Top-k Closed Sequential Graph Pattern Mining

Author: K. Vijay Bhaskar, R.B.V Subramanyam, K. Thammi Reddy, S. Sumalatha
Journal: International Journal of Information Engineering and Electronic Business(IJIEEB) @ijieeb
Article in issue: 4 vol.8, 2016.
Free access
Graphs have become increasingly important in modeling structures with broad applications like Chemical informatics, Bioinformatics, Web page retrieval and World Wide Web. Frequent graph pattern mining plays an important role in many data mining tasks to find interesting patterns from graph databases. Among different graph patterns, frequent substructures are the very basic patterns that can be discovered in a collection of graphs. We extended the problem of mining frequent subgraph patterns to the problem of mining sequential patterns in a graph database. In this paper, we introduce the concept of Sequential Graph-Pattern Mining and proposed two novel algorithms SFG(Sequential Frequent Graph Pattern Mining) and TCSFG(Top-k Closed Sequential Frequent Graph Pattern Mining). SFG generates all the frequent sequences from the graph database, whereas TCSFG generates top-k frequent closed sequences. We have applied these algorithms on synthetic graph database and generated top-k frequent graph sequences.
Data mining, graph mining, frequent sequential patterns, closed sequential patterns
Short address: https://sciup.org/15013426
IDR: 15013426
Text of the scientific article Top-k Closed Sequential Graph Pattern Mining
Published Online July 2016 in MECS
Frequent graph patterns are substructures that appear in a graph data set to a frequency not less than a user-specified threshold [9]. Structural forms such as subtrees, subgraphs, sublattices are referred as substructures. A frequent structural pattern is a substructure that appears frequently in a graph database. Sequential pattern mining, the mining of frequently occurring sub-sequences as patterns, was introduced in [13] and has become an important problem in data mining. Sequential pattern mining discovers frequent subsequences as patterns. According to the GSP algorithm [14], sequential pattern mining is to find all sequences whose support is greater than the user-specified minimum support, such sequence is called a frequent sequence. In SPADE [8], the set of all frequent sequences is discovered by reducing database scans and it minimizes I/O costs. The GSP and SPADE follow candidate generation and test approach.
The PrefixSpan algorithm [5] is a pattern-growth approach to sequential pattern mining and it follows divide-and-conquer strategy. BIDE [6] is an algorithm used for mining frequent closed sequences without candidate generation. These algorithms [5,6] grow patterns by constructing projected databases to reduce the search space for a pattern. In this paper, we investigated the problem of mining sequential patterns in graph databases. Our approach finds sequential patterns occurring in graph databases.
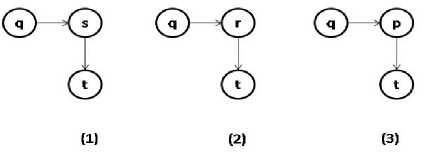
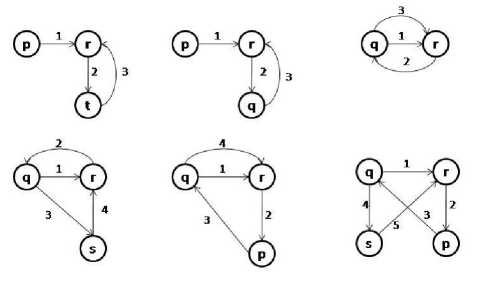
Fig.1. Three graphs where each vertex represents a web page
In “Fig. 1” each node represents a web page. Let us consider that the edges of the given graphs represent the order of visiting the web pages. For example, Graph1 represents the sequence q,s,t. Similarly Graph2 represents the sequence q,r,t and Graph3 represents the sequence q,p,t. Observing the three given graphs, it is clear that page t is accessed after page q(not immediately after q). The resulting pattern is
We proposed SFG( S equential F requent G raph pattern mining) algorithm to mine frequent sequences in a graph database. As the number of edges in a graph increases, the number of sequential patterns also increases exponentially. This requires further analysis of frequent sequential graph patterns. To overcome this difficulty, we proposed TCSFG( T op-k C losed S equential F requent G raph pattern mining) algorithm to generate top-k closed sequential graph patterns.
The rest of the paper is organized as follows. Section ii describes the related work in subgraph mining. Section iii present problem definition and section iv describe SFG, TCSFG algorithms. Our experimental results and performance analysis are presented in section v and our work is concluded in section vi.
-
II. Related Work
Many algorithms exist in the literature for mining frequent graph patterns [1,7,9,16,18]. AGM [1] algorithm efficiently mines frequently appearing induced subgraphs from a graph data database. Experimental results in [1] show that AGM finds all frequent induced subgraphs containing 300 chemical compounds in 40 minutes to 8 days, as the minimum support threshold varied from 20% to 10%. FSG[9] algorithm uses a sparse graph representation which minimizes both storage and computation. The performance of FSG was worse where the number of vertex and edge labels was small. AGM [1] and FSG [9] are Apriori-based algorithms for mining frequent substructures from graph data. Apriori-based algorithms generate subgraph candidates from frequent subgraphs and prunes false positives. These algorithms [1,9] suffer from the problem of subgraph isomorphism test and candidate generation. Candidate generation and pruning false positives are costly.
The gSpan [18] was the first algorithm to discover all the frequent subgraphs without candidate generation and it prunes false positives. gSpan discovers frequent substructures without candidate generation. A new lexicographic ordering among graphs was built in [18] and it maps each with a unique minimum DFS code as its canonical label. gSpan finds both frequent subgraphs and frequent induced subgraphs. It [18] uses rightmost extension technique to minimize the generation of the same subgraphs and explores the depth-first search in frequent subgraph mining.
Frequent subgraph mining is a challenging issue due to the generation of an exponential number of frequent subgraphs. Closed graph pattern mining was introduced in [16] to mine only closed frequent graph patterns. A graph g is closed if there do not exist any proper super graph of g with the same support as g. CloseGraph [16] mines closed frequent graph patterns using the concepts of equivalent occurrence and early termination to prune the pattern search space. It [16] reduces unnecessary subgraphs and also increases the efficiency of the mining process in the presence of large graph patterns. TSP [12], TFP [4] and CloSpan [17] are the recent work for closed sequential pattern mining. CloSpan is the first algorithm to solve closed sequential pattern mining problem. It [17] mines frequent closed sequential patterns and produces significantly less number of discovered sequences. The CloSpan mines long frequent sequences with low minimum support and without any information loss.
Mining top-k frequent closed patterns without minimum support was introduced in [4]. Top-down and bottom-up combined Fp-tree mining strategy was developed in [4] to raise the support and to discover closed frequent patterns. TSP algorithm mines top-k frequent closed sequential patterns of length no less than min_len, the minimum length of each pattern. It [12] doesn’t require the minimum support threshold, it makes use of the length constraint and outperforms the closed sequential pattern mining algorithm that make use of minimum support threshold.
Several algorithms were proposed previously ranging from mining graph patterns with constraints [2,11,19] and without constraints [6,18] for mining closed graph patterns [16]. Frequent graph-pattern mining may result in a large number of patterns. To make the mining more effective, constraints are often used to confine the pattern search. In gPrune algorithm[2] the frequent graph patterns are generated based on the constraints such as density and diameter. The Density of a graph is defined as the ratio of the edge set to vertex set. The diameter of a graph is the maximum length of the shortest path over all pairs of vertices. The problem of incorporating structural constraints in mining frequent graph patterns was solved in gPrune.
Finding closed frequent graphs with connectivity constraints in relational graphs was introduced in [19]. Two approaches, namely CLOSECUT and SPLAT were proposed to speed up the mining process. The former was pattern growth approach and it has better performance on patterns with high support and low connectivity, later approach was pattern reduction approach and it achieves better performance for the high connectivity constraints. These [19] algorithms mines closed frequent graphs with connectivity constraints in relational graphs. DS-search algorithm [11] mines frequent subgraphs of limited diameter and symmetry. It [11] employs the tree decomposition structure of database graphs during the mining process and generates more structurally interesting patterns in the database.
Recently two sequential techniques[3,10] were developed to solve the problem of graph-coloring. Graphcoloring concept [10 ] was used in processor allocation to represent the busy processor and the busy processors are mapped in the graph using different colors. The authors in [3] investigated the problem of Star coloring and they used DNA sequence to construct a solution space for the star coloring problem
Two algorithms RP-FP and RP-GD were proposed in
-
[7] . These algorithms mine a representative set that summarizes frequent subgraphs. In these algorithms [7] a representative set RS is mined such that any frequent subgraph is covered by a representative in RS, and the value of |RS| is minimized. RP-FP and RP-GD algorithms have been proposed to summarize graph patterns efficiently using the concept of δ-cover and generates δ-jump patterns for a user specified δ. Even though there exist many subgraph mining algorithms, the problem of sequential pattern mining of graphs has not been investigated in the literature.
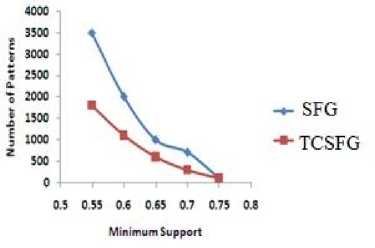
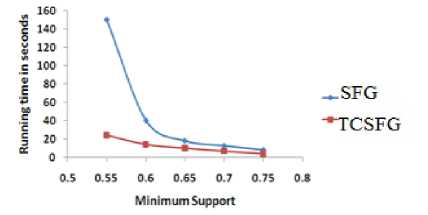
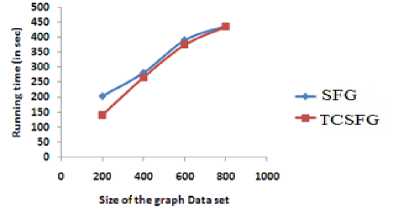
In this paper, we proposed a new algorithm SFG to mine sequential patterns from a graph database using pattern growth approach. We also extended our algorithm to mine top-k closed sequential patterns. We demonstrate that generating top-k closed frequent sequences reduce the number of output graphs without losing much information.
-
III. Problem Definition
In this section, we define sequential graph pattern and frequent sequential graph pattern mining problem.
A Labeled directed Multigraph can be represented as a tuple, G= (V,E,L,F) where V denotes a set of vertices, E denotes a set of edges, L denotes a set of labels and F is a labeling function that assigns labels to the vertices and edges. Every edge is a 4 tuple , where s is the source vertex, d is destination vertex, Gid is Graph id and lb is an edge label. A sample Graph data set is shown in “Fig. 2”.
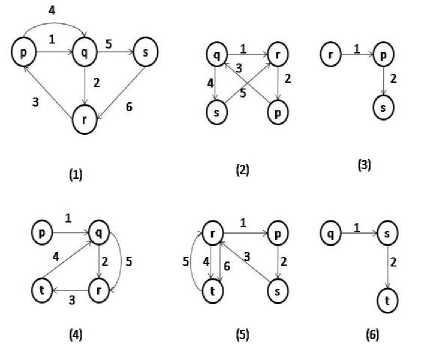
Fig.2. A sample graph data set
Definition 1 (Graph Sequence)
An ordered collection of edges in a graph is called a graph sequence. Every edge is assigned a time constant (time of the creation of the relationship between the vertices) as a label. A Graph Sequence can be represented as,
GS=<(v a ,v b ),(v b ,v c ),….(v l ,v m ),(v m ,v n )> where v a , v n are the source and destination of the Graph sequence and each (vi,v j ) represents an edge from vi to v j . Compact representation of Graph sequence is given as
GS=
Definition 2 (Length of the Graph Sequence).
Given a Graph Sequence GS =
Definition 3 (Support of Graph sequence)
Support of Graph Sequence GS is the total number of graphs containing the sequence GS as a subsequence.
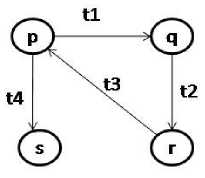
Fig.3. A sample graph
Graph sequence for the graph in “Fig. 3” is
<(p-q),(q-r),(r-p),(p-s)> where t1,t2,t3,t4 are edge labels such that t
1
Definition 4 (Projected database of a sequence S)
Let S be a sequential pattern in a Graph database GD. The S projected database is the collection of subgraph sequences in GD with S as the first occurring sequence.
Definition 5 (Projected database of a vertex)
Given a Graph Database GD = {G 1 , G 2 ,… Gn}, The projected database of a vertex V is the set of subgraphs in which the sequence of the subgraph starts with V.
PDv = { SGi / i ɛ 1,2,..n and v is the starting vertex in each SGi}.For example, in the given graph database, the sequence that starts with vertex p as the source forms projected database of p. In “Fig. 2” edge 1 of Graph 1, edge 3 of Graph 2, edge 2 of Graph 3, edge 1 of Graph 4 and edge 2 of Graph 5 forms the sequence starting with p. Instead of storing the projected database separately for every vertex, considering the space constraints, we store only the
Definition 6 ( Support of a vertex)
Support of a vertex V is the number of sequences that start with V. A graph may contain multiple subsequences starting with V, but the count is only 1 for every graph.
Definition 7 (Canonical form)
Given a multigraph G
i
with n vertices, m edges and a graph sequence GS
Definition 8 (Sequential Graph Pattern)
Given a graph sequence, a Sequential Graph Pattern is all possible subsequences.
For the Graph given in “Fig. 3” Graph Sequence is
Definition 9 (Frequent Sequential Graph Pattern Mining)
Given a Graph database and minimum support, Frequent Sequential Graph-Pattern Mining is to find all the frequent sequences from the graph database.
Table 1. Canonical representation of Graph database
|
Graph-Id |
Graph Sequence (Ordered Edges) |
Canonical form |
|
1 |
p→q, q→r,r→p,p→q,q→s,s→r |
(p,q,1,1),(q,r,1,2),(r,p,1,3), (p,q,1,4),(q,s,1,5),(s,r,1,6) |
|
2 |
q→r, r→p, p→q, q→s,s→r |
(q,r,2,1),(r,p,2,2),(p,q,2,3), (q,s,2,4),(s,r,2,5) |
|
3 |
r→p, p→s |
(r,p,3,1),(p,s,3,2) |
|
4 |
p→q, q→r, r→t, t→q, q→r |
(p,q,4,1),(q,r,4,2),(r,t,4,3), (t,q,4,4),(q,r,4,5) |
|
5 |
r→p, p→s, s→r, r→t, t→r, r→t |
(r,p,5,1),(p,s,5,2),(s,r,5,3), (r,t,5,4),(t,r,5,5), (r,t,5,6) |
|
6 |
q→s, s→t |
(q,s,6,1),(s,t,6,2) |
Table 2. Projected database of vertices
|
Vertex v |
Projected Database |
Support (v) |
Nodes visited from v |
Frequent Sequential Length-1 patterns |
|
P |
{(1,1),(2,3),(3,2) ,(4,1),(5,2)} |
5 |
<7>7>
|
|
|
|
|
|
<6 p:2="">6> |
|
|
|
|
|
<4 q:3="">4> |
|
|
|
|
|
<4>4> |
|
|
|
|
|
<2>2> |
|
’’
-
-
ɛ
-
-
-
ɛ
-
-
-
←
-
-
ʹ
←ʹ
ʹ
-
ʹ
-
ʹʹ -
←ʹʹ
-
ʹ’
ʹ
ʹʹ
ʹ
-
←Φ
-
-
-
←ᴜ
-
-
-
-
<7 q:5="" s:4="" t:3=""><7>7>7>
-
<5><5><4><4><2>
-
<7>
<3 q:2="" s:1="">
“”
р
-
ʹ
←ʹ
ʹ
-
ʹ
-
ʹʹ
ʹʹ
ʹʹ ʹ
←ʹ
-
ʹ’
ʹʹʹ
-
<7><6><5><4><4><4><4><3><3><3><3><3><2>
-
<7>
<3><2><2><2>2>2>2>3> 7> -
<6>6> <3> <2> <2> <2>2> 2> 2> 3>
<2> <2> <2> <2> <3> <7>“”7> 3> 2> 2> 2> 2>
“”
“”
“”“”
“”“”
References Top-k Closed Sequential Graph Pattern Mining
- A. Inokuchi, T. Washio, and H. Motoda. "An apriori-based algorithm for mining frequent substructures from graph data," In Proc. PKDD, ser. LNCS, Springer, Vol.1910,pp. 13-23, July 2002. "doi: 10.1007/3-540-45372-5_2".
- F. Zhu, X.Yan, J. Han, and P. S.Yu, "GPrune: A constraint pushing framework for graph pattern mining," In Proc. PAKDD, ser. LNCS, Springer, vol. 4426, pp. 388–400, May 2007. "doi: 10.1007/978-3-540-71701-0_38".
- G. Sethuraman, and Kavitha Joseph. "Star Coloring Problem:The DNA Solution," International Journal of Information Technology and Computer Science, Vol. 4, No.3, pp.31-37, Apr.2012."doi: 10.5815/ijitcs.2012.03.05".
- J. Han, J. Wang, Y. Lu, and P. Tzvetkov. "Mining top-k frequent closed patterns without minimum support,". In Proc. ICDM 2002, Maebashi, Japan, pp. 211-218, Dec. 2002. "doi: 10.1109/ICDM.2002.1183905".
- J. Pei, J. Han, B. Mortazavi-Asl, J. Wang, H. Pinto, Q. Chen, U.Dayal, and M.C.Hsu. "Mining sequential patterns by pattern growth: Prefix span approach," IEEE Transactions on Knowledge and data engineering, Vol.16, No.11,pp.1424-1440,Nov2004, "doi:10.1109/TKDE.2004. 77 ".
- Jianyong Wang and Jiawei Han, "Bide:Efficient mining of frequent closed sequences," In Proc. of 20th IEEE international conference on Data Engineering ,pp. 79-90, "doi:10.1109/ICDE.2004.1319986".
- Jianzhong Li, Yong Liu, and Hong Gao "Efficient Algorithm for Summarizing Graph Patterns," IEEE Transactions on Knowledge and Data Engineering, Vol.23, Issue:9,pp.1388-1405,2011,"doi:10.1109/TKDE. 2010.48".
- M. Zaki, "SPADE:An Efficient Algorithm for Mining Frequent Sequences," Machine Learning, Kluwer Academic Publishers, Vol.42, issue:1, pp.31-60, 2001, "doi: 10.1023/A:1007652502315".
- M. Kuramochi and G. Karypis, "Frequent Subgraph discovery," In Proc. 2001. Int. conf. Data Mining 2001, pp. 313-320, San Jose, CA, November 2001, "doi: 10.1109/ICDM.2001.989534".
- Mohammed Hasan Mahafzah. "An Efficient Graph-coloring Algorithm for processor Allocation," International Journal of Information Technology and Computer Science, Vol.5, No.7, pp. 43-48, June 2013, "doi: 10.5815/ijitcs. 2013.07.05".
- Natalia Vanetik. "Mining Graphs with Constraints on Symmetry and Diameter," In WAIM 2010 International Workshops, Vol. 6185,Springer, pp. 1-12, July 2010, "doi: 10.1007/978-3-642-16720-1_1".
- Petre Tzvetkov, Xifeng Yan, Jiawei Han. "TSP: Mining Top-K Closed Sequential Patterns," Third IEEE International Conference on Data mining, pp. 347-354, November 2003, "doi:10.1109/ICDM.2003.1250939".
- R. Agrawal and R. Srikant." Mining sequential patterns". In ICDE'95, Taipei, Taiwan, pp. 3-14, Mar. 1995.
- R. Srikant and R. Agrawal. "Mining sequential patterns: Generalizations and performance improvements". In EDBT'96 Proceedings of the 5th International Conference on Extending Database Technology: Advances in Database Technology,pp.3-17,"doi:10.1007/ BFb0014140"
- Synthetic graph generated by IBM Quest Synthetic Data Generation Code for Associations and Sequential Patterns. [http://www.cse.ust.hk/graphgen/].
- X. Yan and J. Han. "CloseGraph: Mining closed frequent graph patterns". In KDD'03, Washington, D.C., August 2003, "doi:10.1145/956750.956784".
- X. Yan, J. Han, and R. Afshar. "CloSpan: Mining closed sequential patterns in large datasets," In SDM'03, San Fransisco, CA, pp. 166-177 May 2003.
- Xifeng Yan, Jiawei Han. "gSpan: Graph-Based Substructure Pattern Mining," In Proc ICDM 2002, pp. 721-724, "doi:10.1109/ICDM.2002.1184038".
- Yan X, Zhou XJ, Han J. "Mining closed relational graphs with connectivity constraints". In Proc of ACM SIGKDD international conference on knowledge discovery in databases (KDD'05), Chicago, IL, pp. 324–333, 2005, "doi:10.1145/1081870.1081908".
