Выделение текстовых блоков из зашумленного изображения

Автор: Цацорин Евгений Анатольевич, Бахвалов Лев Алексеевич
Журнал: Горные науки и технологии @gornye-nauki-tekhnologii
Статья в выпуске: 6, 2011 года.
Бесплатный доступ
В данной статье приведено краткое описание шумов, воздействию которых поддаются изображения в процессе оцифровки и сжатия. Дано описание штрихового фильтра и способ его приложения к поиску текстовых блоков на изображении. Предложены два способа ускорения процесса обработки и приведено сравнение штрихового фильтра с другими часто использующимися в современной практике фильтрами.
Локализация текстовых блоков, распознавание текста, выделение текстовых блоков
Короткий адрес: https://sciup.org/140215344
IDR: 140215344 | УДК: 004.931,
Текст научной статьи Выделение текстовых блоков из зашумленного изображения
При вводе графической информации, она поддается значительному искажению, проще говоря на нее воздействуют различные шумы. Можно классифицировать эти шумы на несколько видов.
Цифровой шум — дефект изображения, вносимый фотосенсорами и электроникой устройств, которые их используют (цифровой фотоаппарат, теле-/видеокамеры и т. п.). Цифровой шум проявляется в виде случайным образом расположенных элементов растра (точек), имеющих размеры близкие к размеру пикселя. Цифровой шум отличается от изображения более светлым или тёмным оттенком серого и цвета (яркостный шум англ. luminance noise) и/или по цвету (хроматический шум англ. chrominance noise).
Шум квантования — ошибки, возникающие при оцифровке аналогового сигнала. В зависимости от типа аналого-цифрового преобразования могут возникать из-за округления (до определённого разряда) сигнала или усечения (отбрасывания младших разрядов) сигнала.
Артефакты сжатия — это заметные искажения изображения вызываемые сжатием с потерями. Так, например, артефакты сжатия JPEG и MPEG при большом коэффициенте сжатия представляют из себя прямоугольные поля одного цвета, которые могут принимать довольно крупный размер в одноцветных областях изображения. Также они снижают чёткость.
Человеческий фактор. Встречающиеся в реальной жизни тексты обычно далеки от совершенства, грязные изображения здесь наиболее очевидная проблема, потому что даже небольшие пятна могут затенять определяющие части символа или преобразовывать один в другой. Также проблемой является неаккуратное сканирование документа.
Для быстрой локализации текстовых блоков на зашумленном изображении предлагается использовать модифицированный алгоритм поиска штрихов [2]. Основные предположения, на которых строится алгоритм следующие:
Штрих отличается от своих прилегающих боковых регионов;
Его прилегающие боковые регионы подобны друг другу;
Эти регионы примерно однородны.
Для каждого пикселя изображения строится его отображение, при этом в построении участвуют три прямоугольных региона (Рис. 1) . Центральная точка – это пиксель, для которого строится отображение, вокруг которого расположены три прямоугольных региона. Пусть под номером 1 будет центральный регион, а под номерами 2,3 – боковые прилегающие регионы. Ориентация и размер этих регионов описываются основными параметрами α, l, w, где α – угол наклона угол наклона прямоугольных областей к горизонтали, l – длина прямоугольных областей, w – ширина прямоугольных областей. Задан также интервал w 2 между боковыми прямоугольными областями и центральным, так как при сжатии изображения контур текста может оказаться искаженным, либо для того чтобы отделить текст от фона он может быть заключен в темные или светлые контуры (Рис. 2) .
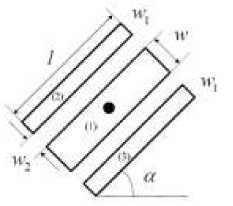
Рис. 1. Описание прямоугольных регионов штрихового фильтра
Рис. 2. Пример текста, заключенного в контур
Результат отображения для каждого пикселя изображения строится согласно:
Rd (x, y)
' 2
(1) ,
где µ i – рассчитанная средняя величина яркости i-го региона.
Реакция фильтра пропорциональна сумме модулей |µ1- µ2| + |µ1- µ3| и обратно пропорциональна модулю |µ2- µ3|. σ – среднеквадратичное отклонение яркостей пикселей в прямоугольном регионе 1, отражает насколько однородна по яркости область 1. Таким образом чем вероятнее что пиксель (x,y) входит в штрих, тем больше вычисляемое значение реакции фильтра.
Однако для практического применения формулу реакции фильтра необходимо разделить на две - для поиска светлых штрихов на темном фоне, и для поиска темных штрихов на светлом фоне. Для поиска светлых штрихов реакция фильтра будет выглядеть следующим образом:
B 2//1-2шах(// 2 ,// з )
R d ( ( x , y ) ,(M 1 >А2) &(А 1 >ХЛ) (2)
( )
Для поиска темных, соответственно:
D 2ш1П(А,М з )"2№
R a,d ( x , y ) ,(M1 < Ц 2 ) &(М ^ Мз) (3)
Оба этих фильтра также следует дополнить условиями, когда яркости областей расположены по возрастающей справа налево, либо слева направо:
R =.,d(x, y) = ° (^ 5 A1 ^ 3)) V (//3 < Ц1 < //2 ) (4)
На 3 показаны условия срабатывания штрихового фильтра для поиска ярких и темных штрихов, номера соответствуют номерам прямоугольных областей, знаки – знакам средних яркостей в этих областях.
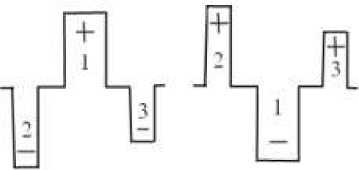
Рис. 3. Условия срабатывания штрихового фильтра: определение светлых и темных штрихов соответственно
Осуществляя процесс фильтрации штрихов к любому пикселю изображения можно построить соответствующее отображение:
RB(x, y) = шах RB,d(x, y X (a, d)
< OB (x, y) = arg шах RB d (x, У), (a)
SB (x, y) = arg шах RBd (x, y).
( d )
где R,O и S соответственно реакция, ориентация и масштаб штриха.
Важной составляющей для практического применения штрихового фильтра является снижение вычислений, для этой цели используются следующие стратегии:
Краевая предобработка изображения – предполагается, что текстовый блок имеет большое количество резких переходов яркости на краях текста, поэтому штриховой фильтр следует применять лишь на блоках с резкими переходами яркости и соседних. Для нахождения этих блоков используется более быстрый алгоритм Canny, разработанный Джоном Ф. Кэнни [3].
Быстрое заполнение – как только штриховым фильтром найден пиксель, дающий сильную реакцию фильтра, его вычисленная реакция, ориентация и масштаб присваивается также и его соседям.
Две указанные стратегии позволяют ускорить процесс фильтрации изображения примерно в шесть раз, по сравнению с обработкой всего изображения штриховым фильтром (согласно данным, приведенным в работе [2]).
После вычисления компонент R,O и S проводится операция выявления текстовых блоков, которая состоит из следующих этапов:
-
• объединение соседних отображений со схожими свойствами в скопления (компоненты), состоящие из координат начала и конца штриха, толщины;
-
• определение количества пересечений (связей) компонент в одном регионе и отбор компонент по количеству связей – не менее двух, но не более четырех (с учетом толщины штрихов);
-
• маркирование набора близких компонент участком, кандидатом в текстовый блок, отбор и нормализация выборки связанных компонент из каждого участка;
-
• предъявление бинарных отображений выборки связанных компонент OCR модулю, подсчет рейтинга кандидата.
По результатам посчитанного рейтинга кандидата в текстовый блок выносится конечное решение – является ли блок текстовым или нет.
В современной практике цифрового распознавания изображений для выделения текстовых блоков чаще всего используются следующие фильтры:
-
1) Краевой фильтр Кэнни (Canny Edge Detector, Canny 1986) [3]
-
2) Фильтр Габора (Gabor filter, Chen et al., 2001)
-
3) Фильтр с использованием преобразования Хаара для нахождения строк (Haar-like line filter, Lienheart и Maydt, 2002) [4]
-
4) Фильтр коэффициента краев (Ratio edge filter, Tupin et al., 1998)
-
5) Штриховой фильтр (Stroke filter, Cheolkon Jung, Qiufeng Liu, Jooungkyu Kim, 2008)
Все вышеперечисленные фильтры основаны на важном свойстве текста – резких перепадах яркости между фоном и текстом на изображении. Сравнительные характеристики фильтров указаны в табл. 1.
Таблица 1
|
Фильтр |
I cl |
S cl |
S ll |
H c |
R s |
|
Canny |
X |
X |
X |
5 |
|
|
Gabor |
х/ |
х/ |
X |
X |
1 |
|
Haar |
X |
X |
X |
4 |
|
|
Ratio |
X |
X |
3 |
||
|
Stroke |
х/ |
х/ |
х/ |
4 |
I cl – задание интервала между фоном и текстом,
S cl – определение разности яркости между фоном и текстом,
S ll – определение сходства фона, расположенного под текстовым блоком,
Hc – определение яркостной однородности текста,
Rs – примерная вычислительная скорость алгоритма.
Задание интервала Icl между фоном и текстом необходимо, так как на изображениях с высокой степенью сжатия по краям текста могут появляться артефакты, что может привести к дальнейшим ошибкам распознавания.
Также сравнение фильтров было произведено на вертикальных линиях различной толщины (Рис. 4) .
-
4 показывает что самый четкий отклик на линии из которых составлен текст дает штриховой фильтр, не указывая при этом на границы перехода условного фона (правая часть картинки).
Таким образом, приведенное выше сравнение указывает на возможность применения штрихового фильтра для эффективной локализации и распознавания текстовых блоков как самого одного из самых быстрых и эффективных методов поиска штрихов, составляющих текст.

Рис. 4. Отклики различных фильтров.
a – исходное изображение, b – Canny edge filter, c – Gabor filter, d – Haar-like line filter, e – Ratio edge filter, f – Stroke filter.
Список литературы Выделение текстовых блоков из зашумленного изображения
- Методы компьютерной обработки изображений/Под ред. В.А. Сойфера. 2-е изд., испр. -М.: Физматлит, 2003. -784 с.
- Cheolkon Jung,Qifeng Liu, Joongkyu Kim Pattern Recognition Letters 30 (2009) 114-122 stroke filter and its application to text localization.
- Canny, J.F., 1986. A computational approach to edge detection. IEEE Trans. Pattern Analyt. Machine Intell. pp. 8, 679-698.
- Lienhart, R., Maydt, J., 2002. An extended set of Haar-like features for rapid object detection. In: Proc. IEEE Conf. Image Processing, pp. 900-903.
