Analysis of Cyberbullying Incidence among Filipina Victims: A Pattern Recognition using Association Rule Extraction

Author: Frederick F. Patacsil
Journal: International Journal of Intelligent Systems and Applications @ijisa
Article in issue: 11 vol.11, 2019.
Free access
Cyberbullying is an intentional action of harassment along the complex domain of social media utilizing information technology online. This research experimented unsupervised associative approach on text mining technique to automatically find cyberbullying words, patterns and extract association rules from a collection of tweets based on the domain / frequent words. Furthermore, this research identifies the relationship between cyberbullying keywords with other cyberbullying words, thus generating knowledge discovery of different cyberbullying word patterns from unstructured tweets. The study revealed that the type of dominant frequent cyberbullying words are intelligence, personality, and insulting words that describe the behavior, appearance of the female victims and sex related words that humiliate female victims. The results of the study suggest that we can utilize unsupervised associative approached in text mining to extract important information from unstructured text. Further, applying association rules can be helpful in recognizing the relationship and meaning between keywords with other words, therefore generating knowledge discovery of different datasets from unstructured text.
Cyberbullying, association rule, pattern recognition, associative approach
Short address: https://sciup.org/15017108
IDR: 15017108 | DOI: 10.5815/ijisa.2019.11.05
Text of the scientific article Analysis of Cyberbullying Incidence among Filipina Victims: A Pattern Recognition using Association Rule Extraction
Published Online November 2019 in MECS
It is true that cyberbullying became one of the major threats in our society today due to the massive damage that it can cause not only in the cyber world and the internet-based business but also lives of many people. The sole purpose of cyberbullying is to hurt and humiliate someone by posting and sending threats through online. However, recognition of cyberbullying has been proven to be hard and challenging task for information technologists to deeply study and analyze due to the incorporeal nature of cyberbullying which makes social media a perfect fit for bullies [1]. In addition, analysis of textual cyberbullying requires a complex understanding of language and text structures. The complications underlying these activities make automatic detection problematic for static computational approaches. For instance, text analytics using a keyword or bag of words analysis is inadequate to identify occurrences of textual cyberbullying, as an existing bag of words text analysis tools often uses an incomplete cyberbullying keyword dictionary.
In the case of supervised machine learning models, these approaches require annotators to label large amount of the dataset and each of which requires consideration of the textual context and complex language that was used. Therefore, this approach significantly alleviating the need for human experts to perform tedious data annotation [2]. Moreover, these developed methods that used to detect cyberbullying incidence is often formulated as a machine learning classification problem. Typically, document classification, topic detection, and sentiment analysis were used to detect electronic bullying analyzing the characteristics of the text messages [3]. These tasks can be considered well researched and researchers now need to direct efforts towards more advanced tasks, such as in the field of pattern recognition which is concerned with the automatic discovery of unknown cyberbullying word patterns predominantly via textual features. The method of searching meaningful cyberbullying information, the need to search the relationship between all keywords present in those text messages and to produce knowledge of the collected unstructured text cyberbullying messages is a difficult and complex task. Though data mining provides tools such as association rule mining, frequent item set mining and pattern mining for effective mining text, there are still some issues that should be addressed such as how to find the relationship between keywords in the messages, how to generate meanings from the generated keywords and how to generate knowledge using keywords relationship.
To deal with these issues with the unstructured information, text analysis can be helpful to researchers to find meanings or knowledge in this textual information. Text analysis is the automated process of obtaining information from unstructured textual information using an associative approach which focuses on understanding how keyword relate to one another keyword. Collocation (two adjacent words e.g. 'best cake' or 'sales support') method helps identify words that commonly co-occur and seek hidden meaning of the words thus, improve the granularity of the insights by counting bigrams as one word. This method can be also be used to decode the ambiguity of the human language to a certain extent, by looking at how words are used in different contexts, as well as being able to analyze more complex phrases.
Basically, the challenge of this research is decoding the ambiguity of human language used in cyberbullying, and to detect patterns and trends from the results to produce meaning and knowledge.
This study utilized unsupervised associative approach text analysis technique to extract important information from unstructured text of cyberbullying messages. Furthermore, analyzed cyberbullying incidence patterns based on recognized relationship and meaning between cyberbullying keywords with other words to generate knowledge discovery.
The rest of this paper is organized into the following five sections. Introduction followed by reviewed of related literature in section 2. Section 3 discusses the methodology and pattern recognition model. The experimental results and discussion are presented in section 4. Finally, section 5 discussed the conclusion and recommendations for future works.
-
II. Related Works
Related studies defined cyberbullying as an intentional and aggressive act accomplished over a period of time by an individual or a group of individuals through an electronic medium over feeble victim who cannot shield themselves [4]. Cyberbullying can also be a type of harassment that takes place online, via e-mail, text messaging, or online forums, such as social networking sites. Social networks provide the ideal background for data gathering that might enable the criminals to execute their crime. In fact, with the rise of social networking and the immediacy of electronic communication, the potential for harassment, threats, cyberbullying, perceived defamation, and general incivility is greater than ever before [5]. Social media can sometimes be used abusively by unethical and irresponsible users to Cyberbully and post bad and harmful words to humiliate individual’s personality [6, 7]. Thus, it is then important to classify and analyze the cyberbullying words, the cyberbullying messages and cyberbullying word patterns in social media.
-
A. Machine Learning
Several researchers conducted a study to effectively detect cyberbullying messages from social media through Support Victor Machine (SVM) classifier algorithm. This algorithm access highest visited link and also provide age verification before accessing the particular social media. The concept depends upon the text analysis, the data which is uploaded or text written by any user is first analyzed and determined whether is it a bully or not. Both studies found that SVM effectively classify cyberbully messages [8, 9]
Another set of researchers conducted a study that will categorize and analyze comments or posts involving sensitive topics that are personal to an individual which are more likely to be internalized by a victim, often resulting in tragic outcomes. They decomposed the overall detection problem into detection of sensitive topics, lending itself into the text classification subproblems utilizing Random Forest Naïve Bayes, Rulebased, J48, C4.5, SVM, and KNN. Their finding shows that the detection of textual cyberbullying can be tackled by building individual topic-sensitive classifiers. More recently, studies have focused on the use of NLP techniques for the detection and prevention of cyberbullying [10-12]. Furthermore, Yin et al. [12] applied a supervised machine learning approach for the automatic detection of cyber harassment.
-
B. Cyberbullying Word Patterns
The current research focuses on the detection analysis of cyberbullying words and cyberbullying patterns used to bully Filipina victims and posts by harassers/predators using the Tweeter. In addition, this study employed association rules utilizing FP-growth to determine cyberbullying patterns. In addition, text associative approach on pattern recognition technique detects language patterns used by bullies and their victims, an application can be developed based on the rules that was generated by the model to automatically detect cyberbullying content.
-
C. Conceptual framework
A study on bullying reveals that verbal (59%) and social/relational (50%) which suggest that verbal and relational abuse like teasing, demeaning and ignoring classmates were identified as forms of bullying while physical and emotional abuse were attributed as violence or aggression [19, 20]. Verbal and social or relational bullying is comparable with cyberbullying language patterns because it both bullying uses patterns of language to bully victims and the only difference is the medium used. To recognize cyberbullying word pattern, association rule mining is used to find frequent patterns or associations from data sets. Finding the rules that may govern frequency and association between words which enable to predict the occurrence of a specific cyberbullying pattern based on the occurrences of the other words in the data set. Analysis of these cyberbullying patterns that hurt the most sensitivity of female victims whether sex related, social/family, intelligence and physical.
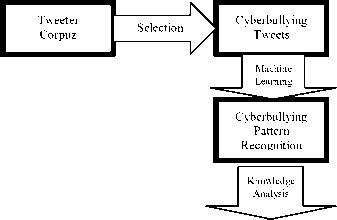
Relationship of Cyberbullying Keywords
\
Sex Related Sex Related Sex Related Sex Related
Fig.1. Conceptual Framework
-
III. Methodology and Pattern Recognition Model
-
A. Data Collection
The first process is the collection of cyberbullying data. The study utilized RapidMiner 7.3 and Web extensions downloaded online specifically the Search Twitter operator. In the gathering process, it took many runs to achieve the desired dataset results. Changing the value of the parameters “query” or the phrase in the “query” will search and retrieve different dataset from Twitter. The parameter or phrase “query” determined the term that should be searched and limit the number of tweets to return. The following terms (e.g. tanga, gago, hayop, baboy, pokpok, puta, and more) were utilized as parameter search possible cyberbullying data. The terms were selected based on the previous researches and also the common terms (e.g. taba, sira, pangit, pokpok, abnormal) used by teenagers for cyberbullying was also employed for searching and filtering purposes [15].
The following criteria were set to determine the characteristics of the tweets:
-
• The average length of a tweet should be 4 words in a sentence
-
• Tweet messages that contain cyberbullying topics were only retained
-
• Only tweet messages that use a combination of Filipino and English and Filipino (“taglish”) or pure Filipino was recorded.
Furthermore, additional validation was conducted to identify whether the owner of tweeter is a female Filipino. Majority of tweets were Filipino and some were combination of English and Filipino (“taglish”). The estimated total dataset of bullying tweets that were gathered were 17,972. Figure 1 shows, the data collection and annotation process that was used to gather posted messages on the Twitter of several accounts. Some of the messages were displayed inside the box, but the source was withheld since the analysis only used the posted messages.
-
B. Data Cleaning
Data cleaning was employed after data collection. The study removes tweets that appeared more than once and the tweets that contain no bullying intention. Only those tweets that contain bullying intention were kept and saved for the next step. A PHP application was developed and employed to clean unnecessary characters that have no value in the cyberbullying pattern recognition process.
Table 1. Sample Tweet
Sample Tweets ung kay quen shadings nmn sinabing manyak like pokpok kay liza malandi gold digger… gets ba malandi matapobre pokpok wala nang ginawang tama matigas ulo walang respeto ano pa may isasakit bang yang sasabihin either bakla sya mas malandi basing (pokpok ang babaeng toh candy lass who knows)
pukyo pokpok malandi pa dati pokpok ngayon malandi nalang kasalanan kasi ito nung malandi naming pokpok kaibigan
-
C. Data Selection and Annotation
The selection and annotation of the cleaned data were made by three female annotators. They were assigned to manually identify whether the tweets are cyberbullying tweets or not. The basis of these grouping was based on the research conducted by Bogart [16]. His study found out and suggest that one rater can rate pretty well, but three can rate better and there is not much gain after increasing to three. The annotators were oriented and trained to determine by applying the criteria for bullying words and nearby words in the tweets. Only tweets identified as bullying was considered as part of the dataset. After the data selection and annotation, the exact total of bullying tweets gathered were 13,440.
-
D. Data Preprocessing
After the data selection and annotation process, the next step employed was the data preprocessing. Data preprocessing includes filtering stop words, stemming, tokenization, case transformation and feature selection or n-gram. The proponent developed a PHP application to filter stop words and stem words to get the root word. However, other preprocessing tasks were done using Rapid Miner.
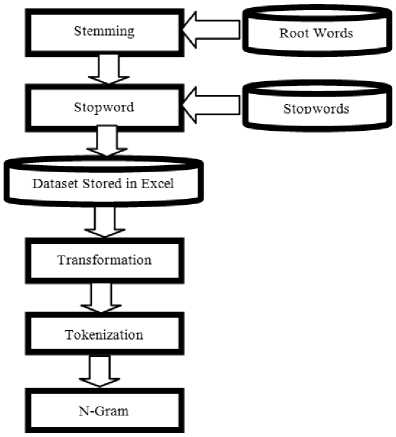
Fig.2. The Preprocessing of Cyberbullying Dataset
-
E. Preprocessing of Dataset
Under the data preprocessing, the first process is to reduce the tweets word into a base form. An automated stemmer was employed utilizing a PHP application and a dictionary of root words store in MySQL database to replace word bases on the replacement rules. Further, the stem process a cyberbullying dictionary was created for the purpose to filter some words which may have the same meaning as Filipino bullying words. Sample stem words are ulol, pakyo, and puta.
Table 2. Sample Stem Tweets
|
Tweets that were not stem |
Stem Word |
|
Olol |
Ulol |
|
fuckyou, fuckGirl, fuccboi, fucking, fuck |
Pakyou |
|
Amputa |
Puta |
The steaming process is very important so that the different forms of the same word are reduced to a common form. Further, stemming process is a feature supported by indexing and search which is very important part of Text Mining applications, Natural Language processing (NLP) systems and Information Retrieval (IR) systems.
-
F. Stop Words Removal
Next is the used of Stopwords (Dictionary) operator to remove all the words equal to the stopwords from the given tweets dataset.
An English stop words translated into Filipino words were used to remove stop words in the tweeter. Stop words were stored using Mysql database and access using the PHP steward application.
-
• Under the data Rapidminer preprocessing, the first step was transforming cases. This operator transforms the cases of letters ( i.e., lower case or upper case ). The study transforms all letters in the
data into lower case for the purpose of convenience.
After case transformation, tokenization was employed. This operator splits the text of a document into a series of tokens. There are several options that can be implied in splitting the text, however the proponent selected the default setting which is the non-letters.
The last step is to utilize n-gram to learn the meaning of words and its neighbors by connecting a sequence of n words from a given sequence of tweets.
Fig.3. Sample stop words in Mysql database
-
G. Pattern Recognition Process
The schema that was utilized to determine the frequency of the words was TF-IDF or Term Frequency – Inverse Document Frequency. This schema was used as numeric measures to show the importance of cyberbullying words in the collection of tweets dataset. The method used to determined the dominant cyberbullying words and patterns is the frequency of the appearance of words in the tweets weighted which has a greater importance. The TF-IDF value increases proportionally to the number of times a word (bullying terms or pronoun) appears in the tweets, but is offset by the frequency of the word in the corpus, which helps to control for the fact that some words are generally more common than others.
-
H. Association Mining Rule
This stage presents a way for mining cyberbullying words from a collection of tweet by automatically extracting frequent words in each tweet. Below we define
Analysis of Cyberbullying Incidence among Filipina Victims: A Pattern Recognition using Association Rule Extraction and describe the association rules:
Consider the following assumptions for representing the association rule in terms of mathematical representation, T = {w i,wi2, … , im } be a set of items. Where tweets Tc = { } t1,t2,..., tm , where each document ti is a set of keywords such that ti ⊆ A . Let Wi be a set of keywords. A tweet ti is said to contain Wi if and only if Wi ⊆ ti . An association rule is an implication of the form Wi ⇒ W j where Wi ⊂ A , Wj ⊂ A and Wi ∩W j = φ . There are two important basic measures for association rules, support(s) and confidence(c). The rule Wi ⇒ W j has support s in the collection of tweets Tc if s% of tweets in Tc contain Wi ∪ Wj . The formula for computing the support and confidence are given below:
Support count of W 1 W j
Support(W 1 W j ) = (1)
Total number of tweets
The rule Wi ⇒ W j holds in the collection of tweets Tc with confidence c if among those tweets that contain Wi , c % of them contain W j also. The confidence is calculated by the following formula:
Confidence
W 1
W j
Support(W 1 W j )
Support ( W 1 )
Frequent item sets are quantified by support which is the ratio of the number of instances where [ w 1 w j ] appeared together in a single transaction to the total number of transactions while the confidence is defined as the probability of finding [ w 1, w j ] together.
This study follows the following mining steps utilizing association rule mining:
-
1) Search all cyberbullying words and the combination of cyberbullying words (cyberbullying wordsets) whose support is greater than the user specified minimum support (called minsup ). Such sets are called the frequent keyword sets [11]. In this study minimum support of (0.2, 0.1, 0.5) were specified input as minsup , if the cyberbullying word meets the condition then words is regarded as frequent cyberbullying words.
-
2) Use the identified frequent cyberbullying wordsets to generate the rules that satisfy a user specified minimum confidence (called minconf ). The frequent keywords generation requires more effort and the rule generation is straightforward.
-
I. Correlation of Cyberbullying Words
Lift ratio is applied in this study to determine the correlation between the words in the rule.
Confidence(A B)
Support (A)
If the value of lift rule > 1 then it has positive correlation. A lift value greater than 1 indicates words appear more often together than expected.
If the value of lift rule < 1 then it has negative correlation. A lift smaller than 1 indicates that words appear less often together than expected.
If the value of lift rule = 1 then it is independent. A lift value of 1 indicates that the words appear almost as often together as expected.
-
J. The Frequent Pattern Growth FP-Growth) Approach
FP-Growth is one of the most utilized association rule mining algorithms. The FP-Growth algorithm mines frequent itemsets without generating the candidates. In this study, the creation of FP-growth Tree consists of the following steps.
-
1. The FP-Growth algorithm starts with the first scan of the datasets (tweets) which derive the set of frequent cyberbullying words single item pattern (1-itemsets). The input minimum support count will be the basis of frequency, then the set of frequent cyberbullying words is sorted in the order of descending.
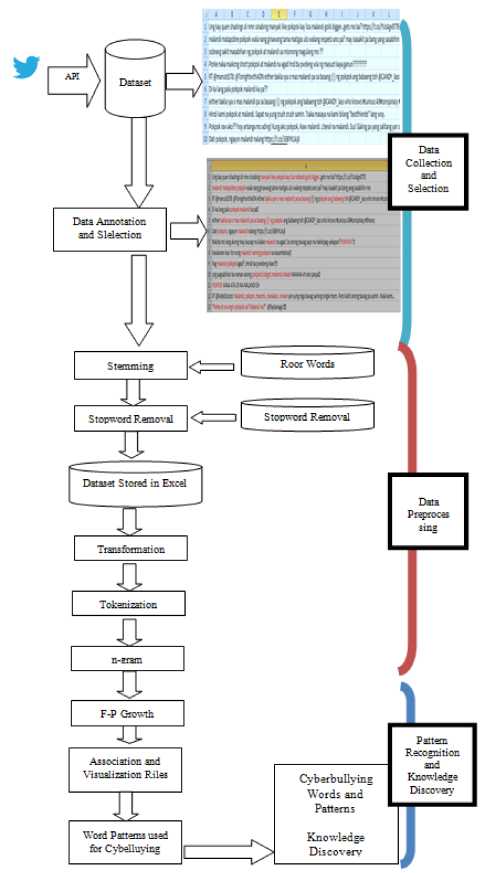
Fig.4. Pattern Recognition Models
-
2. An FP-tree is then constructed as follows.
Construct the conditional FP tree in the sequence of reverse order of F - List - generate frequent item set.
The cyberbullying words in each tweet is processed in L order (i.e., sorted according to descending support count), and a branch is created for each tweet.
Fig. 4 illustrates the whole package of the Pattern Recognition Model which was used in this study. The pattern has three important compartments which embodies several steps to follow (1) data collection, (2) data processing, and (3) data recognition. Cyberbullying word and pattern results obtained from association rule and FP growth were presented and analyzed. The most frequent Filipino bullying terms occurred from the generated dataset
-
1. The first step includes conducting tweet analysis using FP-Growth in terms of frequent patterns of dataset.
-
2. The second step includes the analyzation of a strong relationship between a pair of words using the create association r ules. t o arrive at a strong relationship between items, the proponent experimented difference values for minimum support threshold and values for minimum confidence threshold.
-
3. After pattern recognition experimentation, word visualization was conducted to show the most frequent word used to cyberbully a female twitter user.
-
IV. Results and Discussion
-
A. Dominant cyberbullying words
Table 3 shows the frequent words used in cyberbullying and cyberbullying word frequent patterns.
Table 3. Frequently Used Cyberbullying words
|
Support |
Item |
|
0.397 |
Gaga |
|
0.260 |
Tangina |
|
0.176 |
Hayop |
|
0.139 |
Pakyu |
|
0.087 |
Panget |
|
0.079 |
Ulol |
|
0.079 |
Pokpok |
|
0.065 |
Demonyo |
|
0.056 |
Unggoy |
The dominantly used cyberbullying words were “gaga” (0.397), “tangina” (0.260), “hayop” (0.176), and “pakyu” (0.139). The word “gaga” leads the most frequent cyberbullying word utilized by cyber predator and has several meanings depending on how you use it in a statement. The following words “foolish”, “idiot”, “moron”, “stupid” and “ignorant” were closely related with the word “gaga”.
Example how “gaga” were used in a simple statement
-
• Gaga ka! – You’re an idiot.
-
• Gaga kang babae ! – You’re an idiotic woman!
-
• Ang gaga ng babae mo. – Your woman is so stupid.
-
• Ang gaga ng babaeng ito. – This woman is so ignorant.
-
• Ang gaga mo! – You’re such a moron!
This is one reason why “gaga” is a frequently used cyberbullying word. This is also the common word that humiliate a female internet users due to a different meaning. Another dominant word is “tangina” or the complete word is “putang ina mo” which has different meaning “Mother Fucker”, “your mom’s a prostitute”, “Your mom is a B!TCH!”, and “your mom is a fucking prostitute”. Having different sex related and social family related meaning can embarrass the recipient of the tweets whether it is a male or female. In the Filipino culture mothers are valued by their children that whatever words that destroys the dignity may affect their children.
Another word which is related to “tangina” is “pakyu” in English “Fuck you”. This word is commonly used by teenager in the Philippines to swearword their enemies or someone who is opposed to them. The “pakyu” is a verb in various phrases to express anger, annoyance, contempt, impatience, or surprise, or simply for emphasis. In addition, a word frequently used in cyberbullying is “pokpok” adulterated version in Filipino which means a prostitute. In some instance, it is used for sex related actions to attack a certain individual especially the female. These words are the most frequent words used to cyberbully and degrade the personality or sometimes can cause significant emotional damage to a female victim.
Furthermore, these words were included in the urban dictionaries which were frequently used by teenagers in an actual conversation. In addition, these words are used as sexual bullying often cause distress and devastation to a female victim. The results clearly indicate that sex related cyberbully, social/family and personality associated cyberbullying words were employed by a predator to harass/ bully Filipina victims.
The results of the study are highly related to the study of [13, 15, 18] were cyber predator associated personality/physical words (“ugly”, “dumb”, “freak”) and sex bullying word like (“Bitch”, “Slut”). However, the present study is dominated by sex related cyberbullying words to harass female victims.
-
B. Identified pattern/s of Filipino bullying terms used by Filipino cyber-predator
Table 4 shows cyberbullying patterns under minsup of 20% and minconf of 80 %. The cyberbullying word “gaga” is the dominant frequent cyber words in dataset
|
followed by “pakyu” and “ulol”. Meanwhile, “tangina” was also identified as a dominant cyberbullying words. |
Table 4. Subset of discovered Cyberbullying Patterns under the Minimum Support of 10 % and Minimum Confidence of 90 % |
|||||
|
Clearly, “gaga” is a key cyberbullying word which was combined with other cyberbullying words. A positive relationship was found on “Ulol and pakyu” lif value of 2.618 and “tangina” and “gaga” with a lif value of 1.904, support count of 0.196 and confidence of 0.756. Further, there is a positive relationship “gaga” and “tangina” with a lif value of 1.316, support count of 0.196 and confidence of 0.495. This result indicates that almost 20% of cyberbullying tweets employed “tangina” followed by “gaga” or vice versa. 20% of cyberbullying tweets employed “gaga” followed by “tangina”. Combining these personal and sex related words mean |
Minimum Confidence: Minimum Support: 10 % |
|||||
|
Number of Association Rules : 8 |
||||||
|
Premises |
Conclusion |
Support |
Confident |
Lif |
||
|
Gaga |
Ulol |
0.041 |
0.104 |
1.316 |
||
|
Gaga |
Pakyu |
0.046 |
0.115 |
0.830 |
||
|
Pakyu |
Ulol |
0.029 |
0.207 |
2.618 |
||
|
Pakyu |
Gaga |
0.046 |
0.330 |
0.830 |
||
|
Ulol |
Pakyu |
0.029 |
0.363 |
2.618 |
||
|
Gaga |
Tangina |
0.196 |
0.495 |
1.904 |
||
|
Ulol |
Gaga |
0.041 |
0.523 |
1.316 |
||
|
Tangina |
Gaga |
0.196 |
0.756 |
1.904 |
||
|
great insult both to the female victims and her mother. Ulol and pakyu has the highest correlation with 2.618 followed by “tangina” and “Gaga” with 1.904. These two cyberbullying words has the tendency that they will be found when bullying Filipino female victims online. The results clearly indicate that bullies insult their female victims by relating her as “idiot crazy stupid female that came from a prostitute mother” in which can degrade and humiliate a Filipina victim. |
Table 5. Meaning of Cyberbullying Word Patterns |
|||||
|
Cyberbullying Word Patterns |
Meaning In English |
|||||
|
Gaga Ulol |
|
|||||
|
Tangina pakyu |
• Your mother is a “whore”/,“prostitute” who engages in sexual activity |
|||||
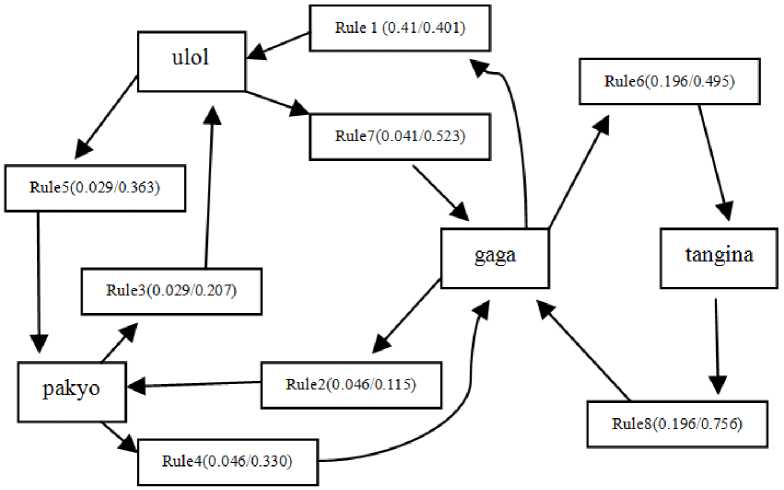
Fig.5. The graphical representation of the discovered rules under Minimum Support of 10 % and Minimum Confidence of 90%
Table 6. Subset of discovered Cyberbullying Patterns under the Minimum Support of 20 % and Minimum Confidence of 80 %
|
Minimum Support: 20 % |
Minimum Confidence: 80 % |
||||
|
Number of Association Rules : 2 |
|||||
|
Premises |
Conclusion |
Support |
Confident |
Lif |
|
|
Gaga |
Tangina |
0.196 |
0.495 |
1.904 |
|
|
Tangina |
Gaga |
0.196 |
0.756 |
1.904 |
|
Table 6 shows cyberbullying patterns under minsup of 20% and minconf of 80 %. The cyberbullying word “gaga” is the dominant frequent cyber words in dataset followed by “tangina”. Meanwhile, the combination of “gaga” and “tangina” was also identified as a dominant cyberbullying word pattern. Clearly, this two cyberbullying words and its combination are the words that cyberbuller used to bully their female cyber victim.
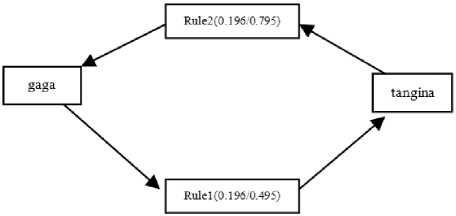
Fig.6. The graphical representation of the discovered rules under Minimum Support of 20 % and Minimum Confidence of 80%
Fig. 6 reveals that there are only 2 cyberbullying combinational rules under 20% minimum support and minimum confidence of 80% were “gaga”, “tangina” and “tangina”, “gaga” to bully female victims. These results show that only few combinational rules can be derived from the dataset when minimum support and minimum confidence is set to these values.
Table 7. Subset of discovered Cyberbullying Patterns under Mininum Support of .05 % and Minumun Confidence of 95 %
|
Minimum Support: 5 % Minimum Confidence: 95 % |
||||
|
Number of Association Rules : 10 |
||||
|
Premises |
Conclusion |
Support |
Confident |
Lif |
|
Tangina |
Landi |
0.012 |
0.046 |
1.027 |
|
Tangina |
Ulol |
0.016 |
0.063 |
0.983 |
|
Gaga |
Ulol |
0.041 |
0.104 |
1.316 |
|
Gaga |
Pakyu |
0.046 |
0.115 |
0.830 |
|
Pakyu |
Ulol |
0.029 |
0.207 |
2.618 |
|
Pakyu |
Gaga |
0.046 |
0.330 |
0.830 |
|
Ulol |
Pakyu |
0.029 |
0.363 |
2.618 |
|
Gaga |
Tangina |
0.196 |
0.495 |
1.904 |
|
Ulol |
Gaga |
0.041 |
0.523 |
1.316 |
|
Tangina |
Gaga |
0.196 |
0.756 |
1.904 |
The experiments choose low threshold support value 5% to extract important words that cannot appear using high minimum support value and chose high threshold minimum confidence value of 95% to extract the more interesting rules.
Table 7 shows cyberbullying patterns under mix-up of 0.5% and minconf of 95 %. Majority of cyberbullying words and patterns were found under minsup of 1% and minconf of 90%, except of the word “landi” and cyberbullying word patterns such as “tangina”, “landi” and “tangina”, “ulol”. “Malandi” means flirtatious, slutty or can be “scandalously flirtatious woman”.
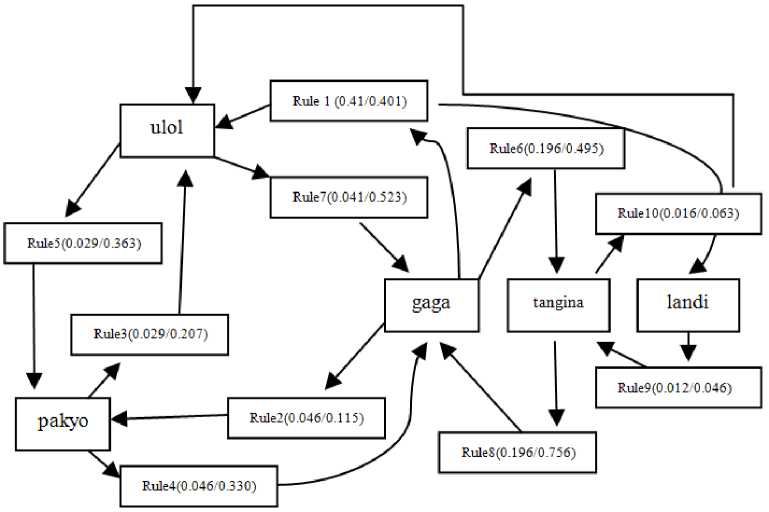
Fig.7. The graphical representation of the discovered rules under Min Support of 5 % and min Confidence of 95%
Fig. 7 reveals that there are two additional cyberbullying combinational rules added under 5% minimum support and minimum confidence of 95% as compared to 10% minimum support and minimum confidence of 90%. These were tangina”, “landi” and “tangina”, “ulol”. “Malandi” These results show that lowering values of minimum support produced many frequent cyberbullying words and this number will decrease as the minimum support increases.
-
V. Conclusion and Recommendation
This study has experimented unsupervised associative approach text mining technique to automatically find cyberbullying words, patterns and extract association rules from a collection of tweets based on the frequent words. Furthermore, this study recognizes the relationship between cyberbullying words with other cyberbullying keywords, thus generating knowledge discovery of different cyberbullying word patterns from unstructured tweets. The study revealed that the dominant frequent cyberbullying words and patterns are intelligence sex related, personality, and insulting words that describes the behavior and appearance of the female victims. The results of the study suggest that we can utilize unsupervised associative approached in text mining to extract important from unstructured text. The technique used and the results of this research may be considered by future researchers as bases of possible solution for automatic detection of cyberbullying traces over a social network to limit or stop cyberbullying. Further, using association rules can be helpful to recognize the relationship and the meaning between keywords with other words and generates knowledge discovery of different datasets from unstructured text. Future research is highly recommended, especially mining cyberbullying words using other method like neural network, clustering techniques to cluster and Naïve Bayes to classify and analyze female cyberbullying. Furthermore, the development of a system that will automatically detect and predict the cyberbullying incidence that occurs in the social media is highly suggested.
References Analysis of Cyberbullying Incidence among Filipina Victims: A Pattern Recognition using Association Rule Extraction
- Potha, N., & Maragoudakis, M. (2014, December). Cyberbullying detection using time series modeling. In Data Mining Workshop (ICDMW), 2014 IEEE International Conference on (pp.373-382). IEEE.
- Raisi, E. and Huang, B., 2018. Weakly supervised cyberbullying detection with participant-vocabulary consistency. Social Network Analysis and Mining, 8(1), p.38.
- Salawu, S., He, Y. and Lumsden, J., 2017. Approaches to automated detection of cyberbullying: A survey. IEEE Transactions on Affective Computing.
- Espelage, D. L., & Swearer, S. M. (2003). Research on school bullying and victimization: What have we learned and where do we go from here?. School psychology review, 32(3), 365-384.
- Bird, L. E., Taylor, T., & Kraft, K. M. (2012). Chapter 10 Student Conduct in the Digital Age: When does the First Amendment Protection End and Misconduct Begin?. In Misbehavior Online in Higher Education (pp. 183-205). Emerald Group Publishing Limited.
- Herman, J. L. (2013). Gendered restrooms and minority stress: The public regulation of gender and its impact on transgender people’s lives. Journal of Public Management & Social Policy, 19(1), 65.
- Livingstone, S., & Helsper, E. J. (2007). Taking risks when communicating on the Internet: The role of offline social-psychological factors in young people’s vulnerability to online risks. Information, Communication and Society, 10(5), 619-644.
- Vinutha, H., & Deepashree, N. S. (2016). An Effective System To Improve The Cyberbullying. IJITR, 4(3), 3002-3006.
- Hosseinmardi, H., Rafiq, R.I., Han, R., Lv, Q., & Mishra, S. (2016, August). Prediction of cyberbullying incidents in a media-based social network. In Advances in Social Networks Analysis and Mining (ASONAM), 2016 IEEE/ACM International Conference on (pp. 186-192). IEEE.
- Dinakar, K., Reichart, R., & Lieberman, H. (2011). Modeling the detection of Textual Cyberbullying. The Social Mobile Web, 11(02).
- Nalini, K., & Sheela, L. J. (2016). Classification using Latent Dirichlet allocation with Naïve Bayes classifier to detect cyber bullying in twitter. Indian Journal of Science and Technology, 9(28).
- Yin, D., Xue, Z., Hong, L., Davison, B. D., Kontostathis, A., & Edwards, L. (2009). Detection of harassment on web 2.0. Proceedings of the Content Analysis in the WEB, 2, 1-7.
- Margono, H., Yi. X., & Raikundalia, G. K. (2014, January). Mining Indonesian cyber bullying patterns in social networks In Proceedings of the Thirty-Seventh Australasian Computer Science Conference Volume 147 (pp. 115-124). Australian Computer Society, Inc..
- Austin, K. 2015. Common Terms Used By Teen Cyberbullies Online. http://www.mobile-spy.com/blog/common-terms-used-by-teen-cyberbullies/
- Beale, A. V., & Hall, K. R. (2007). Cyberbullying: What school administrators (and parents) can do. The Clearing House; A Journal of Educational Strategies, Issues and Ideas, 81(1), 8-12.
- Bogartz, R. S., Interrater Agreement and Combining RatingsUniversity of Massachusetts, Amherst. http://people.umass.edu /~bogartz /Interrater%20Agreement.pdf
- Slater, S. 2014. DCU seeks public’s help to tackle ‘subtle’ cyberbullying. Irish Examiner, http://www.irishexaminer.com./ireland/dcu-seeks-publics-help-to-tackle-subtle-cyberbullying-285366.html
- Winterman, D., (2008). How ‘gay’ became children’s insult of choice. BBC news, 18. Yin, D., Xue, Z., Hond, L., Davison, B.D., Kontostathis, A. and Edwards, L., 2009. Detection of harassment on web 2.0. Proceedings of the Content Analysis in the WEB, 2, pp.1-7.
- Bradshaw, C.P., Waasdorp, T.E., O’Brennan, L.M. and Gulemetova, M., 2011. Findings from the National Education Association’s Nationwide Study of Bullying. National Education Association. Retrieved April, 5, p.2018.
- Villasor, R. 2010. Bulling as Perceived by Adolescent Students, School Counselors, and Teachers. De La Salle University Manila. Presented in the 47th Annual Convention of Psychological Association of the Philippines. Souvenir Invitation. August 18-20,2010. Palawan State University.
- Payne P. 2017. Sex and Dignity? Seriously?, http://www.huffingtonpost.com/peggy-payne/sex-and-dignity-seriously_b_9691660.html
