An Architecture for Recommendation of Courses in E-learning

Author: Sanjay K. Dwivedi, Bhupesh Rawat
Journal: International Journal of Information Technology and Computer Science(IJITCS) @ijitcs
Article in issue: 4 Vol. 9, 2017.
Free access
Over the last few years, the face of traditional learning has changed significantly, primarily due to the emergence of the worldwide web. So in order to take advantage of the web various kinds of learning systems have emerged such as computer-based learning, web-based learning and other forms of electronic learning which have been very successful in meeting different kinds of the educational need of the learners and educators thus they are adopted by a large number of universities and institutions worldwide. E-learning systems let educators distribute information, create content material, prepare assignments, engage in discussions, and manage distance classes among others. They accumulate a huge amount of data as a result of learner's interaction with the site, which has the potential to provide useful knowledge to the students, teachers, e-learning system administrators and university management for decision making. However the tools that existed in the past for data mining were inadequate to provide useful insight into the huge data generated consequently, data mining techniques began to facilitate the process of knowledge discovery. In this paper, we propose an architecture for the recommendation of the best combination of courses to the students and apply the apriori algorithm at the preliminary stage.
Data mining, Weka, Moodle, Apriori algorithm, E-learning, Educational data mining
Short address: https://sciup.org/15012637
IDR: 15012637
Text of the scientific article An Architecture for Recommendation of Courses in E-learning
Published Online April 2017 in MECS
Educational data mining (EDM), involves developing methods that discover knowledge from data originate from educational environments[1].The research community has shown growing interest in the application of data mining techniques in education[2][3][4] [5][22][23][24][25][26][27][28][29]. Data Mining (DM), also known as knowledge discovery in database (KDD) is a process of nontrivial extraction of implicit, previously unknown, and potentially useful information from data in the database [6]. It has been used successfully in many areas including education, banking, telecommunication, business among others. Data mining includes tasks such as outlier detection, association rule mining, clustering, classification, regression etc [2]. It provides several techniques which can be used to discover knowledge about learner’s behavior in the e-learning system. Among all the techniques we use the apriori algorithm.
In this paper, we present an architecture, a tool and the application of the tool to the data collected from Moodle server in order to show the recommendation of the best combination of courses to the learner. We use one of the most widely used association rule mining algorithms namely apriori in order to achieve our aim. The course recommender system has been developed using Moodle, an open source learning management system. Nowadays, Moodle (modular object oriented developmental learning environment)is one of the most commonly used free learning management system which allows the creation of powerful, flexible and engaging online courses and experiences. These e-learning systems accumulate a vast amount of information which is very valuable for analyzing students’ behavior. They can record any student activities involved, such as reading, writing, taking tests, performing various tasks, and even communicating with peers. They normally provide a database that stores all the system's information: personal information about the users (profile), academic results and users’ interaction data. However, due to the huge amount of data generated by these systems, it is very difficult to manage it manually [1]. Recommender systems have used several techniques including data mining agent and reasoning [7] [8][9][10][11].They have been very successful in E-commerce among other domains, although many educational institutes worldwide have begun incorporating them as a part of their education system [7].
The rest of the paper is organized as follows: First, we review related work. Then we present the architecture of the course recommendation system. Next, we present and discuss the result of the apriori algorithm. Finally, we present the conclusion and future work section.
-
II. Related Work
From the study of existing literature, we have found that a significant amount of work on recommendation system based on data mining techniques has been going on in the domain of e-learning. Some of the key work is present here. In [12] they proposed a recommender system which utilizes machine learning algorithm algorithms on historical data obtained from moodle.They used the different combination of k-means and apriori algorithms with weka in order to find the best combination of courses being recommended to learners. In another work [13] they discussed the current state of research and application of data mining methods in elearning. They also presented a taxonomy of e-learning problems to which the data mining techniques have been applied such as learner’s classification based on their learning performance, detection of irregular learning behavior, clustering based on similar E-learning system usage and system adaptability as per the requirements of students.
In yet another work the authors in [14] suggest that recommender system can be used to recommend topics of interest to learners in an e-learning environment. For this, they presented an innovative architecture for a recommender system based on collaborative tagging and conceptual maps. In [15] they narrated technical activity based course recommender system in which they defined an architectural model of this method using a collaborative filtering technique. It works based on collecting and analyzing information about user activity.
A personalized recommender system [4] is described that uses web mining technique for recommending a student which link to visit next within an adaptable educational hypermedia system. They used data mining techniques such as clustering and sequential pattern mining together for discovering personalized recommendation links. The authors in [16] proposed an evolving web-based learning system which can adapt itself not only to the varying requirement of its user but also to the open web. In [18] they presented a personalized recommendation methodology by which they are able to enhance effectiveness and quality of recommendations when applied to an internet shopping mall.
In this [19] work the authors suggested a framework of a personalized learning recommender system with the goal of helping students find learning materials, they would need to read. In another work, the authors suggested [20] how the changing preferences of learner over time can be tracked with adaptive machine learning algorithms. In this approach, they begin by building an initial decision model based on learning style using the available student’s data. This model was further updated with the data generated by student’s interaction with the system in order to reflect more accurately their current preferences.
In [33] they compare different data mining methods and techniques for classifying students based on their Moodle usage data and the final marks obtained in their respective courses. They have also developed a specific mining tool for making the configuration and execution of data mining techniques easier for students. In [34] they discuss the Data warehousing and data mining resources to aid in the assessment of distance learning of students enrolled in distance courses. Relevant information considered for the assessment of distance learning is presented as is the modeling of a data warehouse to store this information and the Multistar environment, which allows for knowledge discovery to be performed in the data warehouse. In yet another work [35] they use the web
Mining techniques in order to build recommender system that could recommend online learning activities or shortcut on a course website based on learner’s access history to help a user to navigate course material as well as assist in the online learning process.
The research work by [36] proposed a data mining system which was implemented in order to study the records of two programming courses in a distance curriculum of computer science. In order to achieve this many data mining models such as linear regression and probabilistic model were used to predict the performance of a student.
The result obtained shows that data mining system can help a distance education teacher even in courses with relatively few students, to improve learning process at different levels, improve exercise, scheduling the course and find out potential drop out at an early stage. The work in [37] proposed an adaptive e-learning system framework which personalizes the learning experience of the learners in an efficient way. Moreover, this system infers the characteristics of the learners and identifies the preferences of the learners and automatically generates personalized learning path and customized learning contents to the individual needs. Authors of [38] used a decision tree approach for predicting student’s Academic performance. They used chi-square automatic interaction detection of SPSS (statistical package for social studies) in order to produce the decision tree structure. The results were produced as the financial status of the students, motivation to learn and gender which affected the performance of the students.
-
III. Modular Object Oriented Development Learning Environment (Moodle)
Moodle is an open source learning management system which helps educators create effective online learning communities [17]. It is used by universities, community colleges, K-12 schools, business and even individual instructors to add web technology to their course. Moodle is freely available on the web at . Moodle allows users to have access to its source code. Moreover, one can look into the code and see how it works, tinker with it and share it with others or use part of it in your own product. All the components of moodle are modularized such as assignment, quiz, taking a test, adding course etc. In our system, we offer various course categories and corresponding courses in each category to the learners using this software. An interface of the proposed system is shown in Fig.1 where only those users with a valid login can access the system, browse the available course categories and enroll in a single or multiple courses. Once a category is selected such as web technology then it lists a number of courses to the learner like HTMK, JavaScript among others to choose a single or multiple courses from them. The course selection made by the user is stored in a log file of the web server. A log file collects all the data which comes from as a result of user interaction with the site. The interaction involves any activity done by the user on the site such as click stream data. In our research, we consider the course selection data which help us to know the courses selected by the user. After all the user selects their courses we retrieve the required data from the log file of moodle server for data preprocessing and mining purpose. The user interface of the course recommender system is designed in such a way that any authenticated user finds it easy to use.
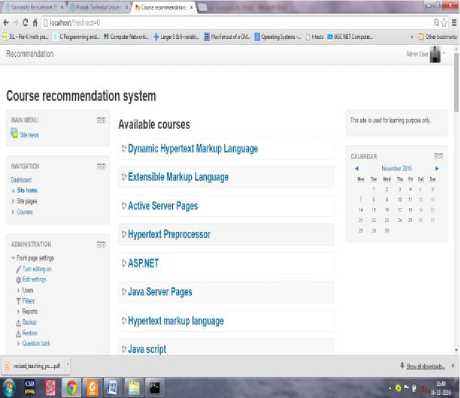
Fig.1. Moodle Interface java source code. Weka implements algorithms for data pre-processing, classification, regression, clustering, and association rules. It also includes a visualization tool.
V. Association Rule Mining
The Apriori algorithm [8][21] is an influential algorithm for mining frequent itemset for Boolean association rules in a transactional database. In association rule mining, the interesting hidden relationships among attributes of the huge database are recognized. There are several algorithms proposed for obtaining association rules [30]. It was first used in the market basket analysis which explained the correlation between items such as placing A and B (where A and B are two item sets) together would increase the chances of their selling. Other applications of this algorithm are in educational data mining, classification, clustering etc. Different forms of the association rule algorithm are Apriori, Sampling, Partitioning and parallel algorithm. Among all these forms Apriori is widely used. It uses two parameters namely support and confidence in order to measure the quality of discovered rules. The support of the association rule X->Y refers to the percentage of the transactions in the database that contain XUY (both X and Y) and confidence of the association rule X->Y is the ratio of the number of transactions that contain XUY to the number of transactions that contain X.
-
IV. Weka (Waikato Environment for Knowledge Analysis)
Fig.2. Weka 3.6.12 with explorer window
Weka [32] is data mining software that implements data mining algorithms. It is freely available for download and offers many powerful features (sometimes not found in commercial data mining software). It has become one of the most widely used tools for the data mining system. Weka consists of machine learning algorithms for data mining tasks. The algorithms are either applied directly to a dataset or can be called from
-
VI. Architecture of Proposed System
This section describes the architecture of e-learning system. We consider 9-course categories and 43 courses which are shown in Table.1. The course categories are Web technology, Image processing graphics and artificial intelligence applications, Principles of programming language Software engineering, Database management system, Networks, Hardware design and engineering, information retrieval, Humanities and social science respectively and the corresponding course name and code are also given against each course category. In Figure.3 we have shown the architecture of course recommendation system in which we allow each student of M.C.A and C.M.C.A of Department of computer science (Babasaheb Bhimrao Ambedkar University) to login into the system (Moodle) with valid username/password before accessing the courses. After successful authentication, a student is allowed to browse the available course category and enroll in single/multiple courses. All this data (enrollment) is accumulated in the log file of the Moodle server. Before mining this data we need to perform data pre-processing over it in order to remove the irrelevant data. The architecture is implemented using Moodle which is an open source learning management system (LMS). There exist many learning management systems which are both commercial and free. The reason for using moodle is its open source nature, ease of use and wider acceptability among Elearning community.
Table 1. Course category, course name and code
|
S.N |
Course category |
Course name and code |
|
1 |
Web technology |
|
|
2 |
Image processing graphics and artificial intelligence applications |
|
|
3 |
Principles of programming language |
|
|
4 |
Software engineering |
|
|
5 |
Database management system |
|
|
6 |
Networks |
|
|
7 |
Hardware design and engineering |
|
|
8 |
Information retrieval |
|
|
9 |
Humanities and social sciences |
|
Fig.3. An architecture of E-learning Recommendation System
-
VII. Result and Analysis
In our research we consider the following courses: Management information system(MIS),Environmental science(EVS), Data mining(DM), Data warehousing(DW), Image processing(IP), Advance computer architecture(ACA), Natural language processing(NLP), Communication skill(CS), Information retrieval(IR),Mobile computing(MC) as shown in Table.2, where ‘y’ indicates that the students are interested in a particular course and n represents that students do not want to enroll in the corresponding course. Before data pre-processing the Enrollment data and the corresponding graph which shows the interest of students in the available courses is shown in Table.2 and Figure.4 respectively.
Figure.4 shows that the maximum number of students is interested in the operating system and a minimum number of students have expressed their willingness to take admission in Finite state automata course. However, Table.2 may contain irrelevant data which is not useful from the mining point of view so data pre-processing is an essential step in order to make the data suitable for mining and analysis steps.
Although data pre-processing includes several substeps such as data cleaning, pattern identification, user identification, session identification and path completion, all these steps are not required in our research. Hence we used only data cleaning step which results in the removal of the data of all those students who enrolled in less than 2 courses and all those courses in which less than 11
students were enrolled. Hence after preprocessing the resulting data is shown in Table.3 and the corresponding graph is also depicted in Figure 5.
As we can see some of the courses such as microprocessor architecture, computer organization and database engineering which contained in Table.2 before data preprocessing have been removed. Moreover, we can also see in Table.3 9 students with Roll. No(2,10,29,31,40,42,44,45,47 and 6)and 5 courses namely microprocessor architecture(MP), computer organization(CO), advanced database system(ADS), finite state automata(FSA), software testing and quality assurance(STQA) and software engineering have been removed as a result of data pre-processing.
It is important to note that in Table.2 and Table.3 ‘y’ means a student is interested in a particular course and ‘n’ indicates that the student does not want to enroll in that particular course. Moreover, we have omitted some course and students from the table in order to save space. The resulting data as a result of data preprocessing is shown in Table.3 and the corresponding graph of this data course vs. the number of students has also been depicted in Figure.5.
Table 2. Before data preprocessing
|
Courses Roll. No |
C |
VB |
ASP |
CN |
NE |
MP |
CO |
DBE |
ADS |
|
1 |
y |
y |
y |
y |
y |
n |
n |
n |
n |
|
2 |
n |
n |
n |
y |
n |
n |
n |
n |
n |
|
3 |
y |
y |
y |
y |
y |
n |
n |
n |
n |
|
4 |
n |
n |
n |
y |
y |
n |
y |
n |
n |
|
5 |
y |
y |
y |
y |
y |
n |
n |
y |
n |
|
6 |
y |
y |
y |
n |
n |
n |
n |
n |
n |
|
7 |
n |
n |
n |
y |
y |
y |
y |
n |
n |
|
8 |
n |
n |
n |
n |
n |
n |
n |
y |
y |
|
9 |
n |
n |
n |
y |
y |
y |
y |
n |
n |
|
10 |
y |
n |
n |
n |
n |
n |
n |
n |
n |
|
11 |
y |
y |
y |
n |
n |
n |
n |
n |
n |
|
12 |
y |
y |
y |
y |
y |
n |
n |
n |
n |
|
13 |
n |
n |
n |
n |
n |
n |
n |
y |
y |
|
14 |
y |
y |
y |
y |
y |
n |
n |
n |
n |
|
15 |
y |
y |
y |
n |
n |
n |
n |
n |
n |
|
16 |
n |
n |
n |
y |
y |
n |
n |
y |
y |
|
17 |
y |
y |
y |
n |
n |
n |
n |
n |
n |
|
18 |
y |
y |
y |
n |
n |
n |
n |
n |
n |
|
19 |
n |
n |
n |
y |
y |
y |
y |
y |
y |
|
20 |
y |
n |
n |
n |
n |
n |
n |
n |
n |
|
21 |
y |
n |
y |
n |
n |
y |
y |
n |
n |
|
22 |
n |
n |
n |
n |
n |
n |
n |
y |
y |
|
23 |
y |
y |
y |
y |
y |
y |
y |
n |
n |
|
24 |
y |
y |
y |
y |
y |
y |
y |
y |
y |
|
25 |
n |
y |
y |
n |
n |
y |
y |
y |
y |
|
26 |
y |
y |
y |
n |
n |
n |
n |
n |
n |
|
27 |
y |
y |
y |
y |
y |
n |
n |
n |
n |
|
28 |
n |
n |
y |
y |
y |
n |
n |
n |
n |
|
29 |
n |
n |
n |
n |
n |
y |
y |
y |
y |
|
30 |
y |
y |
y |
y |
y |
n |
n |
n |
n |
|
31 |
n |
n |
n |
n |
n |
y |
n |
n |
n |
|
32 |
y |
y |
y |
n |
n |
n |
n |
y |
y |
|
33 |
n |
n |
n |
y |
y |
n |
n |
n |
n |
|
34 |
y |
y |
y |
n |
n |
n |
n |
n |
n |
|
35 |
n |
n |
n |
n |
n |
n |
n |
n |
n |
Table 3. After data preprocessing
|
Courses ---► Roll. No 1 |
C |
VB |
ASP |
CN |
NE |
DBE |
OS |
|
1 |
y |
y |
y |
y |
y |
n |
n |
|
3 |
y |
y |
y |
y |
y |
n |
y |
|
4 |
n |
n |
n |
y |
y |
n |
n |
|
5 |
y |
y |
y |
y |
y |
y |
y |
|
6 |
y |
y |
y |
n |
n |
n |
y |
|
7 |
n |
n |
n |
y |
y |
n |
n |
|
8 |
n |
n |
n |
n |
n |
y |
y |
|
9 |
n |
n |
n |
y |
y |
n |
n |
|
11 |
y |
y |
y |
n |
n |
n |
y |
|
12 |
y |
y |
y |
y |
y |
n |
n |
|
13 |
n |
n |
n |
n |
n |
y |
y |
|
14 |
y |
y |
y |
y |
y |
n |
y |
|
15 |
y |
y |
y |
n |
n |
n |
n |
|
16 |
n |
n |
n |
y |
y |
y |
y |
|
17 |
y |
y |
y |
n |
n |
n |
y |
|
18 |
y |
y |
y |
n |
n |
n |
n |
|
19 |
n |
n |
n |
y |
y |
y |
n |
|
20 |
y |
n |
n |
n |
n |
n |
y |
|
21 |
y |
n |
y |
n |
n |
n |
y |
|
22 |
n |
n |
n |
n |
n |
y |
y |
|
23 |
y |
y |
y |
y |
y |
n |
y |
|
24 |
y |
y |
y |
y |
y |
y |
y |
|
25 |
n |
y |
y |
n |
n |
y |
y |
|
26 |
y |
y |
y |
n |
n |
n |
y |
|
27 |
y |
y |
y |
y |
y |
n |
n |
|
28 |
n |
n |
n |
y |
y |
n |
y |
|
30 |
y |
y |
y |
y |
y |
n |
n |
|
32 |
y |
y |
y |
n |
n |
y |
y |
|
33 |
n |
n |
n |
y |
y |
n |
y |
|
34 |
y |
y |
y |
n |
n |
n |
n |
|
35 |
n |
n |
n |
n |
n |
n |
y |
|
36 |
n |
n |
n |
y |
y |
n |
n |
|
37 |
y |
y |
y |
y |
y |
y |
n |
|
38 |
n |
n |
n |
n |
n |
n |
y |
|
39 |
y |
y |
y |
y |
y |
y |
y |
|
41 |
y |
y |
y |
n |
n |
n |
y |
|
43 |
n |
n |
n |
n |
n |
n |
y |
|
46 |
n |
n |
n |
n |
n |
y |
y |
|
48 |
y |
n |
n |
n |
y |
y |
n |
|
49 |
n |
y |
y |
n |
y |
y |
y |
|
50 |
y |
y |
n |
y |
n |
n |
y |
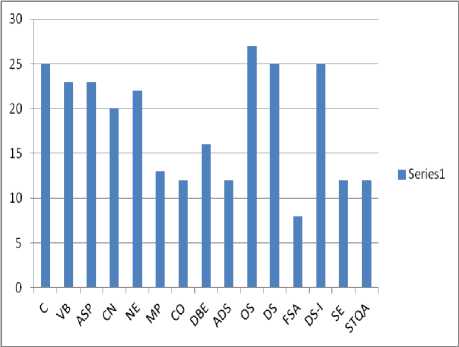
Fig.4. Subject choice before data preprocessing
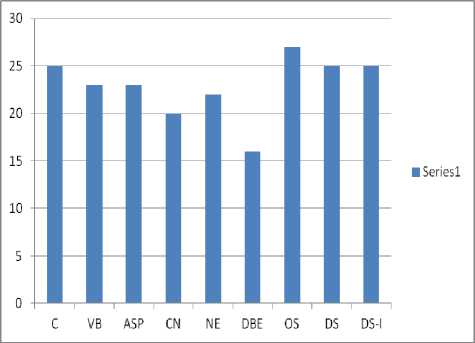
Fig.5. Subject choice after data preprocessing
Table 4. Association rules obtained after data preprocessing
|
S.No |
Courses considered |
Parameter considered |
Results using Apriori algorithm |
|
1 |
quality assurance |
Minimum support:0.6 Minimum metric |
Software testing quality assurance=no
assurance=no
|
|
Table 4. Association rules obtained before data preprocessing |
|||
|
S.No |
Courses considered |
Parameter considered |
Results using Apriori algorithm |
|
2 |
1.Discrete mathematics
3.Microprocessor
|
Minimum support:0.4
Minimum Number of cycles performed:12 |
|
We have used Weka, an open source data mining tool in order to apply Apriori algorithm to the preprocessed data as shown in Table.3. Weka has several algorithms for data mining such as Apriori association rule,Predictive Apriori association rule,Tertius association rule and Filtered association, although we preferred to use Apriori because it gives all association rules containing only “yes”. Other algorithms except the Filtered Associator using Apriori association rule algorithm gives the association rules containing “no” also. In Table.4, we have shown the results of applying Apriori algorithm before and after data preprocessing.
In Row 1 of Table.4, we can see that before data pre- processing we have all negative association rules or the rules containing no only which have no significance in the mining phase as we require only positive association rules i.e. containing only yes for the recommendation of courses.
After data pre-processing the algorithm generated only positive association rules which are the focus of our interest. While applying the algorithm we also set the value of parameters such as support, confidence and number of cycles performed in such a way that we get strong association rules. We also found that if we decrease the minimum support value then we get a large number of association rules which also involved redundant rules on the other hand when we increase the threshold then we get a low number of association rules which may not involve important rules. Moreover, the discovered rules support the assumption that a student would select interrelated courses such as operating system-> distributed system. That means if a student has selected operating system then it is more likely that he would also prefer distributed system course. So we can suggest a student distributed system course along with the operating system.
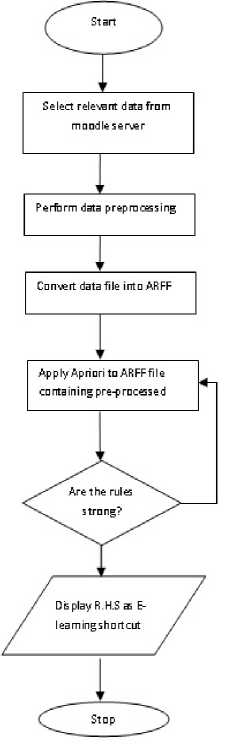
Fig.6. Flow Diagram of Recommendation System
-
VIII. Conclusion and Future Work
In this paper, we have proposed an architecture for course recommendation system, which suggests the best combination of courses to students. The quality of data significantly influences the association rules obtained with Apriori algorithm and has a direct effect on the recommendations. Hence we performed data preprocessing over the data collected through moodle, which resulted in more refined data suitable for applying Apriori algorithm. The association rules that we discovered with apriori algorithm are matched with real life choices of courses. However, in our study of existing literature, we have found that the accuracy of discovered rules can be improved further by using several ways such as certainty factor instead of usually employed support/confidence parameters which may sometimes lead to misleading rules, which results in recommendations that do not match to the need of the learner. Hence our future work consists of using certainty factor and support parameter instead of utilizing usually employed support/confidence parameters in order to improve the quality of obtained rules which eventually leads to improved recommendations of courses.
References An Architecture for Recommendation of Courses in E-learning
- C.Romero,S.Ventura, and E.Garcia,“Data mining in course management system: moodle case study and tutorial”,Comput.Educ, pp368-384,2008.
- V.Kumar, “An Empirical study of the applications of data mining techniques in higher education”, International journal of advanced computer science and application, Vol. 2, No.3,pp. 80-84,2011.
- V.Ramesh.,P.Parkavi and P.Yahhodha,“Performance analysis of data mining techniques for placement chance prediction”, International journal of scientific and engineering research,2011
- C.Romero, and S.Ventura, “Educational data mining: A survey from 1995 to 2005”, Journal of expert systems applications, Vol.33, No.1,pp 135-146,2007.
- C-H.Weng, “Mining fuzzy specific rare itemsets for educational data”, Knowledge based System, Vol. 24, No.5,pp 697-708,2011.
- M-S.Chen,., Han,J.,Yu,P.S, “Data mining: An overview from a database perspective”, IEEE Transaction on Knowledge and Data Engineering,Vol. 8, pp 866-833,1996.
- L.Lee., T-C.Lu, “Intelligent agent-based systems for personalized recommendations in internet commerce”, Expert System with Applications,Vol. 22,pp 275-284,2002.
- S-W.Changchien,.T.Lu, “Mining association rules procedure to support on-line recommendation by customers and product fragmentation”, Expert Systems with Applications, Vol.20,pp 325-335,2001.
- K-W.Cheung, J-T.Kwok, M-H.Law and K-C.Tsui, “Mining customer product ratings for personalized marketing”, Decision Support Systems, Vol. 35,pp 231-243,2003.
- O-B.Kwon,“I know what you need to buy: context- aware multimedia-based recommendation system”, Expert Systems with Applications,2002.
- R-D.Lawrence, G-S.Almasi, V.Kotiyar, M-S.Viveros, and S .Duri, “Personalization of supermarket product recommendations”, Data mining and knowledge Discovery, Vol. 5,pp 11-32,2011.
- S-B.Aher, and L-M-R-J.Lobo, “Combination of machine learning algorithms for recommendation of courses in E-Learning System based on historical data”, Knowledge-Based Systems,Vol. 51, pp 1-14,2013.
- F.Castro,A.Vellido,A. Nebot, and F.Mugica, “Applying data mining techniques to e-learning problems”, Studies in Computational Intelligence,Vol. 62, pp 183-221,2007.
- A-A.Kardan,S.Abbasapour and F.Hendijanifard,“A Hybrid recommender system for e-learning environments based on concepts maps and collaborative tagging.”, In the proceedings of the 4th international conference on virtual learning ICVL,2009.
- L.Feng-Jung and S.Bai-Jiun, “Learning activity based e-learning material recommendation system in multimedia workshop.”, 9th IEEE international symposium,2007.
- T.Tang, and G.McCalla, “ Smart recommendation for an evolving e-learning system: architecture and experiment.”,International journal on E-learning, Vol. 4,No.1, pp 105-129,2005.
- J.Cole, and H.Foster, “Using Moodle: Teaching with the popular open source course management system.”, O’Reilly Media, Inc,2007.
- T-H.Cho,J-K.Kin and S-H.Kim,“A personalized recommender system based on web usage mining and decision tree induction.”, Expert System with Applications,Vol.23, pp 329-342,2002.
- J.Lu, “A personalized e-learning material recommender system”, In proceedings of 2nd international conference on information technology for application (ICITA), Macquarie Scientific Publishing, 2004.
- C.Carmona, G.Castillo and E.Millan, “Discovering students preferences in e-learning”, In: Proceedings of the international workshop on Applying Data Mining in e-learning, pp 33-42,2007.
- R.Agrawal, and R.Srikant, “Fast algorithms for mining association rules”, In proceedings of international conference on Very Large Database(VLDB),1994.
- A.EI-Halees, “Mining students data to Analyze Learning Behavior :A case study ”, In the proceedings of the international Arab Conference of Information Technology,2008.
- B.Baradwaj, and S.Pal, “Mining educational data to analyze student’s performance”, International journal of advanced computer science and applications,Vol.2,No.6,pp 63-69,2011.
- B.Shannaq, Y.Rafael, and V.Alexendro, “Students relationship in higher education using data mining techniques”, Global journal of computer science and technology,Vo.10,No.11,pp 54-59,2010.
- Al-Radaideh,E.AI-Shawakfa, & AI-Najjar, “ Mining students data using decision tree”, In proceedings of the international Arab conference on information technology,2006.
- E.Chandra, and K.Nandhini, “Knowledge mining from student data”, European journal of scientific research,Vol.47,No.1,pp 156-163,2010.
- S.Ayesha,T.Mustafa,A.Sattar, and I.Khan, “ Data mining model for higher education system”,European journal of scientific research,Vol.43,No.1,pp 24-29,2010.
- H.Margo, “Data mining in the E-learning Domain”,Computers and Education,Vol.42,No.3,pp 267-287,2004.
- T-Y.Tang,G.McCalla, “Smart Recommendation for an Evolving E-learning system: Architecture and Experiment”, International journal of E-learning,Vol.4,No.1,pp 105-129,2005.
- R.Agrawal.,T.Imielinski, and A.Swami, “Mining association rules between set of items in large database”, in proceedings of the ACM SIGMOD conference on management of data, pp 207-216,1993.
- R.Srikant,R.Agrawal,“Mining Generalized Association rules”, In proceedings of the 21st international conference on very large database,1995.
- E.Frank, A.Mark A. Hall, H.Ian,and H-I Witten, "Data Mining: Practical Machine Learning Tools and Techniques", Morgan Kaufmann, Fourth Edition,2016.
- C.Romero,S.Ventura,P.G,Espejo,C.Hervas, “Data mining algorithms to classify students”,In: Education Data Mining conference,2008.
- D.Resende,M.Teresa, “Using Data Warehouse and Data Mining Resources for Ongoing Assessment of Distance Learning”,In:IEEE International conference on Advanced Learning technologies,ICALT,2002.
- O.Zaiane, “Building a Recommender agent for e-Learning systems”, In proceeding of the International conference in Education,pp 55-59,2002.
- W.Hamalainen,T.H.Laine,E.Sutinen, “Data mining in personalizing distance education course”,H.Toivonen,In World conference on open learning and distance education,pp 1-11,2004.
- M.Dominic,B.Anthony,S.Francis, “A Framework To Formulate Adaptivity for Adaptive E-learning System Using User Response Theory”, International Journal of Modern Education and Computer Science,Vol.7,No 1,pp 23-30,2015.
- K.David,S.Adepoju,J.Kolo, “A Decision Tree Approach for Predicting Students Academic Performance”, International Journal of Education and Management Engineering(IJEME),Vol.5,No.5,pp 12-19,2015.
