Высокопроизводительный алгоритм генерации простых чисел в произвольном диапазоне с применением кольцевой факторизации

Автор: Минаев Владимир Александрович, Васильев Николай Петрович, Лукьянов Вениамин Владимирович, Никонов Семен Андреевич, Никеров Дмитрий Викторович
Журнал: Спецтехника и связь @st-s
Статья в выпуске: 5, 2013 года.
Бесплатный доступ
Даются определения порядка индексного алгоритма и паттерна размещения составных чисел. Рассмотрены индексные алгоритмы вычисления простых чисел в сочетании с методом кольцевой факторизации для предварительного отбора составных чисел. Производится сравнение индексных алгоритмов различного порядка.
Простые числа, высокоскоростной алгоритм генерации, кольцевая факторизация, индексный алгоритм
Короткий адрес: https://sciup.org/14967176
IDR: 14967176
Текст научной статьи Высокопроизводительный алгоритм генерации простых чисел в произвольном диапазоне с применением кольцевой факторизации
П ростые числа используются для шифрования информации. Так, например, известный алгоритм шифрования RSA использует два простых числа для формирования открытого ключа. При этом, чтобы расшифровать содержимое конфиденциального письма, надо провести процесс факторизации некоторого очень большого числа, т.е. разложить его на сомножители, которые являются простыми числами.
Решение задачи факторизации при этом – исключительно вычислительно-емкая процедура, так как помимо нахождения сомножителей, каждый из них необходимо проверить на простоту.
Для генерации простых чисел методом просеивания (исключение составных чисел, т.н. «решето») применяются решета Эратосфена, Аткина и Сундарама в разных модификациях и производные от этих алгоритмов.
В 2011 г. опубликована работа В.А. Минаева [1], в которой описывается алгоритм, являющийся основой для создания новых высокопроизводительных алгоритмов, превосходящих по скорости вычисления простых чисел все предыдущие. Алгоритм основывается на теореме о полном множестве простых чисел.
Автор доказал, что полное множество простых чисел вида {6 k+1}, k = 1,2,3… (по определению В.А. Минаева – плюс простые числа) формируется путем вычитания из общего множества чисел {+qi} вида {6 k+1}; k = 1,2,3…, определенного как {+S}, подмножества составных чисел С> , определяемых с помощью уравнений:
"cl,-, = "qix-qi + -qix6xm;
Х1? = ЧхЧ + Чхбхт,
где m = 0,1,2…; i = 1,2,3…
А полное множество простых чисел вида {6·k-1} ; k = 1,2,3… (минус простые числа) – путем вычитания из общего множества чисел {–qi} вида {6 k-1} ; k = 1,2,3… , определенного как {‒S} , подмножества составных чисел с( , вычисляемых из соотношений:
С(.п = Qi х V- +<7, х 6 х т;
(2) с.^-^х 9, + qjXbxm, где m = 0,1,2…; i = 1,2,3…
Смысл алгоритма, предложенного в [1], связан не с прямым вычислением простых чисел, а с нахождением полного множества составных того же вида {6 k ± 1} ; k = 1,2,3…., и последующим вычитанием соответствующих множеств.
В настоящей статье описываются новые индексные алгоритмы генерации простых чисел, на сегодняшний день самые быстрые, основой разработки которых является теорема, доказанная в [1], и правило знаков, сформулированное там же.
Эти составные числа адресуются во множестве –S или +S следующими четырьмя индексами:
+k 1 = (–q k + k ),
–k 2 = (+q k – k) , (10)
–k 3 = (–q k – k) ,
+k 4 = (+q k + k)
или в векторном виде (вектор включает по две компоненты):
+k = (±q k + k) , –k = (±q k – k) , (11)
где k = 1,2,3,….
Приведем примеры адресации ( табл. 1, 2 ), используя формулы (5) – (11), при n = 1.
Индексный алгоритм второго порядка для генерации простых чисел
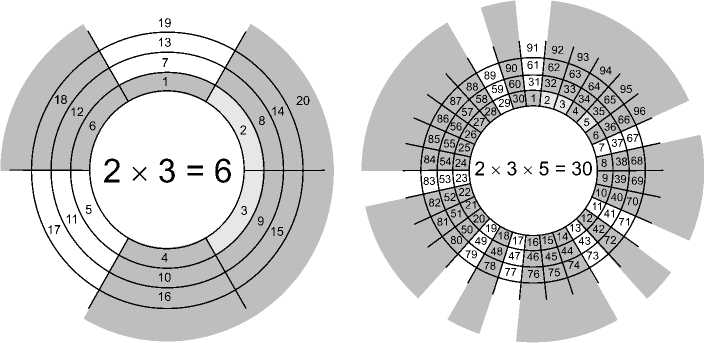
Отметим, что для ускорения поиска простых чисел на определенном отрезке натурального ряда для предварительного отбора составных чисел в работе [2] реализован и исследован индексный алгоритм, построенный с использованием кольцевой факторизации для 3# = 6 (примориал простых чисел 2x3). Она позволила на предварительном этапе отсеять значительную часть составных чисел – 66,66…%. На рис. 1 приведено графическое изображение кольцевой факторизации для 3# и 5# [3 – 4].
Индексные зависимости формирования составных чисел
Согласно правилу знаков [1], любые составные числа из множеств –S и +S представляются в виде произведений:
–c(–q k , +q n ) = –q k × +q n , –c(+q k , –q n ) = +q k × –q n ,
+c(–qk, –qn) = –qk × –qn, +c(+qk, +qn) = +qk × +qn, где k, n = 1,2,3,….
Подставляя соответствующие значения для ±q k и ±q n , получим соотношения:
Рис. 1. Графическое изображение кольцевой факторизации для 3# и 5#
–c(–q k , +q n ) = 6 × (n ×–q k + k) – 1 , (5) –c(+q k , –q n ) = 6 × (n ×+q k – k) – 1 , (6) +c(–q k , –q n ) = 6 × (n ×–q k – k) + 1 , (7) +c(+q k , +q n ) = 6 × (n ×+q k + k) + 1 . (8)
Из (5) – (8) следует, что всевозможные сочетания n и k ( k , n = 1,2,3,…) позволяют получить весь набор составных чисел вида {6×i ± 1} , i = 1,2,3,…; в любом заданном интервале.
Так, например, при n = 1 выражение, стоящее в скобках формул (5) – (8), описывает получение следующего набора составных чисел:
–c(–q k , 7) = 6×(–q k + k) – 1 , –c(+q k , 5) = 6×(+q k – k) – 1 ,
+c(–q k , 5) = 6×(–q k – k) + 1 , +c(+q k , 7) = 6×(+q k + k) + 1 .
Таблица 1. Адресация составных чисел с использованием + k-индексной зависимости
|
k |
±q k |
+k 1 , +k 4 |
±c ( ±q k1 +k 1 ,) ±c ( ±q k1 +k 4 ,) |
|
1 |
5 (множество –S ) |
5+1=6 |
35 (множество –S ) |
|
1 |
7 (множество +S ) |
7+1=8 |
49 (множество +S ) |
|
4 |
25 (множество +S ) |
25+4=29 |
175 (множество +S ) |
|
8 |
47 (множество –S ) |
47+8=55 |
329 (множество +S ) |
|
13 |
79 (множество +S ) |
13+79=92 |
553 (множество +S ) |
|
127 |
761 (множество –S ) |
127+761=888 |
5327 (множество –S ) |
Таблица 2. Адресация составных чисел с использованием – k-индексной зависимости
|
k |
± qk |
–k 2 , –k 3 |
±c ( ±q k1 –k 2 ,) ±c ( ±q k1 –k 3 ,) |
|
1 |
5 (во множестве –S ) |
5 ‒ 1=4 |
25 (во множестве +S ) |
|
1 |
7 (во множестве +S ) |
7 ‒ 1=6 |
35 (во множестве ‒S ) |
|
4 |
25 (во множестве +S ) |
25 ‒ 4=21 |
125 (во множестве ‒S ) |
|
8 |
47 (во множестве –S ) |
47 ‒ 8=39 |
235 (во множестве +S ) |
|
13 |
79 (во множестве +S ) |
79 ‒ 13=66 |
395 (во множестве ‒S ) |
|
127 |
761 (во множестве –S ) |
761 ‒ 127=634 |
3805 (во множестве +S ) |
Нужно отметить, что для 7# (примо-риал простых чисел равен 2x3x5x7) – отсеивается больше 77% составных чисел, а для 251# – около 90%.
Учитывая важность предварительного просеивания, в настоящей работе обосновываются и исследуются индексные алгоритмы, построенные с применением кольцевой факторизации для примориалов, превышающих значение 6.
Введем понятие порядок индексного алгоритма , под которым подразумевается количество первых простых чисел, использованных при соответствующей кольцевой факторизации. Например, для 3# = 2 × 3 = 6 порядок индексного алгоритма равен 2, а для 5# = 2 × 3 × 5 = 30 – порядок равен 3.
Число k = 1,2,3…, участвующее в формировании пары чисел, каждое из которых принадлежит множеству –S или +S , определим как k -индекс .
k -индекс адресует числа множеств –S и +S следующим образом: одному его значению одновременно соответствуют по одному элементу из каждого множества; при этом соответствие между k - индексом и элементом в каждом из множеств – взаимно однозначное.
Множества –S и +S будем называть симметричными по отношению друг к другу, поскольку их элементы формируются симметрично относительно одного и того же k -индекса с разностью 2, т.е. для симметричных элементов множеств –S и +S разность +q k – –q k = 2 .
В связи с тем, что каждое составное число есть член какой-либо арифметической прогрессии [5], был поставлен вопрос: можно ли адресовать все составные числа во множествах –S и +S через k -индексы и первые члены арифметических прогрессий, порождающих их подмножества?
Решение данного вопроса имеет существенную вычислительную и практическую ценность, так как определение массива индексов, соответствующих массиву составных чисел, позволяет избежать выделения огромной памяти под хранение последних в результате решений уравнений (1), (2).
Нужно отметить, что существующие до сегодняшнего дня методы получения очередного простого числа учитывали все найденные предыдущие простые и составные числа, в то время как индексный подход позволяет без
Таблица 3. Примеры адресации составных чисел через их индексы
|
qk |
k |
n |
+kn |
±c(+kn,) |
–kn |
±c(–kn,) |
|
5 ( –S ) |
1 |
1 |
6 |
35 ( –S ) |
4 |
25 ( +S ) |
|
2 |
11 |
65 ( –S ) |
9 |
55 ( +S ) |
||
|
3 |
16 |
95 ( –S ) |
14 |
85 ( +S ) |
||
|
4 |
21 |
125 ( –S ) |
19 |
115 ( +S ) |
||
|
5 |
26 |
155 ( –S ) |
24 |
145 ( +S ) |
||
|
19 ( +S ) |
3 |
1 |
22 |
133 ( +S ) |
16 |
95 ( –S ) |
|
2 |
41 |
247 ( +S ) |
35 |
209 ( –S ) |
||
|
3 |
60 |
361 ( +S ) |
54 |
323 ( –S ) |
||
|
4 |
79 |
475 ( +S ) |
71 |
437 ( –S ) |
||
|
25 ( +S ) |
4 |
1 |
29 |
175 ( +S ) |
21 |
125 ( –S ) |
|
2 |
54 |
325 ( +S ) |
46 |
275 ( –S ) |
Таблица 4. Скорость вычислений и требуемая для работы алгоритма память на различных интервалах
|
Диапазон |
Время, с |
Память, МГб |
|
5÷1·109 |
22 |
317 |
|
5÷2·109 |
48 |
635 |
|
5÷3·109 |
74 |
953 |
|
5÷4·109 |
101 |
1271 |
|
5÷5·109 |
164 |
1589 |
|
1020÷1020+1·109 |
105 |
317 |
|
1020÷1020+2·109 |
162 |
635 |
|
1020÷1020+3·109 |
222 |
953 |
|
1020÷1020+4·109 |
287 |
1271 |
|
1020÷1020+5·109 |
360 |
1589 |
■ Первая половина данных из табл. 5
Верхняя граница интервала
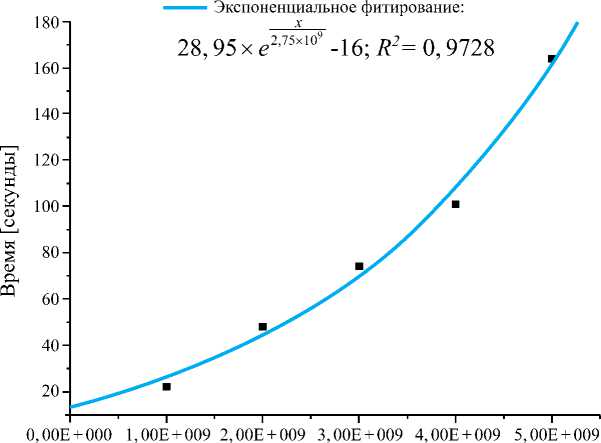
Рис. 2. Зависимость производительности индексного алгоритма от длины интервала в диапазоне 5^5^10 9 .
учета «предыстории» вычислять простые и составные числа в заданном произвольном интервале на множестве натуральных чисел при задании его нижней и верхней границы.
Предположим, требуется получить простые числа в диапазоне от одного миллиарда до двух. Для ранее известных методов приходилось задавать только верхнюю границу, т.е. 2 млрд, выполнять ресурсоемкие расчеты, а затем отсекать ненужные значения простых и составных чисел. В нашем же случае задаются обе границы, и расчет

Вторая половина данных из табл. 5
Используя формулы (12), составим следующую таблицу примеров ( табл. 3 ).
Анализируя столбцы табл. 3 , можно заметить, что +k n адресуют все составные числа в том множестве ( –S или +S ) которому принадлежит ±q k , а –k n – в симметричном множестве. Причем адресуемые составные числа кратны соответствующему ±q k . Это дает возможность, определив граничные условия на ±k n и соответственно максимально необходимые для этого q k , n и k , исходя из границ интервала, найти все простые числа.
Оценка производительности работы индексного алгоритма второго порядка
Верхняя граница интервала
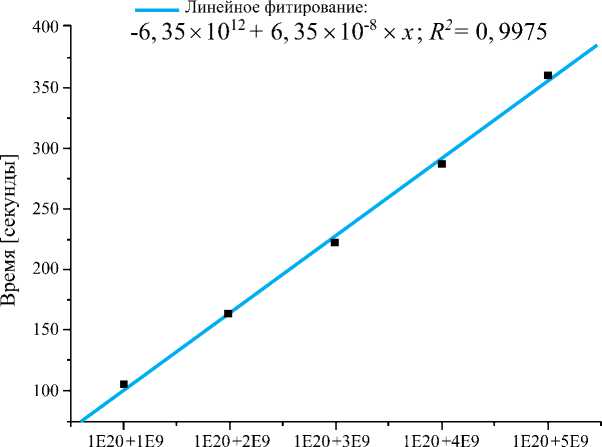
Рис. 3. Зависимость производительности индексного алгоритма от длины интервала в диапазоне 1020+1020+5d0 9 .
2,00Е+009-|
cd cd И Он CD н о S cd У S И cd
1.80Е+009-
1,60Е+009-
1,40Е+009-
1,20Е+009-
1,00Е+009-
8,00Е+008-
О о. CD
6,00Е+008-
4,00Е+008-
2,00Е+008-
■ Индексный алгоритм ▲ Решето Эратосфена ® Алгоритм Минаева ▼ Решето Аткина
■
Индексный алгоритм второго порядка был реализован на C++ и протестирован на скорость вычислений и занимаемую при работе память. Результаты тестов отражены в табл. 4 .
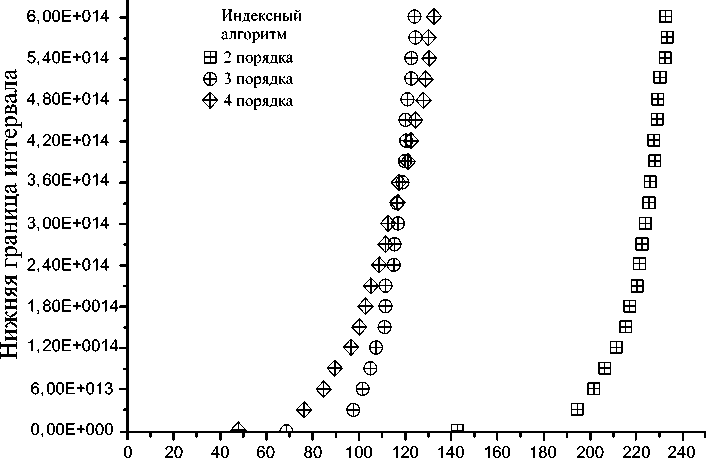
Корректность работы алгоритма проверена с использованием источников для 20-разрядных и менее чисел [6 – 8] в пределах первых 50 млн простых чисел. Интересно отметить, что на начальном интервале расчета 5^5^10 9 время вычислений экспоненциально зависит от величины интервала ( рис. 2 ) – квадрат коэффициента корреляции равен 0,973, а при очень больших значениях n можно использовать линейное приближение ( рис. 3 ), где квадрат коэффициента корреляции составляет 0,9975.
0,00Е+000 -I—i-^i—।—।—।—।—।—।—।—।—।—।—।—।—।—।—।—।—।—।—।—।—।—।
О 5 10 15 20 25 30 35 40 45 50 55 60
Время [секунды]
Сравнение производительности алгоритмов
Рис. 4. Сравнение скоростей работы алгоритмов вычисления всех простых чисел на интервале от 1 до n
ведется только в их пределах для требуемых значений простых и составных.
Для произвольного n обобщим выражения (11) в виде уравнений:
+kn = n × ±qk + k, ‒kn = n × ±qk – k,
где k , n = 1,2,3,…
Члены этих арифметических прогрессий – это k -индексы , адресующие элементы множеств –S или +S ; При этом
±q k может быть как простым, так и составным числом. Члены прогрессии адресуют составные числа, некоторые из них могут адресоваться и другой k -индексной прогрессией, формируя «дубли».
В работе [5] отмечено, что все «дубли» игнорируются при вычитании составных вида {6 k ± 1} , k = 1,2,3…, из объединения множеств +S и –S , в результате остаются только простые числа вида {6 k ± 1} , k = 1,2,3….
Проведем сравнительные тесты различных алгоритмов вычисления простых чисел, работающих в одинаковых условиях: каждый из них был реализован на языке C++, запускался на одном и том же компьютере, на вход подавались одни и те же интервалы от 1 до n и замерялось время, за которое алгоритм выделит все простые числа на данном интервале. Результаты измерений представлены на рис. 4 .
На рис. 5 по оси ординат отложены верхние пределы интервалов вычислений, т.е. n +1000 (нижние пределы отличались от верхних на 1000). По оси абсцисс – время, за которое алгоритм вычислял все простые числа на заданном интервале.
Предварительное просеивание с применением метода кольцевой факторизации в индексных алгоритмах произвольного порядка
Рассмотрим более детально индексный алгоритм второго порядка для нахождения простых чисел в заданном отрезке [Nmin; Nmax], исходя из результатов работы [2]. Для этого применим кольцевую факторизацию для 3# к отрезку [1; Nmax], введем обозначения q+' = 6k +1, q*^ = 6k + 5, где k = 0,1,2, … kmax (для максимально возможного k = kmax должно быть выполнено условие
q+i "бктх max и занесем эти данные в табл. 5. В левом столбце таблицы приведена последовательность индексов 0, 1, 2, … kmax, в двух других столбцах – отображения этой последовательности во множества вида {6k + 1} и {6k + 5}, содержащие как простые, так и составные числа, а также единицу. Перейдем к следующему этапу – отсеву оставшихся после кольцевой факторизации составных чисел из множеств {q6k+1} и {q6k+5}, где k = 0, 1, 2, … kmax. Как показано в [2], все составные числа, кратные числам q6+i1 или q6+i5, где i = 0, 1, 2, … imax (для максимально возможного i = imax должно быть выполнено условие ^6i ^ ≤ Nmax), можно исключить из табл. 5, вычислив массив их индексов с помощью соответствующих соотношений. Для фиксированного q6+i1 последовательность m-q^ + i , где m = 1, 2, 3, … , индексирует все кратные ему составные числа во множестве {q6k+1}, а последовательность m • +' - z -1 , где m = 1, 2, 3, … , индексирует все кратные q6+i1 составные числа во множестве {q6k+5} [2]. Для заданного отрезка [Nmin; Nmax] из вышеупомянутых последовательностей нужно выбирать те их члены, которые индексируют числа, содержащиеся внутри него. Пример для q6·1+1 = 7 приведен в табл. 6, в левом столбце которой отмечены индексы m· q6·1+1, где m = 1, 2, 3, … , а во втором и третьем столбцах отмечены кратные q6·1+1 числа, 2.00E+0018-] я 1,00E+0018-4. И 1.60E+0018-C4. H 1,40E+0018- ® 1,20E+0018-Я■ S 1,00E+0018-^8,00E+0017-§ 6.00E+0017-^4,00E+0017- CQ 2,00E+0017- 0,00E+000 I , 1 , t. I1. 0 2 4 6 Рис. 5. Сравнение скоростей работы алгоритмов генерации простых чисел на интервале от n до n+1000 при различных n. Таблица 5. Результаты кольцевой факторизации для 3# в табличном виде Индекс q6k+1 q6k+5 0 1 5 1 7 11 2 13 17 3 19 23 4 25 29 max 6kmax + 1 6kmax + 5 индексируемые последовательностями соответственно (m·q6·1+1+ 1) = {8, 22, 29, 36, …} и (m·q6·1+1 – 2) = {5, 19, 26, 33, …}. Для фиксированного q6+i5, в свою очередь, уже другая последовательность (m·q6+i5 – i), где m = 1, 2, 3, … , индексирует все кратные этому q6+i5 составные числа во множестве {q6k+1}, а последовательность (m·q6+i5 + i – 1), где m = 1, 2, 3, … , индексирует все кратные q6+i5 составные числа во множестве {q6k+5}. Опять же для заданного отрезка [Nmin; Nmax] из вышеупомянутых последовательностей нужно выбирать те их члены, которые индексируют числа, содержащиеся внутри этого отрезка. Пример для q6·0+5= 5 приведен в табл. 7, в левом столбце которой отмечены индексы m·q6·0+5, где m = 1, 2, 3, … , а во втором и третьем отмечены кратные q6·0+5 числа, индексируемые последовательностями соответственно (m·q6·0+1 – 1) = {4, 24, 29, 34, …} и (m·q6·0+1) = {5, 25, 30, 35, …}. Таким образом, если перебрать все подходящие q6+i1 и q6+i5, то из заданного отрезка [Nmin; Nmax] можно отсеять все ■ Индексный алгоритм ♦ Блочное решето Эратосфена Ф Алгоритм Минаева А Решето Эратосфена 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 Время [секунды] Таблица 6. Пример адресации составных чисел при q6·1+1= 7 k q6k+1 q6k+5 0 1 5 5 31 35 6 37 41 7 43 47 8 49 53 19 115 119 20 121 125 21 127 131 22 133 137 23 139 143 24 145 149 25 151 155 26 157 161 27 163 167 28 169 173 29 175 179 30 181 185 31 187 191 32 193 197 33 199 203 34 205 209 35 211 215 36 217 221 Таблица 7. Пример адресации составных чисел при q6·+05=5 Индексный алгоритм произвольного порядка Сформируем индексный алгоритм произвольного порядка n для нахождения простых чисел в заданном отрезке [Nmin; Nmax], обобщив изложенный алгоритм второго порядка. Применим кольцевую факторизацию для pn# к отрезку [1; Nmax], примем обозначения, аналогичные принятым выше qP.»k = pn#·k + 1, „ + !'.« = pn#·k + pn+1, ~ Pn^-k ... 9^ = pn#·k + pn+s, где k = 0, 1, 2, … kmax (для максимально возможного k = kmax должно быть выполнено условие ≤ Nmax), и зане сем эти данные в табл. 8: В левом столбце табл. 8 приведена последовательность индексов 0, 1, 2, … kmax, в других столбцах – отображения этой последовательности в множества вида {pn#·k + 1}, {pn#·k + pn+1}, {pn#·k + pn+r}, {pn#·k + pn+s}, содержащие как простые, так и составные числа, а также единицу. Использованные обозначения – p1 = 2, p2 = 3, … pn – записанные по возрастанию простые числа, n = 1, 2, 3,…; pn# – примориал (произведение всех простых чисел, меньших либо равных pn); pn+1, … pn+r, … pn+s – записанные по возрастанию числа из интервала (pn; pn#), являющиеся простыми или всевозможными произведениями простых чисел из этого же интервала; s — количество простых чисел и их произведений на интервале (pn; pn#); r = 1, 2, 3, … s. Перейдем к следующему этапу – отсеву оставшихся после кольцевой факторизации составных чисел из множеств { рЛ'к }, {^p.M }, … {^ рЛ-к }, … { ЧР„»-к }, где k = 0, 1, 2, … kmax. Кратные числу q составные числа можно исключить, вычислив их индексы, для чего обобщим полученные для индексного алгоритма второго порядка соотношения на произвольный порядок. При этом q ∈{Q} = {pn#·i + 1} ∪ {pn#·i + pn+1} ∪ … ∪ {pn#·i + pn+r} ∪ … ∪ {pn#·i + pn+s}, где i = 0, 1, 2, … imax (для максимально возможного i = imax должно быть выполнено условие (Ч,\н )2 ≤ Nmax), r = 1, 2, 3, … s. Чтобы вычислить эти индексы, введем для фиксированного q ∈ {Q} числа tqj , где j = 1, 2, … (s + 1). Числа tqj определяются в диапазоне [0; q – 1] и принимают значения из первого столбца табл. 8 соответственно тому, на какой строке в (j + 1)-ом столбце находится кратное q число. Это означает, что для каждого q определяется свой паттерн tqj, q ∈ {Q}, (13) под которым будем понимать схему размещения кратных q чисел в строках с индексами 0, 1, … (q – 1) табл. 8. Покажем, что этот паттерн повторяется в строках с индексами m·q, … , (m + 1)·q – 1, где m=0, 1, 2, … . Число, стоящее в (j + 1)-ом столбце табл. 8 на строке с индексом m·q + tqj,(14) при j > 1 равно pn#·(m·q + tqj) + pn+j–1 = pn#·tqj + + pn+j–1 + pn#·m·q(15) или (при j = 1) pn#·(m·q + tqj) + 1 = pn#·tqj+ 1 + + pn#·m·q,(16) а значит, отличается от стоящего в (j+1)-ом столбце табл. 8 на tqj-й строке числа (при j >1 – pn#·tqj + pn+j–1, или при j = 1 – pn#·tqj + 1 по определению кратного q) на pn#·m·q и, следовательно, делится на q. Очевидно, что для определенного отрезка [Nmin; Nmax] из последовательностей (14) нужно выбирать те их члены, которые индексируют числа, содержащиеся внутри этого отрезка в табл. 8. Рассмотрим в качестве примера отсеивание кратных q30+·07 чисел при выполнении индексного алгоритма третьего порядка. Третий порядок индексного алгоритма означает, что нужно взять 3 первых простых числа и перемножить их – 2 × 3 × 5 = 30, после чего составить таблицу кольцевой факторизации, содержащую все простые числа и состоящую из членов прогрессий {30k + 1}, {30k + 7}, {30k + 11}, {30k + 13}, {30k + 17}, {30k + 19}, {30k + 23}, {30k + 29}. Для отсеивания всех кратных 7 чисел нужно в диапазоне индексов [0; 6] определить паттерн (13) для числа 7: Таблица 8. Результаты кольцевой факторизации для pn# в табличном виде Индекс 4 p^'k z-i + Pirtr р,Лк 0 1 pn+1 pn+r pn+s 1 pn#·1 + 1 pn#·1 + pn+1 pn#·1 + pn+r pn#·1 + pn+s max pn#·kmax + 1 pn#·kmax + pn+1 pn#·kmax + pn+r pn#·kmax + pn+s Таблица 9. Пример адресации составных чисел при q = q30·+07= 7 Далее следует во множестве диапазонов индексов {[7; 13], [14; 20], …} исключить соответственно паттерну (17) кратные 7 числа, которые будут находиться по формуле (14) на тех же местах, что и в диапазоне [0; 6]. Описанный процесс показан в табл. 9, полученной из табл. 8 при n = 3. Таким образом, если в заданном отрезке [Nmin; Nmax] с помощью соответствующих паттернов (13) отсеять составные числа (15) и (16), кратные всем подходящим q (13), то в нем останутся только простые числа. Отметим, что количество паттернов равно количеству элементов множества {Q}, которое зависит от значения Nmax. Следовательно, на отрезках равного размера с различным Nmax количество паттернов будет больше у отрезка с большим Nmax. Перейдем к исследованию индексных алгоритмов различного порядка. 2,40Е+015-| 2,10Е +015- 2,80Е+015- 1.50Е+015- 1.20Е+015- 9,00Е+014- 6,00Е+014- 3.00Е+014- ш ш ш ш ш ш ш ш ш Ш I Ш ш ф ф ф ф ф ф ф ф ф ф ф ф ф ф Ш ф Ш Ф ШФ ШФ Индексный алгоритм ЕВ 2 порядка ф 3 порядка ф4 порядка 0,00Е +000 -p-i—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—г-1 0 10 20 30 40 50 60 70 80 90 100 110 120 Время [секунды] Рис. 6. Сравнение скоростей работы индексных алгоритмов генерации простых чисел на отрезке размером 106 (считая от значения ординаты) Исследование индексных алгоритмов различного порядка Рассмотренные индексные алгоритмы реализованы на языке C++ с исполь- зованием библиотеки GMP для работы с большими числами и проверены на совпадение результатов генерации с первыми 50 млн простых чисел [6 – 8]. Индексные алгоритмы второго, третьего и четвертого порядков исследовались на время работы при различных отрезках и различных нижних границах на компьютере с процессором Intel Core i3 2,93 ГГц. Увеличив- 1.80Е+015 - й 1.60Е+015- R . св ® 1.40Е+015- н Я 1.20Е+015- Я 1.00Е+015-S « ■ S 8.00Е+014- К 6.00Е+014- S 4,00Е+014- 2.00Е+014- 0,00Е+000-- <™1 Ш Ф Ш Ф ИФ ИФ Ш ф ШФ ШФ ffl ffiф № ф —।---1---1---1---1г 20 3040 Индексный алгоритм Ш 2 порядка ф 3 порядка ф 4 порядка Ф Ф Ф Ф Ф Ф Ф Ф И-------1-------1-------1-------1-------1-------1-------1-------1-------1-------1-------1-------1-------1-------Г 50 60 70 80 90 100 110 120 Время [секунды] Рис. 7. Сравнение скоростей работы индексных алгоритмов генерации простых чисел на отрезке размером 5·107 (считая от значения ординаты) миллионного отрезка индексный алгоритм второго порядка работает быстрее остальных, а четвертого – существенно отстает. Однако уже на отрезке 5·107 (рис. 7) видно, что индексный алгоритм третьего порядка по времени работы практически сравнялся по скорости с алгоритмом второго порядка, а на больших отрезках – стал работать быстрее. Аналогичная ситуация повторяется на отрезке 109 (рис. 8): индексный алгоритм четвертого порядка по времени работы сравнялся с индексным алгоритмом третьего порядка, а на отрезке 4·109 (рис. 9) – стал функционировать быстрее. Таким образом, для бóльших отрезков индексные алгоритмы генерации простых чисел большего порядка работают лучше, чем для меньших. Напротив, для меньших отрезков индексные алгоритмы генерации простых чисел меньшего порядка работают лучше, чем для бóльших. Происходит это потому, что для большего отрезка увеличивается время определения соответствующих ему паттернов, согласно которым отсеиваются составные числа. Для меньшего отрезка наблюдается обратная ситуация – паттерны находятся быстрее. Выводы Время [секунды] Рис. 8. Сравнение скоростей работы индексных алгоритмов генерации простых чисел на отрезке размером 109 (считая от значения ординаты) шееся время работы по сравнению с [2] обусловлено 64-битным представлением чисел в упомянутой статье. Использование представления mpz_t из GMP дало возможность судить о поведении алгоритмов за пределом 64-битного представления. На рис. 6 – 9 представлены результаты работы алгоритмов для соответствующих отрезков. Из рис. 6 видно, что для 1 Развитие положений работ [1 – 2] связано с реализацией индексного принципа нахождения составных чисел, заключающегося в вычислении не самих чисел, а массива соответствующих им индексов. Такой подход способен существенно увеличить производительность алгоритмов вычисления простых чисел, а, следовательно, скорость факторизации составных чисел, что напрямую связано с алгоритмами шифрования конфиденциальной информации. 2 Кроме того, индексные алгоритмы ориентированы на решение задач: ♦ дальнейших исследований в области простых чисел, в частности – оценки распределения простых чисел в произвольном диапазоне, проверки решения открытых математических проблем; ♦ создания генератора случайных простых чисел для криптографических приложений; ♦ поиска оптимальных значений простых чисел при использовании хеш- 1,60Е+014 -| Ф ф Индексный алгоритм и 1,40Е+014 - Ф ф в ЕВ 2 порядка Си И Ф ф ф 3 порядка в О- 1.20Е+014 - Ф ф ф 4 порядка в н д Ф ф в S 1.00Е+014- Ф ф в S Ф ф в я 8.00Е+013- Ф ф в би Ф ф в □5 6.00Е+013- Ф ф в Я ^ Ф ф в S 4,00Е+013 - Ф ф в Щ Ф ф в 2.00Е+013 - Ф ф в Ф ф в О.ООЕ+ООО- ■ 1'1'1- ' 1 1'1^1 ' 1 ' 1 ' О 100 200 300 400 500 600 700 800 900 1000 Время [секунды] Рис. 9. Сравнение скоростей работы индексных алгоритмов генерации простых чисел на отрезке размером 4·109 (считая от значения ординаты) таблиц в базах данных и других задач, связанных с их применением. 3 Индексные алгоритмы в их текущей реализации представляют принципиально новый подход к поиску простых чисел. Однако требуется их оптимизация применительно к объему кэш-памяти используемого процессора. В то же время индексные алгоритмы с использованием кольцевой факторизации не требовательны к вычислительным ресурсам, поскольку оперируют с булевым массивом. Благодаря своей многозадачной структуре алгоритм легко модифицируется как многопоточный с реализацией на GPU. В частности они легко реализуемы при параллельном вычислении, используя кластерные вычислительные технологии NVIDIA CUDA [9–11], Open MP, Open MPI и другие ■
k
q6k+1
q6k+5
0
1
5
4
25
29
5
31
35
24
145
149
25
151
155
26
157
161
27
163
167
28
169
173
29
175
179
30
181
185
31
187
191
32
193
197
33
199
203
34
205
209
35
211
215
составные числа и тем самым определить в нем все простые.
k
30k + 1
30k + 7
30k + 11
30k + 13
30k + 17
30k + 19
30k + 23
30k + 29
0
1
7
11
13
17
19
23
29
1
31
37
41
43
47
49
53
59
2
61
67
71
73
77
79
83
89
3
91
97
101
103
107
109
113
119
4
121
127
131
133
137
139
143
149
5
151
157
161
163
167
169
173
179
6
181
187
191
193
197
199
203
209
7
211
217
221
223
227
229
233
239
8
241
247
251
253
257
259
263
269
9
271
277
281
283
287
289
293
299
10
301
307
311
313
317
319
323
329
11
331
337
341
343
347
349
353
359
12
361
367
371
373
377
379
383
389
13
391
397
401
403
407
409
413
419
14
421
427
431
433
437
439
443
449
15
451
457
461
463
467
469
473
479
16
481
487
491
493
497
499
503
509
17
511
517
521
523
527
529
533
539
18
541
547
551
553
557
559
563
569
19
571
577
581
583
587
589
593
599
20
601
607
611
613
617
619
623
629
tqj = {3,0,5,4,2,2,6,3}, для j = 1, … 8, q = 7. (17)
Список литературы Высокопроизводительный алгоритм генерации простых чисел в произвольном диапазоне с применением кольцевой факторизации
- Минаев В.А. Теорема о полном множестве простых чисел. -М.: НИЯУ МИФИ, 2011. -24 с.
- Минаев В.А., Васильев Н.П., Лукьянов В.В., Никонов С.А., Никеров Д.В. Высокопроизводительный алгоритм генерации простых чисел в произвольном диапазоне./Материалы XIV Международной научной конференции «Цивилизация знаний: проблемы и смыслы образования», 2013. -М.: РосНОУ.
- Wheel factorization -[Электронный ресурс]. URL: http://primes.utm.edu/glossary/xpage/WheelFactorization.html. (Дата обращения: 13.06.2013).
- Wheel factorization -[Электронный ресурс]. URL: http://en.wikipedia.org/wiki/Wheel_factorization. (Дата обращения: 18.06.2013).
- Минаев В.А. Простые числа: новый взгляд на закономерности формирования. -М.: Логос, 2011. -80 с.
- The first fifty million primes -[Электронный ресурс]. URL: http://primes.utm.edu/lists/small/millions/. (Дата обращения: 10.06.2013).
- The Prime Pages (prime number research, records and resources) [сайт]. URL: http://primes.utm.edu/(дата обращения 17.02.2013)
- Простые числа [сайт]. URL: http://ru.numberempire.com/primenumbers.php (дата обращения 25.04.2013)
- Cuda Best Practices Guide:: CUDA Toolkit Documentation [сайт]. URL: http://docs.nvidia.com/cuda/cuda-c-best-practices-guide/index.html (дата обращения 07.02.2013)
- Боресков А.В. Основы работы с технологией CUDA./Харламов А.А. -М.: ДМК Пресс, 2010. -232 с.
- Параллельные вычисления на GPU. Архитектура и программная модель CUDA: учеб. пособие./Боресков А.В. и др. Предисловие.: В.А. Садовничий. -М.: Издательство Московского Университета, 2012. -336 с.
