A Conic Radon-based Convolutional Neural Network for Image Recognition

Author: Dhekra El Hamdi, Ines Elouedi, Mai K. Nguyen, Atef Hamouda
Journal: International Journal of Intelligent Systems and Applications @ijisa
Article in issue: 1 vol.15, 2023.
Free access
This article presents a new approach for image recognition that proposes to combine Conical Radon Transform (CRT) and Convolutional Neural Networks (CNN). In order to evaluate the performance of this approach for pattern recognition task, we have built a Radon descriptor enhancing features extracted by linear, circular and parabolic RT. The main idea consists in exploring the use of Conic Radon transform to define a robust image descriptor. Specifically, the Radon transformation is initially applied on the image. Afterwards, the extracted features are combined with image and then entered as an input into the convolutional layers. Experimental evaluation demonstrates that our descriptor which joins together extraction of features of different shapes and the convolutional neural networks achieves satisfactory results for describing images on public available datasets such as, ETH80, and FLAVIA. Our proposed approach recognizes objects with an accuracy of 96 % when tested on the ETH80 dataset. It also has yielded competitive accuracy than state-of-the-art methods when tested on the FLAVIA dataset with accuracy of 98 %. We also carried out experiments on traffic signs dataset GTSBR. We investigate in this work the use of simple CNN models to focus on the utility of our descriptor. We propose a new lightweight network for traffic signs that does not require a large number of parameters. The objective of this work is to achieve optimal results in terms of accuracy and to reduce network parameters. This approach could be adopted in real time applications. It classified traffic signs with high accuracy of 99%.
Image recognition, Conic Radon Transform, Convolutional Neural Networks
Short address: https://sciup.org/15018981
IDR: 15018981 | DOI: 10.5815/ijisa.2023.01.01
Text of the scientific article A Conic Radon-based Convolutional Neural Network for Image Recognition
Object recognition is considered to be a highly important vision task in computer vision. It has considerably been applied in a multitude of applications such as object tracking, vehicle parking systems, biometric applications and surveillance purposes. The classification methods are constituted of two basic steps: features extraction and classification task. First, features are built on from images and are then given to multiple classifiers. Therefore, the classification performance mainly depends on the features and classifiers. The classical Radon transformation (RT) [1]
is a successful tool for feature extraction that integrates straight lines from a one 2D image. The use of RT has not been restricted to recognizing segments in the image. Several researchers have exploited RT to recognize more complex shapes. RT was then used as a basic tool for various shape descriptors. The shape descriptors defined from the RT generally exploit its mathematical properties such as invariance with respect to geometric distortions such as translation, rotation and change of scale. Multiple applications using RT were realized such as detection of centerline [2], biometric identification such as iris identification [3] and object recognition [4]. Since the RT has shown success in different image processing areas, several researches have been carried out to generalize the RT in order to directly detect complex shapes, namely: circles, arcs of circles, broken lines... etc. Therefore, the generalized Radon Transform (GRT) was introduced as the sum of a function on a family of geometric functions other than straight lines. Two families of the GRT formalisms have been emerged. The first includes approaches that focused on an analytical formalism. A discretization then allows mapping from continuous to discrete domains [5, 6, 7]. However, there are other types of discrete RT transformations that based on algorithms applied directly to the image [8, 9, 10, 11].
Deep neural networks have received special attention in the last years as regards to their efficiency in recognizing complex patterns [12]. In fact, deep neural networks have found applications in different fields such as image classification [13], recognition of digit [14] and face recognition [15]. In this work, we propose a new image classification approach entitled CRT-CNN which extracts global features by the use of the CRT which are further combined with the Convolutional Neural Networks (CNN) for the classification task. Good classification rate and less computational complexity are our main objectives in this work.
This paper is structured as follows: section 2 presents a review of the state of the art methods. Afterwards, section 3 presents a little description of the conic Radon transform as well as the convolutional neural Networks. We then present our deep architecture for image classification. We analyze the experimental results in section 4. In final, section 5 presents a conclusion of the paper.
2. Related Works
In this section, we review the state of the art methods of image classification. There are two principal classes of image classification: Explicit features based approaches and Implicit features extraction methods by convolutional networks We focus on some works of the first category.
The methods of features extraction can be categorized into two classes: local and global features extraction. Local approaches are built on some key points. The most popular features are histogram of oriented gradients (HOG) [16], scale invariant feature transform [17, 18]. HOG is based on the histogram of intensity gradients of an object shape. SIFT consists of turning images into a collection of local feature vectors which are invariant to translation, scaling, and rotation.
Different from local features, global features do not consider certain interest points but they take into account the image as a whole. Usual methods apply the Radon transform to extract global features.
The RT is applied for definition of biometric descriptors [19]. The authors defined a RT feature vector from hand images in the authentication process. Besides, RT is applied for face recognition and provides robustness to many illumination and distortion changes. However, the RT obtained features are relative to a predefined number of projection angles and not to the entire image.
Hasegawa et al. proposed an approach for object recognition with the use of the histogram of RT [20]. It was shown that the method is invariant to rotation, translation and scaling. The authors computed an angle correlation matrix and used the dynamic time incrementation to the angle coordinate to attempt robustness to transformations. But it presents sensitivity to noise.
Another pattern recognition method based on classical RT is the GR-signature proposed by Hentati et al [21]. It is based on the combination of RT and the Gradient operator for generalized pattern recognition. The method consists in applying the gradient to the matrix resulting from the application of the RT. Thus, the authors have used the GR-signature to introduce a new rectangularity measurement metric. It has been proven the GR-signature to be robust against noise and deformation.
Besides, the RT was used to recognize features such as polygon curves. The authors proposed a measure for shape polygonality as a metric for object classification [22].
However, these approaches based on classical RT detect only lines. Recently, researches have focused on detecting more than linear shapes.
Elouedi et al. defined the Multidirectional Generalized Radon Transform (GMDRT) [8]. It is an extension of Beylkin’s Discrete Radon Transformation (DRT) [23].
In 1987, Beylkin introduced the DRT defined to recognize parameterized curves which are translated along the horizontal axis. The GMDRT then generalizes the DRT to allow the detection of curves and geometric objects of the image independently of their orientations.
The major drawbacks of this transform are slowness and huge memory cost due to the large number of curves or objects projections.
The polynomial discrete Radon transform (PDRT) maps polynomial curves into peaks in the parameter space [10]. This approach is dedicated to detect only polynomial curves. This approach is applied to fingerprint identification [24].
It presents a shape descriptor in order to identify a person through their fingerprints. This identification is robust to geometric transformations such as translation and rotation. In [25], the authors extend the GMDRT. The composed shape-invariant Radon transform detects objects of complex shapes. This approach decomposes complex objects into basic shapes and then the Radon transform is used on the elements of an object instead of the whole object. This method allows the reduction of the number of projections in Radon transform by the selection of the most important primitives for each object.
In this paper, we define a generalized Radon transform to detect and recognize sophisticated features. The CRT was presented in [26] and is defined to integrate image over conic sections.
In addition to Radon, the CNN has achieved great results in various object classification applications [27, 28].
The deep architecture AlexNet achieved the best accuracy rate on the ImageNet dataset in the ILSVRC-2012 competition [13]. The network is composed of five convolutional layers, max-pooling or ReLU layers, and three fully connected layers with a final 1000 outputs. Data augmentation techniques were added in this architecture to improve results on the used benchmark. Generally, deep learning applications require complex architectures and big size of training data to achieve the most optimal results.
Kheradpisheh et al. proposed a deep spiking neural networks composed of several convolutional layers which are trainable with the spike-timing dependent plasticity (STDP) [29]. The STDP increases the learning of features corresponding to prototypical patterns that were both salient and frequent.
Instead of applying CNN on original images, several methods have used descriptors as input to CNN architectures. The authors in [30] extract from facial expressions fixed numbers of SIFT features which were thereafter used as an input matrix to CNN architecture.
Hayat et al. defined a deep learning approach called the Template Deep Reconstruction Model (TDRM) [31]. They used an encoder to define models specific for classes for training sets. TDRM is based on hand crafted features and requires fine tuning of parameters to refine results. It also requires a heavy computational time for training.
Plant image classification progress has increased in these years due to deep learning techniques. Several researchers were interested in CNN for leaf classification. A review by Zhou et al. [32] presented a study of recent CNN models. The authors reviewed deep learning models for plant image classification such as ResNet, DenseNet and MobileNet [32]. Through their study, they proved that DenseNet achieved the best results in leaf datasets with accuracy of 100%. All remaining Deep Learning models achieved classification accuracy of around 75%.
A study by Barre et al. [33] was based on an overall CNN architecture called LeafNet. This model is based on the concept of modules. Each module is composed of 2 convolutional layers and a MAX-pooling layer. The whole CNN architecture of LeafNet is constituted of five modules followed by a last convolution layer with a MAX pooling layer and ended with three fully connected layers.
As similar to Leaf net [33], Dual-Path Convolutional Neural Network architecture was based on double deep architectures [34]. It contains two branches, one for learning shape features and the second for learning texture features.
Kaya et al. have employed transfer learning to detect plant for leaf classification [35]. After that, they used logistic regression for leaf classification. Their approach achieved an accuracy of 97% using VGG16 and SVM and 99% using VGG16 and LDA.
These different networks presented above need a lot of parameters in the training process. However, our approach aims to reduce parameter number.
Several CNN approaches have been employed in the traffic signs classification. They achieved excellent results on GTSRB dataset. However, the majority of them have focused on accuracy performance instead of the number of parameters, which leads applications of traffic signs classification to be unadapted for real time scenarios.
In [36], the authors proposed a MicronNet, a highly compact deep convolutional neural network for real-time traffic sign recognition. This network achieved good results in terms of accuracy and parameter requirements.
Recently, authors in [37] have used Hough transform which represents a variant of classical RT and CNN for classification. They have reached performance close to state of the art. However, the authors do not provide information about the number of required parameters. In our proposed CRT-CNN method, we try to join on high accuracy with few computational parameters.
Our contribution in this work is to study the sequential employment of conic Radon transform for feature extraction and the convolutional neural networks applied on Radon space.
3. Proposed Approach 3.1. Conic Radon Transforms
The classical Radon transform (RT) in Euclidean space represents an integration of a function f(x, y) over straight lines. It is defined as:
ЯУЧр,ф) = £+” J -” f(x,y)5(p — xсоs(ф') — ysiтl(ф))dxdy (1)
where 5(.) is the Dirac delta function, ф £ [0, n[ is the orientation of the line and p £] — от,+от[ is the distance between the origin of the coordinate system and the line.
The output of the RT is a parametric space where lines are replaced by luminous points (peaks) whose coordinates p and ф represent the corresponding straight lines parameters (p, фУ
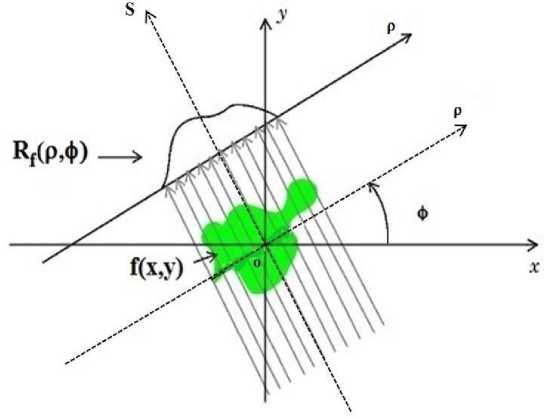
Fig.1. Classical Radon Transform.
As the classical RT is limited to line detection, The CRT was defined to detect conic sections of arbitrary positions and orientations [26].
A conic section can be an ellipse, a parabola, or a hyperbola, according to whether its eccentricity e value is less than, equal to, or greater than 1 (Fig. 2) .
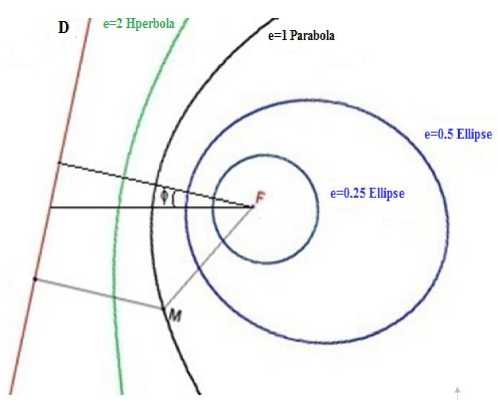
Fig.2. Different Types of Conic Sections: Ellipses (e = 0.25, e = 0.5), Parabola (e = 1) and Hyperbola (e = 2) with Fixed focus F and Directrix D.
The conic section of focus at the origin is represented by: for M(r, 0):
r =
p
1+e со5(6-ф)
where p is the conic parameter and ф corresponds to the orientation of the conic.
The generalized Radon transform represents an integration of a function f(x,y^ over conic sections in the plane. It is defined as:
Rсf(xF,yF,p,ф,e') = jcf(x,y)ds where ds denotes the integration measure on this conic section.
Rcf(xF,yF,p,(p,e) = Jy f (---^——cosCy + ф) + xF,---^——sinCy + ф) + yF)
1+e cos(y) F 1+e cos(y) F
P
V1+e 2 +2 e cos(y) (1+e cos(y))2
dy
where y = 9 — ф.
The CRT space is according to five parameters which are the coordinates of the focus xF and yF, the orientation angle ф, the conic parameter p, and the eccentricity e. (Fig .3) .
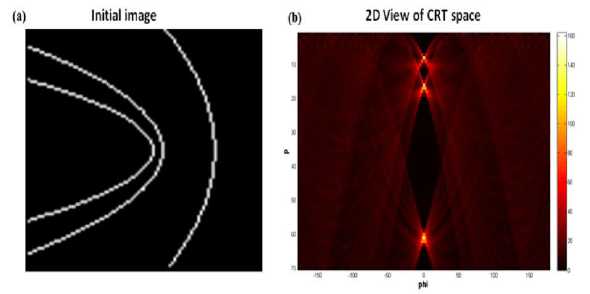
Fig.3. The Result of the CRT on (a) is the (xF,yF,p, ф, e) Parameters Space where (b) presents 2D View of CRT Space (e = 1, xF = yF = 0). Each of the Peaks Corresponds to the Parameters (ф, p) of the Curves.
The basic idea in this work is to apply the CRT in order to extract image’s global features and input the result into CNN in the purpose of achieving an accurate classification.
The features extraction task is reduced to the simple selection of peaks from Radon space. In fact, the integration of an image over curves maps image curves to high leveled points (peaks) in the obtained Radon space.
This paper defines a new object descriptor based on RT over lines, circles and parabolas.
In fact, the result of the CRT over parabolas with fixed focus is a (p, ф) Radon space. We putted the angle ф in [0,180 ° [ and p in [1, ^Nx + № 2 ]. Nx, Ny are the size of image.
We varied the position of focus to extract all potential parabolas. We varied the focus coordinates by considering the increment step 10.
Each peak in the Radon space reflects a parabola in the initial image. We have extracted these peaks in order to define our descriptor.
The same process is applied on the circular Radon transform and the linear Radon transform. We have extracted the luminous points which correspond to circles and lines.
The Radon based descriptor sets all extracted peaks into one final feature vector. This step aims to extract discriminant information that increases the object classification accuracy. The resulting feature vector is reshaped to form a matrix that can be associated with original image and used for the CNN input.
-
3.2. Image Classification with Convolutional Neural Networks
The Convolutional Neural Networks (CNN) architecture is based on a succession of transformations associating linear and nonlinear operations. These transformations are used to recognize data at different abstraction levels. CNN are simply defined as deep architectures since they connect a hierarchy of layers. The outputs of a layer are the next layers inputs.
The architecture of a typical CNN consists of three main layers, namely: Convolutional Layer, Pooling Layer, and Fully-Connected Layer.
Our intent is to propose a new CNN architecture applied on a Radon descriptor which is derived from (circular, parabolic and linear) Radon space. Our goal is to reach competitive accuracy with previous approaches and reduce the computing time of training phase.
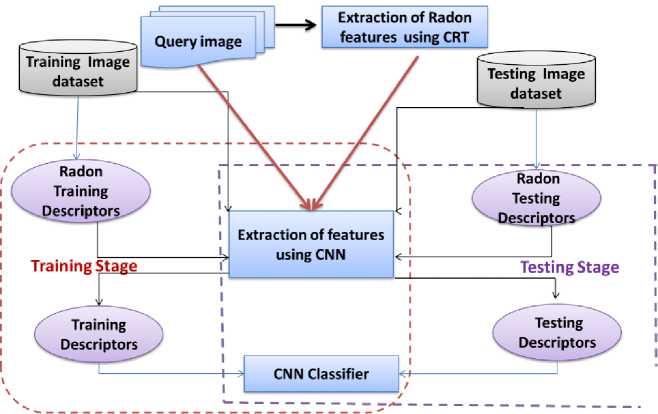
Fig.4. Proposed Approach.
In this work we try training models using small CNN architecture. The input of the network is nxn X k, where n depends on image size for each database and k = 4 is the channel number. Three channels are for image and the last channel is for the extracted Radon features.
Our CNN architecture is characterized by four convolutional layers, three max-pooling layers and fully-connected layer. Finally, the softmax output activation presents object classes. The output is one of the object classes.
The proposed architecture of the convolutional neural network is shown in Figure 5.
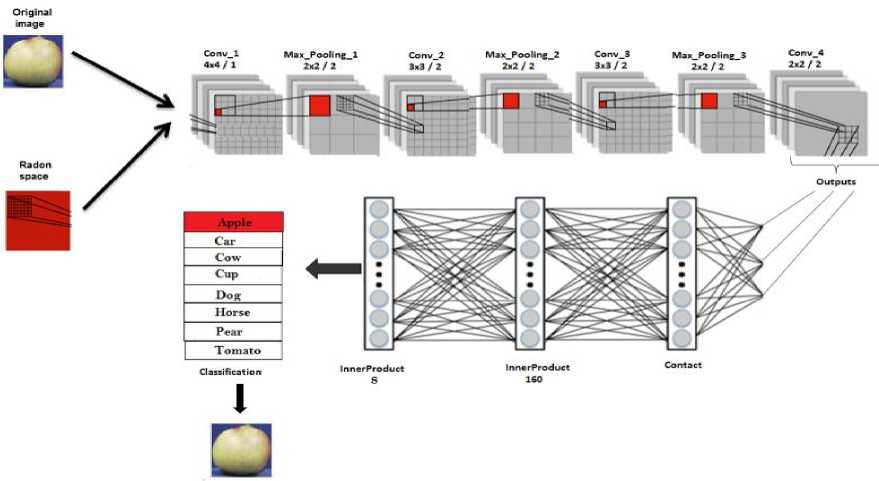
Fig.5. Architecture of the Convolutional Neural Network.
4. Experiments
To validate the performance of our network, we carried out experiments on the most widely used benchmark for image classification.
In this section, we discuss the experimental results on three datasets. First, we describe databases and performance criteria. Then, we provide a comparative evaluation of our object classification approach compared to methods based on Radon transform. In addition, we also present comparative evaluations to methods based on CNN.
In order to make a qualitative analysis, we have opted for an experimental system similar to the previous works. The results of the different previous approaches for these datasets were gathered from their respective articles. Finally, we analyze the time complexity of our approach.
-
4.1. Databases and Evaluation Metrics
In our work, we experiment on ETH80, FLAVIA and GTSRB databases.
-
– ETH80 dataset: It presents a good benchmark to show how the proposed method can handle multi-object categorization tasks. It is represented by eight categories: apples, pears, toy-cows, tomatoes, toy-horses, toy-dogs, toycars and cups. Each category is composed of 10 subcategories objects and 41 views per object are provided with different view angles (Fig.6 -a).
-
– FLAVIA dataset: It is a dataset for grouping plants by categories. It contains 1904 leaf images classified into 32 species as shown in Figure 6-b. This dataset suffers from the large intra-class and the small inter-class variations.
-
– GTSRB dataset: It is a popular dataset, composed of images corresponding to road signs. The image sizes vary from 15×15 to 250×250 pixels. Each image holds a road sign that belongs to one of the 43 classes of traffic sign (Fig .6- c) .
Similar to previous work, the images are cropped and resized to 48×48 pixels.
The 39209 images are selected for training and the rest 12630 images are used as the testing set.

Fig.6. a. ETH-80 Data set, b. FLAVIA Data set, c. GTSRB Data Set.


c
Several evaluation metrics can be used to confirm the following measures:
efficiency of classification methods. We retained the
– Accuracy rate, we have used the following expression:
Accuracy = tp^1°° %
where tp is the number of true classified objects and to is the total number of objects.
– Confusion matrix: it shows how the classification model is confused when it makes predictions.
Table 1. Architecture Configuration.
|
Layer type |
Size/Stride |
Output Dropout Probability |
|
Data |
n X n |
- |
|
Convolution 1 |
4 x 4 /1 |
20 |
|
Max_Pooling 1 |
2 x 2 / 2 |
- |
|
Convolution 2 |
3 x 3 / 2 |
40 |
|
Max_Pooling 2 |
2 x 2 / 2 |
- |
|
Convolution 3 |
3 x 3 / 2 |
60 |
|
Convolution 4 |
2 x 2 / 2 |
80 |
|
Max_Pooling 3 |
2 x 2 / 2 |
- |
|
Fully Connected 1 |
- |
160 Dropout=0.5 |
|
Fully Connected 2 |
- |
8 |
Table 1 shows network configuration, the convolutional layers are applied with different kernel sizes (4x4, 3x3, 2x2) and different strides (1, 2). The Max_Pooling layers reduce the dimensionality of the responses of the convolutional layers with kernel size 2x2 and strice 2.
The parameters used for the training are listed in Table 2. For our model to provide best result, we have chosen the optimal value of these hyper-parameters empirically. We have examined the hyper-parameters in conjunction with the execution time of the training. We have fixed batch size to 20; this value is limited by your hardware’s memory. We have putted the parameters learning rate and Momentum of Stochastic Gradient Descent algorithm respectively to 0.001 and 0.9. These parameters involve in training convergence.
Table 2. Training Parameters.
|
Algorithm |
Parameters |
|
Batch size = 20, |
|
|
SGD |
Epochs = 100, Learning rate = 0.001, Momentum = 0.9 |
-
4.2. Image Classification Results
For the experiments, we have used Pytorch frame work on ubuntu 14.04 LTS and a GeForce GT 525M GPU, which has 2GB of memory.
Figure 7 shows the confusion matrix on ETH80 data set. We reached 96% as recognition rate. It can be shown that our proposed method achieves good performance on the eight categories. But we can observe a confusion between apple and Tomato class (around 5 % of apple objects are misclassified to Tomato objects).
In order to analyze the classification results, CRT-CNN is compared to other Radon transform approaches. These approaches are RT, PDRT, GMDRT and CCSIRT. These different Radon transforms are applied to ETH80 dataset and are used for feature extraction. SVM is used for classification task.
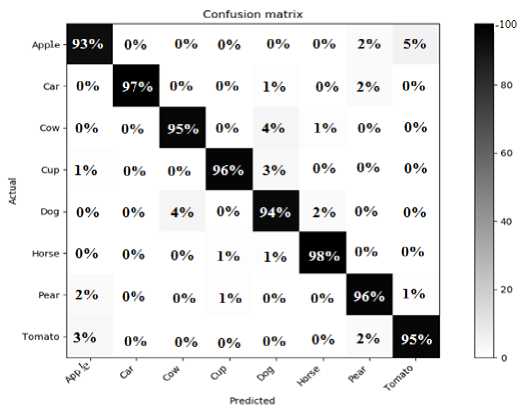
Fig.7. Confusion Matrix of Proposed Method on ETH80 Data Set.
Therefore, several experiments with respect to different sizes of labelled set and test set were performed. From Table 3, we can note that the accuracy of our CRT-CNN method performs the other Radon transform-based approaches for equal division (50% training, 50% test). We denote that the approaches based on the RT, GMDRT and PDRT give lower performances. Besides, CCSIRT provides good results. However, it depends on decomposition approach and the choice of the most pertinent primitives.
Table 3. Comparison Accuracy Scores with other RT Methods on ETH80 Dataset.
|
Approach |
Accuracy |
|
RT |
69 % |
|
GMDRT ([8]) |
75% |
|
PDRT ([11]) |
78% |
|
CCSIRT ([25]) |
94 % |
|
Our proposed method |
96 % |
GMDRT: Multidirectional Generalized Radon Transform, PDRT: Polynomial Discrete Radon Transform, CCSIRT: Compound Complex Shape-Invariant Radon Transform.
Besides, we compared our technique with several image classification methods.
For each class object, five subcategories’ objects are selected for tests and the remaining instances are used for training.
Our work aims to achieve good accuracy and low parameters numbers. We have reached a good accuracy corresponding to small CNN. This small architecture does not require hard complexity for training phase, even in testing phase.
Table 4 presents that the overall classification accuracy of our approach on ETH80 data set outperforms the others previous methods except the TDRM.
This last achieves the best accuracy rate on ETH80 dataset. However, the training step in the TDRM requires a large dataset, it is computationally expensive.
Table 4. Comparison Accuracy Scores with others Deep Learning Methods on ETH80 Dataset.
|
Approach |
Accuracy |
|
CNN(AlexNet+SVM) ([29]) |
79.5 % |
|
CNN(AlexNet) ([29]) |
94.2% |
|
STDP ([29]) |
82.9% |
|
TDRM ([31]) |
98.1% |
|
Our proposed method |
96 % |
SDNN: Spike Deep Neural Network, TDRM: Template Deep Reconstruction Model Our CRT-CNN method shows good scores on FLAVIA dataset. This allows us to prove the effectiveness of our approachfor different datasets.
Table 5 shows the results based on our proposed method and other deep learning methods applied to FLAVIA dataset. The results confirm that our CRT-CNN approach presents a good accuracy rate for leaf classification. We achieved 98.7% of accuracy. However, all other deep leaning methods presented good results; these approaches need a lot of parameter numbers and so much time calculations.
Table 5. Overall Accuracy of Object Classification Methods on FLAVIA Dataset.
|
Approach |
Accuracy |
|
ResNet([32]) |
76% |
|
MobileNet([32]) |
75.8% |
|
DenseNet([32]) |
100% |
|
Leaf net ([33]) |
97.9 % |
|
Dual-path CNN([34]) |
99.7 % |
|
VGG16+SVM([35]) |
97% |
|
VGG16+LDA([35]) |
99% |
|
Our proposed method |
98.7% |
Besides, we have got good results on traffic signs classification. Table 6 reveals that our CRT- CNN approach has performance of 99.1% on traffic signs dataset. This result is competitive to other deep learning methods. Radon transform plays a complementary role to the CNN. The association of CRT and CNN involve discriminative features for classification. The advantage of our approach is shown in terms of parameters numbers. Our model exceeds the whole previous works in terms of parameter requirement as shown in Table 6. Our proposed approach intents to get good accuracy and to reduce the number of required parameters, which makes traffic signs classification adopted for real-time applications.
Table 6. Comparison Accuracy Scores with others deep Learning Methods on GTSRB Dataset.
|
Approach |
Accuracy |
parameters number (M) |
|
MicronNet ([36]) |
98.9% |
0.51 |
|
Hough transform with CNN ([37]) |
98.2% |
- |
|
CNN (capsule networks) ([38]) |
97.6% |
- |
|
Multi-column CNN ([39]) |
99.4% |
90 |
|
Hing Loss Trained CNN ([40]) |
99.6% |
1.16 |
|
Our proposed method |
99.1% |
0.47 |
5. Conclusion
This article proposed a new approach for image classification that applies the conic Radon transform as a preprocessing for the Convolutional neural networks. Our model achieved a performance which is close to the previous works. Considerable refinement in terms of accuracy, and parameters requirement compared to related work are reflected in the proposed network. For object recognition, our model achieved an average accuracy equal to 96%. On the other hand, our model performed well in leaf images. It reached accuracy 98 % for FLAVIA dataset. In traffic signs classification, our proposed CRT-CNN method achieved an accuracy of 99%, with 0.47M parameters. As a perspective, our proposed method could be extended to other more complex and specific datasets.
References A Conic Radon-based Convolutional Neural Network for Image Recognition
- J. Radon. Über die Bestimmung von Funktionen durch ihre Integralwerte längs gewisser Mannigfaltigkeiten. kad. Wiss., 69:262–277, 1917.
- Qiaoping Zhang and Isabelle Couloigner. Accurate Centerline Detection and Line Width Estimation of Thick Lines Using the Radon Transform. IEEE Trans- actions on Image Processing, 16(2):310–316, February 2007.
- B. V. Bharath, A. S. Vilas, K. Manikantan, and S. Ramachandran. Iris recognition using radon transform thresholding based feature extraction with Gradient- based Isolation as a pre-processing technique. In 2014 9th International Conference on Industrial and Infor- mation Systems (ICIIS), pages 1–8, December 2014.
- Thanh Phuong Nguyen and Thai V. Hoang. Projection- Based Polygonality Measurement. Image Processing, IEEE Transactions on, 24(1):305–315, 2015.
- A. M. Cormack. The Radon transform on a family of curves in the plane. Proceedings of the American Mathematical Society, 83(2):325–330, 1981.
- Koen Denecker, Jeroen Van Overloop, and Frank Sommen. The general quadratic radon transforms. Inverse Problems, 14(3):615, 1998.
- Gaël Rigaud, Maï K. Nguyen, and Alfred K. Louis. Circular harmonic decomposition approach for numerical inversion of circular radon transforms. In 5th International ICST Conference on Performance Evaluation Methodologies and Tools Communications, VAL- UETOOLS ’11, Paris, France, May 16-20, 2011, pages 582–591, 2011.
- Ines Elouedi, R. Fournier, A. Nait-Ali, and A. Hamouda. Generalized multi-directional discrete Radon transform. Signal Processing, 93(1):345–355, January 2013.
- Richard O. Duda and Peter E. Hart. Use of the hough transformation to detect lines and curves in pictures. Commun. ACM, 15(1):11–15, January 1972.
- Ines Elouedi, Régis Fournier, Amine Nait-Ali, and Atef Hamouda. The polynomial discrete Radon transform. Signal, Image and Video Processing, 9(Supplement- 1):145–154, 2015.
- Ines Elouedi, Atef Hamouda, Hmida Rojbani, Régis Fournier, and Amine Naït-Ali. Extracting buildings by using the generalized multi directional discrete radon transform. In Image and Signal Processing - 5th International Conference, ICISP 2012, Agadir, Morocco, June 28-30, 2012. Proceedings, pages 531–538, 2012.
- Ian J. Goodfellow, Yoshua Bengio, and Aaron C. Courville. Deep Learning. Adaptive computation and machine learning. MIT Press, 2016.
- Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hin- ton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012. Proceedings of a meeting held December 3-6, 2012, Lake Tahoe, Nevada, United States., pages 1106–1114, 2012.
- Holger Schwenk, Loïc Barrault, Alexis Conneau, and Yann LeCun. Very deep convolutional networks for text classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2017, Valencia, Spain, April 3-7, 2017, Volume 1: Long Papers, pages 1107–1116, 2017.
- Weihong Wang, Jie Yang, Jianwei Xiao, Sheng Li, and Dixin Zhou. Face recognition based on deep learning. In Human Centered Computing - First International Conference, HCC 2014, Phnom Penh, Cambodia, November 27-29, 2014, Revised Selected Papers, pages 812–820, 2014.
- Navneet Dalal and Bill Triggs. Histograms of oriented gradients for human detection. In 2005 IEEE Computer Society Conference on Computer Vision and Pat- tern Recognition (CVPR 2005), 20-26 June 2005, SanDiego, CA, USA, pages 886–893, 2005.
- David G. Lowe. Object recognition from local scale invariant features. In ICCV, pages 1150–1157, 1999.
- Insaf Setitra and Slimane Larabi. SIFT descriptor for binary shape discrimination, classification and matching. In Computer Analysis of Images and Patterns - 16th International Conference, CAIP 2015, Valletta, Malta, September 2-4, 2015 Proceedings, Part I, pages 489–500, 2015.
- Ahana Gangopadhyay, Oindrila Chatterjee, and Amitava Chatterjee. Hand shape based biometric authentication system using radon transform and collaborative representation based classification. In 2013 IEEE Second International Conference on Image Information Processing (ICIIP-2013), pages 635–639, 2013.
- Makoto Hasegawa and Salvatore Tabbone. Histogram of Radon transform with angle correlation matrix for distortion invariant shape descriptor. Neurocomputing, 173:24–35, 2016.
- Jihen Hentati, Mohamed Naouai, Atef Hamouda, and Christiane Weber. Measuring rectangularity using GR- signature. Advances in pattern recognition. Lecture notes in computer science, 6718:136–145, 2011.
- Thanh Phuong Nguyen and Thai V. Hoang. Projection- Based Polygonality Measurement. Image Processing, IEEE Transactions on, 24(1):305–315, 2015.
- G. Beylkin. Discrete radon transforms. IEEE Transactions on Acoustics, Speech, and Signal Processing, 35(2):162–172, 1987.
- Elouedi Ines, Hamdi Dhikra, Fournier Régis, Nait-Ali Amine, and Hamouda Atef. Fingerprint recognition using polynomial discrete radon transform. In 2014 4th International Conference on Image Processing Theory, Tools and Applications (IPTA), pages 1–6, 2014.
- Ghassen Hammouda, Sellami Dorra, and Hammouda Atef. Pattern recognition based on compound complex shape-invariant radon transform. The Visual Computer, pages 1432–2315, 2020.
- Dhekra El Hamdi, Mai K. Nguyen, Hedi Tabia, and Atef Hamouda. Image analysis based on radon-type integral transforms over conic sections. In Proceedings of the 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications - Volume 4: VISAPP, pages 356–362. IN- STICC, SciTePress, 2018.
- Neha Sharma, Vibhor Jain, and Anju Mishra. An analysis of convolutional neural networks for image classification. Procedia Computer Science, 132:377–384, 2018. International Conference on Computational Intelligence and Data Science.
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, and Mu Li. Bag of tricks for image classification with convolutional neural networks. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 558–567, 2019.
- Saeed Reza Kheradpisheh, Mohammad Ganjtabesh, Si- mon J. Thorpe, and Timothée Masquelier. Stdp-based spiking deep neural networks for object recognition. CoRR, abs/1611.01421, 2016.
- Tong Zhang, Wenming Zheng, Zhen Cui, Yuan Zong, Jingwei Yan, and Keyu Yan. A deep neural network- driven feature learning method for multi-view facial expression recognition. IEEE Transactions on Multime- dia, 18(12):2528–2536, 2016.
- Munawar Hayat, Mohammed Bennamoun, and Senjian An. Deep reconstruction models for image set classification. IEEE Trans. Pattern Anal. Mach. Intell., 37(4):713–727, 2015.
- Cheng-Li Zhou, Lin-Mei Ge, Yan-Bu Guo, Dong-Ming Zhou and Yu-Peng Cun. A comprehensive comparison on current deep learning approaches for plant image classification, Journal of Physics: Conference Series, Volume 1873, 2021 2nd International Workshop on Electronic communication and Artificial Intelligence (IWECAI 2021), Nanjing, China.
- Pierre Barre, Ben C. Stöver, Kai F. Müller, and Volker Steinhage. Leafnet: A computer vision system for automatic plant species identification. Ecological Informatics, 40:50–56, 2017.
- Meet P. Shah, Sougata Singha, and Suyash P. Awate. Leaf classification using marginalized shape context and shape texture dual-path deep convolutional neural network. In 2017 IEEE International Conference on Image Processing (ICIP), pages 860–864, 2017.
- Aydin Kaya, Ali Seydi Keceli, Cagatay Catal, Hamdi Yalin Yalic, Huseyin Temucin, Bedir Tekinerdogan, Analysis of transfer learning for deep neural network based plant classification models, Computers and Electronics in Agriculture,Volume 158, 2019, pages 20-29.
- Alexander Wong, Mohammad Javad Shafiee, and Michael St. Jules. munet: A highly compact deep convolutional neural network architecture for real- time embedded traffic sign classification. CoRR, abs/1804.00497, 2018.
- Ying Sun, Pingshu Ge, and Dequan Liu. Traffic sign detection and recognition based on convolutional neural network. In 2019 Chinese Automation Congress (CAC), pages 2851–2854, 2019.
- Amara Dinesh Kumar. Novel deep learning model for traffic sign detection using capsule networks, 2018.
- Dan C. Ciresan, Ueli Meier, and Jürgen Schmidhuber. Multi-column deep neural networks for image classification. CoRR, abs/1202.2745, 2012.
- Junqi Jin, Kun Fu, and Changshui Zhang. Traffic sign recognition with hinge loss trained convolutional neural networks. IEEE Transactions on Intelligent Trans- portation Systems, 15(5):1991–2000, 2014.
