Анализ параметров систем детектирования множественных визуальных объектов в режиме реального времени

Автор: Проценко Владимир Игоревич, Казанский Николай Львович, Серафимович Павел Григорьевич
Журнал: Компьютерная оптика @computer-optics
Рубрика: Обработка изображений: Восстановление изображений, выявление признаков, распознавание образов
Статья в выпуске: 4 т.39, 2015 года.
Бесплатный доступ
Проведён анализ параметров систем детектирования множественных объектов на основе фреймворков для потокового анализа данных Apache Storm и IBM InfoSphere Streams. В качестве объектов для детектирования были выбраны изображения лиц. Тестирование производилось на кластере, состоящем из пяти 32-ядерных узлов под управлением операционной системы CentOS. Apache Storm показал лучшую масштабируемость по сравнению с IBM InfoSphere Streams. Для изображения размером 1920´1080 достигнута скорость обработки 24 кадра в секунду при использовании Apache Storm.
Большие данные, потоковая обработка, набор изображений, детектирование лиц, пропускная способность, система реального времени
Короткий адрес: https://sciup.org/14059625
IDR: 14059625 | DOI: 10.18287/0134-2452-2015-39-4-582-591
Real-time analysis of parameters of multiple object detection systems
Analysis of two streaming frameworks: Apache Storm and IBM InfoSphere Streams was performed in solving a multiple object detection task. The analysis focused on two parameters: throughput and 95th percentile of image processing delay. Faces were chosen as the objects to be detected. Profiling was held under CentOS operating systems running on a five node cluster. Face detection was performed using an OpenCV cascade classifier. First architectures and the experiment description were covered. Final suggestions on the applicability of the two systems were made in the concluding section of the article. Apache Storm demonstrated a scalability advantage over IBM InfoSphere Streams in the experiment conducted. It was confirmed that the system based on Apache Storm was able to operate on FullHD video in real-time, achieving throughput of 24 images per second on the hardware used.
Текст научной статьи Анализ параметров систем детектирования множественных визуальных объектов в режиме реального времени
На сегодняшний день основной объём информации, появляющейся в сети интернет, генерируется пользователями с мобильных устройств. В основном это изображения, звук и видеоданные. Согласно прогнозам компании Cisco, величина мобильного мультимедиа трафика к 2019 году испытает экспоненциальный рост, достигнув значений 23,4 экзабайт в месяц [1]. Важность актуальной информации в сочетании с высокой интенсивностью появления данных создают проблему анализа информации в реальном времени. Для решения данной проблемы был создан ряд систем потоковой обработки данных как коммерческих, так и с открытым кодом. Среди наиболее известных систем с открытым кодом можно назвать Apache Storm, Apache Samza, S4, Apache Streaming, а среди коммерческих - IBM InfoSphere Streams, Oracle Event Processing, Microsoft StreamInsight, Amazon Kinesis, MillWheel.
В настоящей статье выполнен анализ параметров систем детектирования множественных объектов в последовательности изображений на основе фреймворков для потокового анализа: Apache Storm и IBM InfoSphere Streams. Apache Storm является одним из наиболее популярных продуктов с открытым кодом, а IBM InfoSphere Streams - среди коммерческих. Произведён анализ характеристик систем на четырёх размерах изображений: на небольшом размере 100 x 100, на размере 640 x 640, используемом в социальной сети Instagram, на размере 1920 x 1080, известном как Full HD, и на размере 4096 x 3112, являющимся полнокадровым разрешением 4K. Сравнение произведено на последних на текущий момент версиях: 0.9.4 для Apache Storm и v4.0 IBM InfoSphere Streams.
Рассматриваемые фреймворки анализировались авторами ранее в статье [2], результаты которой показали меньшую требовательность к объёму оперативной памяти для IBM InfoSphere Streams по срав- нению с Apache Storm, примерно в 3-4 раза. При этом Apache Storm был более производительным. Однако из-за проведения эксперимента на виртуальной машине исследовать пропускную способность в зависимости от параллелизма не представлялось возможным. Данная работа дополняет ранее выполненный анализ систем новыми результатами экспериментов. Также в описании архитектур приводится информация, соответствующая последним версиям фреймворков.
Анализ визуальной информации имеет важное значение и широкий спектр применений [3–7]. Детектирование визуальных объектов находит применение в таких задачах, как видеомониторинг общественных и частных пространств [8– 11], мониторинг дорожного трафика [12– 16], улучшение взаимодействия с пользователем [17– 18], в биометрических системах [19– 20], в системах контроля качества [21 – 24], автоматического управления транспортным средством [25–26]. Для детектирования объектов в данной работе используется реализация каскадного классификатора библиотеки OpenCV [27], алгоритм которого впервые был описан в работе P. Viola и M. Jones [28], а затем улучшен в работе R. Lienhart [29]. Для данного классификатора объект, который необходимо найти на изображении, описывается конфигурационным файлом - решающим деревом особенностей. Дерево особенностей можно получить после фазы обучения на обучающей выборке. В данной работе был взят готовый конфигурационный файл для детектирования лица в анфас за авторством Rainer Lienhart [30].
При работе с задачами обработки видеопотоков в большинстве случаев возникает требование обработки данных в реальном времени. Для выполнения данного требования применяются различные подходы: создание распределённых алгоритмов на основе технологии MPI [31 – 32], использование технологий CUDA и OpenCL для графических процессоров [33–34], ис- пользование программируемых логических интегральных схем типа FPGA [35–36], использование встроенных сопроцессоров [12]. Недостатком MPI-подхода является сложность создания алгоритмов, эффективно масштабируемых в кластерах с гетерогенной структурой, а также алгоритмов, устойчивых к возможным сбоям узлов. Применение специализированных процессоров позволяет добиться значительной скорости обработки, от 30 до 160 кадров в секунду, в задаче слежения за движущимися объектами [12– 14], однако такой подход ускоряет обработку только на одном узле и не решает проблему распределения вычислений по множеству компьютеров, усложняет реализацию обработки, учитывающую другие типы информации, например текст, GPS-координаты.
Далее будут описаны архитектуры двух рассматриваемых фреймворков – Apache Storm и IBM Info– Sphere Streams, произведётся сравнение систем детектирования множественных объектов по параметрам задержки на обработку кадра и пропускной способности.
Архитектуры Apache Storm и IBM InfoSphere Streams
Apache Storm
Так как архитектура уже была описана авторами ранее в статье [2], мы приведём только отличия, касающиеся версии 0.9.4, и описание механизма надёжной обработки кортежей, используемого в эксперименте. Отличием является то, что для передачи данных между процессами механизм передачи сообщений Netty [37] теперь используется по умолчанию. Также в новой версии исправлено множество ошибок. Отметим положительное свойство системы - устойчивость к выходу из строя узлов и каналов передачи данных. Благодаря тому, что процессы Nimbus и Supervisor хранят состояние не локально, а в Zookeeper [38], система может восстанавливать работоспособность после аварийного завершения процессов.
В данной работе в эксперименте будет использоваться механизм подтверждений. При использовании механизма подтверждений система позволяет добиться гарантии обработки кортежа один или более раз (at-least once).
Для того, чтобы описать алгоритм подтверждения обработки, введём соответствующую терминологию. Id i - идентификатор, присваиваемый пользователем кортежу в источнике Spout. Xi будет обозначать случайное число, идентификатор «дерева» зависимостей, Y j – случайное число, идентификатор кортежа j, K j - кортеж j, где i и j – натуральные числа. Рассмотрим топологию с одним источником source, двумя обработчиками Bolt1, Bolt2 и обработчиком Acker, необходимым для работы алгоритма подтверждений.
На рис. 1 проиллюстрирована работа топологии в режиме гарантии обработки. В работе алгоритма можно выделить 3 фазы: начало обработки, связывание кортежей зависимостью и подтверждение обработки. В начале для нового кортежа источника K1 и идентификатора Id1 генерируется пара
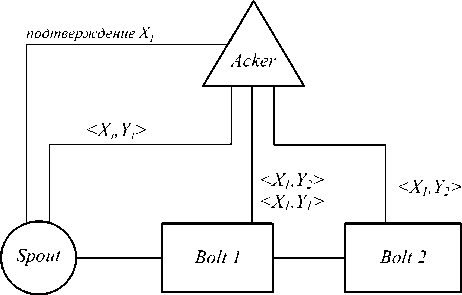
Рис. 1. Иллюстрация работы механизма подтверждений Apache Storm
Опишем недостающую логику алгоритма
-
поведение Acker и Spout при получении сообщения. Acker хранит пары в таблице. В таблицу добавляется пара
Использование данного механизма также позволяет контролировать количество обрабатываемых кортежей в системе, то есть тех, которые отправлены из источника, но ещё не подтверждены (параметр topol-ogy.max.spout.pending). Это позволяет контролировать размер используемой оперативной памяти источника и избежать ошибок OutOfMemoryException при интенсивности источника большей, чем производительность обрабатывающего подграфа.
IBM InfoSphere Streams
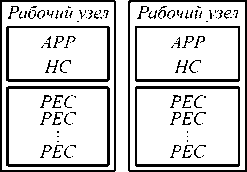
В новой версии v4.0 было введено понятие домена. Домен объединяет ресурсы кластера и сервисы домена. Instance объединяет подмножество ресурсов домена и процессы, отвечающие за потоковую обра- ботку. Одному домену может принадлежать несколько Instance. На рис. 2 изображена архитектура системы. Часть сервисов, ранее принадлежащих Instance, сделаны процессами домена: SWS - веб-консоль администратора, AAS - сервис авторизации пользователей, JMX - jmx-расширения для управления сервисами, AUDITLOG - сервис, ведущий лог операций, производимых над компонентами фреймворка. Конфигурационная информация и данные о назначенных заданиях хранятся в Zookeeper.
В Instance на управляющем узле запускается четыре процесса: сервис метрик приложения, менеджер приложения, планировщик и сервис представления. Менеджер приложения, SAM, отвечает за назначение, перераспределение и отмену задач пользовательского приложения. Он взаимодействует с планировщиком для расчёта распределения задач и с контроллерами рабочих узлов для запуска или удаления задач. Сервис метрик приложения, SRM, следит за работой всех остальных сервисов, собирает данные об их выполнении, а также собирает данные о производительности пользовательских задач, взаимодействуя для этого с контроллерами рабочих узлов HC. Планировщик SCH, анализируя данные о ресурсах системы от сервиса метрик приложения, рассчитывает распределение задач для менеджера приложения. Сервис представления VIEW управляет данными, используемыми в представлениях, которые, в свою очередь, описывают набор атрибутов для отображения на графиках, в таблицах и в Microsoft Excel.
Домен
SWS JMX AUDITLOG AAS
Instance
Управляющий узел SAM SCH
SRM VIEW
Рабочий узел АРР
НС
РЕС РЕС
РЕС
Рис. 2. Архитектура InfoSphere Streams. Домену принадлежит Instance. Верхним прямоугольником в Instance изображается узел с управляющими сервисами, нижними прямоугольниками изображены исполнительные узлы, каждый с локальным управляющим процессом (Host Controller) и рабочими процессами PEC
На рабочих узлах запускаются контроллеры HC, в ответственность которых входят запуск, остановка и мониторинг задач. В его обязанности также входит сбор метрик задач и передача их сервису метрик на управляющий узел. Кроме контроллера, на рабочих узлах запускается сервис развёртывания приложения APP. Данный сервис подготавливает ресурсы для развёртывания и запуска задач, размещает скомпилированные блоки кода к соответствующим ресурсам.
Пользовательская программа, также как и в Apache Storm, представляет из себя граф, описанный на языке SPL [39], в узлах которого находятся операторы. Операторы могут быть реализованы на языках C++ и Java. Для реализации на других языках фреймворк специальных средств не предоставляет, они могут выполняться в системе обёрнутыми в Java или C++. Результатом компиляции является набор разделяемых библиотек (PE). Задачи, упоминаемые выше, и processing element PE в данной секции являются синонимами. Задачи выполняются в процессах PEC.
Начиная с версии 4.0 в IBM InfoSphere Streams реализован механизм надёжной обработки кортежей, позволяющий добиться гарантий обработки один или более раз (at-least-once) [40]. Операторы, начиная с которых вся последующая обработка должна быть надёжной, помечаются ключевым словом @consistent. Начиная с нужного оператора также можно отменить работу логики подтверждений, пометив его ключом @autonomous. Кроме того в каждом приложении с аннотацией @consistent должен фигурировать оператор JobControlPlane. Множество операторов, заключённое между @consistent и последним или @autonomous оператором, называется consistent region и гарантирует обработку каждого кортежа хотя бы один раз в условиях возможных сбоев узлов или каналов передачи сообщений. Реализация алгоритма основана на работе Chandy и Leslie Lamport [41].
Описание модельной задачи
Эксперимент ставился для задачи подсчёта количества лиц в потоке изображений. Лица детектировались каскадным классификатором из библиотеки OpenCV. На вход данному классификатору подавался файл конфигурации, натренированный для детектирования лица анфас. Результатом работы классификатора является список прямоугольников (координаты противоположных по диагонали углов), количество которых считалось количеством лиц на изображении. На рис. 3 показан результат работы алгоритма детектирования лиц.
В табл. 1 приведено время детектирования на одном узле для рассматриваемых разрешений.
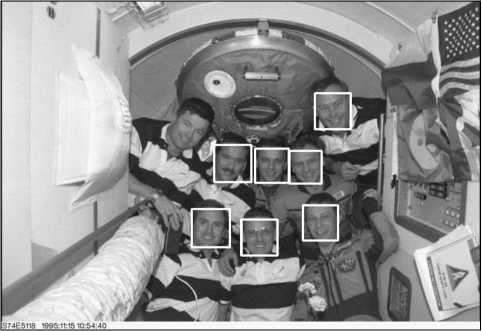
Рис. 3. Результат детектирования лиц на изображении
Табл. 1. Среднее время детектирования лиц на одном ядре для разных размеров изображения
|
Размер изображения |
Время обработки (сек) |
|
100 х 100 |
0,008 |
|
640 х 640 |
0,417 |
|
1920 х 1080 |
1,621 |
|
4096 х 3112 |
9,988 |
Вычислительный эксперимент
Описание
Единицей измерения пропускной способности было количество обработанных изображений в секунду . Величина задержек измерялась в секундах. Задержка рассчитывалась как разница между моментом времени отправки кортежа из источника и отправки кортежа из обработчика.
Топология Apache Storm была реализована на языке Java, состояла из одного источника Spout и одного обработчика Bolt с указанием степени параллелизма. Аналогичная программа была написана для InfoSphere Streams. Операторы были реализованы на языке Java, связи между операторами описаны на языке SPL. В обоих алгоритмах передача производилась в сериализованном формате: ширина, высота, целое число - тип OpenCV, массив байтов изображения.
В ходе планирования и проведения экспериментов было выявлено несколько ключевых параметров, влияющих на анализируемые показатели. В обеих системах существует возможность написания программы с использованием механизма гарантии обработки и без него. Эксперимент для системы Apache Storm без гарантии обработки «один или более раз» не проводился, так как источник в данной системе работает асинхронно с механизмом передачи сообщений, что приводило к заполнению всей выделенной памяти непереданными кортежами и завершению работы приложения с ошибкой OutOfMemoryExcep-tion. В отличие от режима с гарантией обработки, в котором контроль за одновременно обрабатываемым количеством кортежей есть, в этом режиме его пришлось бы писать самому, что усложнило бы эксперимент. В случае с системой IBM Streams использование @consistent приводило к уменьшению пропускной способности в 1,1 – 1,2 раза.
Важным параметром также был параметр topology.max.spout.pending для Apache Storm. Было выявлено, что при установке данного значения равным topology.max.spout.pending=2parallelism достигалась высокая пропускная способность, и в то же время задержка сохранялась небольшой относительно степени параллелизма. Дальнейшее увеличение приводило к увеличению задержки и незначительному приросту пропускной способности, которое для to-pology.max.spout.pending = 3parallelism стабилизировалось около определённого значения. Кроме того, от увеличения данного параметра линейно зависит потребление оперативной памяти, выделенной для JVM источника Spout. Отметим также, что установка значения меньшего, чем значение степени параллелизма, приведёт к параллельной обработке входного потока только частью обработчиков единовременно.
Таким образом, далее анализируются результаты выполнения программы с гарантией обработки кортежей с удвоенным значением одновременно обрабатываемых кортежей, по сравнению с степенью параллелизма для Apache Storm и программы IBM InfoSphere Streams без наличия операторов с гарантией обработки сообщений.
Для анализа систем было добавлено журналирование в каждом операторе: источник для каждого кортежа записывал время начала отправки, обработчики записывали текущее время после отправки результата распознавания объекта (количество лиц на изображении). После минутной работы алгоритм останавливался, и результаты с каждого узла объединялись в единый файл для последующего анализа. Важным моментом при данном способе замера времени является синхронизация времени на узлах с достаточной для эксперимента точностью, что было проделано перед проведением замеров. Узлы были синхронизированы посредством NTP с точностью до третьего знака после запятой.
Тестирование проводилось на кластере с пятью узлами под управлением операционной системы CentOS. Расчёты проводились на 4 узлах, оставляя пятый в качестве управляющего. Характеристики кластера: скорость сети - 10 Гбит/с, процессоры на каждом узле - 2 процессора Intel Xeon E5-2450v2 по 8 реальных ядер с включённой технологией HyperThreading, размер оперативной памяти каждого узла - 96 Гб. Использовалась версия 2.4.10 библиотеки OpenCV.
Анализировались задержки обработки изображения и пропускная способность систем в зависимости от количества параллельно работающих обработчиков на четырёх изображениях разного разрешения. В силу того, что мы хотели бы дать гарантии максимальной задержки, для задержек анализировались значения 95-го процентиля, которое мы будем обозначать греческой буквой α. Данное значение обозначает промежуток времени, в течение которого порядок обрабатываемых кортежей не гарантируется. То есть кортеж K2, отправленный из источника через промежуток времени, отсчитываемый от K1 и равный 95-му процентилю задержки кортежа, с вероятностью 0,95 будет обработан позже K1. Это является ориентиром для выбора буфера, необходимого для восстановления порядка кортежей, при обработке видеопотоков в реальном времени.
Результаты
Сначала рассмотрим графики пропускной способности двух систем, которые представлены на рис. 4 а – г . Основное, что бросается в глаза, – это ограничение роста пропускной способности программы для IBM InfoSphere Streams. Узким местом здесь является источник. Со значения параллелизма 16 нить источника начинает сильно загружать ядро процессора, и к 32 загрузка составляет больше чем 90%.
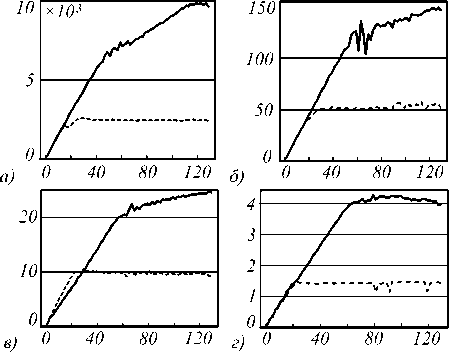
Рис. 4. Зависимость пропускной способности от степени параллелизма для разных размеров изображений:
а) 100 x 100, б) 640 x 640, в) 1920 x 1080, г) 4096 x 3112.
Сплошной линии соответствует Apache Storm, пунктирной – InfoSphere Streams. По оси абсцисс изменяется степень параллелизма, по оси ординат – пропускная способность (кадр/с)
На рис. 5 и в табл. 2 представлен вывод программы top о загрузке процессора для узла с источником, на котором видно, что только половина обработчиков на данном узле загружена. Значения загрузки более 100 % обозначают загрузку более чем одного ядра. Так как новые изображения поступают с меньшей скоростью, чем производится обработка, часть обработчиков простаивает.
|
PID |
USER |
PR |
HT |
VIRT |
RES |
SHR |
5 |
%CPU |
%MEM |
TIME 4- |
COMMAND |
|
13737 |
strearr.sa |
20 |
o |
5356m |
412m |
42m |
R |
100 . |
0.4 |
1:27.51 |
Thread-12 |
|
13735 |
stream.sa |
0 |
5356m |
415m |
42m |
R |
2 2 2. |
0.4 |
Thread-12 |
||
|
streamsa |
q q q qrr |
4 ' qjp |
4 7 m |
p |
' n 0 |
fi 4 |
' . 7 q 7 c |
Thread-12 |
|||
|
13740 |
stream.sa |
20 |
о |
5544m |
2 90m |
42m |
R |
92.2 |
0.3 |
2:10.04 |
ImaceSource-thr |
|
1373 9 |
streainsa |
0 |
5356m |
415m |
42m |
2. |
71.4 |
0.4 |
1:24.53 |
Thread—_2 |
|
|
13 7 31 |
streamsa |
2 2 |
2 2 2 2 m |
255m |
42m |
s |
52.2 |
0.3 |
1:32.60 |
Thread-12 |
|
|
1372 9 |
streamsa |
2 2 |
0 |
5210m |
2 52m |
42m |
s |
12.2 |
0.3 |
1:32.36 |
Thread-12 |
|
14236 |
root |
2 2 |
2 |
16360 |
2652 |
1004 |
2. |
1.3 |
0.0 |
0:00.39 |
top |
Рис. 5. Загруженность процесса источника IBM InfoSphere Streams. Нити отсортированы по убыванию загрузки процессора. Источник имеет название ImageSource-thr, а обработчики – Thread-12
Табл. 2. Данные о загруженности процессора из утилиты top для узла с источником IBM InfoSphere Streams.
Нити отсортированы по убыванию загрузки процессора. Источник имеет название ImageSource-thr, а обработчики – Thread-12
|
PID |
Загруженность процессора (%) |
Имя команды |
|
13737 |
100,4 |
Thread-12 |
|
13735 |
100,1 |
Thread-12 |
|
13733 |
100,1 |
Thread-12 |
|
13740 |
92,8 |
ImageSource-thr |
|
13739 |
71,4 |
Thread-12 |
|
13731 |
52,0 |
Thread-12 |
|
13729 |
14,2 |
Thread-12 |
В отсутствие обработчиков и, следовательно, необходимости передавать сообщения на размере 640x640 производительность источника была равна 365 кадров/сек. Это говорит о том, что проблемным местом здесь является механизм передачи сообщений IBM Streams. К сожалению, параметров для тонкой настройки данного механизма IBM InfoSphere Streams не предоставляет. Поэтому для данного эксперимента - топологии с одним источником и множеством однотипных обработчиков - обойти данное ограничение не получилось. Это поведение было характерно для всех размеров изображений.
Графики программы для Apache Storm можно охарактеризовать двумя прямыми с разными углами наклона, сменяющими друг друга на отметке значения параллелизма 64. Данное явление объясняется включенной технологией HyperThreading. До значения 64, равного количеству ядер кластера, каждый поток рассчитывается на своём ядре, но после этого значения потоки начинают делить физические ядра [42]. Технология HyperThreading позволяет добиться ускорения за счёт объединения потоков инструкций нескольких нитей в один для того, чтобы загрузить все специализированные вычислительные блоки ядра. Можно предположить, что наблюдаемое уменьшение наклона прямой, характеризующей пропускную способность после параллелизма 64, при увеличении размера изображений связано с увеличением времени однотипных операций и в итоге уменьшению ускорения, даваемого технологией HyperThreading из-за однородности потоков инструкций. В табл. 3, 4, 5, 6 представлена выборочная часть результатов замеров пропускной способности для значений параллелизма от 1 до 128, идущих с шагом 20. Выбор данного набора значений параллелизма для таблиц обусловлен желанием компактного представления данных, дополняющих информацию, представленную на графиках.
Табл. 3. Пропускная способность для размера изображения 100 x 100
|
Степень параллелизма |
Пропускная способность |
|
|
Storm |
IBM Streams |
|
|
1 |
162 |
168 |
|
21 |
3112 |
2222 |
|
41 |
5799 |
2455 |
|
61 |
7140 |
2462 |
|
81 |
8072 |
2444 |
|
101 |
9084 |
2491 |
|
121 |
9875 |
2458 |
Табл. 4. Пропускная способность для размера изображения 640 x 640
|
Степень параллелизма |
Пропускная способность |
|
|
Storm |
IBM Streams |
|
|
1 |
2,5 |
2,5 |
|
21 |
47,1 |
42,2 |
|
41 |
91,0 |
51,6 |
|
61 |
107,7 |
52,1 |
|
81 |
131,7 |
52,0 |
|
101 |
138,8 |
56,6 |
|
121 |
147,9 |
55,8 |
На рис. 6а – г изображены графики 95-го процентиля для задержек на обработку изображения. В табл. 7– 10 представлена выборочная часть результатов 95-го процентиля для задержек. На изображениях 100x100 значения α для обеих систем были примерно одинаковыми и отличались только на небольших значениях параллелизма. На всех графиках в начале программа для IBM Streams имела большее значение α, а затем α стабилизировалось около определённой величины. В силу того, что существовало ограничение на производительность источника в IBM Streams, нельзя сказать, что в данной задаче задержки более предсказуемые по сравнению с Apache Storm.
Табл. 5. Пропускная способность для размера изображения 1920 x 1080
|
Степень параллелизма |
Пропускная способность |
|
|
Storm |
IBM Streams |
|
|
1 |
0,56 |
0,55 |
|
21 |
7,46 |
9,34 |
|
41 |
14,48 |
9,95 |
|
61 |
20,51 |
9,80 |
|
81 |
22,23 |
10,18 |
|
101 |
23,33 |
9,56 |
|
121 |
24,40 |
9,57 |
Табл. 6. Пропускная способность для размера изображения 4096 x 3112
|
Степень параллелизма |
Пропускная способность |
|
|
Storm |
IBM Streams |
|
|
1 |
0,09 |
0,09 |
|
21 |
1,44 |
1,39 |
|
41 |
2,72 |
1,43 |
|
61 |
3,93 |
1,40 |
|
81 |
4,12 |
1,13 |
|
101 |
4,18 |
1,45 |
|
121 |
4,09 |
1,42 |
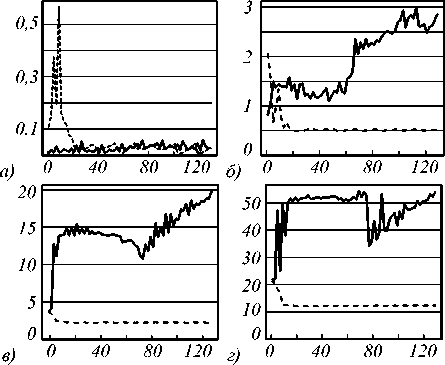
Рис. 6. 95-й процентиль для задержки на обработку изображений для двух систем в зависимости от степени параллелизма для разных размеров изображений: а) 100 x 100, б) 640 x 640, в) 1920 x 1080, г) 4096 x 3112. Сплошной линии соответствует Apache Storm, пунктирной – InfoSphere Streams. По оси абсцисс изменяется степень параллелизма, по оси ординат – 95-й процентиль для задержки (с)
Начиная с размера 640x640 на графиках для программы под Apache Storm видно изменение характера задержек после параллелизма 64. Во всех случаях α задержек начинает расти, что соответствует тому, что нити начинают делить физические ядра. Интересным эффектом является то, что для 1920x1080 и 4096x3112 значение α находится на определённом уровне, затем испытывает спад, и уже после этого медленно растёт. Если бы мы привели среднюю задержку, мы бы увидели, что средняя задержка держится на определённом уровне, а затем после значения параллелизма 64 испытывает медленный рост. Можно сделать вывод, что количество долгих задержек для крупных изображений больше, что влияет на показатель, так как объём обработанных изображений меньше.
Табл. 7. 95-й процентиль для задержек для двух систем на размерах изображений 100 x 100
|
Степень параллелизма |
95-й процентиль задержек (сек) |
|
|
Storm |
IBM Streams |
|
|
1 |
0,010 |
0,109 |
|
21 |
0,013 |
0,036 |
|
41 |
0,012 |
0,029 |
|
61 |
0,016 |
0,027 |
|
81 |
0,040 |
0,033 |
|
101 |
0,027 |
0,045 |
|
121 |
0,020 |
0,008 |
Табл. 8. 95-й процентиль для задержек для двух систем на размерах изображений 640 x 640
|
Степень параллелизма |
95-й процентиль задержек (сек) |
|
|
Storm |
IBM Streams |
|
|
1 |
0,827 |
2,063 |
|
21 |
1,440 |
0,497 |
|
41 |
1,212 |
0,515 |
|
61 |
1,563 |
0,509 |
|
81 |
2,242 |
0,520 |
|
101 |
2,742 |
0,525 |
|
121 |
2,474 |
0,507 |
Табл. 9. 95-й процентиль для задержек для двух систем на размерах изображений 1920 x 1080
|
Степень параллелизма |
95-й процентиль задержек (сек) |
|
|
Storm |
IBM Streams |
|
|
1 |
3,667 |
3,680 |
|
21 |
13,894 |
2,213 |
|
41 |
14,248 |
2,256 |
|
61 |
13,088 |
2,281 |
|
81 |
13,687 |
2,270 |
|
101 |
16,139 |
2,248 |
|
121 |
18,496 |
2,264 |
Табл. 10. 95-й процентиль для задержек для двух систем на размерах изображений 4096 x 3112
|
Степень параллелизма |
95-й процентиль задержек (сек) |
|
|
Storm |
IBM Streams |
|
|
1 |
21,265 |
22,051 |
|
21 |
50,92 |
12,127 |
|
41 |
52,037 |
12,130 |
|
61 |
50,647 |
12,217 |
|
81 |
43,251 |
12,294 |
|
101 |
46,809 |
12,352 |
|
121 |
50,766 |
12,422 |
Выводы
Выполнен анализ систем детектирования множественных визуальных объектов, построенных на основе фреймворков Apache Storm и IBM InfoSphere Streams. В ходе вычислительного эксперимента подсчитывалось количество лиц в потоке изображений. В работе анализировались параметры пропускной способности систем, а также 95-й процентиль для задержек на обработку изображения. Новизной данной работы является использование систем потокового анализа, которые лишены недостатков других используемых для этой задачи технологий. В частности, сложности организации передач данных при использовании MPI. А также проблемы длительной задержки при блочной обработке на Hadoop. Разработанные системы позволяют детектировать объекты в видеопотоках в реальном времени.
В ходе экспериментов было выявлено, что система IBM InfoSphere Streams для данного эксперимента не масштабируется на число ядер в кластере большее, чем 16. На больших изображениях преимуществ от использования технологий HyperThreading нет из-за однородности потока инструкций. Система Apache Storm показала линейный рост пропускной способности до степени параллелизма 64 для всех размеров изображений. При использовании Apache Storm для изображения размером 1920 x 1080 достигнута скорость обработки 24 кадра в секунду. Данная производительность позволяет обрабатывать видеопоток с разрешением FullHD в реальном времени. Таким образом, для рассматриваемой задачи лучше использовать систему Apache Storm.
Если сравнивать с предыдущими подходами [31 – 36] к обработке данных в реальном времени, то преимуществом обработки в анализируемых потоковых фреймворках является возможность совместного анализа потоков разного типа, гарантии обработки данных, отсутствие единой точки отказа, возможность работы с данными, не помещающимися в оперативную память одного узла. Фреймворки могут быть использованы для сложной обработки изображений и видеопотоков, включая учёт информации других типов, например GPS-координат, звука и текста.
Дальнейшие исследования могут быть проведены в направлении усложнения логики обработки изображений, использования графических процессоров на обрабатывающих узлах, что может увеличить производительность систем в несколько раз [34, 43].
Исследование выполнено при поддержке Российского научного фонда (проект № 14-31-00014).
Список литературы Анализ параметров систем детектирования множественных визуальных объектов в режиме реального времени
- Cisco C.V.N.I. Cisco Visual Networking Index: Global Mobile Data Traffic Forecast Update, 2014-2019. . -URL: http://www.cisco.com/c/en/us/solutions/collateral/service-provider/visualnetworking-index-vni/white_paper_c11-520862.html (дата обращения 27.05.2015).
- Казанский, Н.Л. Сравнение производительности систем потокового анализа данных в задаче обработки изображений скользящим окном/Н.Л. Казанский, В.И. Проценко, П.Г. Серафимович//Компьютерная оптика. -2014. -Т. 38, № 4. -С. 804-810.
- Казанский, Н.Л. Распределённая система технического зрения регистрации железнодорожных составов/Н.Л. Казанский, С.Б. Попов//Компьютерная оптика. -2012. -Т. 36, № 3. -С. 419-428.
- Kazanskiy, N.L. Machine vision system for singularity detection in monitoring the long process/N.L. Kazanskiy, S.B. Popov//Optical Memory and Neural Networks (Information Optics). -2010. -Vol. 19, No. 1. -P. 23-30.
- Зимичев, Е.А. Пространственная классификация гиперспектральных изображений с использованием метода кластеризации k-means++/Е.А. Зимичев, Н.Л. Казанский, П.Г. Серафимович//Компьютерная оптика. -2014. -Т. 38, № 2. -С. 281-286.
- Попов, С.Б. Концепция распределенного хранения и параллельной обработки крупноформатных изображений/С.Б. Попов//Компьютерная оптика. -2007. -Т. 31, № 4. -С. 77-85.
- Методы компьютерной оптики/А.В. Волков, Д.Л. Головашкин, Л.Д. Досколович, Н.Л. Казанский, В.В. Котляр, В.С. Павельев, Р.В. Скиданов, В.А. Сойфер, В.С. Соловьев, Г.В. Успленьев, С.И. Харитонов, С.Н. Хонина; под ред. В.А. Сойфера. -Изд. 2-е, испр. -М.: Физматлит, 2003. -688 с.
- Gall, J. Class-specific hough forests for object detection/J. Gall, V. Lempitsky//Decision forests for computer vision and medical image analysis. -London: Springer, 2013. -P. 143-157.
- Cheriyadat, A.M. Detecting multiple moving objects in crowded environments with coherent motion regions/A.M. Cheriyadat, B.L. Bhaduri, R.J. Radke//Computer Vision and Pattern Recognition Workshops, 2008. CVPRW'08. IEEE Computer Society Conference on. -IEEE, 2008. -P. 1-8.
- Felzenszwalb, P.F. Object detection with discriminatively trained part-based models/P.F. Felzenszwalb, R.B. Girshick, D. Allester, D. Ramanan//Pattern Analysis and Machine Intelligence, IEEE Transactions on. -2010. -Vol. 32, Issue 9. -P. 1627-1645.
- Barinova, O. On detection of multiple object instances using hough transforms/O. Barinova, V. Lempitsky, P. Kholi//Pattern Analysis and Machine Intelligence, IEEE Transactions on. -2012. -Vol. 34, Issue 9. -P. 1773-1784.
- Kim, S.H. Real-Time Traffic Video Analysis Using Intel Viewmont Coprocessor/S.H. Kim, J. Shi, Ab. Alfarrarjeh, D. Xu, Yu. Tan, C. Shahabi/Databases in Networked Information Systems. -Springer Berlin Heidelberg, 2013. -P. 150-160.
- Bramberger, M. Real-time video analysis on an embedded smart camera for traffic surveillance/M. Bramberger, J. Brunner, B. Rinner//Real-Time and Embedded Technology and Applications Symposium, 2004. Proceedings. RTAS 2004. 10th IEEE. -IEEE, 2004. -P. 174-181.
- Wójcikowski, M. FPGA-based real-time implementation of detection algorithm for automatic traffic surveillance sensor network/M. Wójcikowski, R. Żaglewski, B. Pankiewicz//Journal of Signal Processing Systems. -2012. -Vol. 68, Issue 1. -P. 1-18.
- Coifman, B. A real-time computer vision system for vehicle tracking and traffic surveillance/B. Coifman, D. Beymer, Ph. McLauchlan, J. Malik, J. Malik B//Transportation Research Part C: Emerging Technologies. -1998. -Vol. 6, Issue 4. -P. 271-288.
- Koller, D. Towards robust automatic traffic scene analysis in real-time/D. Koller, J. Weber, T. Huang, J. Malik, G. Ogasawara, B. Rao, S. Russell//Pattern Recognition, 1994. Vol. 1 -Conference A: Computer Vision & Image Processing., Proceedings of the 12th IAPR International Conference on. -IEEE, 1994. -Vol. 1. -P. 126-131.
- Bradski, GR. Computer vision face tracking for use in a perceptual user interface/G.R. Bradski//Applications of Computer Vision, 1998. WACV '98. Proceedings., Fourth IEEE Work-shop on. -1998. -214-219.
- Guan, P. Estimating human shape and pose from a single image/P. Guan, Al. Weiss, Al.O. Balan, M.J. Black//Computer Vision, 2009 IEEE 12th International Conference on. -IEEE, 2009. -P. 1381-1388.
- Pentland, A. View-based and modular eigenspaces for face recognition/A. Pentland, B. Moghaddam, T. Starner//Computer Vision and Pattern Recognition, 1994. Proceedings CVPR'94, 1994 IEEE Computer Society Conference on. -IEEE, 1994. -P. 84-91.
- Ahonen, T. Face description with local binary patterns: Application to face recognition/T. Ahonen, A. Hadid, M. Pietikainen//Pattern Analysis and Machine Intelligence, IEEE Transactions on. -2006. -Vol. 28, Issue 12. -P. 2037-2041.
- de Araújo, S.A. Beans quality inspection using correlation-based granulometry/S.A. de Araújo, J.H. Pessota, H.Y. Kim//Engineering Applications of Artificial Intelligence. -2015. -Vol. 40. -P. 84-94.
- Polder, G. Spectral image analysis for measuring ripeness of tomatoes/G. Polder, G. Van der Heijden, I.T. Young//Transactions-American Society of Agricultural Engineers. -2002. -Vol. 45, Issue 4. -P. 1155-1162.
- Ponsa, D. Quality control of safety belts by machine vision inspection for real-time production/D. Ponsa, R, Benavente, F. Lumbreras, J. Martı´nez, X. Roca//Optical Engineering. -2003. -Vol. 42, Issue 4. -P. 1114-1120.
- Xie, X. A review of recent advances in surface defect detection using texture analysis techniques/X. Xie//Electronic Letters on Computer Vision and Image Analysis. -2008. -Vol. 7, Issue 3. -P. 1-22.
- Xu, J. Vision-guided automatic parking for smart car/J. Xu, G. Chen, M. Xie//Proceedings of the IEEE Intelligent Vehicles Symposium. -2000. -P. 725-730.
- Gavrila, D.M. Real-time object detection for “smart” vehicles/D.M. Gavrila, V. Philomin//Computer Vision, 1999. The Proceedings of the Seventh IEEE International Conference on. -IEEE, 1999. -Vol. 1. -P. 87-93.
- OpenCV Cascade Classification. . -URL: http://docs.opencv.org/modules/objdetect/doc/cascade_classification.html (дата обращения 20.05.2015).
- Viola, P. Rapid object detection using a boosted cascade of simple features/P. Viola, M. Jones//Computer Vision and Pattern Recognition, 2001. CVPR 2001. Proceedings of the 2001 IEEE Computer Society Conference on. -IEEE, 2001. -Vol. 1.-P. I-511-I-518.
- Lienhart, R. An extended set of haar-like features for rapid object detection/R. Lienhart, J. Maydt//Image Processing. 2002. Proceedings. 2002 International Conference on. -IEEE, 2002. -Т. 1, Vol. 1.-С. I-900-I-903.
- OpenCV. Haar Cascades. . -URL: http://alereimondo.no-ip.org/OpenCV/34 (дата обращения 1.06.2015).
- Daniels, M. Real-time human motion detection with distributed smart cameras/M. Daniels, K. Muldawer, J. Schlessman, B. Ozer, W. Wolf//Distributed Smart Cameras, 2007. ICDSC'07. First ACM/IEEE International Conference on. -IEEE, 2007. -P. 187-194.
- Sinha, D. Application of MPI for Efficient Detection and Extraction of Features in Video Surveillance/D. Sinha, G. Sanyal//International Journal of Computer Technology and Applications. -2011. -Vol. 2, Issue 5. -P. 1269-1274.
- Herout, A. Real-time object detection on CUDA/A. Herout, R. Jošth, R. Juránek, J. Havel, M. Hradiš, P. Zemčík//Journal of Real-Time Image Processing. -2011. -Vol. 6, Issue 3. -P. 159-170.
- Jia, H. Accelerating viola-jones facce detection algorithm on gpus/H. Jia, Yu. Zhang, W. Wang, J. Xu//High Performance Computing and Communication & 2012 IEEE 9th International Conference on Embedded Software and Systems (HPCC-ICESS), 2012 IEEE 14th International Conference on. -IEEE, 2012. -P. 396-403.
- Norouznezhad, E. Object tracking on FPGA-based smart cameras using local oriented energy and phase features/Eh. Norouznezhad, Ab. Bigdeli, Ad. Postula, Br.C. Lovell//Proceedings of the Fourth ACM/IEEE International Conference on Distributed Smart Cameras. -ACM, 2010. -P. 33-40.
- Neoh, H.S. Adaptive edge detection for real-time video processing using FPGAs/H.S. Neoh, A. Hazanchuk//Global Signal Processing. -2004. -Vol. 7, Issue 3. -P. 2-3.
- Фреймворк передачи сообщений Netty. . -URL: http://zeromq.org/(дата обращения 20.05.2015).
- Zookeeper. . -URL: http://zookeeper.apache.org/(дата обращения 20.05.2015).
- Hirzel, M. IBM Streams Processing Language: Analyzing Big Data in motion/M. Hirzel, H. Andrade, B. Gedik, G. Jacques-Silva, R. Khandekar, V. Kumar, M. Mendell, H. Nasgaard, S. Schneider, R. Soule´, K.-L. Wu//IBM Journal of Research and Development. -2013. -Vol. 57, Issue 3-4. -P. 7:1-7:11. DOI: 10.1147/JRD.2013.2243535.
- Gabriela, J.S. Processing tuples at-least-once in InfoSphere Streams v4 with consistent regions. . -URL: https://developer.ibm.com/streamsdev/2015/02/20/processing-tuples-least-infosphere-streams-consistent-regions/(дата обращения 1.06.2015).
- Chandy, K.M. Distributed snapshots: determining global states of distributed systems/K.M. Chandy, L. Lamport//ACM Transactions on Computer Systems (TOCS). -1985. -Vol. 3, Issue 1. -P. 63-75.
- Valles A. Performance Insights to Intel® Hyper-Threading Technology. . -URL: https://software.intel.com/en-us/articles/performance-insights-to-intel-hyper-threading-technology?language=es (дата обращения 1.06.2015).
- CUDA. . -URL: http://opencv.org/platforms/cuda.html (дата обращения 19.06.2015).
