Application of Machine Learning and Predictive Models in Healthcare – A Review

Author: Benjamin Eli Agbesi, Prince Clement Addo, Oliver Kufuor Boansi
Journal: International Journal of Education and Management Engineering @ijeme
Article in issue: 3 vol.14, 2024.
Free access
The use of predictive analytics or models in healthcare has the potential to revolutionize patient care by identifying high-risk patients and intervening with targeted preventative measures to improve health outcomes. This makes the application of analytics in healthcare a concept of utmost interest, which has been explored in various fashions by several scholars. From predicting patients’ ailments to prescribing appropriate drugs, predictive models have seen massive interest. This work studied published works on predictive models in healthcare and observed that the implementation of predictive models in healthcare is experiencing a notable upswing, with a particular focus on research in the United States, where a majority of the top publications originated. Surprisingly, all of the leading nations in this sector have affiliations spanning many continents, with the exception of Africa and South America, together producing a substantially larger volume of research than other countries. The United States also shone out, accounting for 60% of the top five researchers. Notably, although it was published in 2017 (relatively later), Jiang et al. had the most citations (1,346). These studies' core themes were clinical standards, machine learning terminology, and model accuracy. The Journal of Biomedical Informatics topped among journals, with 54 articles, while Luo Gang emerged as the top-performing author, with 12 publications.
Prediction, machine learning, predictive models, healthcare, patients
Short address: https://sciup.org/15019314
IDR: 15019314 | DOI: 10.5815/ijeme.2024.03.05
Text of the scientific article Application of Machine Learning and Predictive Models in Healthcare – A Review
In recent years, there has been a growing interest in using predictive analytics in all aspects of life [1 – 4] One such key area is to identify patients who are at high risk for developing specific health conditions, such as diabetes or heart disease [5, 6]. Predictive analytics involves the use of machine learning algorithms to analyze large datasets and identify patterns or risk factors that may be associated with certain health conditions [5]. Predictive models in healthcare analytics have reshaped how healthcare organizations work, administering insights into patient care, resource allocation, and control of illness. Medical providers may now use sophisticated analytics to accurately project patient outcomes, identify at-risk groups, and optimize care pathways to increase patient outcomes while reducing costs. Predictive models are utilized in a variety of situations in healthcare, including hospitals, clinics, and health insurance firms. This method includes analyzing massive datasets with machine learning and statistical algorithms to anticipate outcomes and uncover patterns that would otherwise be difficult to identify [3]. Predictive models have become a vital tool for healthcare practitioners in this era of big data, allowing them to make data-driven choices and deliver better treatment for patients. Owing to the growing availability of extensive and intricate healthcare data sources, such as electronic health records, claims data, and genetic information [7, 8] the utilization of predictive models in healthcare analytics has surged in recent years. These predictive models assist medical professionals in recognizing high-risk patients while creating tailored treatment approaches to treat them. This method also allows healthcare providers to manage their operations by forecasting service demand, lowering wait times, and enhancing patient flow. Regarding disease monitoring, global epidemic identification, and public health management, predictive models have proved very helpful. These models enable hospitals and other medical facilities to keep tabs on trends in diseases, anticipate probable outbreaks, and put preventive measures in place like vaccination drives and quarantine protocols. But while the use of predictive analytics has the potential to improve patient care, it also raises important ethical considerations that must be carefully considered and addressed [5]. Using algorithms for prediction in the field of healthcare analytics brings with it unique challenges such as data and information privacy, partiality, and comprehension of outcomes. The objective of this paper is to study existing literature, specifically, works published by scholars relating to innovations and the use and implementation of predictive models in healthcare, in order to establish the intellectual structure of scholars, and their possible collaboration on how predictive models were implemented in healthcare so as to assess their global impact.
2. Methodology and Data Source
This research used existing literature to establish its findings. Scholarly articles in line with machine learning (predictive) models in health care were carefully extracted and mined from the Scopus database on 6th June 2023. This database provides comprehensive access to various scientific articles in all fields including healthcare [9 – 11] and is updated with current literature on a daily basis. It is also the world’s largest citation and abstracts database compared to Web of Science (WoS) and PubMed [12]. The search strategy used a combination of healthcare predictive OR prediction models OR analysis OR analytics AND machine learning as phrases. The inclusion criteria for the search were all relevant fully published literature, without limitation to source type, from 2013 to 2022. This range was chosen to ensure coverage of the most recent at the same time detaching obsolete literature. To ensure comprehensive yet absolute relevance to the topic, the search was fine-tuned to articles published only in 11 key health-related disciplines; Medicine, Decision Sciences, Biochemistry Genetics and Molecular Biology, Health Professions, Environmental Sciences, Neuroscience, Nursing, Pharmacology Toxicology and Pharmaceuticals, Agriculture and Biological Sciences, Immunology and Microbiology and Dentistry. The exclusion criterion was all papers that were retracted. Retracted papers in computer science and any other field of study may be caused by among others, questionable research practices and incorrect or erroneous analysis as posited by [13]. This inclusion and exclusion criterion was used in the search strategy to ensure that only articles that were relevant were collated for the study. As indicated in the work of [14], specificity in searching for literature ensures more accuracy. The search resulted in 2,051 published articles, Fig 1. Based on similar studies conducted by [12, 15], relevant articles were saved and exported in a comma-separated value (.CSV) file format, to collect bibliographic information regarding 1. Publication growth, 2. Authors, 3. Type of document, 4. Countries, 5. Source title or journals and 6. Citations. The Visualization of Similarities (VOS) viewer tool, version 1.6.14 , a free software tool for visualization was used to visualize the relationships that exist between authors, citations, and keywords. VOSviewer uses a technique that puts topics into different clusters, marking them with different colors for easy visualization [15]. There is no specialty however regarding its x and y axes, therefore its orientation does not matter. Generally, the circles and labels represent instances or occurrences, colors for clustering or groups, and connectors or lines represent the connections between occurrences [16–18].
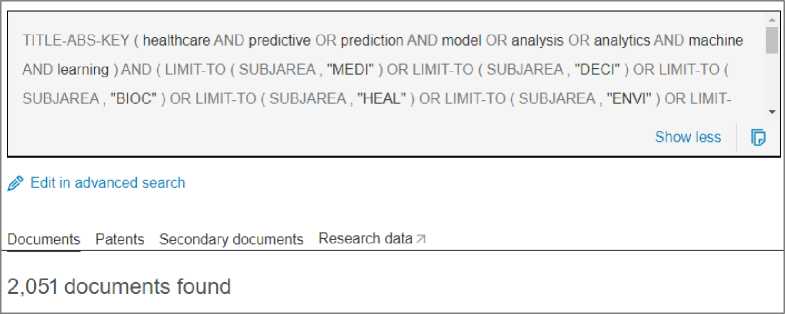
Fig. 1. Search strategy and results
3. Results 3.1 Publication Growth and Geographical Distribution
The bibliometric analysis indicated that there were 2,051 published works that were related to the use of machine learning models in healthcare as of the date of the search. Of these, 57.19% (n = 1,157) were articles, 26.03% (n = 534) were conference proceedings, 204 were Reviews, 86 were chapters, 27 were Conference Reviews, 11 were books, 5 were Editorials, 2 were Errata, 2 short surveys, and 1 letter. Fig. 2 gives a pictorial (pie chart) view of the distribution by source type. The domination of articles indicates among other reasons, an emphasis on rigorousness and scientific progress research in this field. A high number of scholarly papers generally indicates a dedication to furthering scientific or academic understanding of a subject. It indicates a willingness to push the frontiers of knowledge and contribute to the advancement of the area. The analysis again pointed out that the interest in predictive models in healthcare also comes from more than 85 different countries. The top 10 countries alone produced a total percentage of 93.27% (n = 1,913), with the United States of America, India, United Kingdom, and China each publishing more than 100 papers, totaling up to 1,452 representing 70.79% of total publications.
Other (0 0%)
Conference Pape... (26.0%)
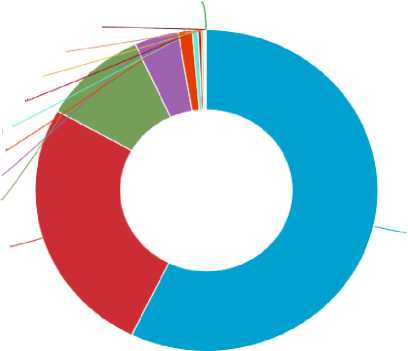
Article (57.2%)
Short Survey (0.1%)
Erratum (0.1%)
Editorial (0.2%)
Note (0.3%) Book (0 5%) Conference Revi... (1.3%) Book Chapter (4.2%) Review (9.9%)
Fig. 2. Distribution by Type of Document
A closer look showed that 9 out of the top 10 countries are members of the G20 [19]. As one of the main aims of this organization is to create sustainable societies committed to achieving equitable health, it may be concluded that these 9 countries had investments to cushion their research, which in consequence aligns with the global aim of equitability in healthcare. The remaining countries have contributed but significantly less than what these G20 countries have done. Looking closely, the top 10 countries had representatives from all continents except for Africa and South America.
Table 1. Top 10 most productive countries
|
SN |
Country |
Publications |
% |
|
1 |
USA |
681 |
33.20 |
|
2 |
India |
471 |
22.96 |
|
3 |
United Kingdom |
170 |
8.29 |
|
4 |
China |
130 |
6.34 |
|
5 |
Canada |
94 |
4.58 |
|
6 |
Italy |
92 |
4.47 |
|
7 |
Saudi Arabia |
88 |
4.29 |
|
8 |
Australia |
67 |
3.27 |
|
9 |
Germany |
64 |
3.12 |
|
10 |
South Korea |
56 |
2.73 |
This observation is intriguing and equally worrying because of the positive impact of predictive models on the human fraternity, which in consequence identifies possible discrepancies in research spending and productivity. It might serve as a wake-up call for these continents to step up their research efforts in healthcare predictive modeling and partner with nations that are at the forefront of the field. It calls into doubt also global health equality. If healthcare predictive modeling research and innovation are focused in a few nations, there may be discrepancies in access to the advantages of these breakthroughs. Table 1 provides the details of the Big 10 regarding the use of predictive models.
Despite the seeming uninterest from some territories, publication growth was however on the rise. From 2013 to 2022, there has been a consistent and steady growth in research into and use of predictive models in healthcare. This can be attributed to a real interest in the field. According to [20] every area of research has three four major stages, 1) the genesis or precursor phase where scholars know little about a topic and hence few or no publications, 2) the stage where scholars begin to have a real sense of the topic through exposure, consequently a relatively slower growth, 3) the maturation phase where scholars have understood the topic and finally 4) the saturation phase where enough knowledge has been generated, leading to a decline in publications. Fig 3 provides a graphical representation of the growth in the publication by year. The years 2013 to 2016 could be adjudged the exposure phase of the use of predictive models in healthcare as publications started appearing to a maximum per year of 35 (year = 2015). The sharp uprise from 2017 (almost a 100% increment compared to its previous year, 2016) makes this research classify 2017 to 2022 as the growth phase of this topic. The graph shows that the maturation phase, where the topic will witness a decline, is yet to come.
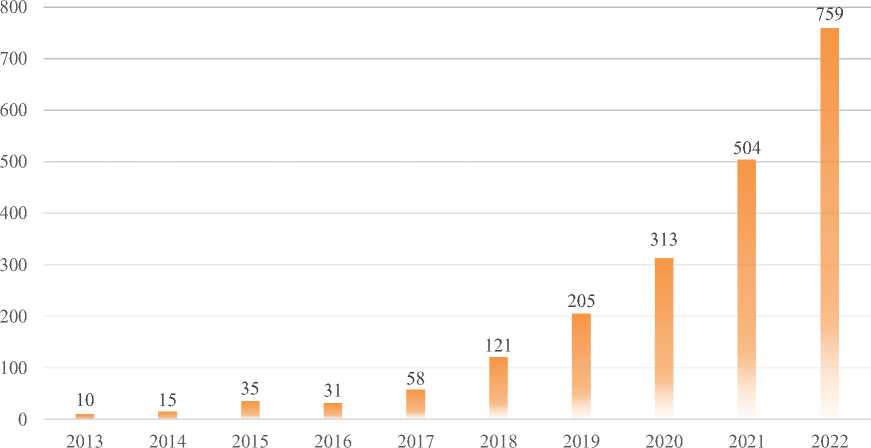
Fig. 3. Publication growth by year
Year
-
3.2 Authors and Citation
The field of science, more especially computing in addition to healthcare, can get very dynamic. Day in and out novel findings, hence information appears in each scene. The ability of technocrats to work together is paramount to progress and new discoveries in the field [21]. The bibliometric analysis pointed out that the most productive author in line with research related to predictive models in healthcare was Luo, G who published a total of 12 papers. Table 2 shows the performance of the top 5 most productive authors and the details of their works.
Table 2. Author Performance
|
SN |
Author |
Territory |
No. of publications |
Avg. Citations |
h-index |
|
1 |
Luo, Gang |
United States |
12 |
14.5 |
8 |
|
2 |
Kahade, Aditya Vishwas |
United States |
10 |
33.1 |
7 |
|
3 |
Schwab, Joseph Hasbrouk |
United States |
10 |
33.1 |
7 |
|
4 |
Scherieier, Gunter |
Austria |
9 |
3.1 |
4 |
|
5 |
Leung, Carson K. |
Canada |
8 |
2.3 |
3 |
*SN is independent of the statistics. It has no bearing on the author’s performance.
-
[22] in trying to understand why citation and references are necessary, indicated that citation gives recognition to a published article and helps identify its sources. A general analogy has it that the more cited a work is, the more valuable or “rich” its content is. However, according to [15], this analogy is flawed and only falls to one side of citation as bigger citations could generally also be attributed to the year of which, hence how long a published work has been in existence [23]. A citation may fall into two broad categories; works cited by an author in a current work and works that cited the work of an author. For this research, citation analysis is based on the latter, works that made reference to the works of the authors, which this work will call direct citations. [24] pointed out that direct citations provide more accurate information hence finding invalidations is limited. Table 3 provides details of the top 10 most cited articles. Analysis of the citations indicated that among the top 10 works related to the use of predictive models in healthcare, works that were published in 2018 (n = 6) totaled 40% of the total citations (n = 2,225/5,556), with 2017 gathering 25%
(n = 1,346/5,556). This observation aligns with the judgment deduced from Fig 2, adjudging 2017 as the year in which the topic started to grow. [20] again posited that higher citations could be attributed to the duration of years of a publication or the impact of the publication. A closer look at Table 3 reveals that the publications that received the highest citation were rather recent i.e., from 2017 to 2020. This would corroborate the latter position of [20] on the impact of publication
-
3.3 Source Titles and Keywords
Table 3.Top 10 most cited publications
|
SN |
Title |
Author(s) |
Country of the first author |
Source Title |
Year |
Time Cited |
*FWCI |
|
1 |
Artificial Intelligence in Healthcare: Past, Present and Future |
Jiaing et al. |
Hong Kong |
Stroke and Vascular Neurology |
2017 |
1346 |
26.08 |
|
2 |
An overview of deep learning in medical imaging focusing on MRI |
Lundervold et al. |
Norway |
Zeistcrift fur Medizinische Phyzik |
2019 |
943 |
45.03 |
|
3 |
Artificial Intelligence (AI) Applications for COVID—19 pandemic |
Vaishya et al. |
India |
Diabeties and Metabolic Syndrome: Clinical Research and Review |
2020 |
694 |
60.37 |
|
4 |
Deep EHR: A Survey of Recent Advances in Deep Learning Techniques for Electronic Health Record (EHR) Analysis |
Shicket et al. |
USA |
IEEE Journal of Biomedical and Health Informatics |
2018 |
556 |
30.1 |
|
5 |
Fully automated echocardiogram interpretation in clinical practice: Feasibility and diagnostic accuracy |
Zhang et. al |
USA |
Circulation |
2018 |
388 |
19.88 |
|
6 |
Artificial Intelligence in retina |
Schmidt-Erfurth et al. |
Austria |
Progress in Retinal and Eye Research |
2018 |
380 |
12.29 |
|
7 |
Federated learning of predictive models from federated Electronic Health Records |
Brisimi et al. |
USA |
International Journal of Medical Informatics |
2018 |
357 |
12.07 |
|
8 |
P4 medicine: How systems medicine will transform the healthcare sector and society |
Flores et al. |
USA |
Personalized Medicine |
2013 |
348 |
2.11 |
|
9 |
Ensuring fairness in machine learning to advance health equity |
Rajkomar et al. |
USA |
Anals of Internal Medicine |
2018 |
274 |
13.25 |
|
10 |
Converging blockchain and nextgeneration artificial intelligence technologies to decentralize and accelerate biomedical research and healthcare |
Momashina et al |
USA |
Oncotarget |
2018 |
270 |
12.01 |
*Field Weighted Citation Impact (FWCI) considers the Year of Publication, Document Type, and Disciplines associated with its source to determine the appropriateness of the article in comparison with similar articles. A bigger value (above 1.00) indicates its performance is above average.
The total number of papers used for this review appeared in more than 30 different journals. Of these, none had made a publication of more than 100. However, one made an appearance in more than 50. Four of these journals have made more than 30 publications, and the remaining falling to less than 30. Table 4 provides a listing of the most influential journals and their details
Table 4. Most Influential journals (ranked on the basis of the total number of publications)
|
SN |
Source Title |
Total publications |
Impact Factor |
*SJR (2022) |
Cite Score |
|
1 |
Journal of Biomedical Informatics |
54 |
8.0 |
1.083 |
8.2 |
|
2 |
BMC Medical Informatics and Decision Making |
38 |
3.3 |
0.940 |
6.2 |
|
3 |
Journal of The American Medical Informatics Association |
33 |
7.9 |
2.440 |
11.7 |
|
3 |
Studies in Health Technology and Informatics |
33 |
0.3 |
0.285 |
1.4 |
|
5 |
IEEE Journal of Biomedical and Health Informatics |
32 |
7.0 |
1.672 |
11.9 |
|
6 |
International Journal of Medical Informatics |
28 |
4.7 |
1.197 |
9.5 |
|
7 |
Smart Innovation Systems and Technologies |
27 |
- |
0.170 |
1.1 |
|
8 |
International Journal of Environmental Research and Public Health |
26 |
4.6 |
0.828 |
5.4 |
|
9 |
Sensors |
25 |
3.9 |
0.764 |
6.8 |
|
10 |
BMJ Open |
22 |
3.0 |
1.059 |
4.4 |
|
10 |
Npj Digital Medicine |
22 |
15.4 |
3.552 |
23.6 |
|
12 |
Journal of Healthcare Engineering |
20 |
3.8 |
0.404 |
3.2 |
*SJR is a measure of the scientific influence of journals that accounts for both the number of citations received by a journal and the importance or prestige of the journals where such citations come from It measures the scientific influence of the average article in a journal, it expresses how central to the global scientific discussion an average article of the journal is.
Research for the themes or keywords for publications related to predictive models in healthcare were visualized and presented in word cloud visualization by mapping of co-occurrences of terms in the title and or abstract for the entire number of articles under study. From the 2,051 published works, 13,933 unique keywords were realized. Of this number, 1,639 appeared in at least 5 works, 828 in at least 10 works and 415 terms occurred at least 20 times. With a keyword threshold of at least 50 appearances, VOSviewer clustered the keywords into four (4) broad categories, represented in Figure 4. The clusters, for the purposes of visual discrimination, were colored as follows; Cluster 1 (color = Red) which involved terms like “adult”, “age”, “male”, “female”, ” age”, “body mass” and “intensive care unit”, all which may be considered as clinical and hospital related terminologies; Cluster 2 (color = Green) mostly had terms like “machine learning”, “forecasting”, “predictive analytics”, nearest neighbor search”, “medical computing”, “predictive analytics” and “logistic regression”, which all related to predictive models, machine learning and data analytics. Cluster 3 (color = Blue) entailed words like “accuracy”, “medical informatics”, “healthcare systems”, “diagnostic imaging” and “predictive medicine”, which seemed more like a combination of computing and healthcare terminologies, and thus may be referred as medical technology, and Cluster 4 (color = Yellow) contained terms like “Bayes Theorem”, “Decision Tree”, “Support Vector Machine” and “random forest”, which are machine learning algorithms.
precision medicine review pandemic
systematic review sars-cov-2
delivery of health care
epidemiology
covid-19
artificial intelligence
data analysis
clinical outcome .
prognosis
data analytics bioinformatics
artificial neural network
follow up
predictive value
accuracy
healthcare health care
a predictive model cohort analysis
article
retrospective studies
female
machine learning dia9n0SiS machine-learning algorithms learning systems support vector machine
adolescent
young adult
adult
male
aged
hypertension risk assessment * nearest neighbor
random forest
predictive analytics cardiotogy nearest neighbor search forecasting a heart
electronic health records
decision trees
middle aged intensive care unit
medical computing hospitals logistic regression
length of stay statistical model

VOSviewer
logistic models
Fig. 4. Word cloud of keywords
4. Findings
The study revealed that there presently is a massive interest in research associated with the use of predictive models in healthcare. This is apparently because of the benefits predictive models bring to bear, not only in health but across all other major sectors ranging from industry to education. Health practitioners are particular in the use of predictive models as they help them detect trends in patients’ sicknesses, among others.
The study proved that publication interest in this topic relating to number started hitting the 100s in the year 2018, with a steady rise even up to 2022, in which year publications have seen up to seven times the fold of that of 2018. This surge and sudden increase point out that predictive model implementation in the health sector is on the rise and technocrats are showing real interest in the field.
Interest in this topic is mainly biased towards researchers in the United States as they produced more research and publications than any other country in the top 10, with 60% of top publishers emanating from the same country, the USA. This geographical disparity relating to this theme indicates an opportunity for more international collaboration among countries which could widen the scope of research relating to predictive models.
All the top 10 countries had affiliations with various continents except for Africa and South America, and have produced significantly more combined, compared to the remaining countries. This finding indicates that efforts would have to be taken to guarantee that the advantages of medical research are distributed in greater proportion across the other parts of the world.
Despite being published later (in 2017) compared to the earliest (in 2013) among the top 10 most cited publications, the work of Jiaing et al. received the most citations 1,346 times, suggesting that the general ideology of oldest publications having the highest citations may be flawed.
The essence of keywords in research enhances searchability, increases precision, and establishes interdisciplinary connections. Incorporating thoughtfully selected keywords will improve a research’s exposure and citations. Significant keywords used in the collated papers hovered around clinical terms, machine learning terminologies, and model accuracy.
Regarding authorship and source titles, the best-performing author was Luo Gang, who produced 12 publications and the most recognized source title was the Journal of Biomedical Informatics being the sole journal with more than 50 publications. Total publications were 54.
5. Conclusion
Healthcare is one, if not the most important thing to humans and all living things. To make the health sectors even more effective has seen the introduction of major developments and innovations from the side of technology among others. One such technological measure is the use of predictive models or analysis in healthcare. The dynamism of the field of science generally necessitates contemporary knowledge. This work fundamentally provides the research environment with a current and vivid overview of the trends relating to knowledge of predictive models relating to healthcare. With such updated knowledge, the research community will have a rudimentary idea of which areas to gear their studies. In this updated research, consideration was given to all works done in line with predictive models in healthcare which were published in Scopus over 10-year duration. The study spanned articles published from 2013 to 2022. It used a bibliometric analysis, paying close attention to the trends in publication, the performance of authors, articles, and journals, and also the relationship between keywords
Availability of Data
The data for this work is available on
Conflict of Interest
The authors declare that there is no conflict of interest regarding this work. This study was conducted with the sole purpose of disseminating and enhancing knowledge.
References Application of Machine Learning and Predictive Models in Healthcare – A Review
- J. L. Rastrollo-Guerrero, J. A. Gómez-Pulido, and A. Durán-Domínguez, “Analyzing and predicting students’ performance by means of machine learning: A review,” Applied Sciences (Switzerland), vol. 10, no. 3, 2020, doi: 10.3390/app10031042.
- Y. Zou and G. Changchun, “Extreme Learning Machine Enhanced Gradient Boosting for Credit Scoring,” 2022.
- K. Y. Ngiam and W. Khor, “Big data and machine learning algorithms for health-care delivery,” Lancet Oncol, vol. 20, no. 5, pp. e262–e273, 2019.
- N. M. Chayal and N. P. Patel, Review of Machine Learning and Data Mining Methods to Predict Different Cyberattacks, vol. 52. 2021. doi: 10.1007/978-981-15-4474-3_5.
- R. Miotto, F. Wang, S. Wang, X. Jiang, and J. T. Dudley, “Deep learning for healthcare: review, opportunities and challenges,” Brief Bioinform, vol. 19, no. 6, pp. 1236–1246, 2018.
- A. Esteva et al., “A guide to deep learning in healthcare,” Nat Med, vol. 25, no. 1, pp. 24–29, 2019.
- J. J. Berman, Principles of big data: preparing, sharing, and analyzing complex information. Newnes, 2013.
- G. J. Kuperman, R. M. Gardner, and T. A. Pryor, HELP: a dynamic hospital information system. Springer Science & Business Media, 2013.
- J. F. Burnham, “Scopus database: a review,” Biomed Digit Libr, vol. 3, no. 1, pp. 1–8, 2006.
- J. Zhu and W. Liu, “A tale of two databases: The use of Web of Science and Scopus in academic papers,” Scientometrics, vol. 123, no. 1, pp. 321–335, 2020.
- S. A. S. AlRyalat, L. W. Malkawi, and S. M. Momani, “Comparing bibliometric analysis using PubMed, Scopus, and Web of Science databases,” JoVE (Journal of Visualized Experiments), no. 152, p. e58494, 2019.
- S. H. Zyoud and S. W. Al-Jabi, “Mapping the situation of research on coronavirus disease-19 (COVID-19): A preliminary bibliometric analysis during the early stage of the outbreak,” BMC Infect Dis, vol. 20, no. 1, pp. 1–8, 2020, doi: 10.1186/s12879-020-05293-z.
- M. Shepperd and L. Yousefi, “An analysis of retracted papers in Computer Science,” PLoS One, vol. 18, no. 5, p. e0285383, May 2023, doi: 10.1371/journal.pone.0285383.
- A. K. Shaikh, S. M. Alhashmi, N. Khalique, A. M. Khedr, K. Raahemifar, and S. Bukhari, “Bibliometric analysis on the adoption of artificial intelligence applications in the e-health sector,” Digit Health, vol. 9, p. 20552076221149296, 2023.
- K. van Nunen, J. Li, G. Reniers, and K. Ponnet, “Bibliometric analysis of safety culture research,” Saf Sci, vol. 108, no. August, pp. 248–258, 2018, doi: 10.1016/j.ssci.2017.08.011.
- N. J. Van Eck and L. Waltman, Visualizing Bibliometric Networks. 2014. doi: 10.1007/978-3-319-10377-8.
- A. B. D. Nandiyanto and D. F. Al Husaeni, “A bibliometric analysis of materials research in Indonesian journal using VOSviewer,” Journal of Engineering Research, 2021.
- N. J. Eck and L. Waltman, “Citation-based clustering of publications using CitNetExplorer and VOSviewer,” Scientometrics, vol. 111, no. 2, pp. 1053–1070, 2017.
- G20, “About G20,” 2023. https://www.g20.org/en/about-g20/ (accessed May 01, 2023).
- D. Price, Little science, big science... and beyond. 1986. Accessed: Aug. 17, 2022. [Online]. Available: http://www.garfield.library.upenn.edu/lilscibi.html
- Fu Yun, Niu Wenyuan, Wang Yunlin, and Li Ding, “Analysis on the author cooperation network in the field of science of science: A case of Science Research Management from 2004 to 2008,” Science Research Management, vol. 30, no. 3, p. 41, May 2009, Accessed: Aug. 18, 2022. [Online]. Available: http://journal26.magtechjournal.com/Jwk3_kygl/EN/
- I. Masic, “The importance of proper citation of references in biomedical articles,” Acta Informatica Medica, vol. 21, no. 3. pp. 148–155, 2013. doi: 10.5455/aim.2013.21.148-155.
- S. Stremersch, N. Camacho, S. Vanneste, and I. Verniers, “Unraveling scientific impact: Citation types in marketing journals,” International Journal of Research in Marketing, vol. 32, no. 1, pp. 64–77, Mar. 2015, doi: 10.1016/j.ijresmar.2014.09.004.
- N. J. van Eck and L. Waltman, “Citation-based clustering of publications using CitNetExplorer and VOSviewer,” Scientometrics, vol. 111, no. 2, pp. 1053–1070, May 2017, doi: 10.1007/s11192-017-2300-7.
