Статистический метод выделения временных паттернов из естественных языков

Автор: Калимолдаев Максат Нурадилович, Пак Александр Александрович, Нарынов Сергазы Сакенович
Журнал: Проблемы информатики @problem-info
Рубрика: Средства и системы обработки и анализа данных
Статья в выпуске: 3 (24), 2014 года.
Бесплатный доступ
Рассматривается алгоритм рекурсивной самоорганизующейся карты (Recursive Self Organizing Map, RSOM) для выделения статистически значимых временных паттернов из символьного потока контекстно-зависимых грамматик. Главной идеей метода является, предложенное Thomas Voegtlin в 2002, объединение классического алгоритма Teuvo Kohonen и неявного представления времени в виде комбинации текущего входа и контекстного отклика сети. В статье приведены результаты экспериментов над текстами на казахском и английском языках.
Обработка естественных языков, нейронные сети, самоорганизация
Короткий адрес: https://sciup.org/14320253
IDR: 14320253 | УДК: 004.8.032.26
Текст научной статьи Статистический метод выделения временных паттернов из естественных языков
Введение. На сегодняшний день суммарный объем символьной информации, аккумулированный в Интернете, превысил все знания человечества, накопленные до создания глобальной информационной среды. Современные методы индексации текстов не справляются в полной мере с задачей быстрого поиска информации. Проблема индексации накопленного знания является нетривиальной задачей. Размер текстов, накопленный в сети, составляет приблизительно 8000 терабайт, среднегодовой объем электронной почты — 10000 терабайт. Очевидно, что в таком большом потоке данных выборка документов, полученная с помощью методов полнотекстового поиска, может содержать много нерелевантных или слаборелевантых результатов из-за синонимического представления запроса, опечаток, грамматических неточностей, сленга и др. [1]. Предложенная Tim Berners-Lee в 2001 году идея семантической паутины была призвана решить вышеобозначенные проблемы, однако в 2006 г. автор идеи признал, что реализация в силу ряда причин невозможна. Принцип семантической паутины основан на оперировании смыслами взамен слов. Иначе говоря, вычислительная машина должна быть способна обобщать слова до некоторых понятий. На сегодняшний день эта задача является отчасти решенной при помощи методов корпусной лингвистики. Однако недостатком подобного подхода является колоссальный объем работы, связанный с разметкой текстов и поддержанием в актуальном состоянии морфологии, синтаксиса и семантики конкретного языка. Без учета грамматических ошибок, сленга и др.
В данной статье будет рассмотрен метод, позволяющий в автоматическом режиме выделять темпоральные паттерны и конструкции естественного языка. Метод основан на нейросетевом подходе самоорганизации и обучении без учителя. На сегодняшний день было разработано несколько способов в нейрокомпьютинге для представления времени, большинство из них связаны с задачами распознавания речи или автоматической обработки языка. Условно можно разделить представление времени на явное, где время дополняет размерность пространства и коэффициент временной задержки используется для оценки мер процесса внутри окна наблюдения [2]. И неявное, когда время выражено опосредовано через логику представления изучаемого феномена [3], что характерно для рекуррентных сетей или так называемых „Leaky integrator“ процессов. В общем случае явное представление времени сверхчувствительно и ограничено к временным деформациям, напротив неявное является более устойчивым и универсальным. Действительным ограничением квазиинтегративных нейронов является тот факт, что информация с долговременной зависимостью обычно затухает по экспоненциальному закону. Однако рекуррентное представление необязательно должно иметь эти ограничения [4], по крайней мере до тех пор, пока не будет использован градиентный спуск.
В ряде научных работ были предложены различные подходы интегрирования представления времени в самоорганизующуюся карту Кохонена (Self-Organizing Map, SOM). Явное представление было рассмотрено в работе [5, 6], методы, основанные на латеральных и рекуррентных связях, были предложены в [7, 8], техники, базирующиеся на квазиинтеграторе [9, 10], также были изучены различные комбинации вышеозначенных принципов в работах [11, 12, 13]. Основным лейтмотивом перечисленных работ является идея обобщения процесса самоорганизации на время. Однако не совсем ясно, каким образом самоорганизация и время могут быть совмещены. Ошибка квантования или искажения в алгоритме SOM с учетом времени не может быть использована напрямую.
В данной статье будет рассмотрен алгоритм рекуррентного модифицированного SOM, где обратная связь будет использована для представления времени. Представление времени неявное и самореферентное в том смысле, что карта учится классифицировать собственные выходы. Однако основная идея заключается в добавлении в классический алгоритм SOM рекуррентных связей при сохранении оригинального принципа самоорганизации. Для того чтобы оценить сходимость сети, было предложено обобщение ошибки квантования временных рядов [14].
Самоорганизация и самореферентность. Широко известным примером рекуррентной нейроной сети является архитектура Simple Recurrent Network (SRN), предложенная Jeff Elman в 1990 году. SRN — это расширение классического Multi Layered Perceptron (MLP), а именно добавлен еще один скрытый слой, которой хранит отклики сети с заданным временным лагом в качестве дополнения к входному вектору. Алгоритм обратного распространения применяется к входному вектору и его копии с лагом. Поскольку SRN обучается на своих прошлых активностях, то его представление на скрытом слое является самореферентным. Самореферентные связи прямого и обратного распространения являются гомогенными. Нет никакой разницы между ними в уравнениях, описывающих активность сети, или правилах обучения. Далее будет показан подход, основанный на данном принципе применительно к SOM, иными словами, будут добавлены рекуррентные связи к оригинальной архитектуре SOM. Следует отметить, что уже существуют рабо-
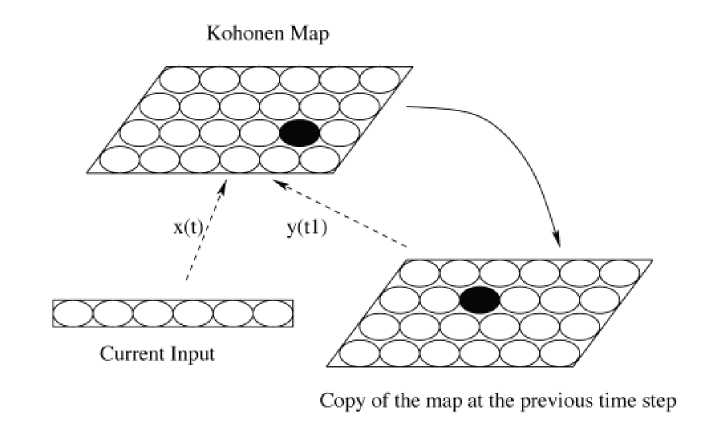
Рис. 1. Архитектура, рекурсивного СОКа. Оригинальный алгоритм карты рекурсивно применяется к входному вектору х(1) и отклику сети, полученному па. предыдущем шаге y(t—1). Пунктирные стрелки обозначают связи обучения. Сплошная стрелка, означает связь один к одному. Сеть учится ассоциировать текущий вход к предыдущему контексту. Взято из работы [14]
ты [7, 8, 12], в которых рекуррентные связи были интегрированы в карту Кохонена, но в этих работах прямая и обратная связь не гомогенны. Архитектура, представленная в данной статье, использует активность сети с задержкой и гомогенность прямых обратных связей (см. рис. 1). Текущий входной вектор и предыдущий отклик сети рассматриваются как один входной вектор классического SOM алгоритма. Иначе говоря, сеть учится кластеризовать пару „входной вектор х и уД — 1) контекст11. Длинные последовательности сеть заучивает итеративно, используя более короткие последовательности в качестве описательных признаков.
В классическом алгоритме SOM каждый г нейрон сравнивает свой вектор весов w,, (1 < г < N) с входным вектором х(Д, где t — это переменная времени. Обычно используется евклидова норма для определения победителя. Победитель определяется соревнованием среди N нейронов по наименьшей ошибке Д = | |w, — x(f)| |. По правилу обучения веса, нейрона-победителя должно быть модифицировано согласно
Awt = ^гк^ (t) -W;), (1)
где г — индекс нейрона-победителя, у — функция скорости обучения, h^ — функция соседства. Традиционно используют так называемую „мексиканскую шляпу11 или гауссиану, см. рис. 2. Существенным различием между ними является тот факт, что „мексиканская шляпа11 позволяет больше специализировать отклик нейрона-победителя.
В данной статье используется такая же нотация. Дополнительно, пусть у(Д — вектор активностей карты в момент времени t. Каждый г нейрон карты (1 < г < А) имеет пару весовых векторов, wf и wf, которые сопоставляются входному вектору x(t) и вектору активностей карты за предыдущую итерацию у(£ — 1) соответственно. Для того чтобы определить нейрон-победитель, предлагается объединить ошибки квантования, соответствующие х (1) и y(t — 1). Поскольку прямые и обратные связи являются гомогенными, то суммарная ошибка квантования выглядит следующим образом
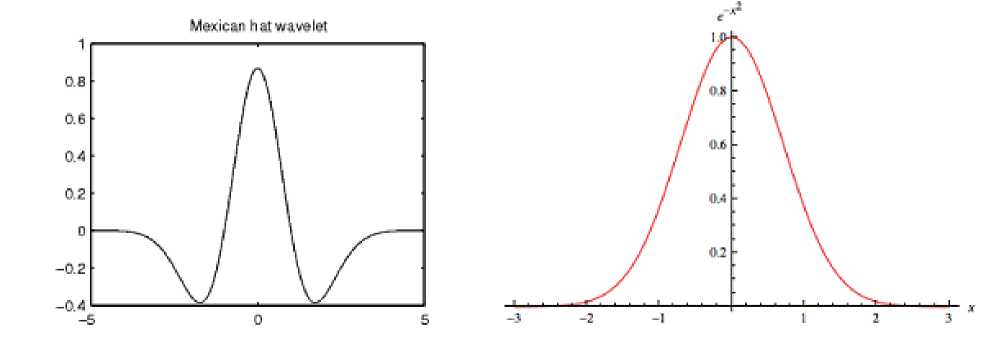
Рис. 2. Вейвлет „мексиканская шляпа11 (слева). Взят с сайта. [15].
Гауссиана. (Справа). Используются в качестве функции соседства, между иейроиами SOM.
Рис. взят с сайта. [16]
Ег = сф^-^ + Р\\у^-Г)-^, (2)
где а > 0 — вес ошибки текущего входа, /3 > О — вес ошибки контекста. Индекс нейрона-победителя будет определен по формуле k = arg min ^Ei^1, тогда, правила эволюции прямых и рекуррентных весов будут иметь вид:
Д w^ = yhik (х (t) - w^), (3)
N = yhik(y (t - 1) - wy), (4)
где y — коэффициент скорости обучения и h,k — функция соседства. Следует отметить, что это правила обучения оригинального SOM, примененные к х (f) и y(t — 1).
Таким образом, в модели Recurrent SOM осуществляется обратная связь. Однако для того чтобы завершить определение модели, необходимо связать активность сети у(^ ко входу и синаптическим весам. Пусть компонента yi вектора, у — это активность г нейрона, зависящая от квадрата ошибки квантования. Однако использование ошибки квантования напрямую у^ = Е^ может привести к нестабильности обучения. В таком случае предлагается использовать функцию активации у, = Е(Е,\ Принцип выбора, функции активации будет разъяснен в следующем разделе.
Следует отметить что параметры а, /3 могут быть исключены из формулы Е\ = ||x(t) — w®||2 + ||y(t — 1) — wy||2 и у, = yJ^F(aEi^. Поэтому прямые и обратные связи являются гомогенными. Мы включили параметры а, /Зв Ei для удобства, анализа сходимости и робастности алгоритма. В любом случае а, 3 могут быть рассмотрены как часть функции активации.
Стабильность и функция активации. Идея использовать в традиционном SOM алгоритме обратные связи была, уже предложена [17, 18]. Однако серьезной проблемой была, нестабильность в обучении [18]. Иными словами, при изменении многомерного представления обучающих примеров на карте, вектор обратных связей не успевал подстроиться, что препятствовало сходимости и стабильности обучения, что подтверждено в работе [17].
В данном разделе будет представлен аппроксимационный анализ стабильности рекуррентного SOM. Несмотря на приблизительный характер анализа, будет дано представление о выборе трансферной функции.
Рассмотрим малое возмущение отклика сети 5y(t) притом, что все остальные переменные и параметры модели остаются неизмененными. Возмущение 5y(t) будет иметь два эффекта. Во-первых, все последующие отклики у (t + п), п > 0 будут искажены рекуррентным распространением возмущения. Поставим в соответствие „будущим11 искажениям вектор 5у (t + и).
Во-вторых, возмущение приведет к изменению распределения вектора у (7), что в свою очередь индуцирует долговременную адаптацию синаптических весов. В первом приближении будем рассматривать только кратковременную эволюцию. При условии достаточно малой величины коэффициента обучения можно пренебречь адаптацией весов.
Стабильность на кратковременной динамике зависит от эволюции 5y(t + n). Если П^у (t + п)|| —> О при п —> оо, то возмущение затухнет.
Более того, если 52„>О ||<5у (7 + п)|| < +оо, тогда распределение у останется неизмененным, и адаптации весов не произойдет. Также покажем, что эффект возмущения мал, если само возмущение мало. Можно выразить это утверждение, используя нотацию Ландау О:
£||М< + Л11 = О(||«у(Д|). (5) 77, > О
Рассмотрим эффекты адаптации весов на стабильность обучения. Строго, стабильность весов должна быть рассмотрена, только когда коэффициент обучения стремится к нулю. Однако мы рассматриваем стабильность в более широком смысле: положим, что коэффициент обучения — малая константа и ожидаемые значения синаптических весов и их вариации можно сделать достаточно малыми правильным выбором коэффициента обучения. Для упрощения представления положим, что веса сходятся, когда используется традиционный алгоритм SOM и распределение входного вектора — константа [19].
Положим, Wy= (wf) , 1 < г < N — матрица весов рекуррентных связей. Рассмотрим малые изменения 7Wy во время обучения. Как выше было сказано, мы рассматриваем матрицу Wy, элементы которой являются ожиданием рекуррентных весов во время обучения, 5Wy — это возмущение этих весов. 5Wy индуцирует прямое изменение отклика у(Д из-за того, что в уравнении (2) изменится wf. В дополнение, к непрямому изменению у (1) может привести распространение возмущения отклика сети, как это было показано выше. Возмущение отклика ду(Д — результат суперпозиции двух компонент, прямой и косвенной. Прямая компонента может быть получена из уравнения (2) и будет иметь тот же порядок энергии, что и 5Wy, при непрерывной трансферной функции. Косвенная компонента — сумма величин, возникших в результате распространения возмущения на шагах t — 1, t — 2 и т. д. Однако, если условие (5) удовлетворено, то энергия косвенной компоненты будет того же порядка, что и прямой компоненты. Поэтому возмущения отклика сети 5у (t) и 5Wy синаптических весов будут одного порядка:
I|5y(t)|| = O(||5WyH). (6)
В обучении подобной модели возникает так называемая проблема „движущейся цели11, где цель — это набор синапсов, стабильных в период обучения. Под движущейся целью подразумевается изменение облака данных, на котором обучается RSOM из-за изменения рекуррентных связей, иными словами, сеть учится классифицировать собственный отклик, который меняется во время обучения. Пусть Т= (ti), 1 < г < N соответствует матрице „движущихся целей", где ti — „цель", к которой должен сойтись текущий вектор wf по совместному стационарному распределению (х (t), у (t — 1)). Следовательно, вектор „цель" в любой определенный момент времени является результатом суперпозиции векторов синапсов и статистического ожидания примеров обучения, мы предполагаем, что для совместного стационарного распределения (х (t), у (t — 1)) ряды x(t) — эргодичны. Однако любое изменение синаптических весов также изменит и распределение (х (t), у (t — 1)), и вектор ti изменится. Для того чтобы гарантировать успевания модели за вектором цели, мы должны наложить дополнительное условие:
РТ||
< Ild'W^H .
Из-за локальных латеральных связей на карте каждый вектор цели ti является барицентром ожидания у (t — 1), когда нейрон г становится победителем в момент времени t. Хотя отношения соседства усложняют анализ возмущений в векторе целей, разумно предположить следующее неравенство:
||5Т|| < ДУЕ|||ау||],
где дТ — вариация матрицы целей из-за возмущения распределения у и £ф] — статистическое ожидание. Из неравенства (8) с учетом (7) получаем:
Дув[|Ну||] < ||^||.
Таким образом, мы получили два условия стабильности. Условие (5) гарантирует стабильность нейронной динамики, и условие (9) — стабильность весов в период обучения.
В случае, если оба условия удовлетворяются, тогда ожидаемые значения весов сходятся во время обучения. Выбор функции активации в работе представлен следующим выражением:
Ut^ = F (Е^ = exp(-a\\x(t) - w^||2 - Д||у (t - 1) - wf||2). (10)
Функция является непрерывной и ограниченной на отрезке (0,1]. Отклик нейрона-победителя находится ближе к 1, отклик проигравшего ближе к 0. Интуитивно активность нейрона-победителя должна быть стабильной в случае возмущения персептивных или синаптических полей. Гауссовская функция активации сглаживает выбросы. Таким же свойством обладает и отклик проигравших нейронов. [14] показал, что (10) удовлетворяет условиям стабильности (5) и (9).
На рис. 3 представлены численные результаты экспериментов по определению области стабильности для рекурсивной карты Кохонена с функцией активации (10).
Эксперимент и параметры обучения. Для тестирования и отладки были проведе d (г, А:)2 ст2
ны эксперименты, использовалась классическая функция соседства Н^ = ехр(—
Размер карты составлял 28 х 28 для английского языка, 36 х 36 для казахского языка. Тек сты, на которых обучалась сеть: „Brave New World", Aldous Huxley; сборник исторических эссе о Казахстане, находящихся в сети в открытом доступе. Буквы были закодированы бинарным вектором, для казахского языка длина вектора составляла 6, и для английского ■5 бит. В предобработке пунктуация была убрана из текста, исключения составляла тильда в английском языке в таких словах как don‘t, haven‘t и т. д. Сам текст был разбит на
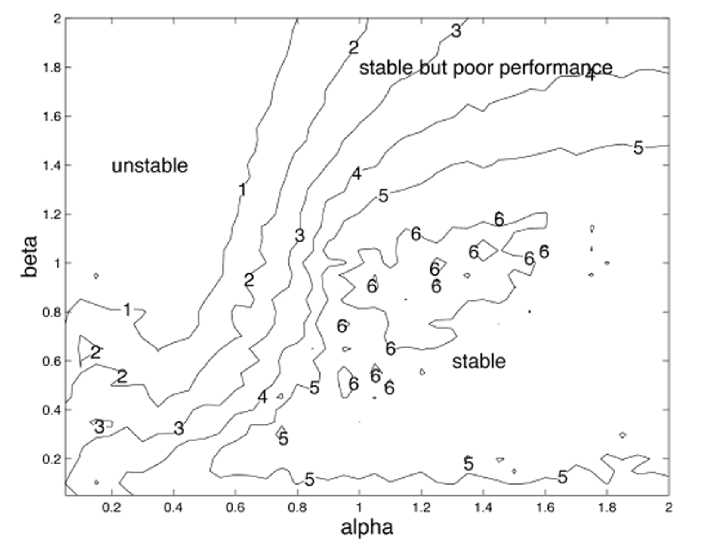
Рис. 3. Области стабильности рекуррентного SOM, обученного на. бинарных последовательностях, для различных параметров а и /3. На рис. представлена, средняя длина, рецептивного поля нейрона-победителя. Для каждого условия данные усреднялись по 8 экспериментам. Низкие значения указывают на. плохую стабильность, большие значения указывают на. хорошую стабильность. В верхней правой области наблюдается стабильность при плохой сходимости. Рис. взят из [14]
слова, разделителем служил пробел. Между словами контекст сети обнулялся. Коэффициент обучения также как и в оригинальной статье был константой у = 0,1. Функция соседства представляла собой гауссиану с шириной а = 1,8 и масштабом s = 5. Параметры а = 3 и /3 = 0,7. По ходу обучения нейроны втягивали в свое персептивное поле образы различных последовательностей букв. Объем текстов для казахского и английского языков составил приблизительно 400 Кб. Длительность обучения для английского языка, составила, около 8 часов. Для казахского языка. — около 15 часов, что объясняется большой размерностью карты и кодирования букв. Реализация алгоритма была сделана на языке JavaSE2. Использовались математические библиотеки линейной алгебры и аналитической геометрии Cern Colt 1.2.0 [20]. Для визуализации экспериментальных данных использовалась программа Pajek64 3.11 [21].
Результаты. На рис. 4 представлены временные паттерны, которые были заучены нейронной сетью на текстах Aldous Huxley. Сеть была, настроена для выявления характерных дифтонгов в тексте. Однако, в силу рекуррентной природы последняя буква, первого дифтонга является также первой буквой второго дифтонга. На рис. 4 видны статистически значимые комбинации дифтонгов, образующие слова английского языка: was, with, whip, and, had, his. Характерные окончания: -ing -ent -n’t
Данные, представленные на рисунке, подвергались постобработке. Прежде всего, были удалены дубликаты с общим корнем и одинаковым образом, что снизило количество узлов с 784 до 348. Также связи между узлами были прорежены по уровню 0,3.
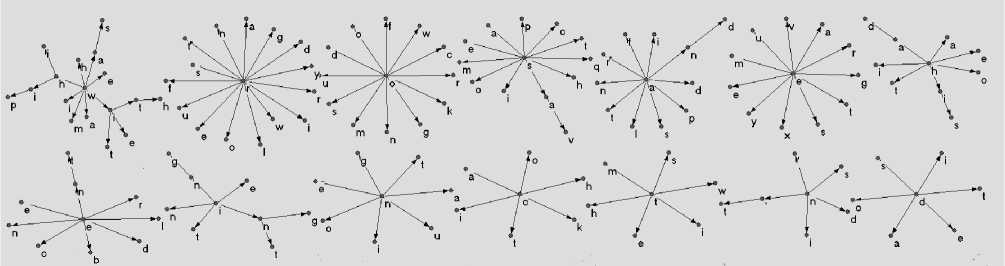
Рис. 4. Результаты обучения рекуррентного SOM на. тексте английского языка.
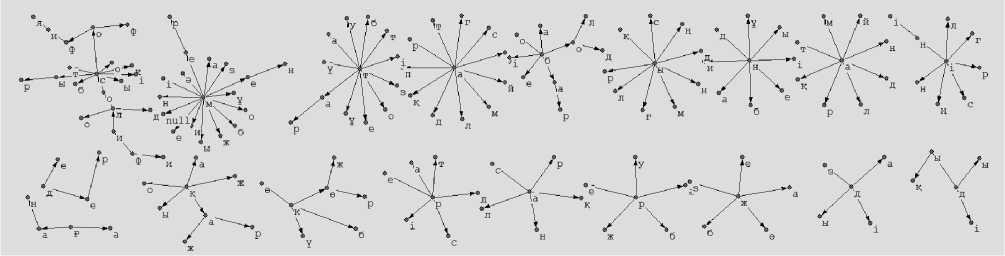
Рис. 5. Результаты обучения рекуррентного SOM на. тексте казахского языка.
На рис. 5 представлены временные паттерны казахского языка, характерные для исторических эссе, находящихся в свободном доступе. На изображение также видно, что сеть смогла выявить характерные сочетания, образующие целые слова: философ, философия, бар, ini, кар, Кер, бол. Характерные части слов: дык, дер, гаи, тар, сыр.
Визуализация для казахского языка, также была, подвергнута, фильтрации, редуцированию количества узлов с 1296 до 300 и прореживанию связей с уровнем 0,4.
Выводы. Сегодня существует большой ажиотаж вокруг обработки естественных языков. Это связано в первую очередь с глубокой востребованностью автоматических методов обработки больших объемов текстовых данных. Естественно, подобное возможно лишь при помощи методов машинного обучения. Здесь наблюдается тенденция в сторону более реалистичных когнитивных моделей, что связано с недавно появившимися эффективными методами „глубокого обучения“, подразумевающего выявление в потоках данных иерархии все более сложно устроенных признаков. Алгоритм рекуррентной карты является хорошим кандидатом для автоматического выявления сложных иерархий в потоке символов. Для развития требуется решить проблемы мертвых нейронов, дубликатов и скорости обучения.
Список литературы Статистический метод выделения временных паттернов из естественных языков
- SHUMSKY S. Selforganizing semantic networks/Neuroinformatics-2001 III All-Russian Scientific Conf. Lect.on Neuroinformatics. Moscow, 2001.
- LANG, K. J., WAIBEL A. H., & HINTON, G. E. A time-delay neural network architecture for isolated word recognition.//Neural Networks. 1990. N 3, P. 23-43.
- ELMAN, J. L. Finding structure in time.//Cognitive Science. 1990. N 14. P. 179-211.
- BENGIO Y., SIMARD P., & FRASCONI P. Learning long-term dependencies with gradient descent is difficult//IEEE Transactions on Neural Networks. 1994. N 5(2). P. 157-166.
- KANGAS J. On the analysis of pattern sequences by self-organizing maps//PhD Thesis, Helsinki University of Technology. 1994.
- VESANTO J. Using the SOM and local models in time-series prediction/Proc. of the Workshop on Self-Organizing Maps’97 Espoo, Finland: Helsinki University of Technology. 1997. P. 209-214.
- EULIANO N., & PRINCIPE J. Spatio-temporal self-organizing feature maps/Proc. of the Inter. Conf. on Neural Networks. 1996. P. 1900-1905.
- HOEKSTRA A., & DROSSAERS M. An extended Kohonen feature map for sentence recognition/Proc. of the Inter. Conf. on Artificial Neural Networks. 1993. P. 404-407.
- CHAPPELL G. J. & TAYLOR J. G. The temporal Kohonen map//Neural Networks. 1993. N 6. P. 441-445.
- PRIVITERA C. M. & MORASSO P. The analysis of continuous temporal sequences by a map of sequential leaky integrators/Proc. of Intern. Conf.on Neural Networks. 1994. P. 3127-3130.
- JAMES D. L. & MIIKKULAINEN R. SARDNET: A self-organizing feature map for sequences//Advances in Neural Information Processing Systems. 1995. N 7. P. 577-584.
- KOSKELA T., VARSTA M., HEIKKONEN J. & KASKI K. Time series prediction using recurrent SOM with local linear models//Intern. J. of Knowledge-based Intelligent Eng. Sys. 1998. N 2(1). P. 60-68.
- MOZAYYANI N., ALANOU V., DREYFUS J. & VAUCHER G. A spatiotemporal data coding applied to Kohonen maps/Proc. of the Intern. Conf. on Artificial Neural Networks. 1995. P. 75-79.
- VOEGTLIN T. Recursive Self-Organizing Maps//Neural Networks. 2002. V. 15 N. 8-9. P. 979-992.
- http://radio.feld.cvut.cz/matlab/toolbox/wavelet/mexihat.html.
- http://www5a.wolframalpha.com/Calculate/MSP/MSP6701h6a8290ga 35bb8600003afghd1hgga79088?MSPStoreType=image/gif&s=61&w= 304.&h=124.&cdf=RangeControl
- BRISCOE G. & CAELLI T. (1997). Learning temporal sequences in recurrent self-organising neural nets. In A. Sattar (Ed.), Advanced topics in artificial intelligence/Proc. of the 10th Australian Joint Conf. on Artificial Intell. Berlin: Springer. 1997. P. 427-435.
- SCHOLTES J. C. Kohonen feature maps in natural language processing/Tech. Rep. CL-1991-01, Institute for Language, Logic and Information, University of Amsterdam. 1991.
- VARSTA M., HEIKKONEN J. & MILLAN, J. D. R. Context-learning with the self-organizing map/Proc. of the Workshop on Self-Organizing Maps’97. Espoo, Finland: Helsinki University of Technology. 1997. P. 197-202.
- KOHONEN T. Self-Organizing Maps. Springer Verlag. 2001.
- http://acs.lbl.gov/software/colt/
- http://pajek.imfm.si/doku.php
