Защита информации в автотранспортных системах связи и мониторинга

Автор: Пестриков Виктор Михайлович, Маковецкая-Абрамова Ольга Валентиновна, Петров Геннадий Алексеевич
Журнал: Технико-технологические проблемы сервиса @ttps
Рубрика: Методические основы совершенствования проектирования и производства технических систем
Статья в выпуске: 2 (24), 2013 года.
Бесплатный доступ
В статье рассматриваются вопросы защиты информации в автотранспортных системах связи с использованием помехоустойчивых кодов. Предлагается алгоритм и структура кодирующих и декодирующих устройств c конвейерной обработкой блоков данных для обнаружения и исправления пакетов ошибок. Обсуждаются задачи системного, структурного и логического этапов проектирования предлагаемых структур.
Системы связи и мониторинга, сommunication and monitoring, конвейерный кодек, помехоустойчивый код, алгоритм кодирования, конвейерная обработка блоков, траектория пакета, потоковые функции
Короткий адрес: https://sciup.org/148186087
IDR: 148186087 | УДК: 681.325.5-184.4
Protection of information in transport systems communication and monitoring
The article deals with the protection of information in the motor systems due to the use of error-correcting codes. An algorithm is proposed and the structure of encoders and decoders c pipelining of data blocks for the detection and correction of error bursts. It is discussed the problem of systemic, structural, and logical design stages of the proposed structures.
Текст научной статьи Защита информации в автотранспортных системах связи и мониторинга
В последние годы в автотранспортные средства интенсивно внедряются различные спутниковые системы связи и мониторинга. Подобные системы позволяют обеспечить такие функции, как: контроль за перемещением автомобилей, дистанционный мониторинг скорости и других важных параметров автомобиля, мониторинг доставки грузов, дистанционная охрана различных объектов, мониторинг времени работы и простоя автомобилей, дистанционная связь с водителем и многие другие. Современные цифровые системы передачи информации, такие как спутниковая, мобильная связь и другие используют беспроводные каналы, которые подвержены воздействию помех различной физической природы. Это приводит к тому, что принятые данные с достаточно высокой вероятностью будут содержать ошибки. В то же время для многих практических применений допустима ограниченная доля ошибок в обрабатываемых дискретных сообщениях. В результате возникает проблема обеспечения надежной передачи цифровой информации по каналам с шумами.
В системах передачи информации возможен ряд стратегий борьбы с ошибками, воз- никающими при передаче данных по каналам связи с различными помехами:
-
• обнаружение ошибок в блоках данных и автоматический запрос повторной передачи повреждённых блоков;
-
• обнаружение ошибок в блоках данных и отбрасывание повреждённых блоков – подход, применяемый в ряде случаев в потоковых мультимедийных системах, в которых отсутствует время на повторную передачу;
-
• исправление ошибок на физическом уровне с использованием помехоустойчивых кодов.
В статье рассматриваются вопросы защиты информации в автотранспортных системах связи и мониторинга с использованием помехоустойчивых (корректирующих) кодов для обнаружения и исправления как одиночных, так и групповых ошибок. Корректирующие коды применяются также во многих системах цифровой связи: передача данных по телефонным каналам, в системах хранения и передачи информации, в модемах и жестких дисках, при передаче данных по сетям WiMax, в оптических линиях связи.
Предлагается алгоритм и структура кодирующих и декодирующих устройств c конвейерной обработкой блоков данных для обна- ружения и исправления пакетов ошибок, рассматриваются организация и проектирование микропроцессорных конвейерных структур помехоустойчивого кодирования информации для защиты передаваемых данных. Основы организации и проектирования микропроцессорных кодирующих и декодирующих устройств с обнаружением и исправлением ошибок для систем передачи информации рассмотрены в работах [1,2,3].
Организация параллельных кодеков с конвейерной обработкой блоков информации позволяет значительно повысить их производительность. Конвейерные кодеки (ККД) имеют следующие преимущества:
-
• простота оценки производительности и монотонный характер ее зависимости от числа процессоров;
-
• функциональная однородность системы и простота ее реконфигурации;
-
• неисправные процессоры легко исключаются из системы, а восстановление задачи сводится к возврату к контрольной точке программы;
-
• отсутствие централизованной управляющей программы, тупиковых ситуаций, а также проблем обмена данными.
Организация конвейерных кодеков
Для организации конвейерных кодеков, например для кода Рида-Соломона (РС), необходимо представить функцию декодирования в виде следующих потоковых функций [2]:
f ( x ) = f . ( f 2 ( f ,,4,5 ( f 5,7 ( f , ) f 9 ( x )))))), (1)
где:
f , ( x ) = R g ( x ) [ ^ ( x )] = S ( x ), обозначим [ F^(x )];
f 8 ( x ) = ( f , ( x )) = S j , x = a j , j = 1,..., 2 t , [ F ,1 ( x )];
f 7 ( x ) = f 7 ( f . ( x ) = Л ( x ), x a j , j = 1,...,2 1 , [ F 41 ( x );
f , ( x ) = f , ( f , ( x )) = Q ( x ), j = 1,...,2 1 [ F ^ ( x )];
f 5 ( x ) = f 5 ( f 7 ( x )) = л ( a j X j = X-, n ,[ F 3 1 ( x );
f 4 (x) = f 4(f - (x)) = л' (x‘X x = aj , j = 1,...21, l = 1,..., t [ F81)
f,(x) = f,(f,(x)) = Q(x ‘X x = a j, j = 1,...,21, l = 1,..., t [ F,1];
f ;( x ) = f , ( f , ( x )),[ F 1 ];
fx ( x ) = fx ( f ;( x )),[ F 71 ].
Каждая подфункция (1) в качестве входных данных использует результаты вычислений предыдущей подфункции, первоначальная подфункция f9(x) работает с входным набором данных принятого кодового блока u(x).Представление структурированных про- грамм декодирования в виде потоковой функции осуществляется следующим образом. Пусть Ф(x) - множество команд в F(x) от первой до некоторой промежуточной команды, ^(x) — множество команд от первой после Ф(x) до последней включительно, и если команды расположены в порядке выполнения, то:
F ( x ) = ^ ( Ф ( x ).
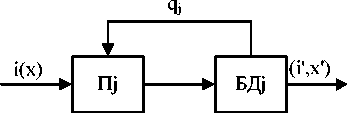
В ККД набор данных представляется в виде пакета ( i, x ), где: х - блок данных; i - номер ступени, равный индексу подфункции.
После i -й ступени ( i, х ) пакет преобразуется в новый пакет (( i -1), F i ( х )). (9, х ) и (0, f ( х )) обозначают соответственно входной и выходной пакеты системы в выражении (1). Схема j -го элемента конвейерного кодека приведена на рис. 1,а, на котором П j - процессор, БД j -буфер данных типа FIFO. Каждый процессор может выполнять любую подфункцию в потоковой функции f ( х ), для чего в его памяти хранятся соответствующие программы. Состояние буфера для j -го пакета определяется следующим образом: если q i = 1, то осуществляется пропуск пакета, а при q i =0 выполняется его обработка.
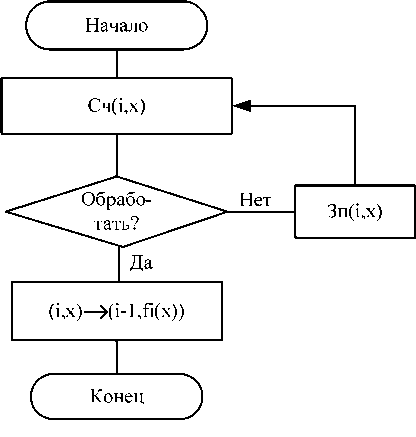
Алгоритм функционирования процессорного модуля представлен на рис. 1,б. Управляющая программа процессора считывает входной пакет ступени, анализирует состояние пакета q j , и если q j =1, то производится пропуск пакета, т. е. пакет без изменения записывается в буфер, а процессор считывает новый пакет. Если q j = 0 или данный процессор последний, то производится обработка пакета по программе j -й ступени. При этом j уменьшается на 1, результат обработки записывается в буфер и цикл работы повторяется.
Для оценки производительности конвейерных кодеков представим возможные траектории при движении пакета (рис. 2).
Фаза обработки в процессоре соответствует перемещению пакета по вертикали до ближайшего элемента, фаза пропуска - перемещению по горизонтали. Обозначим через т0 -среднее время выполнения программы в одной ступени конвейерного кодека, ть -среднее время ввода (вывода) пакета; ю - среднее время анализа условий. Пакет перемещается по вертикали через v ступеней обработки, на что требуется время v(t0 + ю), и по горизонтали через z процессоров за время z(Tb + ю) и zTb соответственно для ввода и вывода информации. Полное время t m перемещения пакета по некоторой траектории определяется следующим выражением:
tm = Z (2Т в +to) + ^(Т0 +®).
Время, затраченное процессорами за период Т для обработки пакетов определяется выражением:
T = N [ z (2 т B + to+у ( т 0 + to )] . (2)
а)
б)
Рисунок1. Конвейерный кодек : а) структурная схема; б) алгоритм функционирования процессора
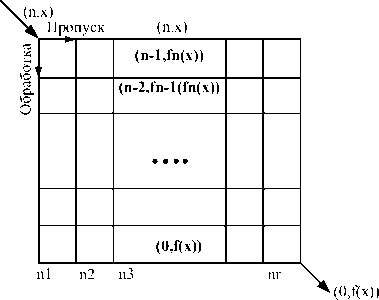
Рисунок 2. Траектория движения пакета в кон вейерном кодеке
Выражение (2) справедливо, если ни один из процессоров не простаивает из-за ожидания входной информации. Для таких систем производительность Р измеряется в пакетах в единицу времени и ее можно определить следующим образом:
P = N =-------1-------.
T (2т B +to+v(T0 +to)
Определим время отклика системы tc как средний интервал от входа пакета в систему до его выхода из нее:
t c = N '[ z (2 т B +to ) + у ( т 0 +to ), (4)
где N - среднее число пакетов, хранящихся в буферах ККД при q = 0. Из (4) следует, что с ростом числа процессоров время отклика также увеличивается. Из (3) определим число процессоров, необходимых для обеспечения заданной производительности P :
Z = У Р (% + to) 1 - p (2т b + to)
Для оценки производительности и времени отклика конвейерного кодека рассмотрена задача декодирования кода РС. Конвейерный кодек кода РС обрабатывает информацию в виде пакетов, которые могут быть обработаны или пропущены различными процессорами ступеней конвейера в зависимости от наличия ошибок в принятом кодом блоке. Для организации кодека сформируем формат пакета, передаваемого через все ступени конвейера (см. рис. 3). Пакет D включает поле 1 для хранения n символов принятого кодового блока V ( х ), поле 2 для вектора ошибок е ( х ), поле 3 для 2 1 символов синдромов, поле 4 для хранения t значений локаторов ошибок и поле 5 для хранения символа q , определяющего состояние пакета. При этом, если q = 0, пакет проходит через ступень с обработкой, в противном случае пакет проходит без обработки.
Структурная схема конвейерного кодека, реализующего код РС, приведена на рис.4. Кодек состоит из шести процессорных ступеней (П1-П6) и функционирует следующим образом. Принятый вектор кодового блока V ( х ) записывается в поле 1 входного пакета 1 первой ступени конвейера, а остальные поля пакета пустые.
|
(1) V(x) 1,2,...,п |
(2) е(х) |
(3) Sj l,2,...,2t |
(4) l,2,...,t |
(5) q i |
Рисунок 3. Формат пакета
Процессор П1 выполняет вычисление синдромного полинома S ( x ), т. е. реализует функцию деления полиномов с недвоичными коэффициентами F 12 и также проверяет значение S ( x ) на нуль. Если S ( x )= 0, т. е. если в принятом векторе V (х) нет ошибок, то процессор П1 устанавливает q в 1 и пакет проходит через все ступени без обработки. Если S ( х ) ≠ 0, то П1
устанавливает q своего выходного пакета в 0. При этом в поле 3 пакета записываются 2 t коэффициентов синдромного полинома S ( x ). П2 ведет обработку входного пакета при q = 0 и вычисляет синдромы S j , j =1,…,2 t в соответствии с функцией F 13, а также вычисляет отношение S j /S j +1 , j =1,…,2 t -1.
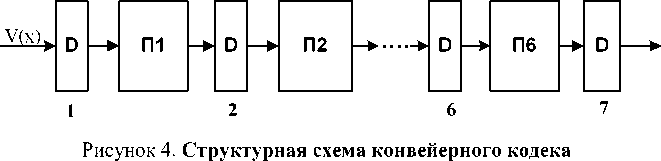
Если это отношение для всех синдромов постоянно, то процессор П2 исправляет единичный пакет ошибок и устанавливает q своего выходного пакета в 1. При этом исправленный блок записывается в поле 1 пакета 3, а в поле 3 помещаются 2t значений синдромов. Если отношение S j /S j+ 1 для j =1,…,2t-1 не постоянно, то процессор П2 устанавливает q своего выходного пакета в 0. Тогда ПЗ ведет обработку пакета 3 и вычисляет функции Ω ( x ) и Λ( x ), их коэффициенты записываются в поле 3 пакета 4, ПЗ устанавливает q пакета 4 в 0. Необходимо отметить, что если q пакета 3 равно 0, то это значение сохраняется до выхода пакета из системы. П4 вычисляет локаторы ошибок х e , е = 1, ..., t по процедуре Ченя (выполнение функции F 13), помещает значения х e в поле 4 пакета 5 и в поле 3 помещает ( t +1)/2 коэффициентов полинома производной Λ'(x) от Λ( x ) вместо коэффициентов Λ(x); коэффициенты Ω( х ) сохраняют свои места в пакете 3. В позициях поля 2 пакета 5, где произошли ошибки, ставятся единицы. Процессор П5 вычисляет значения Λ'(x) и Ω(х) при х=хe, е=1,...,t, и t значений ошибок и помещает их в единичных позициях поля 2, в результате чего формируется пакет 6. Процессор П6 выполняет сложение по модулю два двух векторов (массивов) V(x) и е(х) и передает исправленный блок в поле 1 пакета 7. Каждый из шести процессоров кодека может выполнять программу декодирования кода РС от начала до конца, что важно для повышения живучести системы.
В табл.1 приведен процент вычислений, выполняемых ступенями кодека. Из таблицы следует, что отсутствует сбалансированность по времени загрузки каждой из шести ступеней, поэтому можно объединить ступени (2, 3) и (4, 5, 6). Таким образом, время обработки в 3-й ступени будет определять производительность системы в целом, а кодек будет состоять из трех процессоров. При введении признака одной ошибки в V(х) процессор ступеней (2, 3)
частично обрабатывает пакет, в этом случае следует разделить эти ступени, и кодек будет состоять из четырех процессоров.
Таблица 1. Процент выполняемых вычислений ступенями кодека
|
Номер ступени |
Процент выполняемых вычислений |
|
1 |
33 |
|
2 |
9 |
|
3 |
18 |
|
4 |
37 |
|
5 |
2 |
|
6 |
1 |
Основные этапы проектирования кодеков. Из анализа разработок кодеков можно сделать следующие выводы:
-
• наиболее важным и определяющим этапом при разработке кодеков является этап системного проектирования;
-
• широкий диапазон требований, предъявляемый к кодекам при их проектировании, делает в настоящее время практически неразрешимой задачу выбора оптимальной структуры кодека. Генерация вариантов структур кодеков остается пока монополией высококвалифицированного разработчика, и процесс проектирования достаточно сложных кодеков базируется в основном на эвристических методах;
-
• быстрый прогресс в технологии производства интегральных схем делает актуальной разработку методов распараллеливания и конвейеризации функций кодеков и построение функционально-распределенных кодеков.
Рассмотренные в литературе методики разработки вычислительных и управляющих систем для проектирования кодеков не позволяют учитывать специфику реализуемых задач. Важной является задача обобщения полученных результатов и представление их в виде последовательности основных этапов проектирования циклических кодеков. На рассматривае- мых этапах проектирования решаются задачи системного, структурного и логического проектирования.
Системный этап проектирования
На системном этапе анализируются требования к кодеку, которые задаются техническим заданием и включают:
-
• скорость передачи информации в канале;
-
• тип и число ошибок (одиночные, многократные одиночные, одиночные пакеты);
-
• длину кодового блока;
-
• вероятность ошибочного декодирования бита (не выше 10-9), повторение передачи не разрешается; отказ от декодирования и неправильное декодирование равноценны;
-
• необходимость работы в непрерывном режиме в темпе поступления информации из канала, однако иногда допускается постоянная задержка до десятков длин блоков.
В качестве критерия сравнительной оценки структур кодека выбираем требуемые скорости приема и передачи информации. Исходя из типа ошибок, выбирается корректирующий код из набора кодов, разработанных в теории кодирования. После выбора кода определяются его параметры - длина кода n, избыточность m, порождающий полином g(х).
Логический этап проектирования. На логическом этапе определяются особенности алгоритмов, реализуемых кодеком, и осуществляется их анализ и разработка. Алгоритмы кодирования и декодирования циклических кодов имеют ряд особенностей:
-
• работа в режиме реального времени;
-
• выполнение алгебраических операций в полях Галуа;
-
• представление информации в виде множества блоков, каждый из которых обрабатывается по одному и тому же алгоритму;
-
• различные времена обработки блоков в зависимости от отсутствия ошибок, наличия одной или более ошибок.
Разработка алгоритмов осуществляется на основе выделенных микроопераций, таких как сдвиг массива на один разряд или символ, умножение элементов в GF(2µ), сложение по модулю два двух массивов, вычисление обрат- ного элемента в GF(2µ), cброс и установка i-го разряда регистра. На этом этапе определяется полный набор функций кодеков циклических кодов и их декомпозиция.
Структурный этап проектирования
На структурном этапе проектирования кодеков реализуются алгоритмы выполнения функций, определенных на предыдущем этапе и отвечающих требованиям по быстродействию.
В качестве исходного варианта структуры, реализующей алгоритм выполнения функций кодеков, выбирается микропроцессорный кодек, который включает МП, входной и выходной регистры, ЗУ. Для этого выполняются следующие шаги:
-
• разработка функционально-временной диаграммы при реализации алгоритмов кодека;
-
• выбор типа МП по критериям, определяемым техническим заданием;
-
• разработка и отладка программ для МП кодека.
Если МП кодек не удовлетворяет техническому заданию по быстродействию, необходимо использовать методы распараллеливания и конвейеризации алгоритмов и переходить к организации параллельных кодеков. Когда параллельные кодеки на основе серийных МП не обеспечивают требуемое быстродействие, то осуществляется переход к организации структур с функциональными расширителями. Выделение аппаратно-реализуемых функций выполняется в соответствии с рекомендациями в [2]. Дальнейшее повышение быстродействия кодека связано с реализацией максимального параллелизма функции при обработке блока и использованием матричных структур.
