Deep Learning Model Factors Influencing Decision Support in Crop Diseases and Pest Management: A Systematic Literature Review

Author: Vincent Mbandu Ochango, Geoffrey Mariga Wambugu, Aaron Mogeni Oirere
Journal: International Journal of Information Technology and Computer Science @ijitcs
Article in issue: 6 Vol. 17, 2025.
Free access
The deep learning models are being used in the agricultural sector, ushering in a new age of decision support for crop pest and disease control. In light of the difficulties faced by farmers, this literature study seeks to identify the critical components of deep learning models that affect decision support. All the way from model design to data input to training approaches and their effects on efficient decision-making. Examining the deep learning model factors influencing decision support in crop diseases and pest management was the primary goal. The researcher looked at articles and journals published by IEEE access, ACM, Springer, Google Scholar, Wiley online library, Taylor and Francis, and Springer from 2014 to 2024. From the search results, sixty-three publications were selected according to their titles. The paper provides a synopsis of deep learning models used for crop health management based on a careful evaluation of scholarly literature. In order to shed light on the merits and shortcomings of different models, the article conducts a thorough literature review and literature synthesis. Future studies might be guided by the identification of methodological issues and gaps in present research. Applying deep learning to the problem of agricultural diseases and pest control has real-world consequences, as shown by several case studies and applications. Insightful for academics, practitioners, and legislators in the field of precision agriculture, this extensive study adds to our knowledge of the complex relationship between elements in deep learning models and their impact on decision support.
Deep Learning, Decision Support, Deep Neural Network Architectures, Convolution Neural Network, Data Augmentation, and Transfer Learning
Short address: https://sciup.org/15020088
IDR: 15020088 | DOI: 10.5815/ijitcs.2025.06.03
Text of the scientific article Deep Learning Model Factors Influencing Decision Support in Crop Diseases and Pest Management: A Systematic Literature Review
The merging of data-driven technology with traditional farming practices has opened up new opportunities for enhancing crop resilience and yield in today's dynamic agricultural landscape. The advent of deep learning, a complicated subfield of AI, is fundamental to this new wave of innovation due to its remarkable ability to process enormous amounts of data and reveal intricate patterns. In this study, the researcher conducted a comprehensive literature analysis to identify the many aspects that affect how well deep learning models work in decision support systems for pest and disease control in crops [1]. Deep learning's hierarchical neural network designs have been a model of state-of-the-art innovation as it pertains to comprehending the complex network of connections in agricultural ecosystems. Deep learning models can grasp complex characteristics and subtle relationships because, unlike conventional machine learning methods, they develop hierarchical representations from raw data on their own. Because it can handle a wide variety of data types, including images, sensor data, and time series, deep learning has found widespread use in agriculture, especially for the detection and control of pests and illnesses that affect crops [2].
In decision support for pest and disease control in crops, the efficacy of deep learning models is affected by several distinct variables. Models depend on big, high-quality datasets that reflect different environmental conditions, crop varieties, and pest types, therefore data quality is one of the main concerns. If you want clean data that is good for training models, you need to use proper preprocessing methods like data augmentation and normalization. Another important consideration is the model architecture. For example, weather patterns or time-series data, such as pest populations, may be better handled by Recurrent Neural Networks (RNNs), whereas image-based disease detection is often accomplished using Convolution Neural Networks (CNNs). You can improve the model's accuracy and generalizability by tuning its hyperparameters, such as the learning rate and batch size. Integrating agronomic insights allows for the customization of the model to identify certain diseases or pests relevant to specific crops, which is another important component. Domain-specific information is also crucial. Last but not least, decision support relies heavily on model interpretability so that specialists in agriculture and farming can make sense of the forecasts and suggestions. All of these things come together to decide how well and how practically deep learning models work in farming [3, 4].
This paper delves into some key aspects of deep learning, one of which is the variety of model architectures developed to address certain problems in crop health management. To detect illness symptoms from visual data, Convolutional Neural Networks (CNNs) which are trained for image-based tasks perform very well in extracting spatial characteristics. To track the development of an illness over time, Recurrent Neural Networks (RNNs) are ideal because of their skill at capturing temporal dependencies. Furthermore, a crucial tactic for improving model generalization in agricultural environments is transfer learning, a method that enables models trained in one domain to adapt to another [5]. This literature review explores the vast terrain of research and identifies the key parameters impacting deep learning model performance. To train robust models that can generalize across varied agricultural contexts, we analyze the relevance of high-quality data and highlight the necessity of curated datasets. Examining the interpretability of deep learning choices, the research tackles the persistent problem of simplifying complicated models so that farmers and agricultural practitioners can use them in practice [6].
Three primary research questions served as the basis for this literature study's examination of the elements impacting decision support in crop disease and pest control using deep learning models. The evaluation started by taking a look at the main deep-learning model architectures used in decision support systems for pest and disease management in crops. Its main goal was to figure out how different architectural decisions affected the models' ability to accurately predict future outcomes. Finding out how often different model types were used and how they impacted performance was the goal of this study. Model types might include recurrent neural networks (RNNs), convolutional neural networks (CNNs), or other designs. Second, the research looked at how different data-related aspects affected the accuracy of the models. Research focused on understanding how input data sources (such as kind, quality, and availability) affected model generalizability and performance in actual agricultural contexts. Lastly, the research looked at the main problems and restrictions that have been found when using deep learning models for pest and disease management in crops. Additionally, it took into account the methods and developments suggested by researchers to address these issues, all to make these systems more useful for farmers when making decisions. To answer these concerns, the analysis looked at the current state of deep learning applications in the agricultural sector and areas of future improvement [7, 8].
The investigation goes beyond technical details to include the pragmatic issues of using deep learning models in actual farming contexts. The researcher took into account the socio-economic ramifications of these technologies, as well as their scalability and adaptation to different climatic circumstances. This systematic literature review hopes to fill in the gaps in our knowledge of the potential of deep learning models as game-changing resources for decision-support in the field of agricultural disease and pest control by combining the aforementioned findings. The first objective is to contribute to the academic discourse; the secondary objective is to provide agricultural stakeholders with the knowledge to incorporate these technologies into sustainable and resilient crop production systems [9]. The remaining sections of the paper are structured as follows: Section 2 delves into relevant literature, Section 3 examines methods, Section 4 addresses discussion, and Section 5 concludes the research.
2. Related Works
There is exciting new potential for agricultural technology at the crossroads of decision support systems and deep learning models to transform conventional farming by addressing crop diseases and pests. The purpose of this literature review is to provide a comprehensive analysis of the current research on the topic of crop health decision support by identifying the critical success criteria and barriers to their widespread use.
The successful use of deep learning models in agricultural pest and disease management has been shown by several real-world case studies. One area where CNNs have found use is in tomato farming, namely in the detection of late blight and bacterial spots. These models enabled farmers to snap pictures of diseased plants using their mobile devices and get instantaneous feedback, allowing them to take early precautions. To minimize crop loss and identify autumn armyworm infestations, drones equipped with deep-learning models like YOLO were used in maize fields. This allowed for targeted pesticide treatment. Also, to improve the productivity of post-harvest activities, deep learning models were used in apple orchards to automate sorting by recognizing diseases like apple scab [10].
A deep learning model was trained to analyze historical trends, satellite images, and weather data to forecast the occurrence of rice blast disease in rice farms. This allowed farmers to take precautions, including timing their plantings or fungicide applications more precisely. One further example is the optimization of water consumption in drought-prone regions with the use of Long Short Term Memory networks, which can estimate irrigation demands based on environmental variables and crop growth data. The adoption of deep learning models has revolutionized agricultural operations. These instances show how these models have improved sustainability and production via early disease identification, precise pest control, and efficient resource utilization [11].
Decision support systems for pest and disease management in crops now rely heavily on deep learning technologies, especially federated learning and explainable AI. By making model choices more transparent and interpretable, explainable AI solves a major problem with deep learning models: their black-box nature. Particularly in the agricultural sector, whereby the rationale behind model-recommended pesticide applications or irrigation adjustments is crucial for farmers and agricultural specialists, this is of paramount importance. Stakeholders are now more likely to trust and make good use of AI-based judgments in their practices because to XAI approaches like visual explanations and feature significance, which has increased the field's adoption of deep learning systems [12].
Another noteworthy development is federated learning, which eliminates the need for centralized data by enabling model training across several distributed devices like sensors, drones, or cellphones. This allows groups of farmers or agricultural organizations to work together, with the added security of keeping sensitive data locally while yet taking use of the network's collective wisdom. Localized data may enhance model accuracy while preserving privacy; this method shines in situations with varied crop varieties, temperatures, and pest conditions. Increased efficiency and longevity in the fight against crop diseases and pests are direct results of these developments, which have substantially strengthened decision support systems used in farming [13].
Rajeshram et al., 2023 [15] study provides an in-depth look at how deep learning is being used in crop improvement. The research adds to our understanding of deep learning's potential applications in crop health management, but it also draws attention to several gaps in our understanding that need to be filled up. An important area that needs more investigation is the extent to which deep learning models can be applied to various agricultural contexts and varieties of crops. The report alludes to the significance of studying the effects of various agricultural techniques on the effectiveness of these models and how they function under varied environmental situations. Another major issue is the lack of interpretability in deep learning models when it comes to predictions of diseases, detection of pests, and recommendations for pesticides. For end-users, including farmers and agricultural practitioners, to have faith in and understand these sophisticated systems' suggestions, further research is required to increase the openness of model conclusions. A more inclusive and adaptive approach to precision crop management can only be achieved by filling up these knowledge gaps and using deep learning methods widely in agricultural environments.
The urgent problem of the health of citrus crops is addressed by Luo et al., 2023 using sophisticated detection models. The research adds to the field's expertise by improving disease and pest detection accuracy using the YOLOv8 architecture with the Self-Attention mechanism, but it also shows where we need to fill in certain gaps. One important area that needs more attention is the lack of debate on how well the model performs in different environments and regions. These characteristics are vital since they affect how reliable disease and pest detection is in citrus crops. Furthermore, the article neglects to thoroughly investigate the interpretability of the Self-Attention YOLOv8 model, which is an essential component for its practical use in actual agricultural contexts. Gaining end-user trust, especially from agronomists and farmers, requires understanding the model's decision-making process and recognizing any biases. In addition, before its implementation in agricultural settings with limited resources, further research on the suggested model's scalability and resource efficiency is required. To better comprehend deep learning solutions for precision agriculture and to make the Self-Attention YOLOv8 model more useful for detecting citrus diseases and pests, it is necessary to fill these gaps in our current knowledge [16].
Research by Rathnayake et al., 2023 addresses a major problem in Sri Lankan agriculture. Although the study offers helpful information on how banana producers might use mobile technology to their advantage, there are still some unanswered questions that need to be addressed. To begin, it would be helpful if the article delved more into the particular plant diseases and insect infestations that are common in Sri Lankan banana production. This is because developing successful mobile solutions requires an awareness of the complexities of these problems. The writers may also investigate the banana farmers' socioeconomic background, looking at things like literacy rates, smartphone affordability, and access to technology. The requirements of the target audience may be better met by customizing the mobile solution if these contextual aspects are understood. The article might also explore rural regions' technical infrastructure, looking at problems with power availability and network connection that affect the viability and uptake of solutions that rely on mobile devices. If the authors want their research to be more useful, they could show how their mobile solution works in real-world situations via case studies or pilot projects. To better understand how the mobile solution may empower banana growers in Sri Lanka, it is important to fill up these gaps [17].
There are several limitations in understanding what needs to be addressed, even if Parkavi et al., 2023 did an investigation on the use of Machine Learning and the Internet of Things in farming. First, the suggested sophisticated agro-management systems may not work in all kinds of different agricultural contexts, thus there was a disconnect between what big-scale farmers want and what small-scale farmers with limited resources require. It is critical to address the applicability and scalability of these technologies to various agricultural sizes. Further investigation into the socio-economic effects of using cutting-edge technology in farming, such as the need to train farmers' skills and the possible upheaval to conventional agricultural methods, would strengthen the article. The environmental effects of growing electronic waste from Internet of Things (IoT) devices and the energy needed to keep a network of linked devices running in outlying agricultural regions are two additional potential research gaps concerning the proposed system's long-term viability. Filling up these gaps in information will improve the paper's contributions and help the researcher comprehend the pros and cons of using Machine Learning and the Internet of Things to implement sophisticated agro-management systems [18].
In the article Identification and Classification of Crop Diseases using Transfer Learning-based Convolutional Neural Network published by Mehta et al. in 2023, the authors brought to light several important information gaps. The first issue is that there was not enough focus on optimizing and exploring transfer learning approaches for crop disease detection. This may be due to insufficient research on possible transferrable feature choices, fine-tuning approaches, or pre-trained model selections. Furthermore, there was a gap in the unique difficulties of crop disease datasets, including differences in imaging parameters, a wide variety of plant species, and several phases of disease development. If the researchers want models to be more accurate and generalizable across different agricultural settings, how to include domain-specific information, like agronomic experience, into the training process needs to be done. A comprehensive analysis of the data utilized for training, any biases that may exist in it, and the possible socioeconomic effects of applying this technology to agriculture would strengthen the article. Filling up these gaps in information might greatly improve the suggested Convolutional Neural Network's (CNN) capacity to detect and classify agricultural diseases [19].
Issues with generalizability, possible biases, and overfitting are major concerns when it comes to deep learning models used to aid decision-making in agricultural pest and disease management. Unbalanced datasets, in which the model is trained on a small subset of possible crop types, pest species, or environmental factors, might lead to bias. Consequently, models may work well in certain areas or under some circumstances, but they can't adapt to all types of agricultural settings. A model that has been trained on data from one area may not be able to effectively forecast pests or diseases in another area because of the significant climatic and crop variety differences [20].
A further difficulty arises when models are trained using little or very narrow datasets: overfitting. This can cause the model to develop insights exclusive to the training data, rendering it useless when presented with new, unknown data. In real-world circumstances, where conditions are typically dynamic and changing, the model's value is limited because of this. To prevent overfitting and make the model more resilient, it is necessary to use techniques such as regularization, and cross-validation, and to utilize bigger, more varied datasets [21].
An important concern is the lack of generalizability to other agricultural settings. Distributed datasets that capture regional differences in weather, pests, soil, and crop types are essential for training deep-learning models with broad applicability. For models to be used more widely in agriculture, it is crucial that they can adjust to different situations without losing accuracy. Tackling these concerns necessitates meticulous model construction, enhanced data gathering, and testing in various agricultural settings to guarantee the models provide dependable choice assistance for various farming systems [22].
3. Methodology
A systematic literature review was carried out by the researcher. This is a way to gather, analyze, and synthesize data from prior research on a certain topic in a systematic and orderly manner. Methodically seeking relevant studies, assessing their quality, extracting important data, and summarizing the findings were all steps in this process. Review planning, implementation, and reporting were the first steps of the process [23]. Everything about the review process, from the questions to be answered, is laid out in full. In this research, we aimed to understand how various deep learning factors, such as activation functions, pooling layers, network depth, and convolutional layers, influence decision support in crop diseases and pest management. When developing the search strategy, we considered both the databases and the parameters for the search. The inclusion and exclusion criteria were based on the year and kind of publication. An extensive search was carried out via academic journals, popular publications, and conference proceedings, among other sources [24].
The review was conducted on the aspects impacting decision support in crop diseases and pest control using deep learning models. Data extraction, coding, and synthesis were all carried out according to predetermined protocols. First, the researcher searched databases extensively for relevant publications using terms like deep learning, crop diseases, pest management, and decision support systems. To guarantee that only the most relevant and high-quality research was picked, a thorough screening procedure was carried out once the studies were retrieved, based on predetermined inclusion and exclusion criteria. Important details including model types, performance-influencing variables, and results were meticulously collected and packaged in a structured style for data extraction. Data quality, model design, preparation methods, and domain integration were some of the topics into which the collected data was coded to make it easier to spot trends across research. Last but not least, synthesis included reviewing and evaluating the coded data to draw attention to similarities, differences, and trends in the applications of deep learning models to agricultural decision support. The elements that affect these models' efficacy in controlling pests and diseases in crops were better understood with this methodical approach [25].
-
3.1. Systematic Literature Review Process
A thorough and objective synthesis of the available research on a particular subject is achieved via the rigorous procedures involved in carrying out a systematic literature review. The scientific literature review is used to gather, evaluate, and comprehend all pertinent research about a certain research issue, subject domain, or phenomena of interest. Due to its focus on systematic reviews also known as secondary studies—this research is categorized as a tertiary literature review. The method is structured into three distinct phases. Fig.1. below shows the three components that make up this stage: planning, conducting, and reporting on the review.
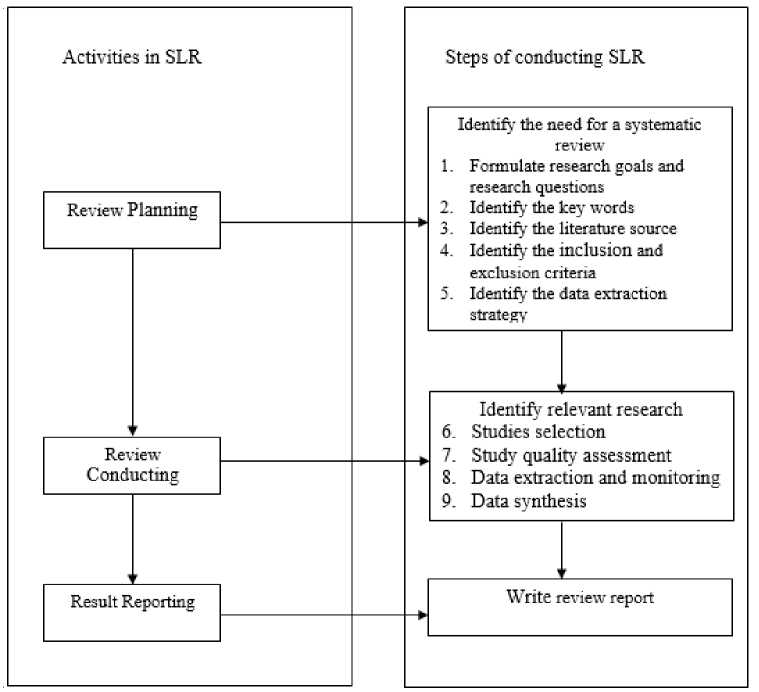
Fig.1. Systematic literature review process
Identifying which research questions will guide the review is the first order of business. To do this, the researcher must first isolate the important ideas and variables, such as the most common deep learning model structures used to aid in decision-making about crop diseases and pest control, and then note any pertinent data-related aspects and difficulties linked to their implementation. Making a plan for a systematic search is the next stage after deciding on research topics. To find relevant material, you need to do things like define search phrases and keywords and choose the right databases and search engines. Furthermore, research should be selected according to predetermined inclusion and exclusion criteria that take into account their quality and relevance [26].
Finding and evaluating relevant studies is the next step in a systematic literature review after creating the search strategy. This entails searching for relevant literature using the specified keywords and established search phrases, and then filtering that material according to the criteria for inclusion and exclusion. There are usually two steps to the screening process: first, a quick scan of the titles and abstracts to find studies that may be of interest, and second, a thorough reading of the whole text to decide which ones to include. Documenting search tactics and screening choices is critical for maintaining transparency and reproducibility throughout the process [27].
Following the identification of appropriate studies, data extraction is carried out to methodically gather information from each study that pertains to the research questions. This could include information on the study's methodology, main results, and any problems or issues connected to the data that were found to be significant. Using standardized forms or templates may make data extraction easier and more consistent across investigations. To answer the study questions, the researcher evaluates and interprets the synthesis results after data extraction. Finding commonalities or trends among the included papers, summarizing their main points, and debating their implications for theory, practice, and future study are all part of this process [28].
The last step in a systematic literature review is to synthesize the results and present them in an organized and clear way. Common methods include formulating research questions, developing a search strategy, conducting screenings, extracting data, analyzing it, and drawing conclusions. A discussion of the methodology's merits and shortcomings, along with suggestions for further study, may also be part of the evaluation. If you want your systematic literature review results to be legitimate and reliable, you need to prepare ahead, pay close attention to detail, and follow all the rules and regulations [29].
Table 1. Steps used to conduct a systematic literature review
|
Step |
Description |
|
1. Define Research Questions |
Clearly articulate the specific research questions or objectives that the review aims to address. These questions guide the search process and the selection of studies. |
|
2. Develop Search Strategy |
Develop a comprehensive search strategy, including selecting appropriate databases, defining search terms and keywords, and setting inclusion and exclusion criteria. |
|
3. Search for Relevant Studies |
Conduct searches using the predefined search strategy across selected databases and sources of literature. |
|
4. Screening of Studies |
Screen the search results based on predefined inclusion and exclusion criteria, initially by titles and abstracts, and then by full-text review. |
|
5. Data Extraction |
Extract relevant data from the included studies using standardized forms or templates, capturing key details such as study characteristics, methodology, and findings. |
|
6. Synthesis and Analysis of Findings |
Synthesize and analyze the extracted data to identify common themes, patterns, and trends across the included studies. |
|
7. Interpretation of Findings |
Interpret the synthesized findings about the research questions, discussing their implications for theory, practice, and future research directions. |
|
8. Writing the Review |
Prepare a comprehensive report or manuscript outlining the methodology, search process, findings, analysis, and interpretation of the systematic literature review. |
|
9. Peer Review and Revision |
Submit the review for peer review and feedback, incorporating any necessary revisions to enhance the clarity, rigor, and validity of the review. |
|
10. Final Publication |
Finalize the systematic literature review for publication, ensuring adherence to journal guidelines and standards, and disseminate the findings to relevant stakeholders. |
-
3.2. Planning the Review
-
3.3. Research Questions
-
3.4. Search Criteria
Developing a clear research question or purpose to guide the review process is the first stage in organizing a systematic literature review. Afterward, precise inclusion and exclusion criteria are defined to pick suitable research. Subsequently, to guarantee thorough coverage, a systematic search method is devised to locate relevant material across many databases[30]. Careful planning goes into the data extraction process, detailing which studies will have certain variables and information retrieved. To ensure that the review is credible, quality evaluation techniques are used to determine the level of consistency in the included research. Statistical or thematic analysis approaches are used to derive relevant conclusions and identify gaps in current knowledge. A thorough and evidence-based overview of the specified issue is contributed to by a systematic synthesis of the results[31].
The following are some of the research questions that will be answered in this investigation;
RQ1. What are the primary deep learning model architectures utilized in decision support systems for crop diseases and pest management, and how do specific architectural choices impact the accuracy and efficacy of predictions?
RQ2. How do various data-related factors, such as the type, quality, and availability of input data sources, impact the performance and generalizability of deep learning models in the context of crop diseases and pest management decision support?
RQ3. What are the key challenges and limitations associated with the application of deep learning models in crop diseases and pest management decision support, and what strategies or advancements have been proposed to address these challenges and enhance the practical utility of such systems in agricultural contexts?
To narrow the search, the researcher considered how deep learning model factors affect the decision support in crop diseases and pest management. Various written works were generated, including white papers, conference papers, journal articles, books, and book chapters. To determine which works were eligible, we looked at their titles, abstracts, and entire texts. This analysis used publications that were published between 2014 and 2024. In Table 1 you can see all the databases that were searched and the documents that were approved or denied.
Table 2. List of databases
|
Database |
Number of documents retrieved |
Discarded duplicates and/or older than 2014 |
Considered for inclusion |
|
IEEE Explore |
109 |
95 |
14 |
|
Google Scholar |
54 |
44 |
10 |
|
ACM digital library |
64 |
57 |
7 |
|
Wiley online library |
77 |
69 |
8 |
|
Taylor & Francis |
62 |
58 |
4 |
|
Springer |
21 |
19 |
2 |
|
Elsevier |
79 |
63 |
16 |
|
Snowballing |
2 |
||
|
466 |
405 |
63 |
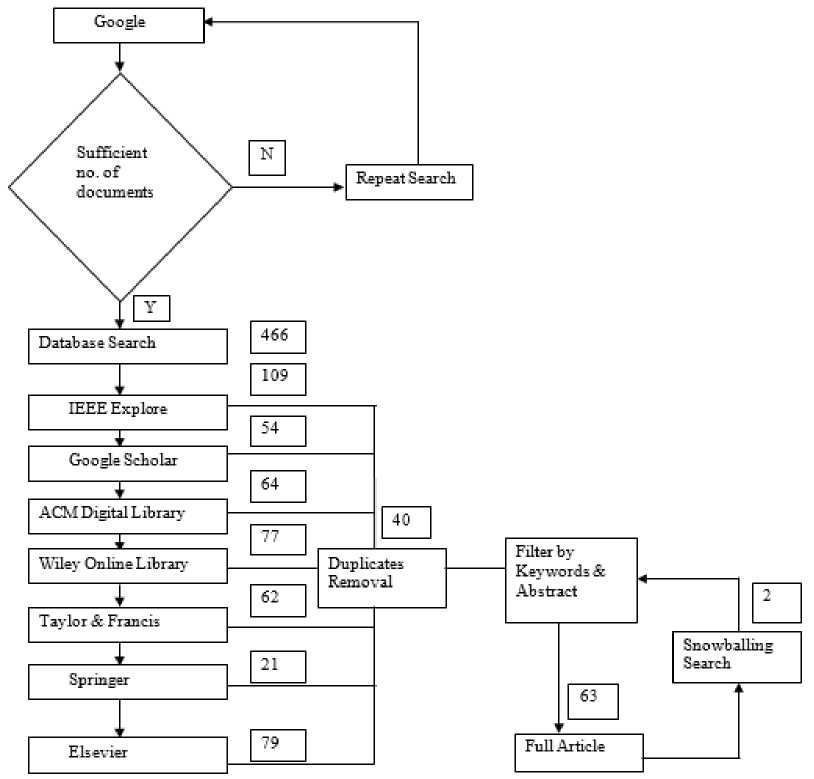
Fig.2. Article selection process
The findings part of a systematic literature review compiles and evaluates all of the research that was included in the review. An impartial and thorough summary of the material around a certain study issue or subject is given to readers in this section, making it crucial.
The agriculture industry has used a variety of deep learning model architectures to tackle the complicated problems associated with decision support systems for crop diseases and pest control. When it comes to image-based applications like crop disease and pest diagnosis, Convolutional Neural Networks (CNNs) stand out as a commonly used architecture. CNNs are great at extracting hierarchical information from pictures, which helps them spot abnormalities or subtle patterns that might be signs of a disease or pest infestation. Important factors include CNN structure and depth; more complex representations may be learned by deeper networks, but this comes at the expense of increasing processing demands[35]. Considerations including network depth, filter size, and training data quantity impact CNN accuracy in crop disease diagnosis. To avoid overfitting, deeper networks with more convolutional layers need more input, but they may capture more complicated characteristics. One way to represent the output of a convolutional layer is as follows:
о t = У У i i, j,k m n i
+ b m,n,k k
For the k-th filter, O i,j,k is the output feature map at location (i,j).
The input pixel value is denoted by Ii+m,j+n, the filter kernel is denoted by Km,n,k, and the bias term is denoted as bk.
Long Short-Term Memory (LSTM) and Recurrent Neural Networks (RNNs) have found use in decision support systems that operate with time series data, including tracking the development of crop diseases across time. These designs are great at seeing trends across time and capturing sequential relationships, which helps us understand how crop health changes over time. With RNNs being better at handling shorter sequences and LSTMs being better at capturing long-term relationships, the decision between two architectures is often dependent on the specifics of the dataset[36]. Recurrent Neural Networks (RNNs) are built to process sequential input by storing information from previous time steps in a concealed state. Traditional RNNs, on the other hand, have issues with vanishing gradients, which reduce their effectiveness when dealing with lengthy sequences. Long Short-Term memories (LSTMs) solve this problem by adopting a more intricate cell architecture that incorporates gates to regulate the information flow. The forget gate, input gate, and output gate are the three main components of a Long Short-Term Memory (LSTM) cell. These gates control the cell's state and update to its hidden state. For the LSTM gates, the formulae are as follows:
ft = CT W f .[ h t - 1 , X t ] + bf (2)
it = ^(W • [ h-1, x ]+bi)(3)
O' = «(W • [ h-1, xt ]+bo)(4)
Ct= tanh (Wc [ ht -1, xt]+be)(5)
c= ft* Ct -1+ it* Ct(6)
ht = ot* tanh (Ct)(7)
Where x t represents the input at time t, h t is the hidden state, C t is the cell state, and tanh is the hyperbolic tangent function. The weight matrices are denoted by W, and the biases are denoted by b and finally, <7 represents the sigmoid activation function.
The application of pre-trained models to massive datasets a technique known as transfer learning has also become more popular in the agriculture sector. Models that have already been trained on large picture datasets may be adjusted to perform tasks particular to crops by using the general information gained during training. When there is a lack of labeled data on agricultural diseases and pests, this method helps the model generalize better to new cases[37].
In conclusion, the data type and the unique difficulties of agricultural settings dictate the deep learning model architectures used for decision support systems dealing with pest and disease control in crops. For optimal accuracy and effectiveness in crop health problem prediction and management, it is necessary to carefully examine and tailor each architecture based on its strengths and trade-offs[38].
Table 3. Deep learning model architectures utilized in decision support systems for crop diseases and pest management
|
Deep Learning Model Architecture |
Description |
Impact on Accuracy and Efficacy |
References |
|
Convolutional Neural Networks (CNNs) |
Ideal for image-based tasks, CNNs excel at capturing hierarchical features. Architectural choices such as depth, convolutional layer configurations, pooling strategies and filter sizes influence the model's ability to discern relevant patterns in agricultural images. Deeper networks can capture intricate representations but may demand higher computational resources. |
Deeper networks may improve accuracy by capturing more intricate features, but computational demands may limit real-world deployment. Properly tuned convolutional layers and pooling strategies contribute to more effective feature extraction. |
[39] |
|
Recurrent Neural Networks (RNNs) |
Suitable for tasks involving temporal data, RNNs capture sequential dependencies. Architectural decisions include the number of layers, hidden units, and dropout rates, which affect the model's ability to capture temporal patterns in the progression of crop diseases over time. |
The choice between RNNs and LSTMs depends on the dataset characteristics. Properly tuned parameters prevent overfitting and contribute to accurate modeling of temporal dependencies. |
[40] |
|
Long Short-Term Memory Networks (LSTMs) |
Specialized RNNs are designed to capture long-term dependencies in temporal data. Effective for monitoring the progression of crop diseases over extended periods. |
LSTMs excel in modeling longer-term dependencies, contributing to accurate predictions in tasks involving temporal data. Careful tuning of architectural parameters is essential for preventing overfitting and ensuring model efficacy. |
[41] |
|
Transfer Learning |
Involves using pre-trained models on extensive image datasets, fine-tuned for crop-specific tasks. Architectural choices include the selection of pre-trained models, the extent of fine-tuning, and adaptation to specific agricultural scenarios. |
Transfer learning is advantageous when labeled data for crop diseases and pests are limited, enhancing model generalization. Proper selection of pre-trained models and fine-tuning strategies is crucial for effective adaptation to agricultural contexts. |
[42] |
The ability of Convolutional Neural Networks (CNNs) to capture hierarchical characteristics from pictures makes them ideal for image-based tasks in pest and crop disease control. How well the model can extract useful characteristics from agricultural images is affected by the network depth, the design of convolutional layers, and the sizes of the filters. There is a trade-off between the greater computing needs caused by deeper networks and the ability to record more complex patterns, which might lead to improved accuracy. To improve feature extraction and maximize model performance, convolutional layers must be tuned correctly[43].
One use of RNNs is tracking the development of agricultural diseases over time, which involves processing data over some time. When designing RNNs, it is essential to consider architectural factors like layer count and dropout rates to capture sequential dependencies and avoid overfitting. If these parameters are tuned correctly, the decision support system will be able to accurately model temporal trends, which will help it forecast how crop diseases will evolve[44].
Long Short-Term Memory (LSTM) networks: A subset of RNNs known as long short-term memories (LSTMs) excel in extracting causal relationships from time series data. Because tracking the development of a disease is so important in agricultural disease management, LSTMs are ideal for modeling trends that span a lengthy period of time. Predictions made utilizing this architecture, which makes use of LSTMs, are more accurate, especially when dealing with long-term changes in crop health[45].
Using pre-trained models on large datasets for tasks particular to crops is known as transfer learning. Here, architectural decisions include things like how much fine-tuning to do and which pre-trained models to use. When there is a lack of labeled data on agricultural diseases and pests, this approach helps the model generalize better, which is very useful. In agricultural settings, the decision support system's effectiveness is greatly affected by how well pretrained models are chosen and adjusted[46].
-
4.2. RQ2: How Do Various Data-related Factors, Such as the Type, Quality, and Availability of input Data Sources, Impact the Performance and Generalizability of Deep Learning Models in the Context of Crop Diseases and Pest Management Decision Support?
When it comes to decision support systems for pest and agricultural disease management, many data-related issues significantly impact how well deep learning models perform and how generalizable they are. First, the effectiveness of the model is greatly affected by the kind of data sources used as input. Models with robust image processing capabilities, such as Convolutional Neural Networks (CNNs), are necessary for the frequent use of image datasets that capture visual signs of crop illnesses and insect infestations. Long Short-Term Memory (LSTM) networks and Recurrent Neural Networks (RNNs) are models that excel at managing sequential information; they are particularly useful for dealing with temporal data, such as weather records and patterns of crop development[47].
To make reliable forecasts, high-quality input data is required. To train models efficiently, high-quality datasets that are well-labeled are needed. Decision support systems run the risk of being misled by models with poor performance due to noisy or incorrect labeling. Improving data quality and making sure models can generalize effectively across multiple settings are common goals of data preparation methods like augmentation and normalization. Incorporating varied data sources, such as hyperspectral or satellite imaging, may enhance the model's capacity to detect and control pests and diseases in crops by providing a more holistic view of the agricultural environment[48]. In general, deep learning models can only be trained using large datasets. This is especially true for complicated tasks like disease diagnosis. One way to estimate how many parameters a CNN layer has is by using the following formula;
Number of Parameters = ( n jiiter x d /uter x w /uter x h /uter ) + n iter (8)
In this context, n filter represents the number of filters, d filter the depth, w filter the width, and hfilter the height of each filter. To successfully train models with many parameters, more data is required.
Table 4. Data related factor
|
Data-Related Factor |
Impact on Deep Learning Models |
References |
|
Type of Input Data Sources |
- Image data requires models with strong image processing capabilities (e.g., CNNs). |
[50] |
|
- Temporal data demands models handling sequential information (e.g., RNNs, LSTMs). |
[51] |
|
|
- Diverse data sources (e.g., satellite imagery, hyperspectral data) enhance model understanding. |
[52] |
|
|
Quality of Input Data |
- High-quality, well-labeled datasets are essential for effective model training. |
[53] |
|
- Noisy or inaccurate labels can lead to suboptimal model performance. |
[54] |
|
|
- Data preprocessing techniques (e.g., normalization, augmentation) improve quality. |
[55] |
|
|
Availability of Labeled Data |
- Limited labeled data can lead to overfitting, impacting model generalization. |
[56] |
|
- Transfer learning with pre-trained models on larger datasets addresses data scarcity. |
[57] |
|
|
- Ensuring diverse datasets aids in capturing a broad range of agricultural scenarios. |
[58] |
|
|
Spatial and Temporal Distribution |
- Models need to adapt to varying conditions across regions and seasons. |
[59] |
|
- Incorporating diverse datasets from different locations improves model robustness. |
[60] |
|
|
- Training on one region or timeframe may limit generalization to others. |
[61] |
A key component impacting the generalizability of models is the accessibility of labeled data. It might be difficult to get labeled datasets for particular pests or illnesses in many agricultural contexts. When data is scarce, overfitting may occur, causing the model to learn from its mistakes and fail to recognize patterns in the real world. In these cases, methods like transfer learning, which make use of previously trained models on bigger datasets, come in handy since they enable the model to generalize better to new, unknown instances by transferring information from similar tasks.
Another factor to think about is the data's geographical and temporal distribution. Models need to be flexible enough to account for environmental elements that vary between areas and seasons in terms of agricultural conditions. Models that are trained using data from a certain area or timeframe may not be able to apply their knowledge to different contexts. To overcome this problem and make sure the model works in multiple agricultural settings, it is necessary to include datasets from different places and historical periods.
In conclusion, decision support systems for crop diseases and pest control rely heavily on the performance and generalizability of deep learning models, which are in turn affected by the kind, quality, and availability of input data sources. To create reliable models that can handle the intricacies of agricultural settings, it is crucial to have datasets that are varied, high-quality, and well-labeled. Additionally, it is important to strategically apply suitable model architectures and data pretreatment approaches[49].
Many parameters about data have a significant impact on how well and how broadly deep learning models perform in decision support for pest control and crop diseases. One must choose a model architecture based on the kind of input data sources. It is common practice to use Convolutional Neural Networks (CNNs) to analyze image data to detect visual symptoms. Models that can handle sequential information, such as Recurrent Neural Networks (RNNs) or Long Short-Term Memory networks (LSTMs), are required for temporal data, which includes weather records and patterns of crop development. Satellite imagery and hyperspectral data are examples of varied data sources that may be used to enhance the model's comprehension and create a more complete decision support system. For model training to be successful, the input data must be of high quality. To provide accurate predictions, it is vital to have high-quality datasets that are well-labeled. Model performance may be severely hindered by data that has erroneous or noisy labels. To fix this, data preparation methods like augmentation and normalization are used to improve the input data quality and provide better model results.
A model's capacity to be applied to new situations is affected by the accessibility of labeled data. Overfitting, in which the model learns to recall individual instances instead of catching broader trends, is a real possibility when labeled data is scarce. To overcome data scarcity, transfer learning which involves training pre-trained models on bigger datasets becomes critical. This technique enables the model to generalize better by transferring information from comparable tasks. Another way to make sure the model is strong is to use varied datasets that show different kinds of agricultural situations.
Considerations of distribution in space and time are crucial in agricultural settings. There is a requirement for models to be able to adjust to regional and seasonal variations. The model's ability to generalize is enhanced by including varied datasets from various regions, which increases its resilience. On the other side, decision support for crop diseases and pest management relies heavily on broad and extensive training datasets, since models trained on data from a single location or period may not be able to generalize to other situations[62].
-
4.3. RQ3: What are the Key Challenges and Limitations Associated with the Application of Deep Learning Models in Crop Diseases and Pest Management Decision Support, and What Strategies or Advancements Have been Proposed to Address these Challenges and Enhance the Practical Utility of Such Systems in Agricultural Contexts?
The decision support systems for pest management and crop diseases face several limitations and challenges when utilizing deep learning models. The need for massive volumes of labeled data to effectively train models is one major obstacle. It may be costly, laborious, and time-consuming to get labeled datasets for different insect infestations and agricultural diseases. Furthermore, there is a possibility of biases and inaccurate predictions from models due to differences in the consistency and quality of labeled data. In addition, resource-constrained agricultural settings may find it challenging to implement deep learning models, particularly those with complicated architectures such as CNNs and LSTMs, due to the high computing resources required for training and inference. As a result, end-users and stakeholders in agricultural settings have a hard time trusting and adopting deep learning models due to concerns about the interpretability of these models. Complex models may provide correct forecasts, but they don't tell us much about what's driving those predictions.
Several approaches and developments have been suggested to overcome these obstacles and improve the practical use of deep learning models in decision support for pest control and crop diseases. To begin, using pre-trained models on large-scale datasets is a great way to address the data scarcity problem, and here is where transfer learning comes in. Less labeled data is needed for efficient training thanks to transfer learning, which enables models to transfer expertise from related tasks to the target domain. Furthermore, data augmentation methods like scaling, flipping, and rotation may artificially expand training datasets in terms of size and variety, which in turn improves the generalizability and resilience of models. Further decreasing reliance on completely labeled datasets and minimizing annotation costs, developments in semi-supervised and weakly supervised learning algorithms have made it possible to use partly labeled or noisy data.
The creation of deep learning models that are both easy to understand and use in agriculture is another area of emphasis. Reducing computing needs while retaining adequate performance levels is achieved via simplified architectures and model compression approaches. In addition, stakeholders and end-users gain confidence in deep learning models when they can see how the models make decisions thanks to attention mechanisms and feature visualization approaches, which improve model interpretability. To aid in crop management decision support, deep learning models must be interpretable so that stakeholders like farmers and agricultural specialists can comprehend the reasoning behind the models' forecasts and suggestions. Methods like feature importance analysis can make models more interpretable by revealing which input factors (such as weather or crop conditions) have the greatest impact on disease or pest infestation predictions. One may also utilize visualization techniques like attention processes or saliency maps to find out where the model looked in a picture (such as the regions of leaves) while making a diagnosis of a crop diseases.
To establish credibility and responsibility in decision support systems powered by artificial intelligence, interpretability is crucial. To increase the likelihood of adoption, farmers and agricultural decision-makers need to comprehend the logic behind the AI's judgments. This will enable them to integrate the AI's insights with their domain expertise. For instance, farmers may take more focused steps, such as altering pesticide application or changing planting techniques, if they know the environmental or agricultural parameters that lead to a model predicting a pest breakout. Better AI for crop health and sustainability management is possible with interpretability, which also helps with mistake diagnosis in models and decision alignment with agronomic techniques. To further guarantee that deep learning solutions are applicable and relevant to real-world agricultural problems, expert views and domain knowledge are included in model validation and development procedures. Lastly, efforts to bring together researchers, agricultural practitioners, and tech developers can help find solutions that work in real-world agricultural settings. This can lead to more people using decision support systems based on deep learning to deal with pests and diseases in crops. Better and better long-term crop management is possible with the help of these tactics and innovations that overcome the drawbacks of deep learning models used for agricultural decision support[63].
Table 5. Challenges and limitations associated with the application of deep learning models
|
Challenges and Limitations |
Strategies and Advancements |
References |
|
Data Scarcity and Quality |
- Transfer learning- Leveraging pre-trained models on large-scale datasets to mitigate data scarcity. |
[64] |
|
- Data augmentation- Increasing the size and diversity of training datasets through augmentation techniques. |
[65] |
|
|
- Semi-supervised learning-Utilizing partially labeled or noisy data to reduce dependency on fully labeled datasets. |
[66] |
|
|
Computational Resources |
- Model compression-Developing lightweight architectures and compression techniques to reduce computational requirements. |
[67] |
|
- Cloud computing-Leveraging cloud-based resources for distributed training and inference. |
[68] |
|
|
Interpretability and Trust |
- Model interpretability-Integrating attention mechanisms and feature visualization techniques to enhance model transparency. |
[69] |
|
- Domain knowledge integration-Incorporating expert insights and domainspecific knowledge into model development processes. |
[70] |
|
|
Applicability to Agricultural Contexts |
- Tailored model development-Co-creation of solutions with agricultural practitioners to address specific needs and constraints. |
[71] |
|
- Collaborative initiatives-Engaging stakeholders in the development and validation of deep learning-based decision support systems. |
[72] |
Due to data scarcity and unpredictability in data quality, it might be tough to gather sufficient volumes of labeled data for successful training of deep learning models in crop diseases and pest control. Data augmentation methods broaden training dataset variety, while strategies like transfer learning use pre-trained models on large-scale datasets to alleviate data shortage. Improved model resilience and less reliance on completely labeled datasets are two additional benefits of semi-supervised learning approaches. These methods also make it possible to use data that is partly or severely noisy.
There may be a lack of accessible computing resources in agricultural contexts that are necessary to train and infer deep learning models, especially those with complicated architectures like CNNs and LSTMs. By reducing processing needs, model compression approaches and lightweight architectures help make deep learning models more accessible. In situations with limited resources, deep learning models may be deployed with the help of cloud computing platforms, which provide affordable and scalable solutions for distributed training and inference.
Complex deep learning models may provide correct forecasts but fail to provide insights into the decision-making process, which raises concerns about the interpretability of these algorithms. Transparency into model predictions and the incorporation of attention processes are two strategies that may be used to improve interpretability. Models developed with domain-specific information and expert insights are more trustworthy and well-received by stakeholders and end-users.
The practical effectiveness of deep learning models in agricultural settings relies on their customization to meet particular goals and limits. The specific problems of crop diseases and pest control may be better addressed by joint efforts between academics, farmers, and IT developers. To make sure that deep learning solutions work for actual agricultural issues, stakeholders should be involved in building and testing decision support systems. These developments and approaches will help overcome the problems with deep learning models for agricultural decision support, making them more useful and impactful in the real world.
-
4.4. Deep Learning Model Factors
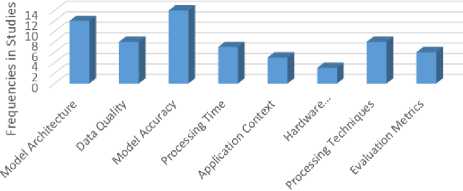
Decision support for crop disease and pest management using deep learning models was shown to be impacted by several important parameters that were discovered in the systematic literature review. Model Accuracy was the most discussed aspect, with several research stressing the need for accurate forecasts for sound decision-making. When investigating which designs provided the highest performance for different agricultural applications, model architecture which includes the usage of CNNs, RNNs, and other structures was also an important point of investigation.
Data Quality was also a major consideration, as several studies have shown that balanced, diversified, and big datasets are necessary for strong model training. Improving the input data quality using preprocessing techniques such as data augmentation and cleaning has a direct influence on the model's efficacy. The models' performance was commonly evaluated using evaluation metrics including recall, precision, and F1-score; nonetheless, arguments over accuracy predominated.
When efficiency was critical for making decisions on agricultural techniques in real-time, several research took processing time into account. Application context, which includes the particular crops or pests that needed to be controlled, had a role in shaping the development and modification of the models. Lastly, research that addressed the processing power required to train and deploy these models did discuss hardware requirements, but other issues were given more emphasis. Taken as a whole, these elements were critical in determining how well and how widely deep learning models were used in agriculture [73].
Factors Influencing Decision Support in Crop Diseases and Pest Management
Factors
Fig.3. Factors influencing decision support in crop diseases and pest management
Fig. 3 shows that much research highlighted the significance of accurate predictions, making model accuracy the most often cited feature in the systematic literature review on deep learning models for decision support in crop disease and pest management. There was also a lot of analysis on model architecture, namely the use of various models such as RNNs and CNNs. Data quality was a major factor; several research have shown that big, well-balanced datasets are necessary for better model performance.
The frequent mention of preprocessing techniques like data augmentation highlights their significance in getting data ready for efficient model training. Despite their relative rarity, evaluation metrics like as recall and precision were deemed essential for gauging the efficacy of the model. Application context and hardware requirements were not as heavily highlighted in efficiency studies, but they were still important factors to consider, particularly when talking about the precise crops or pests that were targeted and the amount of computing power needed. When building deep learning models to control pests and diseases in crops, this study highlights the most important considerations.
4.5. Discussion
5. Conclusions and Future Work
A comprehensive literature review would be incomplete without its discussion section, which provides an interpretation and synthesis of the study findings. The authors' judgments based on the papers they examined are included in this vital portion of the research report. In the discussion section, you may talk about the study's aims or objectives, compare and contrast the findings, find trends and patterns, and explain why some of the studies came to different conclusions.
Several main deep-learning model architectures were discovered in the systematic literature review as being often used in decision support systems for pest and disease control in crops. For image-based applications, Convolutional Neural Networks (CNNs) quickly became the go-to model because of its superior capability to extract hierarchical information from agricultural images. It was shown that CNN accuracy and usefulness were greatly affected by their structure and depth. Deeper networks often captured more complex characteristics, but they were more computationally intensive. Long Short-Term Memory (LSTM) networks and Recurrent Neural Networks (RNNs) were also often used for tasks requiring temporal data, such as tracking the evolution of diseases over time. The model's capacity to faithfully represent sequential dependencies was discovered to be affected by particular architectural decisions, such as the number of layers and dropout rates. To maximize precision and effectiveness in decision support systems for agricultural diseases and pest control, the systematic study emphasizes the significance of meticulously choosing and adjusting deep learning model architectures.
When it comes to decision-support for pest control and agricultural diseases, many data-related aspects affect how well deep learning models work. Common model architectures used were convolutional neural networks (CNNs), recurrent neural networks (RNNs), and long short-term memories (LSTMs), with input data sources ranging from images to time series. It was also determined that input data sources' availability and quality were crucial. Model generalization was hindered by data paucity, but high-quality, well-labeled datasets were crucial for efficient model training. To overcome these obstacles, researchers suggested methods including semi-supervised learning, data augmentation, and transfer learning, which would allow models to use their prior knowledge and make better use of partly labeled or noisy data. It was also noted that the data's regional and temporal distribution affects the model's robustness, highlighting the need for varied datasets that reflect various agricultural situations.
A systematic literature review revealed many major limitations and challenges associated with the use of deep learning models to aid in decision-making regarding crop diseases and pest management. Problems with trust, interpretability, computing resource needs, and data scarcity and quality are among these. Many new approaches and innovations have been suggested to deal with these problems. To overcome data scarcity and computational resource limits, there are methods like as cloud computing, model compression approaches, and transfer learning. Stakeholder trust and acceptability may be improved by making models more interpretable using attention processes and feature visualization approaches. Researchers, agricultural practitioners, and technology developers may work together on collaborative projects to provide customized solutions that tackle particular challenges in agricultural settings. The systematic evaluation concludes that these issues must be resolved if decision support systems based on deep learning are to be more practically useful in the control of agricultural diseases and pests.
This study's systematic literature review sheds light on how decision support systems for pest and disease control in crops make use of deep learning models. The researcher observed that the key deep learning model architectures deployed in this sector are Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Long Short-Term Memory Networks (LSTMs). This addresses Research Question 1 (RQ1). Factors that significantly affect the accuracy and usefulness of these models include the architectural decisions made within them, including the depth, layer configurations, and dropout rates. Review findings for Research Question 2 (RQ2) stress the importance of data-related aspects in shaping deep learning model performance and generalizability, such as input data source type, quality, and availability. There were suggestions for strategies to address data scarcity and enhance model resilience, including transfer learning, data augmentation, and semi-supervised learning. As a conclusion to Research Question 3 (RQ3), the review highlighted some important limitations and challenges related to using deep learning models to support decisionmaking in crop diseases and pest management. These include issues with data scarcity, computational resource requirements, interpretability, and trust. To overcome these obstacles and make these systems more useful in agricultural settings, researchers suggested strategies and innovations which include collaborative efforts, model compression approaches, and transfer learning. The researcher recommends further studies that might help farmers use deep learning to better predict and prevent crop diseases and pest infestations. To begin, scientists should make the collection of high-quality datasets that include a variety of crops, pests, and environments a top priority. Because of this, biases would be lessened and models' applicability to different agricultural settings would be enhanced. To further improve the models' interpretability and guarantee that projections are in line with actual agricultural practices, agronomists' domain expertise should be included in model development. Second, to enhance the efficacy and precision of decision-making, it is necessary to investigate and use hybrid models that integrate deep learning with additional methods, including reinforcement learning or conventional machine learning strategies. To further assist farmers in comprehending and relying on AI-driven suggestions, researchers need to concentrate on creating explainable AI frameworks that render model outputs visible. Collaborative agricultural networks rely on farmers' data privacy, hence it's important to investigate federated learning further so that decentralized model training is possible. Finally, to guarantee the models' practical usefulness, future research should emphasize field testing and validation in various agricultural contexts. Part of this process involves developing defined assessment measures for comparing model performance and building benchmark datasets for agricultural pest and disease control. To improve crop health management and production, researchers should follow these guidelines and help bring deep learning technologies into sustainable agriculture. Ultimately, this systematic literature review highlights the significance of meticulously choosing and fine-tuning deep learning model architectures, taking into account multiple data-related factors, and tackling critical obstacles to enhance the efficacy and practicality of decision support systems for pest and disease management in crops. If researchers want to make deep learning-based techniques more useful in agriculture and overcome their current limitations, the researcher needs to keep researching and working together with agricultural practitioners and technology developers. These systems have the power to impact global food security and sustainability by using deep learning improvements and incorporating domain knowledge to transform crop management techniques.
