Delta Берроуза для древнегреческих авторов: опыт применения

Автор: Алиева Ольга Валерьевна
Журнал: Schole. Философское антиковедение и классическая традиция @classics-nsu-schole
Рубрика: Статьи
Статья в выпуске: 2 т.16, 2022 года.
Бесплатный доступ
В этой статье предпринята попытка эмпирически оценить эффективность метода измерения стилистической разницы, известного как Delta Берроуза, на материале древнегреческого корпуса. Эксперимент с корпусом из четырнадцати (и затем восьми) авторов подтвердил общую эффективность метода. Даже на небольших выборках в 1000–5000 слов решения Delta по большей части корректны, а ее ошибки связаны в основном с текстами, близкими в жанровом отношении. Именно жанровое сходство в обучающей выборке, а не количество слов или длина отрывка, оказывает наибольшее влияние на результат классификации. В спорных случаях, особенно если нет возможности использовать отрывки большей длины (10 000 слов и больше), составление шорт-листов предпочтительнее, чем назначение единственного кандидата. Подобные шорт-листы дают адекватное представление о ближайших стилистических соседях испытуемого текста, оставляя свободу исследователю в интерпретации результатов.
Delta, стилометрия, частотные слова, количественные методы, машинное обучение
Короткий адрес: https://sciup.org/147237658
IDR: 147237658 | DOI: 10.25205/1995-4328-2022-16-2-693-705
Testing Burrows' Delta on Ancient Greek Authors
This paper tests the effectiveness of Burrow’s Delta Method on a corpus of selected prose writings in ancient Greek. When tested on a corpus of fourteen and eight authors, the method yields good results with relatively small samples (1000, 3000, and 5000 words) and different word frequency vectors (100, 200, 500 words), but its performance is worse with texts of similar genres (oratory, historical or medical writings). We conclude that it is the generic proximity that influences the results of classification most. However, in cases where confusion is more likely, such as the writings of Demosthenes and Aeschines, the method proves effective for shortlisting potential authors. Shortlists can give an adequate idea of a sample’s nearest neighbors while leaving some freedom for the researcher in interpreting the results.
Текст научной статьи Delta Берроуза для древнегреческих авторов: опыт применения
Постановка проблемы
В этой статье предпринята попытка эмпирически оценить эффективность метода измерения стилистической разницы, известного как Delta Берроуза,2 на материале древнегреческого корпуса. Хотя метод подтвердил свою эффективность в многочисленных исследованиях,3 испытаний для греческих авторов проводилось не так много,4 так что остается открытым ряд вопросов, ответ на которые необходим для дальнейшего применения метода в ис-
следовательской работе. Эти вопросы касаются, в частности, оптимального количества наиболее частотных слов (далее mfw), минимальной длины отрывка, а также использования слов (лексем) или словоформ для анализа. Кроме того, нас интересует эффективность классической Delta применительно к текстам разных эпох, диалектов и жанров (только прозаических).
Прежде всего следует пояснить статистический смысл метода.5 Суть его заключается в том, что для корпуса текстов рассчитывается частотность ряда показателей; это могут быть слова (словоформы) или так называемые n-граммы, то есть последовательности n символов подряд. Для сравнения берутся самые частотные слова,6 среди которых будет значительная доля служебных, в наименьшей степени связанных с тематикой текста (предлоги, союзы, частицы и т. п.). Поскольку сравниваемые тексты, как правило, имеют разную длину, в стилометрических исследованиях принято брать для сравнения относительную, а не абсолютную частотность; Берроуз идет еще дальше, предлагая использовать так называемые z-scores, то есть стандартизированные оценки, показывающие разброс значений относительно средних. Z-score вычисляется по формуле:
х — mu где случайная величина x – это значение частотности, mu – математическое ожидание (среднее), а sd – стандартное отклонение. Иными словами, z-score показывает, на сколько стандартных отклонений x отстоит от ожидаемого. Зная z-scores для заданных слов у известных авторов/текстов, можно сравнить их с z-scores спорного текста; искомая дистанция Delta вычисляется как сумма взятых по модулю разниц между z-scores у двух сравниваемых текстов, поделенная на количество слов:
Ав ~ ^ 5j| lzi,A- Zi,B I где i – конкретное слово, n – общее число слов, а A и B – сравниваемые авторы (знак | указывает, что суммируется абсолютное значение разницы). Чем больше дистанция, тем менее вероятно авторство.7
Простота метода позволяет использовать его в традиционных методах обучения без учителя, таких как кластерный анализ, так и с машиннообучаемыми классификаторами, когда для каждого значения предиктора x i имеется значение отклика yi. Это позволяет, имея показатели предикторов, прогнозировать отклик, то есть, в нашем примере, определять наиболее вероятного автора. Количество классов формально не ограничено: мы можем сравнивать спорные тексты (test set) как с двумя, так и с двадцатью кандидатами, которые включаются в обучающую выборку (training set).
Функция size.penalize из пакета Stylo,8 разработанного для программной среды R, позволяет проверить эффективность метода на отрывках разной длины9 при работе с различными машинно-обучаемыми классификаторами, в том числе Delta. Функция извлекает из текста случайные выборки все большей и большей длины и сравнивает их с обучающей выборкой для классификации с применением разного числа mfw; по умолчанию для каждой заданной длины отрывка проводится 100 итераций. На выходе функция возвращает матрицы с указанием количество успешных классификаций для каждой длины отрывка и заданного количества mfw, а также матрицы смешения, позволяющие судить о том, между какими авторами чаще возникала путаница. Именно с ее помощью мы намерены проверить применимость метода к древнегреческому корпусу.
Авторы и тексты
Авторы для обучающей выборки были отобраны таким образом, чтобы представлять различные жанры: научную прозу (Гиппократ, Аретей, Гален), ораторскую прозу (Демосфен, Эсхин, Элий Аристид), историческую прозу (Геродот, Фукидид, Ксенофонт), диалог (Платон, Плутарх, Лукиан). В каждой группе как минимум один текст либо с точки зрения хронологии, либо с точки зрения диалекта удален от соседей. В группе исторической прозы это, например, Геродот: можно предположить, что успех классификации в его случае будет выше, если использовать не слова (приведенные к единому «словарному» виду), а словоформы, отражающие характерные диалектные особенности. К указанным авторам мы добавили, достаточно произвольно, по одной книге Аристотеля и Эпиктета: стиль их настолько своеобычен, что ошибочная атрибуция говорила бы о серьезном изъяне в методологии. Итого 14 кандидатов и 23 текста (некоторые из которых мы далее разделили на части, чтобы на каждого автора приходилось два текста). Ниже приведена латинизированная форма имени и датировка (по Oxford Classical Dictionary), а также идентификатор в каталоге Perseus10 для каждого автора и текста. Для произведений указано также число слов.
Табл. 1. Авторы и тексты
|
Автор |
Текст 1 — число слов |
Текст 2 — число слов |
Всего слов |
|
Aeschines (0026) 397–322 до н.э. |
In Ctesiphontem (003) — 19 171 |
In Timarchum (001) — 13 961 |
33 132 |
|
Aelius Aristides (0284) 117–181 н.э. |
Oratio 23 (023) — 5 331 |
Oratio 45 (045) – 31 045 |
36 376 |
|
Aretaeus (0719) ca. 150–200 н.э. |
De causis et signis acutorum morborum lib. 1 (001) — 9 771 |
De causis et signis acuto-rum morborum lib. 2 (002) — 17 640 |
27 411 |
|
Aristoteles (0086) 384–322 до н.э. |
Ethica Nicomachea (010) —58 040 |
58 040 |
|
|
Demosthenes (0014) 384–322 до н.э. |
De corona (018) — 22 893 |
Philippica 1 (004) — 3 338 |
26 231 |
|
Epictetus (0557) сер. I – нач. II в. н.э. |
Dissertationes (001) — 78 609 |
78 609 |
|
|
Galenus (0057) 129–216 н.э. |
De naturalibus facultatibus (010) — 33 104 |
33 104 |
|
|
Herodotus (0016) V в. до н.э. |
Historiae (001) — 189 489 |
189 489 |
|
|
Hippocrates (0627) V в. до н.э. |
De prisca medicina (001) —5 705 |
De articulis (010) — 21 905 |
27 610 |
|
Lucianus (0062) II в. н.э. |
Dialogi mortuorum (066) —11 885 |
Dialogi deorum (068) — 8 021 |
19 906 |
|
Plato (0059) 429–347 до н.э. |
Charmides (018) — 8 410 |
Theaetetus (006) — 23 803 |
32 213 |
|
Plutarchus (0007) сер. I – нач. II в. н.э. |
De defectu oraculorum (092) — 14 196 |
De E apud Delphos (090) — 5 116 |
19 312 |
|
Thucydides (0003) 460–400(?) до н.э. |
Historiae (001) — 153 260 |
153 260 |
|
|
Xenophon (0032) 430(?)–355(?)до н.э. |
Anabasis (006) 58 307 |
Hellenica (001) — 67 939 |
126 246 |
Все эксперименты проводились с использованием корпуса Diorisis.11 Корпус позволяет извлечь из исходных xml как слова в формате Unicode,12 так и словоформы в формате Betacode. Текст в формате Betacode был очищен от диакритических знаков. Необходимый код и полученные с его помощью текстовые файлы доступны в репозитории автора на GitHub.13 Для чистоты эксперимента большие тексты Геродота, Фукидида, Ксенофонта, Эпиктета и Аристотеля были представлены нормальными выборками в 15 000 слов; где необходимо, таких выборок было сделано две, чтобы каждый автор был представлен в корпусе двумя сочинениями. Также две выборки были сделаны для Галена, который представлен в базе Diorisis лишь одним текстом.
Результаты классификации
Результаты классификации даны в сводном виде на рис. 1 (слова в Unicode) и рис. 2 (словоформы в Betacode без диакритики). Как видно, в обоих случаях Delta сработала достаточно осмысленно: медиана почти везде находится в районе единицы. При этом точность стабильно повышается при увеличении длины отрывка с 1000 до 3000 слов, но дальнейшее увеличение не обязательно приводит к улучшению средних значений (выделено серым в табл. 2), хотя сокращение межквартильного размаха говорит о стабилизации результатов (на диаграмме нижняя и верхняя грань «ящика с усами» соответствует первому и третьему квартилю). Зависимость между количеством mfw и точностью атрибуции носит не такой линейный характер: в некоторых случаях увеличение mfw до 200–500 может привести даже к незначительному ухудшению результата (выделено полужирным в табл. 2).
Рис. 1. Точность классификации в зависимости от количества mfw и длины отрывка (слова, Unicode, 14 авторов)
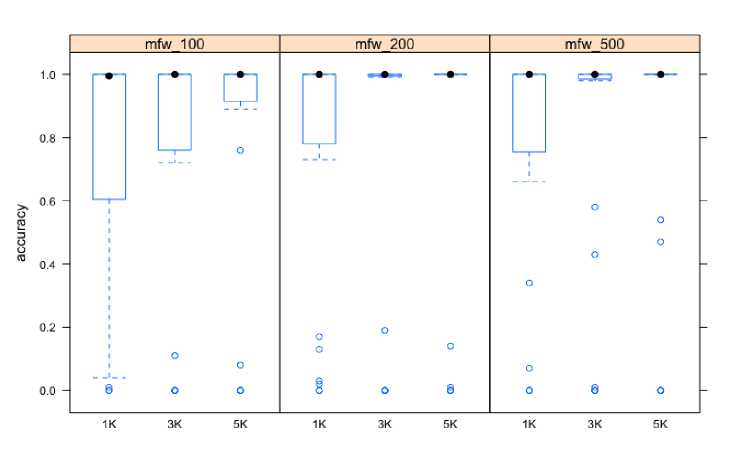
Рис. 2. Точность классификации в зависимости от количества mfw и длины отрывка (словоформы, Betacode без диакритики, 14 авторов)
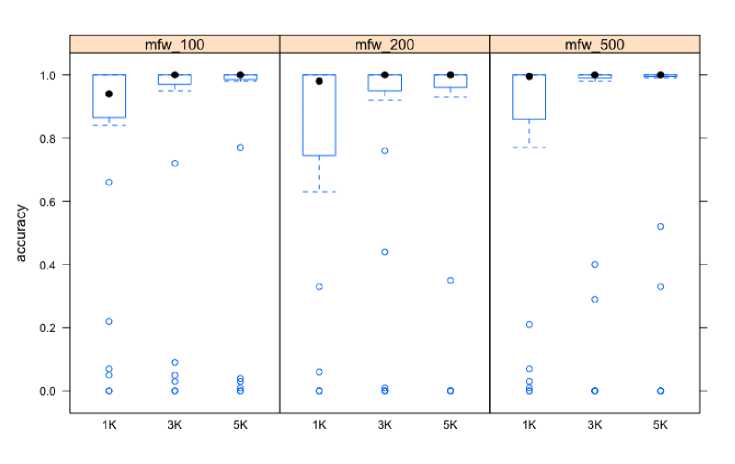
Табл. 2. Средние показатели успешной атрибуции (14 авторов)
|
Unicode (слова) |
Betacode (словоформы) |
|||||
|
1000 |
3000 |
5000 |
1000 |
3000 |
5000 |
|
|
mfw_100 |
0.77 |
0.80 |
0.81 |
0.79 |
0.81 |
0.81 |
|
mfw_200 |
0.78 |
0.79 |
0.79 |
0.79 |
0.83 |
0.83 |
|
mfw_500 |
0.80 |
0.82 |
0.82 |
0.78 |
0.81 |
0.82 |
Средние значения, однако, очень чувствительны к выбросам, то есть к аномальным результатам, представленных на диаграммах кружками. Этих кружки сохраняются и в том случае, если мы используем словоформы в Betacode, что заставляет предположить, что дело не в ошибках лемматизации.
Анализ отклонений
Внимательное изучение «матриц смешения» (confusion matrices), которые возвращает функция size.penalize, говорит о том, что классификатор ошибается в обоих случаях на одной и той же небольшой группе текстов. Путаница происходит между Эсхином, Демосфеном и Аристидом; сочинения Аристида также регулярно приписываются Ксенофонту, Геродоту, Плутарху, Лукиану и даже Галену, что можно объяснить характерной для авторов «второй софистики» подражательностью стиля. Кроме того, классификатор почти не видит разницы между врачами Гиппократом, Аретеем и Галеном, а «Греческая история» Ксенофонта нередко сближается с Фукидидом. Ограничения Delta в этом отношении известны: «различить Хемингуэя и Диккенса всегда будет проще, чем сестер Бронте»14, а Демосфен и Эсхин, несмотря на их политические противоречия, скорее похоже на сестер Бронте.15
За пределами указанной группы число успешных классификаций приближается к 100% на любой длине отрывка и с любым количеством mfw. На рис. 3–4 представлены показатели успеха после удаления из корпуса Эсхина, Аристида, всех врачей и Ксенофонта. Остается 8 авторов, которых Delta определяет почти безошибочно (выбросы теперь не так далеки от медианы и в данном случае связаны с ошибочной классификацией Демосфена, неко- торые выборки из которого приписываются теперь Лукиану и Плутарху). Обратим внимание, что успешными с такой обучающей выборкой оказываются почти все классификации, вне зависимости от количества mfw и длины отрывка. Betacode дает чуть больший размах на небольших отрывках.
Рис. 3. Точность классификации в зависимости от количества mfw и длины отрыв-
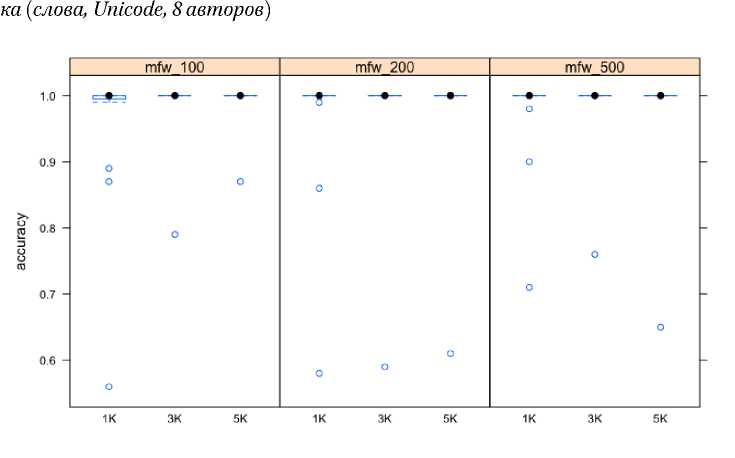
Рис. 4. Точность классификации в зависимости от количества mfw и длины отрыв-
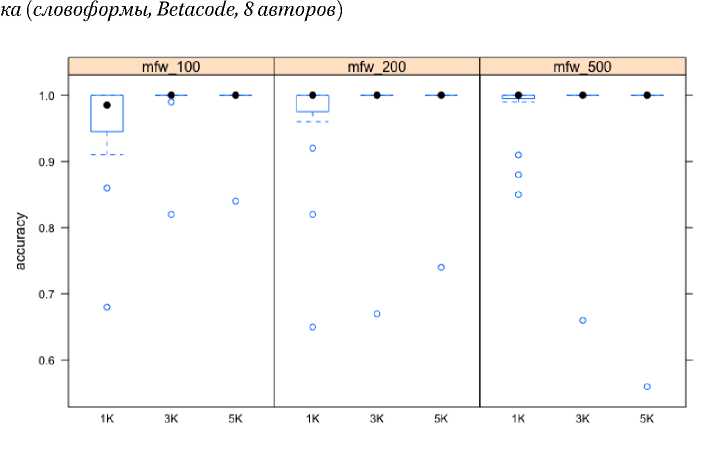
Средние показатели сведены в табл. 3 (серым выделены ряды, в которых увеличение длины отрывка не влечет за собой улучшения точности; полу- жирным начертанием – столбцы, в которых увеличение mfw чуть ухудшает результат).
Табл. 3. Средние показатели успешной атрибуции (8 авторов)
|
Unicode (слова) |
Betacode (словоформы) |
|||||
|
1000 |
3000 |
5000 |
1000 |
3000 |
5000 |
|
|
mfw_100 |
0.96 |
0.99 |
0.99 |
0.95 |
0.99 |
0.99 |
|
mfw_200 |
0.96 |
0.97 |
0.98 |
0.96 |
0.98 |
0.98 |
|
mfw_500 |
0.97 |
0.98 |
0.98 |
0.98 |
0.98 |
0.97 |
Возможные решения
Разумеется, в исследовательской работе мы чаще сталкиваемся с ситуациями, когда выбор кандидатов происходит между похожими и очень похожими авторами, а именно в этом отношении классическая Delta показала не очень высокую эффективность на небольших отрывках.16 Но и когда Delta не в силах с уверенностью определить автора, она способна существенно облегчить работу исследователя, сузив круг возможных претендентов на ав-торство.17 Вместо назначения единственного кандидата мы можем предложить классификатору составить шорт-лист для спорного текста. Техническая возможность для такого решения также есть в пакете Stylo. Выбор финалиста может происходить уже при помощи традиционных методов историко-филологического анализа.18
Попробуем показать, как это работает, на примере Демосфена. При первой классификации (все 14 авторов) матрица смешения для «Первой речи против Филиппа» выглядела так, как показано в табл. 4 (увеличение mfw улучшает точность, но мы намеренно берем худший результат)19:
Табл. 4. Классификация Philippica 1 методом Delta (100 mfw)
|
1000 |
3000 |
5000 |
|
|
Aeschines |
36 |
30 |
27 |
|
Aretaeus |
0 |
0 |
0 |
|
Aristides |
0 |
0 |
0 |
|
Aristotle |
0 |
0 |
0 |
|
Demosthenes |
52 |
69 |
73 |
|
Epictetus |
0 |
0 |
0 |
|
Galen |
0 |
0 |
0 |
|
Herodotus |
0 |
0 |
0 |
|
Hippocrates |
0 |
0 |
0 |
|
Lucian |
11 |
1 |
0 |
|
Plato |
0 |
0 |
0 |
|
Plutarch |
0 |
0 |
0 |
|
Thucydides |
0 |
0 |
0 |
|
Xenophon |
1 |
0 |
0 |
Это значит, что на отрывках в 3000 слов 30 из 100 случайных выборок были приписаны Эсхину и 1 – Лукиану. Теперь попробуем составить шортлист для этой небольшой речи, используя для этого функцию perform.delta. Делать выборки на этот раз не будем: вся речь содержит 3 338 слов, что примерно соответствует выборке выше. «Против Филиппа» на время удалим из корпуса, тем самым усложнив для Delta задачу, а вместо нее добавим «Первую олинфийскую», чтобы Демосфен по-прежнему был представлен двумя текстами. Функция perform.delta требует на входе таблицы с частотностью mfw для обучающей выборки и спорного текста, а возвращает, среди прочего, список наиболее вероятных кандидатов. Длину списка можно задать любую, но следует учитывать состав обучающей выборки: в нашей всего два текста Демосфена, так что третий кандидат неизбежно будет кем-то еще. В табл. 5 для наглядности приведен не только результат классификации, но и показатели расстояния Delta. На первом и втором месте действительный автор речи.
Табл. 5. Классификация Philippica 1 методом Delta (99 mfw; текст 3338 слов)
|
1 |
2 |
3 |
|
|
Кандидаты |
Demosthenes |
Demosthenes |
Aeschines |
|
Delta |
0.7136482 |
0.7988532 |
0.8263089 |
При работе с отрывками в 1000 слов результат (предсказуемо) хуже: в таких объемах частотность слов более подвержена случайным колебаниям. Но и тут Демосфен попадает в шорт-лист из пяти кандидатов во всех отрывках, хотя и не везде лидирует. Заметим мимоходом, что использование евклидовой, а не манхэттенской, метрики, а также так называемой Delta Эде-ра,20 выводит Демосфена в число главных кандидатов. Он также оказывается на первом месте во всех отрывках при использовании 200 mfw. Мы намерено приводим худший результат, чтобы показать, что и в этом предельном случае (небольшой отрывок, немного mfw) действительный автор попадает в шортлист.
Табл. 6. Классификация Philippica 1 методом Delta (99 mfw; выборки 1000 слов)
|
1 |
2 |
3 |
4 |
5 |
|
|
Demosthe-nes_1Phil_1 |
Demosthenes |
Demosthenes |
Aeschines |
Lucian |
Xenophon |
|
Demosthe-nes_1Phil_2 |
Aeschines |
Aeschines |
Xenophon |
Demosthenes |
Demosthenes |
|
Demosthe-nes_1Phil_3 |
Demosthenes |
Demosthenes |
Aeschines |
Aeschines |
Lucian |
Некоторые выводы
Прежде всего можно подтвердить эффективность метода при выборе из множества кандидатов, в том числе с небольшими выборками в 1000–5000 слов: решения Delta по большей части корректны, а ее ошибки связаны в основном с текстами, близкими в жанровом отношении. Именно жанровое сходство в обучающей выборке, а не количество слов или длина отрывка, оказывает наибольшее влияние на результат классификации.
В спорных случаях, особенно если нет возможности использовать отрывки большей длины (10 000 слов и больше), составление шорт-листов предпочтительнее, чем назначение единственного кандидата. Подобные шортлисты дают более полное (и достаточно адекватное) представление о ближайших стилистических соседях испытуемого текста, оставляя свободу исследователю в интерпретации результатов. Существенной разницы между использованием слов в Unicode или словоформ в Betacode мы не зафиксировали.
В заключение оговоримся, что наш эксперимент позволяет делать лишь предварительные выводы: специалист по классической риторике или медицине, каковым автор этой статьи не является, может достичь большего успеха на отрывках другой длины или с другой обучающей выборкой. Последнее представляется особенно важным, поскольку в том же корпусе Де-мосфена21 или Гиппократа немало текстов подложных и спорных, и их попадание в выборку может принципиально влиять на классификацию. Хотя относительно авторства выбранных речей Демосфена нет сомнений, любые пермутации в корпусе могут влиять на результат.22 Что касается Гиппократа, то здесь низкий процент успеха может быть связан с выбором трактата «О древней медицине», относительно авторства которого есть серьезные разногласия.23 Даже если допустить, что трактат написан Гиппократом или в его ближайшем кругу, то в жанровом отношении он отличается от других текстов корпуса своим более риторическим характером, а уже это, как мы имели возможность убедиться, способно сбить с толку классификатора.
Список литературы Delta Берроуза для древнегреческих авторов: опыт применения
- Алиева, О. (2022) “Опыт измерения стилистической однородности методом Delta на материале Платоновского корпуса,” Аристей. Вестник классической филологии и античной истории 25, 19–37.
- Орехов, Б.В. (2020) “Илиада Е.И. Кострова и Илиада А.И. Любжина: стилеметрический аспект,” Аристей. Вестник классической филологии и античной истории 21, 282–296.
- Argamon, Sh. (2008) “Interpreting Burrows’s Delta: Geometric and Probabilistic Foundations,” Literary and Linguistic Computing 23.2, 131–147.
- Burrows, J. (2002) “Delta: A Measure of Stylistic Difference and a Guide to Likely Authorship,” Literary and Linguistic Computing 17.3, 267–287.
- Eder, M. (2011) “Style-Markers in Authorship Attribution: A Cross-Language Study of the Authorial Fingerprint,” Studies in Polish Linguistics 6.1, 99–114.
- Eder, M. (2015a) “Does Size Matter? Authorship Attribution, Small Samples, Big Problem,” Digital Scholarship in the Humanities 30.2, 167–182.
- Eder, M. (2015b) “Taking Stylometry to the Limits: Benchmark Study on 5281 Texts from Patrologia Latina,” Digital Humanities 2015. Sydney. https://dhabstracts.library.cmu.edu/works/2364
- Eder, M. (2017) “Short Samples in Authorship Attribution: A New Approach,” Digital Humanities 2017. Montreal. https://dh2017.adho.org/abstracts/341/341.pdf
- Eder, M., Rybicki, J. (2012) “Do Birds of a Feather Really Flock Together, or How to Choose Training Samples for Authorship Attribution,” Literary and Linguistic Computing 28.2, 229–236.
- Eder, M., Rybicki, J., Kestemont, M. (2016) “Stylometry with R: A Package for Computational Text Analysis,” The R Journal 8.1, 107–121.
- Evert, S., Proisl, Th., Jannidis, F., Reger, I., Pielström, S., Schöch, Ch., Vitt, Th. (2017) “Understanding and Explaining Delta Measures for Authorship Attribution,” Digital Scholarship in the Humanities 32 (Suppl. 2), ii4–ii16.
- Hoover, D. L. (2004a) “Delta Prime?” Literary and Linguistic Computing 19.4, 477–495.
- Hoover, D. L. (2004b) “Testing Burrows’s Delta,” Literary and Linguistic Computing 19.4, 453–475.
- Jannidis, F., Pielström, S., Schöch, Ch., Vitt, Th. (2015) “Improving Burrows’ Delta. An Empirical Evaluation of Text Distance Measures,” Digital Humanities 2015. Sydney.
- Koentges, Th. (2020) “The Un-Platonic Menexenus: A Stylometric Analysis with More Data,” Greek, Roman, and Byzantine Studies 60.2, 211–241.
- Rybicki, J., Eder, M. (2011) “Deeper Delta across Genres and Languages: Do We Really Need the Most Frequent Words?” Literary and Linguistic Computing 26.3, 315–321.
- Savoy, J. (2020) Machine Learning Methods for Stylometry: Authorship Attribution and Author Profiling. Cham.
- Schiefsky, M.J. (2005) Hippocrates: On Ancient Medicine. Leiden / Boston.
- Smith, P. W. H., Aldridge, W. (2011) “Improving Authorship Attribution: Optimizing Burrows’ Delta Method,” Journal of Quantitative Linguistics 18.1, 63–88.
- Thesleff, H. (2009) Platonic Patterns: A Collection of Studies. Las Vegas / Zurich / Athens.
- Trevett, J. (2018) “Authenticity, Composition, Publication,” G. Martin (ed.). The Oxford Handbook of Demosthenes. Oxford, 419–430.
- Vatri, A., McGillivray, B. (2018) “The Diorisis Ancient Greek Corpus: Linguistics and Literature,” Research Data Journal for the Humanities and Social Sciences 3.1, 55–65.
- Vatri, A., McGillivray, B. (2020) “Lemmatization for Ancient Greek: An Experimental Assessment of the State of the Art”, Journal of Greek Linguistics 20.2, 179–196.
