Автоматизация тестирования веб-приложения, используя классификатор типов элементов машинного обучения

Автор: Тулфоров Д.М.
Журнал: Международный журнал гуманитарных и естественных наук @intjournal
Рубрика: Технические науки
Статья в выпуске: 6-2 (45), 2020 года.
Бесплатный доступ
Процессы тестирования программного обеспечения пытаются проверить способность программной системы соответствовать ее требуемым атрибутам и функциональности. По мере усложнения программных систем возникает необходимость в автоматизированных методах тестирования программного обеспечения. Методы машинного обучения показали себя весьма полезными для этого процесса автоматизации. В этой статье представлен классификатор, который может находить элементы Selenium, используя семантическую метку (например, «корзина», «микрофон» или «стрелка») вместо того, чтобы копаться в иерархии приложения.
Тестирование программного обеспечения, машинное обучение, машинное обучение в тестирование, классификатор
Короткий адрес: https://sciup.org/170190824
IDR: 170190824 | DOI: 10.24411/2500-1000-2020-10699
Automate web-application testing using machine learning element type classifier
Software testing processes (software) try to test the ability of a software system to match its required attributes and functionality. As software systems become more sophisticated, there is a need for automated software testing methods. Machine learning (MO) methods have proven very useful for this automation process. This article presents a classifier that can find Selenium elements using a semantic label (for example, “ basket”, “ microphone” or “ arrow”) instead of delving into the application hierarchy.
Текст научной статьи Автоматизация тестирования веб-приложения, используя классификатор типов элементов машинного обучения
Тестирование программного обеспечения - это процесс исследования, который пытается проверить и валидировать соответствие атрибутов и функциональности программной системы ее намеченным целям. Тестирование ПО является трудоемким и дорогостоящим процессом, и, как указано в [2], процесс тестирования может потребовать до 50% ресурсов разработки. В связи с этим желательно использовать автоматизированные подходы к тестированию, чтобы сократить эти затраты и время. Кроме того, автоматизация может значительно повысить производительность процесса тестирования. Следовательно, для будущей разработки программных систем необходимо предпринять шаги для разработки стратегий автоматизированного тестирования [3].
Уже сделано несколько интересных попыток для автоматизации процесса тестирования программного обеспечения. Машинное обучение как поддомен ИИ [11] широко используется на различных этапах жизненного цикла разработки программного обеспечения [15], особенно для автоматизации процессов тестирования программного обеспечения [4]. В [1], эволюционные алгоритмы использовались для автоматизации генерации тестовых случаев. Бриан и др. в [7] предложен метод, основанный на алгоритме дерева решений
C4.5, для прогнозирования потенциальных ошибок в программной системе и локализации ошибок с целью сокращения времени процесса отладки. Все исследования показывают, что применение методов машинного обучения является перспективным подходом для автоматизации процессов тестирования.
Исследование работы классификатора
Обычно в тестах Appium или Selenium вызывается API, чтобы найти элемент пользовательского интерфейса, с которым вы хотите взаимодействовать (например, кнопка, чтобы вы могли щелкнуть ее). Обычно вы идентифицируете элемент, указывая селектор CSS или XPath. Судя по количеству выступлений на эту тему на конференциях Selenium [6] в течение многих лет, это трудно поддерживать, предположительно потому, что структура DOM [8] тестируемого приложения часто изменяется из-за изменений в коде. Традиционный XPath-селектор:
Плагин [5] о котором идёт реч в данной статье позволяет найти элемент, выполнив поиск значка, такого как корзина, кнопка редактирования или логотип Twitter. Это делается путем создания снимков экрана каждого элемента пользовательского интерфейса и запуска снимков экрана через нейронную сеть («модель»), которая знает, как распознать 105 [10] определенных категорий или меток. Он не подходит для поиска текстового поля, раскрывающегося списка, кнопки с текстом или любого другого элемента пользовательского интерфейса, который не является значком.
На предыдущих конференциях Selenium обсуждались вопросы машинного обучения, применяемые к селекторам элемен- тов. В частности, Орен Рубин на выступление в 2016 году [9], продемонстрировал свой продукт Testim.io, который является проприетарным инструментом запи-си/воспроизведения, который фиксирует все свойства элемента и использует стати-стику/машинное обучение для продолжения распознавания элемента, даже если некоторые из этих свойств изменяются. Но этот плагин, исключительно смотрит на скриншоты.

Рис. 1. Новый селектор и пример значка корзины
Как это работает?
Точкой входа плагина является функция, которая называется find. В плагине функция поиска принимает в качестве аргумента нужную метку (например, «корзина» для корзины покупок).
– получает все конечные DOM-элементы из тестируемого приложения, включая координаты и размер каждого элемента;
– получает скриншот приложения;
– обрежьте скриншот на множество маленьких скриншотов, по одному для каждого элемента из шага 1;
– запускает обрезанный скриншот каждого элемента через нейронную сеть. (это было современное состояние в алгоритмах машинного обучения еще в 2015 году [12]):
-
а) сначала изменят размер каждого изображения до 224x224 пикселей, потому что это входной размер, который ожидает модель [13] (нейронная сеть).
-
б) модель [13] возвращает список из 105 [10] «предсказаний»: вероятность того, что это изображение соответствует каждой из 105 меток [10], о которых знает модель [13].
-
в) для каждого изображения, если верхний прогноз соответствует запрашиваемой вами метке, а достоверность превышает 20%, считает, что это совпадение;
-
г) сортирует соответствующие элементы по доверительному баллу и вернёт самый высокий.
Модель MobileNet v1,2[13], которая является предварительно обученной моделью, выпущенной Google AI. MobileNet [13] – это «глубокая», «сверточная» нейронная сеть [14], представляет собой нейронную сеть, которая принимает в качестве входного сигнала 3-канальное цветное изображение размером 224x224 пикселя и выводит 105 [10] чисел, которые представляют достоверность или вероятность того, что входное изображение соответствует каждой из 105 [10] меток, о которых знает модель.
Сверточная нейронная сеть (ConvNet) [14] делает много сверток, используя разные фильтры. Каждый фильтр обнаруживает особый тип объекта: например, вертикальные края, горизонтальные края, диагональные края, яркость, краснота. В отличие от нашего примера фильтра выше, коэффициенты каждого фильтра не определены человеком; они изучаются (или обнаруживаются) машиной в процессе обучения.
Глубокая сеть имеет много слоев этих свёрток. Каждый слой действует на вывод предыдущего слоя, а не на исходные пиксели изображения. Таким образом, сеть узнает более абстрактные фич, такие как
«пушистость». На практике эти функции очень абстрактны и их трудно интерпретировать, поэтому они не вписываются в легко описываемые понятия, такие как «пушистость».
MobileNet v1[13] имеет 14 таких слоев. Первый слой извлекает 32 различных низкоуровневых объекта для каждого пикселя во входном изображении. К тому времени, когда он достигает последнего слоя, он выделяет 1024 высокоуровневых объекта, которые описывают изображение в целом.
После 14 сверточных слоев имеется окончательный классификационный слой. Это не использует свертки; вместо этого он использует линейную регрессию [16], чтобы решить, основываясь на 1024 высокоуровневых функциях, является ли это кошкой или нет. На самом деле он изучает 1000 различных регрессий, по одному для каждой категории, в которой обучалась модель [13].
MobileNet [13] (Google) прошел обучение по миллионам фотографий из набора данных ImageNet [17]: люди, животные, улицы, пейзажи, объекты. Он был обучен распознавать 1000 различных категорий, таких как «кормушка для птиц», «кошка», «музыкальный инструмент», «спорт на открытом воздухе», «человек», «ядовитое растение».
Плагин, взял этот модель MobileNet [13], удалил окончательный классификационный слой и обучил новый классификационный слой на примерах соответствующих значков, оставив при этом другие слои модели без изменений. Cкрипт плагина буквально является сценарием из этого урока TensorFlow [18]. Большая часть работы была бы направлена на создание обучающих данных, если бы в Интернете было найдено 75 000 примеров значков в 105 категориях [10].
Идея этого подхода заключается в том, что MobileNet [13] уже научился извлекать общие функции, которые полезны для понимания изображений в целом; взглянуть на эти функции достаточно информации, чтобы решить, является ли значок корзины покупок или нет. Это называется трансферным обучением: знания, полученные при решении одной проблемы, полезны для решения другой проблемы.
Переподготовка модели таким способом намного дешевле, чем обучение всей модели с нуля, как по времени (минуты вместо недель), так и по количеству требуемых тренировочных образов (тысячи вместо миллионов).
Измерение точности классификатора
Лучшая практика в машинном обучении – тестирование модели с использованием набора данных, отличного от того, который вы использовали для обучения модели. Эти нейронные сети имеют так много пара-метров, что иногда они могут соответствовать обучающим данным и не могут обобщаться для новых входных данных.
Однако у меня нет тестового набора данных, поэтому я проверил модель на собственных данных обучения. Это должно дать нам наилучшую точность; в реальных условиях точность, вероятно, будет ниже. Простейшая мера точности: соответствует ли предсказанная метка правильной?
Таблица 1. Точность классификатора
|
Метод измерения |
Точность |
|
Топ-1 > 20% уверенность |
68 % |
|
Top-1 точность |
70 % |
|
Top-5 точность |
87 % |
«Топ-1» означает: соответствует ли верхний (наиболее вероятный) прогноз модели фактическому ярлыку? (Независимо от уверенности модели в этом прогнозе.)
«Топ-5» означает: соответствует ли ожидаемый ярлык какому-либо из 5 лучших прогнозов модели? Он повышает общую точность за счет уменьшения количества ложных негативов, но значительно увеличивает количество ложных срабаты- ваний (количество ложных срабатываний для «корзины» увеличилось с 6% до 63% всех ответов «корзины»).
Топ-1 и Топ-5 являются типичными показателями, используемыми в литературе по машинному обучению. Плагин соответствует прогнозу топ-1, но только если он превышает доверительный порог, который по умолчанию равен 0,2 (20%). Он не смотрит на топ-5 прогнозов, если топ-1 не тот ярлык, который вы просили.
Исследователи машинного обучения используют более сложные меры точности, такие как «Precision (точность)» и «Recall (полнота)» [19]. На выступлении Test.ai на конференции Selenium 2018 [20] в Чикаго они сказали: «Если есть корзина для покупок, мы найдем ее с точностью 98,9%». В терминологии машинного обучения это 98,9%.
Я протестировал 200 тренировочных образов для ярлыка «тележка» и обнаружил только 81% полноты.
Таблица 2. Точность классификатор в измерениях recall и precision (ложноположительные - лн, ложноотрицательный - ло)
|
Метод измерения |
Recall (ло) |
Precision(лп) |
|
Топ-1 > 20% уверенность |
81 % (40) |
94 %(11) |
|
Top-1 точность |
81 % (39) |
94 % (11) |
|
Top-5 точность |
91 %(19) |
37 % (323) |
Вот некоторые из изображений, которые были неправильно классифицированы:

Рис. 2. Ложноотрицательные результаты классификатора
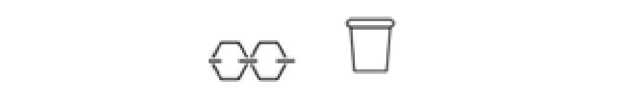
Рис. 3. Ложноположительные результаты классификатора
Последние два изображения, приведенные выше, являются ложноположительными: они взяты из обучающих данных «ссылка» и «мусор», но модель считает, что они оба «тележка» (с уверенностью 24% и 43%, соответственно).
Будущая работа
Тестирование является критически важной задачей в процессе разработки программного обеспечения и значительно накладывает ограничения на стоимость и время процесса разработки. Следовательно, автоматизация процесса тестирования может значительно повысить производительность процесса тестирования. В контексте тестирования программного обеспечения различные типы данных могут быть собраны на разных этапах тестирова- ния. Методы машинного обучения могут использоваться для поиска шаблонов в этих данных и их использования в целях автоматизации. В этой статье мы разбирали практическую применение машинного обучение, а именно работы классификатора, измеряли его точность. Исходя из результата исследований можно выводить что плагин работает не на столько хорошо как хотелось бы, и будущая работа заключается в улучшение работы плагин, а именно преобразовать снимки экрана в оттенки серого, прежде чем запускать их через модель (поскольку модель была обучена на изображениях в оттенках серого), улучшите производительность (скорость), передав все изображения в тензор потока одновременно.
Список литературы Автоматизация тестирования веб-приложения, используя классификатор типов элементов машинного обучения
- Roper M. Using Machine Learning to Classify Test Outcomes, 2019 IEEE International Conference on Artificial Intelligence Testing (AITest), 2019.
- Hourani H., Hammad A., Lafi M. The Impact of Artificial Intelligence on Software Testing, 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT), 2019.
- King T.M., Arbon J., Santiago D., Chin W., Adamo D., Shanmugam R. AI for Testing Today and Tomorrow: Industry Perspectives, 2019 IEEE International Conference on Artificial Intelligence Testing (AITest), 2019.
- Arbon J. AI for Software Testing, in Pacific NW Software Quality Conference. PNSQC, 2017.
- Test.ai Classifier and Appium Plugin. - [Электронный ресурс]. - Режим доступа: https://github.com/testdotai/appium-classifier-plugin (дата: 2.04.2020).
