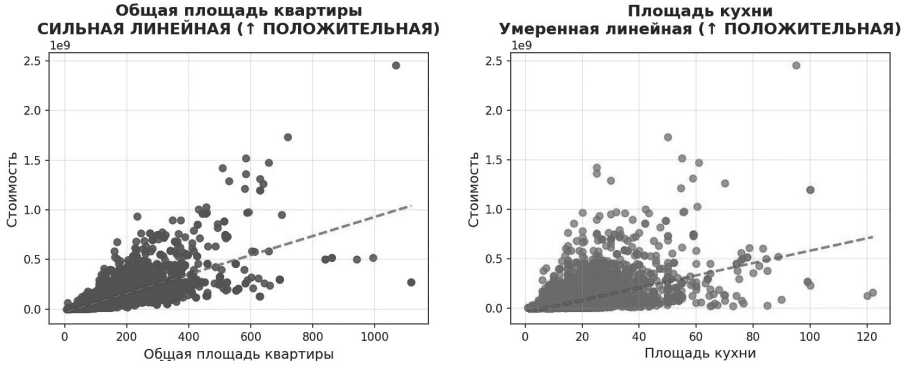
Рисунок 4. Проверка на линейные зависимости
Сравнительный анализ моделей машинного обучения для оценки стоимости недвижимости
Факторный анализ
Для сокращения размерности признакового пространства и устранения избыточности данных применён метод главных компонент (PCA). Данный подход позволяет определить направления максимальной дисперсии и спроецировать данные в новое пространство с сохранением значимой доли информации [7]. На основании анализа предложено сократить количество признаков до трёх, обеспечив при этом минимальные потери при интерпретации результатов работы модели. Результаты факторного анализа представлены на Рисунке 5.
|
ОБЪЯСНЕННАЯ ДИСПЕРСИЯ КОМПОНЕНТАМИ РСА: |
|||||
|
Компонента |
1: 0.3721 |
(37.21%) |
| Накопленно: |
0.3721 |
(37.21%) |
|
Компонента |
2: 0.1670 |
(16.70%) |
| накопленно: |
0.5391 |
(53.91%) |
|
Компонента |
3: 0.1525 |
(15.25%) |
| Накопленно: |
0.6916 |
(69.16%) |
|
Компонента |
4: 0.0977 |
(9.77%) |
| Накопленно: |
0.7893 |
(78.93%) |
|
Компонента |
5: 0.0541 |
(5.41%) |
| Накопленно: |
0.8434 |
(84.34%) |
|
Компонента |
6: 0.0503 |
(5.03%) |
| Накопленно: |
0.8937 |
(89.37%) |
|
Компонента |
7: 0.0388 |
(3.88%) |
| Накопленно: |
0.9324 |
(93.24%) |
|
Компонента |
8: 0.0326 |
(3.26%) |
| Накопленно: |
0.9651 |
(96.51%) |
|
Компонента |
9: 0.0275 |
(2.75%) |
| Накопленно: |
0.9926 |
(99.26%) |
|
Компонента |
10: 0.0074 (0.74%) |
| Накопленно: |
1.0000 (100.00%) |
||
КЛЮЧЕВЫЕ ТОЧКИ:
90% дисперсии объясняется 7 компонентами
95% дисперсии объясняется 8 компонентами Снижение размерности: 10 -> 7 признаков
Рисунок 5. Анализ методом главных компонент
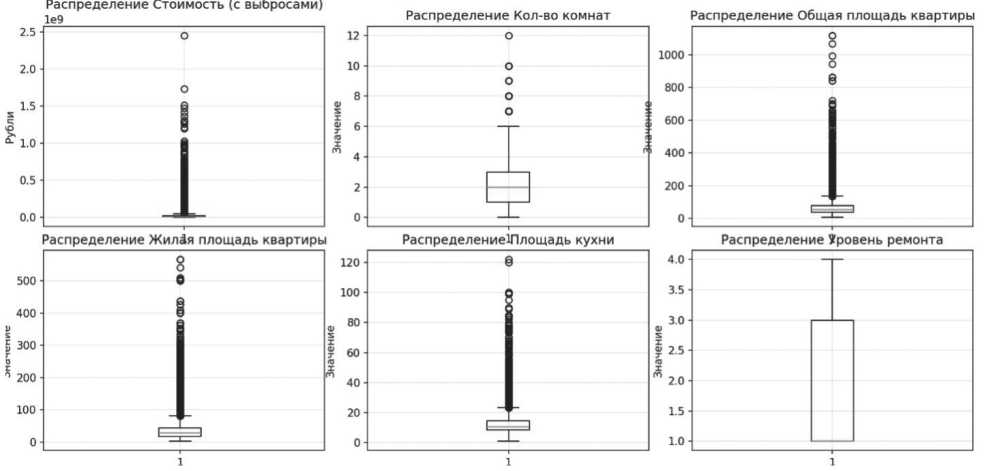
Для оценки наличия аномальных наблюдений (выбросов) в выборке применён метод диаграмм размаха (BoxPlot). Результаты визуализации представлены на Рисунке 6.
Вестник Российского нового университета
Серия «Сложные системы: модели, анализ и управление». 2025. № 4
На основании критерия межквартильного размаха установлено, что 14,7 % наблюдений могут быть классифицированы как выбросы, что свидетельствует о необходимости применения процедуры исключения выбросов перед обучением моделей.
Построение и оценка моделей прогнозирования
В качестве инструментов прогнозирования стоимости объектов жилой недвижимости в настоящем исследовании применены четыре алгоритма машинного обучения:
-
• линейная регрессия;
-
• случайный лес (Random Forest);
-
• градиентный бустинг (Gradient Boosting);
-
• нейронные сети.
Выбор указанных моделей обусловлен их широким применением в прикладных задачах прогнозирования цен, а также результатами последних отечественных исследований [8– 10], подтверждающих их эффективность в условиях нестабильной рыночной среды, высокой размерности данных и наличия сложных взаимозависимостей между признаками.
Линейная регрессия используется как базовая модель, обеспечивающая интерпретируемость результатов и служащая точкой сравнения. Ансамблевые методы (случайный лес и градиентный бустинг) зарекомендовали себя как устойчивые к выбросам и мультиколлинеарности подходы, способные учитывать нелинейные взаимодействия между признаками. Применение нейронных сетей оправданно при наличии сложной структуры данных, требующей выявления скрытых зависимостей и повышения точности прогноза за счёт обучения на больших объёмах информации.
Обучение моделей выполнялось в среде программирования Python с использованием Visual Studio Code. Исходный набор данных был разделён на обучающую и тестовую выборки с применением стратифицированного разбиения, что обеспечило репрезентативность распределения целевой переменной. Для линейной регрессии и нейронных сетей была выполнена стандартизация признаков методом Standard Scaler. Алгоритмы на основе деревьев решений (случайный лес и градиентный бустинг) масштабирования не требовали.
Оценка моделей
После обучения моделей была выполнена их оценка с использованием коэффициента детерминации, средней абсолютной ошибки и среднеквадратичной ошибки. Коэффициент детерминации характеризует долю дисперсии результативного признака y , объясняемую регрессией, в общей дисперсии результативного признака [11]. Чем коэффициент детерминации ближе к 1, тем модель лучше. MAE показывает среднее абсолютное отклонение предсказанных значений от фактических. RMSE является квадратным корнем из MSE.
На Рисунке 7 представлены коэффициенты детерминации, средние абсолютные ошибки и среднеквадратичные ошибки в результате обучения моделей.
Наилучший результат был продемонстрирован моделью случайного леса ( R 2 = 0,78), что подтверждает её высокую эффективность в задачах прогнозирования динамики цен на рынке недвижимости.
Сравнительный анализ моделей машинного обучения для оценки стоимости недвижимости
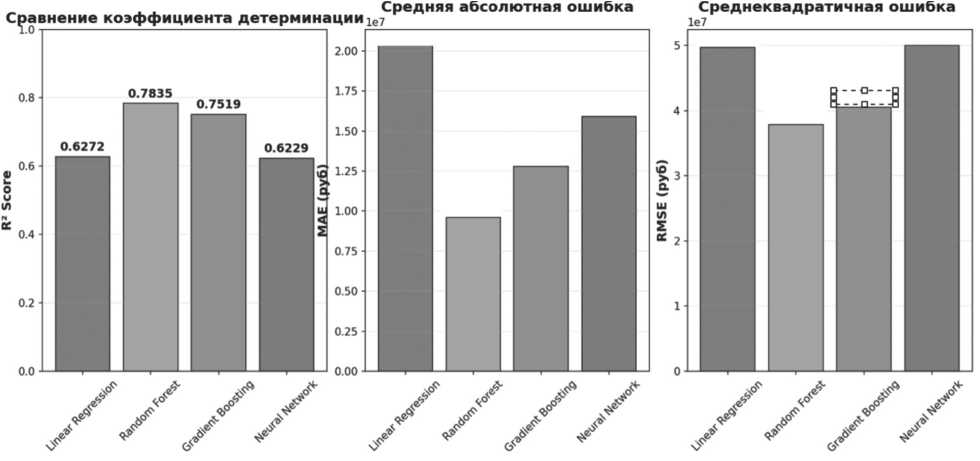
Рисунок 7. Полученные коэффициенты детерминации моделей
Заключение
Проведённое исследование подтвердило применимость методов машинного обучения для решения задачи прогнозирования стоимости объектов жилой недвижимости. Использование современных алгоритмов позволило повысить точность прогнозных моделей по сравнению с линейными подходами.
Наилучшие результаты были достигнуты с использованием модели случайного леса, что объясняется её устойчивостью к шуму, способностью выявлять скрытые закономерности и учитывать сложные взаимодействия между признаками. В то же время было выявлено, что ни один из методов не является универсальным – каждый из них демонстрирует преимущества и ограничения в зависимости от структуры и характера исходных данных.
В качестве перспективных направлений дальнейших исследований целесообразно рассматривать развитие методик автоматизированного подбора гиперпараметров моделей. Также представляет интерес реализация интеллектуальных систем, сочетающих несколько алгоритмов машинного обучения с различной архитектурой и функционирующих в рамках единой модели.
