N=25 N=50 N=100 N=150 N=200
Formula 1 Formula 2
Formula3 Formula 4
Formula 5 Formula 6
Formula 7 Formula 8
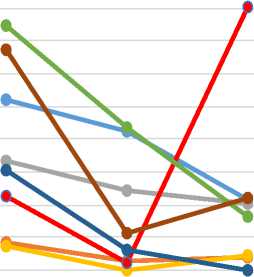
Fig 1: The absolute value of correlation coefficients vs. sample size N for formula 1 to formula 8
Table 1: value of |r|ava for formula 1 to formula 8
Formula | |Hav3 |
Formula 1 | 0.1028517 |
Formula 2 | 0.0423519 |
Formula 3 | 0.0232212 |
Formula 4 | 0.0411278 |
Formula 5 | 0.0165323 |
Formula 6 | 0.0255519 |
Formula 7 | 0.034642 |
Formula 8 | 0.0809405 |
We see from Table 1 that the absolute value of correlation coefficient is the lowest for formula 5, i.e. the linear interdependence between one half of random numbers generated and the other half is the least for formula 5.
3.2 Result based on new formulae of pRNG as stated below
One problem with pseudo-random number generators stated in formula 2 to formula 8 above in section 1 is that if the value of library function rand() placed in denominator in above formulae turns out to be zero, then the number generated is infinity and our computer program will stop to generate any further random numbers. We faced this problem with random number generator given by formula 2 above in section 1 in iteration number 8400. To overcome this problem we propose below following new formulae of pRNGs derived from the library function rand() of C/C++.
„ rand ()*rand()
Formula 9:
rand()+l
Formula 10:
rand()3 rand( )2+l
Formula 11:
rand( )3 rand()*rand()+l
Formula 12:
rand( )4 rand( )3+l
Formula 13:
[rand( )*rand( )]2 rand( )3 + l
Formula 14:
rand( )5 rand( )4+l
Formula 15:
rand( )6 rand( )s+l
For these 7 formulae, i.e. formula 9 to formula 15, and formula 1 we generate respectively 50000, 100000 and 200000 random numbers and find the correlation coefficient of each, for half of the data with respect to the other half, i.e. one half of the data is assumed the variable x and the other half is assumed the second variable y. Thus for the generation of 50000 random numbers, sample size is 25000 and we denote the absolute value of correlation coefficient for this sample size as r. Thus for the sample sizes of 50000 and 100000 respectively the absolute values of correlation coefficients are denoted as ^ and r2.
Same algorithm is used as given in section 3.1 but with different sizes of arrays a[ ], x[ ] and y[ ]. The plot of r, rl and r2 for different formulae is given below.
From Fig.2 we see that the curve for formula 11 is the closest to 0, on an average. This means that the absolute value of correlation coefficient is the smallest for formula 11, on an average, for all sample sizes and hence the randomness of the numbers generated by pRNG formula 11 is the greatest amongst the eight pRNG formulae compared.
However, from Fig.2 we can also find out mathematically the average of absolute value of correlation coefficient lrlavg for each formula.
lrlavg = Area under the curve for a chosen formula from Fig. 2/(100000-25000)
or Vrla^g = [0.5(r + ri)25000 + 0.5(ri + r2)50000] / 75000
The value of |r| avg formula wise is given below.
0.009
0.008
0.007
0.006
0.005
0.004
0.003
0.002
0.001
N=25000 N=50000 N=100000
Formula 1 Formula 9 Formula 10
Formula 11 Formula 12 Formula 13
Formula 14 Formula 15
Fig 2: The absolute value of correlation coefficients vs. sample size N for formula 9 to formula 15 and formula 1
Table 2: value of lrlaV5 for formula 9 to formula 15 and formula 1
Formula | lrlavy |
Formula 1 | 0.00371158 |
Formula 9 | 0.00041733 |
Formula 10 | 0.00245084 |
Formula 11 | 0.00029679 |
Formula 12 | 0.00317576 |
Formula 13 | 0.0039695 |
Formula 14 | 0.00083501 |
Formula 15 | 0.00243022 |
We see from Table 2 that the absolute value of correlation coefficient is the lowest for formula 11, i.e. the linear interdependence between one half of random numbers generated and the other half is the least for formula 11.
We can say from above result that the better pRNG (better than rand()) for short run, i.e. the number of iterations of random number generation algorithm around 400 is
rand()4 rand()3
But, however, the better pRNG (better than rand()) for long run, i.e. the number of iterations of random number generation algorithm equal to or in excess of 50000 is
rand()3
rand() *rand() + 1
This formula instead of rand() alone can be used in computer simulations, specially in Monte Carlo simulations. However, it is not applicable for cryptographic applications.
As stated earlier above, the pRNG formula 2 to formula 8 generates random numbers in the range 0 to infinity. Infinity as such is an undefined number, but if somehow we program our computer to manipulate infinity, these pRNGs are perfect random number generators and are better formulae than that given in formula 9 to formula 15. To find a way to make the computer manipulate infinity let us calculate the largest possible value that a given pRNG generates without rand() becoming zero. To be clear let us take the case of formula 3. The extreme possibility is that the value of rand() in numerator is 32767 and the value of rand() in denominator is 1. Now with these values consider the following algorithm unsigned long int a;
a=pow(32767,3)/1;
The problem with this algorithm is that it gives a warning- overflow in implicit constant conversion. And the value that is output to the terminal is 4294967295, which is not correct. A remedy to this problem is through following algorithm double a;
a=pow(32767,3)/1.0;
The output of this algorithm is 3.51812X1013, which is the correct value of mathematical operation carried out in the algorithm. So instead of creating integers if we create double precision floating point random numbers we immediately see a solution to infinity problem. For the particular case of formula 3 we modify our pRNG algorithm to create the random number “3.51812X1013 +rand()” whenever 0 is encountered for rand() in denominator. This way we have defined infinity for formula 3 to have value 3.51812X1013 + rand(). So if we create double precision floating point random numbers our pRNG formula 2 to formula 8 will turn out to be very-very good random number generators with exceptionally long periods.
 in C/C++")
