An Extended Neo-Fuzzy Neuron and its Adaptive Learning Algorithm

Author: Yevgeniy V. Bodyanskiy, Oleksii K. Tyshchenko, Daria S. Kopaliani
Journal: International Journal of Intelligent Systems and Applications(IJISA) @ijisa
Article in issue: 2 vol.7, 2015.
Free access
A modification of the neo-fuzzy neuron is proposed (an extended neo-fuzzy neuron (ENFN)) that is characterized by improved approximating properties. An adaptive learning algorithm is proposed that has both tracking and smoothing properties and solves prediction, filtering and smoothing tasks of non-stationary “noisy” stochastic and chaotic signals. An ENFN distinctive feature is its computational simplicity compared to other artificial neural networks and neuro-fuzzy systems.
Learning Method, Neuro-Fuzzy System, Extended Neo-Fuzzy Neuron, Computational Intelligence
Short address: https://sciup.org/15010655
IDR: 15010655
Text of the scientific article An Extended Neo-Fuzzy Neuron and its Adaptive Learning Algorithm
Published Online January 2015 in MECS
Artificial neural networks (ANNs) are currently widely used for solving different Data Mining tasks due to their approximating capabilities and their ability to learn from experimental data [1-3]. However, when the data come sequentially in real time, many neural networks lose their effectiveness because of the multiepoch learning (which is used in many ANNs and designated only for a batch mode). Of course, radial-basis-function networks (RBFN) could be used in such situations. These ANNs are characterized by a high speed of learning processes, but, first of all, these networks suffer from the so-called «curse of dimensionality» and, secondly, even a trained neural network is a «black box», and its results can not be interpreted. Hybrid systems of computational intelligence [5-7], and above all neuro-fuzzy systems (NFSs), combining the advantages of ANNs and fuzzy inference systems (FISs), do not suffer from the “curse of dimensionality” and provide linguistic interpretability and transparency of the results. However, since most of the well-known NFSs are trained with the help of the error backpropagation concept, they are ill-equipped to work in an online mode.
Due to the above mentioned problems, we would like to develop hybrid systems of computational intelligence that deal with processing the incoming data in an online mode and have advantages of both ANNs and NFSs.
The remainder of this paper is organized as follows: Section 2 gives a neo-fuzzy neuron architecture. Section 3 describes an extended neo-fuzzy neuron architecture. Section 4 presents experiments and evaluation. Conclusions and future work are given in the final section.
-
II. The Neo-Fuzzy Neuron Architecture
To overcome the above mentioned problems, a neuro-fuzzy system called by the authors a “neo-fuzzy neuron (NFN)” was introduced in [8 – 10]. The architecture of the neo-fuzzy neuron is in fig.1.
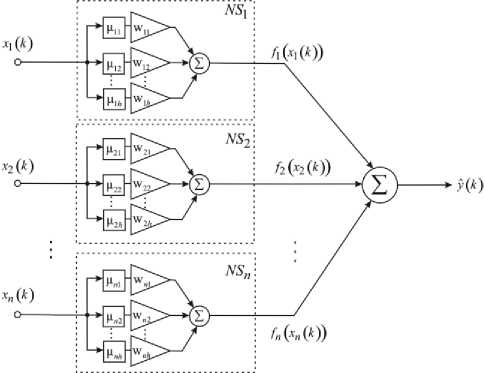
Fig. 1. A neo-fuzzy neuron
The neo-fuzzy neuron is a nonlinear learning system with multiple inputs and one output that implements the mapping
n y=E fi (x) (1)
= 1
where x is the i -th component of the n -dimensional input signal vector x = ( x t,..., x ,..., xn ) T e R n , y is a scalar NFN output. The NFN structural blocks are nonlinear synapses NS that carry out a nonlinear transformation of the i -th component of x in the form
h fi (xi) = £wupu^x,-) (2)
= 1
where w is the l-th synaptic weight of the i-th nonlinear synapse, l = 1,2,...,h , i = 1,2,...,n ; M (x) is the l-th membership function in the -th nonlinear synapse performing fuzzification of a crisp component x . Thus, transformation implemented by the NFN can be written as nh y = УУwiMii (xi).
Fuzzy inference implemented by the same NFN has the form
IF x IS X THEN THE OUTPUT IS wh, i = 1,2,...,h ,
which means that a nonlinear synapse actually implements the zero-order Takagi-Sugeno fuzzy inference [11, 12].
The NFN authors [8–10] used traditional triangular constructions as membership functions that meet the unity partition conditions xi - ci-1,i cii - ci-i,i
if x i G [ c i - i, i , c n J ,
Mu ( x i ) =
c l + 1, i xi .r _ Г 1
------------ if xi ^L c ii , c i + i. i J , c i + i, i - c ii
0 otherwise
where c stands for arbitrarily selected (usually uniformly distributed) centers of the membership functions in the interval [0, 1] , thus, naturally 0 < x. < 1.
Such a choice of the membership functions leads to the fact that the i -th component of the input signal x activates only two adjacent functions, thus their sum is equal to 1 which means that
M ii ( x i ) + M i + 1, i ( x i ) = 1
and f (xi) = wiMi (xi) + wi+1,iMi+1,i (xi) . (7)
Just exactly this circumstance allows to synthesize simple and effective adaptive controllers for nonlinear control objects [13, 14].
One can use other membership functions except triangular constructions, first of all, B-splines [15] that proved their effectiveness in the neo-fuzzy neurons [16]. A general case of the membership functions based on the q -th degree B-spline can be presented in the form
. 1 if xi G [ cii, ci+1, iJ > 0 otherwise for q =L
m IB ( x i , q ) = <
xi ci Ml (x,q —1) + ci+q-1, i cii
+ i + q ’ i ' М + 1Д x i , q — 1 ) for q > 1,
C i + q,i- c. + 1i
. i = 1,2,..., h - q .
When q = 2 , we obtain the traditional triangular functions. It should be mentioned that B-splines also provide the unity partition in the form
h
У m b ( x i , q ) = L i = 1
they are non-negative which means that mI (xi, q )^ 0
and have a local support
Ml ( x i , q ) = 0 for x i ^ [ c ii , c + q , i J .
When the vector signal
x(k) = (x1 (k),...,xi (k),...,xn (k))T ( k = 1,2,... - the current discrete time) is fed to the NFN input, a scalar value is calculated at the NFN output nh y (k)=УУ wii (k-1) Mu (xi (k)) (9)
i = 1 i = 1
where wu ( k - 1 ) is the current value of adjusted synaptic weights that were obtained from a learning procedure of the previous ( k - 1 ) observations.
Introducing a ( nh x 1 ) - membership functions vector m ( x ( k ) ) = ( M 11 ( x 1 ( k ) ) ,-.-, M h1 ( x 1 ( k ) ) , M 12 ( x 2 ( k ) ) ,...,
Mii( x( k)),..., Mhn (xn (k))) and a corresponding synaptic weights vector
w ( k - 1 ) = ( W 11 ( k - 1 ) ,..., w h1 ( k - 1 ) , w 12 ( k - 1 ) ,-, w ii ( k - 1 ) ,
,whn (k- 1))T , we can write the transformation (9) implemented by the NFN in a compact form y (k) = wT (k-1)m(x(k)). (10)
To adjust the neo-fuzzy neuron parameters, the authors used a gradient procedure that minimizes the learning criterion
E ( k ) = 1 ( y ( k )- y ( k ) ) 2 = 1 e 2
nh
=т| y(k )-ZZ wii Ma (xi( k))
-
2 V i = 1 i = 1
and has the form wii (k) = wii (k -1) + ne (k) Mii (x
= w ii ( k - 1 ) + n ( y ( k )- y ( k ) ) Mh
= wii(k -1)+ nh
( k ) =
2 (11)
i ( k ) ) =
■ ( x i ( k ) ) =
+n | y ( k ) - УУ w ii ( k - 1 ) M ii ( x i ( k ) ) I M ii ( x ( k ) ) V i = 1 i = 1 7
where y ( k ) is an external reference signal, e ( k ) is a learning error, n is a learning rate parameter.
A special algorithm was proposed in [17] to accelerate the NFN learning procedure which has both tracking (for non-stationary signal processing) and filtering properties (for "noisy" data processing)
w ( k ) = w ( k -1) + r 1 ( k ) e (k ) a( x (k )), r(k) = ar(k -1) + ||a(x(k))|| ,0 < a < 1.
When a = 0, the algorithm (13) is identical to the one-step Kaczmarz-Widrow-Hoff learning algorithm [18] and when a = 1 - to the Goodwin-Ramage-Caines stochastic approximation algorithm [19].
It should be mentioned that one can use many other learning and identification algorithms including the traditional least-squares method with all modifications to train the NFN synaptic weights.
-
III. An Extended Neo-Fuzzy Neuron
As mentioned above, the NFN nonlinear synapse NS implements the zero-order Takagi-Sugeno inference thus being the elementary Wang-Mendel neuro-fuzzy system [20–22]. It is possible to improve approximating properties of such a system by using a special structural unit which we called an “extended nonlinear synapse” ( ENS , fig.2) and to synthesize an “extended neo-fuzzy neuron” (ENFN) that contains ENS elements instead of usual nonlinear synapses NS (fig.3).
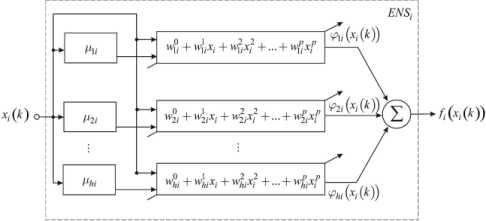
Fig. 2. An extended neo-fuzzy synapse
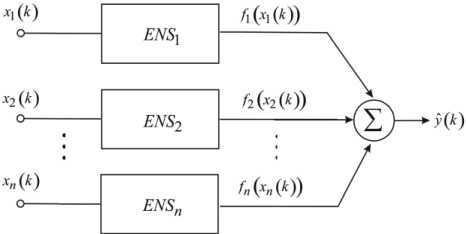
Fig. 3. An extended neo-fuzzy neuron
Introducing additional variables фД xi) = Aii( x)
;0 + "lix + wiX + ' ...+wx,
f, (x) = Z a« (x) (w0+wx+ wix +...+wpx,) = l=1
= wuAu (x,-)+wWki (x)+...+wpx a» (x)+ (15)
+W^i (xi ) + ... + wpxp A2i (xi ) + ... + wpixpAhi (xi ), w = (w0,wu,-, wi, w0,..., wp»-, wp )T ,
A (x) = (A (xt), x,M1i (xi-),..., x-Au (xi-), A21 (xi),-, xpAn (xi),-, xpAm (xi)) T , it can be written
fi (x ) = w A( x),
y=iLf ( x )=1Lw T a ( x ) = wT a ( x ) (19)
= 1 i = 1
where wT =(wT,...,wT,...,wT) ,
A( x ) = ( M T ( x 1 ) ,-, A T ( x i ) ,-, A T ( x n ) ) T .
It’s easy to see that the ENFN contains ( p + 1 ) hn adjusted synaptic weights and the fuzzy inference implemented by each ENS has the form
IF x IS X THEN THE OUTPUT IS w0 + w^x, +... + wpxp, l = 1,2,...,h
which coincides with the p-order Takagi-Sugeno inference.
The ENFN has a much simpler architecture than a traditional neuro-fuzzy system that simplifies its numerical implementation.
When the vector signal x ( k ) is fed to the ENFN input, a scalar value is calculated at the ENFN output
У (k ) = wT (k -1) A( x (k)) (21)
wherein this expression differs from the expression (10) by the fact that it contains ( p + 1 ) times more adjusted parameters than the conventional NFN. It is clear that the algorithm (13) may be used for training ENFN parameters obtaining the form in this case
w ( k ) = w (k -1) + r 1 (k ) e (k ) a( x (k )),
r (k) = ar (k -1) + ||a(x (k))|| ,0 < a < 1.
-
IV. Experiment and Analysis
To demonstrate the efficiency of the proposed adaptive neuro-fuzzy system and its learning procedure (22), we have implemented a simulation test based on forecasting of a chaotic process defined by the Mackey-Glass equation [23]
, 0.2 1 ( t - т ) , .
y ( t ) = 1 + y 10 ( t - т ) " 0.1 y ( t ) . (23)
The signal defined by (22) was quantized with a step 0 . 1. We took a fragment containing 12000 points. The goal was to predict a time-series value on the next step k + 1 using its values on steps k - 3, k - 2, k - 1, and k .
First 7000 points were used as a training set (for adjusting weight coefficients of the architecture), next 5000 points were used as a test set (7001-12000) without adjusting weight coefficients. p is a fuzzy inference order, a number of membership functions h is 3, a smoothing parameter a is 0.9 during the weight adaptation procedure in (21).
We implement one step prediction in all our experiments.
Symmetric mean absolute percentage error (SMAPE), root mean square error (RMSE) and mean square error (MSE), used for result evaluation, are shown in Tab.1-5.
Fig.4-8 present time series outputs, prediction values and prediction errors (a time series value is marked with a blue color, a prediction value is marked with a green color, a prediction error is marked with a red color).
The proposed algorithm gives the close approximation and the high prediction quality of sufficiently non-stationary processes in an online mode.
Table 1. Prediction results of the Mackey-Glass time series
|
RMSEtest |
MSEtest |
SMAPEtest |
|
|
p=0 |
0.0105742 |
0.0022596 |
7.4159348 |
|
p=1 |
0.0064418 |
0.0004191 |
3.5964145 |
|
p=2 |
0.0007427 |
0.0003537 |
3.3670534 |
|
p=3 |
0.0001568 |
0.0004181 |
3.6279506 |
|
p=5 |
0.0009585 |
0.0005421 |
4.0177900 |
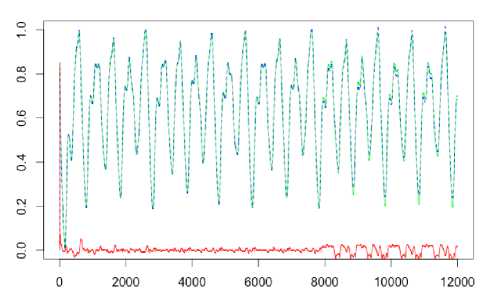
Fig. 4. The Mackey-Glass time series prediction
(p = 3, h = 3, a = 0.9).
The first Narendra object [24] is the dynamic plant identification problem and is described by the equation
y (k + 1) = y (k) / (1 + y2 (k)) + f (k) (24)
where sin3 (nk /250) if k > 500, f (k) = < 0.8sin(nk/250) + 0.2sin(nk/25)
otherwise .
Table 2. Prediction results of the Narendra object
|
RMSEtest |
MSEtest |
SMAPEtest |
|
|
p=0 |
0.0025481 |
0.0021746 |
18.347822 |
|
p=1 |
0.0051009 |
0.0026075 |
11.220434 |
|
p=2 |
0.0012913 |
0.0012601 |
5.5851695 |
|
p=3 |
0.0009847 |
0.0011488 |
5.5871958 |
|
p=5 |
0.0006739 |
0.0010488 |
5.5533630 |
A generated sequence contains 2000 values. We used f ( k ) = sin3 ( n k / 250 ) for the first 500 points (a training set, k = 1...500)
and f ( k ) = 0.8sin ( n k /250 ) + 0.2sin ( n k /25 ) for a test set ( k = 501...2000).
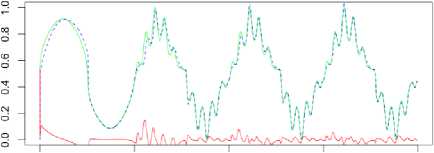
0 500 WOO 1500 2000
Fig. 5. The Narendra time series prediction (p = 3, h = 3, a = 0.9).
The second Narendra plant is assumed to be in the form
y (k + 3) = f (y (k + 2), y (k + 1), y (k), u (k + 3), u (k + 2))
where
f ( x 1 , x 2, x 3, x 4, x 5 ) = ( x 1 x 2 x 4 x 5 ( x 3
— 1 ) + x 4) / ( 1 + x 3 + x^ ) .
A generated sequence contains 1500 values. The input to the plant is given by u (k) = sin (nk / 25) for k < 250, u (k ) = 1 for 250 < k < 500
u ( k ) = - 1 for and
501 < k < 750
u ( k ) = 0.4 sin ( n k /25 ) + 0.1sin ( n k /32 ) + 0.6sin ( n k /10 ) for k > 751.
Table 3. Prediction results of the Narendra object
|
RMSEtest |
MSEtest |
SMAPEtest |
|
|
p=0 |
0.0024681 |
0.0067067 |
14.5441772 |
|
p=1 |
0.0049146 |
0.0054865 |
12.4697803 |
|
p=2 |
0.0017915 |
0.0023304 |
9.3855439 |
|
p=3 |
0.0015882 |
0.0023559 |
9.4933733 |
|
p=5 |
0.0014513 |
0.0024112 |
9.5267278 |
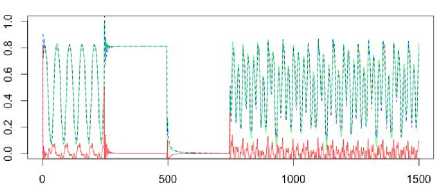
Fig.6. The Narendra time series prediction
(p = 3, h = 3, a = 0.9).
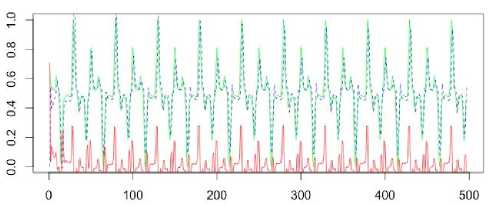
Fig.8. The Narendra time series prediction
(p = 5, h = 3, a = 0.9).
The third Narendra object is described by the equation
y (k + 1) = y (k) / (1 + y2 (k) + f (k)) (26)
where f (k) = (cos(2nk /25) + cos(2nk /2)) if k < 2000, (sin (2nk /250) + sin (2nk /10))3 otherwise
As it can be seen from the fig.4-8, the ENFN approximating properties are better when compared to the traditional NFN architecture which is in fact an ENFN special case (the NFN implements the zero-order Takagi-Sugeno fuzzy inference, p=0).
-
VI. Conclusion
A generated sequence contains 4000 values.
0.0 0.2 0.4 0.6 0.8 1.0
Table 4. Prediction results of the Narendra object
|
RMSEtest |
MSEtest |
SMAPEtest |
|
|
p=0 |
0.0015450 |
0.0012522 |
11.3478218 |
|
p=1 |
0.0028319 |
0.0016039 |
14.2204343 |
|
p=2 |
0.0010964 |
0.0007985 |
6.4813514 |
|
p=3 |
0.0008922 |
0.0007470 |
6.5637786 |
|
p=5 |
0.0006855 |
0.0007125 |
6.6079069 |
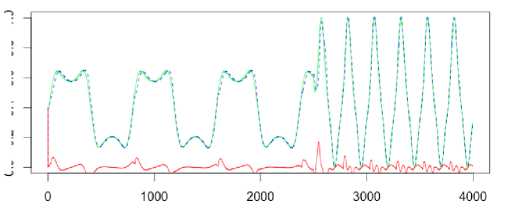
Fig.7. The Narendra time series prediction
(p = 5, h = 3, a = 0.9).
The forth Narendra object is described in the form y (k +1) = y (k) / (1 + y2 (k)) + sin (2nk /25) + + sin (2nk /10)
A generated sequence contains 500 values.
Table 5. Prediction results of the Narendra object
|
RMSEtest |
MSEtest |
SMAPEtest |
|
|
p=0 |
0.0080359 |
0.0214440 |
25.1994989 |
|
p=1 |
0.0114304 |
0.0194163 |
25.3300074 |
|
p=2 |
0.0017572 |
0.0104677 |
20.2466940 |
|
p=3 |
0.0010388 |
0.0106037 |
20.2904977 |
|
p=5 |
8.6533285 |
0.0109404 |
20.4180131 |
The architecture of an extended neo-fuzzy neuron is proposed in the paper which is a generalization of the standard neo-fuzzy neuron in a case of the “above zero”-order fuzzy inference. The learning algorithm is proposed that is characterized by both tracking and filtering properties. The extended NFN has improved approximating properties, it’s characterized by a high learning rate, it also has simple numerical implementation.
Acknowledgment
The authors would like to thank anonymous reviewers for their careful reading of this paper and for their helpful comments.
References An Extended Neo-Fuzzy Neuron and its Adaptive Learning Algorithm
- D. Graupe, Principles of Artificial Neural Networks (Advanced Series in Circuits and Systems). Singapore: World Scientific Publishing Co. Pte. Ltd., 2007.
- K. Suzuki, Artificial Neural Networks: Architectures and Applications. NY: InTech, 2013.
- G. Hanrahan, Artificial Neural Networks in Biological and Environmental Analysis. NW: CRC Press, 2011.
- L. Rutkowski, Computational Intelligence. Methods and Techniques. Berlin: Springer-Verlag, 2008.
- C.L. Mumford and L.C. Jain, Computational Intelligence. Berlin: Springer-Verlag, 2009.
- R. Kruse, C. Borgelt, F. Klawonn, C. Moewes, M. Steinbrecher, and P. Held, Computational Intelligence. A Methodological Introduction. Berlin: Springer-Verlag, 2013.
- K.-L. Du and M.N.S. Swamy, Neural Networks and Statistical Learning. London: Springer-Verlag, 2014.
- T. Yamakawa, E. Uchino, T. Miki and H. Kusanagi, “A neo fuzzy neuron and its applications to system identification and prediction of the system behavior,” Proc. 2nd Int. Conf. on Fuzzy Logic and Neural Networks, pp. 477-483, 1992.
- E. Uchino and T. Yamakawa, “Soft computing based signal prediction, restoration and filtering,” in Intelligent Hybrid Systems: Fuzzy Logic, Neural Networks and Genetic Algorithms, Boston: Kluwer Academic Publisher, 1997, pp. 331-349.
- T. Miki and T. Yamakawa, “Analog implementation of neo-fuzzy neuron and its on-board learning,” in Computational Intelligence and Applications, Piraeus: WSES Press, 1999, pp. 144-149.
- T. Takagi T. and M. Sugeno, “Fuzzy identification of systems and its application to modeling and control”, in IEEE Trans. on Systems, Man, and Cybernetics, no. 15, 1985, pp. 116 – 132.
- J-S.R. Jang, C.T. Sun and E. Mizutani, Neuro-Fuzzy and Soft Computing: A Computational Approach to Learning and Machine Intelligence, New Jersey: Prentice Hall, 1997.
- Ye. Bodyanskiy and V. Kolodyazhniy, “Adaptive nonlinear control using neo-fuzzy model”, in Sinergies Between Information Processing and Automation, pp. 122 – 127, 2004.
- Ye. Bodyanskiy, I. Kokshenev, V. Kolodyazhniy, and P. Otto, “A self-training robust neo-fuzzy controller with constraints on control actions”, 50th Int. Wiss. Koll. Tagungsband, ss. 125 – 126, 2005.
- J. Zhang and H. Knoll, “Constructing fuzzy-controllers with B-spline models – Principles and Applications”, in Int. J. of Intelligent Systems, no. 13, 1998, pp. 257 – 285.
- V. Kolodyazhniy and Ye. Bodyanskiy, “Cascaded multiresolution spline-based fuzzy neural network”, Proc. Int. Symp. on Evolving Intelligent Systems, pp. 26 – 29, 2010.
- Ye. Bodyanskiy, I. Kokshenev and V. Kolodyazhniy, “An adaptive learning algorithm for a neo-fuzzy neuron”, Proc. 3rd Int. Conf. of European Union Soc. for Fuzzy Logic and Technology, pp. 375-379, 2003.
- S. Haykin, Neural Networks: A Comprehensive Foundation. Upper Saddle River, New Jersey: Prentice Hall, 1999.
- G.C. Goodwin, P.J. Ramage, and P.E. Caines, “Discrete time stochastic adaptive control”, in SIAM J. Control and Optimization, no. 19, 1981, pp. 829 – 853.
- L.X. Wang and J.M. Mendel, “Fuzzy basis functions, universal approximation and orthogonal least squares learning”, in IEEE Trans. on Neural Networks, no. 3, 1993, pp. 807 – 814.
- L.X. Wang, Adaptive Fuzzy Systems and Control. Design and Stability Analysis. Upper Saddle River, New Jersey: Prentice Hall, 1994.
- S. Osowski, Sieci neuronowe do przetwarzania informacji. Warszawa: Oficijna Wydawnicza Politechniki Warszawskiej, 2006.
- M.C. Mackey and L. Glass, “Oscillation and chaos in physiological control systems”, in Science, no. 197, 1977, pp. 238-289.
- K.S. Narendra and K. Parthasarathy, “Identification and control of dynamic systems using neural networks”, in IEEE Trans. on Neural Networks, no. 1, 1990, pp. 4-26.
