Тригонометрическая система функций в проекционных оценках плотности вероятности нейросетевых признаков изображений

Автор: Савченко Андрей Владимирович
Журнал: Компьютерная оптика @computer-optics
Рубрика: Численные методы и анализ данных
Статья в выпуске: 1 т.42, 2018 года.
Бесплатный доступ
Исследована задача распознавания изображений, которые описываются векторами признаков высокой размерности, выделенными с помощью глубокой свёрточной нейронной сети и анализа главных компонент. Рассмотрена проблема высокой вычислительной сложности статистического подхода с непараметрическими оценками плотности вероятности векторов признаков, реализованного в вероятностной нейронной сети. Предложен новый метод статистической классификации на основе проекционных оценок плотности распределения с тригонометрической системой ортогональных функций. Показано, что такой подход позволяет преодолеть недостатки вероятностной нейронной сети, связанные с необходимостью обработки всех признаков всех эталонных изображений. В рамках экспериментального исследования для наборов изображений Caltech-101 и CASIA WebFaces показано, что предлагаемый подход позволяет на 1-5 % снизить вероятность ошибки распознавания и в 1,5 - 6 раз повысить вычислительную эффективность по сравнению с исходной вероятностной нейронной сетью для малых выборок эталонных изображений.
Статистическое распознавание образов, обработка изображений, глубокие свёрточные нейронные сети, вероятностная нейронная сеть, проекционные оценки, распознавание лиц
Короткий адрес: https://sciup.org/140228775
IDR: 140228775 | DOI: 10.18287/2412-6179-2018-42-1-149-158
Trigonometric series in orthogonal expansions for density estimates of deep image features
In this paper we study image recognition tasks in which the images are described by high dimensional feature vectors extracted with deep convolutional neural networks and principal component analysis. In particular, we focus on the problem of high computational complexity of a statistical approach with non-parametric estimates of probability density implemented by the probabilistic neural network. We propose a novel statistical classification method based on the density estimators with orthogonal expansions using trigonometric series. It is shown that this approach makes it possible to overcome the drawbacks of the probabilistic neural network caused by the memory-based approach of instance-based learning. Our experimental study with Caltech-101 and CASIA WebFace datasets demonstrates that the proposed approach reduces the error rate by 1-5 % and increases the computational speed by 1.5 - 6 times when compared to the original probabilistic neural network for small samples of reference images.
Текст научной статьи Тригонометрическая система функций в проекционных оценках плотности вероятности нейросетевых признаков изображений
Большинство исследований в области распознавания изображений [1] сосредоточены на повышении точности, надёжности и вычислительной эффективности существующих решений за счёт применения новых архитектур глубоких свёрточных нейронных сетей (СНС) [2, 3, 4], новых классификаторов и их ансамблей [5, 6, 7], методов извлечения характерных признаков [8], алгоритмов приближённого поиска ближайшего соседа [9, 10] и пр. Несмотря на наличие большого числа хорошо зарекомендовавших себя подходов, основанных на технологиях глубокого обучения [1], интенсивность исследований в этом направлении не снижается. И связано это с тем, что современные методы распознавания характеризуются недостаточной точностью в вытекающих из потребностей прикладных исследований задачах, например, при наличии в базе данных малых выборок наблюдений (десятки эталонов для каждого класса) [11, 12], которые невозможно использовать для успешного обучения сложных нейросетевых структур [3, 4]. В таком случае наиболее часто используется перенос знаний или адаптация предметной области [7, 13], в котором глубокие СНС применяются не как метод классификации, а как способ извлечения признаков [8, 10]. Такая СНС предварительно обучается с помощью большого набора изображений, например, ImageNET [14].
В результате встаёт задача выбора наиболее подходящего метода классификации [15]. Достаточно перспективным здесь выглядит универсальный статистический подход [16, 17], в котором предполагается, что
Поэтому актуальной становится задача синтеза непараметрических статистических классификаторов, не требующих хранения и сопоставления всех признаков. Для её решения в настоящей работе показано, что если воспользоваться предположением о независимости главных компонент, выделенных из вектора признаков изображений [15], а для оценки плотности вероятности каждой компоненты вместо ядра Розенблатта – Парзена использовать проекционные оценки [21, 22, 23] на основе тригонометрических функций [24, 25], то возможно преодолеть отмеченные недостатки ВНС без потерь в скорости обучения. При этом получившаяся модификация ВНС будет также сходиться к оптимальному байесовскому решению. В ходе экспериментального исследования в задаче классификации категорий изображений и распознавания лиц для популярных баз данных Caltech-101 [26] и CASIA WebFaces [27] продемонстрировано повышение точности и вычислительной эффективности распознавания по сравнению с традиционными подходами в случае наличия ограниченного количества эталонов для каждого класса.
1. Задача распознавания изображений в условиях малого числа наблюдений на основе вероятностной нейронной сети
Задача распознавания состоит в том, чтобы поступающему на вход изображению одного объекта поставить в соответствие один из C > 1 классов [1, 12]. При этом для каждого c -го класса доступен набор из R ( c ) ≥ 1 эталонных изображений. Рассмотрим далее случай малых выборок [6, 12, 21]: R ≈ 1, который характерен для многих систем обработки изображений. Для каждого доступного изображения осуществляется извлечение характерных признаков. В наиболее часто используемых сейчас методах переноса знаний [2, 13] для настройки классификатора может использоваться не доступное обучающее множество, а внешняя база данных изображений, с помощью которой происходит обучение глубокой СНС [3, 4]. Далее для распознавания произвольных изображений они приводятся к одному размеру (высота U и ширина V ) и подаются на вход СНС [8, 10]. Выходы из D >>1 значений одного предпоследнего слоя нейронной сети нормируются (в метрике L 2) и формируют вектор признаков x этого изображения с размерностью D . Аналогичная процедура применяется для извлечения D -мерного вектора признаков x r ( c ) из каждого r -го эталонного изображения с -го класса [12].
В итоге на этапе распознавания обучается классификатор выделенных признаков. В традиционном переносе знаний применяется логистическая регрессия – последний полносвязный слой исходной СНС заменяется на новый слой с C выходами (по одному на каждый класс исходной задачи), и происходит дообучение ( fine-tuning ) полученной нейросети для доступного обучающегося множества из R эталонов [2, 13].
В случаях малого числа наблюдений такая процедура оказывается недостаточно эффективной [11, 12], поэтому зачастую классификатор упрощается, например, с помощью снижения размерности векторов признаков [28] на основе анализа главных компонент [15], при котором векторы x и x r ( c ) линейно преобразовываются в векторы M << D главных компонент t = [ t 1, ..., tM ] и t r ( c ) = [ tr ,1( c ), ..., tr , M ( c )] соответственно. Далее могут применяться известные методы построения небольшого числа опорных подпространств [29] или отбора наиболее информативных эталонов [19, 30].
Проблема состоит в том [1, 17], что каждому конкретному образу обычно присуща известная вариативность, т.е. изменчивость его признаков от одного образца наблюдения к другому, которая носит случайный характер. Обычно преодоление данной проблемы связывают со статистическим подходом [15, 16], когда в роли образа выступает соответствующий закон распределения Pc векторов признаков объектов одного класса. В таком случае задача сводится к проверке C гипотез Wc о законе распределения P признаков входного изображения:
W c : P = P c , c = 1, C . (1)
Её оптимальное решение дает байесовский критерий минимума среднего риска [16] – делается вывод о принадлежности входного объекта к классу с максимальной апостериорной вероятностью
c * = argmax f ( t| W c ) • P ( W c ) . (2)
c e { 1,..._ C }
Здесь P ( W c ) – априорная вероятность появления c -го класса, f ( t | W c ) – условная плотность вероятности (оценка распределения P c ) главных компонент векторов признаков класса c . Для оценки априорной вероятности зачастую [18] используется соотношение числа эталонов в обучающих выборках P ( W c ) = R ( c )/ R , где R = Ъ C = 1 R ( c ) — общее число эталонов. Восстановление неизвестных законов распределения P c происходит в процессе предварительного обучения по выборкам { t r ( c )} конечных объёмов R ( c ). В предположении о нормальном распределении P c могут применяться модификации линейного дискриминантного анализа [11]. С точки зрения современной прикладной статистики на практике обычно нет оснований полагать справедливость предположения о нормальном законе распределения для произвольных объектов [31, 32]. Поэтому большей популярностью в настоящее время пользуются непараметрические методы оценивания распределений [33], например [18]:
R ( c )
f (tlWc ) = Ъ K (t, tr (c))
R ( c ) r = 1
на основе гауссовского ядра Розенблатта–Парзена
K ( t , t r ( c ) ) =
-
1 f 1 )
= ;-----TT M 72 exp I - Ъ ( t m - t r ; m ( c ) ) I -
(2ПС2 ) I 2° m=1
Здесь о - фиксированный параметр сглаживания. С учётом оценки (3) итоговое решение (2) может быть записано в виде
-
1 R ( c )
c * = argmax — Ъ K ( t , t r ( c ) ) - (5)
c e { 1,..., C } R r = 1
Критерий (5) и представляет собой реализацию ВНС [18]. Здесь для каждого класса происходит сопоставление входного объекта со всеми признаками tr (c) каждого эталона. В таком случае алгоритмическая сложность реализации критерия (5) оценивается как O(RM). Сложность по затратам памяти O(RM) оказывается высокой из-за необходимости хранения всех эталонных объектов. В результате применение ВНС может быть неприемлемо для многих прикладных систем, функционирующих на малопроизводительном оборудовании [9].
Так как известного повышения вычислительной эффективности ВНС за счёт использования подходящих структур данных [34] оказывается обычно недостаточно, преодоление указанной проблемы связывают с выделением в обучающем множестве информативных эталонов [19, 30], которые и участвуют в дальнейшем распознавании. Наиболее популярный подход [19] сводится к предварительной кластеризации обучающего множества (чаще всего, на основе метода k-means [15]) и применении центроидов выделенных кластеров для обучения ВНС (3). К сожалению, такое решение приводит к потере основных достоинств ВНС. Действительно, процедура обучения становится достаточно сложной, а само решение перестаёт быть оптимальным в байесовском смысле, особенно для существенно различающихся по объёму кластеров [35].
и выполнить отсечение первых J членов тригонометрического ряда, то оценка плотности вероятности в (6) примет следующий вид [43]:
R ( c ) J 2
f c ( t m ) = — E EE Vk ) ( t m ' U ) ( t rm ( c )) . (8)
R ( c ) t! j =0 и
К сожалению, реализация такого подхода оказывается в 2 J раз медленнее по сравнению с традиционной ВНС (5). Однако если выполнить несложные тригонометрические преобразования выражения (8), то можно получить эквивалентную оценку плотности вероятности с помощью ядра Дирихле [22, 40]:
VS f c ( t m ) =
1 2 R ( с )
R ( c )
E r=1
sin II J + 2 ) ( t m - t r ; m ( c ))
2sin( t m - t r ; m ( c ))
2. Проекционные оценки плотности вероятности в вероятностной нейронной сети
В настоящем праграфе оценки плотности вероятности [36, 37] с помощью гауссовских ядерных функций Розенблатта –Парзена [18] заменяются на известные проекционные оценки [38, 39], в которых плотность вероятности записывается как сумма ортогональных разложений [40, 41]. Ситуация резко осложняется для многомерного случая, в котором образуется многомерная ортонормированная система из всевозможных произведений одномерных базисных функций. В результате с ростом размерности M вектора признаков экспоненциально возрастает сложность вычисления ортонормированных функций [36] и, как следствие, требование к минимальному числу эталонов каждого класса, достаточных для оценки многомерного распределения. Поэтому использование такого подхода для классификации векторов значений признаков большой размерности на практике в общем случае не представляется возможным. В то же время стоит отметить, что для рассматриваемого случая – признаков главных компонент, выделенных из выходов глубокой СНС, – можно использовать предположение о независимости отдельных компонент векторов t и t r ( c ) [35]. Тогда плотность вероятности каждого класса запишется как
M f (t| Wc ) = П fe (tm ), (6)
m = 1
В результате асимптотическая сложность классификации (2), (6), (9) будет совпадать со сложностью ВНС. Именно в таком виде (с учетом различий в применяемой ядерной функции) традиционно записывается ВНС на основе проекционных оценок [36, 37], которая, хоть и приводит в ряде случаев к повышению точности, очевидно, не влияет на вычислительную эффективность классификации.
3. Предложенный подход на основе проекционных оценок плотности
Стоит отметить, что для тригонометрической системы функций не гарантируется неотрицательное значение выражения (9) [22, 43]. В связи с этим на практике обычно используются другие ортогональные функции, такие как многочлены Лагерра или Лежандра [22]. В нашей работе реализован альтернативный подход, в котором для оценки плотности вероятности fc ( tm ) вычисляется среднее арифметическое первых J частичных сумм тригонометрического ряда [43]. Эта оценка представима в виде (3), где вместо ядра Розенблатта – Парзена применяется ядро Фейера [40, 41]
1 1
f ( t ) =-- X
Jc ( m ) R ( с )2( J + 1)
R ( c ) x E r = 1
( sin
J + 1
( tm
tr ; m ( c ))
sin
V
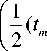
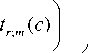
где одномерную плотность вероятности i -го признака fc ( tm ) можно оценить аналогично (3). Если вместо ядра Розенблатта – Парзена (4) воспользоваться проекционными оценками на основе ортогональной системы тригонометрических функций [24, 42]
^V T ( t ) = cos( n jt ), V(2) ( t ) = sin( n jt )
Такой подход, хоть и приводит к неотрицательным значениям оценки плотности вероятности (6), не позволяет повысить вычислительную эффективность распознавания [20, 43]. Поэтому в настоящей работе предлагается воспользоваться другим, эквивалентным (10) выражением [35, 43]:
J 2
f c ( t m ) = 0,5 + EE a mj c ) 'V j ) ( t m ). (11)
j = 1 k = 1
Здесь коэффициенты ряда предложено оценить по имеющейся обучающей выборке как среднее арифме-
тическое (J+1) обычных коэффициентов тригономет рического ряда (7), где m = 1, M, j = 0, J, k = 1,2:
( k ) m ; j
J - j + 1 R ( c ) • ( J + 1 )
R ( c )
E V j )( tr ; m ( C)).
r = 1
Тогда итоговое выражение для распознавания изображений (2), (6) при переходе к более удобному логарифму правдоподобия запишется в виде
M
J 2
Л max ce{1,..., C}
log R ( c ) + E log l 0,5 + EE a m^j (c ) V j ) ( t m ) I . (13)
m = 1
V
j = 1 k = 1
Таким образом, предлагаемый метод состоит в следующем. На этапе обучения для каждого класса вычисляются M (2J + 1) коэффициентов с помощью процедуры (12), имеющей линейную сложность. Далее в процессе распознавания изображение подаётся на вход СНС, выход предпоследнего слоя нормируется и преобразуется в последовательность из M главных компонент. После этого для каждой компоненты вычисляются J значений базисных функций (7). Для ускорения этой процедуры можно воспользоваться известными рекурсивными выражениями для тригонометрических функций суммы переменных:
-
(1) (1) (1) (2) (2)
V j ( t ) = V j - i ( t ) ^V i ( t ) -V j - 1( t ) ^V i ( t ),
-
(2) (1) (2) (2) (1)
V j ( t ) = V j - 1 ( t ) ^V 1 ( t ) + V j - 1 ( t ) ^V 1 ( t )
с инициализацией v(1)(t) = cos(n t), v12)(t) = sin(n t). В итоге количество сложных операций вычисления тригонометрических функций сокращается в J раз (по сравнению с (7)).
Далее для каждого класса и каждой компоненты вектора t оценивается логарифм правдоподобия (13). Итоговое решение принимается в пользу максимально правдоподобного класса.
Остановимся подробнее на преимуществах предложенного подхода. Во-первых, сохраняются все основные преимущества традиционной ВНС: сходимость к байесовскому решению и чрезвычайно быстрая процедура обучения. Стоит отметить, что в предложенном подходе можно эффективно выполнить дообучение при появлении новых эталонных изображений. Действительно, при появлении нового эталона tR(c)+1(c) коэффициенты (12) могут быть скорректированы за константное время следующим образом amk j (c) =
R ( c ) • a mkj ( c ) + V jk ) ( tR ( c ) + 1; m ( c ))
R ( c ) + 1
Наконец, основным преимуществом предлагаемо- го подхода является низкая алгоритмическая сложность его реализации O(СMJ). Как известно [22, 38, 44], сходимость ряда (11) обеспечивается в том слу- чае, если параметр J определяется как o (VR(c)). В
результате вычислительная сложность предлагаемого алгоритма может быть оценена как
C
O\M E V R ( c ) I .
V c = 1 7
В худшем случае, когда для каждого класса доступен только R ( c ) = 1 эталон, асимптотическая сложность реализации разработанной модификации и исходной ВНС одинаковы: O ( MR ). На практике в таком случае предложенный подход может оказаться в несколько раз медленнее за счёт суммирования в (13) 2 J +1 слагаемых. Наибольший выигрыш в скорости распознавания достигается для сбалансированных классов ( R ( c ) = R / C ). Тогда распознавание одного изображения в среднем оказывается приблизительно в R ( c )/ (2 3 J" R ( c )" | + 1) = ( R / C )2/3/2 раз быстрее по сравнению с ВНС (3)–(5). Таким образом, предложенный алгоритм стоит применять вместо ВНС в случае R ( c ) / (2 3 " R ( c )" | + 1) > 1, то есть при наличии в обучающем множестве в среднем не менее R ( c ) =5 эталонных изображений. Кроме того, стоит отметить, что сложность по затратам памяти также снижается: O ( CD • ( RIC ) 1/3)= O ( D • R 1/3 C 2/3) за счёт отказа от обработки всех элементов всех обучающих выборок ( memory-based approach ) и необходимости сохранения только коэффициентов (12).
Таким образом, разработанная модификация (12)– (15) позволяет преодолеть существующие недостатки (низкая вычислительная эффективность, отсутствие обобщения) оригинальной ВНС (4)–(5), сохранив при этом высокую скорость обучения и сходимость к оптимальному байесовскому решению. В следующем параграфе экспериментально продемонстрировано, что и для реальных задач распознавания изображений предложенный подход является не менее эффективным, чем традиционные классификаторы.
-
4. Результаты экспериментальных исследований
Эксперименты проводились на ноутбуке MacBook Pro 2015 (16 Гб ОЗУ, 4-ядерный процессор Intel Core i7 2,2 ГГц). В первом эксперименте рассмотрено применение предложенной модификации ВНС в задаче распознавания C = 101 категорий из набора Caltech-101, содержащего 8677 изображений [26]. Для извлечения признаков использовалась библиотека Caffe [46] и две глубоких СНС – Inception v1 (GoogLeNet) [3] и VGGNet с 19 слоями [4]. Нейросетевые модели, предварительно обученные для распознавания 1000 классов изображений ImageNet, были загружены с официального репозитория Caffe Model Zoo. На вход СНС подавались матрицы цветных (RGB) изображений из набора Caltech-101, приведённых к одной размерности U = V =224 пикселя. Выходы слоев «pool5/7×7-s1» (Inception v1) и «fc6» (VGGNet-19) нормировались в метрике L2, после чего извлекались все главные компоненты для получения окончательных векторов признаков размерности M = 1024 и M = 4096 для Inception и VGGNet-19 соответственно.
В течение 10 раз повторялся следующий эксперимент. В обучающее множество из каждого класса наугад выбиралось фиксированное число изображений R ( c ), а тестирование проводилось на всех остальных изображениях. Для проверки значимости различий в точности и времени распознавания применялся критерий Мак-Немара с уровнем значимости 0,05. Оценки точности классификации α (%) и среднего времени распознавания одного изображения t (мс) для 10 и 25 эталонных изображений в каждом классе R ( c ) представлены в табл. 1 и табл. 2 для признаков, извлечённых с помощью Inception и VGGNet-19 соответственно.
Табл. 1. Результаты распознавания изображений для набора фотографий Caltech-101, Inception v1
Здесь извлечение признаков с помощью VGGNet-19 привело к меньшей точности распознавания по сравнению с GoogLeNet для малого числа эталонных изображений каждого класса (R(c) = 10), но при повышении числа эталонов для ряда методов классификации признаки VGGNet оказались более точными. Подтвердился известный факт о недостаточной эффективности сложных классификаторов (SVM, random forest, искусственная нейронная сеть) при небольших объемах обучающих выборок.
Табл. 2. Результаты распознавания изображений для набора фотографий Caltech-101, VGGNet-19
В следующем эксперименте рассмотрена задача идентификации лиц [1, 12]. Использовались 66000 фотографий первых C = 1000 людей из базы данных фотографий лиц CASIA WebFaces [27]. Для извлечения признаков применялась наиболее точная из свободно доступных нейросетевых моделей – Light СНС (версия C) [47], обученная её авторами с помощью сверхбольшого набора фотографий лиц MS-Celeb-1M. Эта СНС извлекает D = 256 вещественных признаков из полутонового изображения лица с высотой
U = 128 и шириной V = 128 пикселей. Результаты эксперимента приведены в табл. 3.
Табл. 3. Результаты распознавания лиц для набора фотографий CASIA WebFaces, Light СНС
В то же время предложенная модификация (12)– (15) во всех случаях является более предпочтительной как по вычислительной эффективности (в 2,7– 6 раз), так и по точности (на 2–4%), чем оригинальная ВНС (4)–(5). При этом с точки зрения критерия Мак-Немара повышение эффективности по сравнению с ВНС оказывается статистически значимым. Стоит отметить, что в связи с большим числом классов разработанный подход даже для R ( c ) =30 эталонов оказывается более точным по сравнению с остальными методами классификации.
Заключение
Таким образом, в настоящей работе предложена модификация ВНС (12)–(15), основанная на проекционных оценках плотности вероятности, которые используют систему тригонометрических функций и предположение о независимости признаков классифицируемого объекта. Показано, что разработанная модификация сохраняет основные преимущества оригинальной ВНС: сходимость к байесовскому решению, линейное время обучения и константная сложность дообучения. При этом предложенный подход является намного более эффективным с точки зрения вычислительной сложности и затрат памяти (выигрыш до ( R / C )2/3/2 раз) за счёт отказа от хранения признаков всех эталонов и обучения модели с помощью вычисления коэффициентов (12) усреднённого тригонометрического ряда (11). Результаты экспериментального исследования для признаков, извлечённых с помощью современных СНС Incep-tion,VGGNet и Light СНС, показали, что разработанная модификация не только во всех случаях оказывается предпочтительнее исходной ВНС, но и является наиболее точным классификатором для малого числа эталонных изображений.
Основным недостатком предложенного подхода по сравнению с классической ВНС является отсутствие в нём аналога выражения (4), в котором вычисляется расстояние между векторами признаков входного и эталонного изображения. В результате для нашей модификации оказывается недоступным повышение точности ВНС за счёт применения в (4) мер близости более сложных, чем метрика Евклида [5]. Кроме того, стоит отметить, что реализация предложенного подхода оказалась медленнее оригинальной ВНС при наличии очень малого (менее 5) числа эталонов для каждого класса в связи с оценкой отдельной плотности вероятности для каждого признака при вычислении выражения (6).
В то же время следует отметить необходимость проведения ряда дополнительных исследований. Прежде всего, следует оценить точность распознавания изображений для оценки плотности вероятности с помощью других известных ортогональных систем (например, многочленов Лагерра или Лежандра) [22, 23]. Также стоит проанализировать возможность адаптации разработанного метода к обработке больших данных, например, на основе последовательного анализа [48, 49] иерархического представления изображений [2] с применением предложенного подхода для предварительной отбраковки большинства классов и выбора окончательного решения с помощью одного из традиционны классификаторов. Наконец, представляет интерес исследование применимости предложенного подхода для признаков, выделенных СНС с небольшим числом параметров, таких как Mo-bileNet, SqueezeNet, в расчёте на их реализацию на мобильных устройствах.
Исследование выполнено при поддержке гранта президента РФ для молодых ученых – докторов наук № МД-306.2017 и Лаборатории алгоритмов и технологий анализа сетевых структур (ЛАТАС) Национального исследовательского университета Высшая школа экономики. Работа параграфов 3 и 4 выполнена за счёт гранта Российского научного фонда (проект № 14-41-00039).
Список литературы Тригонометрическая система функций в проекционных оценках плотности вероятности нейросетевых признаков изображений
- Prince, S.J.D. Computer vision: Models, learning, and inference/S.J.D. Prince. -Cambridge: Cambridge University Press, 2012. -598 p. -ISBN: 978-1-107-01179-1.
- Goodfellow, I. Deep learning/I. Goodfellow, Y. Bengio, A. Courville. -Cambridge, London: The MIT Press, 2016. -800 p. -ISBN: 9780262035613.
- Szegedy, C. Going deeper with convolutions/C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, A. Rabinovich//Proceedings of the 2015 IEEE International Conference on Computer Vision and Pattern Recognition (CVPR). -2015. -P. 1-9. - DOI: 10.1109/CVPR.2015.7298594
- Simonyan, K. Very deep convolutional networks for large-scale image recognition/K. Simonyan, A. Zisserman//arXiv preprint arXiv:1409.1556, 2014.
- Savchenko, A.V. Probabilistic neural network with homogeneity testing in recognition of discrete patterns set/A.V. Savchenko//Neural Networks. -2013. -Vol. 46. -P. 227-241. - DOI: 10.1016/j.neunet.2013.06.003
- Krizhevsky, A. ImageNet classification with deep convolutional neural networks/A. Krizhevsky, I. Sutskever, G.E. Hinton//Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS'12). -2012. -Vol. 1. -P. 1097-1105.
- Rassadin, A.G. Group-level emotion recognition using transfer learning from face identification/A.G. Rassadin, A.S. Gruzdev, A.V. Savchenko//Proceedings of the 19th ACM International Conference on Multimodal Interaction (ICMI). -2017. -P. 544-548. - DOI: 10.1145/3136755.3143007
- Sharif Razavian, A. CNN features off-the-shelf: an astounding baseline for recognition/A. Sharif Razavian, H. Azizpour, J. Sullivan, S. Carlsson//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW '14). -2014. -P. 806-813. - DOI: 10.1109/CVPRW.2014.131
- Savchenko, A.V. Maximum-likelihood approximate nearest neighbor method in real-time image recognition/A.V. Savchenko//Pattern Recognition. -2017. -Vol. 61. -P. 459-469. - DOI: 10.1016/j.patcog.2016.08.015
- Savchenko, A.V. Deep neural networks and maximum likelihood search for approximate nearest neighbor in video-based image recognition/A.V. Savchenko//Optical Memory and Neural Networks (Information Optics). -2017. -Vol. 26, Issue 2. -P. 129-136. - DOI: 10.3103/S1060992X17020102
- Raudys, S.J. Small sample size effects in statistical pattern recognition: Recommendations for practitioners/S.J. Raudys, A.K. Jain//IEEE Transactions on Pattern Analysis and Machine Intelligence. -1991. -Vol. 13, Issue 3. -P. 252-264. - DOI: 10.1109/34.75512
- Савченко, А.В. Метод максимально правдоподобных рассогласований в задаче распознавания изображений на основе глубоких нейронных сетей/А.В. Савченко//Компьютерная оптика. -2017. -Т. 41, № 3. -С. 422-430. - DOI: 10.18287/2412-6179-2017-41-3-422-430
- Pan, S.J. A survey on transfer learning/S.J. Pan, Q. Yang//IEEE Transactions on Knowledge and Data Engineering. -2010. -Vol. 22, Issue 10. -P. 1345-1359. - DOI: 10.1109/TKDE.2009.191
- Russakovsky, O. ImageNet large scale visual recognition challenge/O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A.C. Berg, F.-F. Li//International Journal of Computer Vision. -2015. -Vol. 115, Issue 3. -P. 211-252. - DOI: 10.1007/s11263-015-0816-y
- Theodoridis, S. Pattern recognition/S. Theodoridis, C. Koutroumbas. -4th ed. -Burlington, San Diego, London: Elsevier Inc., 2009. -840 p. -ISBN: 978-1-59749-272-0.
- Webb, A.R. Statistical pattern recognition/A.R. Webb. -2nd ed. -Chichester, England: John Wiley & Sons, Ltd., 2002. -ISBN: 978-0-470-84513-4.
- Савченко, А.В. Распознавание изображений на основе вероятностной нейронной сети с проверкой однородности/А.В. Савченко//Компьютерная оптика. -2013. -Т. 37, № 2. -С. 254-262. -ISSN 0134-2452.
- Specht, D.F. Probabilistic Neural Networks/D.F. Specht//Neural Networks. -1990. -Vol. 3, Issue 1. -P. 109-118. - DOI: 10.1016/0893-6080(90)90049-Q
- Kusy, M. Probabilistic neural network structure reduction for medical data classification/M. Kusy, J. Kluska//Proceedings of International Conference on Artificial Intelligence and Soft Computing (ICAISC). -2013. -P. 118-129. - DOI: 10.1007/978-3-642-38658-9_11
- Savchenko, A.V. Pattern classification with the probabilistic neural networks based on orthogonal series kernel/A.V. Savchenko//Proceedings of International Symposium on Neural Networks (ISNN 2016). -2016. -P. 505-512. - DOI: 10.1007/978-3-319-40663-3_58
- Čencov, N.N. Statistical decision rules and optimal inference/N.N. Čencov. -Providence, RI: American Mathematical Society, 2000. -ISBN: 978-0-8218-1347-8.
- Деврой, Л. Непараметрическое оценивание плотности. L1-подход/Л. Деврой, Л. Дьёрфи. -М.: Мир, 1988. -408 с. -ISBN: 5-03-000475-0.
- Efromovich, S. Nonparametric curve estimation: Methods, theory, and applications/S. Efromovich. -New York: Springer, 1999. -ISBN: 978-0-387-98740-8.
- Greblicki, W. Classification using the Fourier series estimate of multivariate density functions/W. Greblicki, M. Pawlak//IEEE Transactions on Systems, Man, and Cybernetics. -1981. -Vol. 11, Issue 10. -P. 726-730. - DOI: 10.1109/TSMC.1981.4308594
- Rutkowski, L. Sequential pattern recognition procedures derived from multiple Fourier series/L. Rutkowski//Pattern Recognition Letters. -1988. -Vol. 8, Issue 4. -P. 213-216. - DOI: 10.1016/0167-8655(88)90027-X
- Fei-Fei, L. One-shot learning of object categories/L. Fei-Fei, R. Fergus, P. Perona//IEEE Transactions on Pattern Analysis and Machine Intelligence. -2006. -Vol. 28, Issue 4. -P. 594-611. - DOI: 10.1109/TPAMI.2006.79
- Yi, D. Learning face representation from scratch/D. Yi, Z. Lei, S. Liao, S.Z. Li//arXiv preprint arXiv:1411.7923. -2014.
- Wasikowski, M. Combating the small sample class imbalance problem using feature selection/M. Wasikowski, X. Chen//IEEE Transactions on Knowledge and Data Engineering. -2010. -Vol. 22, Issue 10. -P. 1388-1400. - DOI: 10.1109/TKDE.2009.187
- Жердев, Д.А. Распознавание объектов по диаграммам рассеяния электромагнитного излучения на основе метода опорных подпространств/Д.А. Жердев, Н.Л. Казанский, В.А. Фурсов//Компьютерная оптика. -2014. -Т. 38, № 3. -С. 503-510.
- Савченко, В.В. Принцип минимума информационного рассогласования в задаче спектрального анализа случайных временных рядов в условиях малых выборок наблюдений/В.В. Савченко//Известия высших учебных заведений. Радиофизика. -2015. -Т. 58, № 5. -С. 415-422.
- Орлов, А.И. Развитие математических методов исследования (2006-2015 гг.)/А.И. Орлов//Заводская лаборатория. Диагностика материалов. -2017. -Т. 83, № 1-I. -С. 78-86.
- Shatskikh, S.Ya. Normality assumption in statistical data analysis/S.Ya. Shatskikh, L.E. Melkumova//CEUR Workshop Proceedings. -2016. -Vol. 1638. -P. 763-768. - DOI: 10.18287/1613-0073-2016-1638-763-768
- Лапко, А.В. Непараметрические модели распознавания образов в условиях малых выборок/А.В. Лапко, С.В. Ченцов, В.А. Лапко//Автометрия. -1999. -№ 6. -С. 105-113.
- Franti, P. Fast and memory efficient implementation of the exact PNN/P. Franti, T. Kaukoranta, D.-F. Shen, K.-S. Chang//IEEE Transactions on Image Processing. -2000. -Vol. 9, Issue 5. -P. 773-777. - DOI: 10.1109/83.841516
- Савченко, А.В. Об одном способе повышения вычислительной эффективности вероятностной нейронной сети в задаче распознавания образов на основе проекционных оценок/А.В. Савченко//Информационные системы и технологии. -2015. -№ 4(90). -С. 28-38.
- Rutkowski, L. Adaptive probabilistic neural networks for pattern classification in time-varying environment/L. Rutkowski//IEEE Transactions on Neural Networks. -2004. -Vol. 15, Issue 4. -P. 811-827. - DOI: 10.1109/TNN.2004.828757
- Duda, P. On the Cesaro orthogonal series-type kernel probabilistic neural networks handling non-stationary noise/P. Duda, J.M. Zurada//Proceedings of the 9th International Conference on Parallel Processing and Applied Mathematics (LNCS). -2012. -Vol. 7203, Pt. I. -P. 435-442. - DOI: 10.1007/978-3-642-31464-3_44
- Schwartz, S.C. Estimation of probability density by an orthogonal series/S.C. Schwartz//The Annals of Mathematical Statistics. -1967. -Vol. 38, Issue 4. -P. 1261-1265.
- Efromovich, S. Orthogonal series density estimation/S. Efromovich//Wiley Interdisciplinary Reviews: Computational Statistics. -2010. -Vol. 2, Issue 4. -P. 467-476. - DOI: 10.1002/wics.97
- Фихтенгольц, Г.М. Курс дифференциального и интегрального исчисления/Г.М. Фихтенгольц. -Т. 3. -М.: Физматлит, 2001. -662 с.
- Зорич, В.А. Математический анализ/В.А. Зорич. -Ч. 2. -М.: Наука, 1984. -640 с.
- Hall, P. On trigonometric series estimates of densities/P. Hall//Annals of Statistics. -1981. -Vol. 9, Issue 3. -P. 683-685.
- Новосёлов, А.А. Параметризация моделей управляемых систем/А.А. Новосёлов//Вестник Сибирского государственного аэрокосмического университета. -2010. -№ 5. -С. 52-56.
- Hart, J.D. On the choice of a truncation point in Fourier series density estimation/J.D. Hart//Journal of Statistical Computation and Simulation. -1985. -Vol. 21, Issue 2. -P. 95-116. - DOI: 10.1080/00949658508810808
- Система распознавания изображений . -URL: https://github.com/HSE-asavchenko/HSE_FaceRec/tree/master/src/recognition_testing (дата обращения 01.12.2017).
- Jia, Y. Caffe: Convolutional architecture for fast feature embedding/Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, T. Darrell//Proceedings of the 22nd ACM International Conference on Multimedia. -2014. -P. 675-678. - DOI: 10.1145/2647868.2654889
- Wu, X. A light CNN for deep face representation with noisy labels/X. Wu, R. He, Z. Sun, T. Tan//arXiv preprint arXiv:1511.02683. -2017.
- Savchenko, A.V. Fast multi-class recognition of piecewise regular objects based on sequential three-way decisions and granular computing/A.V. Savchenko//Knowledge-Based Systems. -2016. -Vol. 91. -P. 250-260. - DOI: 10.1016/j.knosys.2015.09.021
- Savchenko, A.V. Sequential three-way decisions in efficient classification of piecewise stationary speech signals/A.V. Savchenko//Proceedings of International Joint Conference on Rough Sets (IJCRS 2017). -2017. -Part II. -P. 264-277. - DOI: 10.1007/978-3-319-60840-2_19
