Архитектура базы знаний для анализа возникновения дефектов печатных узлов

Автор: О.В. Чупринова, Я.А. Щеников
Журнал: Известия Самарского научного центра Российской академии наук @izvestiya-ssc
Рубрика: Машиностроение и машиноведение
Статья в выпуске: 3 т.27, 2025 года.
Бесплатный доступ
Целью исследования является рационализация использования данных при тепловизионном контроле, позволяющая внедрить предупреждающие действия. Для достижения поставленной цели необходимо было решить следующие задачи: собрать данные о процессе тепловизионного контроля и сотрудниках, выполняющих контроль; построить связи между таблицами базы знаний; разработать аппарат для обработки данных с целью выявлений дефектов печатных узлов; Обработка данных по числу возникновений определённых дефектов для составления рекомендаций о необходимости введений предупреждающих действий. Гипотеза: при автоматизации процессов тепловизионного контроля возникает необходимость разработки базы знаний для рационального хранения и использования полученных данных. В работе использовался метод имитационного моделирования базы знаний SQL. В результате исследования разработана информационная модель для базы знаний, сообщающая о необходимости внедрения предупреждающих действий.
Печатный узел, база знаний, тепловизионный контроль, предупреждающие действия
Короткий адрес: https://sciup.org/148331136
IDR: 148331136 | УДК: 004.657 | DOI: 10.37313/1990-5378-2025-27-3-189-194
Knowledge Base Architecture for Analyzing Defect Occurrence in Printed Circuit Assemblies
The study aims to optimize data utilization in thermal imaging inspection to facilitate the implementation of preventive measures. To achieve this goal, the following tasks were addressed: сollect data on the thermal imaging inspection process and the personnel performing inspections; establish relationships between tables in the knowledge base; develop a framework for processing data to identify defects in printed circuit assemblies; analyze data on the frequency of specifi c defect occurrences to generate recommendations for preventive actions. Hypothesis: automating thermal imaging inspection processes necessitates the development of a knowledge base for effi cient storage and utilization of acquired data. The study employed SQL knowledge base simulation modeling. As a result, an informational model for the knowledge base was developed, which provides insights into the need for implementing preventive measures.
Текст научной статьи Архитектура базы знаний для анализа возникновения дефектов печатных узлов
Современные производственные процессы, связанные с изготовлением и контролем печатных узлов, требуют высокого уровня автоматизации и анализа данных для минимизации дефектов сборки. Одним из перспективных методов неразрушающего контроля является тепловизионный анализ, позволяющий выявлять скрытые дефекты, такие как перегрев компонентов, контактов или нарушения теплоотвода. Однако эффективное использование данных тепловизионного контроля невозможно без систематизированного хранения, обработки и интеллектуального анализа накопленной информации.
При внедрении автоматизированных систем теплового контроля [1], появляется необходимость в создании базы знаний. База знаний - совокупность семантически объединенных сведений (фактов), относящихся к определенной предметной области, организованных по определенным правилам, которые могут предусматривать их клиаративно-когнитивное (обеспечивающие их понимание и познание) представление, хранение и манипулирование ими [2].
В отличие от обычных баз данных, базы знаний:
-
. содержат семантические связи между элементами;
-
. могут включать правила логического вывода;
-
. часто имеют механизмы рассуждений [3].
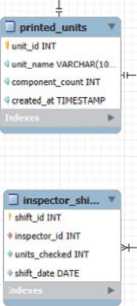
Реляционная архитектура — это подход к организации данных, основанный на реляционной модели. Она использует таблицы (отношения) для хранения данных и устанавливает связи между ними через ключи. Базовая архитектура будет состоять из трех ключевых блоков, включающих в себя информацию о процессе теплового контроля (таблица 1)
Далее, необходимо заполнить связи между столбцами, для дальнейшей обработки данных:
-
1. Работник – неисправность, вид связи – один ко многим. Один работник может зарегистрировать много неисправностей, но каждая неисправность фиксируется только одним работником;
-
2. Печатный узел – неисправность, вид связи – один ко многим. Один печатный узел может иметь много неисправностей, но каждая неисправность относится только к одному узлу;
-
3. Работник – печатный узел, вид связи – многие ко многому. Работник связан с узлами через те неисправности, которые он зарегистрировал.
-
4. Печатный узел – работник, вид связи – агрегация. Такая связь между классами, когда объект одного класса содержит другой объект в качестве своей части. Итоговый общий вид базы знаний представлен на рисунке 1.
Таблица 1. Основные таблицы и содержащиеся в них данные
|
Название таблицы |
Содержание таблицы |
|
Дефекты |
Уникальный номер дефекта |
|
Уникальный номер компонента с выявленным дефектом |
|
|
Уникальный номер проверяющего, обнаружившего дефект |
|
|
Временная метка обнаружения дефекта |
|
|
Сотрудник |
Уникальный номер сотрудника |
|
ФИО |
|
|
Стаж работы |
|
|
Рейтинг |
|
|
Печатный узел |
Количество компонентов в печатном узле |
|
Вид компонента в печатном узле |
□ defects
MetfjdMT
♦ component_type_d ШТ ^f-f mpectofjd ШТ
♦ unit >d ШТ
' defect_tfMe ИМЕНА
iescnpoon TEXT
-
> M«Jd NT
^ inspectors
* mjpectood ШТ
* n«n«VARCHAR( 100
* expen«xe_years IT
* aver«9e_r«t>ng 0КМАЦХ
Рисунок 1 – Общий вид базы знаний
Далее для работы с предупреждающими действиями нужно обработать хранящиеся данные.
Определим 3 основных множества, в которые могут входить данные:
P — множество печатных узлов
D — множество всех дефектов
T — множество типов компонентов
Определим параметры функции для печатных узлов p e P:
id(p) — уникальный идентификатор узла name(p)— название узла count(p)— количество компонентов в узле
Определим параметры функции для дефектов d e D:
unit(d)— идентификатор печатного узла type(d)— тип компонента date(d)— дата регистрации дефекта
Фильтрация по времени
Для временного интервала 5 =30 дней определим подмножество актуальных дефектов Dcurrent:
D current = { d e D\date ( d ) ^ t now — ^ } , (1)
где d – дефект, date(d) - дата регистрации дефекта, tnow –текущая дата
Далее осуществим группировка по узлам
Для каждого печатного узла p e P определим дефекты, связанные с конкретным узлом D p :
Dp ={d e Dcurrentunit(d) = id(P )} ,(2)
где unit(d) – Печатный узел, в котором обнаружен дефект, id(d) – идентификационный номер дефекта.
Определим вычисляемые метрики:
Общее количество дефектов ftotal:
ftotai(P) = Dp I .(3)
Количество затронутых типов компонентов ftypes:
fpss(P) = {ype(d) Id e Dp I } ,( 4)
где type(d) - Тип компонента, к которому относится дефект Плотность (частота возникновения) дефектов на компонент fdensity:
density
-
100 * f totaI ( p ) *100 + 0.5 *10 - 2 . count (p )
Итоговый вид представлен в виде упорядоченного множества кортежей R:
R = { ( name ( p ) f total ( p), ( p ), f derisUy ( p )) | p e P } . (6)
Упорядочивание данных о дефектах. Результат сортируется по убыванию количества дефектов:
V r i r j e R : r i ^ r j ^ П 2( r i ) > П 2( r j ) ,
где π 2 — проекция на второй элемент кортежа (количество дефектов), ri и rj — элементы результирующего множества R, то есть кортежи, содержащие данные о типе компонента, количестве дефектов, названии узла и проценте.
Для узлов без дефектов (D p =0):
f total ( p ) = fippss ( p ) = f density ( p ) = 0 . (8)
Обработка данных, обеспечивающая предложения о введении предупреждающих действий, строится на принципе подсчета повторяющихся однотипных неисправностей. Это может свидетельствовать о проблемах на конкретном участке производственной или сборочной линии.
Введем исходные множества и функции:
Множества:
D — множество всех дефектов;
CT — множество типов компонентов;
PU — множество печатных узлов;
Функции:
type(d) e CT— тип компонента для дефекта d;
unit(d) e PU — печатный узел для дефекта d;
date(d)— дата регистрации дефекта d;
name(ct)— название типа компонента ct;
name(pu) — название печатного узла pu.
Введем связывающую переменную J объединяющую данные из двух разных таблиц в базе, с целью получить нужное подмножество данных:
J = {(d, ct, pu) e Dcurrent * CT * PU\type(d) = ct л unit(d) = pu} ,(9)
Сгруппируем данные по парам тип компонента — узел:
V(ct, pu) e CT * PU, g(ct, pu) = {(d, ct, pu) e J} .(10)
Введем переменную g(ct, pu) – группу дефектов для пары. Для каждой группы g(ct, pu) количество дефектов count( ct , pu ) будет определяться как:
count(ct, pu) = |g(ct, pu)| .(11)
На основе этого, можем ранжировать уровень опасности несоответствия, по количеству возникновений дефектов. Для этого обозначим rec – рекомендации, так, что:
|
" критично ", count ( ct , pu ) > 5 |
|
|
rec ( ct , pu ) = ^ |
" серьезно ",3 < count ( ct , pu ) < 5 " потенциально ", count ( ct , pu ) = 2 " нет ", count ( ct , pu ) < 2 |
Теперь мы можем рассматривать только те дефекты, которые встречаются с периодичностью больше 2 раз в месяц. Для этого введем переменную gfiltr, которая содержит только случаи от «потенциально» возможных несоответствий:
g filtr = { ( ct , pu ) count ( ct , pu ) ^ 2 } .
Подытожим результирующее новое множество R:
R = { ( name(ct ), name(pu ), count(ct, pu ), rec(ct, pu )) |( ct , pu ) e gfiltr } .
И отсортируем в порядке убывания количества дефектов:
V r i ,r j e R : r i ^ r j ^ count ( r i ) > count ( r j ) . (15)
Теперь при возникновении более двух одинаковых дефектов будет возникать предупреждение о возможной неисправности процесса сборки или производства.
В качестве объекта тепловизионного контроля был выбран печатный узел импульсного источника питания, в состав которого входят следующие электронные компоненты, подверженные возникновению дефектов:
-
- предохранитель плавкий;
-
- мост диодный;
-
- микросхема (драйвер);
-
- оптоизолятор;
-
- дроссель входной;
-
- трансформатор;
-
- резистор нагрузочный;
-
- диод выпрямительный выходной;
-
- стабилитрон;
-
- конденсатор выходного фильтра.
Все компоненты печатного узла имеют строгую топологию, что позволяет сегментировать плату, и регистрировать перегрев отдельных компонентов, регистрируя данные в базу знаний. На рисунке 2 представлен пример наполнения компонентами базы знаний.
INSERT INTO conponent_types (type_name, description, unit_id) ('Конденсатор', 'Электролитический конденсатор 100мкФ', 1), ('Резистор', 'Резистор ЮкОм’, 1), ('диод', 'мост диодный', 2), ('дроссель', 'дроссель входной', 3);
Рисунок 2 – Наполнение базы знаний компонентами печатного узла импульсного источника питания
Далее классифицированные по уникальному id компонента, обнаруженные дефекты регистрируются базой знаний, включая в себя определение временной метки обнаружения дефекта и id-номер специалиста, обнаружившего дефект (рисунок 3).
INSERT INTO defects (component_type_id, inspector_id, unit_id, defect_date) (1, 1, 1, '2024-09-15'), (1, 2, 1, '2024-09-20'), (3, 3, 2, ’2024-09-10), (5, 1, 3, '2024-09-05'), (1, 2, 1, '2024-09-25'), (3, 3, 2, '2024-09-18'), (1, 1, 1, '2024-10-01')j
Рисунок 3 – Зарегистрированные дефекты печатного узла импульсного источника питания
По количеству возникновений однотипных дефектов можно определить критерии оценки вероятности (P) рисков возникновения дефектов печатного узла (таблица 2).
Таблица 2. Критерии оценки вероятности (P) рисков возникновения дефектов печатного узла импульсного источника питания
|
Уровень влияния |
Степень влияния сложность корректировки неисправности |
Частота возникновения неисправностей в месяц, % |
|
1 |
Нет |
0...5 |
|
2 |
Низкая |
5.1...10 |
|
3 |
Средняя |
10.1...15 |
|
4 |
Высокая |
15.1...20 |
|
5 |
Очень высокая |
> 20 |
Для определения предупреждающих действий необходимо составить матрицу рисков по возникающим дефектам (таблица 3).
Таблица 3. Матрица рисков возникновения неисправностей компонентов печатного узла импульсного источника питания
|
№ пп |
Риск возникновения неисправностей компонентов печатных плат |
Рн Л О О К о о m |
си S S ч m |
ей а Л о и о |
Меры снижения вероятности возникновения неисправностей в печатных платах |
|
1 |
Холодная пайка из-за нестабильной температуры |
4 |
4 |
16 |
Внедрение SPC (ГОСТ Р ИСО 7870-1-2022), калибровка оборудования (IPC-J-STD-001) |
|
2 |
Короткое замыкание из-за перемычек при трафаретной печати |
3 |
5 |
15 |
Контроль толщины пасты (IPC-7525), AOI-инспекция (IPC-A-610) |
|
3 |
Деформация платы при перегреве в печи |
2 |
5 |
10 |
Использование текстолита с высоким Tg (ГОСТ Р 52931), термопрофилирование (IPC- 7530) |
|
4 |
Окисление контактов из-за высокой влажности |
3 |
3 |
9 |
Хранение материалов в контролируемых условиях (ГОСТ 15150), ускоренные испытания (IEC 60068-2-30) |
|
5 |
Неправильная установка компонентов |
2 |
4 |
8 |
Рентген-контроль (IPC-A-610), обучение операторов (ГОСТ Р 58092-2018) |
|
6 |
Обрыв дорожек из-за механических нагрузок |
1 |
5 |
5 |
Проектирование с запасом прочности (ГОСТ Р 53429-2009), тестирование на вибростенде (IEC 61189-3) |
ЗАКЛЮЧЕНИЕ
В работе описана архитектура базы знаний для процесса теплового контроля, которая обрабатывает данные и выдает предупреждение о необходимости дополнительной проверки или внедрения предупреждающих действий. Данная база знаний является основой, которую можно масштабировать под конкретные цели. Создание дашбордов, пользовательского интерфейса, дополнительные таблицы с данными о процессе, жизненном цикле продукции, а также создание связей между отделами производства и сборки с привязкой к компонентам, даст возможность автоматизации рутин- ных процессов обработки данных теплового контроля и снижение возможных ошибок оператора-контролера.
