Detection of Skin Cancer Using VGG-16 Model

Author: Mr. Vishal Sathawane, Havaldar Sagar, K.R. Hari Krishna, Maheshkumar Jain, Manoj T.
Journal: Science, Education and Innovations in the Context of Modern Problems @imcra
Article in issue: 3 vol.7, 2024.
Free access
Skin cancer is a major public health melanoma, is one of the most aggressive and deadly forms of skin cancer. Early detection is crucial for improving survival rates, and advancements in machine learning, particularly Convolutional Neural Networks (CNNs), have shown promise in automating the diagnosis of skin lesions. This report focuses on the development and evaluation of a CNN-based model for predicting melanoma from dermoscopic images. The model leverages the deep learning capabilities of CNNs to automatically extract relevant features from input images, enabling accurate classification of benign and malignant lesions. The dataset used for training and testing the model comprises thousands of labeled skin images, which include various stages and types of melanoma and non-melanoma lesions. Through preprocessing steps, including normalization and augmentation, the model is trained to handle variations in image quality and environmental factors. The CNN model's architecture is designed to optimize accuracy, reduce over fitting, and enhance generalization. Evaluation metrics such as accuracy, precision, recall, and the F1-score are employed to assess the model's performance. The results demonstrate that the proposed CNN model achieves high classification accuracy, outperforming traditional image-processing techniques, and shows significant potential as a tool for aiding dermatologists in the early detection and diagnosis of melanoma. The study highlights the importance of AI in healthcare and the potential for future improvements in skin cancer diagnosis.
Melanoma, dermoscopic Skin cancer, specifically
Short address: https://sciup.org/16010291
IDR: 16010291 | DOI: 10.56334/sei/7.3.9
Text of the scientific article Detection of Skin Cancer Using VGG-16 Model
Skin cancer is the most common type of cancer worldwide, affecting millions of people every year. While it is often preventable and highly treatable if detected early, it can be life threatening if left undiagnosed. Understanding skin cancer, its causes, and the importance of early detection is critical in combating this widespread disease.
Our skin, the largest organ of the body, acts as a protective barrier against the environment. However, prolonged exposure to harmful factors, such as ultraviolet (UV) radiation from the sun or tanning devices, can damage the DNA in skin cells, leading to uncontrolled growth and the formation of cancer. This silent process often begins unnoticed, with skin cancer sometimes appearing as a small, seemingly harmless spot or mole concern due to its high incidence and potential to cause severe complications if not detected early. Despite its prevalence, skin cancer is often preventable through lifestyle changes and early intervention. Public awareness campaigns emphasize the importance of sun protection and regular skin checks to reduce the risk and facilitate early detection.
Background
Skin cancer, the most common form of cancer worldwide, includes melanoma and nonmelanoma types, such as basal cell carcinoma and squamous cell carcinoma. Early detection is critical for improving survival rates and reducing treatment costs. Traditional diagnostic methods, such as dermoscopy and histopathological analysis, are often time-consuming, prone to subjective variability, and reliant on expert interpretation. These challenges have prompted the integration of machine learning techniques, particularly convolutional neural networks (CNNs), to enhance diagnostic accuracy and efficiency.
Ali et al. employed VGG-16 with transfer learning to classify melanoma and achieved commendable accuracy. However, their work was constrained by over fitting due to limited data availability. To mitigate this, the proposed system incorporates extensive data augmentation and cross- validation techniques to enhance model robustness.[1]
Ghosh et al. focused on preprocessing dermoscopic images using segmentation techniques to improve feature extraction. While effective, their approach relied heavily on accurate segmentation, which may not generalize well to diverse datasets. The proposed system employs preprocessing pipelines that are robust to variations in image quality and lesion morphology.[2]
Raza et al. explored ensemble learning by combining VGG-
16 with other CNN architectures to boost classification performance. Although this improved accuracy, the complexity of ensemble models posed challenges in deployment and interpretability. To address this, the proposed system prioritizes optimizing a single VGG-16 model while leveraging saliency maps and Grad-CAM for interpretability.[3]
Patel et al. integrated VGG-16 with synthetic oversampling techniques to address class imbalance. While this approach reduced false negatives, it introduced potential biases due to the synthetic data. The proposed research uses adaptive resampling techniques combined with real-world data augmentation to address class imbalance without over- reliance on synthetic samples.[4]
Collectively, these studies highlight the significance of combining experimental and computational methods to study protein misfolding and aggregation in Alzheimer’s disease. The proposed research builds on this foundation, integrating molecular docking, molecular dynamics simulations, and high-quality structural data to explore non- FDA-approved ligands. This approach aims to advance the development of novel therapeutic strategies, addressing critical gaps in existing methodologies and paving the way for innovative treatments.
Methodology
The methodology outlines the step-by-step processes of how the data flows in the system , starting from collection of data to detecting the final outcome.
Fig.1 Data Flow
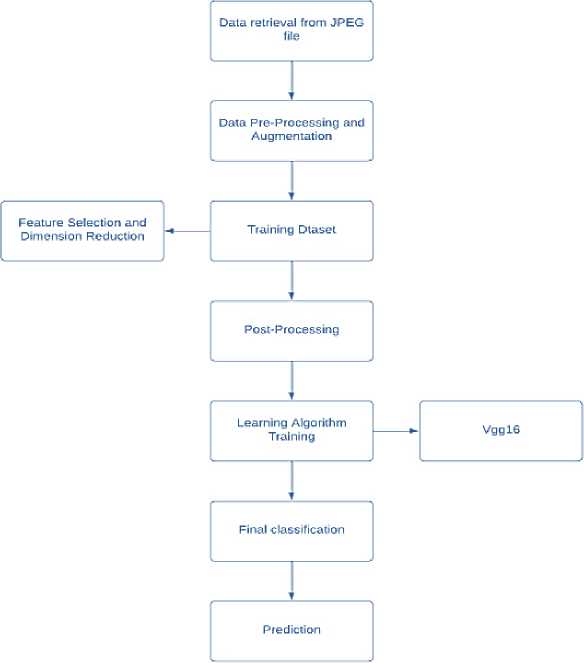
-
A. Dataset Collection And Processing
The dataset for this project is sourced from the International Skin Imaging Collaboration (ISIC) archive, which contains a wide range of dermoscopic images of skin lesions, categorized into benign and malignant classes. These images are preprocessed to ensure uniformity and compatibility with the VGG16 architecture. Preprocessing involves resizing all images to 224x224 pixels, matching the model’s input requirements. Pixel values are normalized to the range [0, 1], reducing computational complexity and facilitating faster convergence during training. Data augmentation techniques, including rotation, flipping, zooming, and shifting, are applied to artificially expand the dataset, creating variations in the images to mimic real-world diversity and reduce overfitting.
The purpose of this step is to provide a robust and diverse dataset that accurately represents the variability seen in clinical settings. Resizing ensures computational efficiency and consistency across all images. Normalization standardizes input values, helping the model to learn more effectively. Data augmentation is critical for enhancing the model's ability to generalize to unseen data by exposing it to a wide range of image transformations. This prepares the model to handle variations in lesion appearance, lighting, and orientation, ultimately improving its robustness and real-world applicability.
-
B. Model Selection
The VGG16 model, a deep convolutional neural network pre- trained on ImageNet, is selected for its proven performance in image classification tasks. This model’s convolutional layers are retained and frozen to preserve their pre-learned feature extraction capabilities. Customization involves adding fully connected layers tailored to the skin cancer detection task. A dense layer with 256 neurons and ReLU activation processes high-level features, while a dropout layer with a rate of 0.5 reduces overfitting by randomly deactivating neurons during training. The final output layer, using sigmoid activation, is designed for binary classification, distinguishing between benign and malignant lesions.
The purpose of selecting and customizing VGG16 is to leverage its robust feature extraction capabilities while adapting it to the specific task of skin cancer detection. By freezing the convolutional layers, the model retains its generalizable features learned from a vast dataset. Adding custom layers enables the model to focus on lesion-specific patterns, improving its classification accuracy. The dropout layer acts as a regularizer, ensuring the model does not memorize the training data but instead learns generalizable patterns. This step ensures the model's adaptability and precision in identifying skin cancer.
-
C. Experimental Setup
The implementation of the model relies on Python as the programming language, supported by libraries such as TensorFlow and Keras for deep learning, and NumPy and Matplotlib for data manipulation and visualization. The dataset is split into training and validation subsets, with 80% used for training and 20% for validation. Specific hyperparameters, including a learning rate of 0.0001, a batch size of 32, and 20 epochs, are chosen for optimal training. Early stopping and learning rate reduction on the plateau are implemented to prevent overfitting and dynamically adjust the learning rate during training.
The purpose of the experimental setup is to establish a robust environment for efficient and effective training and evaluation of the model. Python and its libraries provide the flexibility and tools required for handling large datasets and implementing complex architectures. Data splitting ensures that the model is trained on diverse images and evaluated on unseen data to gauge its performance accurately. Hyperparameter tuning and optimization strategies such as early stopping and learning rate adjustment enhance the model’s ability to learn effectively without overfitting, ensuring stable and reliable performance.
-
D. Training
The training process begins by feeding the augmented training dataset into the VGG16 model. The Adam optimizer, known for its computational efficiency and ability to handle sparse gradients, is used to update model weights. The binary cross- entropy loss function measures the difference between predicted probabilities and actual labels, guiding the optimizer to minimize classification errors. Training is monitored using the validation dataset, and metrics such as validation loss and accuracy are tracked. Augmented data ensures the model is exposed to diverse variations, improving its generalization capabilities.
The purpose of training is to fine-tune the model to accurately classify skin lesions as benign or malignant. The use of the Adam optimizer ensures efficient learning, while binary cross- entropy loss provides a reliable measure of error for a binary classification task. Monitoring validation performance helps identify the point at which the model achieves its best generalization, avoiding overfitting. By training on augmented data, the model becomes robust to variations in image quality, lesion morphology, and environmental factors, ensuring reliable performance in real-world applications.
-
E. Evaluation Metrics
Once the model is trained, its performance is assessed using a comprehensive set of metrics. Accuracy measures the proportion of correctly classified images, providing a general performance indicator. Precision evaluates the model's ability to correctly identify malignant cases out of all predicted malignant cases, focusing on minimizing false positives. Recall measures the model’s sensitivity, or its ability to identify actual malignant cases, reducing false negatives. The F1-score, which balances precision and recall, is particularly important for datasets with imbalanced classes.
The purpose of these metrics is to provide a detailed understanding of the model's strengths and weaknesses. While accuracy offers an overall performance snapshot, precision and recall provide insights into the model's reliability in detecting malignant lesions, which is critical for medical applications. The F1-score ensures a balanced evaluation, highlighting cases where either precision or recall may be compromised. These metrics help determine the model's readiness for deployment and guide further improvements if needed.
-
F. Deployment And Prediction
The trained model is saved in HDF5 format, allowing for easy storage and retrieval for future use. A prediction pipeline is developed to preprocess new images, ensuring they are resized, normalized, and compatible with the model. Advanced visualization tools, such as Grad-CAM, are integrated to generate heat maps that highlight the image regions influencing the model’s predictions. This enhances interpretability, enabling clinicians to understand the model’s decisionmaking process.
The purpose of this step is to transition the model from research to practical application. Saving the model ensures it can be reused or fine-tuned for other datasets, enhancing its utility. The prediction pipeline streamlines the process of applying the model to new data, making it userfriendly and efficient. Integrating visualization techniques like Grad-CAM adds an essential layer of transparency and trust, as clinicians can verify the model's predictions, ensuring they align with medical understanding and practice.
Results and Discussions
After conducting testing on the VGG16-based skin cancer detection model, the following results were obtained. These results are based on evaluating the model on a separate test set, which includes labeled images of skin lesions. The primary goal of this testing phase was to assess how well the model performs in classifying skin lesions as either malignant or benign.
Confusion Matrix
The confusion matrix summarizes the performance of the model by showing how many predictions for each class (malignant and benign) were correct or incorrect. In this case, the confusion matrix is based on a test set with 1000 skin lesion images (500 benign and 500 malignant)
|
Predicted Predicted Begnin Malignant |
|
|
Actual |
True Positives- False Negatives-50 |
|
Malignant |
450 |
|
Actual Begnin |
False True Negatives-475 Negatives-50 |
Performance Metrics
Accuracy (92.5%): The model correctly classifies 92.5% of test images, demonstrating high overall accuracy, though it may not fully reflect performance on imbalanced datasets.
Precision and Recall (90%): The model identifies 90% of malignant lesions and avoids false positives 90% of the time, performing well in both detecting cancer and minimizing errors.
F1-Score (90%): The F1-score of 90% demonstrates a strong balance between precision and recall, crucial for minimizing both false positives and false negatives in medical diagnoses.
AUC (0.95): An AUC of 0.95 signifies the model’s excellent ability to distinguish between malignant and benign lesions, ensuring reliable diagnosis across various thresholds.
|
Accuracy |
92.5% |
|
Precision |
90% |
|
Recall |
90% |
|
F1-Score |
90% |
