Сравнительный анализ схем селекции и замещения для генетического программирования

Автор: Становов В.В.
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 1 т.27, 2026 года.
Бесплатный доступ
Механизм селекции в генетическом программировании привлек внимание многих исследователей, в результате чего были предложена лексикейс селекция и её варианты. Однако схемы замещения часто выходят за рамки большинства исследований по генетическому программированию. В этой статье изучается влияние различных механизмов селекции, когда они применяются как к отбору родителей, так и к замещению. Цель исследования – оценить эффективность различных схем селекции родителей и селекции окружающей средой в генетическом программировании. Для этого в статье сравниваются четыре метода селекции родителей, семь методов замещения и два метода выбора первого родителя в паре, что дает в общей сложности 56 комбинаций. Эксперименты проводились на наборе из 10 регрессионных задач из коллекции PMLB dataset, а коэффициент детерминации использовался в качестве показателя качества. Для анализа значений качества решений использовались статистические тесты Манна – Уитни и ранжирование по Фридману. Анализ результатов показывает, что лексикейс селекция с уменьшенной выборкой может быть эффективным механизмом, выбор текущего индивида в качестве одного из родителей может быть полезным и что либо попарное сравнение, либо выбор лучших из родителей и потомков является эффективной стратегией замещения. Результаты, полученные в этом исследовании, могут быть применены для повышения эффективности решения задач символьной регрессии, которые часто возникают в аэрокосмической отрасли, например, для прогнозирования параметров деградации солнечных панелей или диаграмм направленности антенн.
Генетическое программирование, лексикейс селекция, эволюционные алгоритмы
Короткий адрес: https://sciup.org/148333108
IDR: 148333108 | УДК: 519.87 | DOI: 10.31772/2712-8970-2026-27-1-61-71
Comparative analysis of selection and replacement schemes for genetic programming
The selection mechanism in genetic programming has attracted attention of many researchers, as a result lexicase selection and its variants have been proposed. However, the replacement schemes are often out of the scope of most studies on genetic programming. In this paper, the effects of different selection mechanisms are studied, when they are applied to both parents’ selection and replacement. The aim of the study is to evaluate the efficiency of different parent and environment selection schemes in genetic programming. For this in the paper the four-parent selection, seven replacement are compared and two methods for selecting first parent in a pair, giving a total of 56 combinations. The experiments are performed on a set of 10 regression problems from the PMLB dataset collection, and the determination coefficient is used as a performance metric. The Mann-Whitney statistical tests and Friedman ranking is used for the analysis of the performance values. The analysis of the results show that the down-sampled lexicase selection can is an efficient mechanism, selecting current individual as one of the parents could be beneficial, and that either pair-wise comparison or selection of best of parents and offspring is an efficient replacement strategy. The results obtained in this study can be applied to improve the efficiency of solving symbolic regression problems, which often arise in the aerospace industry, for example for predicting solar panels degradation parameters, or antenna radiation patterns.
Текст научной статьи Сравнительный анализ схем селекции и замещения для генетического программирования
Подходы генетического программирования (ГП) являются частью эволюционных вычислений, которые используются для создания различных видов программного кода, начиная от относительно простых математических уравнений и заканчивая сложным кодом с большим количеством инструкций. Существует множество вариантов ГП, которые были предложены в последние десятилетия, начиная с простого ГП на основе деревьев [1; 2], после которого был предложен линейный ГП (ЛГП) [3], декартов ГП (ДГП) [4; 5], грамматическая эволюция (ГЭ) [6; 7] и Push ГП [8; 9]. Эти варианты ГП отличаются представлением решения, гибкостью и возможностями создания целых программ или их частей и часто используются в качестве гиперэвристических средств для автоматического улучшения существующих алгоритмов или даже создания новых с нуля.
Хотя ГП является мощным инструментом для решения многих задач автоматического проектирования, его основным недостатком является низкая вычислительная эффективность, обусловленная огромным пространством комбинаторного поиска. В течение многих лет исследователи предлагали новые операторы селекции, скрещивания и мутации, которые могли бы повысить эффективность поиска ГП, и некоторые из них показывают очень многообещающие результаты. Однако большинство используемых фреймворков ГП используют ту же алгоритмическую структуру, что и классический генетический алгоритм (ГА) [10], т. е. одну популяцию, которая производит потомство, которое затем замещает своих родителей, сохраняя одного элитного индивида. Эта классическая схема известна своей простотой в реализации и, как может показаться, хорошо работает.
Основное внимание в этой статье уделяется изменению классической схемы, используемой в большинстве вариантов ГП, путем изменения схем селекции и замещения. В частности, четыре схемы селекции, две схемы выбора первого родителя и в общей сложности семь схем замещения были протестированы в экспериментах с классическим ГП на основе деревьев на задачах регрессии. Цель исследования – оценить эффективность различных схем селекции родителей и селекции окружающей средой в генетическом программировании. Анализ результатов экспериментов показывает, что широко используемые процедуры управления популяцией могут быть неоптимальными и что заимствование некоторых механизмов из других эволюционных алгоритмов может оказаться полезным.
Полученные результаты показывают, как алгоритм генетического программирования может быть улучшен на практике, при его применении к задачам из различных областей, в том числе аэрокосмической. Так как механизмы селекции не зависят от типа задачи, а только от величин ошибок, то предлагаемые модификации ГП могут быть применены для таких задач, как предсказание деградации солнечных панелей, предсказание параметров антенн или диаграмма направленности, в том числе ширина основного и побочных лепестков. Для последней задачи ГП для символьной регрессии может быть применен в качестве суррогатной модели.
Генетическое программирование на основе деревьев
Классическое генетическое программирование на основе деревьев было предложено Джоном Козой в [1]. Идея этого ГП заключалась в эволюции математических уравнений, а не двоичных строк, как это было в генетическом алгоритме. Уравнения были представлены в виде направленных ациклических графов, т. е. деревьев, где терминальное множество содержало константы и входные переменные, а функциональное множество содержало арифметические операции (+, –, *, /) и элементарные функции (sin, cos, log, exp, ...).
Инициализация решений в ГП выполняется рекурсивным способом. Сначала для стартового узла выбирается тип операции. Если операция бинарная, то создаются два дочерних узла, в противном случае только один. Затем каждый дочерний узел становится либо функциональным, либо терминальным. Если узел является терминальным (конечным узлом), то эта ветвь дальше не растет, в противном случае создается другой узел. Существует два основных метода инициализации, а именно полный метод, при котором конечные узлы размещаются только на определенной максимальной глубине, и метод выращивания, при котором конечные узлы могут размещаться случайным образом вместо функциональных узлов.
Операторы селекции в классическом ГП такие же, как и в ГА, поскольку выбор не зависит от представления решения, т. е. наиболее часто используемыми подходами являются пропорциональная селекция, ранговая селекция и турнирная селекция [11].
Скрещивание является одной из наиболее важных частей ГП. Оно создает потомков путем обмена ветвями между двумя родительскими деревьями, выбранными путем селекции. Если ветви выбираются случайным образом, это называется стандартным скрещиванием. Другой метод, называемый одноточечным пересечением, сначала определяет общую часть двух родительских деревьев, а затем выбирает точку разрыва в общей части.
Мутация также является важной частью ГП и существуют две основные схемы. В первой мутации изменяется один узел, поэтому она называется точечной мутацией. Например, двоичная операция заменяется на другую двоичную операцию, т. е. с + на –, а константа может быть заменена входным значением. Другой метод мутации называется мутацией выращиванием. Он заменяет существующую ветвь или дерево другой, которая выращивается таким же образом, как и при инициализации.
Базовый классический набор операторов, описанный выше, обычно используется для генетического программирования на основе деревьев в большинстве реализаций, хотя они могут отличаться некоторыми деталями. Далее в этой работе мы будем использовать стандартное скрещивание и мутацию на основе выращивания.
Лексикейс селекция и её варианты
Одним из недостатков всех классических схем селекции, таких как пропорциональная, ранговая или турнирная, является то, что они сводят качество индивида к единому показателю пригодности. Когда мы имеем дело с регрессией, классификацией или любым другим типом задач, где пригодность состоит из показателей качества по набору наблюдений, такое обобщение приводит к потере ценной информации о результатах работы данного индивида в каждом конкретном случае. Другими словами, трудно определить, где у индивида хорошие результаты, а где нет, если суммировать все значения ошибок вместе.
В качестве решения этой проблемы была предложена лексикейс селекция [12; 13], в которой учитывается эффективность e t всех индивидов на каждом обучающем примере t в обучающей выборке T. Основные этапы лексикейс селекции для задач классификации приведены ниже:
-
1. C:= множество всех индивидов i в популяции P;
-
2. T’:= случайно перетасованная обучающая выборка T;
-
3. While |T’|>0 и |C|>1:
-
3.1. t:= первый пример из T’
-
3.2. C:= все кандидаты с e t =e t *
-
3.3. Убрать t из T’
-
-
4. Конец while
-
5. Вернуть случайный выбор из множества C
Таким оразом, сначала все индивиды являются кандидатами для селекции и обучающая выборка перетасовывается. Затем наблюдения отбираются одно за другим и все индивиды, у которых значения ошибок превышают наименьшую ошибку et*, отфильтровываются. Если у нас заканчиваются обучающие примеры или кандидаты, цикл while останавливается. В конце, если в C больше одного индивида, один из них выбирается случайным образом.
Для задач регрессии и других непрерывных задач, где случаи не только считаются правильно или неправильно классифицированными, была предложена ε-лексикейс селекция [14; 15]. Она изменяет условие в алгоритме, рассматривая медианное значение в качестве порогового, т. е. остаются кандидаты с ошибкой et<=et*+et. Пороговое значение рассчитывается как et=медиана(|et-медиана(et)|).
В дополнение к ε-лексикейс селекции существует несколько других вариантов, некоторые из которых реализуют стратегии уменьшения размеров выборки. В своей простейшей форме случайная уменьшенная выборка означает, что индивиды оцениваются не по всему набору данных, а по его части, которая случайным образом выбирается из обучающего множества [16; 17]. Обычно выборка пересоздается в каждом поколении. Оценка на меньшей выборке приводит к значительному ускорению всего алгоритма, так как лексикейс селекция работает намного медленнее, чем турнирная или пропорциональная. Тем не менее, поскольку выборка является случайной, вполне вероятно, что даже при больших коэффициентах уменьшения выборки d после нескольких поколений каждый обучающий пример будет использован.
Предлагаемый подход
В большинстве вариантов генетического программирования и реализаций оба родителя выбираются для скрещивания с помощью применяемого в настоящее время механизма селекции. Однако не все эволюционные алгоритмы следуют этой схеме. Например, в дифференциальной эволюции (ДЭ) [18; 19] каждый индивид в популяции получает шанс произвести потомство, т. е. каждый i-й индивид скрещивается с другими индивидами. Это отличается от выбора обоих родителей с помощью селекции, поскольку существует вероятность того, что некоторые индивиды никогда не будут участвовать в скрещивании. Первая модификация в этой работе вводит стратегию «дай шанс каждому» в ГП.
Другой важной частью каждого алгоритма является схема замещения. Как упоминалось во введении, в большинстве исследований используется простейший механизм, при котором родителей заменяют потомством, при этом сохраняется лучший индивид – такая схема известна как стратегия элитарности. Однако такая стратегия может привести к потере потенциально хороших решений, поскольку они могут никогда не получить шанса поучаствовать в скрещивании, поскольку они никогда не были отобраны, а затем просто заменены новыми. В уже упомянутой дифференциальной эволюции каждый потомок каждого индивида сравнивается с ее i-м родителем (i = 1, 2, ... N, N – размер популяции) и замена происходит только в том случае, если потомок лучше. Это делает весь алгоритм гораздо более консервативным в отношении его перемещения в пространстве комбинаторного поиска, поэтому запоминаются только положительные изменения.
Этап замещения можно рассматривать как еще один этап селекции, когда из объединенного набора родителей и потомков должна быть выбрана новая популяция. Один из самых простых альтернативных подходов здесь заключается в том, чтобы просто выбрать лучших из родителей и потомков, т. е. отсортировать их по пригодности и выбрать только первые N, где N – размер популяции. Здесь может быть применен любой другой механизм селекции, например, турнирная селекция, ранговая селекция или пропорциональная селекция, с той лишь разницей, что один и тот же индивид не должен отбираться дважды.
Далее в этой статье будут рассмотрены следующие настройки:
-
1. Механизмы селекции:
-
1.1. Ранговая.
-
1.2. Турнирная.
-
1.3. ε-лексикейс.
-
1.4. ε-лексикейс с уменьшенной выборкой.
-
-
2. Выбор первого родителя:
-
2.1. Текущий i-я индивид.
-
2.2. Та же селекция, что и у второго родителя.
-
-
3. Схема замещения:
-
3.1. Только потомки с копией лучшего родителя.
-
3.2. Попарное сравнение с i-м родителем.
-
3.3. Лучший из родителей и потомков.
-
3.4. Турнирная селекция.
-
3.5. Ранговая селекция.
-
3.6. ε-лексикейс селекция.
-
3.7. ε-лексикейс с уменьшенной выборкой..
-
Это дает в общей сложности 56 различных комбинаций настроек параметров для тестирования.
Результаты
Вариант генетического программирования, используемый в этом исследовании, основан на деревьях, и тестирование проводится на наборе задач регрессии. Наборы данных были взяты из Penn Machine Learning Benchmarks (PMLB) [20], в частности, было выбрано 10 наборов данных для регрессии. Их характеристики приведены в табл. 1.
Таблица 1
Наборы данных из PMLB
|
Название набора данных |
Примеры |
Признаки |
Бинарные признаки |
Непрерывные признаки |
Категориальные признаки |
|
192_vineyard |
52 |
2 |
0 |
0 |
2 |
|
210_cloud |
108 |
5 |
1 |
1 |
3 |
|
522_pm10 |
500 |
7 |
0 |
0 |
7 |
|
557_analcatdata_apnea1 |
475 |
3 |
0 |
2 |
1 |
|
579_fri_c0_250_5 |
250 |
5 |
0 |
0 |
5 |
|
606_fri_c2_1000_10 |
1000 |
10 |
0 |
0 |
10 |
|
650_fri_c0_500_50 |
500 |
50 |
0 |
0 |
50 |
|
678_visualizing_environmental |
111 |
3 |
0 |
0 |
3 |
|
1028_SWD |
1000 |
10 |
1 |
9 |
0 |
|
1089_USCrime |
47 |
13 |
1 |
0 |
12 |
У ГП были следующие настройки. Набор операций включал в себя: +, –, *, /, ln, exp, sqrt, sin, cos, tan, tanh, 1/x, sinh, cosh, abs. Если какая-либо операция давала результат NaN или очень большое число, оно заменялось числовым пределом, установленным в языке C++ для типа данных double. Использовались только стандартное скрещивание и мутация выращиванием. Другие числовые параметры приведены ниже:
-
1. Размер популяции N=100.
-
2. Максимальная глубина при инициализации: MaxD = 5.
-
3. Вероятность завершения ветви при инициализации InitProb = 0,1.
-
4. Генерация констант: по распределению Коши, параметр масштаба равен 5, параметр местоположения равен последней константе.
-
5. Размер турнира T=3.
-
6. Ранговая селекция с экспоненциальным ранжированием и параметром k = 3.
-
7. Максимальное количество узлов в дереве: maxL = 75.
-
8. Вычислительные ресурсы: NFEmax = 100000 вычислений.
-
9. Коэффициент уменьшения выборки d = 5.
-
10. Количество запусков для каждого набора данных NR = 25.
-
11. Показатель пригодности: коэффициент детерминации R2.
Генетическое программирование было реализовано на C++, скомпилировано с помощью GCC и запущено в кластере на базе OpenMPI на 16 компьютерах под управлением Ubuntu 20.04 с процессорами AMD Ryzen 5700X, каждый из которых имеет 8 ядер и 16 потоков. Постобработка результатов была выполнена на Python.
Для сравнения результатов прогонов с различными параметрами были использованы два инструмента, а именно статистический тест Манна – Уитни для попарного сравнения алгоритмов и процедура ранжирования по Фридману для сравнения всех результатов. Процедура ранжирования по Фридману взята из статистического теста Фридмана, и она независимо ранжирует все прогоны всех конфигураций по одной функции, а затем эти ранги суммируются вместе. Табл. 2 содержит сравнение, где обозначения селекции, выбора первого родителя и замещения соответствуют нумерации в предыдущем разделе (например, турнирное замещение – 3.4). Тесты Манна – Уитни (обозначенные как M-W) были выполнены для каждого набора данных независимо, и количество поражений/ничьих/побед показано как x-/y=/z+. Общий Z-счет рассчитывается как сумма Z-распределенных значений, которые были использованы в нормальном приближении U-статистики Манна – Уитни. Пороговое значение уровня значимости было установлено равным p = 0,01. В табл. 2 в качестве исходного был выбран прогон с номером 45, поскольку он продемонстрировал наилучшие результаты (ε-лексикейс селекция, текущий i-й индивид, попарное сравнение с i-м родителем).
Таблица 2
Сравнение 56 протестированных конфигураций алгоритма
|
# |
Селекция |
Первый родитель |
Замещение |
Тест M-W |
Z-счет |
Ранг по Фридману |
|
1 |
1.1 |
2.1 |
3.1 |
10-/0=/0+ |
–43.64 |
389.16 |
|
2 |
1.1 |
2.1 |
3.2 |
0-/10=/0+ |
–19.01 |
160.32 |
|
3 |
1.1 |
2.1 |
3.3 |
1-/9=/0+ |
–16.47 |
134.44 |
|
4 |
1.1 |
2.1 |
3.4 |
10-/0=/0+ |
–45.33 |
433.96 |
|
5 |
1.1 |
2.1 |
3.5 |
10-/0=/0+ |
–45.67 |
445.88 |
|
6 |
1.1 |
2.1 |
3.6 |
10-/0=/0+ |
–46.22 |
446.72 |
|
7 |
1.1 |
2.1 |
3.7 |
10-/0=/0+ |
–33.61 |
227.16 |
|
8 |
1.1 |
2.2 |
3.1 |
10-/0=/0+ |
–42.05 |
376.88 |
|
9 |
1.1 |
2.2 |
3.2 |
9-/1=/0+ |
–30.50 |
226.92 |
|
10 |
1.1 |
2.2 |
3.3 |
1-/9=/0+ |
–19.42 |
157.12 |
|
11 |
1.1 |
2.2 |
3.4 |
10-/0=/0+ |
–45.73 |
443.32 |
|
12 |
1.1 |
2.2 |
3.5 |
10-/0=/0+ |
–46.22 |
452.92 |
|
13 |
1.1 |
2.2 |
3.6 |
10-/0=/0+ |
–45.91 |
442.78 |
|
14 |
1.1 |
2.2 |
3.7 |
10-/0=/0+ |
–34.56 |
241.08 |
|
15 |
1.2 |
2.1 |
3.1 |
10-/0=/0+ |
–39.95 |
343.92 |
|
16 |
1.2 |
2.1 |
3.2 |
0-/10=/0+ |
–16.10 |
135.72 |
|
17 |
1.2 |
2.1 |
3.3 |
0-/10=/0+ |
–14.36 |
123.28 |
Окончание табл. 2
|
# |
Селекция |
Первый родитель |
Замещение |
Тест M-W |
Z-счет |
Ранг по Фридману |
|
18 |
1.2 |
2.1 |
3.4 |
10-/0=/0+ |
–46.12 |
443.20 |
|
19 |
1.2 |
2.1 |
3.5 |
10-/0=/0+ |
–45.93 |
449.36 |
|
20 |
1.2 |
2.1 |
3.6 |
10-/0=/0+ |
–45.93 |
443.46 |
|
21 |
1.2 |
2.1 |
3.7 |
10-/0=/0+ |
–33.74 |
232.56 |
|
22 |
1.2 |
2.2 |
3.1 |
10-/0=/0+ |
–40.94 |
345.80 |
|
23 |
1.2 |
2.2 |
3.2 |
9-/1=/0+ |
–30.48 |
230.80 |
|
24 |
1.2 |
2.2 |
3.3 |
3-/7=/0+ |
–23.26 |
179.36 |
|
25 |
1.2 |
2.2 |
3.4 |
10-/0=/0+ |
–45.23 |
436.36 |
|
26 |
1.2 |
2.2 |
3.5 |
10-/0=/0+ |
–45.60 |
440.52 |
|
27 |
1.2 |
2.2 |
3.6 |
10-/0=/0+ |
–45.73 |
445.72 |
|
28 |
1.2 |
2.2 |
3.7 |
10-/0=/0+ |
–34.19 |
234.94 |
|
29 |
1.3 |
2.1 |
3.1 |
10-/0=/0+ |
–38.59 |
339.08 |
|
30 |
1.3 |
2.1 |
3.2 |
0-/10=/0+ |
–15.60 |
134.32 |
|
31 |
1.3 |
2.1 |
3.3 |
0-/10=/0+ |
–12.44 |
106.72 |
|
32 |
1.3 |
2.1 |
3.4 |
10-/0=/0+ |
–45.87 |
446.56 |
|
33 |
1.3 |
2.1 |
3.5 |
10-/0=/0+ |
–45.40 |
439.80 |
|
34 |
1.3 |
2.1 |
3.6 |
10-/0=/0+ |
–47.15 |
457.00 |
|
35 |
1.3 |
2.1 |
3.7 |
10-/0=/0+ |
–33.39 |
238.92 |
|
36 |
1.3 |
2.2 |
3.1 |
10-/0=/0+ |
–41.44 |
380.08 |
|
37 |
1.3 |
2.2 |
3.2 |
10-/0=/0+ |
–36.57 |
276.88 |
|
38 |
1.3 |
2.2 |
3.3 |
0-/10=/0+ |
–15.81 |
131.16 |
|
39 |
1.3 |
2.2 |
3.4 |
10-/0=/0+ |
–45.77 |
436.08 |
|
40 |
1.3 |
2.2 |
3.5 |
10-/0=/0+ |
–45.50 |
441.60 |
|
41 |
1.3 |
2.2 |
3.6 |
10-/0=/0+ |
–45.98 |
437.76 |
|
42 |
1.3 |
2.2 |
3.7 |
10-/0=/0+ |
–34.15 |
231.88 |
|
43 |
1.4 |
2.1 |
3.1 |
8-/2=/0+ |
–28.62 |
165.28 |
|
44 |
1.4 |
2.1 |
3.2 |
0-/10=/0+ |
–2.79 |
39.72 |
|
45 |
1.4 |
2.1 |
3.3 |
0-/10=/0+ |
0.00 |
34.08 |
|
46 |
1.4 |
2.1 |
3.4 |
10-/0=/0+ |
–34.46 |
235.60 |
|
47 |
1.4 |
2.1 |
3.5 |
10-/0=/0+ |
–34.11 |
239.08 |
|
48 |
1.4 |
2.1 |
3.6 |
10-/0=/0+ |
–33.49 |
228.68 |
|
49 |
1.4 |
2.1 |
3.7 |
10-/0=/0+ |
–33.66 |
231.04 |
|
50 |
1.4 |
2.2 |
3.1 |
8-/2=/0+ |
–29.41 |
169.08 |
|
51 |
1.4 |
2.2 |
3.2 |
0-/10=/0+ |
–19.44 |
94.20 |
|
52 |
1.4 |
2.2 |
3.3 |
0-/10=/0+ |
–3.63 |
44.28 |
|
53 |
1.4 |
2.2 |
3.4 |
10-/0=/0+ |
–33.86 |
232.62 |
|
54 |
1.4 |
2.2 |
3.5 |
10-/0=/0+ |
–34.38 |
232.60 |
|
55 |
1.4 |
2.2 |
3.6 |
10-/0=/0+ |
–32.81 |
227.44 |
|
56 |
1.4 |
2.2 |
3.7 |
10-/0=/0+ |
–33.66 |
224.80 |
Обсуждение результатов
Три наилучшие комбинации параметров в табл. 2 выделены серым цветом, а именно комбинации 44, 45 и 52. Как видно, все они имеют один и тот же механизм селекции – ε-лексикейс селекция с уменьшенной выборкой, а все остальные варианты имеют гораздо более низкую производительность. Что касается выбора первого родителя, то в двух из трех лучших вариантах использовался выбор i-го индивида, что давало каждому из них шанс произвести потомство. Наконец, схема замены в лучших вариантах – это либо попарное сравнение с i-м родителем, либо лучшие из родителей и потомков.
Другими словами, эти результаты показывают, что генетическое программирование работает намного лучше, если изменить типичную алгоритмическую структуру на ту, которая используется в дифференциальной эволюции. Чтобы сравнить другие операторы между собой, на рис. 1 показаны гистограммы суммарных рангов Фридмана для каждого типа селекции, выбора первого родителя и замещения.
Как показано на рис. 1, в целом, нет большой разницы между результатами ранговой, турнирной и ε-лексикейс селекции, однако ε-лексикейс с уменьшенной выборкой работает намного лучше. Что касается выбора первого родителя, то существует разница между классической схемой, где он выбирается с помощью используемого в данный момент оператора выбора и выбором по индексу. Схемы замещения, по-видимому, сильно отличаются и сильно влияют на конечную производительность. В частности, схема «лучший из родителей и потомков» значительно превосходит все другие методы, за которыми следует попарное сравнение. ε-лексикейс селекция с уменьшенной выборкой дает лучшие результаты, чем остальные методы, а широко используемый вариант «потомки плюс копия лучшего родителя» значительно хуже.
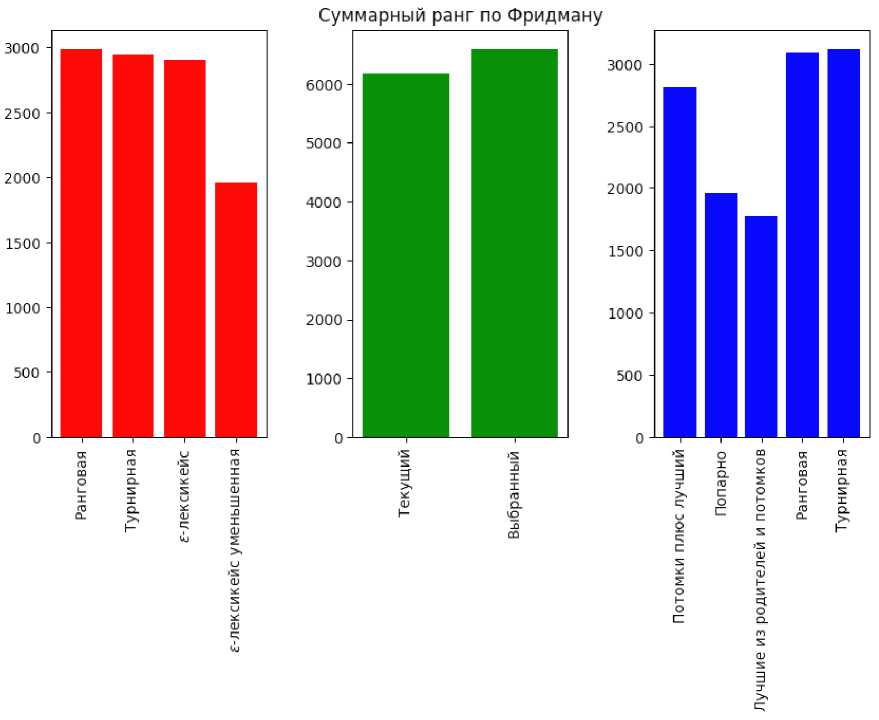
Рис. 1. Столбчатая диаграмма сумм рангов по Фридману для всех типов протестированных операторов
Fig. 1. Bar plot of sums of Friedman ranks for all types of tested operators
Чтобы лучше понять причины, по которым определенные схемы замещения работают лучше, на рис. 2 показан пример, где первые два столбца – это популяция и их потомки, где пригодность показана цветами (чем меньше, тем лучше), а остальные четыре – результаты различных механизмов замещения. Как можно видеть, лучшие из родителей и потомков, сокращенно называемые «элитой», просто копируют всех потомков и заменяют одного из них лучшим родителем. Это приводит к быстрой смене поколений, но может привести к потере хороших решений. С другой стороны, попарное сравнение позволяет выделить наилучший вариант каждого решения из популяции и потомства, что приводит к более стабильному, хотя и медленному прогрессу.
При сортировке просто отбираются лучшие участники из обеих групп и отбрасываются все остальные. Как показали эксперименты, это, как правило, очень эффективная стратегия. В последнем столбце приведена турнирная селекция, но в других, таких как ранговая или лек-сикейс, будет аналогичная картина. Как можно видеть, при турнирной селекции иногда могут быть выбраны плохие решения и упущены лучшие, что приводит к неоптимальному прогрессу.
|
Популяция Потомки |
Элита |
Попарно Сортировка Турнир |
|||
|
1.00 |
0.33 |
0.00 |
0.33 |
0.00 |
0.92 |
|
0.13 |
■ 1.00 |
1.00 |
0.13 |
0.00 |
0.13 |
|
0.19 |
0.32 |
0.32 |
0.19 |
0.13 |
0.19 |
|
0.59 |
0.33 |
0.33 |
0.33 |
0.19 |
0.59 |
|
0.84 |
0.60 |
0.60 |
0.60 |
0.32 |
0.84 |
|
0.00 |
0.85 |
0.85 |
0.00 |
0.33 |
0.00 |
|
0.92 |
0.00 |
0.00 |
0.00 |
0.33 |
0.92 |
Рис. 2. Пример работы стратегий замещения
Рис. 2. Example of replacement strategies operation
Заключение
Эксперименты, проведенные в этой работе, показали, что обычно используемая схема управления популяцией в генетическом программировании является неоптимальной. Процедура замещения играет решающую роль в производительности алгоритма, и многие исследователи часто упускают ее из виду. Использование простых стратегий, таких как попарное сравнение, в сочетании с выбором первого родителя в качестве текущего i-го индивида значительно повышает производительность алгоритма генетического программирования.
Однако у этого исследования есть несколько ограничений. Здесь основное внимание уделялось решению задач регрессии и другие типы задач, такие как регрессия, управление или синтез программ, не тестировались. Тем не менее ожидается, что аналогичные тенденции должны наблюдаться и для других классов задач, поскольку селекция не зависит от типа решаемой задачи – она зависит только от значений ошибок, но это должно быть тщательно проверено в ходе дальнейших исследований.
