Улучшение методов детекции сгенерированных текстов

Автор: Балобин Д.Ю., Сомов О.Д.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Информатика и управление
Статья в выпуске: 3 (67) т.17, 2025 года.
Бесплатный доступ
Детекция сгенерированного текста – это задача классификации текста на естественном языке на два класса: сгенерированный языковой моделью и написанный человеком. Такие детекторы должны быть устойчивы к смене смыслового домена, генерирующей языковой модели и языка. В настоящий момент одни из наиболее эффективных детекторов состоят из одной или нескольких предобученных больших языковых моделей, дообученных на задачу классификации текста. Модели с лучшими показателями дополнительно используют статистические и контекстные признаки текста. В этой работе предлагается новая модель-детектор, которая достигает наивысшей целевой метрики точности среди известных решений при использовании намного меньших вычислительных ресурсов для обучения и применения. Этот детектор использует внутренние представления предобученной языковой модели без её дообучения как признаки для классических алгоритмов классификации. В ходе работы также получены новые результаты, показывающие высокую эффективность для данной задачи использования внутренних скрытых состояний предобученных языковых моделей и понижения размерности этих состояний.
Обнаружение сгенерированного текста, детекция сгенерированного текста, бинарная классификация
Короткий адрес: https://sciup.org/142245833
IDR: 142245833 | УДК: 004.891.2
Improved detection methods for generated texts
Artificial text detection is the task of classifying natural language text into two classes: generated by a language model and written by a human. Such detectors should be resistant to changes in the semantic domain, generating language model, and language. Currently, some of the most effective detectors consist of one or more pre-trained LLMs, fine-tuned for the text classification task. The models with the best accuracy additionally use statistical and contextual features of the text. In this paper, we propose a new detector model that achieves the highest accuracy among known solutions while using much smaller computational resources for training and inference. This detector uses the internal representations of the pre-trained language model without further training as features for classical classification algorithms. In the course of the work, new results were also obtained showing high efficiency for this task of using internal hidden states of pre-trained language models and reducing the dimensionality of these states.
Текст научной статьи Улучшение методов детекции сгенерированных текстов
Детекция сгенерированного текста - это задача классификации текста на естественном языке на два класса: сгенерированный и написанный человеком. В последнее время эта
(с) Валобип Д. Ю., Сомов О. Д., 2025
(с) Федеральное государственное автономное образовательное учреждение высшего образования «Московский физико-технический институт (пациопальпый исследовательский университет)», 2025
2. Данные для оценки
задача становится всё более актуальной в связи с появлением новых больших языковых моделей, способных создавать неотличимый с первого взгляда от человеческого текст.
В рамках данной работы предложен новый подход, который достигает наивысшей целевой метрики точности среди известных решений для английского языка и одной из самых высоких в многоязычном случае. В отличие от других существующих методов, достигающих высоких результатов путём дообучения языковых моделей [1] и их ансамблирования [2] или обучения большего числа параметров поверх неизменных параметров языковых моделей [3], предложенный подход использует меньшую по количеству параметров языковую модель и требует меньше вычислительных ресурсов. При этом не требуется производить какие-либо модификации архитектуры, дообучение базовой модели, изменение процесса обучения или целевой функции.
В ходе реализации этого подхода получены новые результаты, показывающие высокую эффективность использования конкретных внутренних состояний предобученных языковых моделей и метода анализа главных компонент в качестве признаков для классических алгоритмов классификации.
В рамках данного исследования для замера эффективности подхода был выбран дата-сет из соревнования SemEval 2024: Task 8 Subtask А [4], так как он учитывает три смещения в данных: тексты в нём принадлежат различным непохожим друг на друга смысловым доменам, сами генерации созданы несколькими различными актуальными в данный момент и не родственными между собой языковыми моделями, а также они написаны на различных языках. Рассматриваемая подзадача предполагает бинарную классификацию отдельно одноязычных или многоязычных текстов. В данной работе фокус направлен на одноязычную версию, однако на мультиязычном наборе данных подход показывает высокие метрики.
В валидационной выборке одноязычного датасета представлены тексты, сгенерированные только непредставленной в обучающей выборке моделью, а в тестовой к списку моделей-источников добавлена GPT-4, что обеспечивает сдвиг данных на этапе замера целевых метрик. Сдвиг тематики реализован за счёт использования в тестовой выборке текстов из набора Outfox [5], никак не представленного в обучающей и валидационной.
В мультиязычной версии фокус смещён со смены тематического домена на смену языка. Ни одного языка обучающей выборки не представлено в валидационной, а в тестовой представлены тексты на языках, как встречавшихся в обучающей и валидационной выборках, так и нет. Набор генерирующих моделей при тестировании также дополняется неизвестными ранее, однако общий их список отличается от моноязычной версии.
Целевая метрика для этих наборов данных - accuracy. Тестовые наборы почти сбалансированы - 47% в моноязычных или 48% в мультиязычных тестовых текстов написаны людьми.
3. Модель
Предложенная модель ECAT (Embeddings Compression for Artificial Text detection) изображена на рис. 1 и состоит из трёх компонент:
• Предобученная большая языковая модель, которая используется для получения внутренних скрытых состояний текста из конкретного слоя.
• Метод анализа главных компонент, снижающий размерность скрытого состояния.
• Классический алгоритм классификации, обучаемый на полученных признаках.
3.1. Получение признаков
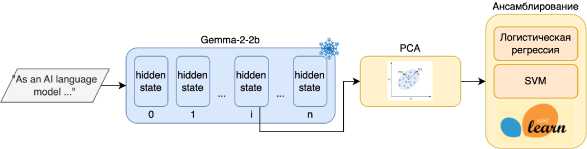
Рис. 1. Схема предложенной модели. Входной текст токенизируется и проходит через предобучен-ную языковую модель, скрытое состояние извлекается из конкретного слоя декодировщика через mean pooling. Обучаемая часть системы состоит из PC А, снижающего размерность скрытого состояния, и классификатора, обучаемого на полученных признаках
Скрытые состояния текста на первом этапе берутся из внутренних слоёв модели gemma-2-2b-it [6]. Это инструктивная версия многослойного декодировщика типа трансформер с 2 миллиардами параметров, полученная методом дистилляции из большей по количеству параметров модели того же семейства.
Последовательность токенов А = (х1 ,х2,...,хп ) подаётся на вход языковой модели. Затем полученные эмбеддинги токенов последовательно пропускаются через L слоёв трансформера, в каждом из которых вычисляются скрытые состояния. Итоговая матрица внутренних состояний Н после прохождения всех слоёв трансформера имеет размерность:
Н = transformer(X) Е RNxLxD, где N — количество токенов в последовательности, D — размерность скрытых состояний.
Чтобы получить внутреннее векторное представление всей последовательности X, эта матрица состояний агрегируется средним арифметическим по первой размерности количества токенов и имеет размерность Havg Е RLxD. Далее под скрытым состоянием текста на конкретном слое I Е {1,..., L} понимается вектор hi = Havg [I] Е RD.
У рассматриваемой модели параметры D = 2304, L = 27, максимальный N = 8192.
3.2. Снижение размерности признаков
Для снижения размерности скрытых состояний используется метод анализа главных компонент (PCА) с алгоритмом ARPACK [7] для решения SVD. Размерность каждого вектора hi после применения алгоритма снижается до D ', где D' < D.
3.3. Классификация
Для классификации на этапе подбора гиперпараметров использовалась логистическая регрессия, обученная на векторах скрытых состояний hr Для финальной классификации используется ансамбль из SVM и логистической регрессии - их предсказания вероятностей объединяются путём усреднения (soft voting) и бинаризируются по порогу 0.5.
3.4. Обучение
Веса выбранной языковой модели не дообучаются и не модифицируются. Для остальных компонентов все гиперпараметры обучения, помимо отдельно обозначенных выше, также остаются по умолчанию, за исключением размерности снижения скрытых состояний D' и индекса слоя трансформера Z, скрытые состояния которого и используются системой для дальнейшей классификации.
Гиперпараметры оптимизируются последовательно. Сначала для каждого индекса слоя Z от 1 до L получается оптимальный ему гиперпараметр D'. Он выбирается из неоднородного промежутка [4,128] для одноязычного случая и из [4, 896] для многоязычного по метрике F1 на предусмотренной датасетом валидационной выборке, составляющей 4% (2% для многоязычного набора) размера обучающей.
Затем выбирается набор кандидатов из возможных пар (ЦП’) D’ в которых стремится к оптимальной медиане (рис. 2). В итоге на тренировочной и валидационной выборках учится несколько классификаторов и оцениваются на тестовой.
—•— Оптимальное значение
--- Медиана
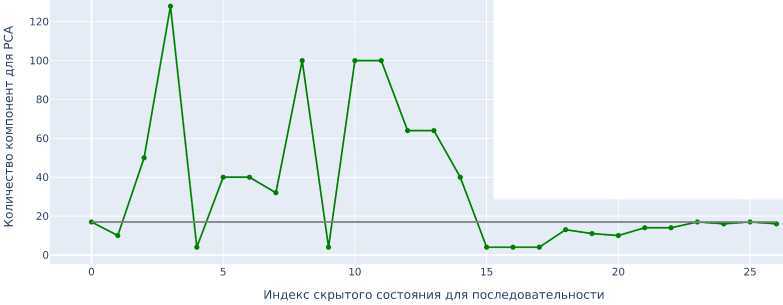
Рис. 2. Оптимальное D' для каждого слоя на моноязычном наборе
4. Результаты
Описанный выше подход достигает наивысшей целевой метрики точности среди известных решений на одноязычных данных (табл. 1) и одну из самых высоких на многоязычных (табл. 2). Ранг с обозначением * для предложенной модели означает, что такое место решение заняло бы в соревновании, будь оно представлено до дедлайна.
Таблица!
Сравнение точности на тестовом моноязычном наборе
|
Ранг |
Модель |
accuracy |
|
78 |
KInIT |
0.727 |
|
27 |
FI Group |
0.853 |
|
16 |
Бейзлайн roberta |
0.885 |
|
2 |
USTC-BUPT |
0.961 |
|
1 |
Genaios |
0.969 |
|
1 * |
EC AT |
0.979 |
Таблица2
Сравнение точности на тестовом многоязычном наборе
|
Ранг |
Модель |
accuracy |
|
36 |
Genaios |
0.757 |
|
18 |
Бейзлайн roberta |
0.809 |
|
2 |
FI Group |
0.959 |
|
1 |
USTC-BUPT |
0.96 |
|
1 * |
KInIT |
0.971 |
|
д * |
EC AT |
0.953 |
Наиболее информативными скрытыми состояниями для этой задачи оказались те, что имеют индекс, близкий к Д но не равный ему. Оптимальным слоем в случае одноязычной классификации оказался I = 24, для многоязычной в этой работе было зафиксировано то же значение гиперпараметра.
Понижение размерности почти для всех скрытых состояний значительно повышает эффективность итоговой модели классификации (рис. 3) — в среднем на 11.5% или на 14%, если учесть только положительные влияния. Оптимальное количество компонент PC А для английского языка D‘ = 16. На многоязычном наборе среднее оптимальное D ‘ для всех слоёв больше, в итоговой модели оно равно 40. Это говорит о том, что по сравнению с обобщением на различные тематики на одном языке для обобщения модели на разные языки требуется больше информации.
Финальные метрики модели на многоязычной версии датасета при добавлении в классификационную голову SVM падали почти на 5%, поэтому в табл. 2 метрики приведены для классификатора только на логистической регрессии с оптимальным Dr2 4.
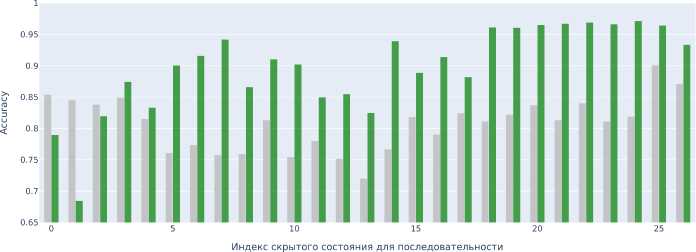
Рис. 3. Влияние применения PC А на целевую метрику на моноязычной тестовой выборке
5. Заключение
Результаты проведённого исследования демонстрируют, что внутренние скрытые состояния трансформеров содержат важную информацию, позволяющую повысить качество систем детекции сгенерированных текстов. Для рассматриваемой задачи наиболее информативными оказались те скрытые состояния, которые извлекаются из слоёв между серединой и концом блока декодировщика, хотя традиционно для задач классификации последовательностей используются финальные. Это может объясняться тем, что на ранних слоях формируются более общие признаки текста, тогда как ближе к выходу происходят более глубокие изменения этих признаков, а выход фокусируется непосредственно на генерации.
Уменьшение размерностей усреднённых векторов скрытых представлений всей последовательности алгоритмами анализа значимых компонент дополнительно повышает эффективность классификатора. Это подтверждается динамикой оптимального количества компонент PC А — в среднем от первых слоёв к последним оно уменьшается и стремится к 16 для моноязычного случая.
Важным преимуществом предложенного метода является то, что без дообучения параметров большой языковой модели и с использованием меньших вычислительных ресурсов он позволяет извлекать информативные признаки и показывает наилучшую на данный момент эффективность на рассматриваемом наборе данных.
В будущем возможно развитие метода за счёт тестирования на других моделях увеличенного размера, рассмотрения более сложных алгоритмов классификации. Неисследованной остаётся подверженность предложенного подхода атакам различных типов [8]. Также важным направлением будет исследование возможности более простого выбора наиболее оптимального скрытого состояния для различных прикладных задач классификации текста.
