AI Scheduling with Contextual Transformers

Author: Oleksandra Bulgakova, Viacheslav Zosimov, Victor Perederyi
Journal: International Journal of Intelligent Systems and Applications @ijisa
Article in issue: 4 vol.17, 2025.
Free access
This paper presents a comprehensive framework for intelligent and personalized task scheduling based on Transformer architectures and contextual-behavioral feature modeling. The proposed system processes sequences of user activity enriched with temporal, spatial, and behavioral information to generate structured task representations. Each predicted task includes six key attributes: task type, execution time window, estimated duration, execution context, confidence score, and priority level. By leveraging Transformer encoders, the model effectively captures long-range temporal dependencies while enabling parallel processing, which significantly improves both scalability and responsiveness compared to recurrent approaches. The system is designed to support real-time adaptation by integrating diverse data sources such as device activity, location, calendar status, and behavioral metrics. A modular architecture enables input encoding, multi-head self-attention, and global behavior summarization for downstream task generation. Experimental evaluation using artificially generated user data illustrates the model’s ability to maintain high accuracy in task type and timing prediction, with consistent performance under varying contextual conditions. The proposed approach is applicable in domains such as digital productivity, cognitive workload balancing, and proactive time management, where adaptive and interpretable planning is essential.
Adaptive Scheduling, Transformer Model, Behavioral Sequence Modeling, Time Management, Productivity Optimization
Short address: https://sciup.org/15019923
IDR: 15019923 | DOI: 10.5815/ijisa.2025.04.05
Text of the scientific article AI Scheduling with Contextual Transformers
In the digital environment, peoples are faced with an overwhelming number of tasks, notifications, and timesensitive commitments, often leading to cognitive overload and inefficiencies in daily planning. Although various digital time management tools exist, most of them are static and fail to adapt to users’ evolving contexts and behavior. These tools typically disregard crucial dynamic parameters such as location, productivity, shifting priorities, or mental and physical energy levels. As a result, schedules generated by such systems often require frequent manual adjustments and offer limited personalization.
Recent research has increasingly focused on intelligent time management solutions leveraging artificial intelligence. Notable efforts include systems that generate activity templates based on behavior-derived patterns in workplace settings [1], the incorporation of psychological and emotional factors into productivity analysis [2,3], and the use of AI in project management and automation [4-6,8]. Despite these advancements, many existing models still rely on basic algorithms or traditional recurrent neural networks (LSTM, GRU), which are often inadequate in capturing long-range temporal dependencies, integrating diverse data streams, or scaling efficiently for real-time applications.
This paper introduces an adaptive task scheduling framework that utilizes Transformer-based architectures to model user behavior in context-aware environments. Transformers, originally developed for natural language processing [7], are particularly suited for sequence modeling due to their multi-head attention mechanism, which captures global dependencies across long sequences in parallel. This makes them an effective solution for modeling complex behavioral and contextual patterns without the computational drawbacks of recurrent models.
A distinctive feature of our approach is its ability to personalize schedules dynamically based on real-time contextual data. The system processes multi-source inputs, including temporal markers, location, device status, behavioral metrics, and task history, to generate structured task recommendations. Each output includes six core attributes: task type, time window, estimated duration, execution context, confidence score, and priority level.
The goal is not only to improve the accuracy and adaptability of planning but also to enhance user experience by reducing manual effort and providing interpretable, context-sensitive task suggestions.
This paper is structured as follows: section 2 presents a review of the state of the art methods. Afterwards, section 3 presents a little description of the proposed Transformer-based scheduling methodology, including input encoding, model design, and task generation components. We analyze the simulation-based experiments results in section 4. In final, section 5 presents a conclusion of the paper.
2. Related Works
In this section, we review the state-of-the-art methods in intelligent task scheduling. These methods can be broadly divided into two categories: traditional approaches based on handcrafted rules or shallow machine learning algorithms, and deep learning-based approaches that extract temporal and contextual patterns from user behavior. We focus on recent developments in the second category, particularly on sequence modeling techniques such as RNNs, LSTMs, and Transformer-based architectures, and analyze their suitability for personalized scheduling in dynamic environments.
Intelligent task scheduling has evolved significantly, progressing from rule-based approaches to AI-driven adaptive systems. Early digital time management tools were grounded in expert-defined rules, static templates, and logical filters. These systems generated schedules based on fixed conditions such as the day of the week or task type [1,4,5], offering little adaptability and no mechanism for learning from user behavior over time.
To introduce automation, classical machine learning models such as decision trees, linear regression, and support vector machines were applied. While these approaches could handle a limited number of features, they lacked the capacity to detect long-term temporal dependencies or incorporate multi-source user context [13].
A notable improvement came with the adoption of recurrent neural networks and their variants such as LSTM and GRU [9-11,14]. These models made it possible to learn from sequences of user activity and predict upcoming tasks based on interaction history. However, RNN-based systems face inherent limitations: they struggle with long input sequences due to vanishing or exploding gradients, require strictly sequential data processing which reduces scalability, and are constrained in their ability to integrate diverse context sources (geolocation, device state, or energy levels).
To overcome these limitations, researchers have turned to Transformer architectures, originally developed for natural language processing tasks [12,17]. Transformers use a multi-head self-attention mechanism that captures dependencies between all elements in a sequence, regardless of their position, and allows for parallel processing making them highly suitable for time-sensitive behavioral modeling.
Advanced Transformer variants such as Informer [15] have shown strong performance in long-range forecasting, including time-series and scheduling tasks, while reducing computational complexity. These models are particularly effective in processing high-dimensional sequences with irregular or noisy input, a common challenge in real-world scheduling.
Several studies have proposed adaptive scheduling methods that combine user context, behavioral trends, and system feedback [2,3,16]. Such works emphasize the role of emotional states, cognitive load, and behavioral history in optimizing productivity. However, most existing models rely either on limited feature sets or non-adaptive architectures that do not support real-time personalization.
Furthermore, incorporating context awareness is essential for meaningful personalization. According to [13], context-aware systems should dynamically adjust behavior based on location, device state, availability, and user preferences. Nevertheless, many scheduling systems treat context as static filters rather than as dynamic, learnable components.
To address the identified limitations, we propose a scheduling architecture based on the Transformer model, designed for behavioral task planning. Our approach integrates sequential user behavior, temporal dynamics, spatial context, and task-specific metadata into a unified representation, enabling the generation of personalized and adaptive task schedules.
Our work addresses these gaps by proposing a Transformer-based architecture that integrates behavioral sequences, temporal and spatial context, and task metadata to generate personalized schedules. Unlike traditional or RNN-based methods, our system supports scalable, interpretable, and context-aware task planning adaptable to real-time user states.
3. Proposed Approach 3.1. Data Description
Let there be a historical sequence of user activity events over the past T steps (days or individual task executions), denoted as:
E = {e i , e2, ^,eT}
Each ev ent e T is a feature vector composed of four main groups of attributes e T = [ A t , B t , C t , D t ], where Ate RdA, t = 1. .5 its task-related features:
-
A 1 – textual task description (title);
-
A 2 – category/type (work, rest, exercise…);
-
A 3 – task duration (in minutes);
-
A 4 – task importance (user-defined priority, scale 1–5);
-
A 5 – is completed (binary: 1 if completed, 0 otherwise).
Bte RdB - temporal features :
-
B 1 – start time;
-
B 2 – day of week (0–6);
-
B 3 – time of day (morning, afternoon, evening, night);
-
B 4 – is weekend (binary);
-
B 5 – recurrence flag (binary: whether it is a recurring task).
Cte Rdc - contextual features :
-
C 1 – location (home, office, transit);
-
C 2 – device activity (screen on, idle, in motion);
-
C 3 – calendar availability (busy or free);
-
C 4 – interruptions count (number of interruptions during the task);
-
C 5 – weather code (sunny, rainy,…).
Dte Rd ° - behavioral metrics :
-
D 1 – time avg (average focus duration in minutes)
-
D 2 – task completion rate (percentage of completed tasks);
-
D 3 – deviation from plan (average delay);
-
D 4 – energy profile (vector of productivity levels by hour);
-
D 5 – break frequency (average number of breaks per day).
The full input matrix is:
X = [e i , е 2 ,.,е т ] e RTxd
where d = dA + dB + dc + dD is the total dimensionality of the embedded and encoded feature vector. The model aims to generate a sequence of predicted tasks for the next scheduling window Z = {z1, z2,... , zN}. Each predicted task zi,i = 1...N includes the following components: z^1 - task type or title, z^2 - predicted time window [start ;, ], z^2 -expected task duration, z ^ 2 - recommended execution context (e.g., location, device state), z ^ 2 - confidence score, z ( 2 – optional priority score. The problem can be formulated as a multi-objective forecasting and sequence generation task:
f' RT^d ^ R Nxm
Where the function f is implemented by a transformer-based neural network model trained on sequential and contextual behavioral data. The model captures temporal dependencies and real-time context to output personalized schedule recommendations that adapt to individual user dynamics. The example of predicted output you can see in Table 1.
Table 1. The example of predicted output data
|
Task title , z ^ 1 |
Time window , z ( 2 |
Duration , z ^ 2 |
Context , zf2 |
Confidence , z (s2 |
Priority , z (62 |
|
morning stand-up meeting |
09:00 – 09:30 |
30 min |
office |
0.92 |
high |
|
outdoor walk |
16:00 – 16:45 |
45 min |
outdoors |
0.87 |
medium |
|
respond to email messages |
18:00 – 18:30 |
30 min |
home |
0.95 |
high |
3.2. Methodology
To feed the user event sequence (2) into the Transformer encoder, each event vector e t undergoes a fixed and clearly defined encoding procedure. The algorithm uses a consistent transformation pipeline for different feature types, chosen based on implementation requirements. The A 1 field is embedded using a pretrained fastText model (frozen during training). The resulting vector of dimension d text = 100 represents the semantic content of the task:
A l = fastText(A l )eR100
All categorical variables are embedded using trainable embedding layers of fixed dimension d cat = 16, including A 2 , C 1 , C 2 , C 3 , B 3 . Each categorical value is converted into a dense vector via its respective embedding layer. Continuous numerical features, such as A 3 , A 4 , C 4 , D 1 , D 2 , D 3 , D 5 are standardized using fixed normalization parameters:
х-и. x =-- а
where µ and σ are computed from the training set. Time-of-day values are encoded using sinusoidal time encoding:
B l = [sin(2n • t/24),cos(2jf • t/24)]
D 4 given as a 24-dimensional vector (one per hour), is projected with a linear layer to a fixed-size vector of 32 dimensions:
D ^ = WproJD4 + b
All encoded components from steps 1 to 5 are concatenated into a unified vector of fixed length d=256
et = Concat(A l , A l ,..., Di) e RTx2S6
The complete input sequence becomes:
x = [e r ,e i..... е т ] e r"-"-
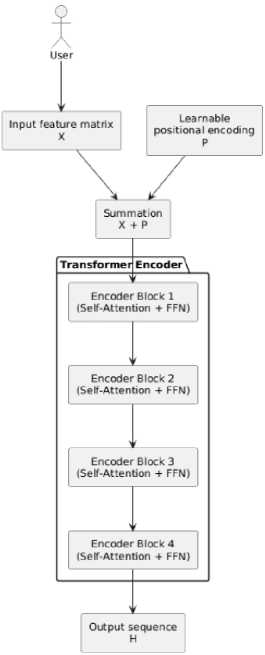
Fig.1. Transformer encoder architecture
The Fig.1 illustrates the internal structure of the Transformer encoder used in the proposed adaptive planning system. The model receives an input sequence of feature vectors X , representing the user's historical events. First, learnable positional encodings P are added to the input vectors to preserve the order of events within the sequence. The result X + P is then passed to a stack of four identical encoder blocks.
Each encoder block consists of a multi-head self-attention mechanism that computes attention weights between all elements in the sequence; a feed-forward neural network that transforms the representations; and residual connections with layer normalization, which improve learning stability.
The encoder produces an output matrix H , where each vector h t contains a contextual representation of event e t , enriched with global sequence information.
The resulting representations H = [h 1 ,h2,.... ,hT] are high-level contextual vectors that encode the user’s behavioral history in a format suitable for predicting future actions. Each vector ℎ t contains not only the information about the corresponding input event e t , but also the influence of all other events in the sequence both recent and distant. Thanks to the self-attention mechanism, the model can determine which past events are most relevant for forecasting.
These contextual embeddings are then passed to the next stage – the Task Generation Module, where the encoder output is transformed into explicit recommendations: task types, optimal time windows, durations, expected execution contexts, and priorities.
The task generation module is responsible for converting the output representations H , produced by the Transformer encoder, into a personalized set of predicted tasks Z = {z1, z2,... , zN] for the upcoming scheduling interval. Each task is defined by six parameters, N =6. The module first aggregates the encoder outputs using a global attention mechanism. Let W q , W k , and W v denote the trainable projection matrices for the query, key, and value representations, respectively. Then the global vector is computed as:
a
= softmax (^(^ ), hglobal
The resulting global vector h global ummarizes the user's recent behavior and serves as input for task generation. For each task i , a prediction vector zl is produced as follows. The task type is predicted with a softmax classifier:
z[ 1 = arg-max
(softmax(W1h g l obai + b i ))
The task start and end times are generated using a regression head:
zl = [tstart , tend ] = W2hglobal + ^ 2
The duration can be either predicted independently:
z [3 = W3hgiobal + b3
or derived as the difference tgnd — tlstart, depending on the implementation. The expected execution context is also predicted using a softmax classifier:
z [4 = arg-max
(softmax(W4h giobai +Ь^
The model estimates the likelihood of task relevance through a sigmoid activation:
2 (5 = a(Wsh giobai + b s )
The predicted priority is generated via an additional softmax output:
z ( 6 = arg-max
(softmax(W6h giobai + b))
Each task zl is generated independently but is based on the shared global representation h global , which ensures overall coherence and personalization. The generation module transforms abstract behavioral embeddings into explicit, interpretable scheduling elements, enabling a personalized and explainable planning experience.
The proposed intelligent planning system is trained on historical user data, which includes sequences of completed tasks, temporal markers, execution contexts, and behavioral metrics. Training is conducted in a supervised learning setting with a multi-output architecture that combines regression and classification objectives.
The model is optimized using a composite loss function that integrates several components. Classification targets such as task type, execution context, and priority are optimized with cross-entropy loss. Regression targets such as the time window and task duration are optimized using mean squared error. The confidence score, reflecting the predicted relevance of a task, is trained via binary logistic loss. The total loss function is a weighted sum of all components. Following initial training on large-scale historical datasets, the system supports personalization through feedback-based adaptation. All user interactions including acceptance, rejection, rescheduling, or editing of tasks are logged and can be utilized for model fine-tuning either on-device or within a secure environment.
Adaptation may be performed in batch mode (e.g., periodic local weight updates) or in an online setting, for example by fine-tuning the final layers or applying gradient-based refinement of predictions. This allows the model to retain its generalization capability while improving responsiveness to individual patterns. The architecture is also compatible with active learning techniques, whereby the system can request user input to refine preference modeling.
4. Experiments
To preliminarily validate the functionality of the proposed algorithm, we conducted a series of experiments using artificially generated user data simulating hypothetical users with varying patterns of activity. This approach allowed us to test the model architecture in a fully controlled setting, verify its robustness to noise, and confirm its ability to learn behavioral dependencies even without prior exposure to real-world datasets.
-
4.1. Databases and Evaluation Metrics
-
4.2. Results
The artificial data consisted of task sequences of length T = 100 , with each task comprising structured features such as task type, start time, duration, importance, execution context, and behavioral attributes. The Table 2 presents a fragment of input data.
Table 2. The fragment of input data
|
A 1 |
A 2 |
A 3 |
A 4 |
A 5 |
B 1 |
… |
C 1 |
… |
D 1 |
.. |
D 3 |
D 4 |
|
email check |
work |
30 |
4 |
1 |
08:30 |
… |
home |
… |
25 |
… |
5 |
0.9 |
|
workout |
sport |
45 |
3 |
1 |
10:00 |
… |
gym |
… |
40 |
… |
0 |
0.8 |
|
team sync |
meetig |
60 |
5 |
1 |
11:30 |
… |
office |
… |
50 |
… |
10 |
0.7 |
|
… |
… |
… |
||||||||||
|
lunch |
rest |
60 |
2 |
1 |
13:00 |
… |
cafe |
… |
20 |
… |
0 |
0.6 |
|
code review |
work |
90 |
5 |
0 |
14:30 |
… |
office |
… |
55 |
… |
15 |
0.85 |
|
… |
… |
… |
The model generated a personalized schedule for the upcoming time window. Since the structure of the input data and reference outputs were predefined, predictions could be directly compared to the ground truth based on task type, start time, duration, and execution context in Table 3.
Table 3. The fragment of output data
|
z C1) zi |
z (2 zi |
z (3 ) zi |
A (4) zi |
z (5) zi |
z (6) zi |
|
work |
08:30 – 09:00 |
30 |
home |
0.92 |
medium |
|
sport |
10:00 – 10:45 |
45 |
gym |
0.89 |
medium |
|
meetig |
11:30 – 12:30 |
60 |
office |
0.93 |
high |
|
rest |
13:00 – 14:00 |
60 |
cafe |
0.88 |
low |
|
work |
14:30 – 16:00 |
90 |
office |
0.85 |
high |
To better understand how the model performs in practice, we analyzed where it tends to make mistakes, Table4. Overall, the system predicted task types, timing, and context very accurately, almost all scheduled tasks matched the input data in these aspects. However, we noticed that the model sometimes made different decisions about task priority. In about 15% of the cases, it marked important tasks as only “medium” priority. This could be due to how the model interprets the broader situation, such as task congestion or time availability.
We also looked at how well the model predicts how long tasks will take and when they should start. On average, the timing was very close to the expected values, with only minor differences, just a few minutes off, which is acceptable in most real-life planning scenarios.
We checked how confident the model was in its predictions. Most tasks had high confidence scores, showing that the model was generally sure about its suggestions.
These results show that the system works well in structured environments with clear behavior patterns. The few mistakes it makes seem reasonable and are likely related to the limitations of synthetic data. As a next step, we plan to test the model on real-world user data to evaluate its adaptability to natural behavior patterns, unexpected task types, and incomplete or noisy input. This will allow us to assess the model’s performance in realistic conditions and improve its personalization mechanism
Table 4. Quantitative error analysis on simulated data
|
Metric |
Value |
|
Task type prediction accuracy |
98% |
|
Priority prediction accuracy |
85% 15% tasks downgraded to “medium” priority |
|
MAE (task duration) |
3.1 min |
|
MAE (time window start/end) |
4.4 min |
|
Mean confidence score |
0.894 |
|
Standard deviation |
0.03 |
5. Conclusions
This paper introduced an intelligent task planning architecture based on a Transformer encoder and contextual-behavioral feature modeling. The proposed system is designed to generate personalized task recommendations by encoding user activity sequences and dynamically predicting structured task vectors that include type, time window, duration, context, confidence, and priority.
To validate the model’s functionality, we conducted a controlled experiment on artificially generated data. This allowed us to evaluate the behavior of the model in a noise-free environment and test its ability to detect patterns in synthetic user behavior. The model achieved high accuracy in task type prediction and timing estimation, correctly aligning most predicted outputs with the corresponding input events. Some variation was observed in priority predictions, which may reflect the model's consideration of additional contextual signals beyond raw importance scores.
The findings demonstrate that the model architecture is capable of producing interpretable and contextually appropriate task suggestions based on behavioral sequences. However, the results also highlight that performance on artificial data cannot be fully generalized to real-world scenarios. In real settings, the presence of behavioral noise, unpredictability, and personal variability necessitates continuous adaptation and learning from feedback.
In future work, we plan to deploy the proposed model in real-world environments by collecting behavioral data from users through mobile applications and wearable devices. This will enable evaluation of the system’s adaptability to natural, unstructured behavior patterns. To address challenges related to incomplete or noisy data, we will implement imputation strategies and assess model stability under uncertainty.
