Автоматическая рубрикация текстов с использованием алгоритмов машинного обучения

Автор: Челышев Эдуард Артурович, Оцоков Шамиль Алиевич, Раскатова Марина Викторовна
Рубрика: Информатика и вычислительная техника
Статья в выпуске: 4, 2021 года.
Бесплатный доступ
Рассмотрено решение задачи автоматической рубрикации русскоязычных текстов с использованием алгоритмов машинного обучения на примере корпуса новостных статей как задачи классификации на некоторое число непересекающихся классов. Показан алгоритм подготовки текстовых данных для классификации и его практическая реализация на языке программирования Python. Проведен анализ существующих методов нормализации токенов. Представлены результаты проведенного исследования по построению ряда классификаторов для решения задачи классификации русскоязычных текстов. Обобщающая способность классификаторов оценена по ряду метрик.
Классификация, токенизация, нормализация, стоп-слово, метрика
Короткий адрес: https://sciup.org/148323530
IDR: 148323530 | УДК: 004.912 | DOI: 10.18137/RNU.V9187.21.04.P.175
Automatic text rubrication using machine learning algorithms
The article presents the solution of the problem of automatic rubrication of Russian-language texts using machine learning algorithms on the example of a corpus of news articles. This problem is considered as a classification problem for a certain number of disjoint classes. The algorithm of preparing text data for classification and its practical implementation in the Python programming language is presented. The analysis of existing methods of token normalization is carried out. The results of the research on the construction of a number of classifiers for solving the problem of classification of Russian-language texts are presented. The generalizing ability of classifiers is estimated by a number of metrics.
Текст научной статьи Автоматическая рубрикация текстов с использованием алгоритмов машинного обучения
Вводные замечания
Всеобъемлющее развитие информационных технологий и их внедрение в разнообразные сферы деятельности приводят к росту производимых человечеством и хранимых в различной форме данных. Так, например, прогнозируется, что к 2025 году общемировой объем данных составит более 175 зеттабайтов [13].
Столь стремительный рост накопленных данных приводит к тому, что человеку становится все сложнее ориентироваться в информационном поле, из-за чего возрастает потребность в использовании средств автоматизированной обработки информации, которая может осуществляться с применением алгоритмов машинного обучения.
В работе рассматривается задача автоматической рубрикации текстов на естественном языке с точки зрения машинного обучения по прецедентам, в терминологии которого она трактуется как задача классификации на несколько непересекающихся классов, при этом каждая отдельная рубрика рассматривается как отдельный класс [7]. В рамках данной задачи также представлен алгоритм подготовки текстовых данных.
Челышев Эдуард Артурович магистрант Московского энергетического института (национальный исследовательский университет), Москва. Сфера научных интересов: машинное обучение по прецедентам, искусственные нейронные сети, машинная обработка текстов на естественном языке, C++. Автор 1 опубликованной научной работы.
Алгоритм подготовки данных в задаче классификации текстов
Пусть имеется некоторый набор данных, каждый объект которого содержит текстовые данные на естественном языке и метку принадлежности к определенному классу. Рассмотрим текстовые данные отдельного объекта вышеуказанного набора данных. Для построения классификатораданные необходимо подготовить, преобразовав их в числовой вид. Такая подготовка включает в себя следующие этапы:
-
• удаление нерелевантных символов и приведение символов к общему регистру;
-
• токенизация;
-
• нормализация;
-
• удаление стоп-слов;
-
• векторизация.
Первый этап подготовки, а именно удаление нерелевантных символов и приведение символов к общему регистру , позволяет исключить из текста шумовую информацию. Нерелевантными символами могут являться цифры, знаки препинания, прочие небуквенные символы.
На этапе токенизации проводится разбиение текстовых данных на отдельные токены, то есть отдельные текстовые единицы [3]. В рассматриваемом алгоритме в качестве токенов выступают отдельные слова, а порядок следования токенов не играет роли, поэтому без ограничения общности можно считать, что на данном этапе формируется исходное множество T 0 , каждый элемент которого является отдельным токеном. Отметим также, что в контексте данной статьи понятия «слово» и «токен» в целом взаимозаменяемы.
Автоматическая рубрикация текстов с использованием алгоритмов машинного обучения
Нормализация токенов позволяет привести различные формы слова к одному токену. Это полезно, так как одному и тому же значению соответствуют сразу несколько форм одного слова, которые в дальнейшем при машинной обработке могут восприниматься как различные токены [4]. На этапе нормализации каждый токен множества T 0 преобразуется к своей начальной форме [8]. Измененное таким образом множество токенов обозначим T 1 . Более подробно задача нормализации токенов и подходы к ее решению изложены в статье далее.
Стоп-слова – это часто встречающиеся в текстах слова, которые играют большую роль в обеспечении связности предложения, однако при машинной обработке естественного языка являются шумом. К ним можно отнести частицы, предлоги, союзы и др. [4]. Обозначим множество стоп-слов S . Тогда множество токенов с удаленными из него стоп-словами обозначим T = T 1 \ S .
Векторизация – процесс, в результате которого каждому токену ставится в соответствие его векторное представление [2], то есть вектор v некоторого мерного векторного пространства К n , иными словами, задается отображение
f : T ^ V , (1)
где V = { v 1 ,v 2 ,..., v m } - множество векторов-образов размерности n .
В конечном итоге текстовым данным каждого объекта ставится в соответствие вектор, определяемый как среднее арифметическое векторов, соответствующих отдельным токенам, полученным из текстовых данных этого объекта, то есть
Z f ( t ) v = ^T- ----,
| T |
где | T | – мощность множества T .
Методы нормализации токенов
Для решения задачи нормализации токенов используются два метода –стемминг и лемматизация, каждый из которых имеет свои достоинства и недостатки [1].
Стемминг (англ. stemming) – метод нормализации токенов, в ходе которого от слов отсекаются префиксы, суффиксы и окончания, в результате чего выделяется основа слова [9]. Системы, осуществляющие стемминг, называются стеммерами. Наибольшее распространение получили алгоритмические стеммеры. Их недостатком является тот факт, что они могут совершать ошибки, из-за которых результат стемминга может оказаться отчасти некорректным [9].
Лемматизация – метод приведения слов к начальной форме, при котором проводится морфологический анализ слова, по результатам которого оно отождествляется с некоторой лексемой, которая называется леммой. Лемматизация гарантирует, что различные формы слова будут приведены к одной, начальной, лексеме. Однако лемматизация более требовательна к вычислительным ресурсам, нежели алгоритмический стемминг [8].
Практическая реализация алгоритма подготовки данных
Рассмотрим практическую реализацию приведенного выше алгоритма. Для подготовки текстовых данных был разработан программный модуль на языке программирования Python с использованием ряда его библиотек.
Удаление нерелевантных символов было проведено с использованием регулярных выражений. Токенизация текстов осуществлялась с использованием встроенного метода word_tokenize стандартной библиотеки NLTK [12].
В рамках данной работы для решения задачи нормализации токенов была выбран метод лемматизации, которая осуществлялась с использованием русскоязычного морфологического анализатора, реализованного в библиотеке pymorphy2 [5; 10].
Для решения задачи удаления стоп-слов в программном модуле реализована функция delete_stop_words. Получая на вход список токенов, она возвращает список, очищенный от стоп-слов, поочередно сравнивая каждый поступивший на вход токен с токенами в списке стоп-слов. Такой список для русского языка, состоящий из 151 слова, имеет в своем составе библиотека NLTK.
Для получения векторного представления слов используются различные методы векторизации, которые могут как сохранять семантические, то есть смысловые, отношения слов, так и игнорировать их. В данной работе была использована предобученная модель векторизации FastText , сохраняющая семантические отношения, доступная для свободного использования на интернет-ресурсе [14].
Пример текстовых данных корпуса, прошедших все этапы подготовки (кроме векторизации), представлен на Рисунке 1.
text topic
О [январь, год, всё, телеканал, оплачивать, услу...8
-
1 [германский, автопромышленный, концерн, vollksw...8
-
2 [нераспределённый, прибыль, оао, Тюменнефтегаз... 8
-
3 [крупный, телекоммуникационный, компания, сша,...8
-
4 [оао, газ, нижегородский, банк, Сбербанк, росс...8
Рисунок 1. Фрагмент подготовленных с использованием программного модуля данных
Проведение экспериментов по построению классификаторов
Были построены четыре классификатора: на основе наивного байесовского классификатора (далее – НБК), логистической регрессии (далее – ЛР), случайного леса решающих деревьев (далее – СЛРД) и искусственной нейронной сети (далее – ИНС), архитектура которой подробно рассмотрена в [6]. Классификаторы были обучены с использованием описанного выше подготовленного корпуса статей, который предварительно был разделен на обучающую и тестовую выборки.
Гиперпараметры классификаторов, дающие наилучшую обобщающую способность, определялись с использованием алгоритма решетчатого поиска. Оценка обобщающей
Автоматическая рубрикация текстов с использованием алгоритмов машинного обучения способности классификаторов производилась с использованием метрик precision ность) и recall (полнота), определяемых формулами (3) и (4) соответственно.
(точ-
precision =
recall =
G ; ;
G++G -
G ;
g; + g- '
где G p - число верно классифицированных объектов; G p - число объектов, которые были неверно отнесены к текущему классу; G - - число объектов, которые неверно были отнесены к другим классам.
Также была использована F 1 -мера, определяемая формулой
2 ■ precision ■ recall
.
1 precision + recall
В Таблице приведены средние взвешенные по классам значения метрик классификации для каждого классификатора.
На Рисунке 2 представлена гистрограмма значений среднего взвешенного по классам значения F1 -меры.
Таблица
Сводная таблица значений метрик классификации на тестовой выборке для построенных классификаторов
|
Классификатор |
Среднее взвешенное по классам значение точности |
Среднее взвешенное по классам значение полноты |
Среднее взвешенное по классам значение F 1 -меры |
|
НБК |
0,81459 |
0,79775 |
0,75367 |
|
ЛР |
0,90216 |
0,90236 |
0,90222 |
|
СЛРД |
0,88318 |
0,88310 |
0,88221 |
|
ИНС |
0,9253 |
0,9250 |
0,9251 |
Заключение
Представлен, реализован и опробован алгоритм подготовки текстовых данных для задачи классификации. На подготовленных с его помощью данных был обучен ряд моделей машинного обучения, которые показали достаточно высокие значения обобщающей способности; можно сделать вывод о правильности предложенного алгоритма.
Рассматривая результаты проведенных экспериментов по построению классификаторов, можно заключить, что ИНС показала наивысшие значения метрик классификации. Классификаторы на основе логистической регрессии и случайного леса решающих деревьев показали результаты чуть хуже. Наименьшее значение продемонстрировал наивный байесовский классификатор.
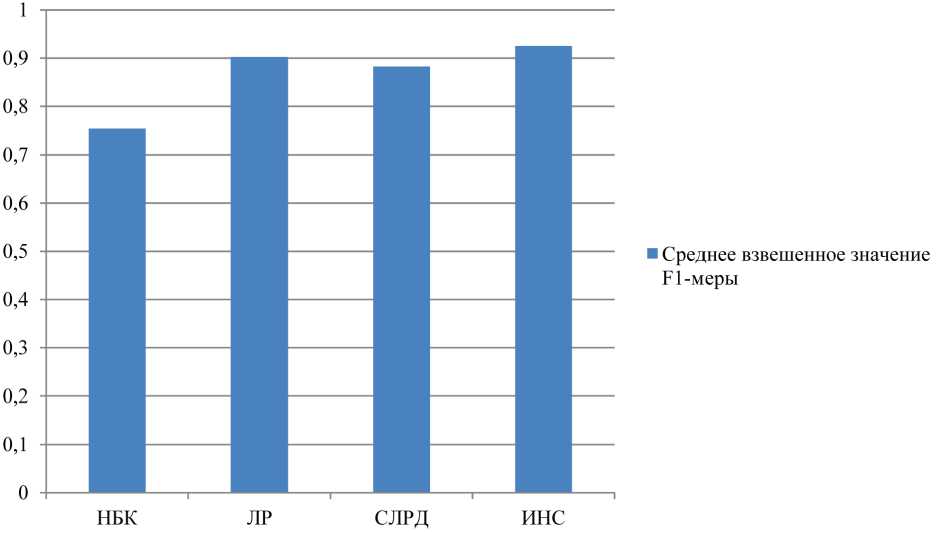
Рисунок 2. Сравнительная диаграмма значений F 1 -меры для построенных моделей классификации
Список литературы Автоматическая рубрикация текстов с использованием алгоритмов машинного обучения
- Вершинин Е.В., Тимченко Д.К. Исследование применения стемминга и лемматизации при разработке систем адаптивного перевода текста // Наука. Исследования. Практика: сборник избранных статей по материалам Международной научной конференции (Санкт-Петербург, 25 декабря 2019 г.). Санкт-Петербург: Гуманитарный национальный исследовательский институт «Нацразвитие», 2020. 310 с. ISB N 978-5-6043877-4-0.
- Жеребцова, Ю.А., Чижик А.В. Сравнение моделей векторного представления текстов в задаче создания чат-бота. // Вестник НГУ. 2020. Т. 18.
- Захаров В.П., Богданова С.Ю. Корпусная лингвистика: учебник. Иркутск: ИГЛУ. 2011.
- Мартынов В. А., Плотникова Н.П. Нормализация и фильтрация текста для задачи кластеризации // XLVIII Огарёвские чтения: материалы научной конференции. В 3 ч. (Саранск, 06–13 декабря 2019 г.). Саранск: Национальный исследовательский Мордовский государственный университет имени Н.П. Огарёва, 2020. С. 448–452.
- Морфологический анализатор pymorphy 2 [Электронный ресурс]. URL: https://pymorphy2.readthedocs.io/en/stable/ (дата обращения: 03.05.2021).
- Челышев Э.А., Оцоков Ш.А., Раскатова М.В. Разработка информационной системы для автоматической рубрикации новостных текстов // Международный журнал информационных технологий и энергоэффективности. 2021. Т. 6, № 3 (21). С. 11–17.
- Шаграев А.Г. Модификация, разработка и реализация методов классификации новостных текстов: дис. … канд. техн. наук. М.: МЭИ, 2014. 108 с.
- Якиль К.А., Рязанова Н.Ю. Фильтрация SMS-спама // Автоматизация. Современные технологии. 2016. № 9. С. 19–24.
- Яцко В.А. Алгоритмы и программы автоматической обработки текста // Вестник Иркутского государственного лингвистического университета. 2012. № 1 (17). С. 150–161.
- Korobov M. (2015) Morphological Analyzer and Generator for Russian and Ukrainian Languages. Analysis of Images, Social Networks and Texts, pp. 320–332.
- Kaggle: Your Home for Data Science. Available at: https://www.kaggle.com/yutkin/corpus-of-russian-news-articles-from-lenta (date of the application: 08.02.2021).
- NLTK 3.6.2 documentation. Available at: https://www.nltk.org/ (date of the application: 14.04.2021).
- Reinsel D., Gantz J., Rydning J. (2018) The Digitalization of the World, 28 p. Available at: https://www.seagate.com/files/www-content/our-story/trends/files/idc-seagate-dataagewhitepaper.pdf (date of the application: 11.03.2021).
- Rus Vectores: semantic models for the Russian language. Available at: https://rusvectores.org/ru/ (date of the application: 14.02.2021).
