Загадки «больших данных» или from Big Data to куда-то

Автор: Сократилин Владимир
Журнал: Телескоп: журнал социологических и маркетинговых исследований @teleskop
Рубрика: Информационные технологии
Статья в выпуске: 1, 2016 года.
Бесплатный доступ
Обсуждение темы Big Data или «Больших данных», через семь лет после появления этого термина заполнило околонаучной литературу и литературу, связанную с обработкой данных. Дошла очередь и до использования этого термина в эмпирической социологии - социологических и маркетинговых исследований. Описание технологий, маркируемых этим термином, представляется, во многих случаях, как новая парадигма в области обработки информации. Для исследовательских компаний слова «Big Data» довольно быстро становятся инструментом рекламной кампании с атрибутами настоящего рекламного инструмента - мотивацией потенциального покупателя возможностью получения новых, необычайно полезных результатов, и создание общего позитивного настроения, путем размывания смыслов и ухода от четких формулировок. Тщательное изучения феномена Big Data показывает, что это всего лишь часть общего процесса изменения отношения человеческого общества к информации. Главное в этом процессе - упрощение доступа человека к любым видам информации и упрощение коммуникаций между людьми. Этот процесс, безусловно, ведет к принципиальным изменениям в жизни человеческого общества, предоставляет новые возможности для проведения социологических и маркетинговых исследований, но совершенно не изменяет парадигму обработки данных.
Большие данные, эмпирическая социология, информационная революция, математические модели
Короткий адрес: https://sciup.org/142182167
IDR: 142182167
Текст научной статьи Загадки «больших данных» или from Big Data to куда-то
3 сентября 2015 года исполнилось семь лет с того момента, как главный редактор журнала Nature Клиффорд Линч подготовил специальный номер, посвященный поиску ответа на вопрос «Как могут повлиять на будущее науки технологии, открывающие возможности работы с большими объемами данных?» [3.8]. И именно этот день принято считать датой рождения термина Big Data. Чаще всего при упоминании Big Data, как явления ссылаются на доклад «Big data: The next frontier for innovation, competition, and productivity», выпущенный в мае 2011 года компанией McKinsey Global Institute [3.5]. Вот, что говорит на эту тему Леонид Жуков, профессор ВШЭ и известный ныне специалист по изучению проблемы Big Data: «На самом деле, эта тема была, конечно, создана в какой-то момент McKinsey. После публикации этого отчета об этом заговорила вся пресса. Все пишут о big data, о том, как это можно использовать, о том, что это будет революция» [2.1].
Точно представить себе какая «это будет революция» пока никому не удается, потому что точно объяснить, что такое Big Data пока никто не смог. Даже в специализированных изданиях мы встречаем крайне эмоциональные высказывания, примерно, следующего вида: «Проще всего представить Big Data в виде стихийно обрушившейся и невесть откуда взявшейся лавины данных или свести проблему к новым технологиям, радикально изменяющим информационную среду, а может быть, вместе с Big Data мы переживаем очередной этап в технологической революции? Скорее всего, и то, и другое, и третье, и еще пока неведомое» [3.7].
Все, кто, так или иначе, мимоходом сталкивается с Big Data, переполняются эмоциями, то ли от ожидания чего-то потрясающего и необычного, то ли от ощущения суеверного страха. Между тем о применении технологий, связанных с большими данными уже твердят со всех сторон, причем даже те, кто заведомо такими технологиями не пользуется. И этот ажиотаж вызывает стремление использовать понятие Big Data, как рекламный трюк в бизнесе и вызывает некоторые опасения в научной среде. В научной среде в явлении Big Data не видят ничего необычного и наступления этого феномена предсказывали многие ученые.
5-я Грушинская конференция, как зеркало…
Вот и V-я социологическая Грушинская конференция «Большая социология: расширение пространства данных», на- верное, превзошла многие социологические конференции по надеждам, сомнениям, энтузиазму и неопределенности. Высказывания известнейших российских социологов и руководителей крупнейших и самых авторитетных социологических компаний были полны тревоги и надежд одновременно.
В своем вступительном слове Генеральный директор ВЦИОМ Валерий Федоров, который был модератором пленарного заседания, сформулировал проблему: «Как нам создать «большую социологию», которая своим масштабом мысли, глубиной анализа и, вероятно, его плодами ответила бы революционному вызову, который несут нам «большие данные»?» [1.2]
Президент Фонда «Общественное мнение» Александр Ос-лон осторожно заметил по этому поводу: «Дело в том, что наша культура очень любит слова. И когда появляется новое слово, вновь появляется и маленькая надежда на чудо. Пока это слово не очень понятно, надежда сохраняется. Потом, постепенно, либо смысл проясняется, и тогда надежда иссякает; либо смысл остается мутным, а слово привычным как стертая монета, не вызывает никаких ощущений» [1.2].
Руководитель Исследовательской группы ЦИРКОН Игорь Задорин выступил с неким стратегическим обращением, которое само по себе не вызывает никаких возражений, но и к Big Data относится достаточно опосредовано: «В этом смысле один из лозунгов, который я хотел бы сказать: «Большая социология — это, прежде всего, не «Big Data» и не «Много Data», а «много методов», «мультиметодичность», «много умного инструментария». Мы, конечно, съедим эти большие данные, но не одни. Второй лозунг: «Даешь мультидисциплинарность». Одним нашим социологическим сообществом того самого объема данных, которые очень различаются по предмету, конечно, не хватит. … И наконец, третий лозунг, который я хотел бы сказать: «Большая социология — это большое профессиональное сообщество» [1.2].
А о больших перспективах, связанных с Big Data, и о уже имеющихся успехах рассказал заведующий лабораторией Ин-САП РАНХиГС Дмитрий Рогозин. Он представил переведенный им, совместно с коллегами (научными сотрудниками этого же института Анной Ипатовой и Еленой Вьюговской) Отчет Американской ассоциации исследователей общественного мнения (AAPOR) о больших данных [1.1].
Множество интересных и поучительных докладов, которые были сделаны, как на пленарном заседании, так на специальной секции, прозвучали как попытка ответа на поставленные вопросы [1.5]. Из этих докладов мы узнали о наличии Big Data, о перспективах Big Data, о необходимости использовать
Big Data, о новой научной парадигме, связанной с Big Data и даже уже и о наборе приемов для работы с Big Data.
Однако, все эти доклады, реплики и сообщения оставили впечатление скорее некого одобрительного шума и некой перспективы, нарисованной такими широкими мазками, что иногда не понять, что и нарисовано. Процитированное выше замечание А. Ослона осталось актуальным — смысл не прояснился, но надежда осталась.
Из возникшей вокруг Big Data информационной кампании можно лишь неясно уловить смысл и содержание этого явления, а уже появились совершенно потрясающие сообщения о том, как простая обработка этих данных изменит мир и как простой анализ заменит деятельность целых научных институтов. И, несмотря на то, что такие сообщения очень быстро опровергались научным сообществом, а попытки внедрения простых решений чаще всего терпят фиаско, но эти сообщения перерастают в удивительные истории, которые кочуют из публикации в публикацию, постепенно обрастая настоящими мифологическими деталями.
Несколько удивляет то, что не социологи рассказывают обществу об особенностях и перспективах нового явления, которое вот-вот перевернет жизнь, если не всего человеческого общества, то, по крайней мере, значительной его части, а все вокруг рассказывают об этом друг другу, а социологи озадачены не сутью явления, а тем, как его использовать для проведения исследований.
Из докладов, которые сделали на конференции специалисты, несвязанные прямо с социологией, и из обсуждений проблем Big Data вне социологического сообщества, можно сделать вывод, что для представителей разных направлений деятельность, понятие Big Data рассматривается с разных точек зрения, а иногда даже означает разное. Поэтому было правильным разобраться сначала с тем, что мы собственно обсуждаем и что такое Big Data именно для эмпирической социологии.
Что называют «Большими данными» в околонаучных публикациях?
Изучение литературы, посвященной «Большим данным» показывает, что люди, работающие в разных областях, понимают под этим понятием разное, однако стараются использовать то определение, которое дают IT-специалисты, которые судят о данных со своих позиций. Их привлекают туда, где данные генерируются в огромных количествах в автоматическом режиме, например в телекоммуникационных компаниях или при регистрации покупок. Прежде всего, они думают об организации хранения данных и возможности доступа с последующей обработкой. Отсюда и возникают пресловутые три V, характеризующие Big Data — Volume, Variety, Velocity (объем, многообразие, скорость пополнения). На авторство концепции трех V, судя по публикациям, претендует IBM [3.6], хотя еще задолго до того, как возникло само понятие Big Data, в 2001 г. идея 3V была высказана в работе, помещенной на сайте компании Gartner, Inc (тогда еще называвшейся Meta Group) [5.6]. На этом пути уже нашлись достойные последователи и в некоторых работах речь идет уже о 5V [3.3]. Вполне вероятно, что скоро мы узнаем и про 7V, и про 27V, благо слов на букву V в словаре много.
Книги статьи и исследования, посвященные Big Data, обычно начинаются с введения, в котором объясняется, что Big Data — это революция, которая перевернет жизнь человечества. Следующая часть, которая, чаще всего, называется «Что такое Big Data?», сообщает, что точного определения у этого понятия нет. Например, так: «Для «больших данных» нет строгого определения. Изначально идея состояла в том, что объем информации настолько вырос, что рассматриваемое количество уже фактически не помещалось в памяти компьютера, используемой для обработки, поэтому инженерам потребовалось модернизировать инструменты для анализа всех данных». [3.1]
В знаменитом докладе McKinsey Global Institute, опублико- ванном в мае 2011 года, на который так часто ссылаются, когда рассуждают о значении Big Data для бизнеса, дается такое определение: «Большие данные — это наборы данных, размеры которых выходят за пределы возможностей по сбору, хранению, управлению и анализу, присущих обычному программному обеспечению базы данных» [3.5] (перевод цитируется по [3.2]).
Характерным является, такое сообщение: «Однозначного определения понятия «большие данные» не существует, однако можно сослаться на два описания сути этой концепции, с которой согласится большинство людей» [3.2].
Наши коллеги, из упомянутой уже AAROM, дают совершенно невнятное определение: «Термин «большие данные» — это своего рода описание больших по объему и разнообразных по составу характеристик, практик, технических приемов, этических проблем и последствий, которые связаны с данными» [1.1].
Ознакомившись с подобными определениями, уже нисколько не удивляешься набору разнообразных парадоксальных высказываний, забавных баек и настоящих мифов о Big Data.
Встанем теперь на позиции эмпирической социологии и зададимся вопросом: «А нам-то какое дело до того, что где-то в мире появились наборы данных, «размеры которых выходят за пределы…» или «описание больших по объему …этических проблем», мы-то почему должны обращать на это внимание? Заметим, что наиболее уверенно о проблемах и возможностях использования Big Data рассуждают IT-специалисты, которые работают с конкретными данными в конкретных компаниях [3.4], [2.2.]. Для этих специалистов Big Data — это данные, с которыми они работают, большими их называют потому, что им приходится для работы с этими данными привлекать новые методы и технологии, в силу особенностей данных, о которых мы говорили выше. Не так уверенно, как IT-специалисты, но достаточно позитивно и взвешенно рассуждают о проблеме ученые, занимающиеся естественными и техническими дисциплинами [2.3]. Для них Big Data — это только часть информационного пространства, которое расширяется благодаря Интернету.
Итак, что же за явление обозначают эти пресловутые Big Data, с точки зрения социологии, то есть с точки зрения механизмов функционирования и развития общества и возможностей изучения этих механизмов? Если мы не разберемся в сути этого явления, то уже наметившаяся тенденция называть словами Big Data все на свете, только для того, чтобы показать современность собственных взглядов и конкурентоспособность методик, постепенно превратит это понятие не более, чем в рекламный трюк.
Для понимания феномена Big Data следует разобраться в трех вопросах:
-
1. Что такое случилось в жизни части человеческого об щества, что привело к появлению феномена Big Data?
-
2. Что за информация содержится в самих Big Data?
-
3. Почему наличие Big Data, что-то меняет в процессах развития науки, в бизнесе и в жизни общества, в целом?
Ну, а тем, кто занимается эмпирической социологией или работают в смежных областях, важно было бы понять, кроме того, что же меняется собственно в социологических исследованиях?
Когда и как данные стали «большими»?
«Наше время можно с большим основанием назвать «веком информации», все нарастающий поток которой обрушивается на человека и на работе, и в быту. Объем этого потока значительно превосходит возможности человеческого мозга. Даже современные компьютеры не всегда справляются с задачами его обработки и анализа…» — это первая фраза из книги акаде- мика Павла Эльясберга «Измерительная информация: сколько ее нужно? Как ее обрабатывать?» [4.3], вышедшей 33 года назад в 1983 году. (Я позволил себе заменить в этой цитате слова «электронно-вычислительные машины» на слово «компьютеры» с тем, чтобы исключить единственный признак «древности» этой цитаты). Я привел эту цитату для того, чтобы показать, что уже много десятилетий в разных областях человеческой деятельности информация, реализованная в исходных данных, необходимых для принятия решений, имеет значительный объем, а способы и средства ее обработки, чаще всего были недостаточны для решения необходимых задач полностью.
Необходимость обработки в приемлемое время все больших объемов информации была, вероятно, основным фактором увеличения ресурсов вычислительной техники, под которыми тогда понимались, главным образом, быстродействие и объем памяти. С момента создания первых вычислительных устройств, которые можно назвать компьютерами (конец 40-х годов), этих ресурсов постоянно не хватало, в частности, не хватало объемов имевшихся носителей для размещения всей необходимой информации и программных возможностей для обработки больших объемов информации, расположенной на разных носителях. Одновременно, необходимо было искать научную основу для разработки методов обработки этой информации. Научная основа реализовывалась в разработке методов математического моделирования различных процессов. В основном, удавалось моделировать физические процессы, в меньшей степени химические и биологические, с трудом удавалось находить подходы к моделированию экономических процессов и совсем не удавалось моделировать социальные процессы.
Начало 80-х годов ХХ века — это время, непосредственно предшествующее современной «информационной» революции, хотя термин «информационная эпоха» получил определенное распространение уже в конце 1970-х годов. В это время уже появились первые варианты персональных компьютеров (Apple II корпорации Apple Computer, TRS-80 компании Tandy и Commodore PET компании Commodore), в 1983 году сеть ARPANET — прообраз сети Интернет — перешла на современный протокол TCP/IP. Но еще только через год будет разработана система доменных имен и только через 5 лет появится первая система общения в реальном времени (чат). Стоит присмотреться к тому, каким образом в это время осуществлялось хранение и обработка информации, потому что это период непосредственно предшествующий, тем революционным преобразованиям в области информационных технологий, с которыми мы сегодня и связываем термин «большие данные».
Напомним некоторые термины, которые нам понадобятся в дальнейшем:
-
1 . Электронным носителем информации будем называть материальный носитель, используемый для записи, хранения и воспроизведения информации, обрабатываемых с помощью средств вычислительной техники (ГОСТ 2.051-2006, пункт 3.1.15). В настоящее время под электронными носителями информации мы понимаем, в основном магнитные или оптические диски и устройства флеш-памяти.
-
2 . Будем также говорить, что информация храниться или размещается в «электронном» виде, если она храниться на электронном носителе.
Итак, в начале 80-х годов, большая часть информации, которая генерировалась в компаниях, на предприятиях и учреждениях, научными и творческими коллективами, отдельными людьми и различными органами власти, сохранялась еще в «неэлектронном» виде — в библиотеках в виде книг и отчетов, в картотеках отделов кадров, в регистратурах медицинских учреждений, в хранилищах фильмов и пластинок, в альбомах для фотографий, в личных дневниках и в тому подобных конструкциях. Отметим две важные особенности такого вида хранения информации:
во-первых, информация разного типа физически хранилась в разных местах, например книги — в библиотеках, а подробные архивы предприятий, компаний и учреждений — в самих организациях, исторические документы — в архивах и музеях, а личная информация — у самих граждан. Чтобы получить необходимую информацию, как правило, необходимо было прибыть на место хранения информации;
во-вторых, говоря современным языком, информация хранилась в различных форматах, поэтому для работы с ней часто приходилось, тем или иным способом преобразовывать исходную информацию в удобную для работы форму.
Возможности вычислительной техники и средств передачи данных уже позволяли хранить, обрабатывать и передавать достаточно большие объемы информации. Однако некоторые важные ограничения оставались. Выделим самые важные из этих ограничений:
-
• Потребитель информации сам должен был создать необходимые ресурсы для хранения и обработки своей информации. Это могли быть компьютеры отдельных организаций или компаний или мощные вычислительные центры, которые объединяли нескольких мощных компьютеров в интересах нескольких организаций. Но если ресурсов не хватало, то компании, в интересах которой собирались данные, самостоятельно приходилось заниматься усилением своих информационных мощностей.
-
• Сбор, ввод и хранение информации были задачей тех, кто эту информации обрабатывал, анализировал и пользовался ею.
-
• Ввод исходных данных был непростой задачей, так как средства общения компьютеров с человеком (интерфейсы) были, по современным меркам, достаточно примитивные. Организовывать и осуществлять ввод данных могли только профессионалы.
-
• Организовать хранение информации на электронных носителях в удобном для дальнейшей обработки виде было достаточно сложно технически и очень дорого с финансовой точки зрения. Действительно, ведь только размещение компьютеров требовало специальных помещений и коммуникаций, а еще требовался специально обученный персонал и создание специального программного обеспечения для хранения и обработки данных.
Таким образом, для решения большинства научных, хозяйственных, творческих и технических задач данные ВСЕГДА были BIG, а хранению информации в электронном виде препятствовали дороговизна компьютеров и техническая сложность процедур хранения и обработки данных.
Три группы достижений в области IT-технологий резко изменили отношения человечества к хранению и обработке информации. Этими достижениями были — персональные компьютеры, глобальная сеть (Интернет) и свободный доступ к огромным объемам памяти для хранения любой информации. Под персональными компьютерами мы понимаем здесь результат процесса уменьшения размеров и упрощения требований к установке и обслуживанию компьютеров. Этот процесс шел почти три десятка лет и, наконец, были достигнуты технологические прорывы, благодаря которым компьютеры приобрели четыре важнейших свойства:
-
1. Доступность — стоимость компьютеров стала сравнима со стоимостью обычной бытовой техники;
-
2. Простота эксплуатации — требования к установке и эксплуатации персональных компьютеров не отличаются от требований к обычной бытовой технике (например, к телевизору);
-
3. Повседневная полезность — наличие полезного в обыденной жизни и относительно дешевого программного обеспечения;
-
4. простота освоения — интерфейсы программных продуктов, просты и, практически, не требуют специальных навыков.
Надо отметить, что своей «персонализацией» компьютеры, в значительной степени, обязаны развитию технологий, позволяющих резко уменьшить размеры комплектующих — процессоров и других устройств. Миниатюризация комплектующих компьютеры элементов позволила использовать аналоги компьютеров в большом количестве различных устройств и ситуаций. Компьютеризация всех процессов жизни человека стала реальностью. А персональные компьютеры стали стремительно распространяться и в профессиональной среде, и в бизнесе, и в быту. С ростом быстродействия, объемов памяти и с улучшением качества интерфейсов, компьютеры стали использовать для хранения и обработки все больших объемов текущей информации и домашней и рабочей. И почти сразу вслед за появлением персональных компьютеров, в жизнь огромного числа людей в цивилизованных странах вошел Интернет и компьютеры стали еще и средством общения и средством передачи информации. Очень скоро Интернет предоставил пользователям гигантские ресурсы для хранения информации и обеспечил доступ к ним из любой точки мира (в которой, разумеется, есть доступ к Интернету) и с различных устройств. Огромное количество информации, которое генерировалось компьютерами, внедренными в самые разные области жизни, теперь уже не нуждалось в специальном преобразовании для хранения. Эта информация уже изначально создавалась в электронном виде и требовала только коммуникаций для передачи и места для хранения.
Дополнили этот процесс гаджеты — электронные устройства, которые открывают доступ к информации, хранящейся в электронном виде и даже сами создающие информацию в электронном виде (так, цифровой фотоаппарат делает сразу электронные фото или видеоизображения, цифровой диктофон — электронные записи и т.п.).
Таким образом, персональные компьютеры и гаджеты сняли проблему технической сложности и дороговизны процесса ввода информации, а Интернет предоставил колоссальные ресурсы для ее хранения, причем созданы эти ресурсы теперь уже не владельцами информации. Интернет же обеспечил и легкий доступ к информации. И хотя информация, по-прежнему, храниться в различных форматах, но теперь количество форматов ограничено относительно небольшим набором, кроме того, часто, имеется возможность конвертировать данные разных форматов.
Эти технические прорывы не могли не оказать сильнейшее влияние на массовое сознание. Огромное количество ныне здравствующих и активно действующих людей прекрасно помнит первые вычислительные центры — по сути дела целые предприятия, персонал которых ходил в белых халатах и чувствовал себя на передовых рубежах науки. А сегодня большинство людей рассматривает компьютеры в одном ряду с холодильником или микроволновой печью и не видит ничего удивительного в том, что их смартфон играет в шахматы лучше всех их друзей и знакомых.
В общественном сознании той части, человеческого общества, которая оказалась в зоне этой информационно-технической революции сформировались определенные представления об информации, которые приближенно можно сформулировать в виде следующих положений:
-
• Информацию, практически по любому вопросу, можно найти в Интернет.
-
• Доступ к информации возможен отовсюду, где есть компьютер и Интернет.
-
• Поисковики помогут найти все, что надо.
-
• Личную информацию (фотографии, переписку, разговоры в чатах и на форумах и т.п.) можно тоже хранить, причем совершенно не обязательно отбирать только важное и нужное — можно хранить все.
-
• Любая информация будет храниться сколь угодно долго.
-
• Компьютер и Интернет является средством коммуникаций (общения, в том числе с друзьями и родственниками).
-
• В Интернете можно покупать товары и услуги.
-
• В Интернете имеется новый способ общения и хранения информации о себе — социальные сети.
Хранение информации в электронном виде — удобном для обработки, теперь, когда это стало технически несложно и недорого, дало огромные преимущество бизнесу, повысило эффективность научного творчества, резко упростило работу органов власти. Все владельцы информации принялись переводить ее в электронный вид.
Компьютеры, внедренные и внедряемые, практически, во все виды человеческой деятельность генерируют огромный поток информации, причем эта информация появляется сразу в электронном виде. Надо было только изыскать ресурсы для хранения этой информации и такие ресурсы нашлись. Для обычных людей, объемы потенциальной памяти для хранения информации практически безграничны, а форматы позволяют хранить самую разнообразную информацию. Теперь не надо экономить и отбирать только самое важное — места хватит для всего.
Доступ к любой информации теперь можно получить с одного компьютера, подключенного к Интернет. Прямо из офиса или из дома. Это «единое окно» получения информации создает ощущение того, что вся информация храниться в каком-то одном месте и что ее можно «черпать» в любом количестве и в любых сочетаниях. Кроме того, в этом «безбрежном информационном море», в которое мы смотрим через монитор, появилась совершенно новая возможность для поиска необходимой информации — это специальное программное обеспечение — поисковые системы (англ. search engine) — поисковики.
Вот эти технические достижения и изменили совершенно представления человеческого общества о данных и информации. Разумеется, той его части, которая имеет доступ к компьютерам и Интернету. С социологической точки зрения, произошло качественное изменение отношения массового сознания к информации. Люди осознали возможность легкого доступа к огромным объемам информации и возможность легко сохранить информацию любых объемов, причем, практически на неограниченный срок. Именно эта революция в отношении человечества к информации и породила феномен Big Data.
Что за данные содержат «Большие данные» и кому важны 3V?
Даже те объемы информации, доступ к которым открыт, потрясают воображение. Именно это, по-видимому, и позволило Сергею Карелову (Председатель Лиги независимых ИТ-экспертов ЛИНЭКС и создатель стартапа Witology — проекта, работающего в области коллективного интеллекта/разума) сказать на семинаре РВК: «Данных так много, и они настолько разнообразны, что там черт знает, что лежит. Можно найти тот самый стратегический инсайд и процесс принятия решений» [2.1].
Действительно, вся информация, которая накоплена до сих пор человечеством и содержится, в настоящее время, на любых «неэлектронных» носителях рано или поздно найдет свое место в «электронных хранилищах». Книги, описание музейных экспонатов, статьи в газетах, журналах, отчеты о научных исследованиях, архивы — все это, рано или поздно, будет переведено в электронный вид. Процесс перевода информации в электронный вид непрост, но он идет, хотя и не без потерь.
Еще большие объемы информации поступают в электронные хранилища в результате того, что компьютерные технологии проникли, практически, во все сферы жизни. Поэтому информация генерируется сразу в электронном виде, как это происходит, например, с современными кассовыми аппаратами или в системах телефонной связи и может сразу же поступать в «электронные хранилища». Объемы подобной информации огромны, а ценность быстро уменьшается со временем, поэтому часто такая информация храниться ограниченное время, как например, информация с камер наружного наблюдения при охране не очень важных объектов. Впрочем, вполне вероятно, что технический прогресс вскоре приведет к отмене и этих ограничений.
Часть информации создается отдельными людьми в результате общения с друзьями (в виде личной переписки, личных дневников, отзывы и мнения о товарах и т.п.). Раньше эта информация не сохранялась вообще или сохранялась на носите- лях доступных только авторам, а теперь, когда она храниться в электронном виде, эта информация стала, хотя бы потенциально, доступной всем. Ощущение неограниченности ресурсов приводит к тому, что сохраняется даже заведомо бесполезная информация, например, сохраняются неудачные фотографии, в надежде на то, что «когда-нибудь потом посмотрим и отберем только удачные». Эта последняя группа информации создается множеством людей самостоятельно, просто для себя, для своих друзей, близких и знакомых.
Отметим три важных обстоятельства, сопровождающих процесс сохранения новой информации:
Во-первых, для хранения данных подавляющему большинству пользователей-непрофессионалов в области IT не требуется никаких организационных усилий. Какие-то IT-компании уже создали необходимые ресурсы и программное обеспечение, позволяющее каждому, при наличии интернета получить огромные по меркам 80-х годов пространства для хранения информации и легко управлять этой информацией.
Во-вторых, пользователь больше не думает о том, на каких физических носителях или устройствах размещается его информация, где расположены эти серверы (за исключением случаев, когда кто-то обеспокоен безопасностью). Поскольку пользователь, как правило, не представляет ограничений на объемы хранимой информации или эти объемы так велики, что всем хватает никто и не думает об экономии памяти, фильтрации хранимой информации чистке или уничтожении ненужных данных.
В-третьих, доступ к хранимой информации прост и удобен и каждый человек, размещающий собственную информацию, может обеспечить такой же простой и удобный доступ к ней каждому, кому он захочет.
Именно это и позволило С. Карелову сказать на семинаре РВК «Сейчас сошлись на том, что к 2020 году не будет понятия big data вообще. Потому что все будет big data. Это перейдет в новую парадигму, а старая вообще уйдет» [2.1].
Можем ли мы сказать, что информация стала более доступна? Отчасти — да, потому что:
-
• поисковики значительно упрощают поиск необходимой информации;
-
• для получения необходимой информации не надо никуда ехать — почти все может быть получено сразу с помощью собственного компьютера;
-
• вся информация храниться в таком виде (в таких форматах), которые могут быть прочитаны, практически, с любого компьютера.
С другой стороны, далеко не вся информация храниться в открытом доступе — для доступа к части информации требуется разрешение владельца, а это разрешение может быть получено при выполнении определенных условий (от простого предоставления информации о себе — регистрации, до оплаты доступа или выполнения более сложных условий). Предоставление части информации регламентируется специальными законами, например, законом защищается персональная информация граждан. И все же даже объемы информации, находящейся в свободном доступе огромны и они растут.
Если взглянуть на форматы хранения данных, то возникает ощущение, что их огромное количество, например в одних форматах храниться текст, в других фотоизображения и ри- сунки, аудиоинформация — в третьих, видео — в четвертом. Причем для хранения информации одного и того же типа существует несколько разных форматов. И все же это гораздо более простая ситуация, чем та, которая существовала раньше. Ведь все эти форматы для хранения информации в электронном виде! И поэтому принципиально понятно, как можно осуществлять обработку информации любого типа. Это ведь не тоже самое, когда вы хотите сравнить рисунки сделанные на папирусе и хранящиеся в одном из европейских музеев с рисунками на гробнице в египетском Луксоре! Проблема обработки информации, хранимой в разных форматах сегодня — это проблема программистов.
С точки зрения влияния на жизнь всего человеческого общества и изменений общественного сознания, легкий поиск и доступ к любой информации, возможность сохранять огромные объемы данных и возможность простого обмена информацией между людьми и составляют основное содержание современного «информационного» состояния общества, которое люди косвенно связанные с IT-технологиями маркируют термином Big Data.
Простой доступ к информации и легкая коммуникация между людьми — вот истинные технологические достижения, которые производят наблюдаемые нами революционные изменения в жизни человеческого общества и общественном сознании. В этом процессе есть место и для феномена Big Data, но скорее как следствия, а не как самостоятельного явления.
С точки зрения IT-специалистов, вызовы Big Data, как раз и состоят в необходимости обеспечить возможность обработки информации, которая так велика, что не умещается в одном компьютере (Volume), в необходимости сохранения огромных объемов данных, генерируемых в реальном масштабе времени (Velocity) и в необходимости сохранять и обрабатывать данные, находящиеся в разных форматах (Variety). К счастью, в целом IT-специалисты со многими из проблем Big Data более или менее успешно справляются.
Мифы Больших данных
Напомню, необходимость мышления впервые была признана еще до нашей эры. Сегодня она наконец-то отвергнута.
М. Жванецкий
Представление о том, что вся информация о различных аспектах человеческой деятельности в полном объеме храниться в электронном виде и ее, хотя бы потенциально, можно получить и обработать, не отрываясь от собственного компьютера, не является само по себе удивительным или парадоксальным. Например, в 1974 году в статье «Мир через полвека» академик Андрей Сахаров писал: «Но особенную роль будет играть прогресс в области связи и информационной службы. Одним из первых этапов этого прогресса представляется создание единой всемирной телефонной и видеотелефонной системы связи. В перспективе, быть может, поздней, чем через 50 лет, я предполагаю создание всемирной информационной системы (ВИС), которая и сделает доступным для каждого в любую минуту содержание любой книги, когда-либо и где-либо опубликованной, содержание любой статьи, получение любой справки».
Но все же множество даже образованных людей оказались психологически не готовы к практической реализации идеи, которая до сих пор многим кажется фантастической. Соответственно, общественное сознание легко воспринимает и фантастические планы использования «Больших данных». Действительно, раз мы уже реализовали идею, которая казалось фантастической, то и во всех смежных направлениях, в том числе и в обработке данных должны произойти соответствующие изменения. Сергей Карелов, выступление которого на семинаре
РВК, я уже цитировал выше, высказал эту мысль следующим образом: «Этих данных стало так много, что возникла мысль делать с ними нечто иное, чем делали до того. На самом деле, big data — это не эволюционное развитие процессов быстрой обработки информации. Фишка заключается в том, что это новая парадигма обработки информации, IT. Если раньше до big data была задача, которую надо решить, надо делать алгоритмы, которые ее будут решать, надо искать данные, то здесь меняется сама парадигма. Данных так много, и они настолько разнообразны, что там черт знает что лежит. Можно найти тот самый стратегический инсайд и процесс принятия решений. К сожалению, это очень мало звучало. Но на самом деле, вся история big data — для принятия решений на новом качественном уровне на основании той информации, тех знаний. Здесь big data появилась как новая парадигма» [2.1].
Формулировки этой новой парадигмы, обычно, также многословны и неконкретны, как и определение «Больших данных». Однако суть их сводится к тому, что вместо того, чтобы выдвигать гипотезы о причинах взаимосвязи явлений в реальных процессах и строить соответствующие модели, в которых эти взаимосвязи будут отражаться в виде взаимосвязей параметров (показателей), надо просто наблюдать за взаимосвязью определенных показателей и считать, что эти взаимосвязи и выражают реальные связи. Можно, конечно, задумываться о причинах выявленных связей, но это — потом. Все взаимосвязи, существующие в природе, можно выявить и так.
В книге В. Майер-Шенбергера и К. Кукьера эта мысль выражена следующим образом: «Поразительнее всего то, что обществу придется отказаться от понимания причинности в пользу простых корреляций: променять знание почему на что именно. Это переворачивает веками установленный порядок вещей и ставит под сомнение наши фундаментальные знания о том, как принимать решения и постигать действительность» [3.1.].
Идея о новой парадигме в обработке информации отражена и в представленном на V Грушинской конференции Отчёте Американской ассоциации исследо вателей общественного мнения (AA- Задан набор чисел: POR) о больших данных: «В классиче ской статистической парадигме ис- 10 36 19 б 18 5 : следователи формулировали гипоте зу, определяли состав выборки, разрабатывали инструментарий и методику выборочного исследования, а потом анализировали результаты [Groves, 2011a]. Новая парадигма означает, что сегодня возможно собирать данные в цифровом виде, семантически их согласовывать, сводить и коррелировать» [1.1].
Мысль о том, что могут существовать методы обработки информации, которые позволят выявлять имеющиеся в мире взаимосвязи, путем каких-либо манипуляций с данными, независимо от их (данных) природы или физического смысла, возникала и раньше, но вместе с феноменом Big Data показалась некоторым исследователям очень привлекательной. Такая точка зрения быстро распространилась в литературе, посвященной Big Data. И хотя, обычно, подобные высказывания либо сразу сопровождались многочисленными оговорками, либо опровергались впоследствии, тем не менее они проникали в околонаучную литературу, оттуда — в информационные издания, а оттуда и в сознание многих людей так или иначе, связанных с данными.
С научной точки зрения, возможность получать содержательную информацию путем манипуляции с данными без выдвижения предварительных гипотез и предположений о природе и взаимосвязи этих данных представляется довольно странной. Действительно, классический способ использования математических методов при решении прикладных задач заключается в том, что реальным объектам сопоставляются некоторые математические объекты. В основе такого сопоставления лежит предположение о том, что эти реальные объекты обладают свойствами математических объектов и взаимосвязи между реальными объектами близки или полностью совпадают с взаимосвязями, существующими между математическими объектами. Если такое предположение кажется нам справедливым, то и весь математический аппарат, разработанный ранее для выбранных нами математических объектов, может быть использован для описания объектов реальных. Но задача обоснования выбора того или иного математического метода для описания реальных явлений ложиться на исследователя и именно ему предстоит понять, какой реальный смысл имеют полученные математические результаты. Для того, чтобы понять то, какой математический аппарат может быть использован в каждом конкретном случае и показать правомерность использования такого аппарата, обычно, приходиться потратить значительное время и силы. И в тех научных дисциплинах, где так используют математические методы и научные, и практические результаты впечатляют. Для современного физика мысль о том, чтобы производить математическую обработку данных просто как данных, не вникая в их физический смысл, вызовет удивление и улыбку. И это касается не только физиков. Вот что сказал в интервью по итогам семинара в РВК по большим данным Сергей Абрамов, член-корреспондент РАН, директор Института программных систем имени А. К. Айлама-зяна: «Мы занимаемся многими вещами смежными и родственными с отраслью Big Data. Мы смотрим в эту сторону, стараемся быть в курсе происходящего, делаем новые разработки в этой же струе. Но всегда надо делать то, что действительно кому-то надо. Во главе угла стоит не железо и не программы для него, а задача. Сначала должна быть реальная задача — из потребностей реальной экономики или науки» [2.3].
Об обработке данных вообще или пример того, что не бывает «просто данных»
В качестве иллюстрации того, что получается при статической обработке «просто чисел» рассмотрим следующий пример.
б 36 2 30 7 20 19 36 36 3 36 21 17 16 6 15 30 6
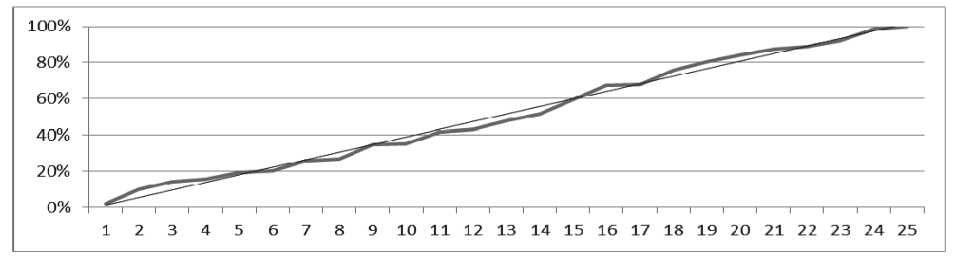
Предположим сначала, что нам неизвестен реальный «физический» смысл этих чисел. Однако, изучая этот ряд с использованием минимального статистического пакета, мы сможем отметить, например, что среднее значение чисел этого ряда равно 18,4 , медиана — 18, а мода — 36. Мы легко найдем и среднеквадратическое отклонение — 11,87. Мы, без труда, построим диаграммы, показывающие частоту появления каждого из чисел в представленном ряду (Рисунок 1) и изменение суммы элементов этого ряда (Рисунок 2), последнее, как мы видим, носит характер близкий к линейному.
Мы можем продолжать вычислять оценки еще каких-либо статистических параметров этого ряда. Однако, до тех пор, пока мы не узнаем содержательного смысла этого числового ряда, наши манипуляции с числами остаются всего лишь упражнениями в использовании статистических методов.
Но, если нам сообщат, что этот ряд представляет собой количество покупок научного журнала «The Big Data Today» в киоске на углу Невского проспекта и Михайловской улицы в Петербурге, в первые 25 дней распространения этого журнала, вот тогда наши данные заиграют многочисленными смыслами! И вот когда мы почувствуем торжество статистических методов!
Ведь мы поймем, что в среднем в день журнал покупают 18 человек, но почти каждый четвертый день количество покупателей было более 30, что общее количество покупателей растет почти линейно и еще, и еще… и еще.
К сожалению, мы не получим этого прекрасного сообщения и не испытаем радости от удачного применения статисти- ческих методов. Потому, что, на самом деле приведенный ряд чисел — это зашифрованная числами строка из стихотворения А. С. Пушкина, являющаяся эпиграфом этой статьи (без кавычек). Буквы от А до Я зашифрованы числами от 1 до 33, а вместо пробелов подставлено число 36. Чтобы понять содержательный смысл этого числового ряда, нам надо проводить совершенно другую обработку данных. Я уверен, что каждый читатель легко догадался бы о способе шифрования, если бы ему заранее сказали, что в этом ряду зашифрована какая-то фраза.
Мы видим, что выбор методов обработки и анализа данных зависит от реального, физического (в широком понимании) смысла этих данных. Статистические методы обработки и анализа не являются универсальным инструментом. Необоснованное применение любых ме
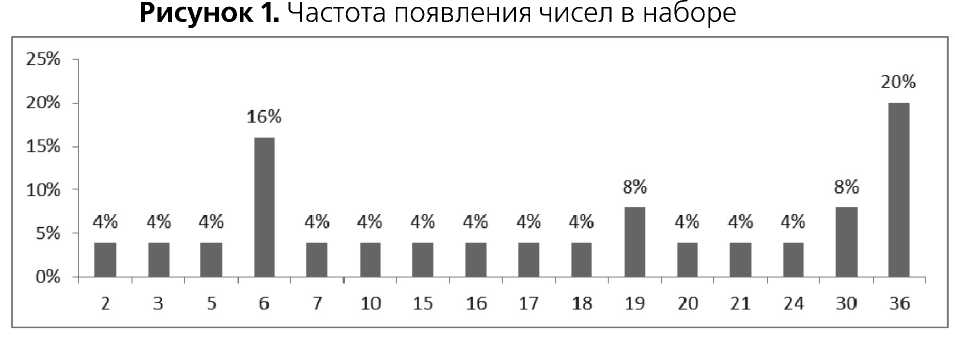
Рисунок 2. Динамика изменения суммы членов в наборе чисел
тодов приводит к получению бессмысленных результатов, которые, однако, могут выглядеть вполне наукообразно.
Более того, и в случае, когда мы знаем, в общем, о природе данных, для выбора методов обработки и анализа часто необходимо более детальное понимание особенностей процесса, который описывают эти данные. Чем более точно мы понимаем природу происходящего, тем более подходящие методы мы сможем использовать, и тем более адекватные результаты мы будем получать. Понимание же природы данных, по сути дела, отражается в модели.
Вы создаете модель, даже если вы ее не создаете.Пример «о конверсии в магазине»
Но даже, если, производя ту или иную математическую обработку исходных данных, мы не создаем специально никакой модели, это вовсе не означает, что мы не пользуемся никакой моделью. Действительно, ведь разработчики математических методов и процедур опираются на некоторые предположения, на основании которых они и вывели эти правила и процедуры. Обоснование того, что эти предположения можно использовать при изучении реальных процессов ложиться на исследователя. И исследователь должен понять, какие же предположения сделаны создателями математического аппарата, который он собирается использовать. Если данные обрабатываются без модели — это означает, что мы просто не хотим утруждать себя осознанием того, какие предположения мы сделали, решив применить те или иные методы обработки. Рассмотрим для подтверждения этой мысли еще один пример.
В одном большом магазине, который торгует товарами, предназначенными для использования в домашнем хозяйстве, было установлено устройство для подсчета числа посетителей. Директор магазина ежедневно определял долю покупателей, среди общего числа посетителей. Делал он это путем вычисления отношения числа покупателей (которое определялось по количеству чеков) к числу посетителей (подсчитанных с помощью устройства). Полученное частное, составлявшее примерно 50%, он интерпретировал, как коэффициент конверсии (назовем этот способ подсчета коэффициента конверсии «алгоритмом директора»). Полагая, что значение 50% слишком низкое, директор поставил своим сотрудникам задачу увеличить этот коэффициент до 75%.
Однако, опрос посетителей магазина, проведенный на выходе, показал, что с покупками ушли около 82% опрошенных. В ходе анализа данных, собранных путем опроса посетителей, были объяснены различия в оценках коэффициента конверсии, полученного разными способами. Дело было в том, что то- вары, представленные в этом магазине, предназначались для использования домашним хозяйством в целом и за покупками часто приходили сразу несколько членов одного домашнего хозяйства. Поэтому потенциальным покупателем являлся не каждый посетитель магазин, а группы посетителей. Группы состояли чаще всего из одного, двух или трех человек, а отношение общего числа посетителей к числу групп составляло 1,7 (условно, эту величину можно считать «средним размером группы потенциальных покупателей»). Таким образом, количество потенциальных покупателей было в 1,7 раза меньше, чем полученное с помощью счетчика посетителей, коэффициент конверсии составлял 85%, что вполне соответствовало результатам опроса. Заметим, что при таком значении среднего размера группы потенциальных покупателей коэффициент конверсии, рассчитанный по методике директора, не может превышать 60%.
Этот пример приведен вовсе не для того, чтобы прославить маркетологов и посмеяться над их клиентами. А для того, чтобы продемонстрировать, как отказ от построения модели на самом деле приводит к неосознанному использованию неправильной модели. Основная ошибка, сделанная директором, состояла в том, что он пользовался в неявном виде и неосознанно некоторыми предположениями, которые и составляли простую модель покупательского поведения. Действительно, ведь для того чтобы обосновать правильность вычисления коэффициента конверсии с помощью «алгоритма директора» надо было сделать следующие предположения:
-
1. Покупки в этом магазине совершаются в интересах домашнего хозяйства в целом.
-
2. От каждого домашнего хозяйства в магазин прибывает ровно ОДИН потенциальный покупатель.
Второе предположение этой модели, как мы видели, неверно. Но вряд ли директор рассуждал о предположениях, когда искал оценку коэффициента конверсии. Вероятнее всего, ему казалось, что никакая модель в этом простом случае не нужна.
Каждый раз, когда мы применяем какие-то математические методы, мы явно или неявно делаем определенные предположения. Правильным является проверить, что эти предположения верны в нашей конкретной ситуации. Даже не очень сложные математические методы подчас подразумевают, что выполнены множество различных условий. И если вы не знаете, каковы эти условия, то это означает только то, что вы неявно считаете их выполненными. То есть вы пользуетесь какой-то моделью процесса, даже не зная, что это за модель. Например, применяя методы математической статистики, разработанные во многих случаях для нормально распределенных слу- чайных величин, вы всегда проверяете, что у вас все распределения нормальны?
Корреляция как панацея
Когда рассуждают о новой научной парадигме, которая возникает в связи с понятием Big Data, речь идет, как мы уже видели, идет об обработке данных путем выявления взаимосвязей между показателями или группами показателей и последующей интерпретацией этих связей. Впрочем, новая парадигма не требует, насколько можно понять, немедленной интерпретации (то есть ответа на вопрос почему?), а допускает просто констатацию наличия зависимости. Я не стремлюсь утомить читателя рассмотрением с этой точки зрения разных способ выявления зависимостей и остановлюсь только на самом распространенном методе — поиске корреляций (тем более, что именно этот метод прямо упоминается в докладе AAPOR [1.1]). Несмотря на кажущуюся простоту и распространённость употребления этого статистического показателя, коэффициент корреляции двух случайных величин не такая уж простая для понимания конструкция. «Определенный выше коэффициент корреляции принадлежит к числу наиболее трудных для понимания числовых характеристик теории вероятностей. Если такие характеристики, как частота, вероятность, математическое ожидание, стандартное отклонение, осознаются сравнительно легко, то понятие «коэффициент корреляции» долго не доходит до сознания. Это в первую очередь объясняется сравнительной сложностью выражения для этого коэффициента и отсутствием соответствующего понятия в обыденной жизни», — пишет в упомянутой уже книге академик П. Эльясберг [4.3].
Напомню, что в теории вероятностей доказывается, что коэффициент корреляции двух случайных величин (для тех случаев, когда он существует!):
-
• принимает значения от -1 до 1. При этом значение 1 или -1 коэффициент корреляции принимает тогда и только тогда, когда случайные величины зависит друг от друга линейно;
-
• если случайные величины независимы (в том смысле, в каком определяет независимость теория вероятностей), то коэффициент корреляции равен 0 (такие случайные величины называются некоррелируемыми). Обратное, что очень важно, неверно, то есть некоррелируемость не означает независимости.
Близость значения коэффициента корреляции ( или его статистической оценки) к 1 или -1, обычно интерпретируется, ду показателями х и у, а пытаемся установить факт наличия или отсутствия такой зависимости, изучая соответствующие значения пар чисел (х,у), полученный нами в ходе некого эксперимента.
Пусть мы получили две последовательности пар:
-
• одна — 11 значений, начиная от х= -0,5 и до х=0,5 с шагом 0,1 (-0,5; -0,4; -0,3; … 0,4; 0,5);
-
• другая — 11 значений, начиная от х=3 и до х=4, тоже с шагом 0,1 (3,0; 3,1; 3,2; … 3,9; 4,0).
Оценивая значение коэффициента корреляции по первой последовательности, мы получим в точности значение 0. Хотя очевидно, что речь идет о заведомо зависимых величинах.
А оценивая значения коэффициента корреляции по второй последовательности, мы получим значение очень близкое к 1 (примерно 0,9992), хотя зависимость между х и у заведомо нелинейная.
Однако и просто автоматическое нахождение корреляций тоже приводит к появлению проблем с интерпретацией получаемых данных, но проблем несколько другого рода. Об этом следующий пример.
Пример о числе корреляций и о конце поэзии
Этот пример вызван рассуждениями о новой парадигме в обработке и анализе данных, которая заключается в возможности автоматизировать просто поиск корреляций среди любых наборов данных, а затем в анализе полученных корреляций и отборе действительно существенных. Таким образом, могут быть выделены действительно существующие причинно-следственные связи и сформулированы новые научные гипотезы.
Рассмотрим набор данных, включающих в себя N показателей, которые мы обозначим через A1, A2, …, AN. Предположим, что эти показатели описывают N независимых друг от друга процессов. Это означает, что процессы развиваются независимо друг от друга и не влияют друг на друга никаким способом. Соответственно, показатели A1, A2, …, AN попарно независимы. Однако, независимость процессов не означает, что не существует общих факторов, влияющих на все процессы сразу. Так, в упомянутой книге академика П. Элья-сберга [4.3] приводится пример того, как солнечная активность является фактором, влияющим на количество автомобильных аварий и на количество неисправностей на искусственных спутниках Земли. Известно, что солнечная активность влияет на многие непосредственно между собой не как показатель того, насколько зависимость случайных величин отличается от линейной (чем ближе к 1 или -1, тем ближе эта зависимость к линейной).
Наличие близкого к 1 или -1 коэффициента корреляции не означает наличие причинно следственной связи, а означает только, что две случайные величины изменяются вместе, возможно из-за наличия какого-то третьего фактора.
Насколько надо быть осторожным при интерпретации результатов, полученных путем оценки коэффициента корреляции, показывает следующий пример.
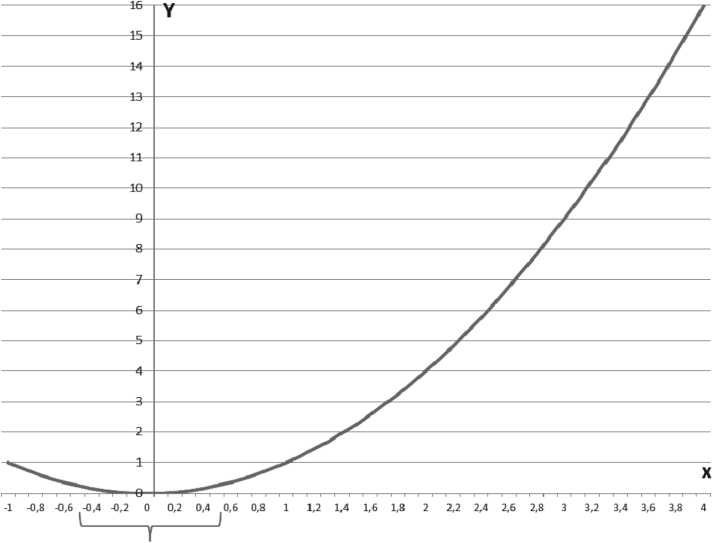
Пример о параболе
Представим себе, что два показателя (две случайные величины), обозначим их через х и у, связаны между собой в реальности простым соотношением у=х2. График этой функции парабола, хорошо известная всем из школьного курса (Рисунок 3).
Представим теперь, что мы не знаем изначально, имеется ли зависимость меж-
Рисунок 3. Графическое представление зависимости показателей x и y
связанные процессы на Земле. Предположим теперь, что имеется фактор, влияющий на все рассматриваемые нами процессы. Этот фактор описывается показателем B. Предположим также, что каждый из показателей A1, A2, …, AN линейно зависит от показателя B. Тогда, наблюдая в ходе эксперимента значения показателей A1, A2, …, AN и B, с учетом возможной погрешности определения их значений, мы получим значения коэффициентов корреляций между показателями Ai и B, близким по модулю к 1
|r (Ai,B)| ? 1, где i=1, 2, …, N
Однако, поскольку зависимости между показателями Ai и B линейны, для всех i=1, 2, …, N , линейными будут и зависимости между парами показателей Ai и Aj для всех i=1, 2, …, N и для всех j=1, 2, …, N . Таким образом. Значения коэффициентов корреляции между ними будут также близки по модулю к 1
|r (Ai,Aj)| ? 1 , для всех i=1, 2, …, N и для всех j=1, 2, …, N.
В ходе нашего исследования мы выявили бы N зависимостей, действительно отражающих причинно-следственные связи между процессами (это зависимости между показателями Ai и B для всех i=1, 2, …, N ). Но, вместе с тем, выявили бы еще больше корреляций между парами показателей Ai и Aj, для всех i=1, 2, …, N и для всех j=1, 2, …, N . Очевидно, что такие зависимости не отражают никаких причинно-следственных связей, а отражают только факт наличия у процессов общей причины. Количество таких «наведенных» корреляций рассчитывается, как известно из комбинаторики, как «число сочетаний из N по 2» и равно, в соответствии с [5.3]:
№(N-1)/2
Таким образом, при нахождении N «полезных» зависимостей, мы будем вынуждены изучить порядка N2 — «наведенных». Хорошо еще, если в обрабатываемых нами данных будет присутствовать показатель B ! А если окажутся только показатели A1, A2, …, AN , то вся работа будет проделана впустую. К тому же никаким «автоматизированным» способом не получится отобрать действительно значимые корреляции. Для этого придется построить математические модели процессов или, по крайней мере, качественно обосновать наличие реальной причинно-следственной связи. Автоматизированный поиск корреляций не высветит зависимости, не замеченные пока еще исследователями, а вывалит на исследователей кучу мусора, в которой надо будет найти «жемчужное зерно».
Такая автоматизация напоминает мне попытку писать стихи путем автоматизированной генерации различных наборов букв, а затем оценка полученных последовательностей на предмет получения гениальных стихов. Например, стихотворение А. С. Пушкина, строка из которого взята в качестве эпиграфа этой статьи, состоит из 611 знаков, включая пробелы. Если мы возьмем алфавит русского языка (33 знака), добавим еще пробел, точку, запятую и двоеточие (как у поэта), то всего получим 37 знаков. Расстановки 37 знаков в 611 разных комбинациях в комбинаторике [5.3] называются «размещения с повторениями». Их количество в данном случае составляет 37611. Полученное число составляет, примерно 10958 (единица и 958 нулей). Конечно, количество комбинаций можно уменьшить — например, выкинув сразу слова, начинающиеся с пробела, знаков препинания и некоторых букв, а также сочетания, состоящие из большого числа повторений одной буквы, но все же количество комбинаций будет огромно. А самое главное, уверены ли мы, что тот «оценщик», который будет просматривать сочетания, сумеет правильно оценить гениальные строки? Для того, чтобы заметить в сгенерированной последовательности гениальные стихи, придется, вероятно, в качестве «оценщика» посадить «нового» Пушкина?
Пример о гриппе
Рассмотрим теперь замечательный пример, который приводится в книге В. Майер-Шенбергера и К. Кукьера [3.1]. Это пример о предсказании зоны распространения пандемии гриппа H1N1 в 2009 году. Пример этот действительно поучительный, он кочует из издания в издание, из одного рассказа об опыте использования Big Data в другой. В какой-то мере, этот пример уже стал классикой. Я не знаком с деталями этого проекта, а слышал о нем много раз только в пересказе. Однако, этот пересказ давно живет уже отдельно от реальности и в разных изложениях обрастает новыми потрясающими воображение деталями. Поучительный рассказ о завершении этого проекта мы услышали от Д. Рогозина (РАНХиГС). И его рассказ мы приведем ниже почти полностью.
Итак, прогноз, насколько можно судить по описанию в книге [3.1], делался компанией Google путем анализа содержания поисковых запросов. Судя по всему, были проанализированы запросы 2007-2008 годов и информация о территориях распространения гриппа в эти же годы. В результате, было выявлено «сочетание 45 условий поиска, использование которых с математической моделью давало коэффициент корреляции между прогнозируемыми и официальными данными, равный 97%» [3.1]. (О чем говорят авторы этой невнятной цитаты можно только догадываться, я все же не возьмусь изложить ее смысл нормальным научным языком, хотя, возможно, что это просто какая-то ошибка перевода). Затем, полученные «условия поиска» были использованы для того, чтобы анализируя запросы уже 2009 года получить информацию о территориях распространения гриппа.
Заметим сразу, что, хотя в начале и в конце этого волнующего рассказа речь идет о распространении вируса H1N1-2009, территории распространения именного этого вируса указанным способом выявить невозможно по следующим причинам:
-
• во-первых, при выявлении «45 условий поиска» использовались данные об эпидемиях тех лет, когда упомянутый вирус еще не фиксировался;
-
• во-вторых, и, в главных, как мы узнаем из сообщения Всемирной организации здравоохранения (ВОЗ) о вирусе H1N1: «Признаки пандемического гриппа схожи с гриппозными проявлениями, включая дискомфорт, повышенную температуру, кашель, головную боль, боль в мышцах и суставах, боль в горле и насморк, а иногда тошноту и диарею. Большинство людей болеют пандемическим гриппом в легкой форме и полностью выздоравливают без лечения» [5.1]. То есть больные не могут самостоятельно диагностировать у себя грипп, вызванный именно вирусом H1N1 и, следовательно, ни от них, ни от окружающих не могут поступить какие-то специфические связанные именно с этим вирусом запросы.
Таким образом, выявить зоны распространения именно пандемического вируса H1N1, описанным выше способом не представляется возможным. А вот территорию распространения эпидемии обычного гриппа таким способом, вероятно, можно определить. Причем можно до тех пор, пока поведение людей при заболевании гриппом остается похожим на их поведение в 2007-2008 годах. И не просто поведение людей, а поведение в Интернете и даже не просто поведение в Интернете, а именно поведение с точки зрения поисковых запросов. Как только это поведение по каким-то причинам изменится — зоны распространения будут определены неверно. В какой момент произойдет изменение поведения понять невозможно, потому, что мы же не объяснили, почему люди реагируют на грипп именно подобным образом (то есть мы не создали модели поведения людей). А значит можно только надеяться, что в очередной год поведение не изменилось и прогноз остается верным. А поведение людей со временем обязательно изменится и даже в таком, вроде бы, понятном вопросе, как лечение гриппа. Очевидно, что это поведение будет зависеть, например, от тех средств профилактики и борьбы с гриппом, которые в общественном сознании будут позиционированы, как наиболее эффективные, и от рекламной кампании, которую будут проводить фармацевтические компании, и от освещения эпи- демической обстановки в СМИ. Возможно, найдутся и другие факторы, влияющие на поведение населения в условиях приближающейся или уже наступившей эпидемии гриппа. И действительно, вот какое продолжение этой истории мы услышали на пленарном заседании V-й Грушинской конференции от Дмитрия Рогозина: «В том докладе, который мы перевели на эту конференцию (видимо, речь идет о докладе [1.1] — прим. автора) — он у вас есть — приводится очень любопытный пример, когда Google по своим прогнозам, построенным по запросам на поисковых данных, давал совершенно точный прогноз по обращению людей с респираторными заболеваниями и с гриппом — более точный, чем вся статистика, которая есть в Соединенных Штатах. И на эти прогнозы стали сильно ориентироваться. Понятно, что там есть и денежная составляющая, потому что через них можно было оценить потоки больных в больницу и потребности в страховых компаниях. И вот они давали точнейшие прогнозы три-четыре года, и на пятый (в 2013 или в 2014) произошел колоссальный провал. Провалилось всё — начали разбираться. И тут стал возникать шанс того, что мы действительно можем осмысленно начать говорить о больших данных, не сказки друг другу рассказывать, что там — хорошо, здесь — хорошо, что у нас возникла новая эра ползучего эмпиризма» [1.2]. Интересно в чем же тогда отличие подобных прогнозов от простого угадывания, даже если мы назовем это «ползучим эмпиризмом»?
Этот пример показывает неизбежность ошибки прогнозирования, когда вместо осмысления происходящих процессов, формирования на основе этого осмысления модели процесса и создания прогноза на основе модели, мы пытаемся экстраполировать прошлое в будущее. Можно двигаться по прямой дороге спиной вперед и предсказывать, маршрут, глядя на пройденный путь, в надежде, что впереди ситуация, примерно, такая же, как и позади. Но на первом же резком повороте вы сойдёте с дороги и упадёт в кювет.
Когда мы изучаем корреляции в прошлом и экстраполируем их в будущее, то все будет хорошо, пока будут сохраняться условия, которые обеспечивают, более или менее, непрерывность по времени прогнозируемых показателей. Этих условий мы не знаем и наибольший интерес представляют ситуации, когда небольшие изменения в исходных условиях приводят к скачкообразным изменениям изучаемых показателей. Именно такие ситуации наиболее важны для прогнозирования резких изменений, в том числе, и в экономике, и в социальных процессах. Но такие скачкообразные изменения изучаемых показателей невозможно предсказать, экстраполируя прошлые процессы на будущее, да еще используя для этого непрерывные функции. Если нам так повезло, что удалось создать настолько подробную модель изучаемого процесса, что для описания динамики отдельных или всех показателей могут быть использованы дифференциальные уравнения, то мы, скорее всего, сможем выявить условия скачкообразных изменений изучаемых показателей. Это и будут ситуации кризисов и именно изучением таких ситуаций занимается направление в математике, которое несколько пафосно называется теорией катастроф [5.7].
Прошлый опыт осмысливается человечеством путем понимания глубинных причин и взаимосвязей и понимание этих глубинных причин и взаимосвязей позволяет создавать модели, на основании которых можно делать прогнозы. В известном смысле и модель формируется на основе уже имеющегося (прошлого) опыта, однако модель подразумевает, что мы понимаем именно принципы развития процесса, которые существенно реже подвергаются изменениям со временем, чем условия развития процесса. «Знание некоторых принципов легко возмещает незнание некоторых фактов», — сказал об этом еще в XVIII веке французский философ Клод Адриан Гельвеций.
«Огуречный» результат
Почти 50 лет назад вышли ставшие впоследствии очень по- пулярными среди научных работников, студентов и преподавателей вузов книги «Физики шутят» и «Физики продолжают шутить». Это были сборники переводных юмористических статей о науке и ученых. Во второй из этих книг был приведен доклад, который называется «О вреде огурцов (Упражнение в сравнительной логике и математической статистике)». Цитаты из этого доклада часто использовали, для иллюстрации ошибок при обработке данных, связанных именно с предлагаемой новой «парадигмой» в обработке данных. Вот лишь одна цитата из этого короткого доклада:
-
« 99,7% всех лиц, ставших жертвами автомобильных и авиационных катастроф, употребляли огурцы в пищу в течение двух недель, предшествовавших фатальному несчастному случаю. 93,1% всех малолетних преступников происходят из семей, где огурцы потребляли постоянно» [5.4].
Полвека назад такие результаты казались смешными, но одна из особенностей феномена Big Data состоит как раз в том, что доступ к данным резко упростился, также как и методы первичного анализа. В результате внедрения «новой парадигмы» мы еще услышим о множестве подобных «огуречных» открытий. А провалы, подобные тому, который произошел при определении районов, охваченных эпидемией гриппа из приведенного выше примера — это еще цветочки. Разница между современными «огуречными» результатами и результатами полувековой давности заключается в том, что современные будут поддержаны мощной кампанией по продвижению «новой парадигмы».
О конце выборочного метода и наивной вере в «N=Всё»
Надо с сожалением признать, что, хотя выборочный метод в эмпирической социологии используется уже давно, глубокого понимания сути этого метода среди использующих его социологов и маркетологов не наступило. Особенно это касается специалистов в области маркетинговых исследований, применяющих социологические методы. В известном учебнике по маркетинговым исследованиям в разделе, посвященном выборочному методу, встречаем «соображения» типа: «Бюджет и временные ограничения служат существенными доводами в пользу выборки» [5.7]. Поэтому не приходиться удивляться, что, взяв понятие Big Data, в качестве инструмента объясняющего самим фактом своего существования любые изменения в обработке информации, можно попробовать еще раз «изменить парадигму», в этот раз, отказавшись от выборочного метода.
Невозможно удержаться от длинной цитаты из много раз упомянутой книги В. Майер-Шенбергера и К. Кукьера. Эта цитата должна вызывать изумление у каждого человека, хотя бы немного разбирающегося в методах математической статистики и обработки данных: «Выборка — продукт эпохи ограниченной обработки информации. Тогда мир познавался через измерения, но инструментов для анализа собранных показателей не хватало. Теперь выборка стала пережитком того времени. Недостатки в подсчетах и сведении данных стали гораздо менее выраженными. … Понятие выборки подразумевает возможность извлечь максимум пользы из минимума материалов, подтвердить крупнейшие открытия с помощью наименьшего количества данных. Теперь же, когда мы можем поставить себе на службу большие объемы данных, выборки утратили прежнюю значимость. Технические условия обработки данных резко изменились, но адаптация наших методов и мышления не поспевает за ней. Давно известно, что цена выборки — утрата подробностей. И как бы мы ни старались не обращать внимания на этот факт, он становится все более очевидным. Есть случаи, когда выборки являются единственным решением. Однако во многих областях происходит переход от сбора небольшого количества данных до как можно большего, а если возможно, то и всего: «N = всё». Используя подход «N = всё», мы можем глубоко изучить данные. Не то, что с помощью выборки!» [3.1].
Я привел эту цитату не для того, чтобы разбирать весь этот набор нелепостей и дилетантских высказываний, а только для того, чтобы показать, что эти наивные представления действительно существуют. Важным является то, что авторы при подходе к описанию различных процессов, окружающих человека, в том числе, происходящих в экономике и социальной сфере, неявно исходят из идеи детерминизма, полагая, что «все» в принципе может быть изучено.
На самом деле, огромное количество экономических и социальных процессов (может быть их подавляющее большинство), с точки зрения теории вероятностей может быть описано только случайными процессами. Случайный процесс довольно сложное понятие из области теории вероятностей и здесь я отмечу только, что это понятие я употребляю в классическом смысле, который описан, например, в классической книге И. Гихмана и А. Скорохода [5.8].
В частности, распределение числа автомобилей на улицах городов, количество покупателей в магазине, объем ежедневных покупок, количество посетителей кинотеатров, количество телефонных звонков, обращения в органы государственной власти и т.д. и т.п. — все эти процессы моделируются случайными процессами. А если это так, то ни о каком «N=Всё» не может идти и речь. Потому что, если мы изучили все события, произошедшие в течение сегодняшнего дня, то мы изучили просто одну из реализаций случайного процесса. Завтра будет другая, а для того чтобы оценить параметры этого процесса выборки более, чем достаточно.
Вероятностная парадигма (а вот это действительно новая парадигма!) при описании подобных процессов появилась относительно недавно. Ее появление связано с созданием академиком Андреем Колмогоровым аксиоматизации теории вероятностей в 30-х годах прошлого века. Но окончательное становление и философское осознание понятия «вероятность» произошло только в 50-х годах при выдающемся участии математика и философа профессора Василия Налимова. О становлении этой парадигмы можно прочитать в четвертой главе книги В. Налимова «Облик науки» [4.1]. Это философское осмысление позволило вероятностной парадигме быстро занять важнейшее место в технических науках, достаточно важное место в естественных науках, но до экономики и социологии эта волна почти не докатилась. Не докатилась она и до их практических приложений.
«Большие данные» и эмпирическая социология или о чем взывают вызовы Big Data?
С точки зрения эмпирической социологии существование разнородных данных большого объема, возрастающего к тому же с большой скоростью, не является никаким вызовом или удачным стечением обстоятельств. А вот то, что среди цивилизованной части человечества произошла революция в восприятии и использовании информации, безусловно, является крайне важным. Важным является и то, что информация, в том числе в значительной степени отражающая особенности поведения людей и их мнения, стала накапливаться в электронном виде и доступ, по крайней мере, к значительной ее части сильно упростился. И, наконец, очень важным для нас является изменение образа жизни людей в связи с открытиями ими возможностей Интернета — общение в социальных сетях, чаты и форумы, интернет-торговля и т.п.
К счастью для тех, кто занимается обработкой данных, методы обработки развиваются достаточно адекватными темпами. Однако те методы обработки, о которых обычно говорят в связи с Big Data представляют исследователю всего лишь набор возможных действий, из которого он должен выбрать методы, соответствующие его задачам. Заметим, кстати, что процесс представления всей имеющейся информации в электронном виде не означает, что вся необходимая исследователю информация имеет большие объемы и относится к категории «Больших данных». Наоборот, большая часть необходимой информации будет вполне обычных размеров. Важнее то, что эта ин- формация может быть обнаружена исследователем в уже готовом для обработки электронном виде. И это, с одной стороны, открывает большие возможности, а, с другой стороны, создает большие проблемы для эмпирической социологии. Потому что, математические методы обработки информации уже имеются в довольно большом количестве и разнообразии, а вот методы интерпретации полученной числовой информации и выявления «социологического смысла» полученных результатов довольно бедны. В прикладной части эти методы сводятся часто к констатации факта. Что получены такие числа и динамика их такая-то без объяснений того почему так получилось и что это означает в социологическом смысле.
Решение этой проблемы для эмпирической социологии лежит на пути создания математических моделей изучаемых явлений, причем взгляд на математику, как на некоторый язык науки, который, как мне кажется, позволяет разрешить конфликт между относительной простотой математических методов и очевидной сложностью даже локальных процессов происходящих в человеческом обществе, в целом изложен в упомянутой работе В. Налимова [4.1].
Без построения математических моделей в эмпирической социологии, все изобилие методов превратиться в манипуляцию с числами. Сами по себе «Большие данные» не приведут к прорыву в понимание закономерностей окружающего нас мира, однако в сочетании с новыми моделями, причем именно математическими моделями, безусловно — приведут. Поэтому следует говорить не о новой парадигме в обработке информации, а о расширении старой парадигмы.
Следует отметить, что множество существующих методов анализа социологической информации, особенно, когда этот анализ производится не социологами, основаны на здравом смысле или на «эвристических моделях» (то есть, не имеющих строго научного обоснования, но, вроде бы, не противоречащих здравому смыслу). В качестве примера такого подхода можно привести модели анализа поведения покупателей в интернет-магазинах [3.9]. Приведенный в настоящей статье «Пример о гриппе» также описывает использование таких методов. Обычно, такие методы создаются IT-специалистами в отсутствии научных моделей поведения людей, построенных социологами. При этом разработчики сосредоточены на обеспечении функционирования всего продукта, а в идеологию его закладывают соображения, исходя из здравого смысла. Само по себе использование «эвристических методов» широко распространено в науке и технике, но следует иметь в виду, что их научная необоснованность не позволяет определить границы применения метода. Существует множество примеров того, как в одинаковых, на первый взгляд, ситуациях один и тот же «эвристический метод» дает разные результаты. Создание обоснованных моделей и направлено в частности на уточнение, обоснование или опровержение уже используемых эвристических методов.
Казалось бы, что «информационная революция» открывает пред эмпирической социологией новые возможности и не несет никаких особых угроз. Однако, это не так. Прикладной и, вследствие этого, часто коммерческий характер эмпирической социологии заставляет использовать каждое новое направление и новую возможность, как элемент рекламы. Вероятно, именно рекламным приемом «присоединение к передовому» можно объяснить н определенную шумиху вокруг Big Data. Придумывание различных новых наукообразных терминов, демонстрирующих свою современность также является одним из рекламных приемов. Примечательно, в этом смысле, высказывание на семинаре РВК специалиста в области Big Data профессора ВШЭ Леонида Жукова: «Не только термин big data, но и другие термины стали теперь популярными. Например, data driven business — и любой бизнес хочет стать именно таким» [2.1].
Big Data предоставляют большие возможности для околонаучных спекуляций, поражая неподготовленного читателя от- четов новой непонятно, но солидно выглядящей терминологией и ссылкой на колоссальные объемы обработанных данных. Например, мы вполне вероятно, скоро узнаем, что « в результате обработки 1,5 миллионов историй болезней с помощью методики BigDataСucumber Analysis выявлено, что 99,9% умерших от рака ели огурцы».
Простота доступа к данным, возможности современных средств обработки данных, в сочетании с рассуждениями о «новой парадигме» в обработке, позволят засыпать информационной пространство огромным количеством подобных исследований. Этот поток почти не наносит ущерба теоретической социологии, как науке, но наносит, очевидный ущерб прикладным направлениям, в частности, эмпирической социологии. Остановить этот поток невозможно, потому что он востребован рынком. Это утверждение звучит довольно странно лишь на первый взгляд. Дело в том, что основной целью деятельности компании на рынке является коммерческий результат, а вовсе не постижение истины. Поэтому все результаты, способствующие получению коммерческого результата, рынок приветствует. А такие результаты, вопреки утверждениям из учебников по маркетинговым исследованиям, далеко не всегда должны соответствовать реальности. Более того, обладание реальной информацией о рынке является разве лишь необходимым, но, совершенно точно, недостаточным для достижения коммерческого успеха.
Процесс использования понятия Big Data в рекламных целях уже идет полным ходом и это объективный процесс, сопровождающий каждое новое явление, а тем более явление такого масштаба, как «информационная революция». Однако необходимость отделять «зерна от плевел» все же есть. Иначе мы рискуем просто скомпрометировать эмпирическую социологию и связанные с ней прикладные дисциплины в глазах общества. Инструментом и арбитром в процессе отделения должна бы стать теоретическая социология и университетская наука. Примером такого подхода являются взаимоотношение астрономии и астрологии. Рынок услуг астрологии, вероятно, в разы превосходит рынок астрономических услуг. Однако, все потребители астрологических услуг предупреждены со стороны научного сообщества о том, что они покупают ненаучные результаты. Хороший пример этих взаимоотношений приведен в [5.8].
«Информационная революция» в форме Big Data призывает эмпирическую социологию стать настоящей наукой (точнее настоящей частью настоящей науки), использующей настоящий язык науки — математику и современные научные методы моделирования. И тогда реализуется и «маленькая надежда на чудо», о которой говорил на V-й Грушинской конференции Александр Ослон.
Список литературы Загадки «больших данных» или from Big Data to куда-то
- Джапек, Л., Кертнер, Ф., Берг, М. и др. Отчет AAPOR о больших данных: 12 февраля 2015/Американская ассоциация исследователей общественного мнения; Пер. с англ. Д. Рогозина, А. Ипатовой, Е. Вьюговской; Предисловие Д. Рогозина. М., 2015. Материалы V социологической Грушинской конференции, 2015
- Тезисы V социологической Грушинской конференции «Большая социология: расширение пространства данных»; 12-13 марта 2015 г. -Материалы конференции -М: ВЦИОМ, 2015 -814 с
- Виктор Майер-Шенбергер, Кеннет Кукьер, Большие данные. Революция, которая изменит то, как мы живем, работаем и мыслим. Издательство: Манн, Иванов и Фербер. 2013 г
- Билл Фрэнкс, Укрощение больших данных. Как извлекать знания из массивов информации с помощью глубокой аналитики. Издательство: Манн, Иванов и Фербер, 2014 г
- Аналитический обзор Больших Данных. Компании IPOboard и Московская биржа, 2015, ООО «Борд»
- Налимов В. В. Облик Науки. СПб. -М: Центр гуманитарных инициатив, Издательство МБА, 2010
- Осуга С. Обработка знаний: Пер. с японского -М. : Мир, 1989
- Эльясберг П. Е. Измерительная информация: сколько ее нужно? Как ее обрабатывать? -М.: Наука. Главная редакция физикоматематической литературы, 1983
- Арнольд В. И. Теория катастроф. -3-е изд., доп., -М: Наука. Гл. ред. физ.-мат. лит., 1990
- Виленкин Н. Я. Комбинаторика. М.: Наука. Гл. ред. физ.-мат. лит., 1969
- Физики продолжают шутить. Сборник переводов. Составители переводчики: Ю. Конобеев, В. Павлинчук, Н. Работнов, В. Тур-чин. Издательство «Мир», Москва, 1968
- Сурдин В., Астрология и наука. Издательство «Век 2», Фря-зино, 2007
- Малхотра, Нэреш К., Маркетинговые исследования. Практическое руководство. Третье издание, Издательский дом «Вильямс», Москва, Санкт-Петербург, Киев, 2002
- Гихман И. И., Скороход А. В. Введение в теорию случайных процессов, М: Наука, 1977
