Using publications linked open data to define organizational policies

Author: Muhammad Ahtisham Aslam
Journal: International Journal of Information Engineering and Electronic Business @ijieeb
Article in issue: 5 vol.10, 2018.
Free access
Researchers around the world are publishing their scientific research results in different forms such as books, journal articles, reference works and project reports. Publishers of these scientific documents usually describe them by using metadata for organizational purposes. This metadata provides a rich information about scientific documents that can be used for analysis purposes such as measuring the impact of researchers and research centers. It can also be used to find scientific documents published in domain of some ones interest, which ultimately can be used to raise the state of the art to the next level. Scientific publications metadata can also be used to analyze the quality and directions of common and highly cited individuals and organizations, and based on this analysis other individuals and organizations can define directions for their future work and research. However, the main limitation of this metadata is that it is available in different formats that might not facilitate the analysis of scientific documents. Therefore, in this paper we clarify that how our SPedia knowledge base (a semantic based knowledge base of scientific publications metadata which we extracted by using SpringerLink as information source) facilitates the analysis of scientific data for policy making. We discuss different kind of questions that can be answered through SPedia knowledge base and we show that how results of these questions can be used to analyze the performance of individuals as well as organizations. We also show that how results of such analysis can help in making organizational policies regarding future research directions.
Linked open data, policy making, RDF, knowledge representation, data analysis, reasoning
Short address: https://sciup.org/15016145
IDR: 15016145 | DOI: 10.5815/ijieeb.2018.05.02
Text of the scientific article Using publications linked open data to define organizational policies
Published Online September 2018 in MECS DOI: 10.5815/ijieeb.2018.05.02
Semantic Web and Linked Open Data (LOD) communities have been working since more than a decade on knowledge representation and reasoning technologies. The purpose is to make the existing data available in such a format that it can be used to link to
1 ˜
2 other existing datasets as well as to make the data available in such a format that it can be used to make queries (rather than to have only textual data) and results of queries can be used for analysis purposes. The languages such as RDF, RDF-S and OWL can be used for knowledge representation and reasoning on existing data. Translating the metadata of scientific documents in a format (such as RDF data) which can be used to make queries as well as to link with other open datasets can be helpful [6]. Representing and developing the schema of such domain knowledge by using reasoning language such as RDF-S and OWL can be helpful in machine understanding and analysis on the indirect data.
To address these limitations, we make use of SPedia [7], [8] RDF datasets. SPedia is a semantically enriched knowledge base which we extracted by taking SpringerLink as source. SPedia provides information on about eight and half million scientific publications and has datasets that consist of about approximately three hundred million RDF triples. We also demonstrate the use of SPedia SPARQL endpoint [9] to perform different types of analysis such as analyzing author’s trend in writing different types of documents, finding multiauthorship trends in different disciplines, finding the citation patterns of research articles, reference chains, authors indexing, and collaboration patterns and so on. Results of such analysis can be used in understanding research trends and styles and then to make policies accordingly to define the research directions for the future. At the same time these RDF datasets can be used to link with other existing open datasets in the Linked Open Data Cloud to create improved and enhanced knowledge graphs. Querying to such bigger knowledge graph, for sure can produce better and quality results which ultimately can be used for analysis purpose. In next stage results of such analysis can be used for the policy making purposes.
The remaining paper is organized as follows: related work is discussed in the Section II. In Section III we describe the SPedia knowledge base. Statistics of SPedia datasets are described in the Section IV. Then we describe use case and potential applications of using linked open data of scientific publications in Section V. Finally Section VI concludes our work.
-
II. Related Work
Analyzing publications data is useful for both universities and research institutes in policy making. Several internal (within university) and external (outside university) factors play a key role for improved policy making to support science, technology and innovation (STI) [4]. Debackere and Glnzel [10] show how the publication data is used first time by Flemish government to allocate around 93 million Euro among 6 universities for fiscal year 2003. They defined a methodology and instrument as component of research funding policy making on the Web-of-Science SCI data.
Ventura and Mombr [11] made use of bibliometric information to help in making research policy. They compared the publication and citation profiles of School of Chemistry, Uruguay Associate and Full Professors. They suggested that number of citations and number of papers per year allowing a bi-dimensional ranking of the individuals, can be used as a component in policy making for promotion of Associate Professors. They also suggested that for further deep and accurate analysis different qualitative and quantitative parameters can be considered.
Hassan et al., [12] discussed recent ties between STI and policy making. They devised a methodology to highlight the South Asian Countries research strengths and research activity association between South Asian countries and European Union. And suggested that results can be used to make improved STI related policy making. Results of this study focused on different levels of collaborations between different kinds of stake holders targeting the improved joint research patterns.
Jimnez-Sez et al., [13] investigated that who leads research productivity growth and found that the policy makers who were able to create comprehensive research groups through their policies were successful. As they found that the comprehensive research groups are major contributors of the fruitful STI systems. This study also founded that the more the collaborations between research groups, the more qualitative and quantitative research could be produced.
Chan et al., [4] conducted a very interesting study to analyze the correlation between researcher external success (presence on the web, TED talk invitation, or New York Times bestselling book success), internal success within university (number of papers and citations received) and his speaking fee. Initially, all variables and found correlated with speaking fee but once external impact is controlled, internal success factors within university were no longer statistically significant. It shows that how the individual’s research and organization performance is correlated to different variables and factors and how the values can vary the results of research contribution of every individual and organizations as a whole.
Huang et al., [14] investigated the evolution of the Chinas scientific research policies from 1949-2010, and core government agencies role in policy making using publications data. They found that main focus of policies was on applied research and industrialization as compared to basic research. They also found that number of agencies for making policies are increasing day by day, but collaboration among the agencies is not significantly increasing to help each other to improve policies. Results of such analysis directed the government bodies to define future polices in a way to maximize the collaboration between government agencies and to define future policies based on the joint analysis of these organizations.
Turko et al., [15] analyzed the Russian Government program 5-top 100 to increase universities competitiveness. The program defined policies for Russian universities for being ranked among top in the world rankings. Next year university funding and current year performance were found directly proportional. The program found effective for gaining top positions in the world universities rankings by prioritizing university aims and enhancing its worth. Recently, Daraio et al., [16] proposed a method for data management which is based on ontology to identify, maintain and integrate the data required for STI policy making. They implemented Sapientia, an ontology of multidimensional research assessment. Sapientia offers a transparent platform for assessment process. They claimed that simple access mechanism for publication data can let us better understand science and presentation of research outcomes to more people.
Above mentioned related work shows the value of analyzing scientific publication data in defining organizational polices. Better represented publications data will produce better analytical results based on reasoning of existing data and results of such analysis can definitely play role in defining better policies. In this paper we also focus on analyzing scientific publications data by making use of SPedia knowledge base [7], [8] (a semantically enriched repository of scientific publications data) to facilitate organizational policy making for STI in a simpler way like Sapientia [16].
-
III. SPEDIA Knowledge Base
The Springer portal (i.e. SpringerLink) provides access to more than ten million documents. This portal is also a gateway to metadata of these publications. This metadata is available in textual format and is not very well usable for analysis purposes by applying data mining and semantic Web techniques. As a solution, we processed this metadata of around nine million scientific documents and represented it in RDF format so that it can be used to answer complex queries by using SPARQL protocol [17], [18].
SPedia [7], [8] is the semantic Web based knowledge repository that we extracted by using SpringerLink as information source. Figure 1 shows the process that we used to parse metadata of scientific documents and produce RDF datasets. It also shows the SPedia extraction process and our approach about how we consider the link of the source portal as input and process each and every document to extract its metadata to produce related RDF datasets. The SPedia extraction process considers every document as a resource, extracts its metadata and produce the RDF datasets for every property of every document. Actually these properties are mapped/used to establish links between different resources and then used to query the data based on different attributes such as number of authors, years, collaboration between authors.
RDF datasets can be loaded to any Triple Store Server and used to make SPARQL queries that otherwise is not possible. SPARQL queries that are executed against the RDF datasets provide direct as well as indirect relations (semantics) data, making the results and knowledge graph [19], [20] more and more bigger. The bigger knowledge graph ultimately results in accurate and more precise results which ultimately can be used to define accurate and long term polices. The results of SPARQL queries can be numbers which can also be converted to statistical graphs for further analysis purpose as well as real life data for quality assurance purposes. RDF datasets, when linked to other datasets can produce better and more accurate results and can also be used to create linked open scientific profiles for collaboration and knowledge sharing purposes.
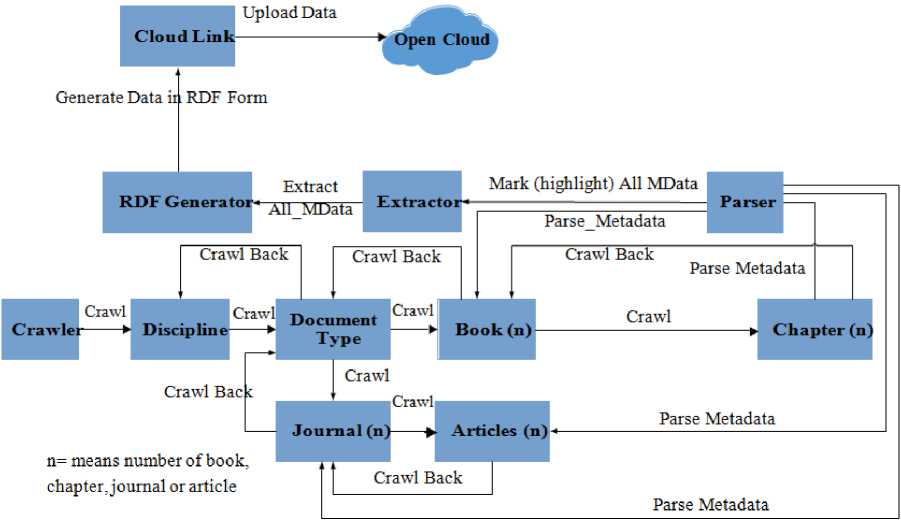
Fig.1. Process to extract document’s metadata and to produce RDF datasets.
These property level datasets makes it easier to load just those files in the triple store servers which are required to perform analysis or experiments. We can also use the SPedia SPARQL endpoint to query from the complete datasets.
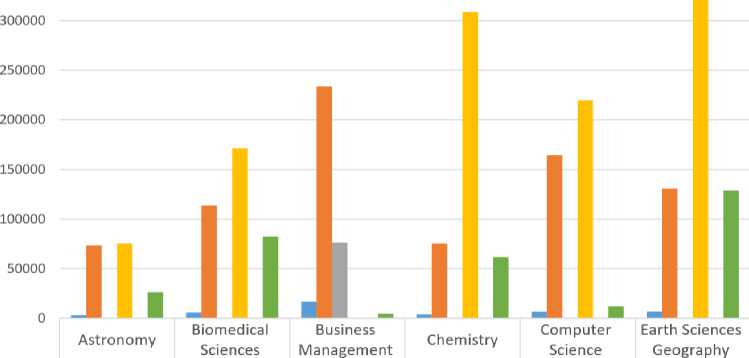
■ Book 2942 5644 16728 3815 6610 6774
■ Chapter | 73466 113615 | 233609 f 75262 164244 ~|~ 130857
■ Journal I 22 54 ~[ 76437 | 56 258 | 208
■ Article 75224 171188 40 308768 219724 321280
■ Reference Work 23 127 22 84 49 71
■ Ref Work Entry 26279 82364 4500 61567 11939 128783
-
■ Book ■ Chapter ■ Journal ■ Article ■ Reference Work ■ Ref Work Entry
Fig.2. Discipline wise statistics of RDF datasets extracted for different types of documents.
-
IV. SPEDIA Datasets Statistics
Datasets of SPedia repository are available on the project website3 for download. Users can download these datasets for local experiments and analysis purposes. We have also established a SPARQL endpoint that can be used to make queries over the SPARQL protocol. SPedia datasets consist of approximately three hundred million RDF triples which provide data about eight and half million scientific publications. Figure 2 provides some sample discipline wise statistics of every kind of documents such as reference works, journals, books, chapters, articles, and reference work entries.
Advancements in automated information extraction can be used to extract, produce and link [21] the data about scientific documents published by different publishers and to create a linked open data cloud of scientific publications data, which ultimately can help researchers and scientist to pose semantically enriched queries to find scientific publications as well as researchers with matching interests and similar domains of research. For this purpose in SPedia that sets have been extracted in RDF format so that we can query this data by using SPARQL protocol.
-
V. Use Case And Potential Applications Of SPEDIA
SPedia can be used to perform multi-purpose analysis based on different factors. For example, SPedia datasets can be used to find the citation network between authors, journals or organizations. Such kind of analysis can help to find that how much citation diversity a particular scientific document has. The citation diversity can be used to analyze the multi-domain research as well as research collaboration of individuals as well as organizations. We can also analyze the multi-author publication trend during different periods of time. Such kind of analysis can help organizations to find collaboration and joint research trends in different disciplines. We can also use SPedia datasets to analyze the existing publications trends such as to analyze that either authors prefer to publish as single author or jointly with other researchers. Results of such analysis can be used to find collaboration trends which ultimately can be used to define organizational policies such as promotion criteria for employees.
Books and Authors
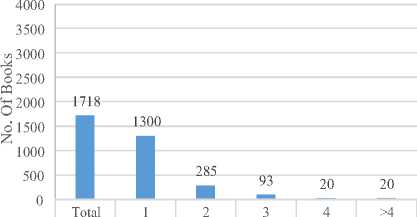
■Books 1718 1300 285 93 20 20
No. Authors
Books and Editors
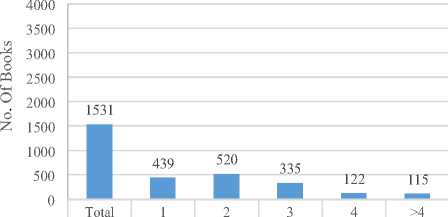
■Books 1531 439 520 335 122 115
No. of Editors
( a ) ( b )
Books and Authors Books and Editors
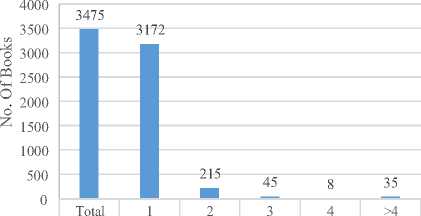
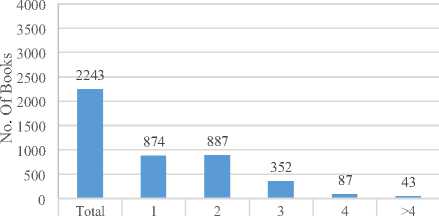
-
■Books 3475 3172 215 45 8 35 ■ Books 2243 874 887 352 87 43
No. Authors No. of Editors
( c )
( d )
-
Fig.3. Statistics of multi-author trend in books writing and editing.
The Figure 3 (c) shows that author’s trend in writing books as solo author is much more than writing books with multi-authors. The Figure 3 (d) shows that publishing the edited books as single or two authors has very close trend than to edit book with more than two authors. Now we can use this analysis in assigning marks to written as well as edited books in defining promotion criteria as well as we can use it to define our future vision in book and article writing. Such analysis may help in covering the week aspects of an organization’s research.
PREFIX spr:<>
PREFIX rdf: <>
SELECT (count(?book) as ?TotalBooks) (count(?book1) as ?book1count) (count(?book2)as ?book2count)
(count(?book3)as ?book3count) (count(?book4)as ?book4count)(count(?bookM)as ?bookMorecount) where{
{SELECT ?book (count(?bookAuthor) as ?bookAuthors) WHERE {
?book rdf:type spr:Book.
?book spr:has_Author ?bookAuthor.
}
GROUP
BY ?book } union {
SELECT ?book1 (count(?book1Author) as ?book1Authors) WHERE {
?book1 rdf:type spr:Book.
?book1 spr:has_Author ?book1Author.
}
GROUP BY ?book1
having(?book1Authors=1)
union{
SELECT ?book2 (count(?book2Author) as ?book2Authors) WHERE {
?book2 rdf:type spr:Book.
?book2 spr:has_Author ?book2Author.
}
GROUP BY ?book2
having(?book2Authors=2)
union{
SELECT ?book3 (count(?book3Author) as ?book3Authors) WHERE {
?book3 rdf:type spr:Book.
?book3 spr:has_Author ?book3Author.
}
GROUP BY ?book3
having(?book3Authors=3)
union{
SELECT ?book4 (count(?book4Author) as ?book4Authors) WHERE {
?book4 rdf:type spr:Book.
?book4 spr:has_Author ?book4Author.
}
GROUP BY ?book4
having(?book4Authors=4)
}
}
Fig. 4. Sample SPARQL query to extract results of multi-author trend in books writing and editing.
VI. Conclusion
In this paper we presented potential applications of SPedia : a semantically enriched knowledge base of scientific publications metadata. We also described our data extraction process that we used to parse, extract the metadata and then to produce RDF datasets. We described in detail that how such metadata can be used by organizations to evaluate the research contribution and performance of individual researchers as well as departments. As a proof of concept, we applied sample SPARQL queries to SPedia dataset to find the multiauthor trend in book writing. Analysis of such queries showed that multi-author trend in writing books is different than multi-author trend in editing books. From analysis of such results we suggested that organizations need to define polices to improve collaboration pattern in booking writing. Such policies can help in improving the joint research and scientific writing among researchers. We also showed that how such analysis can be used to motivate individual researchers as well as to refine future research policies of organizations. Our linked open data of scientific documents can also be used for multiple purposes such as to find citation graphs between authors and institutions, analyze the organizational performance and to analyze the acceptance of researchers at global scale.
As part of future work, we are continuously increasing the scope of datasets by linking it with metadata of other publisher’s documents. We are also working on using the contents of scientific documents, the context in which a particular content is being used and then applying ontological reasoning and data mining techniques to find the links between different research contributions.
References Using publications linked open data to define organizational policies
- N. Piedra, J. Chicaiza, J. Atenas, J. Lopez-Vargas, and E. Tovar, Using Linked Data to Blended Educational Materials With OER—A General Context of Synergy: Linked Data for Describe, Discovery and Retrieve OER and Human Beings Knowledge to Provide Context. Berlin, Heidelberg: Springer Berlin Heidelberg, 2017, pp. 283–313.
- J. Chicaiza, N. Piedra, J. Lopez-Vargas, and E. Tovar-Caro, “Domain categorization of open educational resources based on linked data,” in Knowledge Engineering and the Semantic Web, P. Klinov and D. Mouromtsev, Eds. Cham: Springer International Publishing, 2014, pp. 15–28.
- D. Burkhardt, K. Nazemi, W. Retz, and J. Kohlhammer, “Visual explanation of government-data for policy making through open-data inclusion,” in The 9th International Conference for Internet Technology and Secured Transactions (ICITST-2014), Dec 2014, pp. 83–89.
- H. F. Chan, B. S. Frey, J. Gallus, M. Schaffner, B. Torgler, and S. Whyte, “Do the best scholars attract the highest speaking fees? an exploration of internal and external influence,” Scientometrics, vol. 101, no. 1, pp. 793–817, 2014. [Online]. Available: http://dx.doi.org/10.1007/s11192014-1379-3
- B. Aleman-Meza, F. Hakimpour, I. B. Arpinar, and A. P. Sheth, “Swetodblp ontology of computer science publications,” Web Semantics: Science, Services and Agents on the World Wide Web, vol. 5, no. 3, pp. 151 – 155, 2007. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S1570826807000121
- R. Manrique, O. Herazo, and O. Marino, “Exploring the use of linked˜ open data for user research interest modeling,” in Advances in Computing, A. Solano and H. Ordonez, Eds.˜ Cham: Springer International Publishing, 2017, pp. 3–16.
- M. A. Aslam and N. R. Aljohani, “SPedia: A semantics based repository of scientific publications data,” in Web-Age Information Management: 17th International Conference, WAIM 2016, Nanchang, China, June 3-5, 2016, Proceedings, Part I, B. Cui, N. Zhang, J. Xu, X. Lian, and D. Liu, Eds. Cham: Springer International Publishing, 2016, pp. 479–490.
- M. A. Aslam and N. R. Aljohani, “SPedia: A Central Hub for the Linked Open Data of Scientific Publications,” International Journal on Semantic Web and Information Systems (IJSWIS), vol. 13, no. 1, pp. 128–146, 2017. [Online]. Available: http://www.igi-global.com/article/SPedia/172426
- G. Gombos and A. Kiss, SPARQL Processing over the Linked Open Data with Automatic Endpoint Detection. Cham: Springer International Publishing, 2014, pp. 183–192.
- K. Debackere and W. Glanzel, “Using a bibliometric approach to¨ support research policy making: The case of the flemish bof-key,” Scientometrics, vol. 59, no. 2, pp. 253–276, 2004. [Online]. Available: http://dx.doi.org/10.1023/B:SCIE.0000018532.70146. 02
- O. N. Ventura and A. W. Mombru, “Use of bibliometric information to´ assist research policy making. a comparison of publication and citation profiles of full and associate professors at a school of chemistry in uruguay,” Scientometrics, vol. 69, no. 2, pp. 287–313, 2006. [Online]. Available: http://dx.doi.org/10.1007/s11192-006-0154-5
- S.-U. Hassan, P. Haddawy, P. Kuinkel, A. Degelsegger, and C. Blasy, “A bibliometric study of research activity in asean related to the eu in fp7 priority areas,” Scientometrics, vol. 91, no. 3, pp. 1035–1051, 2012. [Online]. Available: http://dx.doi.org/10.1007/s11192-012-0665-1
- F. Jimenez-S´ aez, J. M. Zabala-Iturriagagoitia, and J. L. Zof´ ´ıo, “Who leads research productivity growth? guidelines for r&d policy-makers,” Scientometrics, vol. 94, no. 1, pp. 273–303, 2013. [Online]. Available: http://dx.doi.org/10.1007/s11192-012-0763-0
- C. Huang, J. Su, X. Xie, X. Ye, Z. Li, A. Porter, and J. Li, “A bibliometric study of china’s science and technology policies: 1949–2010,” Scientometrics, vol. 102, no. 2, pp. 1521–1539, 2015. [Online]. Available: http://dx.doi.org/10.1007/s11192-014-1406-4
- T. Turko, G. Bakhturin, V. Bagan, S. Poloskov, and D. Gudym, “Influence of the program “5–top 100” on the publication activity of russian universities,” Scientometrics, vol. 109, no. 2, pp. 769–782, 2016. [Online]. Available: http://dx.doi.org/10.1007/s11192- 016-2060-9
- C. Daraio, M. Lenzerini, C. Leporelli, H. F. Moed, P. Naggar, A. Bonaccorsi, and A. Bartolucci, “Data integration for research and innovation policy: an ontology-based data management approach,” Scientometrics, vol. 106, no. 2, pp. 857–871, 2016. [Online]. Available: http://dx.doi.org/10.1007/s11192-015-1814-0
- M. Schmidt, M. Meier, and G. Lausen, “Foundations of sparql query optimization,” in Proceedings of the 13th International Conference on Database Theory, ser. ICDT ’10. New York, NY, USA: ACM, 2010, pp. 4–33. [Online]. Available: http://doi.acm.org/10.1145/1804669.1804675
- P. Peng, L. Zou, M. T. Ozsu, L. Chen, and D. Zhao, “Processing¨ sparql queries over distributed rdf graphs,” The VLDB Journal, vol. 25, no. 2, pp. 243–268, Apr. 2016. [Online]. Available: http://dx.doi.org/10.1007/s00778-015-0415-0
- F. Kerdjoudj and O. Cure, “RDF knowledge graph visualization from´ a knowledge extraction system,” CoRR, vol. abs/1510.00244, 2015. [Online]. Available: http://arxiv.org/abs/1510.00244
- R. Chawuthai and H. Takeda, “Rdf graph visualization by interpreting linked data as knowledge,” in Semantic Technology, G. Qi, K. Kozaki, J. Z. Pan, and S. Yu, Eds. Cham: Springer International Publishing, 2016, pp. 23–39.
- S. Elbassuoni, M. Ramanath, R. Schenkel, and G. Weikum, “Searching RDF graphs with SPARQL and keywords,” IEEE Data Eng. Bull., vol. 33, no. 1, pp. 16–24, 2010. [Online]. Available: http://sites.computer.org/debull/A10mar/weikum-paper.pdf
