Text Localization and Character Extraction in Natural Scene Images using Contourlet Transform and SVM Classifier

Author: Shivananda V. Seeri, J. D. Pujari, P. S. Hiremath
Journal: International Journal of Image, Graphics and Signal Processing(IJIGSP) @ijigsp
Article in issue: 5 vol.8, 2016.
Free access
The objective of this study is to propose a new method for text region localization and character extraction in natural scene images with complex background. In this paper, a hybrid methodology is suggested which extracts multilingual text from natural scene image with cluttered backgrounds. The proposed approach involves four steps. First, potential text regions in an image are extracted based on edge features using Contourlet transform. In the second step, potential text regions are tested for text content or non-text using GLCM features and SVM classifier. In the third step, detection of multiple lines in localized text regions is done and line segmentation is performed using horizontal profiles. In the last step, each character of the segmented line is extracted using vertical profiles. The experimentation has been done using images drawn from own dataset and ICDAR dataset. The performance is measured in terms of the precision and recall. The results demonstrate the effectiveness of the proposed method, which can be used as an efficient method for text recognition in natural scene images.
Natural scene images, Text localization, Contourlet transform, SVM classifier, GLCM, horizontal profile, vertical profile
Short address: https://sciup.org/15013974
IDR: 15013974
Text of the scientific article Text Localization and Character Extraction in Natural Scene Images using Contourlet Transform and SVM Classifier
Published Online May 2016 in MECS DOI: 10.5815/ijigsp.2016.05.02
Of late, digital cameras have become very popular, efficient and powerful image acquisition tools, which are commonly attached with various handheld devices like mobile phones, tablets, pens, wrist watches, head mounted devices, PDAs and so on. Fabricators of these devices are now considering such devices for embedding numerous useful technologies. Potential technologies may include recognition of texts in natural scene images, text-to-speech conversion and so on. Extraction and recognition of texts in natural scene images are suitable for persons with visual impairment and foreigners with language impediment. Furthermore, the ability to automatically detect text from scene images has potential applications in image retrieval, robotics, computer vision and intelligent transport systems. However, developing a robust system for extraction and recognition of texts from captured scenes is a great challenge due to several factors which include variations of style, color, spacing, distribution, layout, light, background complexity, presence of multilingual scripts and fonts. Text appearing in images can provide very useful semantic evidence to describe the image content. In general, text existing in images can be categorized into scene text and caption text. A scene text is a part of an image, whereas a caption text is laid over the image in a later stage. Caption text is often used for successful indexing and retrieval of images or videos. The Fig.1 shows these two types of text present in the images.

(a)
Fig.1. Sample Digital Images Containing (a) Scene text (b)Caption text

(b)
In this paper, a hybrid methodology is proposed for text region localization and character extraction in natural scene images with complex backgrounds. The proposed hybrid approach involves four steps. First, potential text regions in an image are extracted based on edge features using Contourlet transform. In the second step, potential text regions are tested for text content or non-text using GLCM features and SVM classifier. In the third step, detection of multiple lines in localized text regions is done and line segmentation is performed using horizontal profiles. In the last step, each character of the segmented line is extracted using vertical profiles.
Due to growing requirement for extraction of text from images, much research work has been done on text extraction in images. Several techniques have been proposed for extracting the text from an image. The existing methods are based on morphological operators, wavelet transform, artificial neural network, skeletonization operation, edge detection algorithm, histogram technique and so on. All these methods have their benefits and limitations.
-
II. Related Work
Text extraction in an image encompasses four phases, namely, (i) Detection, (ii) Localization (iii) Extraction and (iv) Recognition (OCR). Text detection and text localization are closely related and more exciting phases which had fascinated the devotion of many researchers. The main objective of the two phases is to spot all text objects in a natural scene image and to provide a unique identity to each text. Due to the variety of font size, style, orientation, and alignment as well as the complexity of the background, designing a robust general algorithm, which can effectively detect and extract text from natural scene images, is a challenging task. Various methods have been proposed in the past for detection and localization of text in images and videos. These approaches take into consideration different properties related to text in an image such as color, intensity, region, connected components, texture, edges, etc. These properties are used to discriminate text regions from non-text regions within the image. In this section, the recent works focused on text detection, localization, line segmentation and character extraction are reviewed. The various methods proposed in these works can be categorized as region based, morphology based and texture based methods.
Among region based methods [29], a method for detecting video text regions containing player information and score in sports videos is proposed in [1], in which key frames were extracted based on color histogram in order to minimize the number of video frames. A unified method to extract a text region from heterogeneous images by using contourlet transform is proposed in [2]. A new scheme for character detection and segmentation from natural scene images is proposed in [3], in which stroke edge and graph cut algorithm is employed to detect text regions and geometrical features are used to filter out non-text regions. A method based on histogram thresholding, entropy filtering and connected components is used to extract Bengali text and Bengali characters from multimedia images is proposed in [16]. A method for character extraction and recognition from images is proposed in [4], in which edge density is calculated for four orientations (00, 450, 900, 1350) to detect potential text regions and clustering is used to localize text regions. A combined approach based on color and edge features for extracting text from video is proposed in [5], in which color-edge approach is used to remove text background and vertical and horizontal projection is employed to locate text in image. The comparative study of edge-based and connected-components based approaches in terms of accuracy, precision and recall rates is given in [14], in which each approach is analyzed to determine its success and limitations.
A morphology based text line extraction algorithm for extracting text regions from cluttered images is proposed in [6], in which an algorithm is adopted for recovering a complete text line from its pieces of segments and verification scheme is then employed for verifying all extracted potential text lines according to their text geometries. A mathematical morphology and connected components based algorithm to extract text from images is proposed in [7], in which the text is extracted based on the thresholding of variance of the each connected component. Extraction of Devanagari and Bangla texts from camera captured scene images is investigated in [21]. In [30], a unified framework that combines morphological operations and genetic algorithms (GA) for extracting and analyzing the text data region in an image is designed.
Texture based methods are numerous. A texture descriptor, based on line-segment features for text detection in images and video sequences, for car license plate localization system is proposed in [8], wherein color and edge features are used for text/non-text discrimination to exploit accurate perceptual information. A texture based method for detecting texts in images is proposed in [9], in which SVM and a continuously adaptive mean shift algorithm (CAMSHIFT) is adopted to analyze the textural properties of text for localization. In [10], an approach to locate text in different backgrounds is proposed, which is based on Haar wavelet transform. In [11], the procedure for text extraction in color images using 2D Haar wavelet transform (2D-DWT) is suggested for text extraction in vehicle plate and the document images. A new methodology based on GLCM features is proposed in [12] for text region extraction and non-text region removal from complex background coloured images. An approach based on Haar wavelet is proposed in [13] to detect the text regions from the complex images, which is robust to different scripts in single or multi-line text image. An algorithm for Tamil text extraction from images is considered in [15] using dual tree complex wavelet transform. In [17], a heuristic approach is developed for detecting potential text regions in colour image, which are further classified as text using text features such as frequency, orientation and spatial cohesion. In [18], an efficient algorithm is designed for Kannada text localization in images with complex backgrounds using a colour reduction technique. An approach based on Haar wavelet and k-means clustering is developed in [19] for extracting a text from an image with cluttered background. A methodology for text extraction from low resolution natural scene images is attempted in [20] using DCT. A novel hybrid method for multilingual text detection in natural scene images with complex backgrounds is developed based on Haar wavelet and fuzzy classification in [22] and SVM classifier in [27]. A caption text detection technique is presented in [23], which combines Haar wavelet and geometric based features. A hybrid method based on fusion of Daubechies DWT, radiant difference and SVM is designed for text extraction in [24]. A rule based method for text localization using connected components filtering is explored in [25]. Text detection and character extraction in natural scene images has been investigated in [26] using histogram based textural features.
-
III. Proposed Methodlogy
The proposed methodology consists of four phases: preprocessing, potential text region detection, feature extraction, classification, followed by character extraction. The four phases of proposed methodology are described below.
Preprocessing
After the conversion of the input color image into grayscale image, the median filter is applied to remove any noises present in the grayscale image and to obtain sharp edges in the image.
Potential text region detection
Contourlet transform is applied on the pre-processed image to obtain the edge map containing strong edges. The morphological operations are applied on the transformed image, which yield segmented image. The connected components in the segmented image are filtered based on thresholding the geometric properties of the connected components. The filtered connected components are the potential text regions detected in the image, which will be classified as text or non-text regions using the trained SVM classifier in the classification phase.
Feature extraction
Gray level co-occurrence matrix (GLCM) has proved to be a popular statistical method of extracting textural feature from images. It is a 2D histogram of pair wise neighboring pixels with local textural uniformity in an image. It is denoted by C(i, j) and represents joint probability of occurrence of pixels with intensities i and j. It is computed using a displacement vector with radius δ and orientation θ. The values δ=1 and θ=0, 45, 90 and 135 degrees are chosen in the present work. From the cooccurrence matrix, Haralick defined fourteen textural features to extract the characteristics of texture statistics of images. The four important features, namely, Contrast, Homogeneity, Energy and Entropy, of potential text regions are extracted, which are then used to classify the regions into text and non-text classes.
Contrast: It evaluates local gray level variation in an image and measures the spatial frequency.
F 1 =ij(і-ј)2∑∑С(i,j)
Homogeneity/Inverse Difference Moment: It measures local uniformity in the image. It is high when local gray level is uniform.
F2 =∑∑ 1+ (( ,J ))∗ ; ]
Energy: It is also referred as uniformity or angular second moment (ASM) and describes image smoothness. It is high when image has very good homogeneity.
F3 =∑∑С(i,j)
Entropy: It measures the disorder or complexity of an image. The entropy is high when the image has complex textures with high degree of non-uniformity.
F4 =∑∑іјС(i, j) logC(i, j)
Classification
The support vector machine (SVM) is trained using GLCM textural features and statistical features of text regions in training images, and is then used to classify the potential text regions extracted from natural scene test image as a text or non-text.
Character extraction
Text localized image will be then further processed in order to extract the characters from the image. Horizontal projection is used to detect multiple lines in the localized text image and then each line is segmented. Further, each line segment is subjected to vertical projection to segment the characters. The horizontal projection H(i) and the vertical projection V(j) of a binary image are given by:
H(i) =∑j^o1 В(i, j) (5)
V(j) =∑HO1 В(i, j) (6)
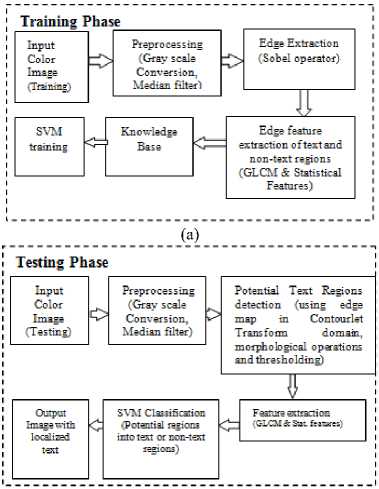
The proposed methodology for text localization and character extraction is depicted in the block diagrams shown in the Fig.2 and Fig.3.
(b)
Fig.2. Block Diagram of the Text Localization Module of the Proposed Method. (a) Training Phase, (b) Testing Phase
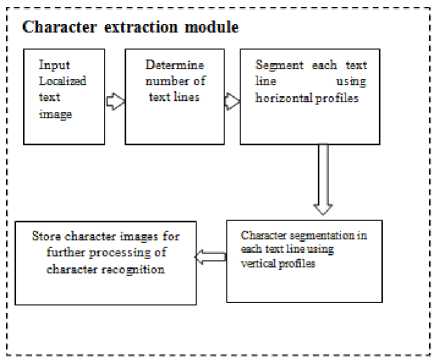
Fig.3. Block Diagram of the Character Extraction Module of the Proposed Method.
The training and testing phases of the proposed methodology are described below.
Training phase:
In training phase, the input color image is converted to grayscale image and then median filter is applied. The edge map of the filtered image is obtained using the Sobel edge operator. The GLCM features F1 to F4 and statistical features, namely, standard deviation and mean absolute deviation, are computed from edge map and stored in knowledge base. This procedure is repeated for all natural scene images in training set to obtain complete knowledge base, which is used for training SVM classifier.
Testing phase:
In the testing phase, the input color image is transformed to grayscale image and then subjected to median filter. The edge map of the filtered image is obtained by using the Contourlet transform [28]. The dominant edges pertaining to the text in the image are retained by thresholding technique, in which thresholds based on mean and standard deviation of the edge map are used. Further, the resulting binary image is considered for morphological processing. The two structuring elements, namely, disks of radius 3 and 6 (empirically chosen), are employed that yield two separate images containing potential text regions. These two images are combined using logical OR operation to obtain connected components relating to potential text regions in the image. The portion of the input image corresponding to connected components is cropped and the texture features are extracted from the cropped regions. The SVM classifier is used to classify each potential region as text or non-text. The text region may contain singe line or multiple lines (Fig.4). The horizontal projection is used to extract each line separately. The segmented line is subjected to vertical projection to extract characters (Fig.5).

Fig.4. Sample Result of the Proposed Method Showing Input Image and Corresponding Text Localized Output Image.
ADVERTISING DOESN'T WORK!
(a)
ADVERTISING DOESNT
■иизз™
(b)

(c)
Fig.5. (a) Text Localized Input Image (b) Lines Segmented Image (c) Characters Segmented Image
-
IV. Experimental Results And Discussions
The proposed method is implemented in MATLAB R2009b and tested on Intel Core i5 processor @ 2.5 GHz 4GB RAM machine. The experimental data set contains 344 natural scene images (including ICDAR data set), out of which 244 are used as training images and 100 as testing images. The SVM classifier is trained using the training set which contains 122 text images and 122 nontext images. These images are color (RGB) images in JPEG format, which contain multilingual texts of different complexity and complex background. The scripts of the text in the training images are Kannada Hindi and English, whereas text in test images are in different languages, namely, Urdu, Tamil, Bengali, English, Hindi, Kannada, Telugu, Japanese, Chinese and, Malayalam. The result of the proposed algorithm is shown in the Fig.4 and Fig.5. The performance of the proposed algorithm has been evaluated in terms of precision, recall, F-measure and accuracy, which are defined below.
True Positives (TP) are the text regions that are identified as text in an image.
False Positives (FP) are non-text regions, but identified as text in an image.
True Negatives (TN) are non-text regions that are identified as non-text.
False Negatives (FN) are the text regions, but identified as non-text.
|
Precision |
= X 100 TP+FP |
(7) |
|
Recall |
= X 100 TP+FN |
(8) |
|
F-measure= |
2∗Precision∗Recall |
(9) |
|
(Precision+Recall)∗100 |
||
|
TP+TN Accuracy = X 100 3 TP+TN+FP+FN |
(10) |
|
The proposed method has yielded the precision and recall rates of 98.85% and 90.85%, respectively. The F-measure is obtained as 0.95, which is close to 1. The accuracy of the proposed method is 89.90%. The experimental results demonstrate the effectiveness of the proposed method, which are better than the results obtained by the methods in [22] [27]. The improvement in the performance can be attributed to the Contourlet transform employed for obtaining edge map which has preserved the dominant edges of text in the image, and thus leading to more accurate localization of text regions as compared to wavelet transform based method [27]. This performance comparison of the methods is illustrated in the Fig.6. The SVM is trained with only three scripts, namely, Hindi, English and Kannada. The proposed method is robust to extract text regions of different scripts in natural scene images. The extracted text regions containing multiple lines of text of different scripts are segmented successfully. The character extraction from each segmented line is done, which is illustrated in the Fig.5. The performance comparison of the proposed method with the other methods in literature is given in the Table 1.
Table 1. The Performance Comparison of the Proposed Method with the other Methods
|
Methods &Year |
Techniques Used |
Precision (P) % Recall (R)% F-measure (F) Accuracy (A)% |
Benefits |
|
|
1. |
Proposed method |
Contourlet Transform GLCM, statistical features, geometric properties, Mathematical Morphology, SVM classifier |
P=98.85 R=90.85 F=94.68 A= 89.90 |
Multilingual, Robust to style, font and complex backgrounds Robust edge features |
|
2. |
Seeri, et al. [22] |
Wavelet Transform, Statistical features, fuzzy classification, K-Means clustering |
P=95.54 R=89.14 F=0.92 |
Multilingual, Robust to style, font and complex backgrounds |
|
3. |
Seeri, et al. [27] |
Haar wavelet transform, GLCM, statistical features, geometric properties, Mathematical Morphology, SVM classifier |
P=97.14 R=89.81 F=0.94 A= 88.99 |
Multilingual, Robust to style, font and complex backgrounds |
|
4. |
Leon, etal. [23] |
Wavelet Transform, Hierarchical image model |
P=91.0 R=79.55 F=0.85 A=85.78 |
Insensitive to Different size, color, complex background for caption text |
|
5. |
Sumathi, et al. [12] |
Gamma correction, GLCM and Thresholding concepts |
P=78.0 R=91.0 F=0.84 |
Robust to size, style, font and complex background for English text |
|
6. |
Pavithra, et al. [24] |
Wavelet Transform, Gabor filter, K-Means clustering |
P=98.0 R=80.20 F=0.88 |
Multilingual text detection, Robust to horizontal texts. |
-
V. Conclusion
The occurrences of text in a natural scene image pose a difficult challenging task in digital image processing due to complex background and illumination variations. The text may be multilingual with variations in font style, font size, scale, lighting and orientation. The proposed method is based on Contourlet transform which preserves the dominant edges of text in the image, and thus leads to more accurate localization of text regions. The localized text regions containing multiple lines of text of different scripts are segmented and then the character extraction from each segmented line is done successfully. The proposed method has yielded the F-measure and accuracy of 94.68% and 89.90%, respectively, and is robust to variations in script, font style, font size, scale, lighting and orientation of text in an image. The recognition of segmented characters of a script will be considered in our future work.
Input Image

Text localized Image (Wavelt transform) [27]

Text localized Image (Contourlet transform)

Fig.6. Performance Comparison of the Proposed Method Based on Contourlet Transform and the Method in [27]
Acknowledgment
The authors acknowledge the K.L.E Technological University and BVBCET, Hubballi 580031, India, for the financial support under the “Capacity Building Projects” grants.
References Text Localization and Character Extraction in Natural Scene Images using Contourlet Transform and SVM Classifier
- Vijayakumar, R. Nedunchezhianm, A Novel Method For Super Imposed Text Extraction In A Sports Video, International Journal Of Computer Applications, Volume 15– No. 1, 0975 – 8887, February 2011, pp. 1-6.
- Chitrakala Gopalan and Manjula, Text Region Segmentation from Heterogeneous Images, IJCSNS International Journal of Computer Science and Network Security, VOL.8 No.10, October 2008, pp. 108-113.
- Xiaopei Liu, Zhaoyang Lu, Jing Li, Wei Jiang, Detection and Segmentation Text from Natural Scene Images Based on Graph Model, WSEAS TRANSACTIONS on SIGNAL PROCESSING, E-ISSN: 2224-3488, Volume 10, 2014, pp. 124-135.
- Xiaoqing Liu and Jagath Samarabandu, Multiscale Edge-Based Text Extraction From Complex Images, Multimedia and Expo, 2006 IEEE International Conference, ISBN 1-4244-0366-7, 2006, pp. 1721-1724.
- Xin Zhang, Fuchun Sun, Lei Gu, "A Combined Algorithm for Video Text Extraction", 2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery, ISBN 978-1-4244-5931-5,2010, pp. 2294 – 2298.
- Jui-Chen Wu Jun-Wei Hsieh Yung-Sheng Chen, Morphology-based text line extraction ,International Journal of Machine Vision and Applications, P-ISSN: 0932-8092, Volume 19, Issue 3,2008, pp. 195-207.
- Rama Mohan Babu, G., Srimaiyee, P. Srikrishna, A., Text Extraction From Heterogeneous Images Using Mathematical Morphology, Journal Of Theoretical And Applied Information Technology, Vol. 16 Issue 1/2, 2010, pp. 39-47.
- Chu Duc Nguyen, Mohsen Ardabilian and Liming Chen, Robust Car License Plate Localization using a Novel Texture Descriptor, Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance, E-ISBN : 978-0-7695-3718-4, 2009, pp. 523 – 528.
- Kwang In Kim, Keechul Jung, And Jin Hyung Kim, Texture-Based Approach For Text Detection In Images Using Support Vector Machines And Continuously Adaptive Mean Shift Algorithm , IEEE Transactions On Pattern Analysis And Machine Intelligence, Vol. 25, No. 12, ISSN: 0162-8828, 2003, pp. 1631 – 1639.
- Neha Gupta, V.K Banga, Localization of Text in Complex Images Using Haar Wavelet Transform, International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-1, Issue-6, November 2012, pp. 111-115.
- Akash Goel, Yogesh Kumar Sharma, Text Extraction of Vehicle Number Plate and Document Images Using Discrete Wavelet Transform in MATLAB, IOSR Journal of Computer Engineering (IOSR-JCE), e-ISSN: 2278-0661, p- ISSN: 2278-8727, Volume 16, Issue 2, Ver. V (Mar-Apr. 2014), pp. 117-126.
- Sumathi, C.P. and G. Gayathri Devi, Automatic Text Extraction From Complex Colored Images Using Gamma Correction Method, Journal of Computer Science, published Online 10 (4) 2014, ISSN: 1549-3636, 2014, pp. 705-715.
- Adesh Kumar, PankilAhuja, Rohit Seth, Text Extraction and Recognition from an Image Using Image Processing In Matlab, Conference on Advances in Communication and Control Systems 2013 (CAC2S 2013), pp. 429-435.
- Parthasarathi Giri, Text Information Extraction And Analysis From Images Using Digital Image Processing Techniques, Special Issue of International Journal on Advanced Computer Theory and Engineering (IJACTE), ISSN (Print) : 2319 – 2526, Volume-2, Issue-1, 2013, pp. 66-71.
- S. T. Deepa, S. P. Victor, Tamil Text Extraction, International Journal of Engineering Science and Technology (IJEST), ISSN: 0975-5462, Vol. 4 No.05 May 2012, pp. 2176-2179.
- Ankita Sikdar, Payal Roy, Somdeep Mukherjee, Moumita Das and Sreeparna Banerjee, A Two Stage Method For Bengali Text Extraction From Still Images Containing Text, Natarajan Meghanathan, et al. (Eds): SIPM, FCST, ITCA, WSE, ACSIT, CS & IT 062012. © CS & IT-CSCP 2012, DOI: 10.5121/csit.2012.2306, 2012, pp. 47–55.
- Satish Kumar, Sunil Kumar, S. Gopinath, Text Extraction From Images, International Journal of Advanced Research in Computer Engineering & Technology, ISSN: 2278 – 1323, ISSN: 2278 – 1323, 2012, pp. 34-36.
- Keshavaprasanna, Ramakhanth Kumar P, Thungamani.M, ManoharKoli, Kannada Text Extraction From Images And Videos For Vision Impaired Persons, International Journal of Advances in Engineering & Technology, ISSN: 2231-1963, Nov 2011, pp. 189-196.
- Narasimha Murthy K N, Y S Kumaraswamy, A Novel Method for Efficient Text Extraction from Real Time Images with Diversified Background using Haar Discrete Wavelet Transform and K-Means Clustering, IJCSI International Journal of Computer Science Issues, Vol. 8, Issue , No 3, ISSN (Online): 1694-0814,September 2011, pp. 235-245.
- S. A. Angadi, M. M. Kodabagi, A Texture Based Methodology for Text Region Extraction from Low Resolution Natural Scene Images, International Journal of Image Processing (IJIP) Volume(3), Issue(5), November 2009, pp. 229-245.
- U. Bhattacharya, S. K. Parui and S. Mondal, Devanagari and Bangla Text Extraction from Natural Scene Images, 2009 10th International Conference on Document Analysis and Recognition, 978-0-7695-3725-2/09 $25.00 © 2009 IEEE, DOI 10.1109/ICDAR.2009, pp. 171-178.
- S. V.Seeri, J. D. Pujari, P. S. Hiremath, Multilingual Text Localization in Natural Scene Images using Wavelet based Edge Features and Fuzzy Classification, International Journal of Emerging Trends & Technology in Computer Science (IJETTCS), Volume 4, Issue 1, , ISSN 2278-6856, February 2015, pp. 210-218.
- Miriam Leon, Veronica Vilaplana, Antoni Gasull and Ferran Marques, Lecture Notes in Electrical Engineering, Springer, vol. 158, ISSN1876-1100, 2013, pp. 21-36.
- NitiSyal, Naresh Kumar Garg, Text Extraction in Images Using DWT, Gradient Method And SVM Classifier, International Journal of Emerging Technology and Advanced Engineering, ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 6, June 2014, pp. 477-481.
- Nobuo Ezaki, Marius Bulacu, Lambert Schomaker, Text Detection from natural Scene Images: Towards a System for Visually Impaired Persons, Proc. of 17th Int. Conf. on Pattern Recognition (ICPR 2004), IEEE Computer Society, vol. II, 23-26 August, Cambridge, UK.,2004, pp. 683-686.
- Shraddha Naik, Sankhya Nayak, Text Detection and Character Extraction in Natural Scene Images, International Journal of emerging Technology and Advanced Engineering, ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 2, February 2015, pp. 178-182.
- S. V. Seeri, J. D. Pujari, P. S. Hiremath, Multilingual Text Detection in Natural Scene Images using Wavelet based Edge Features and SVM Classifier, International Journal of Advanced Research in Computer Science and Software Engineering (IJARCSSE), ISSN 2277-128x Volume 5, Issue 11, November 2015, February 2015, pp. 81-89.
- P. S. Hiremath and Rohini A. Bhusnurmath, Non-subsampled contourlet transform and local directional binary pattern for texture image classification using support vector machine, Int. Jl. Of Engineering Research and Technology, Vol. 2, Issue 10, Oct. 2013, pp. 3881-3890.
- Samabia Tehsin, Asif Masood, Sumaira Kausar, Survey of Region-Based Text Extraction Techniques for Efficient Indexing of Image/Video Retrieval, IJIGSP Vol. 6, No. 12, November 2014, pp.53-64.
- Dhirendra Pal Singh, Ashish Khare, Text Region Extraction: A Morphological Based Image Analysis Using Genetic Algorithm, IJIGSP Vol. 7, No. 2, January 2015, pp. 39-47.
