Алгоритм поиска дубликатов изображений на дисковых хранилищах

Бесплатный доступ
В статье представлен алгоритм поиска повторяющихся изображений с учетом небольших изменений в структуре файла. Рассмотрена оптимальная структура хранения данных для поиска.
Алгоритм, анализ данных, хеш, исходная сумма, дубликаты
Короткий адрес: https://sciup.org/140277542
IDR: 140277542
Algorithm for searching duplexes of images on disk storage
The article presents an algorithm for finding duplicate images, taking into account small changes in the file structure. The optimal structure of data storage for search is considered.
Текст научной статьи Алгоритм поиска дубликатов изображений на дисковых хранилищах
Введение. Файловые хранилища больших объемов данных сталкиваются с проблемой хранения идентичных файлов. Это может возникнуть в случае многократной загрузки пользователями на веб-портал одного файла под разными именами. Эти файлы могут иметь до нескольких сотен и тысяч повторов, что приводит к деградации коэффициента эффективности использования дискового пространства.
Цель исследования. Необходимо определить наиболее эффективный алгоритм поиска дубликатов файлов.
Последовательное сравнение. В общем случае все файлы хранятся в одном каталоге или подкаталогах с полными правами доступа. Для поиска дубликатов наивным методом «каждого с каждым» потребуется огромные затраты времени. В среднем для N файлов количество вариантов можно определить по формуле:
CN
N
T
При количестве файлов N>10000 и времени на обработку каждой пары 50мс потребовалось бы около 695 часов на обработку. Такое время является недопустимым.
Первой оптимизацией может являться сравнение групп файлов по их размеру, для чего потребуется составление таблицы содержащих в качестве ключа размер файла в байтах, а в качестве значения – список имен файлов этого размера. Последующий поиск дубликатов производился бы в группах, содержащих 2 и более элементов. Что сократит время поиска в среднем на 10%.
Хеширование. Рассмотрим оптимизацию структуры данных хранения файлов. Для каждого файла найдем значение хеша. Рассчитаем 32х-битную контрольную сумму CRC-32 для всего массива. Контрольная сумма представляет собой число, полученное последовательным суммированием байт файла и применением операции XOR. В итоге мы получим хеш-таблицу для нашего хранилища. Поиск в таблице аналогичен поиску в группах, поэтому необходимо изменить структуру хранения. Для этого построим суффиксное дерево, где каждый узел будет хранить в себе один байт контрольной суммы. Суффиксное дерево позволит найти элемент в дереве за время O(|S|), где S- длина строки [1]. Пример построения приведен на рисунке 1.
ninuuuuul lununndSm
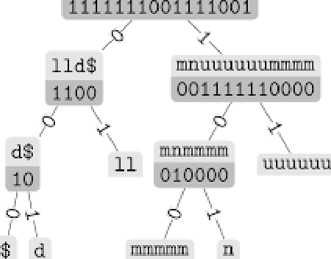
Рис. 1 Суффиксное дерево
Для каждого файла, применим функцию нахождения контрольной суммы d = {SRC(Fl )| i 6 [1..N]}, если, начиная с корня не будет найдено следующего байта, то создаем узел равный необходимому байту. По окончанию записи контрольной суммы в последний узел записываются параметры объекта, в нашем случае имя файла. В результате будет получено суффиксное дерево, где в конечных узлах содержатся имена идентичных файлов. Последним шагом алгоритма остается итеративный проход по каждому из узлов и определение числе элементов в нем. Дубликатом признаются узлы, содержащие 2 и более имен. Данный алгоритм работает не за линейное время и позволит намного эффективнее избавиться от точных копий файлов.
Перцептивное хеширование. Рассмотрим случай, при котором хранилище объектов - хостинг изображений, которые могут незначительно отличаться по разным характеристикам: яркость, размер, наличие небольших искажений, водяные знаки как на рисунке 2.

Рис. 2 Незначительно отличающиеся изображения
Принцип работы перцептивного хеша заключается в том, что два объекта различных в яркости, размере или прочих деталям, но обладающие одинаковыми базовыми свойствами совпадут по хешу. Для этого используется следующее свойство изображений: высокие частоты обеспечивают детализацию, а низкие – структуру [2]. Для построения перцептивного хеша выполним следующие действия:
-
1) Сжатие изображения. Чтобы убрать высокие частоты необходимо уменьшить изображение, установим размер 8х8 пикселей. Результат показан
на рисунке 3.
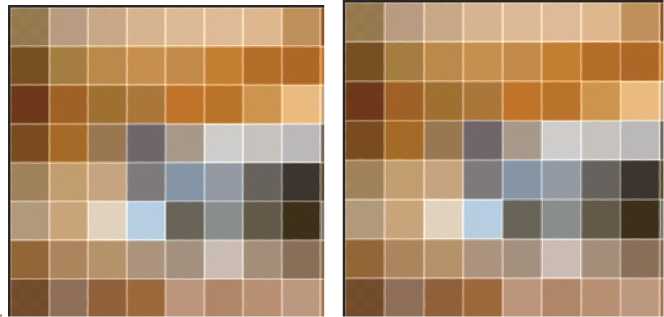
Рис. 3 Сжатые изображения
-
2) Обесцвечивание. Каждый пиксель из полученных определяется
конфигурацией RGB, а значит хеш по размеру будет равен 64*3=512 пикселей. Переведем изображение в градации серого и сократим хеш втрое, до 64.
-
3) Вычисление среднего. Суммируем все значения оставшихся пикселей и поделим на их число, в итоге получим порог avg для сравнения.
-
4) Бинаризация. Для каждого из пикселей р установим значение 1 или 0, по принципу:
(1, р < avg
{0, р > avg
Результат этого шага показан на рисунке 4.
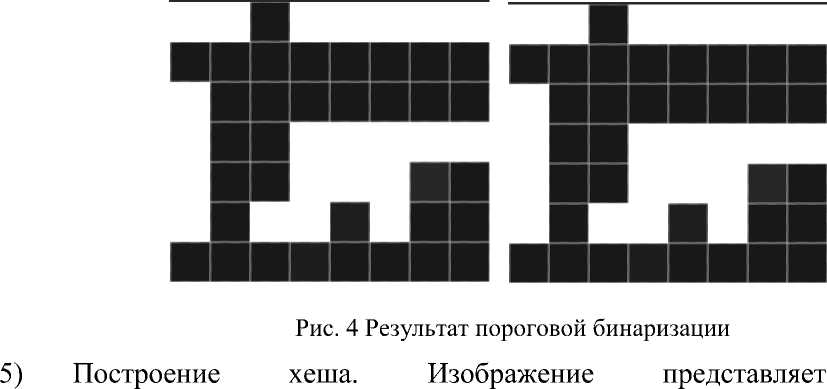
собой
последовательность 0 и 1, запишем их последовательно в виде 64-битного значения. В итоге получим следующее значение – «8f373714acfcf4d0» для обеих картинок. Значение также не изменится, если записывать значение байт в другом порядке.
Итоговый перцептивный хеш не изменится, если картинка подвергнется масштабированию, обесцвечиванию, смене контраста или яркости. В совокупности с суффиксным деревом алгоритм на множестве из 10000 объектов при наличии 1% дубликатов находит из-за t=112 секунд.
Заключение.
Лучшую эффективность поиска дубликатов небольших файлов, в частности изображений, показала совокупность работы перцептивного хеширования и построения суффксного дерева. Минусами данного алгоритма является наличие маловероятной погрешности при возникновении коллизий хеширования и необходимость хранения всей структуры данных в оперативной памяти.
Список литературы Алгоритм поиска дубликатов изображений на дисковых хранилищах
- Блейхут Р. Теория и практика кодов, контролирующих ошибки- СПб, 1986., с 576.
- Эгмотен М.Обработка изображений при помощи нейронных сетей- 2002, Москва, 1985., с 45-47.
