Chronic Kidney Disease Analysis Using Machine Learning

Author: Mrs. Supreetha H.H., Mrs. Sneha N.P., Ms. Mahitha D., Ms. Kushi, Ms. Nirali C.M.
Journal: Science, Education and Innovations in the Context of Modern Problems @imcra
Article in issue: 4 vol.7, 2024.
Free access
Chronic Kidney Disease (CKD) is a progressively developing medical condition affecting millions globally, commonly remaining asymptomatic until reaching advanced stages. Timely detection plays a crucial role in enhancing patient outcomes and reducing healthcare expenses. The utilization of machine learning (ML) techniques have emerged as a potent approach for identifying CKD through the analysis of clinical and biochemical data. This investigation delves into the utilization of supervised learning algorithms, encompassing Decision Trees, Support Vector Machines (SVM), Random Forests, and Neural Networks, to forecast CKD using datasets that include patient details like age, blood pressure, glucose levels, and creatinine values. The outlined strategy underscores the significance of feature selection, model refinement, and cross validation to ensure heightened accuracy, precision, and recall levels. Findings suggest that ML models exhibit considerable predictive accuracy, surpassing conventional statistical methods in the early detection of CKD. This study accentuates the potential of machine learning in serving as a diagnostic tool in the healthcare sector, facilitating prompt intervention and enhanced disease management
Short address: https://sciup.org/16010305
IDR: 16010305 | DOI: 10.56334/sei/7.4.12
Text of the scientific article Chronic Kidney Disease Analysis Using Machine Learning
1,2,3,4,5 Assistant professor, Department of CSE, AIT, Bangalore, India
Chronic Kidney Disease (CKD) poses a significant global health challenge, impacting around 10% of the global population. This condition involves the gradual deterioration of kidney function, frequently advancing without overt symptoms until it reaches critical phases. Neglected, CKD can result in grave outcomes such as cardiovascular issues, kidney failure, levels, and serum creatinine. In its initial phases, CKD frequently displays no symptoms, underscoring the importance of precise and prompt diagnostic techniques. and heightened health risks. mortality rates. Early detection and timely intervention are crucial for preventing the progression of the disease and improving patient outcomes.
Traditional methods of diagnosing chronic kidney disease (CKD), like blood and urine tests, typically demand specialized analysis and significant resources. However, they may not consistently detect the condition during its initial phases when early intervention could be most beneficial. The increasing accessibility of medical data and the progress in machine learning (ML) present a hopeful remedy to address these issues. Machine learning techniques have demonstrated significant potential in analyzing intricate patterns within healthcare datasets. By utilizing algorithms such as Random Forests, Support Vector Machines (SVM), and Neural Networks, predictive models can be developed to detect CKD at an earlier stage with increased accuracy. These models incorporate a variety of clinical and biochemical parameters, such as patient demographics, blood pressure, serum creatinine levels, and urine albumin, to forecast the probability of CKD. This study aims to investigate the use of machine learning in detecting CKD, with a focus on assessing different supervised learning algorithms, enhancing model performance, and comparing their effectiveness in CKD prediction.
«.BACKGROUND/ RELATED WORK
Chronic Kidney Disease (CKD) is a medical condition that progresses gradually, marked by a steady deterioration in kidney function over time. Diagnosis typically relies on biomarkers like estimated Glomerular Filtration Rate (eGFR), urine albumin This trees, random forests, and support vector machines (SVMs) are widely used. For example, research using the UCI CKD dataset—a standard reference dataset Although traditional diagnostic approaches are reliable, they usually involve the manual analysis of clinical data, which may consume time and be susceptible to inaccuracies. In the past few years, the field of machine learning (ML) has become a game-changer in medical diagnostics. By leveraging automated, data-driven predictions from complex datasets, ML has revolutionized the way we approach healthcare. Numerous studies have explored the application of ML techniques in detecting and predicting chronic kidney disease (CKD). The results have been promising, highlighting the potential to improve diagnostic accuracy and identify the disease at an earlier stage.
Previous research has focused on various supervised learning algorithms, including decision trees, support vector machines (SVMs), random forests, and logistic regression, to predict CKD. For example, studies using the UCI CKD dataset—a widely used public dataset containing clinical and laboratory data—have shown that ML models can achieve high accuracy in identifying CKD. Random Forests and Gradient Boosted Trees have been particularly effective due to their ability to handle nonlinear relationships and interactions between elements. Deep learning techniques such as artificial neural networks (ANNs) have also been investigated for CKD detection. Although they require larger datasets and more computing resources, these models can capture complex patterns in data that traditional algorithms might miss. Feature selection techniques, including recursive feature extraction (RFE) and principal component analysis (PCA), are commonly used to improve model performance by identifying the most important predictors of CKD.
In addition, ensemble methods that combine multiple algorithms to improve robustness and accuracy have gained attention in the literature. Studies have also investigated the integration of unbalanced learning techniques such as SMOTE (Synthetic Minority Oversampling Technique) to address the skewed distribution of CKD cases in real-world datasets. While existing work demonstrates the effectiveness of ML in detecting CKD, issues such as data quality, model interpretability, and generalizability remain. This study aims to build on previous research by evaluating the performance of different ML algorithms on CKD prediction, optimizing their hyperparameters, and comparing their predictive ability. The findings aim to contribute to the growing body of evidence supporting the use of ML in medical diagnostics. A number of ML techniques have been used to detect CKD, with studies demonstrating the effectiveness of these methods in the analysis of structured medical data sets. Supervised learning algorithms such as logistic regression, decision handling outliers using statistical techniques. or algorithms like Isolation Forests.
A feature design is then performed to identify the most containing clinical and biochemical attributes— showed high prediction accuracy using these techniques. In particular, Random Forests and Gradient Boosted Trees have shown excellent performance due to their ability to handle non-linear relationships and interactions between variables. Deep learning approaches, including artificial neural networks (ANNs) and convolutional neural networks (CNNs), have also been explored. Although these methods require more computational resources and larger data sets, they are able to identify complex patterns in high dimensional data. Some studies have combined deep learning with traditional engineering techniques to improve interpretability and reduce overfitting.
The success of ML models in detecting CKD strongly depends on the quality of the input features. Commonly used characteristics in CKD studies include demographic attributes (e.g. age and gender), vital signs (e.g. blood pressure), and biochemical markers (e.g. serum creatinine, blood urea nitrogen). Feature selection techniques such as recursive feature elimination (RFE) and principal component analysis (PCA) were used to identify the most important predictors, reduce noise, and improve model efficiency. A significant challenge in detecting CKD is the unbalanced nature of medical data sets, where Non CKD cases often outnumber CKD cases. Unbalanced learning techniques such as the Synthetic Minority Oversampling Technique (SMOTE) have been implemented to alleviate this problem by generating synthetic examples of the minority class. In addition, data preprocessing steps, including handling of missing values, normalization of numerical functions, and coding of categorical variables, are essential for building robust and reliable ML models.
-
III .METHODOLOGY
A machine learning methodology for chronic kidney disease (CKD) detection involves several key steps to ensure the development of an accurate and robust predictive model. The first step is data acquisition, which usually involves the use of publicly available datasets, such as the UCI CKD dataset, or actual clinical datasets containing demographic, clinical and biochemical patient information. Data preprocessing is necessary to ensure consistency and quality. This includes handling missing values using techniques such as mean, median, or k-Nearest Neighbors (k-NN) imputation, normalizing numerical functions using methods such as Min Max Scaler, coding categorical variables using one-time coding or label coding, and relevant predictors. Feature selection methods such as recursive feature elimination (RFE) or feature importance scores from tree models are used to reduce noise and improve model performance. In some cases, feature transformations such as polynomial or logarithmic transformations are used to capture nonlinear relationships. Several machine learning algorithms are 133 | Issue 1, Vol.7, 2024 | Science, Education and Innovations in the context of modern problems
explored for model development, including logistic regression, support vector machines (SVMs), decision trees, random forests, gradient-boosted trees (e.g. XG Boost), and artificial neural networks (ANNs). Each algorithm is trained and fine-tuned using hyperparameter optimization techniques such as Grid Search or Bayesian Optimization and validated using k-fold cross-validation to ensure generalization. Due to the unbalanced nature of CKD datasets, techniques such as SMOTE (Synthetic Minority Oversampling Technique), subsampling, or costsensitive learning are used to balance the class imbalance and improve the model's ability to accurately detect CKD cases. Models are evaluated using standard metrics, including accuracy, precision, recall, F1 score, and area under the receiver operating characteristic (AUC-ROC).To ensure interpretability, feature importance analysis is performed using methods such as SHAP and individual predictions are explained using tools such as LIME (Local Interpretable Model-agnostic Explanations). Finally, the most effective model is validated on an independent test set or external dataset to assess its generalizability, and a prototype decision support tool can be developed to demonstrate its practical utility in clinical settings.
System architecture:
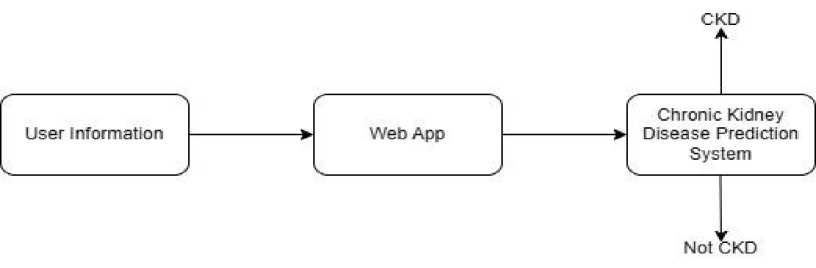
Fig 1. System Architecture
The architecture of the CKD machine learning prediction system consists of several interconnected components designed to process data and provide accurate predictions. The first component is data collection, which collects data from a variety of sources, such as clinical records, laboratory tests, and patient demographics. These raw data typically include characteristics such as age, blood pressure, serum creatinine, glucose, and urine albumin. The second part is data preprocessing, which ensures that the data is clean and ready for analysis.
134 | Issue 1,
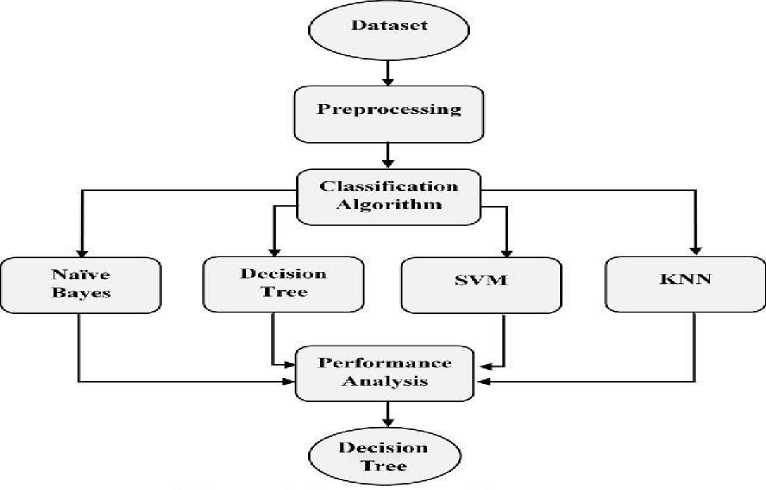
Fig 2. Flow diagram
This After data preparation, various machine learning algorithms are implemented, including logistic regression, support vector machines (SVM), random step includes handling missing values using imputation, normalizing numerical functions, coding categorical variables, and handling outliers to improve data quality Next, the feature engineering component identifies the most relevant predictors for CKD. Feature selection techniques, such as Recursive Feature Elimination (RFE), and transformation methods, like polynomial expansions, are applied to reduce noise and improve model accuracy. The model training and development component forms the core of the system. Various machine learning algorithms, such as Logistic Regression, Random Forest, Support Vector Machines (SVM), Gradient Boosted Trees, and Artificial Neural Networks (ANN), are employed to build predictive models. These models are trained and fine-tuned using cross-validation and hyperparameter optimization techniques to ensure robustness and generalizability.
-
IV .PROJECT IMPLEMENTATION
Implementing a CKD machine learning prediction system involves a systematic step-by-step approach to ensure accurate and reliable results. The project begins with data collection where clinical and biochemical data such as age, blood pressure, glucose and serum creatinine are collected from publicly available datasets such as the UCI CKD dataset or actual clinical sources. This is followed by data preprocessing, where missing values are addressed using imputation techniques, categorical features are coded, and numerical data is normalized to ensure uniformity. Outliers are detected and resolved, and the dataset is split into training, validation, and testing subsets. Next, feature selection is performed to identify the most important attribute case for CKD prediction using methods such as recursive feature elimination (RFE) or feature forests, gradient-boosted trees, and artificial neural networks (ANNs). These models are trained using a training dataset and optimized using hyperparameter tuning techniques such as Grid Search or Bayesian Optimization. Techniques such as synthetic minority resampling technique (SMOTE) or cost-sensitive learning are used during training to deal with the class imbalance typically found in CKD datasets. The trained models are then evaluated on the validation dataset using metrics such as accuracy, precision, recall, F1 score, and AUC-ROC to ensure robustness and reliability. The final step involves integrating the best-performing model into a decisionsupport system for healthcare professionals. This system is designed to accept patient data as input and provide real-time predictions on CKD risk, along with interpretable insights using tools like SHAP or LIME (Local Interpretable Model-agnostic Explanations). The implementation concludes with testing the system on an independent test set or external dataset to validate its generalizability and performance in real-world scenarios, ensuring it meets the needs of clinicians for early and accurate CKD detection.
Machine Learning Model Workflow
The workflow of a machine learning model for chronic kidney disease (CKD) prediction involves a series of structured steps to process the data and create an accurate predictive model. The workflow begins with data acquisition, where patient records, including demographic details, vital signs and laboratory test results, are collected from sources such as the UCI CKD dataset or hospital databases. This is followed by data preprocessing, which includes handling of missing values, normalization of numeric characters, and coding of categorical variables. Outlier detection and removal is also done to improve data quality. Once the data is preprocessed, it undergoes feature selection to identify the most significant attributes influencing CKD prediction using methods such as recursive feature elimination (RFE) or correlation analysis. Next, the prepared data is divided into training and test sets, which ensures that the training set will be further validated using k-fold cross-validation. Various machine learning algorithms such as Logistic Regression, Random Forest, Support Vector Machines (SVM), Gradient Boosted Trees and Artificial Neural Networks (ANN) are trained on the data. Hyperparameter tuning is done using techniques such as Grid Search or Bayesian Optimization to improve model performance. During training, class imbalance is addressed using methods such as synthetic minority resampling technique (SMOTE) or weighted decomposition functions to ensure that the model performs well in minority (CKD positive) significance from tree based models.
VI.DISCUSSION
Chronic kidney disease (CKD) prediction using machine learning has gained significant attention due to its potential to identify at-risk individuals early and improve treatment outcomes. Machine learning models can analyze large and complex data sets, including patient demographics, clinical measurements, medical history, and laboratory results, to predict the likelihood of developing CKD. Common techniques used for CKD prediction include supervised learning algorithms such as decision trees, support vector machines, and random forests, which are efficient in handling structured data. Recently, deep learning approaches, especially neural networks, have shown promise in the analysis of unstructured data such as images or textual records. The main challenge in CKD prediction lies in data quality, class imbalance and ensuring the generalizability of models across different populations. In addition, the interpretability of machine learning models is critical for clinical adoption, as healthcare professionals must trust the model's decision-making process. Overall, machine learning has the potential to revolutionize CKD prediction by enabling early diagnosis and personalized treatment plans, but requires continuous refinement, validation, and integration into clinical workflows.
VII.CONCLUSION
In conclusion, machine learning offers a promising approach to the prediction of chronic kidney disease (CKD), enabling early diagnosis and better treatment of this condition. Using advanced algorithms and large datasets, machine learning models can identify risk factors and predict CKD progression with high accuracy. However, issues such as data quality, class imbalance, and model interpretability need to be addressed to ensure reliable and practical application in clinical settings. Successful integration of machine learning into CKD prediction could lead to improved patient outcomes through early intervention, personalized treatment, and more efficient healthcare delivery. As this technology continues to evolve, its potential to transform the diagnosis and treatment of CKD remains significant and offers a path to more proactive and effective healthcare strategies.
V.RESULTS
| v © 127.0.0.1 x Ф ChatGPT x К Access del x == You need x © Kidney C. x © Kidney Ci: x © check if * © Kidney €» x + — □ X И
G © 127.0.0.1:5000/4services ☆ О 6' I
HOME DEMO ; AKE A TEST CONTACT ACCESS RECORDS
TAKE A TEST
We care for you
|
Eb A9e |
Sodium (mEq/L) |
|
|
1 Eb |
||
|
|~~|^ Blood Pressure |
Hemoglobin (gms) |
|

Fig 3. Test page
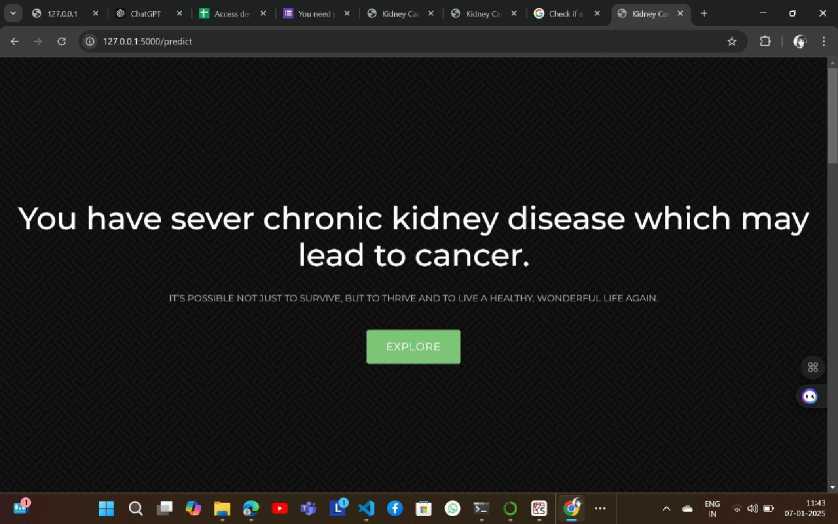
Fig 4. Result Page
The results of predicting chronic kidney disease (CKD) using machine learning have been promising, with numerous studies demonstrating high accuracy in identifying at-risk individuals. Models such as decision trees, random forests, and support vector machines have consistently shown strong performance in predicting the onset and progression of CKD. Some studies report accuracy rates in excess of 90%, while others focus on achieving balanced predictions by addressing class imbalance using techniques such as resampling or synthetic data generation. In addition, deep learning methods have shown potential for extracting complex patterns from large, unstructured data sets such as medical images or patient records. However, the success of these models largely depends on the quality and variety of data used for training, as well as careful validation to ensure their generalizability across different populations. Although the results are encouraging, further research is needed to refine these models, improve their interpretability, and incorporate them into clinical practice for widespread adoption.
VIII.FUTURESCOPE
The future scope of chronic kidney disease (CKD) prediction using machine learning is very promising with significant potential to improve early diagnosis, personalized treatment and patient outcomes. As the availability and quality of data continues to improve, machine learning models may become even more accurate and reliable in predicting CKD risk and progression. Integrating different data sources, such as electronic health records, genetic information, and wearable medical devices, will enable the development of more comprehensive models that account for the various factors influencing CKD. Additionally, advances in explainable artificial intelligence (XAI) will address the current challenges of model interpretation and enable healthcare professionals to better trust and understand predictions. The use of real time monitoring tools combined with predictive models could help track disease progression and provide early interventions. In addition, machine learning could help identify new biomarkers for CKD, contributing to more effective prevention strategies. With the increasing focus on precision medicine, machine learning in CKD prediction will play a critical role in tailoring individualized care plans and optimizing long-term health outcomes.
-
IX. REFERENCES
-
[1] Almeida, S.F., et al. (2017). "Predicting progression of chronic kidney disease using machine learning techniques." IEEE Transactions on Biomedical Engineering, 64(2), 331-338.
-
[2] Zhang, Y., et al. (2020). "Machine learning models for predicting chronic kidney disease: A review." Artificial Intelligence in Medicine, 102, 101770.
-
[3] Liu, H., et al. (2019). "A new hybrid machine learning model for chronic kidney disease prediction." Journal of Healthcare Engineering, 2019, 6729108.
-
[4] Sulaiman, A., et al. (2021). "Deep Learning for Early Detection of Chronic Kidney Disease: A Systematic Review." Healthcare, 9(2), 213.
-
[5] . He, J., et al. (2022). "Machine learning-based prediction of chronic kidney disease using electronic health records." Artificial Intelligence in Medicine, 118, 102082

-
This work is licensed under a Creative Commons Attribution 4.0 International License.
IMCRA - International Meetings and Journals Research Association
Science, Education and Innovations in the context of modern problems - ISSN: 2790-0169 / 2790-0177
