Сравнительный анализ состязательных методов для нетематической классификации текстов

Автор: Лепехин М.Н., Шаров С.А.
Журнал: Программные системы: теория и приложения @programmnye-sistemy
Рубрика: Искусственный интеллект и машинное обучение
Статья в выпуске: 1 (70) т.17, 2026 года.
Бесплатный доступ
Нетематическая классификация текстов широко используется в современных приложениях. Одной из проблем, возникающих при решении этой задачи, является наличие смещений в распределении в тренировочных текстовых корпусах. Наиболее существенным видом смещений являются тематические смещения. Для решения этой проблемы в данной работе применяются состязательные методы - Adversarial Domain Adaptation, Energy-based ADA, BERT с контрастной функцией потерь и ADA с контрастной функцией потерь. В работе впервые производится модификация контрастной функции потерь для снижения влияния тематических сдвигов и показывается, что использование состязательных методов повышает точность и надежность классификаторов для задачи определения пола автора текста. Также проводятся эксперименты с LLaMA-3B и показано, что большие языковые модели достигают в режиме few-shot более низкую точность чем дообученные модели с меньшим числом параметров, и требуют больше времени для предсказания.
Состязательные методы, контрастная функция потерь, классификация гендера, классификация текстов, нетематическая классификация, bert, доменная адаптация
Короткий адрес: https://sciup.org/143185570
IDR: 143185570 | УДК: 004.89:004.93 | DOI: 10.25209/2079-3316-2026-17-1-57-84
Comparative Analysis of the Adversarial Methods For Non-Topical Classification of Texts
Non-topical text classification is widely used in modern applications. One of the issues related to this problem is the presence of biases and shifts in the distribution in the training text datasets. The most significant type of shift is the topical shift. To handle this issue we apply competitive methods such as Adversarial Domain Adaptation, Energy-based ADA, BERT with contrast loss function, ADA with contrast loss function. In this paper, we first modify the contrast loss function to reduce the influence of thematic shifts and show that the use of adversarial methods improves the accuracy and reliability of classifiers for the task of determining the gender of the author of a text. We also apply LLaMA-3B and show that the large language models attain lower accuracy in the few-shot mode and require more time for prediction than the pre-trained models based on smaller architectures.
Текст научной статьи Сравнительный анализ состязательных методов для нетематической классификации текстов
Нетематическая классификация текстов охватывает широкий спектр задач, направленных на выявление свойств текста, не связанных напрямую с его тематикой. К таким задачам относятся определение стиля, уровня сложности, эмоциональной окраски, вежливости, а также социолингвистических характеристик автора (возраст, пол, родной язык и др.). Решения подобных задач важны для информационного поиска, адаптивных образовательных систем, лингвистических исследований, рекомендательных систем и других областей.
В отличие от тематической классификации, где целевой признак часто коррелирует с набором ключевых слов, нетематические свойства являются более абстрактными и не определяются непосредственно по лексическому составу. Это создаёт дополнительные трудности для классификации. В частности, модели оказываются чувствительны к сдвигам распределения , особенно к тематическим сдвигам [1] .
Тематический сдвиг возникает, когда в обучающих данных существует нежелательная корреляция между целевым признаком и тематикой текстов (например, спортивные тексты чаще написаны авторами-мужчинами). В таких условиях модель начинает опираться на тематические маркеры, что приводит к значительной деградации качества на данных с иной тематической структурой [2] .
Для повышения устойчивости моделей к доменным и тематическим сдвигам используются методы, направленные на обучение доменноинвариантных признаков. Одним из наиболее перспективных подходов является состязательная доменная адаптация (Adversarial Domain Adaptation, ADA) [3] , позволяющая извлекать характеристики текста, не зависящие от источника данных. Её улучшенная версия — метод Energy-based ADA (EADA) [4] — использует энергетическую функцию и специальную функцию потерь для выравнивания распределений между доменами, снижая влияние доменных различий.
Другой класс подходов — методы контрастного обучения [5] , формирующие более компактные и разделимые представления целевых классов. Несмотря на доказанную эффективность этих методов для повышения общей точности классификации [6 , 7] , их потенциал для уменьшения влияния тематических сдвигов в задачах нетематической классификации остаётся недостаточно изученным.
Параллельно с развитием специализированных архитектур стремительно совершенствуются большие языковые модели (LLM), такие как LLaMA [8], GPT-4 [9] и DeepSeek [10]. Они демонстрируют высокую эффективность в решении широкого круга задач без явного дообучения [11,12]. Однако их вычислительная дороговизна и задержки выполнения делают необходимым сопоставление их возможностей с более компактными моделями на основе BERT в контексте нетематической классификации.
Постановка задачи. Цель данной работы — разработать и экспериментально оценить методы, устойчивые к тематическим сдвигам, для задач нетематической классификации текстов. Особое внимание уделяется снижению зависимости качества моделей от домена (источника данных) и анализу того, в какой степени различные подходы позволяют уменьшить влияние тематических корреляций в обучающих данных.
Основной вклад работы заключается в следующем:
(1) Демонстрируется высокая чувствительность моделей на основе BERT к тематическим сдвигам и источнику данных (Раздел 6.1);
(2) предлагается модификация контрастной функции потерь, направленная на более эффективное подавление влияния тематических сдвигов;
(3) впервые для задачи нетематической классификации текстов исследуется совместное применение ADA и контрастной функции потерь;
(4) Проводится сравнение дообучаемых моделей меньшего размера с большой языковой моделью LLaMA-3B-Instruct в режиме fewshot; показывается, что LLM уступает дообучаемым моделям по качеству и времени выполнения в задаче классификации пола автора (Раздел 6.3).
2. Связанные исследования
Настоящее исследование существенно расширяет и углубляет результаты работы [13] , включая эксперименты с контрастным обучением, его комбинацией с ADA, а также расширенный анализ с использованием современных больших языковых моделей.
Задача классификации текстов является одной из наиболее важных и часто возникающих в обработке естественного языка. Долгое время архитектура BERT [14] и её производные (например, XLM-RoBERTa [15] ) служили основой для многих современных моделей классификации [16] . В данной работе BERT используется в качестве базовой архитектуры для всех сравниваемых методов.
Проблема доменной адаптации тесно связана с задачами классификации, особенно в условиях сдвигов распределения данных. Для нетематической классификации, где целевые признаки слабо выражены на лексическом уровне, устойчивость к таким сдвигам приобретает критическое значение. В литературе можно выделить несколько основных подходов к решению этой проблемы.
Методы, основанные на модификации эмбеддингов. Ряд работ предлагает напрямую корректировать векторные представления слов. Например, в исследовании [17] предлагается выявлять и модифицировать эмбеддинги слов, специфичных для определённой предметной области ( weird words ). Несмотря на простоту и эффективность в рамках конкретного домена, этот подход требует предварительного знания ключевых слов и не решает общей задачи создания классификатора, устойчивого к любым тематическим сдвигам.
Состязательные методы доменной адаптации (ADA). Классический подход Adversarial Domain Adaptation [3] и его развитие — Energy-based ADA (EADA) [4] — используют состязательное обучение для извлечения признаков, инвариантных к домену. Однако в оригинальных работах эти методы применялись преимущественно для задачи переноса знаний из домена с большим количеством размеченных данных в домен с малым их количеством. Наша работа фокусируется на иной цели: минимизации влияния доменных (в частности, тематических) признаков на классификацию внутри одного набора данных, что позволяет снизить чувствительность модели к доминирующему источнику в обучающей выборке.
Методы с мета-обучением. Исследование [18] интегрирует метаобучение с ADA, вводя дополнительный модуль — генератор метазнаний на основе BiLSTM. Целью является не только улучшение классификации, но и максимальное «запутывание» дискриминатора домена. Однако данная работа сфокусирована на задачах тематической классификации (анализ тональности, категоризация новостей), в то время как мы исследуем более сложный случай нетематической классификации.
Контрастное обучение. Методы, основанные на контрастных функциях потерь [5] , направлены на формирование компактных кластеров в пространстве признаков для объектов одного класса. В нашей работе мы используем этот подход, но вносим ключевые модификации: добавляем механизм для сближения эмбеддингов текстов из разных предметных областей (доменов) при совпадении целевого класса, а также применяем нормирование контрастной функции потерь. Это позволяет напрямую бороться с тематическими сдвигами, а не только повышать общую разделимость классов.
Каузальные модели. Подходы, основанные на каузальном выводе, такие как CausaLM [19] и CausalNLP [20], направлены на выявление и устранение влияния конфаундеров — признаков, создающих ложные зависимости между переменными. В отличие от оригинальных работ, где основной целью является оценка значимости признаков или анализ причинно-следственных связей, мы используем каузальную функцию потерь из [19] для прямой максимизации точности классификации, заставляя модель уделять меньше внимания конфаундерам (тематическим признакам).
Большие языковые модели (LLM). С появлением моделей типа GPT-4 [9] , Gemini [21] и LLaMA [8] значительно возрос потенциал решения задач без явного дообучения [22] . Однако их использование сопряжено с высокими вычислительными затратами и ограничениями на доступ. В нашей работе мы исследуем более экономичный вариант — модель LLaMA-3.1-3B-Instruct в режиме few-shot, — чтобы оценить, насколько современные LLM способны решать задачу нетематической классификации без дополнительной тонкой настройки, и сравнить их с дообученными моделями меньшего размера.
Таким образом, существуют различные подходы к повышению устойчивости моделей классификации: модификация эмбеддингов, состязательная доменная адаптация, мета-обучение, контрастное и каузальное обучение. Однако многие из них либо не ориентированы специально на борьбу с тематическими сдвигами в нетематической классификации, либо требуют априорных знаний о доменах, либо фокусируются на других типах задач (тематическая классификация, анализ тональности). Недостаточно изученным остаётся совместное применение и адаптация этих методов для прямой минимизации влияния доминирующего источника данных на качество классификации.
В нашей работе мы систематически применяем ADA, EADA и контрастное обучение и исследуем их эффективность для решения именно этой задачи.
3. Методология
Состязательные и контрастные функции потерь показали свою эффективность в ряде задач, включая доменную адаптацию и классификацию текстов. Во всех методах, рассматриваемых далее, особое внимание уделяется тому, каким образом они способны снижать влияние сдвигов в распределении между обучающим и тестовым доменами. Под тематическими сдвигами подразумеваются изменения распределений тематик текстов между двумя источниками данных (например, различия между блогами Mail.Ru, содержащими тексты на самые разные темы, и
AWD с преобладанием текстов о путешествиях). Механизмы подавления доменных различий представлены в описании каждого метода.
-
3.1. Состязательная адаптация домена (ADA)
Метод ADA (Adversarial Domain Adaptation [3] ) изначально был разработан для решения задачи доменной адаптации и относится к задаче адаптации домена без учителя (Unsupervised Domain Adaptation, UDA) [23] . В постановке задачи адаптации домена без учителя есть исходный домен с большим числом размеченных примеров и целевой домен с отсутствующими или крайне малочисленными метками и требуется обучить модель таким образом, чтобы она смогла показывать достаточную точность на целевом домене. Данный метод показывает высокую эффективность в задачах обработки естественного языка, включая случаи значительного различия тематик между доменами [3] .
В доменной адаптации предполагается обучение модели на размеченных текстах исходного домена (X s , Y s ) для применения на целевом домене (X t ,Y t ).
Модель ADA состоит из извлекателя признаков f = G f (x), классификатора целевого класса y = G y (x) и доменного дискриминатора d = G d (x). Дискриминатор пытается отличить тексты по происхождению, а извлекатель признаков — извлекать такие признаки, по которым это сделать сложно. Обучение формулируется как состязательный процесс: (1) min L y (X s ,Y s ) - ^L f (X s ,X t )
G f ,G y
-
(2) min L d (X s ,X t ).
-
3.2. Состязательная адаптация домена на основе энергии (EADA)
G d
Компонента L f уменьшает различимость доменов в скрытом представлении. Тем самым ADA стремится сделать признаки инвариантными к предметной области .
В качестве извлекателя признаков используется BERT: классификатор и дискриминатор — полносвязные слои с активацией ReLU [24] . Гиперпараметр X ada > 0 управляет степенью подавления доменной информации.
В нашей работе решается не задача доменной адаптации, а проблема снижения влияния тематических сдвигов. Поэтому важным отличием по сравнению с исходным методом ADA является то, что мы используем в обучении целевые метки обоих доменов.
Состязательный механизм делает скрытые представления нечувствительными к источнику данных. Это уменьшает зависимость классификатора от доменных маркеров (лексики, специфической для источника, стиля), что важно при наличии сильного распределительного сдвига. Поскольку тема текста часто является сильным доменным маркером, дискриминатор вынуждает извлекатель признаков подавлять тематическую информацию. Таким образом, классификация становится менее зависимой от тематического контекста и более устойчивой к различиям в темах между Mail.Ru и AWD.
Energy-based Adversarial Domain Adaptation (EADA) [4] является улучшенной версией метода ADA. EADA оптимизирует значение энергетической функции , характеризующей различие между доменами: автоэнкодер усиливает различия, а извлекатель признаков их подавляет, что приводит к более стабильному и гладкому распределению признаков. Это улучшает переносимость модели между доменами. В нашей постановке задачи это может сделать модели менее чувствительными к тематическим смещениям и повысить переносимость модели на другие источники.
Тематические различия между доменами проявляются в структуре текстовых эмбеддингов. Извлекатель признаков в EADA вынужден формировать такие эмбеддинги, которые не содержат устойчивых тематических сигналов , поскольку автоэнкодер их постоянно выделяет. Это уменьшает зависимость классификатора от тематики текстов и снижает проседание качества при смене тем.
Модель EADA включает классификатор целевого класса и автоэнкодер. Оптимизация записывается следующим образом:
-
(3) min L ce (X s ,Y s )+ XL ae (X t ),
G f ,G y
-
(4) min ( L ae (X s ) + max(0,m - L ae (X t )) ) .
-
3.3. Контрастная функция потерь (Contrastive Loss)
G a
Автоэнкодер G a стремится усиливать различия между эмбеддингами исходного и целевого доменов, в то время как извлекатель признаков G f пытается их уменьшить, обеспечивая сохранение информации, необходимой для классификации.
Гиперпараметр λ ADA задаёт силу штрафа за доменно-специфические признаки, а параметр m определяет минимальную степень отделимости представлений доменов в пространстве автоэнкодера.
Другим важным и потенциально эффективным методом является контрастная функция потерь [5]. Она устроена таким образом, что стимулирует модель к сближению эмбеддингов текстов с одинаковыми целевыми метками.
Пусть P(i) — индексы текстов той же метки, что и x i . Функция потерь:
Lci = Е i∈I
-1 , exp(z i • z p /t )
|P(i)| ^ EaeA(i) exP(zi • Za/T) , а итоговая функция потерь имеет вид:
-
(6) L total = (1 — ^ Cb )L ce + ^ CL L cl .
В работе вводятся изменения:
• семплирование позитивных примеров только с противоположным значением конфаундера, чтобы стимулировать объединение по целевой метке вне зависимости от источника или темы;
• нормировка Lcl для стабилизации обучения.
3.4. ADA + контрастная функция потерь
3.5. Эксперименты с LLaMA 3.2 3B Instruct
4. Эксперименты
Мотивация заключается в том, чтобы сделать эмбеддинги текстов с разными значениями конфаундера максимально близкими друг к другу при условии совпадения значений целевого класса. Чем более похожими становятся эмбеддинги текстов с разными значениями конфаундера, тем сложнее восстановить значение конфаундера из признакового пространства, выученного нейронной сетью. Таким образом, данная модификация контрастной функции потерь должна способствовать снижению влияния тематических сдвигов на предсказание целевого класса.
ADA и контрастная функция потерь по-своему полезны для уменьшения влияния тематических сдвигов. При этом актуальным является вопрос о том, насколько эти методы эффективны при совместном применении. Для этого проводятся эксперименты с комбинированной функцией потерь: (7) L total = ^ cl L cl + (1 — ^ cC tL ada .
Контрастная часть сближает элементы одного класса, а ADA делает признаки доменно-инвариантными, обеспечивая двойную регуляризацию. ADA подавляет тематические сигналы как доменные особенности, а контрастная функция потерь делает похожими эмбеддинги текстов с одинаковым значением целевой метки, даже если темы различаются. В сочетании это может быть особенно эффективно против тематических сдвигов.
Также проводятся эксперименты с LLaMA 3.2 3B Instruct [8]. Эта модель обладает значительно большей обобщающей способностью за счёт приблизительно 3 миллиардов параметров.
Крупные языковые модели обладают высокой степенью доменной обобщаемости. Эксперименты позволяют проверить, насколько одного лишь проектирования промптов (инструкций) достаточно для подавления тематических эффектов без доменной адаптации.
Основная цель экспериментов — выяснить, может ли LLaMA обеспечивать устойчивость к тематическим сдвигам просто за счёт составления промптов без дополнительного обучения. Пример промпта (инструкции) на английском языке приведён в подразделе 6.3.
Основной метрикой для сравнения моделей в данной работе является точность (accuracy).
Целью данного исследования является обучение надежного классификатора для пола автора текста, для которого изменение предметной области по сравнению с обучающим набором данных как можно меньше ухудшало бы точность модели.
Для этого наборы данных Блоги Mail.Ru и AWD табл. 1 разбиваются в соотношении 4:1 на тренировочную и тестовую часть. Обучение проводилось на наборе данных, полученном сэмплированием а% текстов из тренировочной части Блогов Mail.Ru и (100 — а)% текстов из AWD. Тестовая часть из каждого источника данных используется для оценки качества моделей. Для того, чтобы рассмотреть поведение моделей и в случае преобладания Mail.Ru и в случае преобладания AWD в тренировочном множестве текстов, используются а = 25, 75, 90.
Для оценки моделей вычисляется:
-
• точность текстов из источника, преобладающего в тренировочном наборе данных;
-
• точность текстов из недостаточно представленного источника данных;
-
• Определим разницу в точности текстов из источника данных, преобладающего в обучающем наборе данных, и текстов из источника данных, недостаточно представленных в тренировочном наборе данных, как разница в точности. Обозначим её 5.
Параметр 5 показывает, насколько снижается точность классификации при тестировании на текстах из источника, мало представленного в обучении. По своей сути, это значение является метрикой для оценки эффекта тематических сдвигов в источнике текста, преобладающем в обучающем наборе данных.
В рамках экспериментов, обучаются модели на основе BERT с применением алгоритмов ADA, EADA, Contrastive Loss, Contrastive Loss + ADA и CausaLM. Используется многоязычный BERT с базовой конфигурацией (12 слоев, 768 скрытых элементов, 12 голов, 125 миллионов параметров, google-bert/bert-base-многоязычный интерфейс в оболочке HuggingFace) в качестве основы для всех экспериментов. Во всех экспериментах используется learning rate=10 -5 , поскольку это значение предложено в [16] и [4] .
Для экспериментов с контрастной функцией потерь и её комбинацией с ADA используются те же самые параметры архитектуры.
Но для уменьшения числа экспериментов, при подборе оптимальных значений λ CL и λ ADA для контрастной функции потерь и ADA+CL фиксируются значения следующих гиперпараметров:
• τ = 0.5;
• K = 5;
• стратегия отбора проб — взятие K случайных положительных примеров.
5. Данные
После нахождения оптимальных значений λ CL и λ ADA производится перебор τ ∈ [0.25, 0.5, 0.75] и K ∈ [3, 5, 7, 9].
Классификация пола автора текста это нетематическая классификация, поскольку целевой классификационной переменной является не тема или тематический признак, а более сложное понятие, которое невозможно описать с помощью определенных ключевых слов.
В таблице 1 показано распределение по полу и длине текста. Здесь и далее L 10% — 10-й перцентиль длин, L ср — среднее арифметическое длин, L median — медиана длин.
Таблица 1. Наборы данных для обучения и тестирования классификаторов с указанием распределения длин
|
Источник |
#M |
#W |
L ср |
L 10% |
L 25% |
L median |
L 75% |
L 90% |
|
|
3236 |
6764 |
217 |
71 |
83 |
115 |
188 |
370 |
|
AWD |
5984 |
4016 |
84 |
13 |
21 |
39 |
76 |
144 |
Во всех экспериментах берутся 8000 примеров для обучения и 2000 текстов для тестирования. И Блоги Mail.Ru и AWD являются российскими платформами социальных сетей. Однако их контент и целевая аудитория различаются. Mail.Ru Blogs — это универсальная платформа, которая включает в себя широкий спектр тем, включая спорт, политику, технологии, здравоохранение, науку, туризм и так далее. В то же время, AWD — это платформа о туризме. Это приводит к значительным тематическим сдвигам в наборе данных AWD.
Эти наборы данных имеют эталонные метки для половой принадлежности авторов текстов, поскольку пол указывается самими пользователями платформ.
6. Результаты 6.1. Предсказание источника данных для текста
Сопоставим источникам данных mail.ru и awd бинарную метку: awd = 0, mail = 1. Номер источника данных (mail или awd) используется в качестве искажающего фактора как для состязательных методов, так и для каузальных моделей. Чтобы убедиться, что распределение текстов в этих двух источниках данных существенно отличается, проведен ряд экспериментов с классификаторами источника текста.
Результаты экспериментов показывают, как на точность исходных классификаторов влияет доля источников данных в тренировочном наборе данных. Многоязычные классификаторы BERT обучены на наборах данных, содержащих α = 10, 25, 50 и 75 процентов текстов Mail.Ru. Таблица 2 показывает, что вне зависимости от доли текстов из блогов Mail.Ru в обучении точность классификатора источника текста превышает 90%.
|
α |
точность |
|
25 |
0.901 |
|
50 |
0.931 |
|
75 |
0.920 |
|
90 |
0.905 |
Это означает, что тексты в Mail.Ru и AWD сильно отличаются, и даже базовый BERT без применения каких-либо дополнительных методов и алгоритмов способен заметить разницу между ними. Предполагается, что это обусловлено тематическими смещениями в AWD, вызванными специализацией этого веб-сайта. Различия показывают уязвимость базовой модели BERT к такого рода тематическим сдвигам.
-
6.2. Дообучение состязательных моделей
Разница δ между точностью на текстах из источника данных, преобладающего в обучении, и точностью на источнике данных с недостаточным представлением используется в качестве второго ключевого показателя для оценки уязвимости модели к тематическим сдвигам в тестовых данных.
Наши эксперименты показали, что ADA помогает уменьшить разницу в точности между тестированием на текстовом источнике, преобладающем в тренировочном наборе данных, и тестированием на текстах из недостаточно представленного источника. Увеличение значения гиперпараметра λ ADA соответствует уменьшению значения δ. При этом точность на текстах из тестового набора данных для источника, преобладающего в тренировочном наборе данных, снижается, в то время как точность на текстах из недопредставленного источника увеличивается, что делает модели более устойчивыми к изменениям предметной области.
Зависимость эффективности метода CausaLM от λ ADA оказалась аналогична зависимости для состязательных методов: чем выше значение λ ADA , тем ниже значение δ и тем выше точность на текстах из источника, недостаточно представленного в тренировочных данных. Хотя при этом CausaLM обеспечил меньшую разницу δ, чем состязательные методы, но снижение точности на текстах из чрезмерно представленного источника оказалось более значительным, чем для метода ADA.
Оказалось, что точность на текстах из Mail.Ru выше, чем на текстах из AWD, даже когда в обучении преобладает AWD (α = 25). Это вызвано большей средней длиной текстов из Mail.Ru, поскольку длина текста влияет на точность моделей, основанных на архитектуре Трансформер. В этом случае значение δ становится отрицательным и менее информативным, чем прямая оценка точности на текстах из источника, недостаточно представленного в обучающей выборке.
Таблица 3. Результаты экспериментов (accuracy);
наилучшие значения выделены жирным , вторые по величине — курсивом
|
Метод |
λ ADA |
точность, mail |
точность, awd |
δ |
|||||
|
α=75 |
α = 90 |
α = 75 |
α = 90 |
α = 75 |
α=90 |
||||
|
BERT |
0 |
0.838 |
0.716 |
0.122 |
|||||
|
CausaLM |
0.05 |
0.785 |
0.725 |
0.060 |
|||||
|
CausaLM |
0.2 |
0.781 |
0.728 |
0.054 |
|||||
|
ADA |
0.05 |
0.830 |
0.725 |
0.105 |
|||||
|
ADA |
0.2 |
0.825 |
0.731 |
0.094 |
|||||
|
ADA |
0.5 |
0.815 |
0.719 |
0.096 |
|||||
|
EADA, m=2 |
0.05 |
0.819 |
0.688 |
0.131 |
|||||
|
EADA, m=2 |
0.2 |
0.819 |
0.673 |
0.146 |
|||||
|
EADA, m=4 |
0.05 |
0.819 |
0.692 |
0.127 |
|||||
|
EADA, m=4 |
0.2 |
0.815 |
0.685 |
0.130 |
|||||
|
EADA, m=8 |
0.05 |
0.832 |
0.694 |
0.138 |
|||||
|
EADA, m=8 |
0.2 |
0.823 |
0.685 |
0.138 |
|||||
|
CL, |
λ CL |
= 0.05 |
0.810 |
0.722 |
0.088 |
||||
|
CL, |
λ CL |
= 0.2 |
0.800 |
0.722 |
0.078 |
||||
|
CL, |
λ CL |
= 0.2 |
0.800 |
0.726 |
0.074 |
||||
|
ADA + CL, |
λ CL |
= 0.05 |
0.05 |
0.810 |
0.800 |
0.734 |
0.709 |
0.076 |
0.091 |
|
ADA + CL, |
λ CL |
= 0.1 |
0.05 |
0.810 |
0.810 |
0.716 |
0.715 |
0.094 |
0.095 |
|
ADA + CL, |
λ CL |
= 0.2 |
0.05 |
0.804 |
0.790 |
0.704 |
0.683 |
0.1 |
0.107 |
|
ADA + CL, |
λ CL |
= 0.05 |
0.1 |
0.820 |
0.725 |
0.095 |
|||
|
ADA + CL, |
λ CL |
= 0.1 |
0.1 |
0.820 |
0.732 |
0.088 |
|||
|
ADA + CL, |
λ CL |
= 0.05 |
0.2 |
0.820 |
0.800 |
0.721 |
0.713 |
0.099 |
0.087 |
|
ADA + CL, |
λ CL |
= 0.1 |
0.2 |
0.810 |
0.800 |
0.719 |
0.673 |
0.091 |
0.127 |
|
ADA + CL, |
λ CL |
= 0.2 |
0.2 |
0.760 |
0.760 |
0.618 |
0.594 |
0.142 |
0.166 |
Состязательные методы для нетематической классификации текстов 69
Наилучшая точность достигается при значениях λ CL и λ ADA , близким тем, которые были подобраны при отдельном применении ADA и контрастной функции потерь. Такое наблюдение позволило существенно сократить время, требуемое на подбор оптимальных гиперпараметров, выбирая λ CL и λ ADA по отдельности для контрастной функции потерь и ADA соответственно.
Наилучшие результаты достигнуты при умеренных значениях обоих гиперпараметров: X ada = 0.05, X cL = 0.05 для a = 75 и X ada = 0.2, X cL = 0.05 для a = 90. Это свидетельствует о сбалансированном вкладе обоих компонентов и синергетическом эффекте их комбинации.
После фиксирования подобранных оптимальных значений X cl =0.05 и X ada = 0.05 производится перебор гиперпараметров т G [0.25, 0.5, 0.75] и K G [3, 5, 7, 9] аналогично экспериментам в статье [5] . По результатам экспериментов, представленных в таблице 4, оптимальными значениями оказались т = 0.5, K = 7.
Таблица 4. Зависимость от k и τ значений точности (accuracy) для mail и awd и их разности δ при alpha = 75 и λ CL = 0 . 05
|
Метод |
k |
τ |
|
awd |
δ |
|
CL |
5 |
0.5 |
0.800 |
0.726 |
0.074 |
|
CL |
3 |
0.5 |
0.810 |
0.726 |
0.084 |
|
CL |
7 |
0.25 |
0.813 |
0.708 |
0.095 |
|
CL |
7 |
0.5 |
0.817 |
0.729 |
0.088 |
|
CL |
7 |
0.75 |
0.807 |
0.715 |
0.092 |
|
CL |
9 |
0.25 |
0.813 |
0.708 |
0.095 |
|
CL |
9 |
0.5 |
0.817 |
0.729 |
0.088 |
|
CL |
9 |
0.75 |
0.807 |
0.715 |
0.092 |
|
ADA+CL |
5 |
0.5 |
0.810 |
0.734 |
0.076 |
|
ADA+CL |
7 |
0.5 |
0.818 |
0.721 |
0.097 |
|
ADA+CL |
7 |
0.75 |
0.811 |
0.723 |
0.074 |
|
ADA+CL |
9 |
0.5 |
0.810 |
0.720 |
0.090 |
|
ADA+CL |
9 |
0.75 |
0.805 |
0.736 |
0.069 |
Для каждого метода и каждого α в таблице 5 выбрана конфигурация с наивысшей точностью на недостаточно представленном в обучении источнике данных (выделено жирным) и/или наименьшим значением δ (выделено жирным или курсивом ).
Таблица 5. Сводка лучших результатов для каждого метода в зависимости от α
|
Метод |
m |
α |
λ ADA |
λ CL |
|
awd |
δ |
|
ADA |
- |
25 |
0.2 |
0 |
0.818 |
0.759 |
-0.059 |
|
EADA |
4 |
25 |
0.2 |
0 |
0.809 |
0.746 |
-0.063 |
|
CL |
- |
25 |
0 |
0.05 |
0.800 |
0.730 |
-0.055 |
|
CausaLM |
- |
75 |
0.2 |
0 |
0.781 |
0.728 |
0.054 |
|
ADA |
- |
75 |
0.2 |
0 |
0.825 |
0.731 |
0.094 |
|
EADA |
8 |
75 |
0.05 |
0 |
0.832 |
0.694 |
0.138 |
|
CL |
- |
75 |
0 |
0.2 |
0.817 |
0.729 |
0.088 |
|
ADA + CL |
- |
75 |
0.05 |
0.05 |
0.805 |
0.736 |
0.069 |
|
ADA |
- |
90 |
0.2 |
0 |
0.825 |
0.712 |
0.113 |
|
EADA |
4 |
90 |
0.05 |
0 |
0.832 |
0.699 |
0.133 |
|
ADA + CL |
- |
90 |
0.05 |
0.1 |
0.800 |
0.715 |
0.095 |
Напрашивается вывод, что при преобладании Блогов Mail.Ru в тренировочном наборе данных совместное использование ADA и контрастной функции потерь приводит к наилучшим результатам среди всех рассмотренных методов как по точности на AWD, так и по значению δ . ADA при этом существенно улучшает результат стандартного BERTа, уступая только комбинации ADA и контрастной функции потерь.
Кроме того, для моделей на основе BERT, ADA, контрастной функции потерь и ADA+CL с лучшими значениями гиперпараметров была проведена 5-fold кросс-валидация с использованием 5 различных случайных разбиений на обучение и тест для проверки стабильности получаемых результатов. В итоге среднее значение точности на валидационном множестве по всем кросс-валидационным разбиениям оказалось равным 0.790, 0.787, 0.788 и 0.782 для BERT, ADA, CL, ADA+CL соответственно. При этом, среднее стандартное отклонение получилось равным 0.011, 0.006, 0.007 и 0.009 соответственно. Это показывает, что модели, обученные с использованием состязательных методов, более устойчивы к изменению разбиения на тренировочный и тестовый датасет.
Для оценки статистической значимости улучшений, достигнутых с помощью состязательных методов, применен односторонний t-критерий. Для каждой экспериментальной настройки (α = 25, 75 и 90) проводилось многократное случайное разбиение данных с последующим расчетом точности модели. Полученные p-значения оказались меньше 0.05 для ADA при α = 75 и α = 90, что подтверждает статистическую значимость улучшений. Для разбиения α = 25 результаты не достигли статистической значимости (p-value = 0.18), что, предположительно, связано с особенностями распределения длин текстов в наборе данных AWD, который преобладает в данном тренировочном наборе.
В большинстве случаев повышение точности на тестовом наборе данных является статистически значимым, что подтверждает эффективность методов состязательной адаптации предметной области для снижения последствий тематических сдвигов.
В таблице 6 можно увидеть пример правильного и неправильного
Таблица 6. Пример корректного и некорректного предсказания BERT
-
6.3. Большие языковые модели в режиме zero-shot. LLaMA 3B Instruct
Поскольку большая часть данных для обучения модели LLaMA [8] на английском языке, было решено использовать инструкцию для предсказания половой принадлежности автора текста с помощью LLaMA тоже на английском языке, см. таблицу 7.
В каждой инструкции использовались 5 текстов. При этом, рассматривались 2 вида инструкций:
-
• 4 случайных текста из Mail.Ru + 1 случайный текст из AWD;
-
• 4 случайных текста из AWD + 1 случайный текст из Mail.Ru.
Это сделано, чтобы максимально приблизить эксперименты с LLaMA 3.2 3B Instruct к экспериментам с дообучением моделей меньшего размера.
Таблица 7. Формат инструкции для LLaMA 3.2 3B Instruct.
Текст с описанием задачи выделен жирным шрифтом.
These are examples of correct responses:
Text: «Текст 1>". Response: «Пол автора текста 1>".
Text: «Текст 2>". Response: «Пол автора текста 2>".
Text: «Текст 3>". Response: «Пол автора текста 3>".
Text: «Текст 4>". Response: «Пол автора текста 4>".
Text: «Текст 5>". Response: «Пол автора текста 5>".
Given this text, you should understand the gender of its author.
Return only one character: M (for male) or W (for female)
Text:
"Всем доброго времени суток. у меня 4 перелета Львов-Стамбул-Белград и Сараево-Стамбул-Харьков"
По результатам таблицы 8 видно, что точность больших языковых
Таблица 8. Точность LLaMA 3.2 3B Instruct
По результатам экспериментов можно сделать следующие выводы:
-
(1 ) Тематические смещения оказывают значительное влияние на классификатор пола автора текста;
-
(2) использование состязательных и каузальных методов немного повышает точность модели при тестировании на текстах из другой предметной области;
-
(3 ) хотя при использовании CausaLM разница уменьшается в большей степени, методы ADA и Contrastive Loss позволяют добиться этого без существенного снижения точности на текстах из преобладающего источника. Время, затрачиваемое на обучение причинно-следственных моделей с использованием ADA, значительно меньше, чем при использовании CausaLM. Это делает использование ADA более раци-
- ональным с точки зрения требуемых временных и вычислительных ресурсов;
-
(4 ) несмотря на то, что это более сложный алгоритм, EADA показывает улучшение только при семплирования тренировочного набора данных из 75% mail.ru и 25% данных awd. Следовательно, метод оказывается менее эффективным, чем ADA и контрастная функция потерь;
-
(5) контрастная функция потерь позволяет повысить точность классификации по сравнению со стандартным BERT при преобладании текстов из mail.ru в тренировочном наборе данных;
-
(6 ) при преобладании текстов из mail.ru в тренировочном наборе данных, совместное использование ADA и Contrastive Loss оказывается более эффективным, чем использование просто ADA;
-
(7) LLaMA 3.2 3B Instruct без дообучения показывает более низкую точность на тесте, но при этом требует больше времени на предсказание одного текста, что делает её применение к задаче классификации пола автора текста не оправданной.
-
6.4. Анализ ошибки
Результаты на AWD модели, обученной на 75% Mail, 25% AWD.
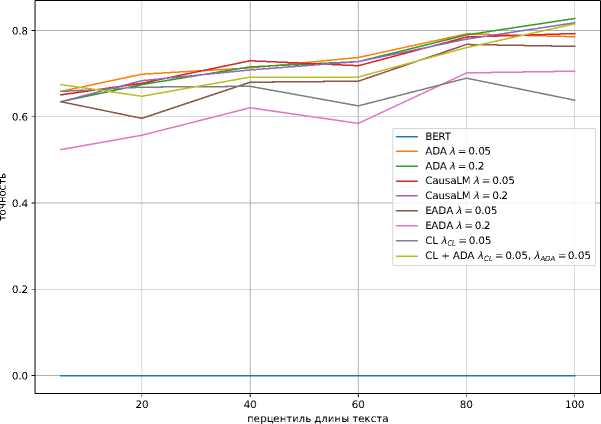
Рисунок 1. Влияние длины текста на эффективность состяза тельных методов при семплировании, а = 75
На графике рисунка 1 показано, как длина текстов влияет на точность модели. Тексты разбиваются на группы одинакового размера по количеству слов в них. Видно, что ADA с λ = 0, 05 при обучении на наборе данных α = 75 превзошёл стандартный BERT при любой длине текста. Однако при семплировании в тренировочную выборку α = 25 состязательные методы менее стабильны на самых коротких и самых длинных текстах.
В отличие от ADA, в EADA есть дополнительный гиперпараметр m — разница между представлениями из исходного домена и целевого домена. Значение по умолчанию, рекомендованное в [4] , равно 4. Также были проверены m = 2 и m = 8 для тренировочного набора данных α = 75. Поскольку все они показали худший результат, чем m = 4, мы оставили m = 4 для всех остальных экспериментов.
График для обучения на α = 75 показывает чёткую закономерность, согласно которой точность модели имеет сильную положительную корреляцию с длиной текста в тестовом наборе данных. Это видно и для всех моделей, обученных на этом распределении mail/awd, что подтверждает выводы из [25] .
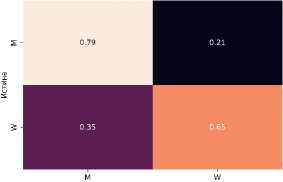
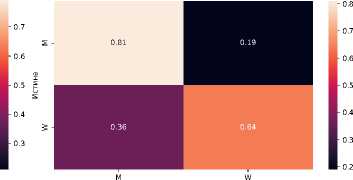
Рисунок 2. Матрица ошибок при обучении на α = 75 и тестировании на awd для BERT и ADA с λ ADA = 0 . 05 соответственно.
Предсказание
Предсказание
Рисунки 2 и 3 показывают как распределены ошибки при классификации с использованием стандартного BERT и классификации при использовании Adversarial Domain Adaptation с λ ADA = 0.05. Видно, что при обучении на наборе данных с преобладанием текстов из Блогов Mail.Ru и тестировании на AWD, точность на текстах женского мужского выше. При обучении на наборе данных с преобладанием текстов из AWD и тестировании на Блогах Mail.Ru результат оказывается противоположным.
При преобладании Блогов Mail.Ru в обучении доля текстов женских авторов становится выше 50% в связи с распределением полов в наборах данных табл. 1 и ADA снижает долю ошибок при предсказании для текстов авторов как мужского, так и женского пола. При преобладании AWD в обучении ADA показывает существенное повышение точности для текстов авторов женского пола, но при этом доля ошибок для текстов авторов мужского пола увеличивается.
Вне зависимости от распределения источников данных в обучении, модель, обученная с использованием ADA, снижает долю ошибок на текстах того пола, который менее представлен в обучении.
0.68
0.32
0.15
0.85
0.8
0.7
0.6
0.5
0.4
0.3
0.2

0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
Предсказание
Предсказание
7. Время обучения
Рассчитано время, необходимое для обучения модели каждой архитектуры, упомянутой в экспериментах. Все модели обучены на одном графическом процессоре на базе Nvidia TITAN RTX. Доступный объем графического процессора: 24 ГБ. Результаты представлены в таблице 9.
|
Модель |
Источник |
Время на эпоху, сек. |
|
BERT |
|
117 |
|
ADA |
|
128 |
|
EADA |
|
132 |
|
CausaLM |
|
234 |
|
CL |
|
162 |
|
CL + ADA |
|
174 |
Мы видим, что добавление состязательной функции потерь при использовании методов доменной адаптации (как ADA, так и EADA) к моделям BERT не приводит к существенному увеличению времени обучения. При этом заметное увеличение времени обучения происходит при использовании контрастной функции потерь, поскольку для неё требуется предподсчёт всех эмбеддингов текстов, полученных на предыдущей эпохе. Самым долгим по обучению методом является CausaLM.
Заключение
В работе рассмотрена проблема изменений в распределении обучающих данных, в частности, проблема тематических сдвигов. Предложена модификация семплирования для контрастной функции потерь, нацеленная на снижение эффектов тематических сдвигов. Впервые проведено исследование комбинированного метода ADA с контрастной функцией потерь.
Результаты экспериментов показывают, что состязательные методы полезны для улучшения нетематических классификаторов текстов при наличии тематических сдвигов и изменении предметной области. В целом, использование контрастной функции потерь может быть рекомендовано для случаев, когда в тестовых данных происходит значительный сдвиг предметной области. При этом, ADA остаётся наиболее эффективным методом в случае преобладания одной темы в обучающем наборе данных. Это важный практический результат, учитывая распространённость и актуальность задач нетематической классификации текстов в современном мире.
Кроме того, в работе показывается, что несмотря на быстрый прогресс в развитии больших языковых моделей, для ряда задач они все ещё остаются менее эффективными, чем дообученные модели меньшего размера.
Дальнейшие исследования будут направлены на адаптацию состязательных и контрастных методов для задач регрессии на текстах.
