Архитектуры нейронных сетей

Автор: Кузьменко А.А.
Журнал: Инфокоммуникационные технологии @ikt-psuti
Рубрика: Школа молодого ученого
Статья в выпуске: 2 т.20, 2022 года.
Бесплатный доступ
Нейронные сети в настоящее время являются одной из самых современных творческих и интересных областей знаний. Использование нейронных сетей позволяет решать многие задачи, с которыми иные подходы почти невозможны в связи со сложностью решения данных задач. К настоящему времени существует большое количество архитектур нейронных сетей - от простых, как персептрон, до нейронных сетей с триллионами параметров. Такое разнообразие архитектур нейронных сетей обуславливаются задачами, которые ставятся перед ними. Помимо этого, область применения нейронных сетей также растет вследствие возможности их применения по причине роста объема данных и вычислительных мощностей. В статье приведен обзор основных архитектур нейронных сетей, на основе которых стоятся современные нейронные сети, нашедших применение во многих аспектах повседневной жизни.
Нейронная сеть, перцептрон, нейронные сети прямого распространения, нейронная сеть хопфилда
Короткий адрес: https://sciup.org/140297110
IDR: 140297110 | УДК: 004.032.26 | DOI: 10.18469/ikt.2022.20.2.15
Neural network architectures
Neural networks are currently one of the most modern creative and interesting areas of knowledge. The use of neural networks allows solving many problems when the use of other approaches is almost impossible due to their complexity. Todaty, there are a large number of neural network architectures available, including simple ones like perceptron and neural networks with trillions of parameters. Such a variety of neural network architectures is determined by the tasks they face. In addition, the scope of neural networks is also growing due to the emergence of the possibility of their application in connection with increasing data volumes and computing power. The article provides an overview of the main of neural networks architectures, which serve as the basis for development of the modern neural networks, that can be used in many aspects of everyday life.
Текст научной статьи Архитектуры нейронных сетей
Нейронные сети в настоящее время являются одной из самых современных творческих и интересных областей знаний. Использование нейронных сетей позволяет решать многие задачи, с которыми иные подходы почти невозможны в связи со сложностью решения данных задач. К таким задачам относятся [1]:
-
• Распознавание объектов на изображениях;
-
• Рисование картин;
-
• Понимание и обработка устной речи;
-
• Нахождение паттернов в больших объемах данных;
-
• Ориентация в пространстве и т. д.
Данные задачи с легкостью решаются с использованием нейронных сетей.
В связи с тем что использование нейронных сетей позволяет решать широкий спектр задач, тема машинного обучения, интеллектуальных алгоритмов и искусственного интеллекта является довольно популярной, что подтверждает статистика GoogleTrends (рисунок 1).
К настоящему времени насчитывается огромное количество архитектур нейронных сетей – от простых, как перцептроны, до нейронных сетей с триллионами параметров (Open AI GPT-3) [3].
аб
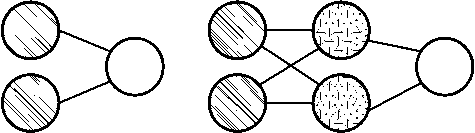
Рисунок 2. Нейронные сети прямого распространения (FFNN) ( б ) и перцептрон (P) ( а ) [5]
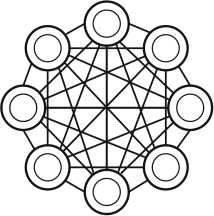
Рисунок 3. Нейронная сеть Хопфилда [5]
Нейроные сети прямого распространения
Первым видом рассматриваемых нейронных сетей будут нейронные сети прямого распространения и перцептроны. Данная архитектура нейронной сети является прямолинейной и передает информацию от входа к выходу. Строение этой архитектуры нейронных сетей напоминает слоеный пирог, где нижний слой представляет собой входы нейронной сети, а самый верхний – выходы, другие же слои являются скрытыми. При данной архитектуре нейронных сетей нейроны одного слоя не связаны друг с другом, но каждый слой связан с предыдущим [4] (рисунок 2).
Данная архитектура нейронной сети обычно обучается методом обратного распространения ошибки, при котором на вход и выход подается большое количество данных. Данный метод обучения относится к методам обучения с учителем, о котором будет подробнее рассказано далее. Вышеупомянутая ошибка является разницей между вводом и выводом. Если у сети есть достаточное количество скрытых нейронов, она теоретически способна смоделировать взаимодействие между входным и выходными данными. Практически такие сети используются редко, но их часто комбинируют с другими типами для получения новых [6].
К нейронным сетям прямого распространения также относятся и нейронные сети радиальнобазисных функций (RBF), которые используют радиальные базисные функции как функции активации [7].
аб
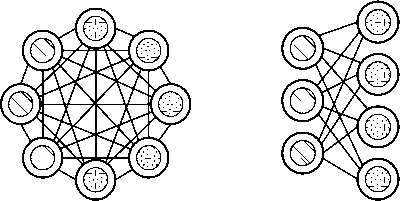
Рисунок 4. Нейронная сеть BM ( а ) и RBM ( б ) [5]
Нейронные сети на базе цепей Маркова
Нейронная сеть Хопфилда (HN) является полносвязной нейронной сетью с симметричной матрицей связи. Особенностью данной сети стало то, что во время получения данных каждый узел сети служит входом и после обучения (когда данные узлы становятся скрытыми) выходами (рисунок 3).
Данная нейронная сеть основана на принципе цепей Маркова. Обучение данной сети происходит с установки значений нейронов в соответствии с желаемым шаблоном. В процессе обучения нейронная сеть формирует веса, которые после обучения не изменяются.
Нейронная сеть Хопфилда может обучаться по нескольким шаблонам и при поступлении новых данных склоняется к тому или иному шаблону. Недостатком этого является то, что шаблон, к которому склоняется нейронная сеть, не всегда будет желаемым.
HN стабилизируется в зависимости от общей «энергии» и «температуры» сети. У каждого нейрона есть свой порог активации, зависящий от температуры, при прохождении которого нейрон принимает одно из двух значений, которые обычно равны -1 или 1, а в более редких случаях 0 или 1. Данная архитектура нейронной сети относится к сетям с ассоциативной памятью [8].
Еще одной архитектурой нейронных сетей, основанных на цепях Маркова, является машина Больцмана (BM). Архитектура данной сети очень схожа с архитектурой нейронных сетей HN, разница между ними заключается только в том, что у BM часть нейронов являются постоянно скрытыми (рисунок 4).
Входные нейроны у данной нейросети, также как и у HN, становятся и выходными после обучения. Алгоритм обучения BM происходит по методу обратного распространения ошибки или алгоритму сравнительной расходимости и в целом схож с процессом обучения сетей HN. Данная архитектура нейронной сети называется стохастической сетью [9].
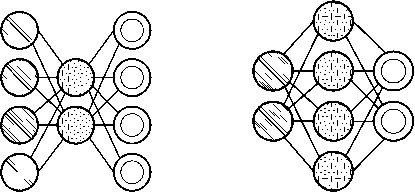
аб
Рисунок 5. Нейронная сеть AE ( а ) и SAE ( б ) [5]
Разновидностью BM является ограниченная машина Больцмана (RBM). Данная архитектура нейронной сети схожа с BM, с разностью лишь в том, что нейроны одного типа не связаны друг с другом.
Данный тип нейронных сетей возможно обучать как нейронные сети FFNN, с разницей лишь в том, что вместо прямой передачи данных и обратного распространения ошибки нужно передавать данные сперва в прямом направлении, затем в обратном. После этого проходит обучение по методу прямого и обратного распространения ошибки [5; 10].
Нейронные сети типа автокодировщики
Архитектура нейронной сети автокодировщик (AE) имеет сильное сходство с архитектурой нейронной сети FFNN, что обусловлено тем, что AE можно назвать иным использованием FFNN. Основной идеей данной архитектуры является автоматическое сжатие информации. По внешнему виду архитектура данной сети напоминает песочные часы. Скрытые слои в AE содержит меньше входов и выходов, а сама архитектура является симметричной (число входов равно числу выходов). Обучение сети происходит по методу обратного распространения ошибки. При обучении AE на вход подаются входные данные, а ошибка между входом и выходом принимается равной разнице между входом и выходом [11] (рисунок 5).
Среди архитектур нейросетей имеется и противоположность AE, которая называется разряженным автокодировщиком (SAE). В отличии от AE, данная архитектура имеет большее количество скрытых нейронов, чем входов и выходов. При данной архитектуре нейронных сетей информация отображается в большем количестве узлов. Сети такого типа полезны для работы с большим количеством мелких свойств набора данных. Если обучать сеть как обычный автокодировщик, ничего полезного не выйдет. Поэтому кроме входных данных подается еще и специаль-
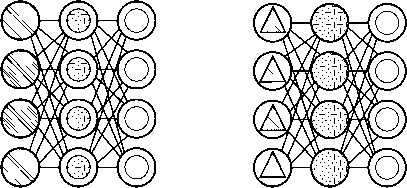
аб
Рисунок 6. Нейронная сеть VAE ( а ) и DAE ( б ) [5] ный фильтр разреженности, который пропускает только определенные ошибки [12].
Еще одной разновидностью нейронных сетей AE являются вариационные автокодировщики (VAE). Данные нейронные сети имеют сходство с AE, но их обучение происходит по иному способу, нежели AE, а именно по методу приближения вероятностного распределения входных образцов. Данной особенностью VAE обязаны BM, но, в отличие от BMVAE, используют бей-совскую математику в случаях, когда речь идет о вероятностных выводах и независимости, которые интуитивно понятны, но сложны в реализации. Данная нейронная сеть принимает во внимание влияние нейронов. Основы VAE сводятся к следующему: учитывайте влияние. Если одно происходит в одном месте, а другое происходит где-то еще, они не обязательно связаны. Если они не связаны, то распространение ошибки должно учитывать это. Это полезный подход, потому что нейронные сети представляют собой большие графы (в некотором роде) [13].
Нейронная сеть DAE (шумоподавляющий автокодировщик) являются нейронными сетями архитектуры AE, которые при обучении обращают внимание на более широкие свойства входных данных, нежели маленькие, которые подвержены изменениям вследствие зашумленности. Обращения на широкие свойства входных данных удается добиться благодаря тому, что обучение данной нейронной сети происходит на зашумленных данных. Ошибка вычисляется так же, как и в AE, и выходные данные сравниваются с зашумленными [14] (рисунок 6).
Рекуррентные нейронные сети
Рекуррентные нейронные сети (RNN) являются FFNN с завихрением времени: они не апатриды; у них есть связи между проходами, связи во времени. Нейроны получают информацию не только от предыдущего слоя, но и от самих себя с предыдущего прохода. Это означает, что порядок, в котором вы вводите входные данные и обучаете сеть, имеет значение: подача «молока», а затем
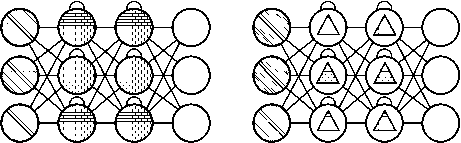
аб
Рисунок 7. Нейронная сеть RNN ( а ) и GRU ( б ) [5]
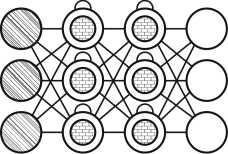
Рисунок 8. Нейронная сеть LSTM [5]
«печенья» может дать разные результаты по сравнению с подачей «печенья», а затем «молока». Одной из больших проблем с RNN является проблема исчезающего (или взрывающегося) градиента, когда, в зависимости от используемых функций активации, информация со временем быстро теряется, точно так же, как очень глубокие FFNN теряют информацию в глубине. Интуитивно это не было бы большой проблемой, потому что это просто веса, а не состояния нейронов, но веса во времени – это то место, где хранится информация из прошлого; если вес достигнет значения 0 или 1 000 000, предыдущее состояние будет не очень информативным (рисунок 7).
В принципе RNN можно использовать во многих областях, поскольку большинство форм данных, которые на самом деле не имеют временной шкалы (т. е. в отличие от звука или видео), могут быть представлены в виде последовательности. Изображение или строка текста могут передаваться по одному пикселю или символу за раз, поэтому веса, зависящие от времени, используются для того, что было раньше в последовательности, а не для того, что произошло за x секунд до этого [15].
В общем, рекуррентные сети – хороший выбор для продвижения или дополнения информации, такой как автозаполнение.
Долго/кратковременная память (LSTM) сети пытается бороться с проблемой исчезающего/ взрывающегося градиента, вводя гейты и явно определенную ячейку памяти. Она вдохновлена главным образом схемотехникой, а не столько биологией. Каждый нейрон имеет ячейку памяти и трое ворот: вход, выход и забывание. Функция этих ворот состоит в том, чтобы защищать информацию, останавливая или разрешая ее поток (рисунок 8).
Входной вентиль определяет, сколько информации из предыдущего слоя сохраняется в ячейке. Выходной слой берет на себя работу на другом конце и определяет, какая часть следующего слоя узнает о состоянии этой ячейки [16].
Закрытые рекуррентные блоки (GRU) являются небольшой вариацией LSTM. У них на один гейт меньше и разводка немного другая: вместо входа, выхода и забывчивого гейта у них есть гейт обновления. Этот шлюз обновления определяет, сколько информации нужно сохранить из последнего состояния и сколько информации пропустить из предыдущего уровня. Ворота сброса работают так же, как ворота забывания LSTM, но расположены немного иначе.
Они всегда посылают свое полное состояние, у них нет выходных ворот. В большинстве случаев они функционируют очень похоже на LSTM, с самым большим отличием в том, что GRU немного быстрее и проще в работе (но также немного менее выразительны). На практике они, как правило, компенсируют друг друга, поскольку вам нужна более крупная сеть, чтобы восстановить некоторую выразительность, что, в свою очередь, сводит на нет преимущества в производительности [17].
Двунаправленные рекуррентные нейронные сети, двунаправленные сети долговременной/ кратковременной памяти и двунаправленные рекуррентные блоки (BiRNN, BiLSTM и BiGRU соответственно) выглядят точно так же, как и их однонаправленные аналоги. Разница в том, что эти сети связаны не только с прошлым, но и с будущим. Например, однонаправленные LSTM могут быть обучены предсказывать слово «рыба», вводя буквы одну за другой, при этом повторяющиеся соединения во времени запоминают последнее значение. BiLSTM также будет получать следующую букву в последовательности при обратном проходе, что дает ей доступ к будущей информации. Это обучает сеть заполнять пробелы, а не продвигать информацию, поэтому вместо расширения изображения на краю она может заполнить дыру в середине изображения [18].
Комбинированные нейронные сети
Нейронная сеть типа deepbelief (DBN) представляет собой соединенные между собой несколько нейронных сетей с архитектурой RBM или VAE. Обучение таких сетей происходит поблочно, при этом каждому блоку необходимо уметь закодировать предыдущий. Такая техника называется «жадным обучением», которая заключается в выборе локальных оптимальных реше-
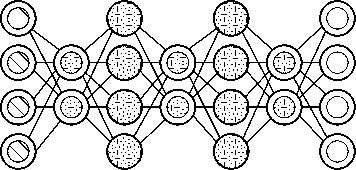
Рисунок 9. Нейронная сеть DBN [5]
ний, не гарантирующих оптимальный конечный результат. Имеется также возможность обучения DBN с использованием метода обратного распространения ошибки, таким образом DBN можно будет обучить отображать данные в виде вероятностной модели. При обучении DBN без учителя стабилизированную модель можно использовать для генерации новых данных [19] (рисунок 9).
Генеративно-состязательные сети (GAN) относятся к разным сетям, они близнецы: две сети, работающие вместе. GAN состоят из любых двух сетей (хотя часто это комбинация FF и CNN), одна из которых предназначена для создания контента, а другая должна оценивать контент. Дискриминирующая сеть получает либо обучающие данные, либо сгенерированный контент из генеративной сети. Насколько хорошо дискриминирующая сеть смогла правильно предсказать источник данных, затем используется как часть ошибки для генерирующей сети. Это создает форму конкуренции, когда дискриминатор становится лучше в различении реальных данных от сгенерированных данных, а генератор учится становиться менее предсказуемым для дискриминатора. Это хорошо работает отчасти потому, что даже довольно сложные шумоподобные паттерны в конечном итоге предсказуемы, но сгенерированный контент, похожий по функциям на входные данные, сложнее научиться различать. GAN может быть довольно сложно обучать, так как вам нужно не просто обучать две сети (каждая из которых может создавать свои проблемы), но их динамика также должна быть сбалансирована. Если прогнозирование или генерация становятся слишком хорошими по сравнению с другими, GAN не будет сходиться, поскольку существует внутреннее расхождение [23] (рисунок 10).
Сверточные нейронные сети
Сверточные нейронные сети (CNN) и глубинные сверточные нейронные сети (DCNN) сильно отличаются от большинства других сетей. Они в основном используются для обработки изображений, но также могут применяться для других типов ввода, таких как аудио (рисунок 11).
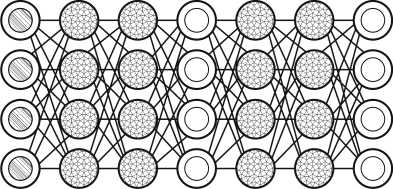
Рисунок 10. Нейронная сеть GAN [5]
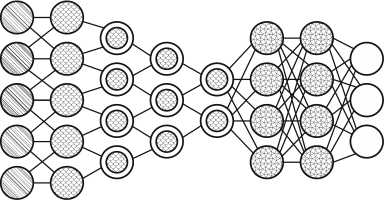
Рисунок 11. Нейронная сеть CNN [5]
Типичный вариант использования CNN – это когда вы загружаете сетевые изображения, а сеть классифицирует данные, к примеру, она выводит «кошка», если вы даете ей изображение кошки, и «собака», когда вы даете ей изображение собаки. CNN, как правило, начинают со «сканера» ввода, который не предназначен для одновременного анализа всех обучающих данных. Например, чтобы ввести изображение размером 200 x 200 пикселей, вам не нужен слой с 40 000 узлов. Вместо этого вы создаете сканирующий входной слой, скажем, 20 x 20, в который вы загружаете первые 20 x 20 пикселей изображения (обычно начиная с верхнего левого угла).
После того как вы передали этот ввод (и, возможно, использовали его для обучения), вы передаете ему следующие 20 x 20 пикселей: вы перемещаете сканер на один пиксель вправо. Обратите внимание, что нельзя переместить входные данные на 20 пикселей (или любую другую ширину сканера), вы не разбиваете изображение на блоки 20 x 20, а скорее, просматриваете его.
Затем эти входные данные передаются через сверточные слои вместо обычных слоев, где не все узлы подключены ко всем узлам. Каждый узел занимается только близкими соседними ячейками (насколько они близки, зависит от реализации, но обычно не более нескольких). Эти сверточные слои также имеют тенденцию сжиматься по мере того, как они становятся глубже, в основном за счет легко делимых коэффициентов входных данных (так что 20, вероятно, перейдут к слою 10, за которым следует слой 5). Здесь очень часто используются степени двойки,
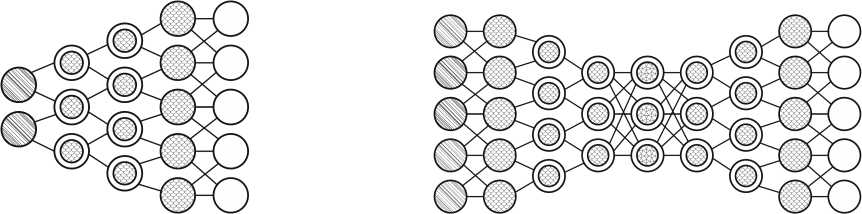
Рисунок 12. Нейронная сеть DN [5]
так как они могут быть четко и полностью разделены по определению: 32, 16, 8, 4, 2, 1.
Помимо этих сверточных слоев, они также часто имеют объединяющие слои. Объединение – это способ отфильтровать детали: часто встречающийся метод объединения – это максимальное объединение, когда мы берем, скажем, 2 x 2 пикселя и передаем пиксель с наибольшим количеством красного. Чтобы применить CNN для звука, вы в основном подаете входные звуковые волны и дюйм по длине клипа сегмент за сегментом.
Реальные реализации CNN часто приклеивают FFNN к концу для дальнейшей обработки данных, что позволяет использовать очень нелинейные абстракции. Эти сети называются DCNN, но названия и аббревиатуры между этими двумя сетями часто применяются взаимозаменяемо [20].
Развертывающие нейронные сети (DN), также называемые обратными графическими сетями (IGN), представляют собой обратные сверточные нейронные сети. Представьте, что вы кормите сеть словом «кошка» и обучаете ее создавать кошачьи изображения, сравнивая то, что она генерирует, с реальными изображениями кошек (рисунок 12).
DNN можно комбинировать с FFNN точно так же, как обычные CNN, но это тот момент, когда линия подводится к придумыванию новых сокращений. На них можно ссылаться как на нейронные сети с глубокой деконволюцией, но вы можете утверждать, что, когда вы прикрепляете FFNN к задней и передней части DNN, вы получаете еще одну архитектуру, которая заслуживает нового названия. Обратите внимание, что в большинстве приложений на самом деле не будет передаваться текстовый ввод в сеть, скорее, входной вектор двоичной классификации. Представьте, что <0, 1> – кошка, <1, 0> – собака, а <1, 1> – кошка и собака [21].
Глубоко сверточные инверсные графические сети (DCIGN) имеют несколько вводящее в заблуждение название, поскольку на самом деле они являются VAE, но с CNN и DNN для соответ-
Рисунок 13. Нейронная сеть DCIGN [5]
ствующих кодировщиков и декодеров. Эти сети пытаются смоделировать «признаки» в кодировке как вероятности, чтобы научиться создавать картинку с кошкой и собакой вместе, видя только одну из двух на отдельных картинках. Точно так же вы можете скормить ей изображение кота с надоедливой соседской собакой и попросить убрать собаку, даже не проделав такой операции. Демонстрации показали, что эти сети также могут научиться моделировать сложные преобразования изображений, такие как изменение источника света или вращение 3D-объекта. Эти сети, как правило, обучаются с обратным распространением [22] (рисунок 13).
Нейронные сети со случайными связями
Машина неустойчивых состояний (LSM) – это тип нейронных сетей с пиками: сигмоидные активации заменены пороговыми функциями, и каждый нейрон также является накапливающей ячейкой памяти. Таким образом, при обновлении нейрона значение не присваивается сумме соседей, а добавляется к самому себе. Как только порог достигнут, он передает свою энергию другим нейронам. Это создает пиковый паттерн, когда какое-то время ничего не происходит, пока внезапно не будет достигнут порог [24] (рисунок 14).
Машины экстремального обучения (ELM) – это, по сути, FFNN, но со случайными соединениями. Они очень похожи на LSM и ESN, но не повторяются и не пикируют. Они также не используют обратное распространение. Вместо этого они начинают со случайных весов и обучают веса за один шаг в соответствии с методом наименьших квадратов (наименьшая ошибка для всех функций). Это приводит к гораздо менее выразительной сети, но также намного быстрее, чем обратное распространение [25].
ESN (Echostatenetworks) – это еще один другой тип (рекуррентной) сети. Этот отличается от других наличием случайных связей между нейронами (то есть не организованных в аккуратные наборы слоев), и эти сети обучаются по-другому.
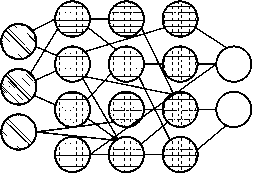
Рисунок 15. Нейронная сеть ESN [5]
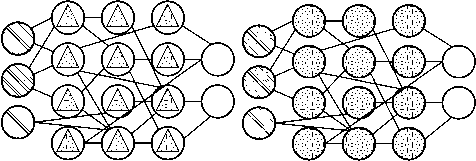
аб
Рисунок 14. Нейронная сеть LSM и ELM [5]
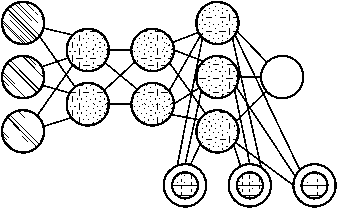
Рисунок 16. Нейронная сеть NTM [5]
Вместо подачи входных данных и обратного распространения ошибки мы передаем входные данные, пересылаем их и некоторое время обновляем нейроны, а затем наблюдаем за выходными данными с течением времени. Входной и выходной слои играют немного нетрадиционную роль, поскольку входной слой используется для запуска сети, а выходной слой действует как наблюдатель за моделями активации, которые разворачиваются с течением времени. Во время тренировки меняются только связи между наблюдателем и скрытыми слоями [26] (рисунок 15).
Нейронные машины Тьюринга
Нейронные машины Тьюринга (NTM) можно понимать как абстракцию LSTM и попытку разблокировать нейронные сети (и дать нам некоторое представление о том, что там происходит). Вместо того чтобы кодировать ячейку памяти непосредственно в нейрон, память разделяется. Это попытка объединить эффективность и постоянство обычного цифрового хранилища с эффективностью и выразительной силой нейронных сетей. Идея состоит в том, чтобы иметь банк памяти с адресацией по содержимому и нейронную сеть, которая может читать и записывать из него. «Тьюринг» в нейронных машинах Тьюринга происходит от того, что они являются полными по Тьюрингу: способность читать и записывать и изменять состояние на основе того, что сеть читает, означает, что она может представлять все, что может представлять универсальная машина Тьюринга [27] (рисунок 16).
Дифференциальный нейронный компьютер (DNC) – это усовершенствованные нейронные машины Тьюринга с масштабируемой памятью,
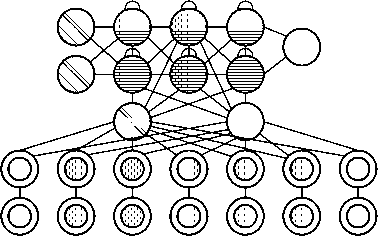
Рисунок 17. Нейронная сеть DNC [5]
вдохновленные тем, как воспоминания хранятся в человеческом гиппокампе. Идея состоит в том, чтобы взять классическую компьютерную архитектуру фон Неймана и заменить центральный процессор RNN, который узнает, когда и что считывать из оперативной памяти. Помимо наличия большого банка чисел в качестве памяти (размер которого можно изменить без переобучения RNN), DNC также имеет три механизма внимания. Эти механизмы позволяют RNN запрашивать сходство бита ввода с записями в памяти, временную связь между любыми двумя записями в памяти, была ли запись в памяти недавно обновлена, что снижает вероятность ее перезаписи при отсутствии пустых записей [28] (рисунок 17).
Нейронные сетис множественными связями
Капсульные сети (CapsNet) – это основанные на биологии альтернативы объединению, где нейроны связаны с несколькими весами (вектором), а не только с одним весом (скаляром). Это позволяет нейронам передавать больше информации, чем просто то, какая функция была обнаружена, например, где функция находится на изображении или какой у нее цвет и ориентация. Процесс обучения включает в себя локальную форму обучения Хебба, которая оценивает правильные прогнозы вывода на следующем уровне [29] (рисунок 18).
Сети Кохонена (KN, также самоорганизующаяся (характеристическая) карта, SOM, SOFM) используют конкурентное обучение для
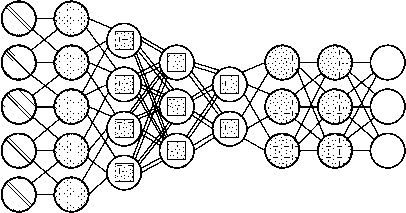
Рисунок 18. Нейронная сеть CapsNet [5]
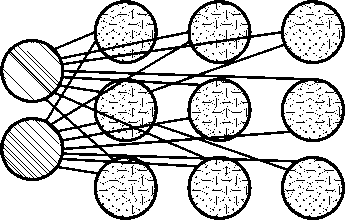
Рисунок 19. Нейронная сеть KN [5]
классификации данных без учителя. Входные данные предоставляются сети, после чего сеть оценивает, какие из ее нейронов наиболее точно соответствуют этим входным данным. Затем эти нейроны настраиваются, чтобы еще лучше соответствовать входным данным, увлекая за собой соседние нейроны в процессе. Насколько переместятся соседние нейроны, зависит от расстояния нейронов до лучших совпадающих нейронов [30] (рисунок 19).
Другие нейронные сети
AN (attentionnetworks) можно рассматривать как класс сетей, включающий в себя архитектуру преобразований. Они используют механизм внимания для борьбы с увяданием информации, отдельно сохраняя предыдущие состояния сети и переключая внимание между состояниями. Скрытые состояния каждой итерации в слоях кодирования хранятся в ячейках памяти. Слои декодирования связаны со слоями кодирования, но также получают данные из ячеек памяти, отфильтрованных по контексту внимания. Этот шаг фильтрации добавляет контекст для слоев декодирования, подчеркивая важность определенных функций. Сеть внимания, создающая этот контекст, обучается с использованием сигнала ошибки с выхода уровня декодирования. Более того, контекст внимания может быть визуализирован, что дает ценную информацию о том, какие входные функции соответствуют каким выходным функциям [31] (рисунок 20).
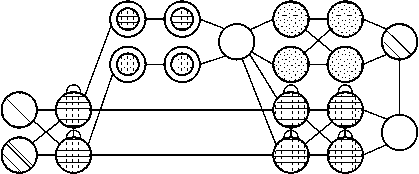
Рисунок 20. Нейронная сеть AN [5]
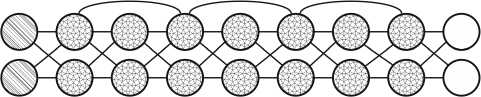
Рисунок 21. Нейронная сеть DRN [5]
Глубокие остаточные сети (DRN) – это очень глубокие FFNN с дополнительными соединениями, передающими входные данные с одного уровня на более поздний уровень (часто от 2 до 5 уровней), а также на следующий уровень. Вместо того чтобы пытаться найти решение для сопоставления некоторых входных данных с некоторыми выходными данными, скажем, на 5 слоях, сеть вынуждена научиться сопоставлять некоторые входные данные с некоторыми выходными данными + некоторые входные данные. По сути, она добавляет идентичность решению, перенося старые входные данные и подавая их свежими на более поздний уровень. Было показано, что эти сети очень эффективны при изучении паттернов глубиной до 150 слоев, что намного больше, чем обычные от 2 до 5 слоев, которые можно было бы обучить. Однако было доказано, что эти сети, по сути, являются просто RNN без явного построения на основе времени, и их часто сравнивают с LSTM без шлюзов [32] (рисунок 21).
Выводы
-
1. К настоящему времени создано большое количество архитектур нейронных сетей, что обуславливается применением данных архитектур в различных задачах.
-
2. Их применение дает возможность решать ряд сложных задач, таких как классификация изображений, не только по изображению (сверточные сети), но и по видеопотоку.
-
3. Использование нейронных сетей позволят восстанавливать часть утерянных данных
Список литературы Архитектуры нейронных сетей
- Нейронные сети. URL: https://neuralnet.info/book/ (дата обращения: 01.01.2022)
- Машинное обучение. GoogleTrends. URL: https://trends.google.ru/trends/explore?date=2004-01-01%202017-08-19&q=%2Fm%2F01hyh_ (дата обращения: 02.01.2022).
- Microsoft teams up with OpenAI to exclusively license GPT-3 language model. URL: https://blogs.microsoft.com/blog/2020/09/22/microsoft-teams-up-with-openai-to-exclusively-license-gpt-3-language-model/ (дата обращения: 10.01.2022).
- Rosenblatt F. The perceptron: A probabilistic model for information storage and organization in the brain // Psychological Review. 1958. Vol. 65, no. 5. P. 386–408.
- The neural network zoo URL: https://www.asimovinstitute.org/neural-network-zoo/ (дата обращения: 02.01.2022).
- Шпаргалка по разновидностям нейронных сетей. Часть первая. Элементарные конфигурации. URL: https://tproger.ru/translations/neural-network-zoo-1/ (дата обращения: 02.01.2022).
- Broomhead D.S., Lowe D. Radial Basis Functions, Multi-Variable Functional Interpolation and Adaptive Networks. London: Royal Signals and Radar Establishment Malvern, 1988. 35 p.
- Hopfield J.J. Neural networks and physical systems with emergent collective computational abilities // PNAS. 1982. Vol. 79. P. 2554–2558.
- Hinton G.E., Sejnowski T.J. Learning and relearning in Boltzmann machines // Parallel Distributed Processing: Explorations in the Microstructure of Cognition. 1986. P. 282–317.
- Smolensky P. Information Processing in Dynamical Systems: Foundations of Harmony Theory. Colorado: Univ at boulder dept of computer science, 1986. P. 194–281.
- Bourlard H., Kamp Y. Auto-association by multilayer perceptrons and singular value decomposition // Biological Cybernetics. 1988. No. 59. P. 291–294.
- Efficient Learning of Sparse Representations with an Energy-Based Model / M.A. Ranzato [et al.] // Proceedings of NIPS. 2007. P. 1–8. URL: https://proceedings.neurips.cc/paper/2006/file/87f4d79e36d68c3031ccf6c55e9bbd39-Paper.pdf (дата обращения: 01.01.2022).
- Kingma D.P., Welling M. Auto-encoding variational Bayes // arXiv. 2014. P. 1–14. URL: https://arxiv.org/pdf/1312.6114v10.pdf (дата обращения: 01.01.2022).
- Extracting and Composing Robust Features with Denoising Autoencoders / V. Pascal [et al.] // Proceedings of the 25th International Conference on Machine Learning. ACM. 2008. P. 1–8. URL: http://machinelearning.org/archive/icml2008/papers/592.pdf (дата обращения: 01.01.2022).
- Elman J.L. Finding structure in time // Cognitive Science. 1990. No. 14. P. 179–211.
- Hochreiter S., Schmidhuber J. Long short-term memory // Neural Computation. 1997. No. 9 (8). P. 1375–1780.
- Empirical evaluation of gated recurrent neural networks on sequence modeling / C. Chung [et al.] // arXiv. 2014. P. 1–9. URL: https://arxiv.org/pdf/1412.3555v1.pdf (дата обращения: 01.01.2022).
- Schuster M., Kuldip K.P. Bidirectional recurrent neural networks // IEEE Transactions on Signal Processing. 1997. No. 45. P. 2673–2681.
- Greedy layer-wise training of deep networks / Y. Bengio [et al.] // Advances in Neural Information Processing Systems. 2007. No. 19. P. 153–161.
- Gradient-based learning applied to document recognition / Y. LeCun [et al.] // Proceedings of the IEEE. 1998. No. 86. P. 2278–2324.
- Deconvolutional networks. Computer Vision and Pattern Recognition (CVPR) / M.D. Zeiler [et al.] // Proceedings of the IEEE. 2010. P. 1–8. URL: https://www.matthewzeiler.com/mattzeiler/deconvolutionalnetworks.pdf (дата обращения: 01.01.2022).
- Deep convolutional inverse graphics network / T.D. Kulkarni [et al.] // Advances in Neural Information Processing Systems. 2015. P. 1–10. URL: https://arxiv.org/pdf/1503.03167v4.pdf (дата обращения: 01.01.2022).
- Generative adversarial nets / I.J. Goodfellow [et al.] // Advances in Neural Information Processing Systems. 2014. P. 1–9. URL: https://arxiv.org/pdf/1406.2661v1.pdf (дата обращения: 01.01.2022).
- Maass W., Natschläger T., Markram H. Realtime computing without stable states: A new framework for neural computation based on perturbations // Neural Computation. 2002. No. 14. P. 2531–2560.
- Huang G., Zhu Q., Siew C. Extreme learning machine: Theory and applications // Neurocomputing. 2006. No. 70. P. 489–501.
- Jaeger, H., Harald H. Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication // Science. 2004. Vol. 304, no. 5667. P. 78–80.
- Graves A., Wayne G., Danihelka I. Neural turing machines // arXiv. 2014. P. 1–26. URL: https://arxiv.org/pdf/1410.5401v2.pdf (дата обращения: 01.01.2022).
- Hybrid computing using a neural network with dynamic external memory / A. Graves [et al.] // Nature. 2016. No. 538. P. 471–476.
- Sabour S., Frosst N., Hinton G.E. Dynamic routing between capsules // In Advances in Neural Information Processing Systems. 2017. P. 3856–3866.
- Kohonen T. Self-organized formation of topologically correct feature maps // Biological Cybernetics. 1982. No. 43 (1). P. 59–69.
- Spatial Transformer Networks / M. Jaderberg [et al.] // In Advances in Neural Information Processing Systems. 2015. P. 2017–2025.
- Deep Residual Learning for Image Recognition / K. He [et al.] // arXiv. 2015. P. 1–12. URL: https://arxiv.org/pdf/1512.03385v1.pdf (дата обращения: 01.01.2022).
