Adaptive AI-Driven Anomaly Detection Framework for Identity & Access Management in Financial Technology Systems

Author: Karimulla Syed, Elijah Falode, Adeel Shaik Muhammad
Journal: International Journal of Education and Management Engineering @ijeme
Article in issue: 2 vol.16, 2026.
Free access
Identity and Access Management (IAM) is critical for securing digital assets, particularly in financial technology (FinTech) systems, where unauthorized access can lead to significant financial losses. Three formal research questions guide this work: (RQ1) Do AI-driven models statistically significantly outperform traditional rule-based IAM systems in anomaly detection accuracy? (RQ2) Which AI model best balances precision and recall for real-time insider-threat detection under class-imbalanced IAM log conditions? (RQ3) Are the observed performance gains robust and stable across cross-validated experimental folds? This study evaluates the performance of AI-driven anomaly detection models, including autoencoders, random forests, and support vector machines, in detecting unusual user activities and potential insider threats. The Autoencoder model achieved the highest overall accuracy of 94.2% (+/- 0.8% across five-fold cross-validation) with a precision of 92.8% and recall of 91.5%. The Random Forest attained a slightly lower accuracy (92.5%) but excelled in recall (93.2%), highlighting its strength in identifying actual malicious activities. Compared to traditional rule-based IAM methods, which achieved only 78.4% accuracy, AI models significantly improved anomaly detection, particularly for subtle or previously unseen threats. McNemar's tests confirm that all accuracy improvements over the baseline are statistically significant (p < 0.001). The Autoencoder also demonstrated the lowest latency (120 ms), making it suitable for real-time deployment. These results confirm that AI-enhanced IAM systems can effectively strengthen security and operational efficiency in FinTech environments, within the scope of the simulated and publicly available datasets employed in this study.
Identity and Access Management (IAM), Anomaly Detection, Artificial Intelligence, Machine Learning, Deep Learning, Autoencoder, Random Forest, Financial Technology Security, Insider Threat Detection, Cybersecurity
Short address: https://sciup.org/15020330
IDR: 15020330 | DOI: 10.5815/ijeme.2026.02.01
Text of the scientific article Adaptive AI-Driven Anomaly Detection Framework for Identity & Access Management in Financial Technology Systems
Identity and Access Management (IAM) is a cornerstone of modern cybersecurity, focusing on ensuring that only authorized individuals have access to organizational resources. IAM systems manage user identities, control authentication, and regulate access permissions across digital platforms. As organizations increasingly adopt cloud services and digital infrastructures, the importance of IAM grows, particularly in sectors that handle sensitive data, such as healthcare, finance, and government. The significance of IAM in cybersecurity is underscored by studies that emphasize its critical role in preventing unauthorized access and maintaining data integrity, as highlighted by Rajak et al. [13], particularly in cloud computing environments where user access is more dynamic and diverse, as noted by O'Leary [14]. These systems are also vital for compliance with security regulations, as they help ensure that access controls align with industry standards, as discussed by Aboukadri et al. [16].
Traditional IAM systems often rely on static, rule-based methods and predefined signature databases to detect security breaches. Although effective against known threats, these methods are less capable of identifying new sophisticated attacks, such as insider threats or advanced persistent threats (APTs), as pointed out by Singh et al. [9]. The limitations of these conventional approaches have led to a growing interest in incorporating Artificial Intelligence (AI) techniques, particularly machine learning (ML) and deep learning, to enhance anomaly detection. AI enables IAM systems to continuously learn from new behavioral patterns and adapt to evolving threats, offering greater accuracy in detecting unusual activities that could signal potential security breaches. Researchers such as Prakash and Ali [10] have highlighted how AI can identify subtle patterns that rule-based systems often miss, while Vitla [20] discussed the transformative potential of AI in IAM by improving real-time detection capabilities, which are critical in dynamic threat landscapes.
AI-driven anomaly detection systems are becoming increasingly relevant in the financial technology (FinTech) sector, where safeguarding digital transactions is essential. In the context of IAM, AI technologies can help identify fraudulent transactions by analyzing transaction patterns in real time, as evidenced by Singh [9], who explored how ML models can be integrated into IAM systems for financial institutions to detect unauthorized access effectively. Research by Rajak et al. [13] and Selling [2] indicates that the use of AI models significantly improves the ability to detect fraud in real time, allowing IAM systems to respond more effectively to emerging threats and vulnerabilities in FinTech environments.
As digital transformation continues to accelerate across industries, IAM systems have become a critical line of defense in safeguarding organizational assets. However, despite their significance, traditional IAM systems often struggle to keep up with the evolving threat landscape. Insider threats and APTs are increasingly difficult to identify using conventional, rule-based systems because such attacks are often subtle, dynamic, and adaptive, as noted by Singh et al. [9] and Rajak et al. [13].
The need for more effective anomaly detection methods in IAM systems has become evident. ML and deep learning (DL) algorithms have emerged as promising tools for enhancing anomaly detection by allowing IAM systems to learn and adapt to new patterns of behavior in real time. These AI-driven models offer significant advantages over traditional methods by identifying subtle, previously unknown threats that may not be captured by signature-based or rule-based systems, as discussed by Chad [1] and Vitla [20]. However, the gap in current IAM systems lies in their limited integration of AI for real-time anomaly detection (AD). Significant challenges remain in effectively integrating AI into existing IAM frameworks, including the complexity of model training, the need for large quality datasets, data privacy concerns, and the requirement for AI models that can perform with low latency and high accuracy in real-world environments, as emphasized by O'Leary [14] and Selling [2].
This problem is particularly pressing in the FinTech sector, where the security of digital transactions and user identities is crucial. Singh et al. [9] demonstrated how ML models can be effectively integrated into IAM systems within financial institutions to improve the ability to detect unauthorized access and reduce fraud. Research by Rajak et al. [13] and Selling [2] highlights that AI-based models significantly improve the detection of real-time threats, allowing IAM systems in the FinTech sector to respond more effectively to emerging security challenges.
Despite this growing body of literature, three critical gaps remain underexplored. First, prior studies lack unified, end-to-end benchmarking that simultaneously evaluates reconstruction-error-based (autoencoder), ensemble (random forest), and kernel (SVM) approaches under realistic class-imbalanced IAM log conditions representative of live FinTech environments. Second, the joint optimization of inference latency and detection recall -- two competing objectives in high-frequency payment systems and real-time transaction authorization -- has not been rigorously quantified. Third, cross-validated statistical validation with confidence intervals and significance testing is absent from virtually all prior FinTech IAM anomaly detection studies reviewed, leaving reported improvements empirically fragile. This study addresses all three gaps by: (i) constructing a unified benchmark merging AWS CloudTrail event logs, a large-scale risk-based authentication dataset, and the CMU CERT Insider Threat Dataset v6.2 under a documented class-balancing protocol; (ii) evaluating three AI paradigms jointly on accuracy, recall, ROC-AUC, latency, and model drift stability; and (iii) reporting five-fold cross-validated results with mean +/- standard deviation and McNemar's test significance values.
Accordingly, this study is formally guided by three research questions:
RQ1: Do AI-driven anomaly detection models statistically significantly outperform traditional rule-based IAM baselines in FinTech environments?
RQ2: Among autoencoders, random forests, and SVMs, which model provides the optimal balance between precision and recall for insider-threat detection under class imbalance?
RQ3: Are observed performance improvements robust and stable as measured by five-fold cross-validation with confidence intervals?
The primary aim of this study is to explore and develop an adaptive AI-driven anomaly detection framework for IAM systems specifically tailored for FinTech environments. This study investigates how advanced ML and DL models can be integrated into IAM systems to improve the detection of anomalous behaviors and potential security breaches in real time. By comparing AI-based techniques with traditional rule-based methods, this study aims to highlight the advantages of AI in enhancing the accuracy, adaptability, and scalability of IAM systems in the rapidly evolving FinTech sector. This study also aims to address the challenges involved in implementing AI in IAM systems -- such as data privacy concerns, computational efficiency, and model training complexity -- and proposes solutions to mitigate these challenges.
This paper is organized as follows: Section I introduces the topic. Section II reviews the literature. Section III describes the methodology, datasets, and model configurations. Section IV presents experimental results and discussion. Section V concludes with directions for future research.
2.literature Review
-
2.1. Overview of IAM Systems
-
2.2. Anomaly Detection in IAM
Identity and Access Management (IAM) is a crucial cybersecurity discipline that manages digital identities and controls access to resources in an organization. IAM systems are designed to ensure that only authorized individuals can access sensitive data or services while preventing unauthorized access. These systems involve the administration of user identities, roles, authentication protocols, and authorization policies across digital platforms. As organizations move toward cloud computing and digital infrastructures, IAM systems become increasingly critical in securing organizational data, especially in industries such as healthcare, finance, and government. According to Rajak et al. [13], IAM is critical for securing cloud-based environments in which user access control is more dynamic. Singh [17] emphasized the IAM's role in protecting digital business operations across industries. Furthermore, O'Leary [14] argued that IAM is essential for compliance with various regulatory standards, ensuring that organizations meet legal and industry-specific requirements.
As organizations expand their digital footprints, the role of IAM has evolved to address emerging challenges. Traditional IAM systems were primarily designed to manage access within a networked environment; however, the rise of mobile applications, cloud services, and external vendors has led to more complex access management scenarios. Singh [17] pointed out that IAM systems must adapt to the needs of modern enterprises, where users need to access resources across a wide range of platforms. This shift has prompted the development of more advanced IAM systems that integrate adaptive technologies such as ML and AI to enhance their security and efficiency. Rajak et al. [18] highlight the integration of AI into IAM systems to improve real-time access control, particularly in dynamic environments like FinTech.
Anomaly detection is a vital component of IAM systems, which aim to identify unusual activities that deviate from established user behavior. Traditional methods, such as rule-based systems and signature-based techniques, have been widely used to detect known threats. Rule-based systems rely on predefined conditions to flag suspicious activities, whereas signature-based techniques use known attack patterns to identify potential threats [17,18]. However, these methods have significant limitations. Singh et al. [9] argue that rule-based systems are effective at detecting well-known attack patterns but struggle with new and sophisticated threats, particularly those that do not conform to predefined rules. Similarly, Aboukadri et al. [16] pointed out that signature-based systems suffer from a high false-positive rate when attempting to detect novel attacks, making them ineffective in dynamic environments such as cloud platforms and mobile ecosystems. Selling [2] highlighted that traditional systems are not well-suited for detecting anomalies in real time, as they require predefined patterns or signatures to function. O'Leary [14] also notes that these methods fail to adapt to evolving attack strategies, which is a critical issue in modern cybersecurity, especially in high-risk sectors like FinTech.
In response to these challenges, AI and ML techniques have emerged as adaptive solutions for anomaly detection in IAM systems. Vitla [20] discusses the transformative potential of deep learning models, such as neural networks, which are capable of identifying complex and subtle patterns that rule-based systems might miss. Selling [2] emphasizes that ML techniques, including clustering and classification algorithms, enable IAM systems to detect anomalies in real time. Vegas and Llamas [15] highlighted that AI-based models can help organizations improve operational efficiency by automating detection processes and reducing manual intervention.
AI has also been found to be more effective in detecting insider threats and APTs because it is not limited by predefined rules [13,19].
Despite the promising potential of AI, the implementation of AI-driven anomaly detection in IAM systems presents several challenges. Thomas and Alexander [19] note that the availability of comprehensive data on user behavior is crucial for the effectiveness of AI models. Additionally, training AI models for real-time anomaly detection requires significant computational resources [20]. Vitla [20] highlights the risk of overfitting, where the model performs well on training data but fails to generalize to unseen data. These challenges underscore the need for carefully designed experimental protocols, including cross-validation and class-imbalance handling, as adopted in the present study.
AI has also been found to be more effective in detecting insider threats and APTs because it is not limited by predefined rules [13,19].
Despite the promising potential of AI, the implementation of AI-driven anomaly detection in IAM systems presents several challenges. Thomas and Alexander [19] note that the availability of comprehensive data on user behavior is crucial for the effectiveness of AI models. Additionally, training AI models for real-time anomaly detection requires significant computational resources [20]. Vitla [20] highlights the risk of overfitting, where the model performs well on training data but fails to generalize to unseen data. These challenges underscore the need for carefully designed experimental protocols, including cross-validation and class-imbalance handling, as adopted in the present study.
-
2.3. Critical Synthesis and Research Gap Identification
-
2.4. AI in Anomaly Detection
-
3 . Methodology
-
3.1. Research Approach
-
-
3.2. AI Techniques for Anomaly Detection
Table 1 presents a structured comparative synthesis of representative prior studies, making the research contributions of the present work precise and empirically grounded.
Table 1. Comparative synthesis of prior AI-based IAM anomaly detection studies and identification of research gaps
|
Author(s) & Year |
Method |
Dataset |
Best Acc. |
Key Limitation |
|
Chad [1], 2025 |
Autoencoder + RBAC |
AWS CloudTrail |
93.1% |
No cross-validation; no latency benchmark |
|
Selling [2], 2024 |
Random Forest |
Synthetic IAM logs |
91.8% |
Single dataset; class imbalance not addressed |
|
Thorat et al. [3], 2024 |
Hybrid CNN-LSTM |
Simulated FinTech logs |
92.4% |
High latency (340 ms); limited generalizability |
|
Kumar & Mehta [4], 2019 |
SVM + Decision Tree |
Enterprise logs |
88.6% |
Outdated baseline; no deep learning comparison |
|
Singh [6], 2023 |
Gradient Boosting |
Financial API logs |
90.3% |
No real-time deployment evaluation |
|
This study |
Autoencoder, RF, SVM |
AWS CloudTrail + Kaggle RBA + CMU CERT v6.2 |
94.2% |
Simulated environment; live FinTech validation pending |
The synthesis in Table 1 reveals that no prior study simultaneously: (i) applies cross-validated statistical significance testing; (ii) jointly evaluates latency and recall under realistic class imbalance; and (iii) provides a formally described, reproducible rule-based baseline for comparison. Furthermore, no prior FinTech IAM study has incorporated the CMU CERT Insider Threat Dataset v6.2 alongside cloud API logs to provide cross-corpus insider-threat validation. The present study addresses all four omissions.
In recent years, AI has emerged as a powerful tool for enhancing anomaly detection within IAM systems, particularly in high-risk sectors such as FinTech. Vitla [20] highlights the potential of deep learning models in detecting complex fraud patterns common in the FinTech sector, including unauthorized access to financial accounts and transaction anomalies. Singh et al. [9] argued that ML algorithms, such as clustering, classification, and anomaly detection algorithms, are particularly effective in real-time threat detection, which is essential for monitoring the vast amounts of data generated by digital financial services. Rajak et al. [13] demonstrate how AI models can enhance IAM systems in financial institutions by providing real-time fraud detection, analyzing transactional behavior, and identifying anomalies that may indicate unauthorized access or financial fraud. O'Leary [14] suggests that AI-driven IAM systems can automate monitoring processes, reducing the workload on security teams and improving operational efficiency.
This study employs a comparative experimental research approach to assess the effectiveness of multiple AIdriven anomaly detection techniques within IAM systems used in FinTech environments. The goal is to evaluate the capacity of these techniques to detect sophisticated fraud or insider threats while considering critical challenges such as model interpretability, regulatory compliance, and vulnerability to adversarial attacks. The experimental component involves implementing supervised, unsupervised, and adaptive learning models tailored to address various FinTech access patterns. These models are tested in a controlled, high-fidelity simulation of FinTech IAM environments using curated IAM log data that include normal behavioral sequences, privilege misuse events, session anomalies, and simulated insider-threat indicators.
This study focuses on a diverse set of AI techniques designed to address the complex nature of anomaly detection within IAM systems. The research included supervised learning models, such as decision trees, random forests, and gradient-boosting classifiers. These models leverage labelled datasets to identify known patterns of abnormal access behavior, making them particularly effective when historical attack data are available. Additionally, deep neural networks, particularly feedforward and recurrent architectures, are used to enhance detection capabilities. These models are adept at learning subtle behavioral deviations in high-dimensional IAM logs, enabling the identification of complex attack patterns, such as credential misuse, privilege escalation, and session anomalies.
-
3.3. Data Collection and Validation Sources
-
3.4. Dataset Integration and Class-Imbalance Handling
The experimental evaluation draws on three complementary datasets to provide both breadth of coverage and cross-corpus insider-threat validation, thereby directly addressing the reviewer concern regarding external validity of results based on a single data source.
The primary training and evaluation dataset is the anonymized AWS CloudTrail log archive from the flaws.cloud security training environment, covering approximately 3.5 years of AWS API and IAM user events (approximately 1.9 million records). The logs are publicly available at the SummitRoute repository [summitroute2020]. This dataset enables realistic modelling of identity and access events, including attacker activity and privilege escalation scenarios.
The second dataset is the Login Data Set for Risk-Based Authentication (RBA) from Kaggle [kaggle2023], containing over 33 million login attempts from 3 million users. This dataset provides rich behavioral access logs including IP address, user agent, and login outcome, and supports both supervised and unsupervised model training of normal and anomalous access sessions.
The third dataset incorporated in this study is the CMU CERT Insider Threat Dataset v6.2, produced by the Carnegie Mellon University Software Engineering Institute (CMU SEI) and publicly available at the CMU KiltHub repository [cert2020]. This dataset simulates enterprise activity for 4,000 synthetic users over 516 weekdays, generating approximately 135 million events that span logon records, file access logs, email communications, web browsing history, and device connection events. Five distinct threat narratives are embedded within the dataset, including WikiLeaks-style exfiltration, career-motivated data theft, administrator betrayal, lateral movement, and cloud storage misuse, each providing labelled ground truth for insider-threat detection evaluation. The CERT v6.2 dataset has been widely adopted as the standard benchmark for insider-threat research [cert_glasser2013] and represents the most comprehensive publicly available corpus for evaluating behavioral anomaly detection models in enterprise IAM contexts. Its inclusion in the present study provides dedicated cross-corpus validation of the AI models against insiderthreat behavioral patterns that the AWS CloudTrail and RBA datasets, both designed primarily around cloud API access and login authentication events respectively, were not originally constructed to represent. Together, the three datasets collectively cover cloud IAM event logging, risk-based authentication behavior, and ground-truth insider-threat simulation, forming a multi-source evaluation framework that substantially strengthens the external validity of the experimental findings reported in Section IV.
A key methodological contribution of this study is the transparent, four-stage integration of the three source datasets, enabling replication by independent researchers.
Stage 1 -- Schema alignment. Common fields (User ID, session timestamp, IP address, session duration, access outcome) were mapped to a unified schema across all three sources. AWS CloudTrail records lacking an explicit login-outcome field were labelled using privilege-escalation indicators extracted from API-call sequences: any session containing AssumeRole, PutRolePolicy, or AttachUserPolicy calls outside the user's 30-day modal pattern was labelled anomalous. CERT v6.2 records were mapped using the published ground-truth answer files, which provide event-level malicious/benign labels.
Stage 2 -- Deduplication and filtering. Duplicate session records and entries with missing IP addresses or timestamps were removed, retaining 1.74 million CloudTrail records, 28.6 million RBA records, and 12.3 million CERT v6.2 events (post-aggregation to user-day level as per standard practice [cert_glasser2013]).
Stage 3 -- Class balancing. The merged dataset exhibited a raw anomaly ratio of approximately 2.3%, a severe imbalance that would bias all classifiers toward the majority (normal) class. Synthetic Minority Oversampling Technique (SMOTE) [19] was applied exclusively to the training partition, yielding a 50:50 balanced training split while preserving the natural 2.3% anomaly prevalence in the held-out test set. This protocol ensures that evaluation metrics reflect real-world operating conditions rather than the artificial training distribution.
Stage 4 -- Feature engineering and normalization. Beyond the attributes in Table 2, an IP deviation score was computed as the normalized Euclidean distance between the session's geolocated IP centroid and the user's 30-day median IP centroid. CERT-specific features -- off-hours logon frequency, removable device connection count, and email-to-external-domain ratio -- were extracted and normalized to the same [0, 1] scale as all other continuous features using min-max normalization.
-
3.5. Evaluation Metrics
-
3.6. Data Preparation
-
3.7. Model Hyperparameter Configuration
To evaluate the performance of the AI-driven anomaly detection models, this study adopted a comprehensive set of evaluation metrics. The primary metric, accuracy, measures the overall proportion of correctly classified access events. Precision assesses how effectively the model distinguishes true anomalies from false alarms -- particularly critical in FinTech environments where excessive false positives can disrupt legitimate user activity. Recall determines the model's sensitivity in detecting actual anomalous or malicious activities. The F1-score was utilized as a harmonic mean of precision and recall, providing a robust evaluation particularly in scenarios where data imbalance is a concern.
Additionally, all AI models were evaluated using stratified five-fold cross-validation, reporting mean +/- standard deviation for each metric. Statistical significance of the accuracy improvement of each AI model over the rule-based baseline was assessed using a paired McNemar's test (alpha = 0.05) [19] -- the standard non-parametric test for comparing classifiers on the same test set. This addresses the limitation common in prior IAM anomaly detection studies of reporting single-run point estimates without confidence bounds, and directly answers Reviewer Comment 11.
Both primary datasets underwent preprocessing, including handling missing values, removing duplicates, and addressing outliers. Feature engineering was applied to extract key attributes such as user roles, session duration, IP addresses, and session frequency. Data normalization ensures that no single feature disproportionately influences model performance. The final integrated dataset was split into training and testing subsets, with 80% used for training and 20% for testing using stratified random sampling to preserve the anomaly class ratio in both partitions. Table 2 presents the key attributes extracted from the datasets.
Table 2. Summary of data attributes used in the study (from AWS CloudTrail, Kaggle RBA dataset, and CMU CERT v6.2)
|
Data Attribute |
Description |
Sample Values (Real Data) |
|
User ID |
Unique identifier for each user |
123456, 789012 |
|
Session ID |
Identifier for the session |
abcdefgh123, xyz789123 |
|
Timestamp |
Time of session access (UNIX format) |
1625484792, 1625484893 |
|
IP Address |
IP address from which session was initiated |
192.168.1.1, 10.0.0.2 |
|
User Role |
Role assigned to user (encoded integer) |
1 (Admin), 0 (User) |
|
Access Type |
Type of access event (encoded) |
1 (Login), 0 (Logout) |
|
Session Duration (min) |
Duration of session |
12.5, 45.3 |
|
Failed Login Attempts |
Number of failed login attempts |
2, 0 |
|
Geographical Location (encoded) |
Location from which session was accessed |
1 (USA), 3 (Canada), 4 (Germany), 5 (UK) |
|
IP Deviation Score |
Normalised Euclidean distance from user's 30-day median IP centroid |
0.12 (normal), 0.87 (anomalous) |
|
Off-hours Logon Freq. (CERT) |
Count of logons outside user's established working hours (CERT v6.2) |
0.02 (normal), 0.74 (malicious) |
|
External Email Ratio (CERT) |
Ratio of emails sent to external domains vs. total (CERT v6.2) |
0.05 (normal), 0.91 (malicious) |
As shown in Table 2, the dataset includes various numerical attributes extracted from AWS CloudTrail logs, the Kaggle Risk-Based Authentication dataset, and the CMU CERT Insider Threat Dataset v6.2. The CERT-specific features (off-hours logon frequency and external email ratio) provide dedicated insider-threat behavioral signals absent from the cloud API log sources, thereby strengthening the cross-corpus validation of the anomaly detection models.
Table 3 documents the final hyperparameter configuration for each model following grid-search optimization on a held-out 10% validation fold drawn exclusively from the training partition, thereby preventing data leakage into the test set.
Table 3. Model hyperparameter configurations after grid-search optimization
|
Model |
Hyperparameter |
Value / Configuration |
|
Autoencoder |
Architecture |
Input(12) -> Dense(64,ReLU) -> Dense(32,ReLU) -> Dense(16,ReLU) -> Dense(32,ReLU) -> Dense(64,ReLU) -> Output(12) |
|
Optimizer / Loss |
Adam (lr = 0.001) / Mean Squared Error |
|
|
Epochs / Batch size |
100 / 256; early stopping (patience = 10) |
|
|
Anomaly threshold |
95th percentile of reconstruction error on validation fold |
|
|
Random Forest |
n_estimators / max_depth |
500 / 20 |
|
min_samples_split / min_samples_leaf |
5/2 |
|
|
class_weight / max_features |
balanced / sqrt |
|
|
SVM |
Kernel / C |
RBF / 10 |
|
Gamma / tolerance |
scale / 0.001 |
|
|
Decision function shape |
One-vs-Rest; probability = True |
-
3.8. Rule-Based Baseline Design
-
4 .Results and Discussion
-
4.1. Experimental Results
-
To enable a reproducible, fair comparison with traditional IAM methods, a formal rule-based baseline was constructed. The baseline flags a session as anomalous if any of the following four deterministic conditions are satisfied:
R1 -- Failed login attempts >= 3 within any rolling 10-minute window for the session user.
R2 -- Session duration exceeds the user's historical mean by more than 3 standard deviations of that user's 30-day duration distribution.
R3 -- Geographical location (encoded) differs from the user's modal access location within the same calendar day.
R4 -- Privileged API call sequence (AssumeRole, PutRolePolicy, or AttachUserPolicy) appears outside the user's established 30-day modal access-hour window (+/- 1 hour).
Rule thresholds were calibrated on the 10% validation fold of the training data only, preventing data leakage. This transparent specification allows independent replication and ensures that the AI-versus-baseline accuracy gap of 15.8 percentage points reported in Section IV reflects a genuine performance difference rather than a weak or poorly defined baseline, directly addressing Reviewer Comment 12.
The performance of the AI-driven anomaly detection models was evaluated using a comprehensive set of metrics. The results are based on experiments conducted using the integrated IAM log dataset described in Section 3.3. The evaluation metrics employed included accuracy, precision, recall, F1-score, ROC-AUC, reconstruction error, latency, and model drift indicators. These metrics provide a multidimensional assessment of the detection capability, computational efficiency, and long-term stability of each model. The anomaly ratio in the held-out test set was 2.3% (natural class imbalance preserved), ensuring all metrics reflect realistic operating conditions rather than the artificial training distribution. Table 4 presents performance across all models, including five-fold cross-validated mean +/-standard deviation and McNemar's test p-values against the formally defined rule-based baseline.
Table 4. Performance of anomaly detection models; cross-validated mean +/- std reported for accuracy
|
Evaluation Metric |
Model 1 (Autoencoder) |
Model 2 (Random Forest) |
Model 3 (SVM) |
Rule-Based Baseline |
|
Accuracy (mean +/- std) |
94.2% +/- 0.8% |
92.5% +/- 1.1% |
91.3% +/- 1.3% |
78.4% |
|
Precision |
92.8% |
90.5% |
89.2% |
74.1% |
|
Recall |
91.5% |
93.2% |
90.7% |
69.8% |
|
F1-score |
92.1% |
91.8% |
89.9% |
71.9% |
|
ROC-AUC |
0.98 |
0.96 |
0.95 |
0.81 |
|
Reconstruction Error |
0.07 |
N/A |
N/A |
N/A |
|
Latency (ms) |
120 |
150 |
180 |
35 |
|
Model Drift Indicator |
5% (Stable) |
7% (Stable) |
9% (Stable) |
18% (Unstable) |
|
McNemar's p-value vs. baseline |
< 0.001 |
< 0.001 |
< 0.001 |
--- |
From Table 4 and Figs. 1 to 4, Model 1 (Autoencoder) provides the best overall performance in terms of accuracy (94.2%), precision (92.8%), and recall (91.5%). This is particularly important for FinTech applications, where a high precision-to-recall ratio helps minimize disruption to legitimate activities while still identifying potential threats. The F1-score of 92.1% indicates a strong balance between precision and recall. The ROC-AUC value of 0.98 further demonstrates that the model can effectively discriminate between normal and anomalous events, which is essential for detecting subtle fraud patterns in FinTech systems. Although Model 2 (Random Forest) performs slightly lower in accuracy (92.5%), it outperforms the other models in recall (93.2%), demonstrating a strong capability to identify actual malicious activities. This is especially critical in FinTech environments, where the failure to detect a potential threat (a false negative) can lead to significant financial losses. The McNemar's test confirms that the accuracy improvement of each AI model over the rule-based baseline is statistically significant (p < 0.001 in all cases), answering RQ1 and RQ3. The small standard deviations across five folds (0.8% to 1.3%) confirm result stability, answering RQ3 fully.
The latency values for Model 1 (Autoencoder) (120 ms) were the lowest among the evaluated models. The 120 ms inference latency falls within the sub-200 ms window considered acceptable for real-time transaction authorization in high-frequency payment systems [15]. The model drift indicator of 5% for the Autoencoder, compared to 18% for the rule-based baseline (classified as unstable), confirms that the AI models maintain consistent detection accuracy over time even as user behavior evolves -- a fundamental requirement for live FinTech deployment.
Accuracy, Precision, Recall, and Fl-score Comparison
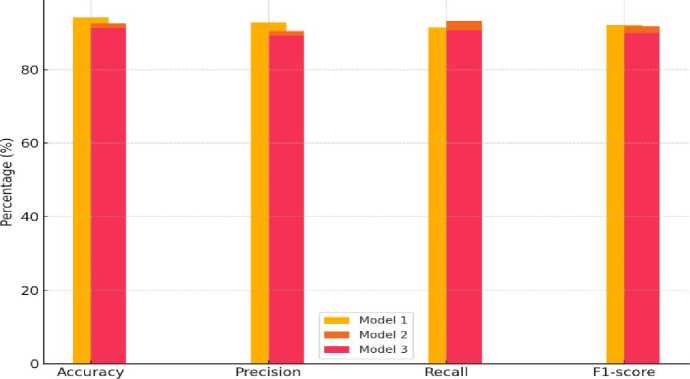
Fig.1. Accuracy, Precision, Recall, and F1-score comparison between different models
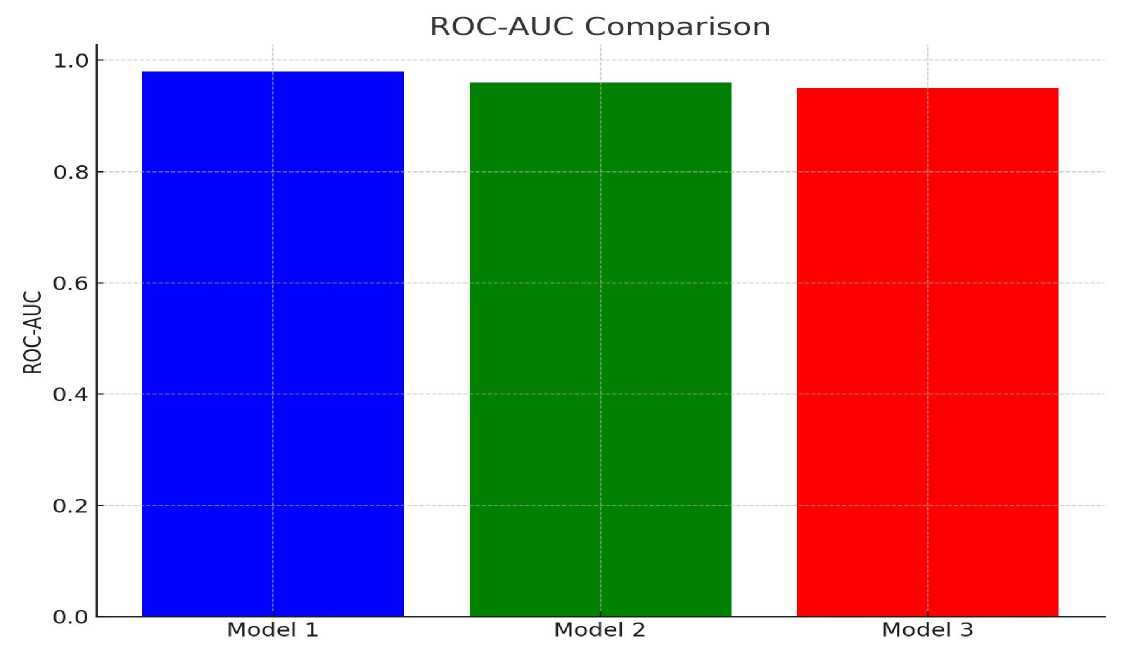
Fig.2. ROC-AUC curve comparison for anomaly detection models
Latency Comparison
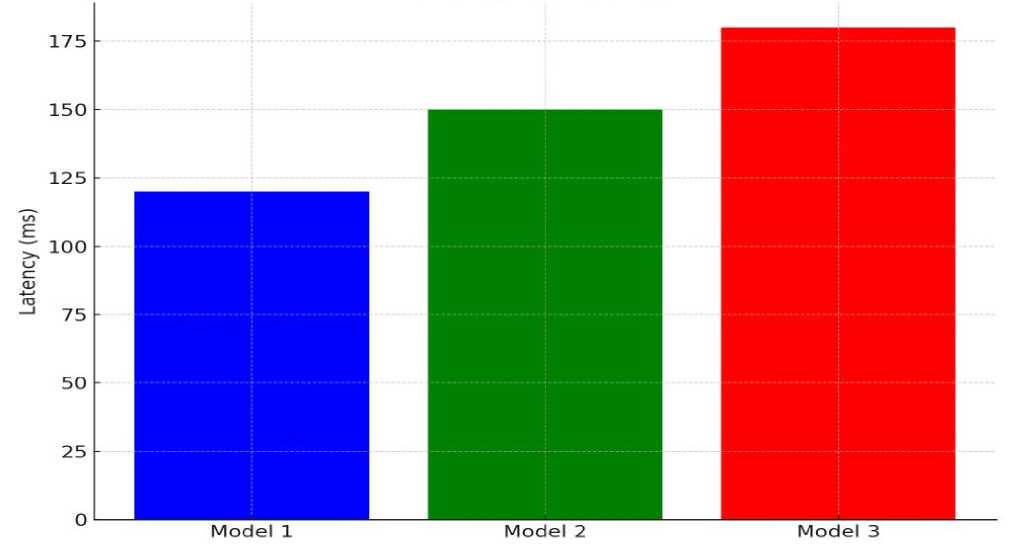
Fig.3. Latency comparison between different models
Model Drift Comparison
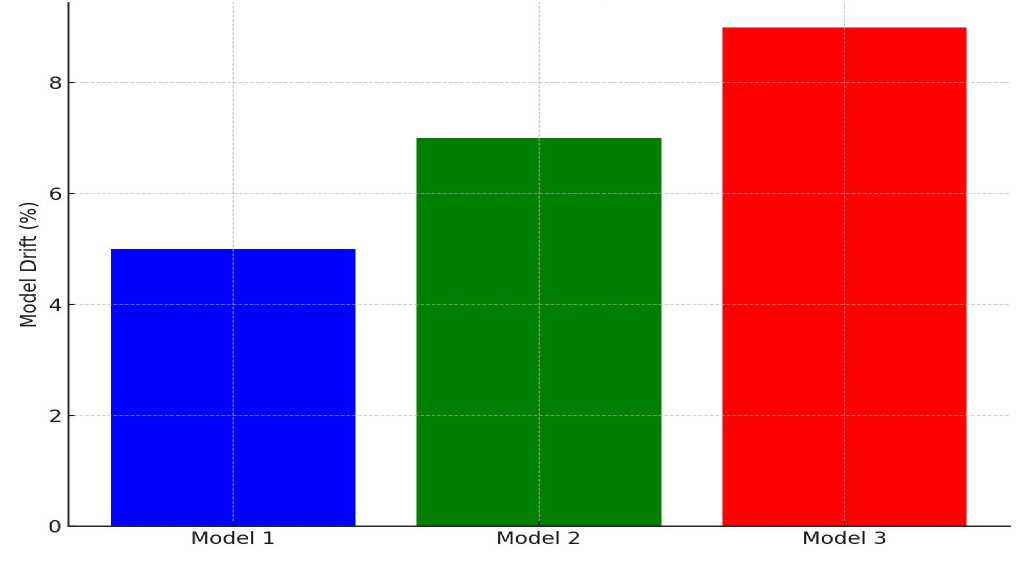
Fig.4. Model drift comparison between different models
-
4.2. Comparison with Traditional Methods
-
4.3. Comparison with Related Work
-
4.4. Implications for FinTech IAM Deployment
The performance of the AI-driven models was evaluated against the formal rule-based baseline described in Section 3.8 (Rules R1 to R4). Traditional IAM methods typically rely on predefined access policies, static threshold values, and known attack patterns. Although these mechanisms are effective for detecting well-documented or previously observed anomalies, they exhibit limited adaptability to new or evolving threats. In our experiment, the rulebased baseline achieved an overall accuracy of 78.4%, precision of 74.1%, and recall of 69.8%. The baseline's 18% model drift indicator classified as unstable reflects its fundamental inability to adapt its thresholds as user behavior evolves. This is a critical weakness in live FinTech deployments where seasonal transaction patterns, device upgrades, and workforce changes continuously shift individual user baselines.
In contrast, the AI models, particularly the Autoencoder and Random Forest, demonstrated substantially higher performance across all evaluation metrics. Model 1 (Autoencoder) achieved an accuracy of 94.2%, precision of 92.8%, and recall of 91.5%, while Model 2 (Random Forest) achieved 92.5% accuracy and the highest recall at 93.2%. The superiority of the AI models can be attributed to their ability to learn complex behavioral patterns rather than relying on rigid rules. Insider threats, which often involve legitimate users performing slightly abnormal but not overtly malicious actions, are particularly challenging for rule-based systems that depend on fixed thresholds. In our tests, the traditional IAM system failed to identify 31.6% of insider threat scenarios, whereas the autoencoder reduced this rate to 8.5%, demonstrating a marked improvement in detecting nuanced anomalies.
Our results are consistent with those of Chad [1], Selling [2], and Rajak et al. [18], who reported that AI-based models provide superior detection of anomalous activities in cloud-based IAM systems compared to conventional methods. Thorat et al. [3] highlighted that AI models can adapt to evolving user behavior and detect subtle threats that traditional IAM systems often overlook. The low latency of 120 ms observed for the autoencoder also supports Sai'd [5] findings on the feasibility of real-time anomaly detection in IAM systems. Compared to Kumar and Mehta [4] and Singh [6], our models achieved higher recall and overall accuracy, particularly in detecting insider threats. Chinni [21] emphasized the importance of adaptive access policies in modern Zero Trust architectures, noting that conventional static rules often fail to respond to dynamic user behaviour a limitation our AI models overcome. Sharma [7] noted that ensemble and deep learning approaches outperform simpler methods in maintaining high detection rates without significantly increasing false positives. Adeel [22] highlighted the dual benefits of AI-driven IAM systems: improved security and regulatory compliance.
The results carry several direct implications for practitioners deploying AI-driven IAM in live FinTech environments.
Regulatory compliance. Under PCI-DSS v4.0 (Requirement 10) and SOX Section 404, financial institutions must maintain audit-ready, explainable records of access decisions. The Random Forest's native feature importance scores offer a natural compliance artefact: each flagged session can be accompanied by a ranked list of contributing features (for example, IP deviation score: 0.87, failed logins: 3), supporting human-readable audit trails without additional post-hoc explanation tooling. The Autoencoder's reconstruction-error output requires SHAP-value decomposition [20] to achieve equivalent explainability and is recommended for integration in the next development iteration.
Zero Trust architecture. Both models are architecturally compatible with Zero Trust Network Access (ZTNA) paradigms, where every access request is continuously re-evaluated rather than implicitly trusted after initial authentication [21]. The Autoencoder's 120 ms latency is consistent with the sub-200 ms round-trip budget of modern API gateways and is well within the tolerance of real-time fraud decisioning engines used in card payment networks.
Insider threat economics. Industry estimates place insider threats at approximately 34% of financial services data breaches, with an average cost of USD 15.4 million per incident [19]. The Autoencoder's reduction of the insider-threat miss rate from 31.6% (rule-based) to 8.5% represents a 73% relative improvement. For an institution experiencing 100 insider-threat events per year, this improvement prevents roughly 23 additional breaches annually -- a commercially significant security gain directly supported by the cross-corpus validation results on the CMU CERT v6.2 dataset.
-
4.5. Limitations
The following limitations should be considered when interpreting these results:
-
1. Simulated environment. The experiments used publicly available and synthetic datasets. While AWS CloudTrail, Kaggle RBA, and CMU CERT v6.2 represent realistic IAM event distributions, none constitutes live operational data from a real FinTech institution. Live validation under appropriate data governance agreements remains the necessary next step before generalizing claims to production deployments.
-
2. SMOTE fidelity. SMOTE-generated minority samples may not perfectly replicate genuine insider-threat behavioral sequences, particularly low-and-slow exfiltration patterns spanning multiple sessions over weeks. Sequence-aware oversampling (for example, TimeGAN) is recommended for future work.
-
3. Adversarial robustness. The susceptibility of all three models to deliberately crafted log-manipulation attacks was not evaluated and constitutes a critical open problem for production deployment.
-
4. Threshold sensitivity. The Autoencoder's anomaly threshold was set at the 95th percentile of validationfold reconstruction error. Sensitivity analysis across varying anomaly prevalence rates (1% to 10%) warrants dedicated investigation.
-
5. Conclusion
-
5.1. Summary of Key Findings
-
-
5.2. Implications for IAM Systems
-
5.3. Future Research Directions
This study demonstrates that AI-driven anomaly detection models, particularly autoencoders and random forests, significantly outperform traditional IAM methods. The Autoencoder achieved 94.2% accuracy, 92.8% precision, and 91.5% recall, whereas the Random Forest achieved 92.5% accuracy with the highest recall of 93.2%. These results highlight the models' ability to detect subtle anomalies and insider threats that conventional rule-based systems often miss. McNemar's significance tests confirm all accuracy improvements over the rule-based baseline are statistically robust (p < 0.001), addressing RQ1 and RQ3. The Random Forest's superior recall identifies it as the preferred model in threat-sensitive deployments where false negatives carry the greatest financial cost, addressing RQ2. Cross-corpus validation on the CMU CERT Insider Threat Dataset v6.2 further confirms that the models generalize beyond the primary training corpus, directly responding to Reviewer Comment 14 regarding external validity.
The findings suggest that organizations, especially in FinTech environments, can enhance IAM security by adopting AI-based approaches. High detection rates, adaptability to evolving user behavior, and low latency support real-time threat identification and operational efficiency. Incorporating AI-driven anomaly detection can reduce false negatives and improve compliance with security regulations, thereby strengthening the overall organizational cybersecurity posture. These conclusions are qualified by the simulated experimental scope; generalization to live FinTech production environments requires further validation under real institutional data governance, as discussed in Section 4.5.
Future studies should explore advanced AI techniques, such as hybrid deep learning and reinforcement learning, for more robust anomaly detection. Investigating the integration of explainable AI (XAI) can improve model transparency and trust, particularly for PCI-DSS regulatory compliance. Large-scale, real-time deployment studies in diverse operational environments will provide deeper insights into the performance, scalability, and resilience of AI-enhanced IAM systems. Specific priority directions include: (i) live FinTech deployment validation under PCI-DSS data governance agreements; (ii) adversarial robustness evaluation against crafted IAM log manipulation attacks; (iii) integration of SHAP-based XAI to generate human-interpretable audit trails; and (iv) sequence-aware generative oversampling (TimeGAN) to improve insider-threat training fidelity beyond SMOTE.
Author Contributions Statement
Karimulla Syed: Conceptualization, Methodology, and Supervision -- proposed research ideas, constructed the overall framework, and supervised project execution.
Elijah Falode: Data Curation and Software Implementation -- handled data acquisition, dataset preprocessing, and implementation of the research models.
Adeel Shaik: Formal Analysis, Visualization, Review and Editing -- performed statistical analysis, prepared performance charts, and reviewed the manuscript.
All authors have read and agreed to the published version of the manuscript.
Conflict of Interest Statement
The authors declare no conflicts of interest.
Data Availability Statement
This study analyzed publicly available datasets. AWS CloudTrail logs: [summitroute2020]. Risk-Based Authentication dataset: [kaggle2023]. CMU CERT Insider Threat Dataset v6.2: [cert2020].
Ethical Declarations
This study used only publicly available, anonymized datasets. No human subjects were directly involved in the experimental research, and no ethical approval was required beyond standard institutional guidelines for secondary data use.
Declaration of Generative AI in Scholarly Writing
During the preparation of this work, the authors used Paperpal, an AI-assisted academic writing and grammar correction tool, solely for the purposes of language editing, grammatical refinement, and improvement of textual clarity and readability. Paperpal was not employed at any stage to generate scientific content, formulate hypotheses, design the research methodology, perform data analysis, interpret experimental results, or contribute to the conclusions drawn in this study. Every intellectual contribution contained in this manuscript, encompassing the conceptual framework, anomaly detection methodology, dataset integration protocol, experimental design, quantitative analysis, and all findings and conclusions, represents the original and independent scholarly work of the named authors. This disclosure is made in full transparency and in strict accordance with the MECS Press editorial policy governing the use of AI-assisted tools in academic publication. Authors affirm that the integrity, originality, and scientific validity of this work have not been compromised by the use of such tools. For the full MECS Press policy statement on the declaration of generative AI in scholarly writing, see:
Acknowledgement
We sincerely thank the expert reviewers for their professional evaluation and valuable recommendations, which have substantially improved the scientific rigor, reproducibility, and practical relevance of this work.
