AAFNDL — точная модель распознавания поддельной информации с использованием глубокого обучения вьетнамского языка

Author: Нгуен Вьет Хунг, Тханг Куанг Лои, Нгуен Ти Хыонг, Тран Тхи Туй Ханг, Труонг Ту Хыонг
Journal: Информатика и автоматизация (Труды СПИИРАН) @ia-spcras
Section: Информационная безопасность
Article in issue: Том 22 № 4, 2023.
Free access
В интернете «фейковые новости» - это распространенное явление, которое часто беспокоит общество, поскольку содержит заведомо ложную информацию. Проблема активно исследовалась с использованием обучения с учителем для автоматического обнаружения фейковых новостей. Хотя точность растет, она по-прежнему ограничивается идентификацией ложной информации через каналы на социальных платформах. Это исследование направлено на повышение надежности обнаружения фейковых новостей на платформах социальных сетей путем изучения новостей с неизвестных доменов. Особенно трудно обнаружить и предотвратить распространение информации в социальных сетях во Вьетнаме, потому что все имеют равные права на использование интернета для разных целей. Эти люди имеют доступ к нескольким платформам социальных сетей. Любой пользователь может публиковать или распространять новости через онлайн-платформы. Эти платформы не пытаются проверять пользователей, их местоположение или содержимое их новостей. В результате некоторые пользователи пытаются распространять через эти платформы фейковые новости для пропаганды против отдельного лица, общества, организации или политической партии. Мы предложили проанализировать и разработать модель распознавания фейковых новостей с использованием глубокого обучения (называемого AAFNDL). Метод выполнения работы: 1) во-первых, анализируем существующие методы, такие как представление двунаправленного кодировщика от преобразователя (BERT); 2) приступаем к построению модели для оценки; 3) подходим к применению некоторых современных методов к модели, таких как метод глубокого обучения, метод классификатора и т.д., для классификации ложной информации. Эксперименты показывают, что наш метод может улучшить результаты на 8,72% по сравнению с другими методами.
Социальные сети, вычислительное моделирование, глубокое обучение, извлечение признаков, алгоритмы классификации, фейковые новости, BERT, TF-IDF, PhoBERT
Short address: https://sciup.org/14127449
IDR: 14127449 | DOI: 10.15622/ia.22.4.4
Text of the article AAFNDL — точная модель распознавания поддельной информации с использованием глубокого обучения вьетнамского языка
1. Introduction. Nowadays, broadcasting fake news online has become standard on Social Networks [1, 2], and more information, opinions, and topics can happen worldwide [3]. Fake news has a huge impact. Detecting fake news is a critical step. Using machine learning techniques to see fake news employs three popular methods: Naive Bayes [4, 5], Neural Network [6, 7], and Support Vector Machine [8 – 10]. Normalization is essential in cleaning data before using machine learning to classify it [11].
Moreover, the analysis of fake news and information distortion detection algorithms is becoming popular [12, 13]; several methods of detecting fake news in Russia have also been proposed, such as using artificial intelligence [14] and machine learning [15].
In [16], Fake news is information that is false or misleading and is presented as news. Fake news is frequently intended to harm a person’s or entity’s reputation or to profit from advertising revenue. Nonetheless, the word has no fixed definition and has applied to false information. Public Informatics and Automation. 2023. Vol. 22 No. 4. ISSN 2713-3192 (print) 795 ISSN 2713-3206 (online) figures also use it to refer to any negative news. Furthermore, disinformation is the dissemination of incorrect information with malicious intent, and it is sometimes generated and spread by hostile foreign actors, particularly during elections. Some definitions of fake news include satirical articles that are misinterpreted as genuine and articles that use deception. Figure 1 describes the process of identifying fake information.
Fig . 1. Procedures for receiving and handling fake information
Stamp fake news
Stamping false news
Stamp authentication information

Reception methods
The sources
Classification of information received

STEP 2: ASSESSMENT
-
• The authorities have concluded the news
-
• News reported by organizations and individuals
We have performed the analysis and divided it into three steps; below are our implementation steps:
– Step 01 – Received Information : First, the information is gathered using various techniques from social networking sites like Twitter and
Facebook, as well as breaking news from CNN, BBC, or online publications. Then, this data will be classified as news content, social content, and outside knowledge.
– Step 02 – Assessment : Following classification, the data will be compared to standard datasets supplied by individuals or organizations to verify the correctness of the news. In the past, comparison and evaluation experts handled this work. Hence censorship groups frequently needed a lot of staff, time, and effort. However, these tasks have been mechanized by algorithms that improve comparison, contrast, and evaluation under the heavy weight of big data.
-
– Step 03 – Disclosure : Finally, the data is split and labeled as fake news, false news, and factual information.
In [17], Fake news was well-known in politics when it harmed the field. The election of Donald Trump as president has generated a lot of controversy due to false information regarding the number of votes cast in his favor. However, in the last two years [18], as the Covid-19 pandemic has become a severe problem in many nations, distance has made it easier for people to access unconventional information. For example, there is much false information about vaccines, and media campaigns to stop the spread of Covid-19 have destroyed numerous health systems. Price information also encourages people to hoard food, which contributes to inflation. The economy, health, and particularly human health have all negatives impacted by false information. We must identify and remove fake news from media outlets to combat it.
In the past [19], when looking for false news, individuals checked it manually by submitting it to professionals who would screen it; however, this requires a lot of time and money. Therefore automatic fake news search engines are now regarded as fake news, a current efficient fix. Machine learning and deep learning algorithms are a couple of them. In [20], these two AI algorithms frequently are utilized since more modern AI algorithms have been developed that better solve categorization challenges (natural text classification, voice classification, image classification, etc.) Additionally, as technology becomes more productive and affordable and as the availability of standard datasets rises, it becomes easier to assess the accuracy of false news detection models.
Although numerous datasets are available, you must use them correctly with your strategy. "Granik and colleagues Fake news detection using naive Bayes classifier" was published in 2017. However, because he used the dataset 4.9%, which is fake news, his accuracy is only 74% [20]. Compared to the entire surface of identifying fake news, it is a low number. In this case, four Kaggle datasets were used to accomplish this. These datasets are appropriate for the method.
-
– We analyze the existing techniques, such as BERT;
-
– We proceed to build a model to evaluate to classify fake information;
-
– We approach some Modern techniques to apply to the model through techniques, such as Deep Learning techniques, classification techniques, etc.
-
2. Related work. Because of the increased internet use, it is much easier to spread fake news. Many people are constantly connected to the internet and social media platforms. There are no restrictions when it comes to posting notices on these platforms. Some people take advantage of these platforms and begin spreading false information about individuals or organizations. This can ruin an individual’s reputation or harm a business. Fake news can also sway people’s opinions about a political party. There is a need for a method to detect fake news. A new study [21] has shown that machine learning classifiers are used for various purposes, including detecting fake news. The classifiers are listed first. The classifier trainers use a data set known as the training data set. Following that, these classifiers can detect fake news automatically.
This paper is organized as follows: Section 2 discusses the related work. Section 3 presents the concepts and features of identifying fake news on social networks. Section 4 describes the suggested viewport estimation technique. Section 5 contains the performance assessment. Section 6 concludes with a discussion of our conclusions and open questions.
Fake news and hoaxes have been around since before the Internet. Many clickbait use flashy titles or designs to entice users to click on links to increase ad revenue. In article [22], the author examined the prevalence of fake news in light of the media advances brought about by the rise of social networking sites. In this article, the author has developed a solution that users can use to detect and filter out websites containing false and misleading information.
In [23], supervised methods have yielded encouraging results. However, they have one significant limitation: they require a reliably labeled dataset to train the model, which is frequently complex, time-consuming, expensive to obtain, or unavailable due to privacy or data access constraints. Worse, because of the dynamic nature of news, this limitation is exacerbated under the setting, as annotated information may quickly become outdated and cannot represent news articles on newly emerging events. As a result, some researchers investigate weakly supervised or unsupervised methods for detecting fake news.
Studies [24, 27] have shown that Online social media networks have developed into a powerful platform for people to access, consume, and share fake news. Additionally, this results in the widespread dissemination of fake news or purposefully false or misleading information. The models must perform better for news in unexplored fields (domains) due to domain bias, which remains a significant obstacle for practical application even though accuracy is improving. As a result, numerous reports are shared, such as [24], focusing on analyzing the various traits and varieties of fake news and suggesting an efficient solution to detect it in online social media networks. This model, however, also deals with data that falls under the purview of the Online Social Media model. On the other hand, in research [25], the author has concentrated on examining data sources, particularly those that always include pairs of false and true news about the same topic. The author also relies on that to assess the accuracy and provide a dataset for concatenation useful for cross-domain detection. By examining the connection between domain news and its news environment, the author, like the method [26], focuses on developing a framework for comprehending the historical news environment. In all earlier posts, the author has cited history and the current state of the mainstream media. The author also creates a model to identify fake news by representing perceptions through domain gates. The outcomes are also good, but due to the anti-face change, this method is still only somewhat predictive if the user consciously improves; changes the history. To accomplish this, we discover that the method [27] the authors have chosen to emphasize in the suggested research, has compared various supervised machine learning models to categorize fake news (hoax news) with reliability. Although the author has suggested the K nearest neighbor model from there to classify the sample and improve the quality of service like the advertisement the author mentioned, this is similar to the method [26].
The real issue with social media is that anyone can post or share anything, occasionally leading to issues if the shared information needs to be verified. For many recent studies, this is also a challenge before sharing. For instance, [26] shows how the author used the skill by using news from Facebook, Instagram, and other social networks. The author has improved accuracy by using the random forest to enhance the quality. The method we have extended by designing a model through the data model is rigorously testbed, and the data is analyzed, in contrast to the methods mentioned above.
Most research has concentrated on detecting fake news in a specific language. Much information, however, is disseminated not only among native English speakers but also among speakers of other languages from other cultures. It raises an important question about the applicability of current methods for detecting fake news [23]. An extensive multilingual news database is required to train a multilingual fake news detection model. To the best of our knowledge, there are very few datasets for multilingual rumor detection. The PHEME dataset includes tweets in both German and English [29]. COVID-19 news in both English and Chinese is included in multilingual COVID-19 [18], whereas fake Covid [30] includes COVID-19 news in 40 languages. COVID-19 news is available in six languages on mm-COVID [31]. While the datasets available can assist scholars with multilingual fake news research, they could be more extensive in terms of the number of languages and data they contain.
Due to the benefits of AI algorithms, numerous researchers have used these algorithms. In 2019, in study [32] the authors used machine learning to compare three Nave Bayes algorithm classifiers, Support Vector Machine, and Logistic Regression to categorize fake news. Therein, the Nave Bayes algorithm classifier had the highest accuracy result of 83%. The HC-CB-3 approach [33], which the authors proposed in 2018, was deployed in the Facebook Messenger chatbot and verified using a real-world application, reaching 81.7% accuracy in the detection of fake news. By utilizing the binary classification method [20] in 2020, the authors could identify fake news with an accuracy of up to 93%. In the same year, in [34] the authors developed a method known as Bi-Directional Graph Convolutional Networks (Bi-GCN), which can process large amounts of data quickly and efficiently while yet maintaining accuracy to assist in the study of the propagation of rumors. In 2022, a new author suggested using the TF-IDF algorithm and a random forest classifier, but the results showed 72.8% of accuracy [35].
Additionally, numerous studies have taken an interest in recent studies developed and proposed in Vietnam, such as Bidirectional Encoder Representation from Transformer (BERT) [36]. In [36], the author uses deep learning and natural language processing to base a question on an answer. The author attempts to apply both language-specific BERT models and multilingual BERT models for the Vietnamese language, including DeepPavlov multilingual BERT and multilingual BERT refined on XQuAD (PhoBERT). The analysis in this direction, though, ends at the level of the representative model. In [37], the BERT and Hybrid fastText-BILSTM models are also improved for the rather large data set of customer reviews. However, the approach of this method clearly shows that the BERT model is superior to Deep Learning. Recently, the K-BERT model has been suggested to support language representation knowledge in specialized fields [38]. Using the knowledge graph’s topic model to infer the topic for the input sentence, the author has examined and approved the model for segmenting the knowledge graph by topic. Our approach, however, relies on the BERT technique and then normalizes the data using context analysis based on the TF-IDF evaluation model to prevent the problem of incorrect input data.
In this research, we present a deep-learning aggregation model that employs the TfidfVectorizer algorithm to train and test the data, matching and transforming the training set in practice and altering the test set to increase the accuracy in detecting fake news combined with computation economics of the current BERT scheme. Additionally, Indonesia’s recent development is also making substantial progress [39]. However, the BERT model still has unresolved challenges, such as sentiment analysis, text classification, and summarization. In this report, we used the BERT and TF-IDT models to analyze and evaluate fake information. Experimental findings demonstrate our model’s great effectiveness, with false news detection accuracy up to 99% higher than that of the V3MFND, TF_RFCFV, and FNED models.
-
3. Theory background
-
3.1. Definition of fake news. Defining fake news has become complicated since before 2016; it only referred to satirical and humorous news [40]. After a period of complex changes with different meanings in production, the press and the people’s government are threatened [41]. Since then, fake news has become a buzzword on social networks [42]. Through the analysis of the authors [40 – 42]. We define fake news as a type of information that is inaccurate, or in other words, false with the primary information (accurate information). They can be misleading, incorrect, or intentionally created to deceive the public into attracting attention or increasing specific personal or collective interests.
-
In Vietnam [43 – 45], much information, including accurate and incorrect information, is transmitted throughout the country to deceive appropriate property. Many authors have proposed and built models for that information, such as [43] predictive models to transfer knowledge from one data set to another without entity or relational matching. Besides, the author in [44] carefully recommends counterfeit practices that rely on covid 19 to take advantage of it to benefit individuals and organizations. This news is never proper to reality and is given to deceive and create misunderstandings about a particular issue or event.
Unfortunately, fake news is now not only spread by word of mouth from one person to another, but through media effects, and social networks, it spreads at breakneck speed. Because it is fabricated news, it is exaggerated, so it contains thrilling, attractive, easy-to-hit emotions and the psychology of people with high "expectations".
Fake news not only wins over the curiosity of readers, but it also weakens the media. Fake news misdirects a part of society and "guides" some reporters and press agencies - unverified information from individuals on Facebook, Zalo, etc. But there are online newspapers that still "quickly" turn into journalistic products.
Our research shows that not only in Vietnam but also in other countries, it is pretty common to identify fake information or human behavior can be classified into three main categories as follows in Figure 2:
– The group that reluctantly publishes negative information always finds bad points or distorts information.
– The group of people who need to be fully informed but rely on their limited knowledge to give false information.
– The group has no data but wants to get views and badmouths, so they are ready to spread unverified information.
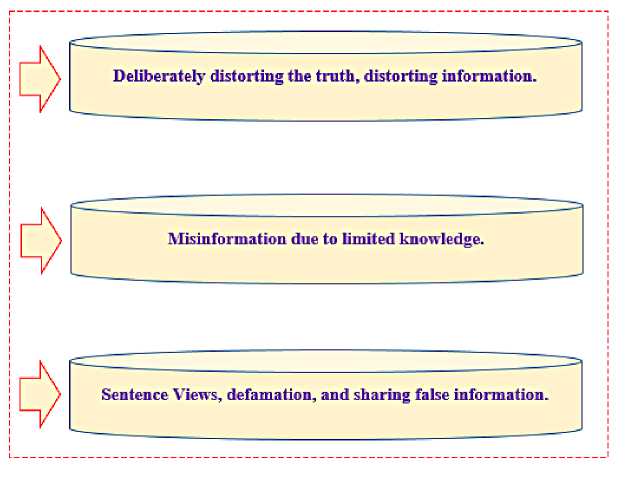
Fig . 2. Three groups of people spread fake news famous in Vietnam
-
3.2. Some features of recognizing fake news on social networks. There are three fundamental characteristics to detect fake news on social networks: User, Posts, and Network.
– User : Fake news can be created and spread from malicious accounts on social networking sites. User features represent how those users interact with information on social media. The characteristics of social networks can
be divided into different levels: individual level and group level, in which the personal level includes relevant information such as Age, number of followers, number of posts, etc. At the group level, users will know information related to news of the posts that the user posts in the group.
– Post : People express their opinions or feelings through social media posts such as Feedback, sensational reactions, etc. Therefore, extracting Post features helps to find news stories and fake news through public posts. Feature Post relies on user information validation to infer authenticity from multiple aspects related to social media posts. We can extract Post information to detect fake news on social networks. These features are divided into three levels: 1) Usually, social media posts. Each post usually has characteristics such as Opinion, topic, and credibility - Post Level, 2) All relevant posts, specifically the one using “Wisdom of Crowds”, which means “Wisdom of the crowd”. For example, average confidence scores are used to assess news reliability - Group Level, and 3) Recurrent Neural Network (RNN) is used to determine when to post on social networks to attract posts that change over time. Based on the shape of this time series for different metrics of related posts (e.g., Number of Posts), mathematical features can be calculated, such as Parameters by time – Temporal Level.
– Network : Users use social networks to connect members with similar interests, topics, and relationships with each other – network-based extracts particular structures from users who post public posts on social networks. Network-based is built in different styles.
– Stance Network : Built by visible nodes for all news-related posts, the edges represent the weight of the Stance Network similarity.
– Co-occurrence Network : Built on user interaction by counting whether those users have posts related to the same article.
– Friendship Network : Indicate whether users follow or not follow related posts.
Based on the features of detecting fake news on social networks presented above. In this study, the authors use Post features to identify the information to be verified.
-
4. AAFNDL. In this section, we discuss some of the issues of fake news – definitions, components, types, and features of disinformation. We detail our export model, which does some of the following work to identify forgery information printed.
-
4.1. Problem Formulation. Fake news has become a global issue that must be addressed immediately [46]. Defines fake news as misleading content such as conspiracy theories, rumors, clickbait, fabricated news, and satire [46]. According to reference [47], fake news is defined as misinformation
-
__________________ИНФ_ОРМ_АЦИ_ОННАЯ БЕЗОПАСН_ОСТЬ__________________ and disinformation, including false and forged information, that is spread to mislead people or fulfill propaganda.
In reality, there are several types of fake news. For example, we can take the form of a stance, satire, multi-modal, deep fake, or disinformation. There are four types of perspectives: agree, disagree, discuss, and unrelated [48]. Each concurrence is similar to the information in the fake news headline. In addition, the point of disagreement contains conflicting information.
Therefore, properly evaluating fake information to combat fake news is a big challenge. And from there, we can build a system to combat misinformation or phony information on today’s social networking platforms. Most studies evaluate using English, Spanish, and Portuguese [49]. We find that English is the most commonly used language today. We recognize that the style of fake news and how it is written can also vary from country to country, so a dataset from a country that speaks that language would be a good contribution, rather than translating existing datasets into other languages.
Furthermore, we have tried more than two examples above, and the results show that our system performs reliably. With trained documents, the system always ensures high accuracy. In addition, we also have tried a few examples in addition to the training document the results are also good.
However, before processing for inclusion in the system, we have added a step before putting it into the system, that is, to process the actual data on social networking sites (the text is too long, the grammar is incorrect, or misspellings and so forth). We call this phase the "Text summarization system", but it doesn’t change the meaning of the entire text. Our system will be faster due to the shorter sentence structure.
In Figure 3, we use a Text summarization that has become an essential and helpful tool for supporting and extracting textual information in today’s rapidly evolving information age. Therefore, in this section, we propose a system of "Text summarization system" in three main stages as follows:
– Analysis : Analyze the input text to provide descriptions, including information used to search and evaluate necessary corpus units and input parameters for the summary.
– Transformation : The selection of extracted information is transformed to simplify and unify; as a result, corpus units have been summarized.
– Synthetic : From the summarized corpus, create a new text containing the primary and essential points of the original text.
Extraction plays a significant role in detecting fake information and word processing-related problems. The extraction method is built by extracting necessary textual units (sentences or paragraphs) from the original text based
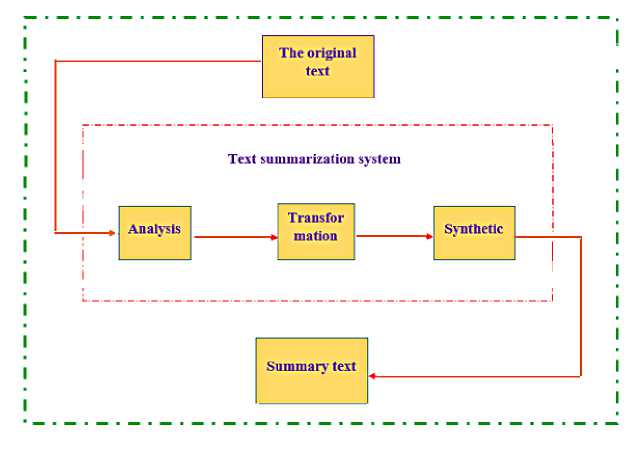
Fig. 3. Stages of the text summarization system on analysis of words/phrases, frequencies, locations, or suggested words to determine the units’ importance and extract the actual units from there as a summary. We can see it in Figure 3. Text transformation is how we use statistical and graphing algorithms to represent it. Calculate the weight of the sentence importance and select a subset of the original text to become the summary text and represent it as natural language processing.
-
4.2. Design and problem solve. Based on the inadequacy and explosion of information technology, we found that many studies have used tools to detect bots but have yet to detect other bots because of the constant change of the bot feature. It is hard to meet many requirements for online detection. Therefore, in this section, we analyze and build a method to detect many separate types of bots instead of one. According to [50], the authors devised an unsupervised technique for automatically clustering similar bot accounts based on a dataset and then assigning homogeneous accounts to specialized bot classifiers.
In this section, we propose a model to identify fake information. We analyze to detect phony information and use programming techniques to build an artificial i nformation d etection m odel. The p roposed m odel uses neural network architecture to predict fake news in Figure 4.
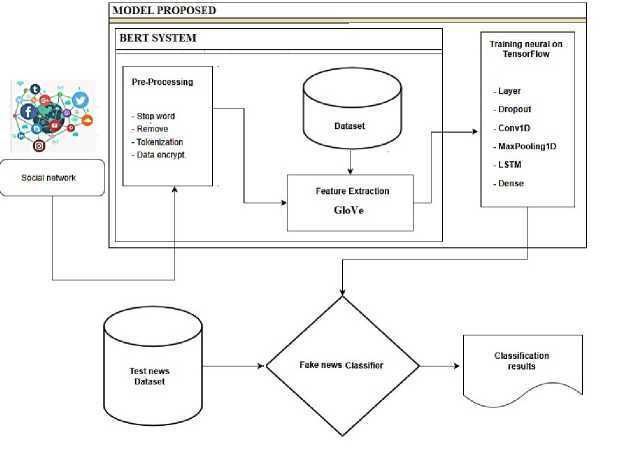
Fig . 4. AAFNDL algorithm model evaluates fake information
The model is detailed as follows:
Step 01. Data collection : The proposed approach will input the dataset from a Social network to include in the system. The data is then fed into the BERT system, a variety of techniques analyzed by many researchers such as Word2vec [51], and FastText [43]. However, in this report, we use word2vec for analysis in the BERT system shown in Figure 4. This system will analyze the contents of the word information based on the analyzed content, according to Golve. We call it the benchmark license for evaluation. This is very important because it directly affects the later a nalysis. For example, the b attery in the computer, if it is said that the battery runs fast, it is not good because the battery runs out quickly. Therefore, the BERT technique will find a vector representing each word based on a large corpus, so it cannot describe the diversity of contexts. This creation shares his direction toward the accuracy of sentences in Vietnamese. In [3], the author also shared the opinions and views of the comments. Therefore, creating a representation of each word based on the other words in the sentence yields much more meaningful results. In this step, our method will focus on data processing, and this step will be analyzed through techniques and combined with modern methods such as BERT to process the original data quickly.
In summary, at this step, we do the following two tasks:
– First , test data is collected from the content of articles from pages and groups of social networking sites. Collect stories with many views, comments, and shares for this data.
– Second , we collect real-life data sets collected from trusted websites, and the data are described in detail in the performance evaluation sections.
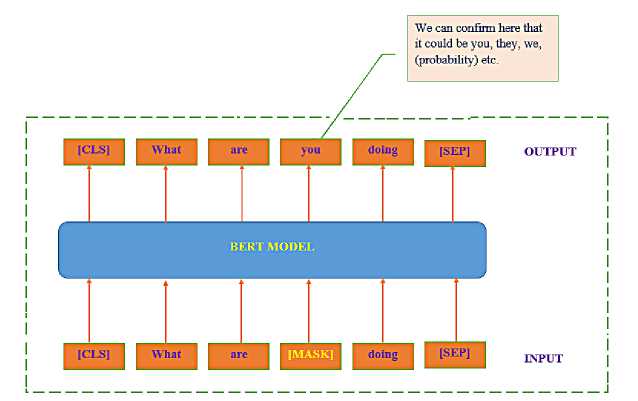
Fig . 5. BERT example uses two-way words on both sides
Step 02. Data preprocessing: The data will be analyzed and preprocessed before entering the system. We use several analytical techniques, such as word separation, unnecessary word removal, labeling, and data encryption. Furthermore, we also use the BERT [36, 39, 52, 53] feature to BERT extends the capabilities of previous methods by generating contextual representations based on words first and then leading to a language model with richer semantics.
After collecting data from news websites and social media stories according to a particular structure, data preprocessing is performed. First, convert the data to its correct form and apply word separation measures to separate the document’s content into corresponding words and phrases, remove redundant characters in Vietnamese, and keep only words mean. The result of the preprocessing stage is the index vector for each text document. The preprocessing steps are performed in Figure 6.
Split words with vnTokenizer
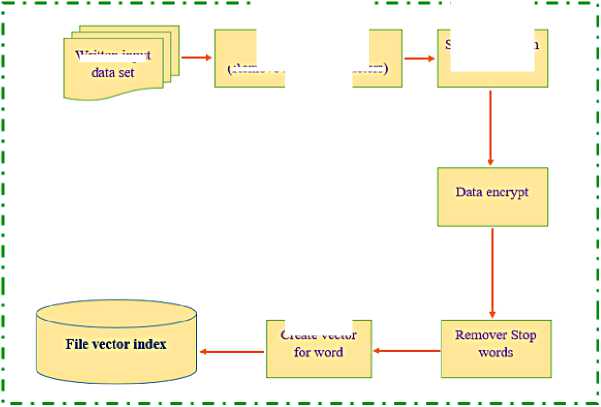
Create vector
Fig . 6. Our Data Preprocessing Diagram
Written input
Clean input data (Remove special characters)
Step 03. Extract information : Extract the essential information from a text to create a concise version that still contains enough of the core information of the original text with the requirement to ensure grammatical and spelling correctness.
We find that the BERT model has shown superiority and responsiveness to the processing process. However, the current techniques could be more extensive in expressing the capabilities of representative vector models, especially the fine-tuning a pproach. The main limitation here is that language models are built based on a one-dimensional context, which limits the choice of architectural model to be used during pre-training. In OpenAI GPT [53], for example, the authors use a left-to-right architecture, meaning the tokens depend only on the previous tokens.
Furthermore, we can see that Figure 7 is a small data collection module that performs normalization with the following specific functions:
-
– Step 01 : Read news from data contextually analyzed by BERT;
-
– Step 02 : Extract information, select information and remove inappropriate information;
-
– Step 03 : Save information and system for proof;
-
– Step 04 : Process the TF-IDF index for news data;
-
– Step 05 : Build an inverse index for news for information search;
-
– Step 06 : Finish.
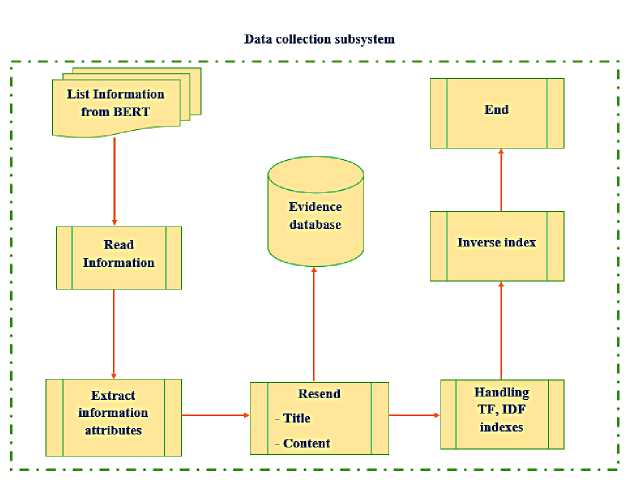
Fig . 7. Data collection subsystem
In general, this system with the idea is to build an accurate data set as evidence to deal with fraudulent and fake acts of users. In the future, we will continue to update more information, hoping that the system will automatically update and put more data into the system.
Step 04 Identify features: The study uses TF-IDF to pinpoint the characteristics of the text’s content. The most well-known statistical method for assessing the significance of a word in a text paragraph within a collection Informatics and Automation. 2023. Vol. 22 No. 4. ISSN 2713-3192 (print) 809 ISSN 2713-3206 (online) of various text fragments is TF-IDF (Term Frequency - Inverse Document Frequency). It is frequently employed in text data mining as a weight. Text representation is transformed into vector space by TF-IDF. Therefore, we have used additional TFIDF [51, 54] features by calculating the TF by counting the keywords on the input data. However, we consider the number of keywords (for keywords that are too large, i.e., more than nine times, we consider correlation rather than using keywords). This will be more difficult because the input data processes at the basic levels. Therefore, here we have further analyzed using the following logarithmic (log) function to calculate TF :
TF =
1 + log ( Keyword Count ) log ( Word Count )
This parameter Term Frequency ( T F ) reflects whether we use a keyword too often or too rarely. Sometimes this value does not affect a positive because we may need to measure the importance of a phrase, not just the frequency in terms of how many times it uses, but be it a preposition, pronouns, conjunctions, e.t. Therefore, to avoid that, we need the Inverse Document Frequency ( IDF ) index, give by:
IDF = log(1 +
Total datasets Datasets with keyword
The IDF formula is equivalent to the T F procedure. A linear lower function will more accurately reflect the value in situations where phrases with high IDF scores because a linear IDF function pushes a document’s score too high. When phrases with high IDF scores (possibly uncommon words, misspelled terms, etc.) are in the field, the Linear IDF , like TF, can raise the document’s score excessively.
Therefore, the TF - IDF is a comprehensive metric, unlike the keyword density measure, which only reflects the degree of "cramming" a specific keyword into the text. Furthermore, it helps to lessen the prominence of meaningless words and phrases while elevating the importance of meaningful and uncommon terms.
Step 05 Output parameter setting: After performing the IF-IDF analysis, we conduct the analysis based on the classes trained through Layer, Dropout, Conv1D, MaxPooling1D, LSTM, and Dense layers for classification. Here we perform the assessment and divide it into two categories. If the result is 1, it is fake news; if the result is 0, it is not. The experimental results that we define in formula 3 are the ones we tested:
(1 fake news
Classification results = < „ . . . (3) [ 0 otherwise
Finally, if we want to test with our model, we can input data from the test set, and the system, through the trained data, will evaluate whether the information is fake or not.
-
5. Performance Evaluation. This section will detail the installation process and present some assumptions for detecting fake information through the performance evaluation process.
-
5.1. Experimental Settings. This section will discuss standard disinformation detection methods used in our review. In this study, we focus on processes that take only previously forged information as input. Our future work will include more advanced methods.
-
-
5.2. Performance evaluation. This section uses three datasets to evaluate the methods referenced, including fake_or_real_news, news, and WELFake_Dataset in [57].
In particular, we evaluate three Fake News on ASUS Rog Strix G15 G513IC Laptop, with Chip: Ryzen 7- 4800H, Ram: 16 GB, and Graphics: RTX 3050 4GB methods: A comprehensive multi-domain multimodal model for identifying fake news in Vietnamese (we called V3MFND), Term Frequency - Resource Frequency combination to detect fake Vietnamese (we called TF_RFCFV), and A Deep Network for Social Media Fake News Early Detection (we called FNED). The following are the specifics of each method:
– V3MFND [44] : The author of this article also employs the multidomain deep multimodal fake news detection model for Vietnamese, also known as v3MFND. Based on the evaluation of the function of each method in the multimodal model, the tests are expanded on the actual data set and demonstrate the performance of multi-domain, multimodal fake news detection for Vietnamese people.
– TF_RFCFV [45] : This model uses the PhoBERT [55] pre-trained language model and the Term Frequency - Resource Frequency combination to detect fake Vietnamese news on social networking sites. For word embedding and extraction for tamper detection, inverse data (TF-IDF) and convolutional neural networks (CNN) were used.
– FNED [56]: This method suggests a new deep neural network for early fake news detection. The technique is based on state-sensitive crowdresponse feature extraction, which takes the user’s text feedback and the corresponding user profile and extracts text and user features. The average aggregation mechanism, approach, and location-aware attention mechanism highlight the importance of user feedback at specific ranking positions. To carry out feature aggregation across multiple regions using different window sizes.
In general, the methods are evaluated to be relatively stable. The advantages of every technique are demonstrated. Regarding our approach, we draw on some of the used strategies, like using tools, machine learning, and deep learning to improve our algorithms using the abovementioned methods. However, our system was created based on neural network architecture to foretell fake news.
To experiment with the evaluations between the AAFNDL method and the reference methods, we divide and arrange the data sets according to 8:2, which means that 80% of the dataset uses for training and the remaining 20% uses tests. The analyzed data evaluates as follows: for the data file " fake_or_real_news " in Figure 8, " news " in Figure 9, and " WELFake_Dataset " in Figure 10. In general, our method outperforms the mentioned methods. Studies reveal that, in contrast to the FNED method, which consistently achieves results of 92%, our method achieves over 99% in Table 1.
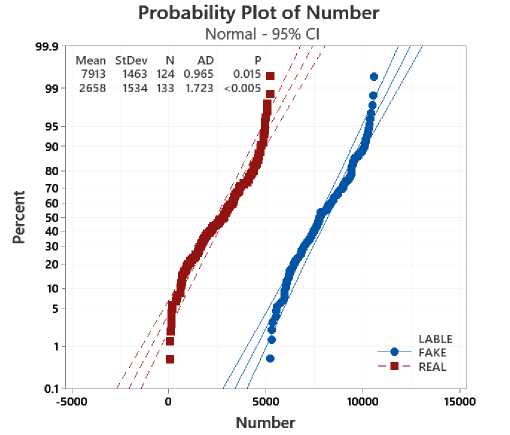
Fig . 8. Probability Plot of fake_or_real_news " with Confidence Interval 95%
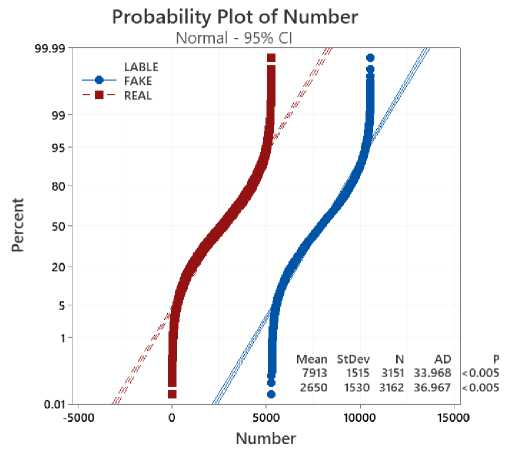
Fig . 9. Probability Plot of " news " with Confidence Interval 95%
Table 1. Findings from comparing the AAFNDL method to the referenced methods
|
STT |
Methods |
Value |
Dataset names |
||
|
fake_or_real_ news |
news |
WELFake_ Dataset |
|||
|
1 |
V3MFND |
Accuracy |
98.44 |
98.19 |
98.81 |
|
F1-Score |
92.72 |
92.79 |
95.97 |
||
|
2 |
TF_RFCFV |
Accuracy |
95.83 |
93.13 |
95.83 |
|
F1-Score |
82.91 |
82.91 |
90.43 |
||
|
3 |
FNED |
Accuracy |
90.76 |
90.76 |
91.99 |
|
F1-Score |
68.47 |
68.27 |
77.13 |
||
|
4 |
AAFNDL |
Accuracy |
99.22 |
99.48 |
99.70 |
|
F1-Score |
95.97 |
94.36 |
95.97 |
||
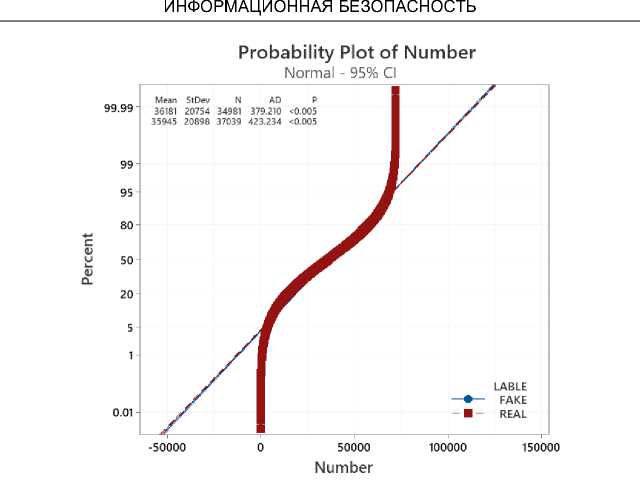
Fig . 10. Probability Plot of " WELFake_Dataset " with Confidence Interval 95%
To evaluate the performance of the proposed method with the evaluation method, we make two measurements, Accuracy, and F1-score from [58, 59], using the following formulas:
TP + TN
Accuracy = TP + TN + FP + FN •
P recision
TP
TP + FP,
Recall =
TP
TP + FN,
F 1 — Score = 2 *
P recision ∗ Recall
Precision + Recall ’
where:
-
– TP: The model predicts 1 while actually, it is 1;
-
– TN: The model predicts 0 while actually, it is 0;
-
– FN: The model predicts 0, but the truth is 1;
-
– FP: The model predicts 1, but the truth is 0.
-
6 . Conclusions. This paper presents the recent techniques that BERT widely uses along with the evaluation as mentioned above criteria TF-IDF. We are applying assessment techniques to analyze fake information in Vietnam and the limited problems in Vietnam and the general world. Second, we have built and analyzed an evaluation model based on the combination of two criteria of BERT and TF-IDF. Besides, we also have used Deep learning techniques to classify fake information on social networking sites like Facebook, Zalo, etc.
On the one hand, for each dataset, the methods all show relatively stable results from the WELFake_Dataset to fake_or_real_news and news. For the dataset WELFake_Dataset, the techniques have the best results: V3MFND of 98.81%, TF_RFCFV of 95.83%, and FNED of the lowest at 91.99%, and our method achieves the best rate up to 99.70%. For the dataset fake_or_real_news, the methods V3MFND, TF_RFCFV, and FNED are 98.44%, 95.83%, 90.76%, and 99.22%, respectively. The remaining dataset is 98.19% with V3MFND, 93.13% with TF_RFCFV, 90.76% with FNED, and ours is 99.48%.
Moreover, the experiment also shows that the results of the F1-Score of AAFNDL are always better than those of the reference methods; the results can improve up to 3.25%, 13.06%, and 27.50% for the referenced procedures projections are V3MFND, TF_RFCFV, and FNED, respectively.
On the other hand, considering each method, the data is different. However, the experiment shows that the oscillometric methods at the set level, such as the V3MFND method (from 98.19 to 98.81) and the proposed method (from 99.22 to 99.70), fluctuate by no more than 1%, besides two of the remaining techniques ranged no more than 3% with TF_RFCFV from 93.13 to 95.83, and with FNED from 90.76 to 91.99 not more than 2%.
Also, this paper has looked at four methods for identifying false information. Our analysis also demonstrates that, when there is a method that can detect fake news up to 98.81%, the estimated performance of the current techniques is relatively good. Howeve, experiments have shown that our method is better than the referenced methods when the proposed model and analysis technique is used. In the future, our research will enhance current approaches by enlarging the problem with more data.
