An Automated Model for Sentimental Analysis Using Long Short-Term Memory-based Deep Learning Model

Author: Shashank Mishra, Mukul Aggarwal, Shivam Yadav, Yashika Sharma
Journal: International Journal of Engineering and Manufacturing @ijem
Article in issue: 5 vol.13, 2023.
Free access
A post, review, or news article's emotional tone can be automatically ascertained using sentiment analysis, a natural language processing approach. Sorting the text into positive, negative, or neutral categories is the aim of sentiment analysis. Many methods, including rule-based systems and machine learning algorithms, can be used to analyse sentiment, or deep learning models. These techniques typically involve analyzing various features of the text, such as word choice, sentence structure, and context, to identify the overall sentiment. Here long short-term memory-based deep learning is applied in this research for the model development purpose. Deeply interconnected neural networks are used in this method. Sentiment analysis can be used in many different applications, such as market research, brand reputation management, customer feedback analysis, and social media monitoring. It shows the use of sentiment analysis in a variety of fields and increases the need of technology to perform it on the existing machines.
Tokenizers, LSTM Model, Sentiment, NLP, Machine Learning, Binary Text Classification
Short address: https://sciup.org/15018709
IDR: 15018709 | DOI: 10.5815/ijem.2023.05.02
Text of the scientific article An Automated Model for Sentimental Analysis Using Long Short-Term Memory-based Deep Learning Model
The reach of the internet to the public is expanding as it gets bigger. Twitter, Facebook, and Tumblr are the most effective social media and microblogging sites for rapidly disseminating trending topics and condensed news across the globe. When lots of people weigh in with their opinions and judgements on a topic or piece of news, it gets popular and becomes an important source of internet perception on that subject. These subjects are meant to raise awareness or to promote political campaigns, well-known individuals running for office, advertisements, leisure such as award shows and movies, and endorsements. Big businesses and organizations use consumer input from these platforms to improve their goods and services, which helps to improve marketing efforts.
One such instance would be the pre-release marketing of the impending iPhone by leaking images of the device to generate excitement. So, there is a big opportunity for business-driven applications to find and analyze intriguing patterns from endless social media data. Sentiment analysis is the process of identifying emotions in a word, sentence, or corpus of texts. It serves as a tool for analysing the opinions, attitudes, and sentiments expressed in internet mentions [1]. The goal is to be aware of or have access to a summary of general public opinion on a number of issues. It may be used to categories talks as positive, bad, or neutral.
The number of people expressing their views and opinions online is growing along with the rapid advancement of web technologies. Everyone can benefit from this information, including individuals, corporations, and governments. Twitter is evolving into a significant information source with its 500+ million tweets every day. Twitter is a microblogging platform most known for its 140-character messages, or tweets. There is a 140-character restriction. Twitter is a good resource for information because it has 240+ million active users. Users frequently talk about their personal opinions on many topics and current events in tweets. We chose Twitter over other well-known social networking platforms like Facebook, Google+, and Myspace for the following reasons. Sentiment analysis is a developing field of Natural Language Processing, and study in this area ranges from document-level classification to understanding word and phrase polarity. Due to the character limitations for tweets, sentiment classification for Twitter messages is most analogous to sentence-level sentiment analysis [2,3]. Yet, Twitter sentiment analysis is a different issue due to the informal and particular language used in tweets as well as the basic structure of the microblogging domain.
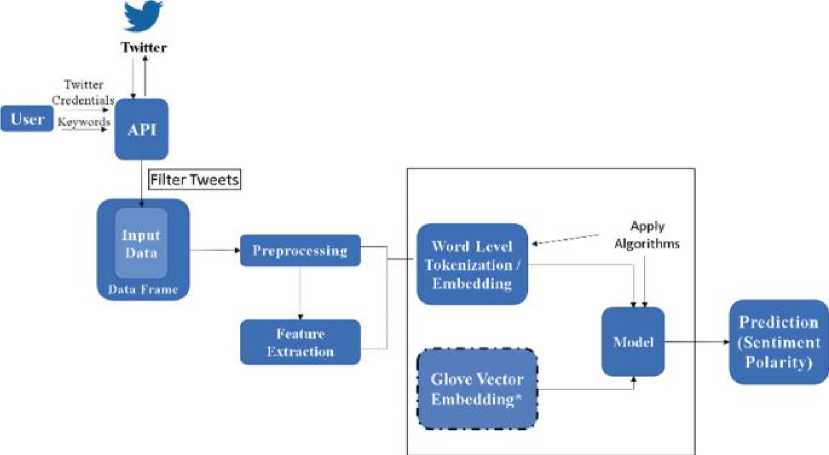
Fig. 1. Process involved in Twitter data sentiment analysis [4]
The method of figuring out the sentiment behind a tweet is called sentiment analysis. This research is mainly focused to develop a model which can identify whether a tweet or other piece of writing is favourable, neutral, or negative. Let's say there is an election in our nation. The government would then begin its campaigning and want to analyze how the public reacted to its advertisements and the tweets of its leaders or party members. To do this, election parties would need to know how the public felt about their actions. To do this, election parties could analyze how the public responded to them on social media platforms and determine whether the public overall approved of them or not. Natural language processing is used in Twitter sentiment analysis to extract, recognize, and characterize the sentiment material.
2. Literature Review
-
[1] Hate speech identification on Twitter is crucial for applications like contentious event extraction, building AI chatterbots, content recommendation, and sentiment analysis. Online social networks have seen a huge increase in social engagement, but there has also been a rise in nasty acts that make use of this infrastructure. Because the manual method of removing nasty tweets is not scalable, experts are looking for automatic alternatives. This research focuses on the issue of identifying if a tweet is racist, sexist, or neither. Due to the complexity of natural language constructs— different types of targets, different kinds of hatred, and various methods to express the same meaning—the endeavour is exceedingly difficult. In this study, we looked into the use of deep neural network architectures to detect hate speech. We discovered that they perform noticeably better than the current approaches. Gradient-boosted decision trees combined with embeddings discovered from deep neural network models produced the best accuracy results.
-
[2] Sentiment analysis is a method of superficially analysing the semantics of texts. Its goal is to generate opinions about numerous interesting subjects from the reader. People may be curious about what consumers think about particular products, what voters think about political parties, or what investors think about stocks, for example.
Sentiment analysis received a lot of attention from the early attempts due to the web and social media's rapid expansion in the 2000s. Many techniques for sentiment analysis have been developed as a result of the proliferation of various sorts of textual information (such as news, blogs, reviews, comments on Facebook and Twitter posts, etc.).
To determine the text's sentiment in the first place, the set of words that have been determined to contain sentiment are employed. In the second example, a sentiment classification model is first created using a significant amount of texts that have been sentiment-labeled, and it is then applied to the stream of unlabeled texts. The model is implemented as a function that turns textual properties into sentiment labels (which typically have discrete values: negative, neutral, or positive).
-
[3] Twitter has developed into a significant social media network and is a topic of great interest for sentiment analysis experts. TSA (Twitter Sentiment Analysis) research is a current area of study in text mining. TSA refers to the employment of computers to process the sentiments and views that are subjective to Twitter data. In this study, a wide range of recently proposed methods and applications are examined along with a complete analysis of the most recent advancements in the field. Social networking services (SNS) have recently exploded in popularity, and as a result, a huge amount of user-generated data, including comments and reviews, is constantly being produced. The information, which is mostly focused on a shared object of interest, expresses people's ideas and sentiments. These data have grown into informational treasure troves, providing several opportunities for evaluating consumer behaviour, which is particularly helpful in predicting product sales, stock market trends, and election results. Sentiment analysis is the focus of the linguistic and natural language processing subfield of opinion mining. It evaluates the degree of polarity of the words and phrases under consideration in order to generate opinions and sentiments from textual data. Given the foregoing, it is evident that the machine-learning-based TSA method is the most often used.
-
[4] The study of how people connect and communicate on various topics is called social network analysis, and interest in it has lately grown. On social media platforms like Facebook and Twitter, millions of people voice their opinions on a wide range of subjects every day. It has a wide range of applications in many academic disciplines, including business and social science. As there are so many posts on social media every day and it might be challenging to extract people's opinions, opinion and sentiment mining are important research areas. Around 90% of the population has received the data for today.
-
[5] The following are the contributions made by this work: (1) We give POS-specific prior polarity features. (2) We look into the use of a tree kernel to reduce the need for laborious feature engineering. The tree kernel outperforms the state-of-the-art baseline, performing roughly on par with the additional features (when paired with previously mentioned features). Microblogging websites have evolved into a source of a wide range of information. This is a result of the nature of microblogs, where users post messages in real time about a variety of subjects, current affairs, complaints, and complimentary remarks for things they frequently use.
Manufacturers of these products have started to read these microblogs to determine how customers feel about their products. We use manually annotated Twitter data for our experiments. These tweets have an advantage over past data sets because they were gathered using a streaming method, accurately reflecting genuine tweets in terms of language use and content. Our recent data collection is accessible to other academics. Sentiment analysis has been regarded as a task in natural language processing at various granularities.
-
[6] Now that it has sophisticated methods for analysing people's opinions, society and organisations might experience a wide range of issues if people are not understood and their perspectives are not taken into consideration. In an era when technology had advanced and communication channels like Twitter, Instagram, and email had experienced substantial changes, we used to convey letters by strolling, which evolved into birds and humans riding horses. Social media sites like Facebook, Instagram, Twitter, and others are used to share knowledge and opinions on various subjects. These websites are producing enormous amounts of data. To analyse this data, a variety of statistical and machine learning technologies are available. Using several methods, we have examined the correctness of the sentiment in this research. The SVM-SGD is the best, according to our research, but after adjusting the grid search and other parameters, the Logistic Regression worked better for us.
-
[7] Emotion is an evaluation of attitudes towards particular occasions or objects. Sentiment analysis of existing data is the process of gathering opinions. This method can also be used to examine the assessments people make on particular items. The internet is the most reliable resource for sentiment analysis. Many people use social media, particularly Twitter, to voice their opinions on various topics in the Covid-19 epidemic era. Users frequently utilise Twitter as their go-to social media platform for posting their ideas online. Soft computing, particularly fuzzy logic, may be used to create, produce, and build bots that can analyse Twitter user opinions. Almost everywhere in the world has experienced a lifestyle change this year. This is because a new human-attacking virus called Coronavirus Disease 2019 has emerged (Covid-19). The term "coronavirus" refers to a group of viruses from the Ortho Coronavirus subfamily that can infect birds and mammals in addition to humans.
-
[8] The authors of this study used the publicly available Stanford University Twitter dataset. Many feature extraction approaches were used to evaluate this labelled dataset. We created a system where the preprocessor was used to improve the readability of the raw sentences.
of the tweet, we used several machines learning methods, including Naive Bayes, Maximum Entropy, Decision Tree, Random Forest, XGBoost, SVM, Multi-Layer Perceptron, Recurrent Neural networks, and Convolutional Neural Networks. Bigrams and unigrams were the two types of features we employed for classification, and we found that adding bigrams to the feature vector increased accuracy. SA is textual contextual mining that extracts subjective information from the source material and recognises it. It also helps businesses understand the social attitude towards their services, brands, or products by monitoring internet chats. SA controls opinions, attitudes, and subjective text.
[17] Using sentiment analysis, these reviews are categorised as either good or negative depending on the opinions expressed in them. The dataset was first preprocessed to turn the unstructured reviews into structured forms. After that, we employed a lexicon-based method to translate the structured evaluation into a numerical score value. We preprocessed the dataset in the lexicon-based technique utilising semantic analysis and feature selection. Preprocessing tasks included stopping word elimination, stemming, and emotion score calculation using the Twitter dataset. Finding user sentiment on a subject or text under study is done through sentiment analysis. It's sometimes referred to as "opinion mining." Therefore it establishes if a piece of writing is constructive, destructive, or neutral.
[18] Due to the enormous volume of opinionated data available on many social networking sites, opinion mining has recently gained attention. Microblogging is a relatively new phenomenon, and Twitter is the most widely used platform for it. One of the largest free, public data sources is this one. Twitter today frequently sees a variety of viewpoints. To better understand the feelings of the general population, academics use sentiment analysis and opinion mining. Twitter is used as a source of opinionated data in this essay.
[19] In this research, the author developed a set of machine learning methods with semantic analysis for categorizing words and product reviews using Twitter data. A pre-labelled Twitter dataset will be used to evaluate a huge number of reviews. Maximum entropy is outperformed by the nave byes method and applying a unigram model to SVM yields results that are superior to using it alone. The accuracy rises to 89.9% from 88.2% when the semantic analysis WordNet is added to the previously mentioned method.
[20] Twitter is a fantastic information source where people from all over the world get together to exchange opinions on various topics. As a result, it offers researchers a wide platform to gather a lot of unreliable information. This rudimentary information processing is used to analyze user opinions. We have examined the many categories of text analysis categorization algorithms based on the results of this survey. The text extraction from the provided data is done using the data mining technique. This information is used to classify the text as good, negative, or neutral. Sentiment analysis is a type of data mining that classifies a piece of content's specific data as positive, negative, or neutral based on its overall tone. Opinion mining, which infers the opinions of people, is another name for sentiment analysis. Sentiment analysis provides us with insight into user opinions of products, events, or movies.
3. Methodology
4. Dataset
Sentiment analysis is an important aspect of determining industry quality. Each industry must get feedback from its end consumers to identify potential or present problems.
Python can do sentiment analysis to detect and evaluate the sentiment concealed inside every piece of text. An intelligent system may be created by combining machine learning and artificial intelligence approaches. These algorithms enable us to comprehend the emotions of any text or do any sort of analysis on a big amount of data. Binary text classifiers are used to extract the emotion of any sentence in this case. Several natural language processing (NLP) approaches were employed for data cleaning and filtration, as well as the development of a text classifier using LSTM Layers. These text classifications help to extract the sentiment from test data.
The dataset was taken from Kaggle named “Twitter US Airline Sentiment”. The dataset comprised about 14000 tweet data samples, which were classified into three categories: Positivity, Negativity, and Neutrality [10]. This dataset is already cleaned, and no null value exists.
As this dataset has a huge number of tuples which can fulfill the need of a large and simple dataset for model developing. It has around 15 attributes and 14k tweets which act as tokens during model training.
The following tools and libraries were used over the data set during the model development:
• Python-
• TensorFlow-
• Pandas-
• Matplotlib-
-
5. Data Preprocessing
There are more than 14000 tweets included in the data set. The dataset looks like the following:
6. Model Building
df.columns
Q Index(['tweet_id', "airline_sentiment', 'airline_sentiment_confidence', 'negativereason', 'negativereason_confidence', 'airline', 'airline sentiment g old', 'name', 'negativereason g old', 'retweet_count', 'text', 'tweet_coord', "tweet_created', 'tweet_location', 'user_timezone'], dtype='object')
Fig. 2. Attributes of the dataset
As binary text classification is used here so it does not need the neutral tweets so rows containing the neutral tweets get dropped here.
Categorical classifiers get applied in this model hence machine will understand only the data represented with numerical values so factorized method gets used to change the categorical values with numerical values. Here positive perceptions get represented with a value of 0 and negative perceptions get represented with 1 [11,12]. Further, it needs to convert the form of data in a manner so that the machine can understand it. In essence, we must turn the content into an array of vector embeddings. Word embeddings are a lovely method to depict the connection between a text's words.
To perform it, we first assign a specific number to each of the individual words and then substitute that word with the assigned number. This includes the tokenization process within the model. In the tokenization process, all the words are extracted from the dataset and get tokenized with the help of Tokenizer. Tokenizers break down all the words of text into small parts referred to as tokens. The fit_on_texts() function links the words with the numbers allocated to them. This relationship is saved in the tokenizer.word_index property as a dictionary. Now, using the text_to_sequence() function, replace each word with its corresponding integers. The length of sentences within the dataset is different so the Padding method gets used to equalize the length of sentences [13].
The LSTM model gets used here for text classification. LSTM layers get used in this artificial intelligence model for natural language processing. The model's architecture is made up of three layers: an embedding layer, an LSTM layer, and a dense layer. The model included the Dropout mechanism inside the LSTM layers to reduce the number of parameters [14]. This Long short-term memory technique is an enhanced version of (RNN).
LSTMs are designed to selectively "remember" or "forget" information over time. They do this by using a set of memory cells that are connected through a series of gates, which regulate the flow of information into and out of the memory cells. The gates consist of sigmoid neural network layers that determine which information to keep or discard.
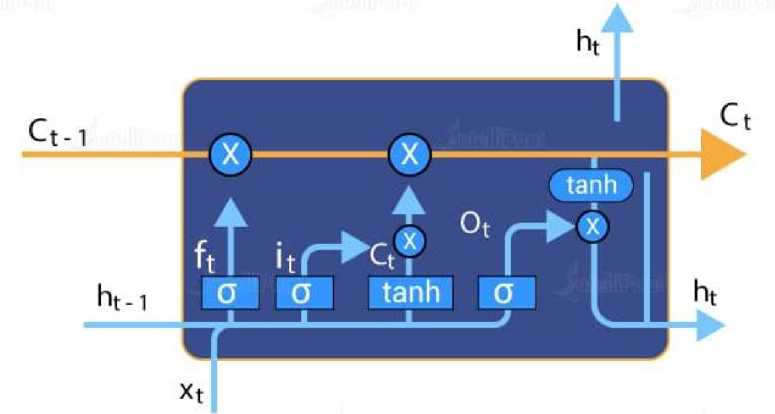
Fig. 3. Working of a deeply connected LSTM network [17].
It works by randomly dropping out (i.e., set to zero) some of the neurons in the neural network during training. During each training iteration, a certain percentage of neurons are randomly selected, and their outputs are set to zero [18,19]. This prevents any individual neuron from being overly dependent on the presence of specific other neurons, which can help the model generalize better to new, unseen data. The layer accepts as its parameter a value between 0 and 1 that specifies the likelihood that the neurons will be dropped.
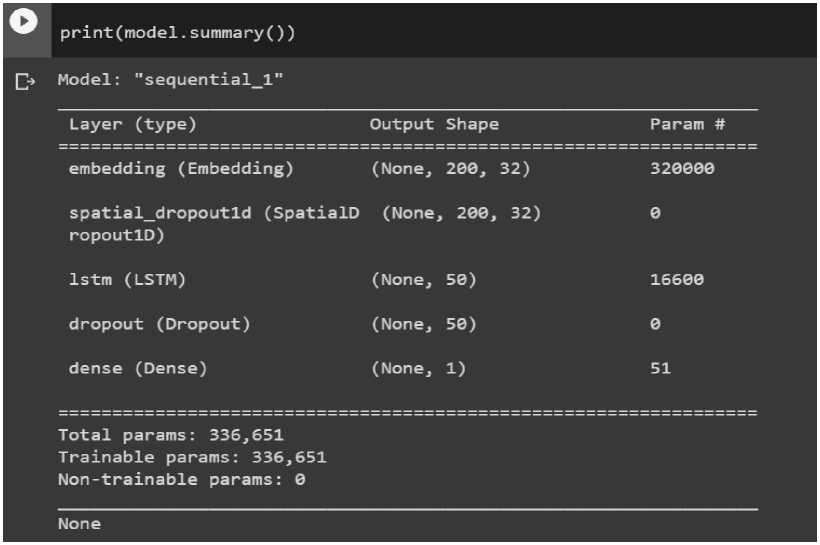
Fig. 4. Model structure after the tokenization and padding process.
7. Model Development
0.96
0.94
0.92
0.90
0.88
0.86
0.84
0.82
0.0 0.5 L0 L5 2.0 2.5 3.0 3.5 40
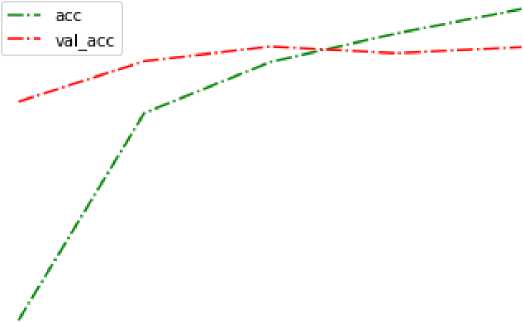
Fig. 5. Comparison graph between accuracy and validation accuracy.
0.40
0.35
0.30
0.25
0.20
0.15
0.10
0.0 0.5 L0 L5 20 25 3.0 3.5 4.0
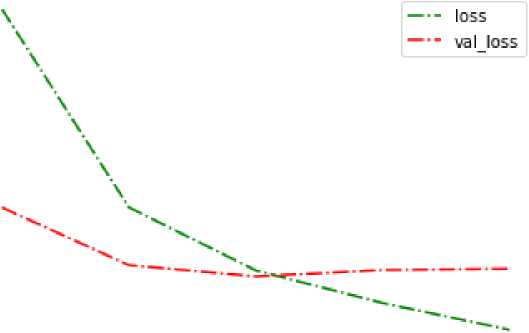
Fig. 6. Comparison graph between loss and validation loss.
8. Result and Discussion
This developed sentimental analysis model is mainly based on the long short-term memory-based neural networks which are focused on binary classification. The model achieved an accuracy of 95% after the completion of all the epochs and their validation [22]. It interprets the sentences or inputs according to their perceptions and gives the output in terms of positive or negative.
t_sentencel = "It is wonderful to fly on this extraordinary journey." predict_sentiment(t_sentencel)
t_sentence2 = "I despise waiting for the release of the latest installment." predict_sentiment(t_sentence2)
^ 1/1 [==============================] - 0s 50ms/step Predicted label: positive
1/1 [==============================] - 0s 58ms/step Predicted label: negative
Fig. 7. Outcome window of the model specifies perception.
9. Conclusion
Sentiment analysis is the practice of examining textual information to identify the writer's attitude or sentiment. Finding the overall attitude of a text, whether it be favorable, negative, or neutral, is the aim of sentiment analysis. In recent times, sentiment analysis has become an important tool for businesses and organizations to gain insights into customer feedback, track brand reputation, and improve their products and services. sentiment analysis is a valuable technique that can provide insights into the emotions and attitudes expressed in large volumes of text data.
Here developed automated sentiment analysis model can extract the perception from the individual input sentence or the collection of huge data. This model is based on the LSTM technique and achieved nearly 95% accuracy which states that the LSTM technique is efficient in the development of these types of NLP-based text classification needs. This model is useful in all types of business domains to take feedback from the end customers and know their perceptions.
References An Automated Model for Sentimental Analysis Using Long Short-Term Memory-based Deep Learning Model
- S. Mishra, M. Aggarwal, S. Yadav and Y. Sharma, "Comparison of Machine Learning Techniques for Sentiment Analysis," 2023 3rd International Conference on Advances in Computing, Communication, Embedded and Secure Systems (ACCESS), Kalady, Ernakulam, India, 2023, pp. 184-191, doi: 10.1109/ACCESS57397.2023.10200806.
- Igor Mozeti , Miha Grˇcar , Jasmina Smailovi , “Multilingual Twitter Sentiment Classification: The Role of Human Annotators” , 5 May 2016.
- Yili Wang , Jiaxuan Guo , Chengsheng Yuan and Baozhu Li , “Sentiment Analysis of Twitter Data” , 19 November 2022
- https://link.springer.com/chapter/10.1007/978-3-031-05767-0_12.
- Hamid Bagheri , Md Johirul Islam , “Sentiment analysis of twitter data”.
- Apoorv Agarwal, Boyi Xie , Ilia Vovsha, Owen Rambow , Rebecca Passonneau , “Sentiment Analysis of Twitter Data”.
- VANAMA YASWANTH , VIDHI MATHUR , SNEH SINGH, “Sentiments Analysis Using Tweets” , 31 May 2022.
- Devi Ajeng Efrilianda , Erika Noor Dianti , Oktaria Gina Khoirunnisa, “Analysis of twitter sentiment in COVID-19 era using fuzzy logic method” , 12 March 2021.
- Vishal A. Kharde , S.S. Sona “Sentiment Analysis of Twitter Data: A Survey of Techniques” , 11 April 2016
- Dr.Jyothi Mandala,Pragada Akhila, Uriti Archana , “An Exploration of Sentiment Analysis using Twitter Dataset” , 18 November 2020.
- Dwivedi, R.K., Aggarwal, M., Keshari, S.K., Kumar, A. (2019). Sentiment Analysis and Feature Extraction Using Rule-Based Model (RBM). In: Bhattacharyya, S., Hassanien, A., Gupta, D., Khanna, A., Pan, I. (eds) International Conference on Innovative Computing and Communications. Lecture Notes in Networks and Systems, vol 56. Springer, Singapore.
- Md. Rakibul Hasan , Maisha Maliha , M. Arifuzzaman , “Sentiment Analysis with NLP on Twitter Data” ,July 2019.
- Anupama B , Rakshith D B, Rahul Kumar M, Navaneeth M , “Real Time Twitter Sentiment Analysis using Natural Language Processing” , 7 July 2020.
- Abdullah Alsaeedi , Mohammad Zubair Khan , “A Study on Sentiment Analysis Techniques of Twitter Data” 2019.
- K. Arun , A. Srinagesh , “Multi-lingual Twitter sentiment analysis using machine learning” , 6 December 2020.
- Saurabh Singh , “Twitter Sentiments Analysis Using Machine Learning” , 27 July 2020.
- https://intellipaat.com/blog/whatislstm/#:~:text='%20LSTM%20stands%20for%20long%20short,especially%20in%20sequence%20predict ion%20problems
- Dr. Pamela Vinitha Eric, Anu Priya K R , “ Twitter Sentimental Analysis using Deep Learning Techniques” , 5 August 2020.
- Dr. P. Sumathy , S. M. Muthukumari , “Sentiment Analysis of Twitter Data Using Multi Class Semantic Approach” , 24 July 2018.
- Ankita Sharma, Udayan Ghose , “Sentimental Analysis of Twitter Data with respect to General Elections in India” , 2020
- Md Ashique , Satyam Kumar , Aanchal Vij , Swapnil Panwar , “Sentiment Analysis Using machines Learning Approaches of Twitter Data and Semantic Analysis” , 2021.
- Pratima Deshpande , Purva Joshi , Diptee Madekar , Pratiksha Pawar , Prof. M.D. Salunke ,” A Survey On: Classification of Twitter data Using Sentiment Analysis”.
