Алгоритмическая устойчивость нейронных сетей глубокого обучения при распознавании микроструктуры материалов

Автор: Клестов Роман Андреевич, Клюев Андрей Владимирович, Столбов Валерий Юрьевич
Рубрика: Краткие сообщения
Статья в выпуске: 1 т.21, 2021 года.
Бесплатный доступ
Исследуется разделение данных для обучения нейронной сети на обучающие и тестовые в различных пропорциях друг к другу. Ставится вопрос о том, насколько качество распределения данных и их правильность аннотирования могут повлиять на конечный результат построения модели нейронной сети. В работе исследуется алгоритмическая устойчивость обучения глубокой нейронной сети в задачах распознавания микроструктуры материалов. Исследование устойчивости процесса обучения позволяет оценить работоспособность нейросетевой модели на неполных данных, искаженных на величину до 10 %. Цель исследования. Исследование устойчивости процесса обучения нейронной сети при классификации микроструктур функциональных материалов. Материалы и методы. Искусственная нейронная сеть является основным инструментом, на базе которого производятся исследования. Используются разные подтипы глубоких сверточных сетей, такие как VGG и ResNet. Обучение нейросетей ведется с помощью усовершенствованного метода обратного распространения ошибки. В качестве исследуемой модели используется замороженное состояние нейронной сети после определенного количества эпох обучения. Произведено случайное распределение количества исключаемых из исследования данных для каждого класса в пяти различных вариантах. Результаты. Исследован процесс обучения нейронных сетей. Проведены результаты вычислительных экспериментов по обучению с постепенным уменьшением количества исходных данных. Исследованы искажения результатов вычисления при изменении данных с шагом в 2 процента. Выявлен процент отклонения, равный 10, при котором обученная нейросетевая модель теряет устойчивость. Приведены промежуточные результаты вычисления до исследования устойчивости модели обучения. Заключение. Полученные результаты означают, что при установленном количественном или качественном отклонении в обучающем или тестовом множествах результатам, которые получаются с помощью обучения сети, вряд ли можно доверять. Хотя результаты данного исследования применимы для частного случая, т. е. задачи распознавания микроструктуры с помощью ResNet-152, авторы предлагают более простую методику исследования устойчивости нейросетей глубокого обучения на основе анализа тестового, а не обучающего множества.
Глубокие нейросети, распознавание и классификация изображений, алгоритмическая устойчивость, тестовое множество, окрестность устойчивого решения
Короткий адрес: https://sciup.org/147233796
IDR: 147233796 | УДК: 004.8 | DOI: 10.14529/ctcr210114
Algorithmic stability of deep learning neural networks in recognizing the microstructure of materials
The division of data for training a neural network into training and test data in various proportions to each other is investigated. The question is raised about how the quality of data distribution and their correct annotation can affect the final result of constructing a neural network model. The paper investigates the algorithmic stability of training a deep neural network in problems of recognition of the microstructure of materials. The study of the stability of the learning process makes it possible to estimate the performance of a neural network model on incomplete data distorted by up to 10%. Purpose. Research of the stability of the learning process of a neural network in the classification of microstructures of functional materials. Materials and methods. Artificial neural network is the main instrument on the basis of which produced the study. Different subtypes of deep convolutional networks are used such as VGG and ResNet. Neural networks are trained using an improved backpropagation method. The studied model is the frozen state of the neural network after a certain number of learning epochs. The amount of data excluded from the study was randomly distributed for each class in five different distributions. Results. Investigated neural network learning process. Results of experiments conducted computing training with gradual decrease in the number of input data. Distortions of calculation results when changing data with a step of 2 percent are investigated. The percentage of deviation was revealed, equal to 10, at which the trained neural network model loses its stability. Conclusion. The results obtained mean that with an established quantitative or qualitative deviation in the training or test set, the results obtained by training the network can hardly be trusted. Although the results of this study are applicable to a particular case, i.e., microstructure recognition problems using ResNet-152, the authors propose a simpler technique for studying the stability of deep learning neural networks based on the analysis of a test, not a training set.
Текст научной статьи Алгоритмическая устойчивость нейронных сетей глубокого обучения при распознавании микроструктуры материалов
Известна проблема подбора обучающего и тестирующего множеств в задачах машинного обучения, к которым также относятся задачи глубокого обучения с целью предсказания физикомеханических свойств функциональных материалов [1–3]. Многие исследователи в области прикладных расчетов используют правило разделения всего доступного множества на обучающее и тестирующее в соотношении 80/20 либо 70/30. Как правило, аргументация такого разделения не приводится. Что касается рекомендаций по объему обучающего множества, то они и вовсе отсутствуют, кроме утверждений, что мощность множества должна быть больше количества параметров нейронной сети в 3–10 раз. Для некоторых сетей существуют теоретически обоснованные оценки. Например, в классической работе [4] приводится примерная оценка количества обучающих данных L для многослойных нейросетей прямого распространения:
L = W/г, где W – количество синоптических связей (весов); ε – ошибка обучения. Например, при ошибке в 0,1 получается правило 10X. В работе [5] для многослойных сетей прямого распространения с одним скрытым слоем приводится оценка величины L в виде
2 (n + m + p) < L < 10 (n + m + p), где n , m , p – количество нейронов во входном, в скрытом и в выходном слоях соответственно. Эта оценка является следствием теоремы существования нейросетей Колмогорова – Арнольда – Хехт – Нильсена [6].
Сегодня глубокие искусственные нейронные сети сверточного типа применяются во многих областях. С помощью миллионов предварительно классифицированных снимков, собранных в массивных базах данных аннотированных изображений, таких как ImageNet или COCO, и метода обратного распространения ошибки удалось достичь действительно впечатляющих результатов [7–9], прежде всего в задачах классификации изображений. Таким образом, начиная с 2012 г. сверточные сети можно считать традиционным методом компьютерного зрения.
Наиболее точной, если не считать малоизученную SENet (Squeeze-and-Excitation Networks), и апробированной сетью является сеть ResNet (Residual Network). Она была предложена в 2015 г. и тогда же победила в ILSVRC. Авторы Kaiming He, Xiangyu Zhang, Shaoqing Ren и Jian Sun заметили, что при увеличении глубины сети ошибка на обучающем и валидационном множестве накапливается [5].
Кроме того, существует проблема оценки качества обучающего множества. Нет четкого ответа на вопрос: насколько ошибочно аннотированные изображения могут повлиять на результат обучения? Например, достаточно часто работу классифицирующей нейронной сети сравнивают с работой человека. Является ли такая оценка справедливой? Ведь обучающее множество содержит аннотированные данные, которые готовились людьми и которые, в свою очередь, содержат те самые ошибки. Насколько эти ошибки могут искажать результат?
Известно, что фундаментальная теория равномерной сходимости В.Н. Вапника – А.Я. Черво-ненкиса [10] трактует фатальные ошибки алгоритма обучения как нарушение алгоритмической устойчивости. Под устойчивыми обучающими алгоритмами понимаются такие, которые формируют только те гипотезы, результат применения которых изменяется незначительно при малом изменении обучающей выборки [11, 12]. В рамках данной теории найдены семейства таких алгоритмов, например, регрессия, метод опорных векторов и т. д.
Обучение глубоких нейронных сетей вряд ли можно проанализировать в рамках теории равномерной сходимости, но численное исследование на устойчивость конкретных сетей может быть вполне доступно. Например, в работе [13] проведено исследование влияния размеров обучающего и тестирующего множеств на точность и обобщающую способность трехслойной нейросети MLP в задаче бинарной классификации. В работе [14] исследуется точность и разброс сети GoogLeNet в задаче классификации частей тела по снимкам компьютерной томографии. Размер обучающего множества подбирается на основании анализа точности результатов обучения. К недостаткам данной работы можно отнести то, что зависимость точности обучения от объема обучающей выборки рассчитывалась на основании 6 численных экспериментов (по каждому из классов), а само тестирующее множество получалось в результате процедуры разделения обучающего множества в пропорции 75/25. Однако если отсутствует устойчивость обучения, то данным результатам вряд ли можно доверять. Кроме того, количество данных для представительности класса можно уменьшить, если использовать предварительно обученные модели [15, 16].
1. Исследование устойчивости
Процесс исследования устойчивости заключался в поиске такой окрестности стабильного решения, при котором происходит нарушение равномерного характера сходимости к среднему. Под стабильным решением понималась обученная глубокая сеть Resnet-152. Сеть обучалась для решения задачи классификации изображений микроструктур по твердости металлического сплава на основе железа. В качестве обучающего множества выступали аннотированные снимки микроструктуры сплавов, примеры которых приведены на рис. 1. При этом микроструктура, приведенная на рис. 1 слева, соответствует сплаву с микротвердостью 1900 МПа, а справа – 7000 МПа. Все исходные изображения микроструктур были разбиты на 14 классов по твердости материала.

Рис. 1. Примеры снимков микрошлифа материала, включенные в обучающее множество Fig. 1. Examples of microsection images of a material, included in the training set
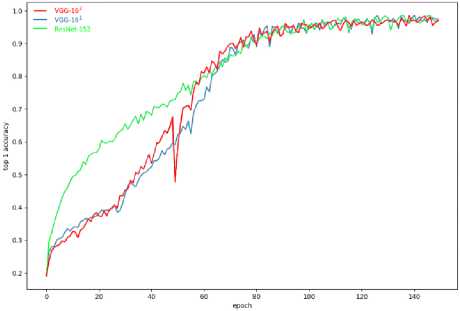
В п роц е сс е об у че н и я с е ти н а 200 -й эпохе была достигнута точность 83,9 % по оценке Top-3, п осле чего в е с а с е ти б ы л и за мор ожены. Оценка точности производилась на ва ли д а ц и он н ом мн о ж е с тв е , с о с тоящ е м и з 10 97 э ле ментов, не предъявленных сети при ее обучен и и . Проц е с с с ход и мост и п о точн ос ти , р а с с ч и та н н ой на обучающем множестве, изображен на ри с . 2.
а)
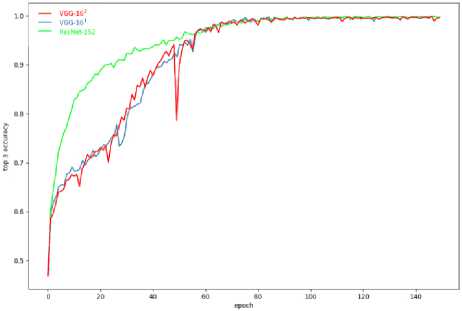
Рис. 2. Точность на обучающем множестве для сетей VGG-161 ,VGG-162 и ResNet-152: а – Top-1; б – Top-3 Fig. 2. Accuracy on the training set for networks VGG-161, VGG-162 and ResNet-152: a – Top-1; b – Top-3
б)
Сеть ResNet-1 52 п ок а зыв а е т высокую скорость сходимости. Практически з а н е с коль к о э п ох была достигнута точность 80 % по Top-3 (рис. 2б). При этом процесс обучения устойчив.
В таб л. 1 п ока за н ы ре зу л ьтаты обучения, выполненные по разным оценк а м, н а об у ча ю щ ем и валидационном множествах.
Таблица 1
Table 1
Результаты обучения сетей
Results of training networks
|
Сеть |
Точн ос т ь н а о б у ча ю щ е м мн оже с тв е |
Точность на валидационном множестве |
||
|
Top-1 |
Top-3 |
Top-1 |
Top-3 |
|
|
VGG-161 |
0,9751 |
0,9975 |
0,4704 |
0,8117 |
|
VGG-162 |
0,9712 |
0,9970 |
0,5203 |
0,8142 |
|
ResNet-152 |
0,9593 |
0,9978 |
0,6243 |
0,8933 |
Определенной неожиданностью стало то, что, несмотря на неустойчивость обучения, непред-обученная сеть VGG-162 показала значительно лучший результат Top-1 в сравнении с предобу- ченной версией этой же сети. Это можно объяснить тем, что первые слои сверточной непредобу-ченной сети смогли лучше приспособиться к специфическим изображениям микрошлифов. Пре-добученная сеть предварительно обучалась на очень большом и разнообразном множестве фотографий. Это улучшило универсальные свойства сети VGG-161 (в особенности ее первых слоев), но ухудшило степень распознавания структур специального вида.
Как и предполагалось, сеть ResNet-152 показала лучший результат – 89,3 % по оценке Top-3. Показанная точность позволяет использовать обученную сеть в качестве ядра интеллектуальной системы комплексного оценивания прочностных свойств функциональных и конструкционных материалов.
Существенное улучшение результатов ResNet-152 было достигнуто при улучшении качества обучающего множества. Из него были исключены образцы снимков с кратностью увеличения x40. Во-первых, их количество было небольшим, во-вторых, снимки с такой кратностью присутствовали не во всех классах изображений. Было сделано предположение, что данные снимки ухудшают результаты обучения. Предположение подтвердилось, так как в результате обучения точность ResNet-152 выросла и достигла величины 92,1 % по Top-3 и 66 , 2 % по Top-1. В табл. 2 представлены точности распознавания по классам материала.
Таблица 2
Точность распознавания по классам материала
Table 2
Accuracy of recognition by material classes
|
Номер класса |
Точность на валидационном множестве |
|
|
Top-1 |
Top-3 |
|
|
0 |
0,718 |
1,000 |
|
1 |
0,812 |
1,000 |
|
2 |
0,593 |
0,843 |
|
3 |
0,562 |
0,812 |
|
4 |
0,375 |
0,937 |
|
5 |
0,937 |
1,000 |
|
6 |
0,687 |
0,937 |
|
7 |
0,500 |
0,933 |
|
8 |
0,562 |
0,875 |
|
9 |
0,906 |
0,906 |
|
10 |
0,937 |
1,000 |
|
11 |
0,375 |
0,843 |
|
12 |
0,894 |
1,000 |
|
13 |
0,590 |
1,000 |
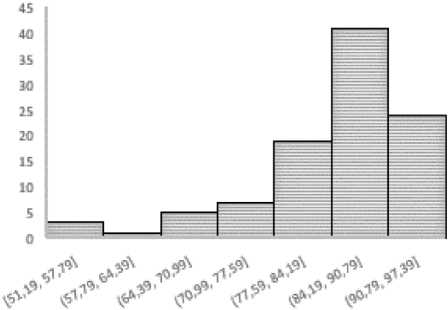
Рис. 3. Гистограмма распределения точности в тестовом множестве
Fig. 3. Histogram of the accuracy distribution in the test set
Лучшая точность по обеим оценкам достигнута в классе 10. Худшая точность по оценке Top-1 получена на классах 11 и 4. При этом по оценке Top-3 на этих же классах достигнута приемлемая точность, которая составила 84,3 %.
Определение точности работы сети по тестовому множеству показало, что плотность распределения точности может быть аппроксимирована распределением Пирсона первого рода, гистограмма которого приведена на рис. 3.
Для изучения устойчивости обученной сети тестовое множество подвергалось вариациям. Окрестность стабильного решения формировалась путем исключения из тестового множества определенного количества элементов. Элементы выбирались случайным образом на 100 реализа- циях. Такую окрестность принято называть Leave-one-out (LOO) окрестностью [5]. Обычно ее глубина равна 1 элементу. В данной работе строились несколько окрестностей: с 2, 4, 6, 8, 10 и 12%-ным отклонением от базового количества элементов в тестирующем множестве, которое использовалось для оценки точности стабильного решения. После прогона и определения точности по всем реализациям в окрестности результирующая точность получалась усреднением. Результаты численного эксперимента показаны на рис. 4.
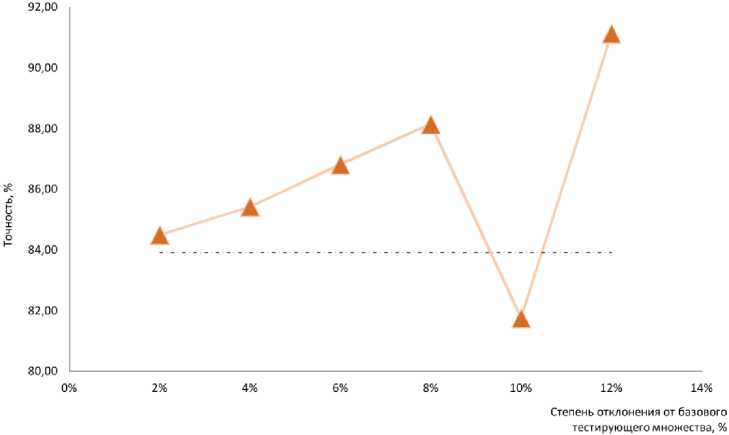
Рис. 4. Зависимость точности обученной нейросети в LOO окрестности базового тестирующего множества Fig. 4. Dependence of the accuracy of the trained neural network in the LOO neighborhood of the base testing set
-
3. Анализ результатов
Из рис. 4 следует, что процесс проверки обученной сети равномерно сходится к точности, полученной на базовой выборке (обозначена пунктирной линией). При уменьшении количества элементов в тестовом множестве более чем на 8 % происходит резкая осцилляция оценки точности, что, по нашему мнению, является потерей алгоритмической устойчивости нейронной сети в рассматриваемой задаче классификации, которую она решает.
Данное утверждение может быть распространенно и на процесс обучения, так как тестовое множество является независимой случайной однородной выборкой. Если алгоритм потерял устойчивость на тестовой выборке при контрольной проверке точности работы сети, то и процесс обучения сети потеряет устойчивость при уменьшении количества элементов в обучающей выборке на более чем 8 %.
Здесь необходимо отметить, что поиск потери устойчивости процесса обучения в глубоких сетях прямым методом является сложной задачей. Если процесс обучения сети на обучающем множестве размером в несколько десятков тысяч элементов может занимать несколько дней, то исследование устойчивости обучения затруднительно с практической точки зрения. Авторами данной работы предлагается упрощенный подход – исследовать равномерную сходимость на тестовом множестве, после чего распространить полученные выводы на все обучающее множество.
Результат, полученный в данной работе, может накладывать не только количественные, но и качественные ограничения на обучающее множество. Полученный предел может говорить о том, что в обучающем множестве не может быть более 8 % ошибочно аннотированных снимков, иначе процесс обучения потеряет устойчивость и результатам обучения доверять нельзя.
Заключение
В работе изучена проблема равномерной сходимости процесса обучения и оценки точности глубокой сети ResNet-152 в задаче анализа микрошлифов сплавов на основе железа. Показано, что при 10%-ном количественном отклонении в базовом множестве алгоритм обученной сети теряет устойчивость. Это означает, что при таком количестве элементов в тестовом множестве адекватная оценка точности сети невозможна.
Методика оценки устойчивости работы глубокой сети, примененная в данной работе, может быть распространена и на другие сети и задачи. Она не требует объемных вычислений, так как позволяет оценить достаточность количества элементов в обучающем множестве, не выполняя обучения сети на обучающих множествах, имеющих разнообразные мощности.
Список литературы Алгоритмическая устойчивость нейронных сетей глубокого обучения при распознавании микроструктуры материалов
- Recommendation System for Material Scientists Based on Deep Learn Neural Network / A. Kliuev, R. Klestov, M. Bartolomey, A. Rogozhnikov //Advances in Intelligent Systems and Computing. -2019. - Vol. 850. - P. 216-223.
- Evaluation of mechanical characteristics of hardened steels based on neural network analysis of digital images of microstructures / A.V. Klyuev, V.Yu. Stolbov, N.V. Kopceva, Yu.Yu. Jefimova // Cherny Metally. - 2020. - No. 6. - P. 50-56.
- Klestov, R. About some approaches to problem of metals and alloys microstructures classification based on neural network technologies / R. Klestov, A. Klyuev, V. Stolbov // Advances in Engineering Research. - 2018. - Vol. 157. - P. 292-296.
- Хайкин, С. Нейронные сети: полный курс: пер. с англ. / С. Хайкин. - 2-е изд. - М. : Издат. дом «Вильямс», 2006. - 1104 с.
- Борисов, В.В. Искусственные нейронные сети. Теория и практика /В.В. Борисов, В.В. Круглов. - М. : Горячая линия - Телеком, 2003. - 382 с.
- Hecht-Nielsen, R. Kolmogorov's mapping neural network existence theorem / R. Hecht-Nielsen // IEEE First Annual Int. Conf. on Neural Networks. - San Diego, 1987. - Vol. 3. - P. 11-13.
- Going deeper with convolutions / Christian Szegedy, Wei Liu, Yangqing Jia et al. // 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). - 2015. - P. 1-9.
- Deep Residual Learning for Image Recognition / Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun // 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). - 2016. -P. 770-778.
- Squeeze-and-Excitation Networks / Jie Hu, Li Shen, Samuel Albanie et al. - 2017. - ILSVRC 2017 image classification winner. arXiv: 1709.01507.
- Вапник, В.Н. Теория распознавания образов / В.Н. Вапник, А.Я. Червоненкис. - М. : Наука, 1974. - 416 с.
- Bousquet, O. Algorithmic Stability and Generalization Performance / O. Bousquet, A. Elisseeff // Advances in Neural Information Processing Systems. - 2001. - No. 13. - P. 196-202.
- Bousquet, O. Stability and Generalization / O. Bousquet, A. Elisseeff // Journal of Machine Learning Research. - 2002. - No. 2. - P. 499-526.
- Brownlee, J. Impact of Dataset Size on Deep Learning Model Skill and Performance Estimates / J. Brownlee. - https://machinelearningmastery.com/impact-of-dataset-size-on-deep-learning-model-skill-and-performance-estimates (дата обращения: 04.02.2019).
- How much data is needed to train a medical image deep learning system to achieve necessary high accuracy? / Junghwan Cho, Kyewook Lee, Ellie Shin et al. - 2015. - arXiv: 1511.06348, preprint arXiv.
- Warden, P. How many images do you need to train a neural network? / Pete Warden. -https://petewarden. com/2017/12/14/how-many-images-do-you-need-to-train-a-neural-network (дата обращения: 04.11.2019).
- Soekhoe, D. On the Impact of data set Size in Transfer Learning using Deep Neural Networks / Deepak Soekhoe, Peter van der Putten, Aske Plaat //IDA 2016: Advances in Intelligent Data Analysis XV. - 2016. - p. 50-60.
