A Multidimensional Cascade Neuro-Fuzzy System with Neuron Pool Optimization in Each Cascade

Author: Yevgeniy V. Bodyanskiy, Oleksii K. Tyshchenko, Daria S. Kopaliani
Journal: International Journal of Information Technology and Computer Science(IJITCS) @ijitcs
Article in issue: 8 Vol. 6, 2014.
Free access
A new architecture and learning algorithms for the multidimensional hybrid cascade neural network with neuron pool optimization in each cascade are proposed in this paper. The proposed system differs from the well-known cascade systems in its capability to process multidimensional time series in an online mode, which makes it possible to process non-stationary stochastic and chaotic signals with the required accuracy. Compared to conventional analogs, the proposed system provides computational simplicity and possesses both tracking and filtering capabilities.
Learning Method, Cascade System, Neo-Fuzzy Neuron, Computational Intelligence
Short address: https://sciup.org/15012127
IDR: 15012127
Text of the scientific article A Multidimensional Cascade Neuro-Fuzzy System with Neuron Pool Optimization in Each Cascade
Published Online July 2014 in MECS
Today artificial neural networks (ANNs) and neuro-fuzzy systems (NFSs) are successfully used in a wide range of data processing problems (when data can be presented either in the form of “object-property” tables or in the form of time series, often produced by non-stationary nonlinear stochastic or chaotic systems). The advantages ANNs and NFSs have over other existing approaches derive from their universal approximating capabilities and learning capacities.
Conventionally “learning” is defined as a process of adjusting synaptic weights using an optimization procedure that involves searching for the extremum of a given learning criterion. The learning process quality can be improved by adjusting a network topology along with its synaptic weights [1, 2]. This idea is the foundation of evolving computational intelligence systems [3, 4]. One of the most successful implementations of this approach is cascade-correlation neural networks [5–8] due to their high degree of efficiency and learning simplicity of both synaptic weights and a network topology). Such a network starts off with a simple architecture consisting of a pool (ensemble) of neurons which are trained independently (the first cascade). Each neuron in the pool can have a different activation function and a different learning algorithm. The neurons in the pool do not interact with each other while they are trained. After all the neurons in the pool of the first cascade have had their weights adjusted, the best neuron with respect to a learning criterion forms the first cascade and its synaptic weights can no longer be adjusted. Then the second cascade is formed usually out of similar neurons in the training pool. The only difference is that neurons which are trained in the pool of the second cascade have an additional input (and therefore an additional synaptic weight) which is an output of the first cascade. Similar to the first cascade, the second cascade will eliminate all but one neuron showing the best performance whose synaptic weights will thereafter be fixed.
Neurons of the third cascade have two additional inputs, namely the outputs of the first and second cascades. The evolving network continues to add new cascades to its architecture until it reaches the desired quality of problem solving over the given training set.
Authors of the most popular cascade neural network, CasCorLA, S. E. Fahlman and C. Lebiere, used elementary Rosenblatt perceptrons with traditional sigmoidal activation functions and adjusted synaptic weights using the Quickprop-algorithm (a modification of the δ -learning rule). Since the outgoing signal of such neurons is non-linearly dependent on its synaptic weights, the learning rate cannot be increased for such neurons. In order to avoid multi-epoch learning [9–16], different types of neurons (with outputs that depend linearly on synaptic weights) should be used as network nodes. This would allow the use of optimal learning algorithms in terms of speed and process data as it is an input to the network. However, if the network is learning in an online mode, it is impossible to determine the best neuron in the pool. While working with non-stationary objects, one neuron of the training pool can be identified as the best for one part of the training set, but not for the others. Thus we suggest that all neurons retain in the training pool and a certain optimization procedure (generated according to a general network quality criterion) is used to determine an output of the cascade.
It should be noticed that the well-known cascade neural networks implement non-linear mapping Rn → R1 , i.e. they are a systems with a single output. At the same time, many problems (which are solved with the help of ANNs and NFSs) require the multidimensional mapping Rn ^ Rg implementation, which leads to the fact that g times more neurons should be trained in each cascade comparing to a conventional neural network, which makes such a system too cumbersome. Therefore, it seems appropriate to use as the cascade network nodes specialized multidimensional neuron structures with multiple outputs instead of traditional neurons like elementary Rosenblatt perceptrons.
The remainder of this paper is organized as follows: Section 2 gives an optimized multidimensional cascade neural network architecture. Section 3 describes training neo-fuzzy neurons in the network. Section 4 describes output signals’ optimization of the multidimensional neo-fuzzy neuron pool. Section 5 presents experiments and evaluation. Conclusions and future work are given in the final section.
-
II. An Optimized Multidimensional Cascade Neural Network Architecture
An input of the network (the so-called “receptive layer”) is a vector signal
x(k) —(x1 (k),x2 (k),...,xn (k)T , where k — 1,2,... is either the quantity of samples in the “object-property” table or the current discrete time. These signals are sent to the inputs of each neuron MN[m] in the network (j — 1,2,..., q is the quantity of neurons in a training pool, m — 1,2,... is a cascade number), that produces vector [m]j [m]j [m]j [m]j T outputs yd (k)-(y1 (k),y2 (k),•••,yg (k)) , d —1,2,...,g. These outputs are later combined with a generalizing neuron GMN[m] which generates an optimal vector output y [m] (k) of the m—th cascade. While the input of the neurons in the first cascade is x (k), neurons in the second cascade have g additional inputs for the generated signal y*[1] (k), neurons in the third cascade have 2g additional inputs y*[1] (k), y*[2] (k), neurons in the m — th cascade have (m — 1) g additional inputs y*[1] (k), y*[2] (k),..., y*[m—1] (k). New cascades become a part of the network during a training process when it becomes clear that the current cascades do not provide the desired quality of information processing.
-
III. Training Neo-Fuzzy Neurons In The Multidimensional Cascade Neuro-Fuzzy Networks
The low learning rate of the Rosenblatt perceptrons (which are widely used in traditional cascade ANNs) along with the difficulty in interpreting results (inherent to all ANN in general) encourages us to search for alternative approaches to the synthesis of evolving systems in general and cascade neural networks in particular. High interpretability and transparency along with good approximation capabilities and ability to learn are the main features of neuro-fuzzy systems [17, 18], which are the foundation of hybrid computational intelligence systems. In [10,11,13] hybrid cascade systems were introduced which used neo-fuzzy neurons [19-21] as network nodes, allowing one to significantly increase the speed of synaptic weight adjustment. A neo-fuzzy neuron (NFN) is a nonlinear system having the following mapping
n y — 2 fi ( xi) (1)
i — 1
where X i is the i — th input ( i — 1,2,..., n ) , y is the neo-fuzzy neuron’s output. Structural units of the neo-fuzzy neuron are nonlinear synapses NSi which transform the i — th input signal in the following way
h fi (xi) —2 wli^H (xi) (2)
l — 1
where w^ is the l — th synaptic weight of the i — th nonlinear synapse, l — 1,2,... h is the total quantity of synaptic weights and therefore membership functions P li ( x i ) in this nonlinear synapse. In this way NS i implements the fuzzy inference [18]
IF x IS X i li (3)
THEN THE OUTPUT IS wli where Xli is a fuzzy set with a membership function ^li , Wli is a singleton (a synaptic weight in a consequent). It can be seen that, in fact, a nonlinear synapse implements Takagi-Sugeno zero-order fuzzy inference.
The j — th neo-fuzzy neuron ( j — 1,2,..., q ) of the d — th output ( d — 1,2,..., g ) of the first cascade
(according to the network topology) can be written n_ yd1]j (k) — 2 f^j (x(k)) i—1 h
J — 22 < kdH ( x i ( k ) ) , (4)
i — 1 1 —
IFx i ( k ) ISX j
THEN THE OUTPUT IS w [^] j .
Authors of the neo-fuzzy neuron [19–21] used traditional triangular constructions meeting the conditions of Ruspini partitioning (unity partitioning) as membership functions [22]:
[1]j xi cd,l-1,i if Лc[1]j cl „[1] j_ диj , if xi eL cd,l-1,i, c cdli cd, l-1, i
gh n +
m - 1
z p p=1
parameters.
Introducing the vector of
® ( X i M
[1]j cd, l+1, i xi
[1] j [1] j , c d , l + 1, i c dli
if Xi ^[ c dm , cdd + 1, i ] , (5)
0, otherwise where c[1] j are relatively arbitrarily chosen (usually evenly distributed) center parameters of membership functions over the interval [ 0,1] where, naturally, 0 < xi < 1. This choice of membership functions ensures that the input signal xi only activates two neighboring membership functions, and their sum is always equal to 1 which means that
A di ( xi ) + A d'i ( x i ) = 1 (6)
and fdi]' (xi) = WdU Add (xi)
+ w ' i A d %, i ( x i) .
It is clear that other constructions such as polynomial and harmonic functions, wavelets, orthogonal functions, etc. can be used as membership functions in nonlinear synapses. It is still unclear which of the functions provide the best results, which is why the idea of using not one neuron, but a pool of neurons with different membership and activation functions seems promising.
Similar to (4) we can determine outputs for the remaining cascades: outputs of the neurons in the second cascade:
nh
.y?v=2£ w ASA Xi^+ i=11=1
gh
+ ZZ W d 2] n + 1 A d 2 j ( y d [1] ) V d = 1, 2,.., g ; (8)
d = 1 1 = 1
outputs of the neurons in the m - th cascade:
nh
-dim ^^zz w? (x.)+ i=11=1
g n + m - 1 h
+ z z z w^j A dmj y d p - n ] ) (9)
d = 1 p = n + 1 1 = 1
V d = 1,2,..., g .
Thus, the cascade network formed with neo-fuzzy neurons consisting of m cascades contains membership functions for the j - th NFN of the d - th output in the m - th cascade
A [ m ] ' (y *[ m - 1] ( k \T
, ^dh,g(n+m-1) (^gV and a corresponding synaptic weights’ vector
[m]j [m]j [m]j [m]j [m]j[ wd -(wd 11 ,-,Wdh1 ,wd 12 ,-,wdh2 ,•••,wdli ,••;
[m]j [m]j [m]j [m]j wdhn , wd 1, n+1, • • •, wdh, n+h, • • •, wdh, g (n+m-1) )
the output signal can be finally written down in a compact form ydm ]j( k ) = ( wd”1' )T Ai" ]j( k).(10)
Since this signal is linearly dependent on the synaptic weights, any adaptive identification algorithm [23-25] can be used for training the network neo-fuzzy-neurons, for example, the exponentially-weighted least-squares method in a recurrent form wd- ]'(k+1)=wm I' (k )+[„+(Am1' (k+1))T x X Pdm ]'( k ) a,”]'( k + 1))-1 (P” ]'(1)( yd ( k + 1)-_-(wd”]'(k))TAdm]'(k + ) Amk(k +1), Pi,”]'(k +1) = 1 (Pd”1' (k)-(= + (Ai”L'(k + 1))T x xPd ”]'(k) Ai”]'(k +1))-1 (P” ]'(k) Ad”1' (k + 1)x .(Ad”]'(k + 1))''PJ” ]'(k ))
(here y d ( k + 1 ) , d = 1,2,..., g - an external learning signal, 0 < a < 1 - a forgetting factor) or the gradient learning algorithm with both tracking and filtering properties [26]
W d” ] j ( k + 1 ) = W d” ] j ( k ) + ( r d m ] j ( k + 1 ) )- 1 ( yd ( k + 1 ) -
- ( W ” ] j ( k ) ) T a , ] ' ( k + 1 ) ) A d” ] j ( k + 1 ) , (12)
r d” ] j ( k + 1 ) = a r d” ] j ( k ) +1 A d” ] j ( k + 1)|2,0 < a < 1.
An architecture of a typical neo-fuzzy neuron which was discussed earlier as a part of the multidimensional neuron MN[g1] of the cascade system is redundant, since a vector of input signals x (k) (the first cascade) is fed to one-type nonlinear synapses NS[1] j of the neo-fuzzy neurons, each neuron of which generates at its output a signal y[^j (k), d = 1,2,...,g . As a result, the output vector components
y[1]j (k) = (yj1]j (k), rl'1j (k),..., yg1]j (k)) are calculated independently. This can be avoided by considering a multidimensional neo-fuzzy neuron [27], which is a modification of the system proposed in [28]. Structure nodes are composite nonlinear synapses MNSi[1] j , each synapse contains h membership functions Ц1j and gh adjustable synaptic weights
w [1] j . Thus, a multidimensional neo-fuzzy neuron of the first cascade contains ghn synaptic weights, but only hn membership functions that makes it g times less than if the cascade would have been formed of conventional neo-fuzzy neurons.
Taking into consideration a ( hn x 1 ) - membership functions’ vector
ц [1] j ( k ) = ( Ц м j ( x 1 ( k ) ) ,
Ц2 1 j ( x 1 ( k ) ) .-, Цу j ( x 1 ( k ) ) ,
, цн j(x(k)),-.дВj(xn(k)))
and a ( g x hn ) - synaptic weights’ matrix
y [1] j ( k ) = W [1] j Ц 1 j ( k ) . (13)
Multidimensional neo-fuzzy-neuron learning can be implemented with the help of a matrix modification of the exponentially-weighted recurrent least squares method (11) in the form of
W [1] j ( k + 1 ) = W [1] j ( k ) + ^ a + ( ц [1] j ( k + 1 ) ) T P [1] j ( k ) x х ц [1] j ( k + 1 ) ) ( y ( k + 1 ) - W [1] j ( k ) ц [1] j ( k + 1 ) ) x
x ( ц [1У ( k + 1 ) ) r P [1 ] j ( к ) , (14)
P [1] j ( k + 1 ) = — ( P [1] j ( k ) -Г a + ( ц [1] j ( k + 1 ) ) x x P [1] j ( k ) ц" j ( k + 1 ) ) 1 ( P [1] j ( k ) ц [1] j ( k + 1 ) x x ( ц [1] j ( k + 1 ) ) T P [1 ] j ( k ) ) ) ,0 < a < 1
or in the form of a multidimensional version of the algorithm (12) [29]:
W [1] j ( k + 1 ) = W [1 ] j ( k ) + ( r [1] j ( k + 1 ) ) 1 ( y ( k + 1 ) -
. - W [1] j ( k ) ц [1] j ( k + 1 ) )( Ц [1] j ( k + 1 ) ) Г , (15)
r [1 ] j ( k + 1 ) = a r [1 ] j ( k ) +1| ц [1] j ( k + 1 )|| , 0 < a < 1
T here y ( k + 1 ) = ( y1 ( k + 1 ) , y 2 ( k + 1 ),..., y g ( k + 1 ) ) .
The remaining cascades are trained in a similar manner, while the m - th cascade membership functions’ vector Ц m ] j ( k + 1 ) increases its dimensionality by ( m - 1 ) g components which are formed by the previous cascades’ outputs.
-
IV. Output Signals’ Optimization Of The Multidimensional Neo-Fuzzy Neuron Pool
The output signals of all the neurons MN[m] of the pool in each cascade are joined by a neuron generalizer GMN[m] , the output signals yVm] (k) = (y*[m](k),y2m] (k),..,y*[m](k))T of which should surpass the accuracy of any signal y[m] (k). This problem can be solved by using undetermined Lagrange multipliers and adaptive multidimensional generalized prediction [30, 31].
Let’s introduce a neuron output signal GMN[m] in the form of y *[ m ] (k) = ]Tc[,m ] y[m] (k) = y[ m ] (k) c[ m ] (16)
j = 1
where y [ m ] ( k ) = ( y )[ m ] ( k ) , y^m ] ( k ),..., y Vm ] ( k ) ) -
( g x q ) - a matrix, c [ m ] ( k ) - ( q x 1 ) - a generalization coefficients’ vector meeting the unbiasedness conditions
-
^^ c [m ] = E T c [ m ] = 1, (17)
-
J = 1
E = ( 1,1,...,1 ) T - ( q x 1 ) - a vector that consists of ones. Entering a training criterion
E [ m ] ( k ) = ]T|| y ( t ) - y [ m ] ( t ) c [ m ]|2 =
-
T = 1
= Tr ^ ( Y ( k ) - Y [ m ] ( k ) I 0 c [ m ] ) T x (18)
x ( Y ( k ) - Y [ m ] ( k ) I 0 c [ m ] ) )
|
(here Y ( k ) = ( y T ( 1 |
) , y T ( 2 ),... |
, y T ( k ) ) - ( k x s ) - an |
|
observations’ matrix, ^ y [[ m ] T ( 1 ) |
y 2m ] T ( 1 ) |
... yqm ] t ( 1 )^ |
|
Y [ m ] ( k ) = y m ] T ( 2 ) . y m ]T ( k ) |
y 2 m ] T ( 2 ) y 2 m ] T ( k ) |
... ym]T ( 2 ) - a ... yqm ] T ( k )v |
( k x gq ) - matrix, I - an identity ( g x g ) - matrix, 0- a tensor product symbol).
Let’s write down the Lagrange function taking into consideration the constraint (6)
L [ m ] ( k ) = E [ m ] ( k ) + A ( E T c [ m ] - 1 ) =
k
= E y ( T ) - y [ " ] ( t ) c " ]|| + я ( E T c " ] - 1 ) =
T = 1
= Tr ( ( Y ( k ) - Y [ m ] ( k ) 1 0 c [ m ] ) T x (19)
x ( Y ( k ) - Y [ m ] ( k ) 1 0 c [ m ] ) ) + a ( E T c [ m ] - 1 ) =
= Tr ( V [ m ] T ( k ) V [ m ] ( k ) ) + A ( E T c [ m ] - 1 )
where V[m] (k) = Y (k)- Y[m] (k) 10 c[m] -(k x g)- an innovations’ matrix.
The Karush-Kuhn-Tucker equations’ system solution
-
V c L m ] ( k ) = 0 ,
' d Lm ] ( k ) _0 (20)
. dA leads to an obvious result
c [ m ]
= ( R [ m ] ( k ) ) 1 E | E T ( R [ m ] ( k ) ) 1 E
A = - 2 ET ( ^ [ m ] ( k ) ) 1 E
Thus, an optimal union of all neurons’ pool outputs of each cascade can be organized. It is clear that not only the multidimensional neo-fuzzy neurons can be used as such neurons, but also any other structures that implement the nonlinear mapping R n +( m - 1 ) g ^ R g .
-
V. Experiment And Analysis
To demonstrate the efficiency of the proposed adaptive neuro-fuzzy system and its learning procedures (19) and (21), we have implemented a simulation test based on solving the chaotic Lorenz attractor identification. The Lorenz attractor is a fractal structure corresponding to the long-term behavior of Lorenz oscillator. The Lorenz oscillator is a 3-dimensional dynamical system that exhibits chaotic flow, well-known for its lemniscate shape. The map shows how a dynamical system state (three variables of a three-dimensional system) evolves over time in a complex non-repeating pattern.
The Lorenz attractor is described by the differential equation in the form
' X = CT ( y - x ) ,
-
< y = x ( r - z ) - y , (22)
z = xy - bz .
We can rewrite (22) in the recurrent form:
x ( i + 1 ) = x ( i ) + ct ( y ( i ) - x ( i ) ) dt ,
-
< y ( i + 1 ) = y ( i ) + ( rx ( i ) - x ( i ) z ( i ) - y ( i ) ) dt , (23)
z (i +1) = z (i) + (x (i) y (i)- bz (i)) dt where parameter values are:
CT = 10, r = 28, b = 8/, dt = 0.001.
The data sample was obtained using (23) which consists of 10000 samples, where 7000 samples form a training set, 3000 samples form a checking set.
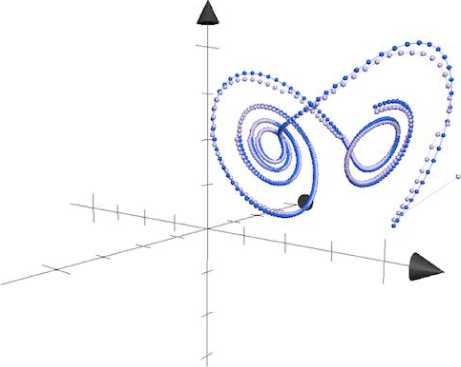
Fig. 1. A visual representation of the predicted values (500 iterations)
where R [ m ] ( k ) = V [ m ] T ( k ) V [ m ] ( k ) .
Fig.1 and Fig.2 present a time series output and a prediction value for 500 and 10000 iterations respectively (a dark color stays for a time series value, a light color stays for a prediction value).
Symmetric mean absolute percentage error (SMAPE) and mean square error (MSE), used for results evaluation, are shown in Fig.3 and Fig.4.
Fig.1 presents a time series output and a prediction value (a dark color stays for a time series value, a light color stays for a prediction value).
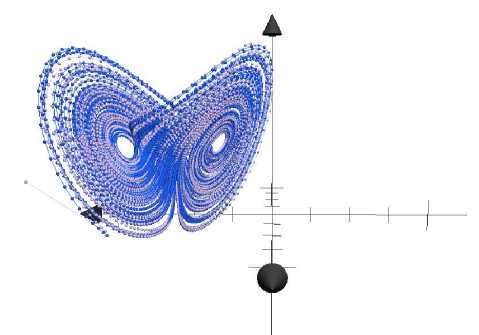
Fig. 2. A visual representation of the predicted values (10000 iterations)
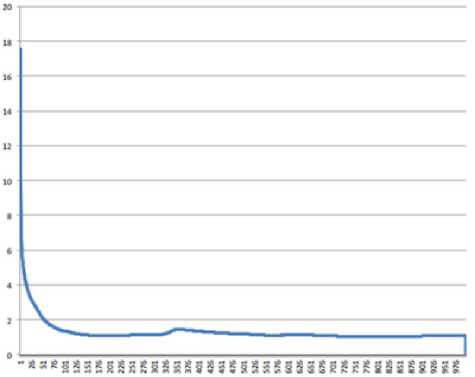
Fig. 3. Symmetric mean absolute percentage error (SMAPE)
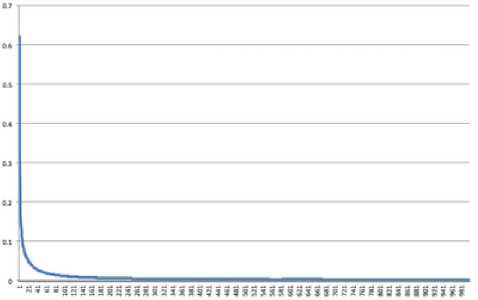
Fig. 4. Mean squared error (SME)
By the 10000th iteration the evolving system consists of 8-9 cascades and, as one can see in Fig.3 and Fig.4, the error curve is almost parallel to the Y-axis, which means the highest possible prediction accuracy, conditioned by the form of membership functions, is reached.
-
VI. Conclusion
The new cascade system type of computational intelligence is proposed in the paper, in which nodes are multi-dimensional neo-fuzzy neurons that implement the multidimensional Takagi-Sugeno-Kang fuzzy reasoning. The adaptive learning algorithm for a multidimensional neo-fuzzy neuron is proposed that has both tracking and filtering properties. The distinguishing feature of the proposed system is that each cascade is formed by a set of neurons, and their outputs are combined with an optimization procedure of a special type. Thus, each cascade generates an optimal accuracy output signal. The proposed system which is essentially an evolving system of computational intelligence, makes it possible to process incoming data in an online mode unlike other traditional systems. This feature allows to process multidimensional non-stationary stochastic and chaotic signals under a priori and current uncertainty conditions as well as to provide the optimal forecast accuracy.
Acknowledgment
The authors would like to thank anonymous reviewers for their careful reading of this paper and for their helpful comments.
References A Multidimensional Cascade Neuro-Fuzzy System with Neuron Pool Optimization in Each Cascade
- A. Cichocki, R. Unbehauen, Neural Networks for Optimization and Signal Processing. Stuttgart: Teubner, 1993.
- S. Haykin, Neural Networks: A Comprehensive Foundation. Upper Saddle River, New Jersey: Prentice Hall, 1999.
- N. Kasabov, Evolving Connectionist Systems. London: Springer-Verlag, 2003.
- E. Lughofer, Evolving Fuzzy Systems – Methodologies, Advanced Concepts and Applications. Berlin-Heidelberg: Springer-Verlag, 2011.
- S.E. Fahlman and C. Lebiere, “The cascade-correlation learning architecture,” in Advances Neural Information Processing Systems, San Mateo, CA: Morgan Kaufman, 1990, pp. 524-532.
- L. Prechelt, “Investigation of the CasCor family of learning algorithms,” in Neural Networks, vol. 10, 1997, pp. 885-896.
- R.J. Schalkoff, Artificial Neural Networks, New York: The McGraw-Hill Comp., 1997.
- E.D. Avedjan, G.V. Bаrkаn and I.K. Lеvin, “Cascade neural networks,” in J. Avtomatika i Telemekhanika, vol. 3, 1999, pp. 38-55.
- Ye. Bodyanskiy, A. Dolotov, I. Pliss and Ye. Viktorov, “The cascaded orthogonal neural network,” in Int. J. Information Science and Computing, vol. 2, Sofia: FOI ITHEA, 2008, pp. 13-20.
- Ye. Bodyanskiy and Ye. Viktorov, “The cascaded neo-fuzzy architecture and its on-line learning algorithm,” in Int. J. Intelligent Processing, vol. 9, Sofia: FOI ITHEA, 2009, pp. 110-116.
- Ye. Bodyanskiy and Ye. Viktorov, “The cascaded neo-fuzzy architecture using cubic-spline activation functions,” in Int. J. Information Theories and Applications, vol. 16, no. 3, 2009, pp. 245-259.
- Ye. Bodyanskiy, Ye. Viktorov and I. Pliss, “The cascade growing neural network using quadratic neurons and its learning algorithms for on-line information processing,” in Int. J. Intelligent Information and Engineering Systems, vol. 13, Rzeszov-Sofia: FOI ITHEA, 2009, pp. 27-34.
- V. Kolodyazhniy and Ye. Bodyanskiy, “Cascaded multi-resolution spline-based fuzzy neural network,” Proc. Int. Symp. on Evolving Intelligent Systems, pp. 26-29, 2010.
- Ye. Bodyanskiy, O. Vynokurova and N. Teslenko, “Cascaded GMDH-wavelet-neuro-fuzzy network,” Proc 4th Int. Workshop on Inductive Modelling, pp. 22-30, 2011.
- Ye. Bodyanskiy, O. Kharchenko and O. Vynokurova, “Hybrid cascaded neural network based on wavelet-neuron,” in Int. J. Information Theories and Applications, vol. 18, no. 4, 2011, pp. 35-343.
- Ye. Bodyanskiy, P. Grimm and N. Teslenko, “Evolving cascaded neural network based on multidimensional Epanechnikov’s kernels and its learning algorithm,” in Int. J. Information Technologies and Knowledge, vol. 5, no. 1, 2011, pp. 25-30.
- J-S.R. Jang, C.T. Sun and E. Mizutani, Neuro-Fuzzy and Soft Computing: A Computational Approach to Learning and Machine Intelligence, New Jersey: Prentice Hall, 1997.
- S. Wadhawan, G. Goel and S. Kaushik, “Data Driven Fuzzy Modelling for Sugeno and Mamdani Type Fuzzy Model using Memetic Algorithm,” in Int. J. Information Technology and Computer Science, vol. 5, no. 8, 2013, pp. 24-37, doi: 10.5815/ijitcs.2013.08.03.
- T. Yamakawa, E. Uchino, T. Miki and H. Kusanagi, “A neo fuzzy neuron and its applications to system identification and prediction of the system behavior,” Proc. 2nd Int. Conf. on Fuzzy Logic and Neural Networks, pp. 477-483, 1992.
- E. Uchino and T. Yamakawa, “Soft computing based signal prediction, restoration and filtering,” in Intelligent Hybrid Systems: Fuzzy Logic, Neural Networks and Genetic Algorithms, Boston: Kluwer Academic Publisher, 1997, pp. 331-349.
- T. Miki and T. Yamakawa, “Analog implementation of neo-fuzzy neuron and its on-board learning,” in Computational Intelligence and Applications, Piraeus: WSES Press, 1999, pp. 144-149.
- M. Barman and J.P. Chaudhury, “A Framework for Selection of Membership Function Using Fuzzy Rule Base System for the Diagnosis of Heart Disease,” in Int. J. Information Technology and Computer Science, vol. 5, no.11, 2013, pp. 62-70, doi: 10.5815/ijitcs.2013.11.07.
- B. Widrow and Jr.M.E. Hoff, “Adaptive switching circuits,” URE WESCON Convention Record, vol. 4, pp. 96-104, 1960.
- S. Kaczmarz, “Approximate solution of systems of linear equations,” in Int. J. Control, vol. 53, 1993, pp. 1269-1271.
- L. Ljung, System Identification: Theory for the User, New York: Prentice-Hall, 1999.
- Ye. Bodyanskiy, I. Kokshenev and V. Kolodyazhniy, “An adaptive learning algorithm for a neo-fuzzy neuron,” Proc. 3rd Int. Conf. of European Union Soc. for Fuzzy Logic and Technology, pp. 375-379, 2003.
- Ye. Bodyanskiy, O. Tyshchenko and D. Kopaliani, “Multidimensional non-stationary time-series prediction with the help of an adaptive neo-fuzzy model,” in Visnyk Nacionalnogo universytety “Lvivska politehnika”, vol. 744, 2012, pp. 312-320.
- W.M. Caminhas, S.R. Silva, B. Rodrigues and R.P. Landim, “A neo-fuzzy-neuron with real time training applied to flux observer for an induction motor,” Proceedings 5th Brazilian Symposium on Neural Networks, pp. 67-72, 1998.
- Ye.V. Bodyanskiy, I.P. Pliss and T.V. Solovyova, “Multistep optimal predictors of multidimensional non-stationary stochastic processes,” in Doklady AN USSR, vol. A(12), 1986, pp. 47-49.
- Ye.V. Bodyanskiy, I.P. Pliss and T.V. Solovyova, “Adaptive generalized forecasting of multidimensional stochastic sequences,” in Doklady AN USSR, vol. A(9), 1989, pp.73-75.
- Ye. Bodyanskiy and I. Pliss, “Adaptive generalized forecasting of multivariate stochastic signals,” Proc. Latvian Sign. Proc. Int. Conf., vol. 2, pp. 80-83, 1990.
