An Evolving Cascade System Based on a Set of Neo - Fuzzy Nodes

Author: Zhengbing Hu, Yevgeniy V. Bodyanskiy, Oleksii K. Tyshchenko, Olena O. Boiko
Journal: International Journal of Intelligent Systems and Applications(IJISA) @ijisa
Article in issue: 9 vol.8, 2016.
Free access
Neo-fuzzy elements are used as nodes for an evolving cascade system. The proposed system can tune both its parameters and architecture in an online mode. It can be used for solving a wide range of Data Mining tasks (namely time series forecasting). The evolving cascade system with neo-fuzzy nodes can process rather large data sets with high speed and effectiveness.
Computational Intelligence, Machine Learning, Cascade System, Data Stream Processing, Neuro-Fuzzy System, Neo-Fuzzy System
Short address: https://sciup.org/15010852
IDR: 15010852
Text of the scientific article An Evolving Cascade System Based on a Set of Neo - Fuzzy Nodes
Published Online September 2016 in MECS
The task of time series forecasting (data sequences forecasting) is well studied nowadays. There are many mathematical methods of different complexity that can be used for solving this task: spectral analysis, exponential smoothing, regression, advanced intellectual systems, etc. In many real-world cases, analyzed time series are non-stationary, nonlinear, and usually contain unknown behavior trends, stochastic or chaotic components. This obstacle complicates time series forecasting and makes the above mentioned systems less effective.
To solve this problem, nonlinear models based on mathematical methods of Computational Intelligence [1-3] can be used. It should be especially mentioned that neuro-fuzzy systems [4-6] are widely used for this type of tasks due to their approximating and extrapolating properties, results’ interpretability, and learning abilities. The most appropriate choice for non-stationary data processing is evolving connectionist systems [7-10]. These systems adjust not only their synaptic weights and parameters of membership functions, but also their architectures.
There are many evolving systems that are able to process data sets in an online mode. Most of them are based on multilayer neuro-fuzzy systems. The Takagi-Sugeno-Kang (TSK) fuzzy systems [11-12] and adaptive neuro-fuzzy inference systems (ANFIS) are the most popular and effective systems that are used to solve such tasks. But in some cases (e.g. when a size of a data set is not sufficient for training) they cannot rapidly tune their parameters, so their effectiveness can significantly decrease.
The first solution for this problem is to decompose an initial task into a set of simpler tasks, so that the obtained system can solve a problem with a data set at hand regardless to its size. One of the most studied approaches based on this principle is the Group Method of Data Handling (GMDH) [13-14]. But in case of online data processing, the GMDH systems are not sufficiently effective. This problem can be solved by an evolving cascade model that tunes both its parameters and its architecture in an online mode.
Generally speaking, one can use different types of neurons or other more complicated systems as nodes in an evolving cascade system. For example, a compartmental R-neuron was introduced as a node of a cascade system [15, 16]. If a data set to be processed is large enough, it seems reasonable to use neo-fuzzy neurons [17-19].
The neo-fuzzy neuron is capable of finding a global minimum for a learning criterion in an online mode, it also has a high learning speed and good approximating properties. It is also appropriate from the viewpoint of computational simplicity.
The remainder of this paper is organized as follows: Section 2 describes an architecture of the evolving cascade system. Section 3 describes an architecture of the neo-fuzzy neuron as a node of the evolving cascade system along with several procedures that can be used for tuning of the neo-fuzzy node parameters. Section 4 presents several synthetic and real-world applications to be solved with the help of the proposed evolving cascade system. Also a comparative analysis of the proposed system and other similar systems is presented. Conclusions and future work are given in the final section.
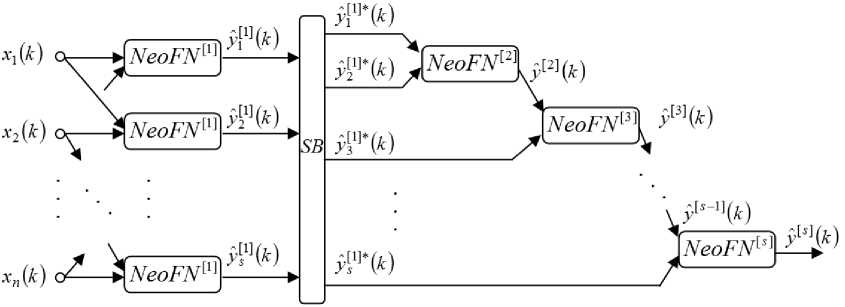
Fig.1. An architecture of the evolving cascade model.
-
II. AN EVOLVING CASCADE MODEL
Taking into consideration all the facts described above, an evolving cascade model based on neo-fuzzy nodes (NeoFNs) is demonstrated in this section.
An architecture of the evolving cascade model is shown in Fig. 1. A (nx1) -dimensional vector of input signals x(k) = (x1 (k), x2 (k),..., xn (k))T is fed to the zero layer of the system (here k = 1, 2,... is an index of the current discrete time). The first hidden layer contains cn2 nodes (each one has two inputs). Here cn2 denotes the number of combinations of two input elements from the set of inputs with size n . The outputs of the first hidden layer form signals y^ (k) , 5 = 1,2,...,0,5 n (n -1) = c2 . Then these signals are fed to the selection block SB that sorts the first layer nodes by some criteria (e.g. by the mean squared error a2 ) so that y5 ] (k) 222
° У Р’Ч k ) < ^ y 1 *(k ) < ° У ^Ч k ) .
The outputs y [ 1 ] * ( k ) and y 2 1 ] * ( k ) of the selection block are fed to a unique neuron of the second layer which forms its output signal y [2] ( k ) . This signal and the signal y 3 1 ] * ( k ) (an output signal of the selection block SB ) are fed to a node of the next layer. A process of the cascades’ increasing is continued until a required accuracy is obtained.
-
III. THE NEO-FUZZY SYSTEM AS A NODE OF THE EVOLVING CASCADE SYSTEM
Neo-fuzzy neurons were proposed by T. Yamakawa and co-authors [17-19]. Advantages of this block are good approximating properties, computational simplicity, a high learning speed, and ability of finding a global minimum for a learning criterion in an online mode. An architecture of the neo-fuzzy neuron as a node of the evolving cascade system is shown in Fig.2.
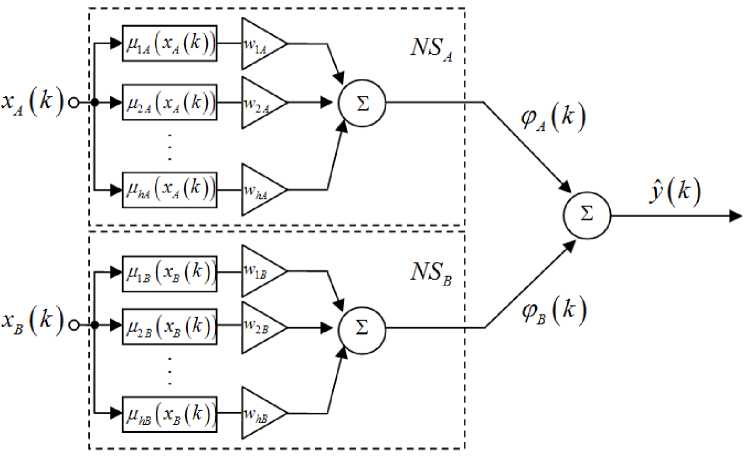
Fig.2. An architecture of the neo-fuzzy neuron.
Nonlinear synapses NSA and NSB which are structural elements of the neo-fuzzy neuron fulfill the Takagi– Sugeno fuzzy inference of the zero order. A twodimensional vector of input signals x ( k ) = ( xA ( k ) , xB ( k ))T is fed to the node’s input. The first layer of each nonlinear synapse contains h membership functions. In [20], it was proposed to use the B-splines as membership functions for the neo-fuzzy neuron. B-splines provide higher approximation quality. A B-spline of the q -th order has the form
|
Pu ( x A ( k ) ) = • |
1if c iA < x A ( k ) < c i + 1, A . , > for q = 1 0 otherwise I xA ( k ) ciA q - -1/ |
|
P iA ( x A ( k ) ) 1 c i + q - 1, A ci A + q , _ ( ) P i ^1, A ( x A ( k ) ) for q > 1 c i + q , A c i + 1, A i — 1,..., h - q , |
1if ciB < xB (k )< ci+1, B ,L, v ' , ^ for q = 1
0 otherwise
P qB ( x B ( k ) ) = •
xB(k)-ciB PB"'(x(k)) + ci+q-1, BciB i+q, B _B( ) pq+1 b (xB (k)) for q >1
ci+q, B ci+1, B i = 1,..., h - q.
where ciA and ciB are parameters that define centers of the membership functions.
It should be noticed that when q = 2 one can get traditional triangular membership functions, and when q = 4 one can get cubic splines, etc. The B-splines meet the unity partitioning conditions
h
E ^ pA ( x A ( k ) ) = 1,
-
< p = 1
I h
E ^ PB ( x B ( k ) ) = 1
. p = 1
that allows to simplify the node’s architecture by excluding a normalization layer.
So, the elements of the first layer compute membership levels P pA ( x A ( k ) ) , P pB ( x B ( k ) ) , P = 1,2,..., h .
The second layer contains synaptic weights wiA and wiB that are adjusted during a learning process according to the procedures written below.
The third layer is formed by two summation units. It computes sums of the output signals of the second layer for each nonlinear synapse NSA and NSB . The outputs of the third layer are values
Ф а ( k 1 E w P ( x A ( k ) ) ,
P = 1
h
Ф в ( k ) = E w pB P pB ( x B ( k ) ) .
p = 1
Another summation unit sums up these two signals in order to produce the output signal y (k ) of the node y ( k ) = Фа ( k ) + Фв ( k ) = hh (1)
= E wpAMpA ( x A ( k ) ) + E wpBMpB ( x B ( k ) ) p = 1 p = 1
The expression (1) can be written in the form
y ( k ) = w T ( k ) ф ( k )
where w ( k ) = ( w 1 A ( k ) , ..., w hA ( k ) , w 1 в ( k ) , ..., w hB ( k ) ) T ,
Ф ( k ) = ( P 1 A ( x A ( k ) ) , ..., P hA ( x A ( k ) ) , P 1B ( x B ( k ) ) , ...,
P hB ( x B ( k ) ) ) T .
To learn the neo-fuzzy neuron, we can use the procedure [21, 22]
w ( k ) = w ( k - 1 ) + r - 1 ( k ) ( y ( k ) - w T ( k - 1 ) ф ( k ) ) ф ( k ) (2)
r ( k ) = a r ( k - 1 ) + ф T ( k ) ф ( k ) , 0 < a < 1
which possesses both filtering and tracking properties. It can be noticed that when a = 1 the procedure (2) coincides with the Kaczmarz–Widrow–Hoff optimal gradient algorithm
, _ , _ y ( k ) - w T ( k - 1 ) ф ( k ) , _
w ( k ) = w ( k " 1 )+ Ф T ( k ) ф ( k , ф ( k ’
• I - 1
) 2
that can be used if a training data set is non-stationary [23].
-
IV. EXPERIMENTS
In order to prove the effectiveness of the proposed system, several simulation tests were implemented. The system’s effectiveness was analyzed by a value of the root mean square error (RMSE) and data processing time measured in seconds.
-
A. A nonlinear system
A nonlinear system to be identified can be described by the equation
m
I y.- i y = —^-- 1 + I ( y.- i i = 1
where u. = sin(2n./20), yj = 0 , j = 1,..., m , m = 10. The model is presented in the form yt = f (y.-1, y.-2,-, y.-10, ut-1 )
where y ˆ t stands for a model’s output. The aim was to predict the next output result using previous inputs and outputs.
This data set contains 2500 points: 2000 points were selected for a training stage and 500 points were used for testing.
To compare results, we used a multilayer perceptron (MLP), a radial-basis function neural network (RBFN), an adaptive neuro-fuzzy inference system (ANFIS), and the proposed evolving cascade system with the neo-fuzzy nodes.
MLP was being learnt during five epochs. A number of MLP’s inputs was equal to 5 and a number of hidden nodes was equal to 10. A total number of parameters to be tuned was equal to 51.
In the RBFN’s architecture, we used 3 inputs and 11 kernel functions, so a total number of parameters to be tuned in the RBFN’s system was roughly equal to 56, which is almost the same as for the proposed system (it had 54 parameters to be tuned).
One of the best results was shown by ANFIS, but it was processing data during 5 epochs and a little longer than the proposed system, so it cannot process data in an online mode. ANFIS had 3 inputs and 34 hidden nodes. A total number of parameters to be adjusted was equal to 32.
The proposed evolving cascade system had 3 inputs and 4 membership functions in each node. A total number of parameters to be adjusted was 54. The proposed system demonstrated the best prediction results (RMSE on the test set is 0.0462), and its data processing time was the best among the others (0.3281 s).
A comparison of the systems’ results is shown in Table 1.
Table 1. Comparison of the systems’ results
|
Systems |
Parameters to be tuned |
RMSE (training) |
RMSE (test) |
Time, s |
|
MLP |
51 |
0.0173 |
0.0178 |
0.5313 |
|
RBFN |
56 |
0.0990 |
0.0993 |
0.4828 |
|
ANFIS |
32 |
0.0070 |
0.0085 |
0.3625 |
|
The proposed system |
54 |
0.0413 |
0.0462 |
0.3281 |
Prediction results for the proposed system are in Fig.3 (a blue line represents signal’s values, a magenta line represents prediction values, and a grey line represents prediction errors). A phase portrait of the signal is shown in Fig.4.
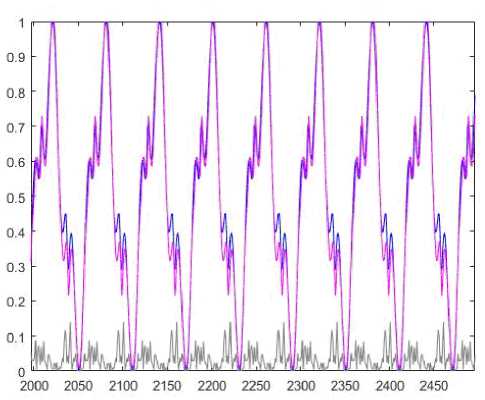
Fig.3. Prediction results.
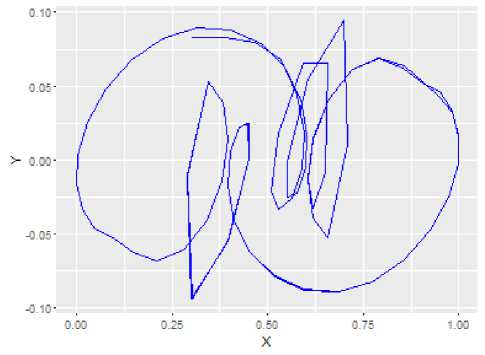
Fig.4. A phase portrait of the signal.
-
B. Internet traffic data (in bits) from an ISP
This data set describes hourly traffic in the United Kingdom academic network backbone (taken from datamarket.com). It was collected between November 19th, 2004, at 09:30 and January 27th, 2005, at 11:11. This data set contains 1657 points: 1326 points were selected for a training stage and 331 points were used for testing.
To compare results, a similar to the previous experiment set of systems was used but with other characteristics.
MLP was being learnt during one epoch (this case is similar to learning in an online mode). A number of MLP’s inputs was equal to 3 and a number of hidden nodes was equal to 8. A total number of parameters to be tuned was 31.
In the RBFN’s architecture, 7 kernel functions and 3 inputs were used, so a total number of parameters to be adjusted in the RBFN system was roughly equal to that of the proposed system.
ANFIS had 4 inputs and 55 hidden nodes. It was processing data during 5 epochs. A total number of parameters to be tuned was 80. This system showed the best prediction result, but it was processing data longer than the proposed system.
The proposed evolving cascade system had 4 inputs and 4 membership functions in each node. A total number of parameters to be tuned was 36. The proposed system showed one of the best prediction results according to RMSE (the second result after ANFIS), and its data processing time was the best among the others.
We used B-splines (q=2) as membership functions for our system which are actually triangular membership functions (Fig.5) for this case (uniformly distributed in a range).
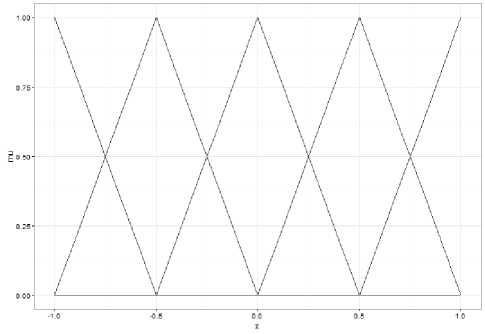
Fig.5. Triangular membership functions.
A comparison of the systems’ results is shown in Table 2.
Table 2. Comparison of the systems’ results
|
Systems |
Parameters to be tuned |
RMSE (training) |
RMSE (test) |
Time, s |
|
MLP |
31 |
0.0682 |
0.0755 |
0.2656 |
|
RBFN |
36 |
0.1038 |
0.1114 |
0.2562 |
|
ANFIS |
80 |
0.0265 |
0.0270 |
0.2031 |
|
The proposed system |
36 |
0.0636 |
0.0550 |
0.1718 |
Prediction results for the proposed system are in Fig.6.
A phase portrait of the signal is in Fig.7.
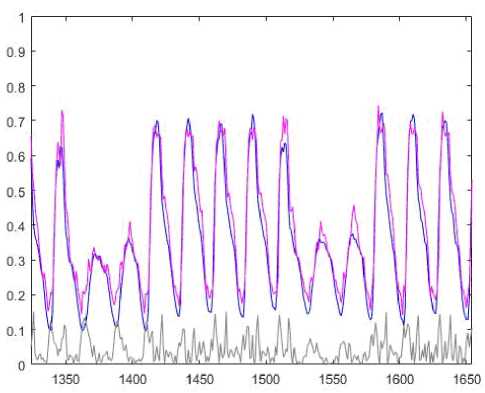
Fig.6. Prediction results.
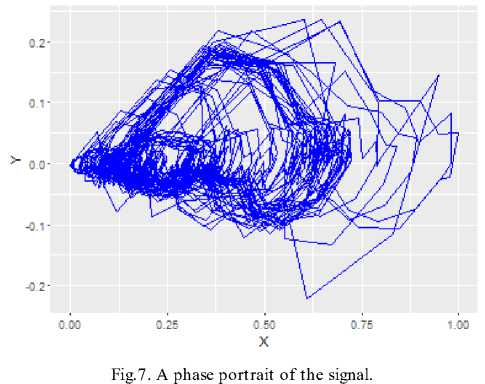
-
C. Darwin Sea Level Pressures
This data set was taken from research.ics.aalto.fi. This data set describes monthly values of the Darwin sea level pressure. It was collected between 1882 and 1998. This data set contains 1300 points: 1040 points were selected for a training stage and 260 points were used for testing.
MLP was being learnt during five epochs. It had 3 inputs and 10 hidden nodes. A total number of parameters to be adjusted was equal to 41.
RBFN had 7 kernel functions and 3 inputs, and a total number of parameters to be tuned in the RBFN system was equal to 36, i.e. it was very close to a number of parameters in the proposed system that had 40 parameters to be tuned.
A number of inputs for ANFIS was 4, a number of hidden nodes was equal to 55. ANFIS was processing data during one epoch. A total number of parameters to be tuned was equal to 80. This system showed the best result from the view point of accuracy, but it was processing data longer than the proposed system.
The proposed evolving cascade system had 3 inputs and 4 membership functions in each node. A total number of parameters to be tuned was 40. The proposed system showed one of the best results, and its data processing time was the best.
A comparison of the systems’ results is shown in Table 3.
Table 3. Comparison of the systems’ results
|
Systems |
Parameters to be tuned |
RMSE (training) |
RMSE (test) |
Time, s |
|
MLP |
41 |
0.0843 |
0.0886 |
0.4844 |
|
RBFN |
36 |
0.1495 |
0.1512 |
0.2391 |
|
ANFIS |
80 |
0.0756 |
0.0866 |
0.2031 |
|
The proposed system |
40 |
0.1159 |
0.1483 |
0.1250 |
Prediction results for the proposed system are in Fig.8.
A phase portrait of the signal is in Fig.9.
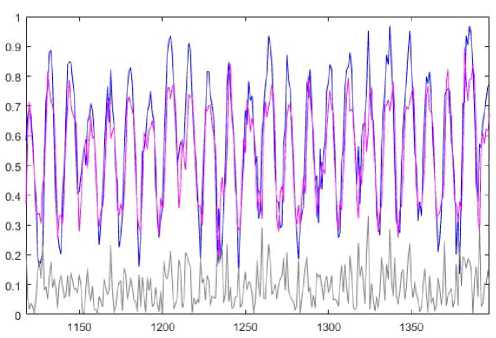
Fig.8. Prediction results.
Fig.9. A phase portrait of the signal.
V. CONCLUSION
An evolving cascade model based on the neo-fuzzy nodes is proposed. It can adjust both its architecture and parameters in an online mode. The proposed system has a rather simple computational implementation and can process data sets with a high speed. A number of experiments demonstrated that this evolving cascade system can forecast time series with high effectiveness.
The results may be successfully used in a wide class of Data Stream Mining and Dynamic Data Mining tasks.
ACKNOWLEDGMENT
The authors would like to thank anonymous reviewers for their careful reading of this paper and for their helpful comments.
This scientific work was supported by RAMECS and CCNU16A02015.
References An Evolving Cascade System Based on a Set of Neo - Fuzzy Nodes
- Du K-L, Swamy M N S. Neural Networks and Statistical Learning. Springer-Verlag, London, 2014.
- Kruse R, Borgelt C, Klawonn F, Moewes C, Steinbrecher M, Held P. Computational Intelligence. Springer, Berlin, 2013.
- Rutkowski L. Computational Intelligence. Methods and Techniques. Springer-Verlag, Berlin-Heidelberg, 2008.
- Jang J-S, Sun C-T, Mizutani E. Neuro-Fuzzy and Soft Computing: A Computational Approach to Learning and Machine Intelligence. Prentice Hall, Upper Saddle River, 1997.
- Arora N, Saini J R. Estimation and Approximation Using Neuro-Fuzzy Systems. International Journal of Intelligent Systems and Applications(IJISA), 2016, 8(6): 9-18.
- Karthika B S, Deka P C. Modeling of Air Temperature using ANFIS by Wavelet Refined Parameters. International Journal of Intelligent Systems and Applications(IJISA), 2016, 8(1): 25-34.
- Lughofer E. Evolving Fuzzy Systems – Methodologies, Advanced Concepts and Applications. Springer, Berlin, 2011.
- Kasabov N. Evolving Connectionist Systems. Springer-Verlag, London, 2003.
- Kasabov N. Evolving fuzzy neural networks: theory and applications for on-line adaptive prediction, decision making and control. Australian J. of Intelligent Information Processing Systems, 1998, 5(3):154 160.
- Kasabov N. Evolving fuzzy neural networks – algorithms, applications and biological motivation. Proc. “Methodologies for the Conception, Design and Application of Soft Computing”, Singapore, 1998:271 274.
- Sugeno M, Kang G T. Structure identification of fuzzy model. Fuzzy Sets and Systems, 1998, 28:15 33.
- Takagi T, Sugeno M. Fuzzy identification of systems and its applications to modeling and control. IEEE Trans. on Systems, Man, and Cybernetics, 1985, 15:116 132.
- Ivakhnenko A G. Heuristic self-organization in problems of engineering cybernetics. Automatica, 1970, 6(2): 207- 219.
- Ivakhnenko A G. Polynomial theory of complex systems. IEEE Trans. on Systems, Man, and Cybernetics, 1971, 1(4): 364-378.
- Bodyanskiy Ye, Grimm P, Teslenko N. Evolving cascade neural network based on multidimensional Epanechnikov’s kernels and its learning algorithm. Int. J. Information Technologies and Knowledge, 2011, 5(1): 25-30.
- Bodyanskiy Ye, Teslenko N, Grimm P. Hybrid evolving neural network using kernel activation functions. Proc. 17th Zittau East-West Fuzzy Colloquium, Zittau/Goerlitz, Germany, 2010:39 46.
- Miki T, Yamakawa T. Analog implementation of neo-fuzzy neuron and its on-board learning. In: Computational Intelligence and Applications, 1999:144 149.
- Yamakawa T, Uchino E, Miki T, Kusanagi H. A neo fuzzy neuron and its applications to system identification and prediction of the system behavior. Proc. 2nd Int. Conf. on Fuzzy Logic and Neural Networks “IIZUKA-92”, Iizuka, Japan, 1992:477 483.
- Uchino E, Yamakawa T. Soft computing based signal prediction, restoration, and filtering. In: Intelligent Hybrid Systems: Fuzzy Logic, Neural Networks, and Genetic Algorithms, 1997:331 349.
- Kolodyazhniy V, Bodyanskiy Ye. Cascaded multiresolution spline-based fuzzy neural network. Proc. Int. Symp. on Evolving Intelligent Systems, Leicester, UK, 2010: 26-29.
- Otto P, Bodyanskiy Ye, Kolodyazhniy V. A new learning algorithm for a forecasting neuro-fuzzy network. Integrated Computer-Aided Engineering, 2003, 10(4): 399- 409.
- Bodyanskiy Ye, Kokshenev I, Kolodyazhniy V. An adaptive learning algorithm for a neo-fuzzy neuron. Proc. 3-rd Int. Conf. of European Union Soc. for Fuzzy Logic and Technology (EUSFLAT’03), Zittau, Germany, 2003: 375-379.
- Bodyanskiy Ye, Viktorov Ye. The cascade neo-fuzzy architecture using cubic-spline activation functions. Int. J. Information Theories & Applications, 2009, 16(3): 245-259.
