Алгоритмы машинного обучения в прогнозировании развития побочных эффектов у пациентов с фармакорезистентностью к антипсихотикам и антидепрессантам

Автор: Жиганова Т.А., Кузнецов А.И., Щепкина Е.В.
Журнал: Сибирский журнал клинической и экспериментальной медицины @cardiotomsk
Рубрика: Цифровые технологии в медицине и здравоохранении
Статья в выпуске: 4 т.40, 2025 года.
Бесплатный доступ
Введение. Искусственный интеллект и машинное обучение открывают новые горизонты в разработке прогностических моделей с использованием данных фармакогенетического тестирования (ФГТ) пациентов. Это может позволить более точно предсказывать развитие побочных эффектов (ПЭ) при терапии антипсихотиками (АП) и антидепрессантами (АД) и применять персонифицированный подход к терапии пациентов с фармакорезистентностью (ФР) к АП и АД. Цель: сравнение алгоритмов машинного обучения для предсказания вероятности развития ПЭ у пациентов с ФР к АП и АД. Материал и методы. В ретроспективном когортном исследовании реальной клинической практики были использованы результаты ФГТ 144 пациентов (72 (50%) мужчин и 72 (50%) женщин, средний возраст 33 ± 8,4 года) с ФР к АП и АД, получавших терапию в амбулаторном режиме в период с 2016 по 2024 гг. ФГТ полиморфизмов генов CYP2D6, CYP2C19, CYP1A2 и MDR1 (C3435T) проводилось в медицинских лабораториях Санкт-Петербурга (МедЛаб, Инвитро). Для построения прогностической модели предсказания развития ПЭ были использованы алгоритмы машинного обучения Lasso, Ridge, Extra Tree (ET), k-Nearest Neighbors (KNN), Naive Bayes (NB), Random Forest (RF) и eXtreme Gradient Boosting (XGB). Результаты. Лучшие результаты получены при построении прогностической модели на основе алгоритма RF. Показатели тестовой выборки составили: ROC-AUC 75,5 [59,6; 89,9] %, чувствительность 72,2 [55,0; 88,9] %, специфичность 58,3 [33,3; 81,8] %. В качестве основных предикторов использовались возраст, пол, генотипы и аллели генов CYP2C19, CYP2D6, CYP1A2, MDR1 С3435Т, курение, наличие неврологических заболеваний и употребление психоактивных веществ. Выводы. Разработанная модель на основе алгоритма машинного обучения Random Forest продемонстрировала высокую эффективность в прогнозировании вероятности развития ПЭ у пациентов с ФР к АП и АД. Она может послужить основой для будущих исследований и разработки персонифицированного подхода к лечению пациентов, принимающих АП и АД, с целью интеграции ее в дальнейшем в систему поддержки принятия врачебных решений.
Цитохромы, MDR1 C3435, фармакорезистентность, антипсихотики, антидепрессанты, машинное обучение, прогностическая модель, Lasso, Ridge, Extra Tree, k-Nearest Neighbors, Naive Bayes, Random Forest, eXtreme Gradient Boosting
Короткий адрес: https://sciup.org/149150158
IDR: 149150158 | УДК: 615.124.32:616.8-08-052:004.85 | DOI: 10.29001/2073-8552-2025-40-4-227-237
Machine learning algorithms for prediction of side effects development in patients with pharmacoresistance to antipsychotics and antidepressants
Rationale. Artificial intelligence and machine learning allow for development of predictive models using pharmacogenetic testing (PGT) data. It helps to predict the development of side effects (SE) in patients treated with antipsychotics (AP) and antidepressants (AD) and provides personalized approach for the treatment of patients with treatment resistance to antipsychotics and antidepressants. Aim: To compare machine learning algorithms for prediction of side effects development in patients with pharmacoresistance (PR) to antipsychotics and antidepressants. Material and Methods. A retrospective study utilized PGT data of 144 patients (72 males and 72 females, mean age 33±8.4 years) with PR to AP and AD, treated on an outpatient basis for the period from 2016 to 2024. PGT assessed CYP2D6, CYP2C19, CYP1A2, and MDR1 (C3435T) gene polymorphisms conducted in medical laboratories in St. Petersburg (MedLab, Invitro). Machine learning algorithms Lasso, Ridge, Extra Tree (ET), k-Nearest Neighbors (KNN), Naive Bayes (NB), Random Forest (RF), and eXtreme Gradient Boosting (XGB) were used to build the predictive model for SE development. Results. RF algorithm demonstrated the best performance as the predictive model in test sample parameters: ROC-AUC 75.5% [59.6; 89.9], sensitivity 72.2% [55.0; 88.9], and specificity 58.3% [33.3; 81.8]. The main predictors included age, sex, CYP2C19, CYP2D6, CYP1A2, MDR1 C3435T genotypes and alleles, smoking, presence of neurological diseases and substance abuse. Conclusion. Random Forest model machine learning algorithm has demonstrated high efficiency in predicting side effects probability in treatment resistant patients to AP and AD. The model can serve as the basis for future research and development of personalized treatment approach for the patients treated with AP and AD, with the possibility of further integration into Medical Decision Support System.
Текст научной статьи Алгоритмы машинного обучения в прогнозировании развития побочных эффектов у пациентов с фармакорезистентностью к антипсихотикам и антидепрессантам
Характерной особенностью фармакотерапии в психиатрической практике является значительная вариабельность терапевтического ответа на лекарственный препарат (ЛП). Одно и то же лекарственное вещество в одинаковой дозе может вызвать побочные эффекты (ПЭ) уже после первого приема у одного пациента, а у другого не оказывает какого-либо эффекта. Генетические особенности пациентов являются одним из основных факторов, определяющих чувствительность к фармакотерапии [1]. Не удается добиться терапевтического эффекта у
22– 25% пациентов при первичном назначении антипсихотиков (АП) и у 39,5% при множественных попытках фармакотерапии [2].
В исследовании STAR*D показано, что примерно у 30% пациентов с диагнозом большого депрессивного расстройства не удается достичь ремиссии после двух попыток терапии разными антидепрессантами (АД) [3].
Фармакорезистентность (ФР) является основной причиной повышения стоимости терапии пациентов в психиатрии. В США затраты в год на лечение пациента с фармакорезистентной депрессией выше на 3,4–4,3 тыс.
долларов в первый год и на 2,1 тыс. долларов во второй год сравнению с депрессией, поддающейся терапии [4].
Основными факторами развития ФР к АП и АД являются индивидуальные различия в метаболизме ЛП. На концентрацию ЛП в крови и нейронах и, соответственно, на эффекты ЛП влияют активность ферментов системы цитохромов [5] и транспортный белок p-гликопротеин (ПГП) [6].
При высокой активности цитохромов и ПГП концентрация ЛП в крови и нейронах низкая, что может приводить к неэффективности терапии и необходимости назначения препаратов в высоких дозах. Низкая активность цитохромов и ПГП может повышать концентрацию ЛП в нейронах и вызывать развитие ПЭ препаратов, что требует коррекции их дозы, а также является фактором негативного отношения пациентов к терапии, снижая их приверженность лечению.
Активность цитохромов и ПГП генетически детерминирована. Синтез неактивных цитохромов кодируют аллели *3, *4, *5 и *6 CYP2D6, *2 и *3 CYP2C19, *1F и *1С CYP1A2. Неактивный ПГП синтезируется при замене цитозина на тимин в положении 3435 гена MDR1. Высокая активность цитохромов наблюдается у носителей нескольких аллелей CYP2D6 (*1NUM), аллели *17 CYP2C19 и при курении пациентов-носителей аллели *1F CYP1A2 [7]. У носителей быстрых аллелей часто наблюдается неэффективность терапии АП и АД, а у носителей медленных аллелей – высокая частота возникновения ПЭ препаратов [8].
В настоящее время руководства по дозированию ЛП (в том числе АП и АД) в зависимости от генотипа цитохромов пациентов разработаны такими организациями, как Dutch Pharmacogenetics Working Group (DPWG) [9] и Clinical Pharmacogenetics Implementation Consortium (CPIC) [10]. Эти руководства удобны при дозировании АП и АД у пациентов-носителей быстрых или медленных аллелей гена только одного цитохрома, например, CYP2D6 или CYP2C19.
Однако наши исследования частоты генотипов у пациентов с ФР к АП и АД, показали, что у 20% пациентов наблюдается комбинация и быстрых, и медленных аллелей генов как одного цитохрома (например, «медленная» аллель *5 и быстрая аллель *1NUM CYP2D6), так и нескольких («медленная» аллель *4 CYP2D6, «быстрая» аллель CYP3C19 *17 и генотип Т/Т, кодирующий синтез неактивного белка ПГП) [11]. У таких пациентов сложно предсказать скорость метаболизма и элиминации ЛП и, следовательно, выбрать наилучший препарат и скорость увеличения его дозы.
Цель исследования: разработать систему поддержки принятия врачебных решений для выявления вероятности развития ПЭ у пациентов с ФР к AП и АД.
Материал и методы
Исследование является ретроспективным когортным с использованием данных реальной клинической практики. Оно включает данные фармакогенетического тестирования (ФГТ) 144 пациентов старше 18 лет, 72 (50%) мужчин и 72 (50%) женщин, получавших терапию АП и АД в амбулаторном режиме с 2016 по 2024 гг. в г. Санкт-Петербурге. ФР к АП и / или АД определяли как наличие минимум одного из следующих критериев: 1) госпитализации более двух раз в год на фоне терапии основного заболевания; 2) сохраняющаяся симптоматика основного заболевания при двух и более попытках терапии двумя препаратами в адекватных дозах с оценкой эффективности терапии через 6–12 нед.
В качестве исхода рассматривалось наличие минимум одного выраженного ПЭ препаратов (экстрапирамид-ные нарушения, повышение массы тела, задержка мочеиспускания, тревога, нарушения сна и др.), снижающего качество жизни пациента и требующего смены терапии. Оценка ПЭ осуществлялась на основе жалоб пациента с последующей оценкой врачом.
В качестве факторов, влияющих на возникновение ПЭ, были проанализированы результаты ФГТ. ФГТ проводилось в медицинских лабораториях (МедЛаб, Ин-витро) и включало определение полиморфизмов генов CYP2D6 (аллели *1, *1N дупликация), *3 (rs35742686), *4 (rs3892097), *5 (делеция гена), *6 (rs5030655), CYP1A2 (аллели *1А, *1F (rs762551), *1С (rs2069514)), CYP2C19 (аллели *1, *2 (rs4244285), *3 (rs4986893), *17 (rs12248560) и гена ПГП MDR1 (C3435T, rs1045642).
Маркеры для ФГТ были выбраны на основе клинических рекомендаций CPIC в сочетании с возможностью их определения медицинскими лабораториями. Так как конечной целью нашей работы является внедрение ФГТ в клиническую практику и с учетом того, что все международные рекомендации (PharmGKB, CPIC) по дозированию ЛП на основе ФГТ применяют «star allele nomenclature», именно данная номенклатура аллелей использована для их идентификации.
Информация о поле, возрасте, курении, наличии неврологических заболеваний и употреблении психоактивных веществ была получена из медицинской карты пациента.
В связи с ретроспективным характером исследования возможность получения информированного согласия пациентов отсутствовала. Все данные пациентов собраны и обработаны в анонимизированном формате.
Статистический анализ
Построение прогностических моделей проводилось средствами языка Питон (Python 3.12.) в 5 этапов.
На первом этапе для повышения качества данных проведена проверка на выбросы и пропуски значений. Для данных, которые имели менее чем 5% пропущенных значений, был применен метод вменения пропущенных значений, основанный на алгоритме машинного обучения k-Nearest Neighbors (kNN).
На втором этапе исходная выборка была разделена на обучающую и тестовую в соотношении 80 : 20, а также было проведено сравнение выделенных групп на статистически значимое различие. Соотношение 80 : 20 было выбрано, основываясь на общепринятых практиках в области машинного обучения и статистики, что позволяет обеспечить достаточный объем данных для обучения модели, сохраняя при этом адекватный размер тестовой выборки для оценки ее производительности.
На третьем этапе для построения модели предсказания ПЭ были выбраны алгоритмы машинного обучения, построены открытые (Lasso, Ridge) и закрытые модели (Extra Tree (ET), k-Nearest Neighbors (kNN), Naive Bayes (NB), Random Forest (RF), eXtreme Gradient Boosting (XGB)) [12].
Lasso: регрессионный метод, который использует L1-регуляризацию для уменьшения переобучения и выбора значимых признаков.
Ridge: регрессионный метод с L2-регуляризацией, который помогает справиться с мультиколлинеарностью и улучшает обобщающую способность модели.
ET: алгоритм, основанный на ансамбле деревьев решений, который использует случайные подмножества данных и признаков для повышения точности.
kNN: метод, основанный на нахождении ближайших соседей, который позволяет классифицировать объекты на основе их сходства с другими объектами.
RF: алгоритм, использующий ансамбль деревьев решений для повышения точности и устойчивости модели.
XGB: метод, который строит модели последовательно, исправляя ошибки предыдущих моделей, что позволяет достичь высокой точности.
Открытая модель предоставляет возможность видеть формулы и правила, на основе которых она принимает решения, что позволяет анализировать и понимать алгоритмы и логику, лежащие в ее основе. Это помогает врачу лучше осознавать, как функционирует модель и принимать более обоснованные решения, опираясь на ее выводы.
В отличие от этого закрытая модель скрывает правила принятия решений в «черном ящике», что делает невозможным увидеть, как она приходит к своим выводам. Это может затруднить понимание ее работы и вызвать сомнения в доверии к ней. Тем не менее, закрытые модели часто демонстрируют более высокие показатели качества, что делает их также востребованными на практике.
На четвертом этапе построенные модели были протестированы на обучающей и тестовой выборках. Для каждой модели рассчитаны точность, чувствительность, специфичность и ROC-AUC (ROC – Receiver Operating Characteristic, рабочая характеристика приемника; AUC Area Under the Curve, площадь под кривой) с определением 95% доверительного интервала (ДИ) методом Бутстреп (Bootstrap) при выборке 1000 экземпляров [13]. Также для максимизации чувствительности и специфичности полученной модели было рассчитано пороговое значение (точка отсечения или cut off) для определения наличия / отсутствия изучаемого исхода. Для оценки калибровки модели использована оценка Брайера (Brier).
На пятом этапе проведена комплексная оценка важности признаков для закрытых и открытых моделей, что позволило получить более полное представление о факторах, влияющих на исход, а также улучшить интерпретируемость и надежность разработанных моделей.
Для закрытых моделей (ET, kNN, NB, RF, и XGB) важность признаков была оценена с помощью метода Permutation Importance. Для открытых моделей Lasso и Ridge оценка значимости признаков осуществлялась через анализ коэффициентов, приписанных каждому признаку в модели. Значение коэффициента признака указывает на силу его влияния на вероятность наступления исхода.
Таким образом, была выбрана наиболее эффективная прогностическая модель, построенная с помощью алгоритма машинного обучения, которая наиболее точно приводит к достижению цели исследования.
Результаты
База данных 144 пациентов была разделена на обучающую и тестовую выборки в соотношении 80 : 20. В обучающую и тестовую выборки попали 114 и 30 пациен- тов соответственно. Выделенные группы статистически значимо не различались между собой (табл. 1).
Результаты оценки качества моделей, обученных с использованием различных алгоритмов машинного обучения, представлены в таблице 2.
Главными параметрами качества прогностической модели являются дискриминация (ROC-AUC) и калибровка (oценка по Брайеру). Именно они помогают врачам оценить, насколько надежна и полезна прогностическая модель в клинической практике. Чем ближе значение ROC-AUC к 100%, тем лучше модель справляется с задачей отнесения пациента в группу без ПЭ или с ПЭ. ROC-AUC модели RF на обучающей и тестовой выборках составила 80 и 76% соответственно с минимальным различием по сравнению с другими моделями. У модели Ridge площадь под кривой ROC-AUC составила 79 и 72% для обучающей и тестовой выборок соответственно. Коэффициент Брайера в тестовой выборке был минимальным для моделей RF и Ridge и составил 0,219, что указывает на более высокий уровень их калибровки по сравнению с другими моделями. Это значит, что предсказания этих моделей более точны и надежны.
Дополнительными параметрами качества моделей являются чувствительность, специфичность и точность. Специфичность теста отражает его способность правильно определять пациентов, у которых отсутствует определяемый признак (в нашем случае ПЭ при назначении АП и АД) среди тех, у кого эти ПЭ действительно отсутствуют. Для модели RT специфичность составила 58,3%, что близко к моделям Ridge, ET и XGB. Модель NB продемонстрировала максимальную специфичность на уровне 100%, однако ее чувствительность была лишь 16,7%. Это означает, что для модели NB характерна высокая гиподиагностика, что плохо для клинической практики, поскольку она может не выявлять значительное количество пациентов с ПЭ. В результате врачи могут упустить важные случаи, требующие внимания, что может привести к неправильному лечению или ухудшению состояния пациентов. Таким образом, несмотря на высокую специфичность, низкая чувствительность модели NB делает ее менее надежной для использования в ситуациях, где важно не только исключить наличие ПЭ, но и правильно их диагностировать.
Чувствительность теста отражает его способность правильно выявлять пациентов с заболеванием (в нашем случае – пациентов, у которых наблюдаются ПЭ) среди тех, у кого эти ПЭ действительно есть. Чувствительность на тестовой выборке у модели RF составила 76%, у модели Ridge – 61%.
Точность модели диагностического теста отражает ее общую способность правильно определять как пациентов с ПЭ, так и тех, у кого их нет. Модель RF показала точность 66,7%, что является наилучшим результатом среди всех протестированных моделей. В то же время модель Ridge продемонстрировала точность на уровне 61%.
Сравнительный анализ признаков, участвующих в рассмотренных моделях, представлен на рисунках 1, 2.
Признаков, которые бы встречались во всех моделях одновременно, выявлено не было. Большинство схожих переменных были выбраны алгоритмами Ridge, ET, KNN, и RF. Пол, возраст, генотипы CYP1A2 *1A/*1C и CYP2С19 *1/*2, аллели *5 CYP2D6 и *17 CYP2С19 встречались в шести из семи моделей (86%).
Таблица 1 . Сравнительная характеристика пациентов с фармакорезистентностью к антипсихотикам и антидепрессантам
Table 1 . Comparative characteristics of patients with treatment resistance to antipsychotics and antidepressants
|
Переменные |
Все, n = 144 |
Тестовая выборка, n = 30 |
Обучающая выборка, n = 114 |
p |
|
Предикторы |
||||
|
Пол: мужской женский |
72 (50,0%) 72 (50,0%) |
15 (50,0%) 15 (50,0%) |
57 (50,0%) 57 (50,0%) |
1,000 |
|
Возраст, лет Me [ Q1 ; Q3 ] |
32,0 [24,.0; 38,25], |
32,5 [24,5; 39,0], |
31,5 [24,25; 38,0], |
0,656 |
|
Курение |
23 (16,0%) |
5 (17,0%) |
18 (15,8%) |
1,000 |
|
CYP2D6 *1/*1 |
84 (58,3%) |
17 (57,0%) |
67 (58,8%) |
0.835 |
|
CYP2D6 *1/*3 |
9 (6,2%) |
2 (7,0%) |
7 (6,1%) |
1,000 |
|
CYP2D6 *1/*4 |
32 (22,2%) |
7 (23,0%) |
25 (21,9%) |
1,000 |
|
CYP2D6 *1*/5 |
3 (2,1%) |
1 (3,0%) |
2 (1,8%) |
0,507 |
|
CYP2D6 *3*/4 |
3 (2,1%) |
1 (3,0%) |
2 (1,8%) |
0,507 |
|
CYP2D6 *4/*4 |
3 (2,1%) |
1 (3,0%) |
2 (1,8%) |
0,507 |
|
CYP2D6 *1/*1Num |
7 (4,9%) |
1 (3,0%) |
6 (5,3%) |
1,000 |
|
CYP2D6 *1NUM/*5 |
3 (2,1%) |
0 (0%) |
3 (2,6%) |
1,000 |
|
CYP2D6 *1 |
135 (93,8%) |
28 (93,0%) |
107 (93,9%) |
1,000 |
|
CYP2D6 *3 |
12 (8,3%) |
3 (10,0%) |
9 (7,9%) |
0,714 |
|
CYP2D6 *4 |
38 (26,4%) |
9 (30,0%) |
29 (25,4%) |
0,645 |
|
CYP2D6*5 |
6 (4,2%) |
1 (3,0%) |
5 (4,4%) |
1,000 |
|
CYP2D6 *1NUM |
10 (6,9%) |
1 (3,0%) |
9 (7,9%) |
0,688 |
|
CYP2C19 *1/*1 |
49 (34,0%) |
13 (43,0%) |
36 (31,6%) |
0,227 |
|
CYP2C19 *1/*2 |
35 (24,3%) |
7 (23,0%) |
28 (24,6%) |
1,000 |
|
CYP2C19 *1/*3 |
1 (0,7%) |
0 (0%) |
1 (0,9%) |
1,000 |
|
CYP2C19 *2/*2 |
1 (0,7%) |
1 (3,0%) |
0 (0%) |
0,208 |
|
CYP2C19 *1/*17 |
47 (32,6%) |
9 (30,0%) |
38 (33,3%) |
0,829 |
|
CYP2C19 *17/*17 |
11 (7,6%) |
0 (0%) |
11 (9,6%) |
0,120 |
|
CYP2C19 *1 |
133 (92,4%) |
29 (97,0%) |
104 (91,2%) |
0,459 |
|
CYP2C19 *2 |
36 (25,0%) |
8 (27,0%) |
28 (24,6%) |
0,815 |
|
CYP2C19 *3 |
1 (0,7%) |
0 (0%) |
1 (0,9%) |
1,000 |
|
CYP2C19 *17 |
58 (40,3%) |
9 (30,0%) |
49 (43,0%) |
0,197 |
|
CYP1A2 *1A/*1А |
63 (43,8%) |
16 (53,0%) |
47 (41,2%) |
0,234 |
|
CYP1A2 *1A/*1F |
69 (47,9%) |
13 (43,0%) |
56 (49,1%) |
0,572 |
|
CYP1A2 *1F/*1F |
8 (5,6%) |
0 (0%) |
8 (7,0%) |
0,205 |
|
CYP1A2 *1A/*1C |
3 (2,1%) |
1 (3,0%) |
2 (1,8%) |
0,507 |
|
CYP1A2 *А |
135 (93,8%) |
30 (100,0%) |
105 (92,1%) |
0,204 |
|
CYP1A2 *F |
77 (53,5%) |
13 (43,0%) |
64 (56,1%) |
0,211 |
|
CYP1A2 *С |
3 (2,1%) |
1 (3,0%) |
2 (1,8%) |
0,507 |
|
MDR1 C/С |
22 (15,3%) |
4 (13,0%) |
18 (15,8%) |
1,000 |
|
MDR1 C/T |
72 (50,0%) |
17 (57,0%) |
55 (48,2%) |
0,412 |
|
MDR1 T/T |
50 (34,7%) |
9 (30,0%) |
41 (36,0%) |
0,541 |
|
MDR1 С |
94 (65,3%) |
21 (70,0%) |
73 (64,0%) |
0,541 |
|
MDR1 Т |
122 (84,7%) |
26 (87,0%) |
96 (84,2%) |
1,000 |
|
ВНПА |
14 (9,7%) |
2 (7,0%) |
12 (10,5%) |
0,735 |
|
Исход |
||||
|
нет ПЭ |
57 (39,6%) |
12 (40,0%) |
45 (39,5%) |
0,958 |
|
есть ПЭ |
87 (60,4%) |
18 (60,0%) |
69 (60,5%) |
|
Примечание: Me – медиана, р – уровень значимости различий между группами, ВНПА – Врожденные Неврологические заболевания и / или злоупотребление ПсихоАктивными веществами, ПЭ – побочные эффекты.
Наилучшие показатели качества модели были достигнуты при использовании алгоритма RF, в результате применения которого была построена закрытая модель. По сравнению с другими моделями на тестовой выборке модель RF продемонстрировала максимальное значение ROC-AUC 75,5 [59,6; 89,9] %. При этом чувствительность модели составила 72,2 [55,0; 88,9] %, специфичность – 58,3 [33,3; 81,8] %. Метрики качества модели, построенной на основе алгоритма RF, представлены на рисунке 3.
Важность признаков, вошедших в модель RF, представлена на рисунке 4. Наиболее значимыми предик- торами возникновения ПЭ оказались возраст (0,142), аллель CYP2C19 *17 (0,087) и генотип CYP2C19 *17/*17 (0,077). Следует отметить, что сумма значимостей всех предикторов (см. рис. 4) равна 1, и в модели использовался 31 предиктор. Это означает, что среднее влияние каждого предиктора составляет 1/31 = 0,03, если все они оказывают одинаковое влияние. Однако мы оценили реальное влияние предикторов, и те предикторы, у которых значимость выше 0,03, имеют влияние на исход выше среднего.
Таким образом, ключевыми факторами риска, вли-
Таблица 2 . Сравнение метрик качества моделей на обучающей и тестовой выборках
Table 2 . Comparative characteristics of models’ quality parameters in training and test sets
|
Мера оценки/ Модель |
LASSO |
Ridge |
ET |
KNN |
NB |
RF |
XGB |
|
Обучение |
|||||||
|
ROC-AUC |
78,4% |
79,1% |
84,7% |
100,0% |
78,7% |
79,9% |
77,2% |
|
[95% ДИ] |
[71,0; 85,5] |
[71,4; 85,8] |
[78,5; 90,2] |
[99,9; 100,0] |
[71,4; 85,5] |
[72,3; 86,9] |
[69,6; 84,0] |
|
Точность |
70,2% |
69,3% |
71,1% |
99,1% |
48,2% |
71,9% |
64,9% |
|
[95% ДИ] |
[62,3; 77,2] |
[62,3; 76,3] |
[64,0; 77,2] |
[97,4; 100,0] |
[40,4; 56,1] |
[64,9; 78,9] |
[57,9; 71,9] |
|
Чувствительность |
69,6% |
68,1% |
68,1% |
98,6% |
14,5% |
71,0% |
59,4% |
|
[95% ДИ] |
[60,0; 78,6] |
[57,8; 77,1] |
[59,1; 76,6] |
[95,9; 100,0] |
[7,4; 22,1] |
[61,3; 80,0] |
[49,3; 69,2] |
|
Специфичность |
71,1% |
71,1% |
75,6% |
100,0% |
100,0% |
73,3% |
73,3% |
|
[95% ДИ] |
[60,4; 82,5] |
[59,6; 81,6] |
[64,6; 85,7] |
[100,0; 100,0] |
[100,0; 100,0] |
[62,5; 84,4] |
[63,0; 83,7] |
|
Оценка Брайера |
0,181 |
0,179 |
0,168 |
0,004 |
0,518 |
0,204 |
0,230 |
|
Тестирование |
|||||||
|
ROC-AUC |
65,3% |
72,2% |
64,1% |
65,3% |
69,0% |
75,5% |
64,6% |
|
[95% ДИ] |
[48,0; 81,4] |
[56,1; 87,3] |
[45,8; 80,1] |
[48,3; 82,3] |
[52,0; 84,7] |
[59,6; 89,9] |
[46,5; 81,8] |
|
Точность |
50,0% |
60,0% |
53,3% |
56,7% |
50,0% |
66,7% |
60,0% |
|
[95% ДИ] |
[36,7; 63,3] |
[46,7; 73,3] |
[40,0; 66,7] |
[43,3; 70,0] |
[33,3; 63,3] |
[53,3; 80,0] |
[46,7; 76,7] |
|
Чувствительность |
55,6% |
61,1% |
50,0% |
77,8% |
16,7% |
72,2% |
61,1% |
|
[95% ДИ] |
[37,5; 75,0] |
[42,1; 80,0] |
[31,2; 70,6] |
[62,5; 94,1] |
[4,8; 33,3] |
[55,0; 88,9] |
[41,2; 80,0] |
|
Специфичность |
41,7% |
58,3% |
58,3% |
25,0% |
100,0% |
58,3% |
58,3% |
|
[95% ДИ] |
[18,2; 66,7] |
[33,3; 81,8] |
[33,3; 81,8] |
[7,1; 46,7] |
[100,0; 100,0] |
[33,3; 81,8] |
[33,3; 81,8] |
|
Оценка Брайера |
0,264 |
0,219 |
0,235 |
0,238 |
0,500 |
0,219 |
0,236 |
Примечание: ДИ – доверительный интервал.
яющими на вероятность развития ПЭ, явились возраст (0,142), CYP2C19*17 (0,087) и CYP2C19*17/*17 (0,077). Меньшая значимость наблюдалась у предиктивных факторов медленных аллелей CYP2D6*3 (0,071) и CYP2C19*2 (0,057).
Обсуждение
В нашем исследовании мы сосредоточились на использовании искусственного интеллекта для разработки прогностического инструмента, который поможет врачам предсказывать возникновение ПЭ у пациентов с ФР к АП и АД, проявляющихся в снижении качества жизни пациента, а также в виде низкой эффективности этих препаратов, что требует смены препарата. Для этого мы анализировали результаты ФГТ, демографические данные и анамнез, собранные в реальной клинической практике.
Мы использовали несколько алгоритмов машинного обучения для построения прогностических моделей. Были построены и проанализированы как открытые (Lasso, Ridge), так и закрытые (ET, kNN, NB, RF, XGB) модели. По результатам оценки построенных моделей на обучающей и тестовой выборках была определена наилучшая модель, которая показала наивысшую точность при прогнозировании ПЭ у пациентов.
Наилучшие метрики качества в нашем исследовании продемонстрировала закрытая прогностическая модель RF, а из двух открытых моделей лучшей оказалась модель Ridge.
Наши данные схожи с результатами других исследований. Например, в работе E. Lin и соавт., проведенной на пациентах с большим депрессивным расстройством из Тайваня с использованием 10 генетических и 6 клинических признаков, была применена модель MFNN (Multilayer Feedforward Neural Network – многослойная нейронная сеть), которая показала наилучшие результаты в предсказании терапевтического ответа на лечение АД. В этом исследовании ROC-AUC составил 82%, чувствительность – 75%, а специфичность – 69%. Однако стоит отметить, что ни один из генетических параметров, использованных в их исследовании, не включал в себя параметры фармакогенетики, которые мы применили в нашем исследовании. В качестве других предикторов в модели использовались возраст пациентов на момент включения в исследование, пол, количество предыдущих депрессивных эпизодов, тяжесть заболевания и наличие суицидальных попыток в анамнезе [14].
В другой работе той же исследовательской группы продемонстрирована высокая предсказательная способность модели RF, использующей данные полногеномного тестирования для предсказания вероятности развития большого депрессивного расстройства в популяции Тайваня [15].
Комплексный эффект трех генетических и одного клинического параметра продемонстрировал, что модель RF может предсказывать ответ на терапию АД у пациентов с фармакорезистентной депрессией, однако ее чувствительность составила всего 25% [16].
В другом исследовании, в котором использовались клинические и генетические факторы для предсказания терапевтического ответа на лечение циталопрамом и эс-циталопрамом, модель RF показала точность 69%, ROC-AUC 70%, что сравнимо с нашими результатами. Однако ни один из выбранных генетических маркеров не включал в себя генотипы цитохромов и ПГП [17].
Мы нашли мало работ, посвященных использованию машинного обучения для предсказания ответа на терапию АП. В одном из исследований была продемонстрирована эффективность открытой модели Lasso у пациентов европейской популяции с впервые выявленным психотическим эпизодом [18]. Как и в нашем исследовании, модель выбрала пол и возраст в момент дебюта заболевания в качестве предиктивных факторов. ROC-AUC составила 59%, чувствительность – 48%, специфичность – 76%, точность – 64%. Молодой возраст пациентов оказался предиктивным фактором развития ПЭ, что согласуется с нашими данными. Среди других предиктивных факторов модель выделила 17 признаков, включая образование, индекс массы тела, употребление алкоголя, наличие продуктивной симптоматики и семейное положение.
В исследовании, посвященном разработке модели
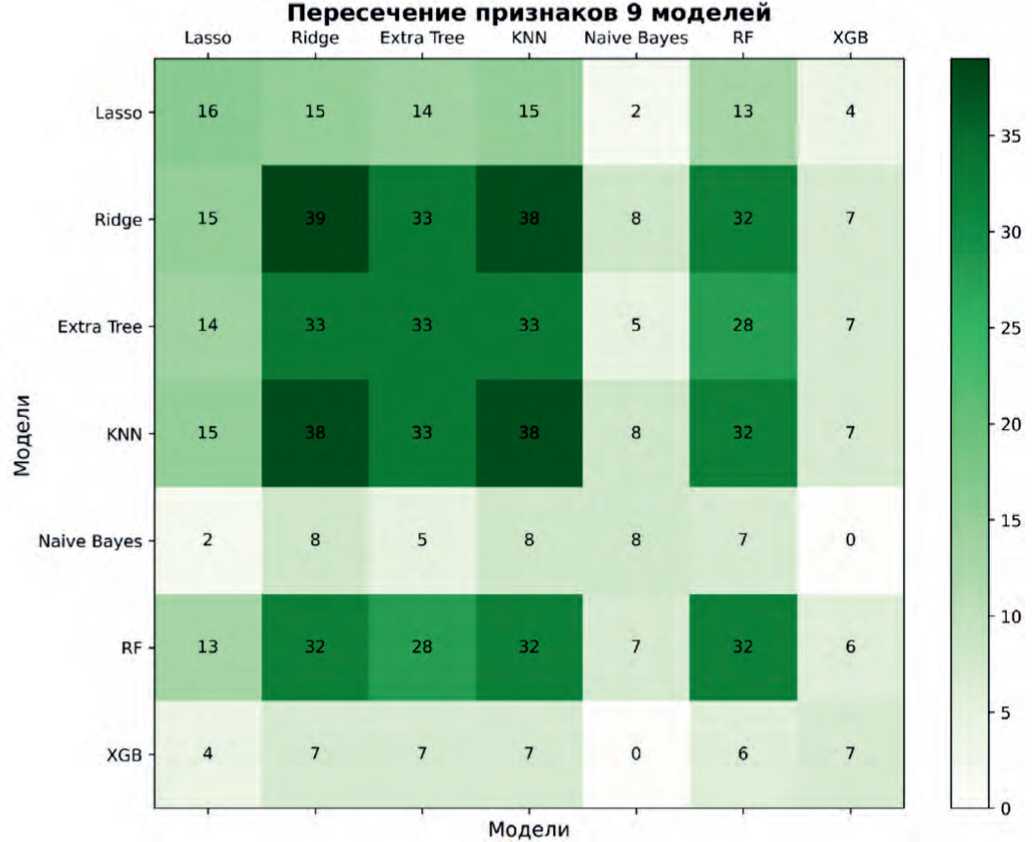
Рис. 1. Распределение предиктивных признаков, используемых в построенных моделях Fig. 1. Distribution of predictive features used in the studied models
для предсказания вероятности развития ФР к АП у пациентов китайской популяции с диагнозами шизофрении, биполярного аффективного расстройства, большого депрессивного расстройства [19], предиктивными генетическими факторами явились гены, вовлеченные в процесс взаимодействия нейронов и нейрогенез (кодирующие синтез фосфолипазы, потенциал-зависимых калиевых каналов и других регуляторы нейротрансмиссии). Наилучшие показатели эффективности выявлены у модели RES (Regression Ensemble Model) с ROC-AUC 85%.
Исследования, проведенные с участием подростков в г. Москва [20], показали возможность использования 11 клинико-демографических переменных для прогнозирования вероятности возникновения ПЭ с использованием моделей LR (Logistic Regression), RF, XGB и CatBoost (Categorical Boosting). Закрытая модель CatBoost продемонстрировала наилучшую надежность. Наиболее значимыми факторами риска развития ПЭ оказались возраст (наибольший риск установлен в возрасте 12–15 лет с последующим снижением), длительность госпитализации и количество госпитализаций в анамнезе. Однако в этом исследовании не были приведены параметры эффективности сравниваемых моделей.
В нашем исследовании мы определили ключевые факторы риска, влияющие на вероятность развития ПЭ на модели RF. Наибольшее значение имели возраст, CYP2C19*17 и CYP2C19*17/*17. Меньшая значимость наблюдалась у предиктивных факторов медленных аллелей CYP2D6*3 и CYP2C19*2.
Поскольку модель RF является закрытой, она не позволяет определить, является ли наличие или отсутствие быстрой аллели или генотипа CYP2C19 предиктивным фактором возникновения ПЭ. Эту информацию можно получить только при анализе данных открытых моделей. Например, модель Ridge показала, что наличие аллели *3 CYP2D6 является наиболее весомым фактором возникновения ПЭ, а наличие у пациента быстрой аллели *17 или генотипа *17/*17 CYP2C19 – наиболее важными факторами отсутствия ПЭ. Увеличение возраста пациента сопровождается снижением вероятности возникновения ПЭ при ФР к АП и АД, а мужской пол является фактором риска возникновения ПЭ.
Результаты нашего исследования помогут выявить важные факторы, влияющие на развитие ПЭ, разработать более эффективные стратегии лечения пациентов, терапия которых является сложной задачей для врача-психиатра. Современные достижения в области искусственного интеллекта могут значительно облегчить
Рис. 2. Частота встречаемости предиктивных признаков в построенных моделях
Fig. 2. Frequency of predictive features in the studied models врачам процесс выявления и анализа сложных закономерностей, связанных с ФР к АП и АД.
К ограничениям исследования можно отнести отсутствие у некоторых пациентов полного набора ФГТ, анамнестических данных о курении и / или употребле- нии психоактивных веществ, что является характерной особенностью исследований с использованием данных реальной клинической практики, а также малый размер выборки пациентов.
Для будущих исследований мы рекомендуем исполь-
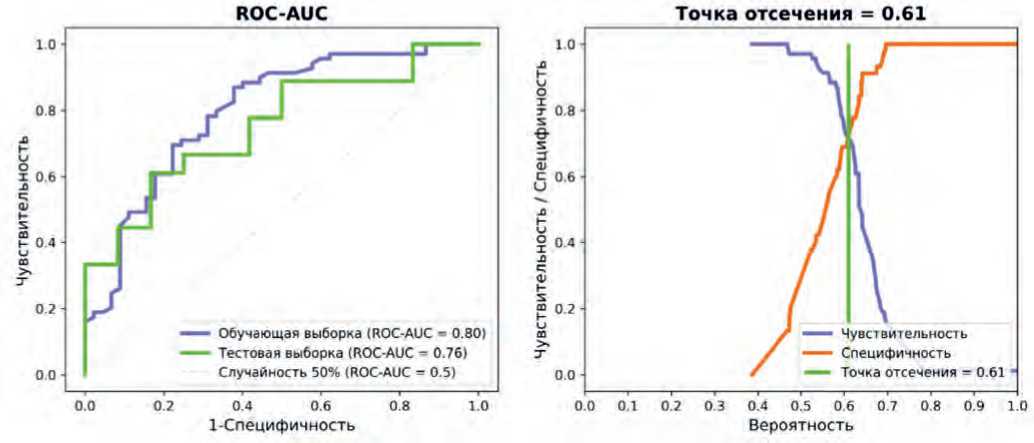
Рис. 3. Метрики качества на обучающей и тестовой выборках модели, построенной на основе алгоритма RF Fig. 3. Quality metrics of training and test samples of the model based on RF algorithm
Рис. 4. Важность признаков, используемых моделью RF
Fig. 4. Importance of features used by RF model
зовать более обширные данные пациентов из популяций, проживающих не только на территории Санкт-Петербурга, но и в других регионах России, что может повысить обобщаемость данных и даст возможность использования модели в популяции пациентов других регионов.
Выводы
В исследовании проведено сравнение семи алгоритмов машинного обучения для прогнозирования развития неэффективности терапии АП и АД у пациентов с ФР. Наилучшие показатели качества модели продемонстрировал алгоритм Random Forest (RF), который показал ROC-AUC 75,5%, чувствительность 72,2% и специфичность 58,3% на тестовой выборке.
Закрытая модель RF обладает хорошей калибровкой и сбалансированными характеристиками чувствительности и специфичности, что делает ее наиболее подходящей для клинического применения в прогнозировании ПЭ у данной категории пациентов.
Ключевыми предикторами развития ПЭ явились возраст пациента, генотипы и аллели генов CYP2C19 (*17 и *17/*17), а также в меньшей степени медленные аллели CYP2D6 *3 и CYP2C19 *2. Кроме того, значимыми факторами риска выступают пол, курение, наличие неврологических заболеваний и употребление психоактивных веществ.
Использование комплексного подхода с включением фармакогенетических данных и клинических факторов позволяет повысить точность прогноза и способствует персонализации терапии у пациентов с ФР.
Заключение
Данное исследование демонстрирует значимость использования алгоритмов машинного обучения в клинической практике для прогнозирования ПЭ у пациентов с ФР к АП и АД. Разработанная модель может служить основой для будущих исследований и разработки персонифицированного подхода к лечению пациентов, принимающих АП и АД, с целью интеграции ее в дальнейшем в систему поддержки принятия врачебных решений.
