Comparative analysis of gradient descent methods and their modifications for optimizing complex functions

Author: Stulov I.S.
Journal: Международный журнал гуманитарных и естественных наук @intjournal
Section: Технические науки
Article in issue: 10-5 (97), 2024.
Free access
This article presents a comparative analysis of various gradient descent optimization methods, including classical gradient descent, momentum-based gradient descent, adaptive gradient descent (Adam), and a learning rate decay method. These methods were applied to two test functions, the Matyas function and Levi Function No. 13, to evaluate their performance in terms of accuracy, convergence speed, and computational efficiency. The study revealed that the Adam optimizer consistently outperformed the other methods, demonstrating the highest accuracy and fastest convergence, particularly on complex, non-linear landscapes. Momentum-based gradient descent improved convergence over the classical method but did not achieve the precision of Adam. The learning rate decay method stabilized the optimization process but fell short of Adam’s performance. These findings highlight the effectiveness of adaptive optimization algorithms in solving complex optimization problems, providing valuable insights for their application in machine learning, neural networks, and other areas requiring efficient optimization techniques.
Gradient descent, momentum-based optimization, adaptive gradient descent, learning rate decay, function optimization, matyas function, levi function № 13, optimization algorithms, convergence speed
Short address: https://sciup.org/170207084
IDR: 170207084 | DOI: 10.24412/2500-1000-2024-10-5-70-78
Сравнительный анализ методов градиентного спуска и их модификаций для оптимизации сложных функций
В данной статье представлен сравнительный анализ различных методов оптимизации градиентного спуска, включая классический градиентный спуск, градиентный спуск на основе импульса, адаптивный градиентный спуск (Adam) и метод спада скорости обучения. Эти методы были применены к двум тестовым функциям, функции Матьяша и функции Леви № 13, для оценки их производительности с точки зрения точности, скорости сходимости и вычислительной эффективности. Исследование показало, что оптимизатор Adam последовательно превосходил другие методы, демонстрируя самую высокую точность и самую быструю сходимость, особенно на сложных нелинейных ландшафтах. Градиентный спуск на основе импульса улучшил сходимость по сравнению с классическим методом, но не достиг точности Adam. Метод спада скорости обучения стабилизировал процесс оптимизации, но не достиг производительности Adam. Эти результаты подчеркивают эффективность алгоритмов адаптивной оптимизации при решении сложных задач оптимизации, предоставляя ценную информацию для их применения в машинном обучении, нейронных сетях и других областях, требующих эффективных методов оптимизации.
Text of the scientific article Comparative analysis of gradient descent methods and their modifications for optimizing complex functions
Gradient descent is a key optimization technique used across a wide range of fields, including machine learning, neural networks, and various scientific and engineering applications. The algorithm's primary function is to iteratively adjust model parameters in the direction of the steepest descent to minimize an objective function. While it is simple and widely applicable, classical gradient descent faces significant difficulties when applied to non-linear or highdimensional problems. These issues often manifest as slow convergence and a tendency to become trapped in local minima, which can significantly reduce its overall effectiveness. To overcome these limitations, several variations of the algorithm have been developed. These include momentum-based methods that leverage past gradients to accelerate convergence, adaptive techniques like Adam that dynamically adjust learning rates, and methods that employ variable learning rates to better handle complex optimization landscapes.
In this study, we conduct a comparative analysis of four different gradient descent-based optimization algorithms: classical gradient descent (GD), momentum-based gradient descent (MGD), adaptive gradient descent (AGD), and a learning rate decay method. These algorithms are applied to two benchmark test functions – the Matyas function and Levi Function № 13 – in order to evaluate and compare their efficiency, accuracy, and speed of convergence. The goal is to provide a deeper understanding of the strengths and weaknesses of each algorithm, shedding light on their performance in optimization tasks of varying complexity.
Methodology
Test Functions
The Matyas function and Levi Function No. 13 were chosen as test cases due to their nonlinear, multi-dimensional nature, which challenges optimization algorithms.
- Matyas Function is defined as:
f(x,y) = 0.26(^2 + у2) — 0.48xy (1)
This function is relatively simple but provides a good baseline for evaluating the optimization process.
- Levi Function № 13 is defined as:
f(x,y) = sin2(37%) + (% — 1)2(1 + sin2(37y)) + (y — 1)2(1 + sin2(27iy)) (2)
Levi Function is more complicated and exhibits multiple local minimums, making it suitable for testing the robustness of different optimization methods.
Gradient Descent Algorithms
The following gradient descent algorithms were implemented and compared:
-
1. Classical Gradient Descent (GD):
The basic approach, where parameters are updated in the direction of the negative gradient. The learning rate is constant, which may result in slow convergence or oscillations in certain cases.
Code for GD:
def GD( func: callable, grad: callable, start_params: np.ndarray, glob_min: np.ndarray, max_iter: int = 1000, lr: float = 0.1, delta: float = 0.001
-
) -> np.array:
-
# initial set of parameters
step = 0
while (step < max_iter and (history[-1][2] -glob_min[2]) > delta):
-
# new parameter values
params = params - lr * grad(params)
-
# saving the result
-
2. Momentum-Based Gradient Descent (MGD):
step += 1
This method introduces an inertia term to the gradient update to accelerate convergence and reduce oscillations near the minimum.
Code for MGD:
def MGD( func: callable, grad: callable, start_params: np.ndarray, glob_min: np.ndarray, max_iter: int = 1000, lr: float = 0.1, delta: float = 0.001, beta: float = 0.5
-
# initial set of parameters
step = 0
-
# new parameter values
params_new = params - lr * grad(params) + beta * (params - params_prev)
params_prev = params params = params_new
-
# saving the result
-
3. Adaptive Gradient Descent
step += 1
(AGD/ADAM):
Adam adjusts the learning rate for each parameter dynamically, using estimates of first and second moments of the gradients. This makes it particularly effective in handling non-stationary and noisy gradients.
Code for AGD:
def AGD( func: callable, grad: callable, start_params: np.ndarray, glob_min: np.ndarray, max_iter: int = 1000, lr: float = 0.1, b1: float = 0.9, b2: float = 0.999, e: float = 10e-8, delta: float = 0.001
-
# initial set of parameters
-
# moments initialization
step = 0
-
# calculating moments
m = b1 * m + (1 - b1) * grad(params)
v = b2 * v + (1 - b2) * grad(params) ** 2
-
# new parameter values
-
# saving the result
-
4. Learning Rate Decay Method (GD_LR):
step += 1
This method applies exponential decay to the learning rate over iterations, which stabilizes the optimization process as it approaches a minimum.
Code for GD_LR:
def GD_LR( func: callable, grad: callable, start_params: np.ndarray, glob_min: np.ndarray, lr: [], max_iter: int = 1000, delta: float = 0.001
-
) -> np.array:
-
# initial set of parameters
step = 0
while (step < max_iter and (history[-1][2] -glob_min[2]) > delta):
-
# new parameter values
params = params - lr[step] * grad(params)
-
# saving the result
step += 1
Experimental Results
Performance on the Matyas Function
The performance of the four algorithms was tested on the Matyas function, with results presented in terms of the final function value, error compared to the global minimum, and the number of iterations.
Results:
-
- Classical Gradient Descent:
The classical gradient descent algorithm showed convergence but exhibited slow progress, with an error of – 0.112, especially as the function approached the global minimum.
-
- Momentum-Based GD:
The momentum-based GD accelerated convergence and achieved a smaller error of -0.079, but still did not reach the exact minimum in some trials.
-
- Adaptive Gradient Descent:
Adam demonstrated the most efficient convergence, reaching the global minimum with a negligible error of -1.98e-08, highlighting its superior adaptability in simpler landscapes.
-
- Learning Rate Decay Method:
The learning rate decay method stabilized the descent and achieved a moderate error of -0.0225, but converged slower compared to Adam.
There are all results for Matyas Function in Table 1.
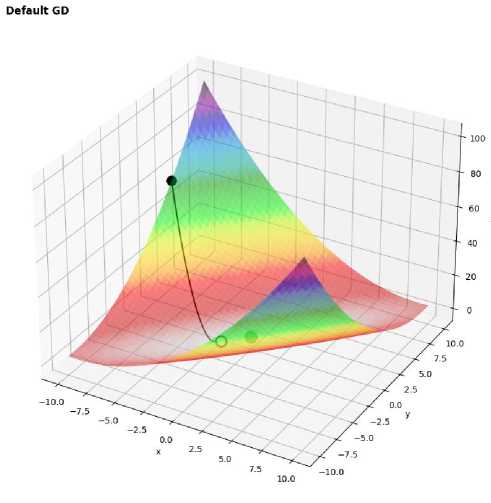
Figure 1. 3D surface plot of Matyas function with optimization path using GM
MGD
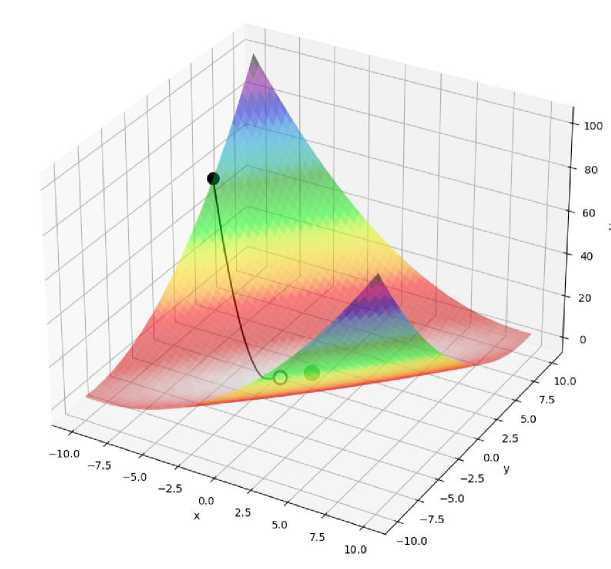
Figure 2. 3D surface plot of Matyas function with optimization path using MGM
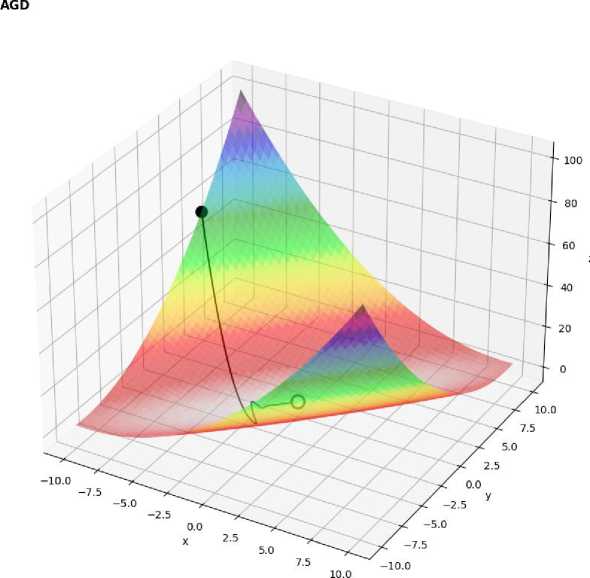
Figure 3. 3D surface plot of Matyas function with optimization path using AGD
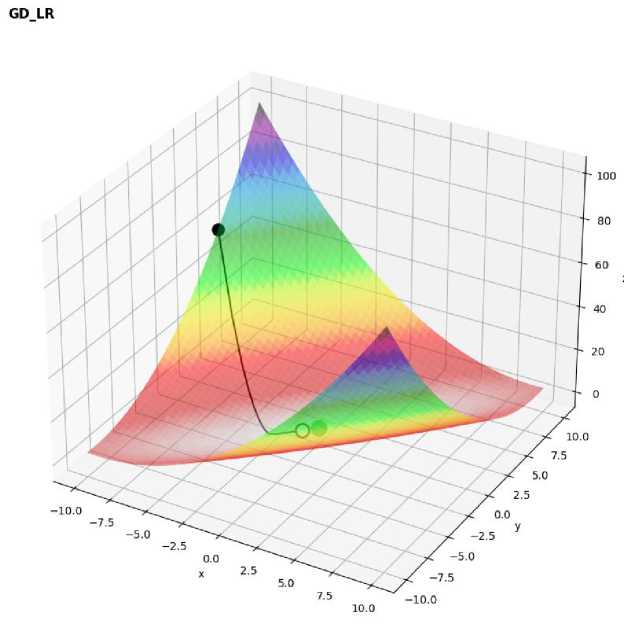
Figure 4. 3D surface plot of Matyas function with optimization path using GD_LR
Table 1. Results for Matyas Function by different methods
|
Method |
Execution time, sec |
Starting point |
Found min |
Global min |
Error |
Number of iterations |
|
GD |
0.147106 |
[-10.00 5.00 56.50] |
[-1.68e+00 - 1.68e+00 1.12e-01] |
[0 0 0] |
-0.1123305 |
10001 |
|
MGD |
0.082393 |
[-10.00 5.00 56.50] |
[-1.41e+00 - 1.41e+00 7.97e-02] |
[0 0 0] |
-0.0797257 |
10001 |
|
AGD |
0.023986 |
[-10.00 5.00 56.50] |
[-7.04e-04 -7.03e-04 1.98e-08] |
[0 0 0] |
-1.97847e-08 |
903 |
|
GD_LR |
0.052210 |
[-10.00 5.00 56.50] |
[-7.50e-01 -7.50e-01 2.25e-02] |
[0 0 0] |
-0.022515088 |
10001 |
Performance on the Levi Function № 13
Due to its multiple local minima, the Levi function presented a more challenging scenario for the algorithms.
Results:
-
- Classical Gradient Descent:
The classical gradient descent struggled with local minima, often failing to converge to the global minimum. It reached a local minimum with an error of -11.94, indicating its sensitivity to the complex landscape.
-
- Momentum-Based GD:
The momentum-based GD improved convergence compared to the classical method, but still showed sensitivity to the choice of initial conditions, resulting in an error of -4.08 and not reaching the global minimum.
-
- Adaptive Gradient Descent:
AGD’s performance was less effective for the Levi function, as it converged to a different local minimum with a significant error of -19.80, indicating challenges in overcoming multiple local minima in this complex function.
-
- Learning Rate Decay Method:
The learning rate decay method was not fully tested for the Levi function due to issues of instability and overflow in its complex landscape, highlighting its limitations in handling non-linear functions with steep gradients.
There are all results for Levi Function № 13 in table 2.
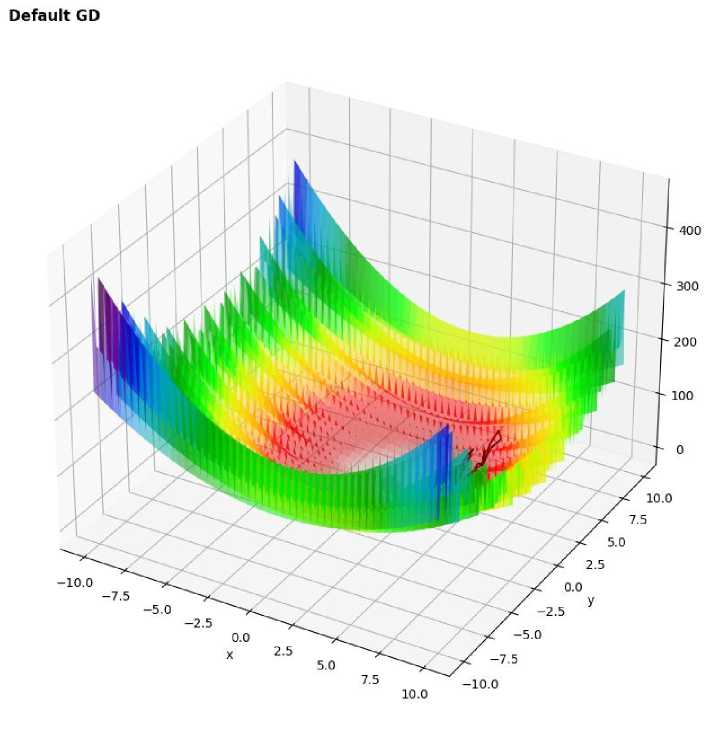
Figure 5. 3D surface plot of Matyas function with optimization path using GD
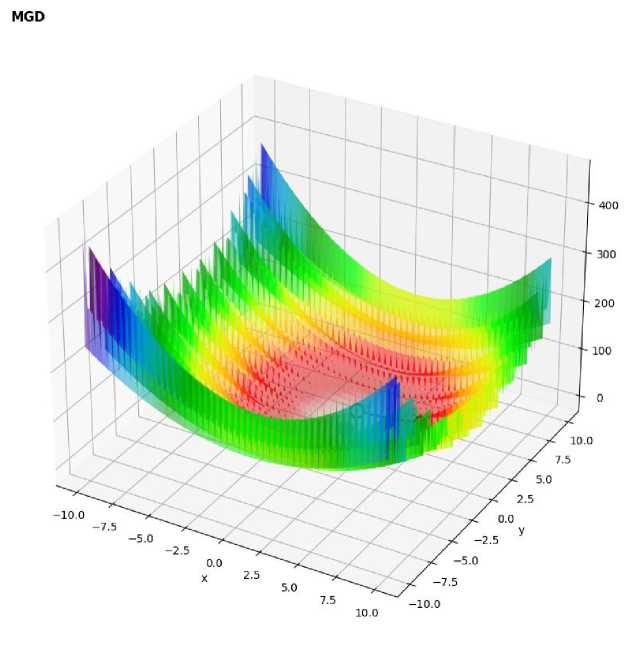
Figure 6. 3D surface plot of Matyas function with optimization path using MGD
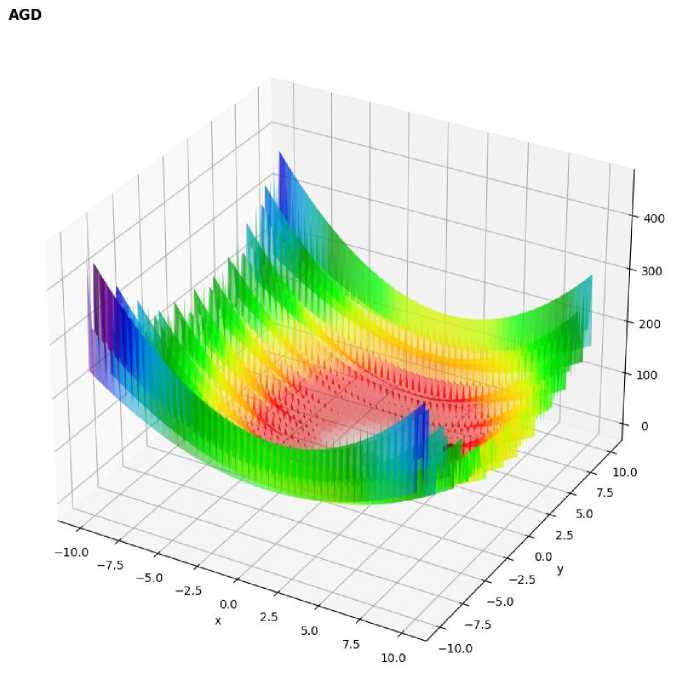
Figure 7. 3D surface plot of Matyas function with optimization path using AGD
Table 2. Results for Levi Function No. 13 by different methods
|
Method |
Execution time, sec |
Starting point |
Found min |
Global min |
Error |
Number of iterations |
|
GD |
0.093601 |
[5.00 3.00 20.00] |
[3.60e+00 2.08e+00 1.19e+01] |
[1 1 0] |
-11.93980307 |
10001 |
|
MGD |
0.149629 |
[5.00 3.00 20.00] |
[6.70e-01 2.99e+00 4.09e+00] |
[1 1 0] |
-4.085823934 |
10001 |
|
AGD |
0.252420 |
[5.00 3.00 20.00] |
[4.95e+00 3.00e+00 1.98e+01] |
[1 1 0] |
-19.80565035 |
10001 |
The experimental outcomes reveal that for the Matyas function, Adam stood out as the most effective algorithm, achieving the global minimum with minimal error. The momentum-based approach improved the convergence speed compared to classical gradient descent, but it fell short of the accuracy level attained by Adam.
For the Levi function, its complex structure with multiple local minima presented significant difficulties for all algorithms. Neither classical GD nor MGD were able to reach the global minimum, and even Adaptive Gradient Descent, typically effective in such cases, struggled to find the optimal solution. The learning rate decay method proved to be unstable for this highly complex function.
In summary, while adaptive gradient descent demonstrated its robustness with simpler functions like the Matyas function, its limitations became clear when faced with the more intricate Levi Function № 13.
Conclusion
This research provides a comparative analysis of four gradient descent-based optimization algorithms: classical gradient descent (GD), momentum-based gradient descent (MGD), adaptive gradient descent (Adam), and a method incorporating learning rate decay. These algorithms were evaluated on two test functions, the Matyas function and the Levi Function No. 13, which provided insight into their varying performances based on the complexity of the optimization task.
For the Matyas function, Adam proved to be the most efficient, offering nearly flawless convergence with very little error. The momentumbased gradient descent improved convergence speed over the classical method but did not achieve the same level of precision as Adam. Meanwhile, classical gradient descent struggled with slow convergence near the global minimum, and although the learning rate decay method offered more stability, it was still less efficient than Adam.
In the case of the Levi Function № 13, which is marked by multiple local minima, all the tested algorithms faced considerable challenges. Both the classical gradient descent and the momentumbased method were trapped in local minima and failed to reach the global minimum. Even Adam, which usually excels in such scenarios, converged to a local minimum with a significant error. The learning rate decay method exhibited instability and was not fully evaluated due to computational difficulties, highlighting its limitations when dealing with complex, highly nonlinear functions.
This study highlights the practical and theoretical significance of various gradient descent vari- ations, especially in the context of machine learning and neural network optimization. Adaptive methods like Adam have proven highly effective in speeding up convergence and minimizing errors in high-dimensional functions, making them ideal for deep learning applications. However, while Adam performs well on simpler tasks, more advanced techniques may be necessary for more complex functions with intricate landscapes and multiple local minima, as encountered in deep neural networks.
Furthermore, this research underscores the importance of selecting appropriate optimization strategies for challenging problems, such as those involving noisy data or complex network architectures. The Levi Function № 13 serves as a representative model for the difficulties faced in real-world machine learning tasks. The findings suggest that combining gradient descent with metaheuristic techniques like evolutionary algorithms or global optimization methods may offer more robust solutions. Additionally, fine-tuning learning rate scheduling could further improve training stability and help prevent overfitting, particularly in large-scale, noisy datasets. These insights open up avenues for future research into hybrid optimization algorithms designed for complex machine learning challenges.
References Comparative analysis of gradient descent methods and their modifications for optimizing complex functions
- Кингма, Д. П., Ба, Дж. Adam: Метод стохастической оптимизации // Международная конференция по представлению обучения (ICLR). - 2015. - С. 9.
- Рудер, С. Обзор алгоритмов оптимизации градиентного спуска. - 2016. - С. 4.
- Паскану, Р., Миколов, Т., Бенгио, Й. О сложности обучения рекуррентных нейронных сетей // Международная конференция по машинному обучению (ICML). - 2013. - С. 8.
- Гудфеллоу, И., Бенгио, Й., Курвиль, А. Глубокое обучение. - MIT Press. 2016. - С. 151.
- Ботту, Л. Машинное обучение в крупном масштабе с использованием стохастического градиентного спуска // Труды COMPSTAT'2010. Physica-Verlag HD, 2010. - С. 177-186.
