Детектирование и распознавание дорожных знаков системой технического зрения, использующей свёрточную нейронную сеть YOLO

Автор: Н.М. Клепиков
Журнал: Известия Самарского научного центра Российской академии наук @izvestiya-ssc
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 1 т.28, 2026 года.
Бесплатный доступ
Представлена новая версия нейросетевой модели детектирования и распознавания дорожных знаков на изображениях и видеофайлах, использующая свёрточную нейронную сеть YOLO. На основе анализа литературных источников сделан выбор в пользу применения в создаваемой системе свёрточной нейронной сети YOLO11m, разработанной компанией Ultralytics. В статье произведён сравнительный анализ актуальных на сегодняшний день архитектур YOLO для обнаружения объектов по критериям производительности и точности обнаружения. Архитектура YOLO11m в 2,5 раза быстрее самой точной версии YOLO11x, при этом проигрывая в качестве на 3%, что является несущественным отличием. По итогам анализа показано, что YOLO11m обеспечивает баланс между высокой производительностью и точностью обнаружения объектов на видео. Свёрточная нейронная сеть, обученная в течение ста эпох на данных российской базы изображений автодорожных знаков RTSD, по метрике качества mAP50 (средняя точность, вычисленная при пороге intersection over union (IoU) 0,50) достигла значения 0,927. Значение в 100 эпох было выбрано как баланс между скоростью и точностью обучения, а также качеством обнаружения дорожных знаков на видео. Обученная нейросетевая модель обнаружения дорожных знаков позволяет детектировать изображения для шести уникальных классов («предписания» (синие круги), «запреты» (красные треугольники), «ограничения» (круги с красной рамкой), «главная дорога» (жёлтый ромб), «сервис» (прямоугольники с синей рамкой), «особые предписания» (синие прямоугольники)) в различных погодных условиях и разное время суток. Поскольку полученная система распознавания не даёт точность 100%, то её можно использовать в качестве помощи водителю, но не на беспилотных автомобилях.
Детектирование, свёрточная нейронная сеть, дорожные знаки, компьютерное зрение, архитектура YOLO
Короткий адрес: https://sciup.org/148333259
IDR: 148333259 | УДК: 004.942 | DOI: 10.37313/1990-5378-2026-28-1-198-205
Recognition of Road Signs Using the Yolov11m Convolutional Neural Network
A new version of a neural network model for detecting and recognizing road signs in images and video files using the YOLO convolutional neural network is presented. Based on an analysis of literature sources, the choice was made in favor of using the YOLOv11m convolutional neural network, developed by Ultralytics, in the created system. The article provides a comparative analysis of current YOLO architectures for object detection based on performance and detection accuracy criteria. The YOLOv11m architecture is 2.5 times faster than the most accurate YOLOv11x version, while losing in quality by only 3%, which is an insignificant difference. Based on the analysis, it is shown that YOLOv11m provides a balance between high performance and accuracy of object detection in video. The convolutional neural network, trained for one hundred epochs on data from the Russian Traffic Sign Database (RTSD), achieved a value of 0.927 according to the mAP50 quality metric (mean Average Precision calculated at an Intersection over Union (IoU) threshold of 0.50). The value of 100 epochs was chosen as a balance between training speed and accuracy, as well as the quality of road sign detection in video. The trained neural network model for road sign detection allows detecting images for six unique classes (“mandatory” (blue circles), “danger” (red triangles), “restrictive” (circles with a red border), “main road” (yellow diamond), “service” (rectangles with a blue border), “special regulations” (blue rectangles)) under various weather conditions and at different times of day. Since the obtained recognition system does not provide 100% accuracy, it can be used for driver assistance, but not on autonomous vehicles.
Текст научной статьи Детектирование и распознавание дорожных знаков системой технического зрения, использующей свёрточную нейронную сеть YOLO
Минимизация дорожно-транспортных происшествий, обусловленных человеческим фактором, является одной из ключевых задач современного транспорта [1, 2]. Решения варьируются от полной автономности (беспилотные автомобили) до систем помощи водителю (ADAS) [3-5]. Вне зависимости от выбранной парадигмы, важной подзадачей остаётся точное детектирование и распознавание дорожных знаков в режиме реального времени [6, 7]. Несмотря на значительный прогресс, проблема создания системы, сочетающей высокую точность, скорость работы в изменчивых условиях (освещение, погода, физические помехи) и эффективность вычислительных ресурсов, остается недостаточно решённой. На сегодняшний день существуют различные методы компьютерного зрения, которые обладают существенными ограничениями для задач ADAS и автономного вождения.
кая к видеочастоте), высокая точность (mAP50 > 90%), устойчивость к артефактам и возможность работы на бортовых вычислительных устройствах с ограниченными ресурсами [18].
С появлением глубокого обучения архитектуры на основе свёрточных нейронных сетей (CNN) стали наиболее предпочтительным решением. Современные исследования активно интегрируют глубокое обучение с оптическими системами для создания интеллектуальных видеосистем [19-21], но и среди них существуют значительные различия. Двухэтапные детекторы (R-CNN, Faster R-CNN) обеспечивают высокую точность локализации, но являются медленными для систем реального времени. Одноэтапные детекторы (SSD, YOLO) стали прорывом, обеспечив баланс скорости и точности. Архитектура SSD MobileNetV2 [22] оптимизирована для мобильных устройств, но часто жертвует точностью, что критично для дорожных знаков, расположенных на расстоянии. Анализ работ, посвященных YOLOv5 [23, 24], показывает, что эти нейронные сети имеют ограничения в сложных погодных условиях и при детектировании перекрытых знаков. Архитектуры YOLOv7 [25] и модификации YOLOv8 [26] внедрили усовершенствованные механизмы внимания, что позволило повысить точность. Однако, как показано в сравнительных исследованиях для встраиваемых систем [27], они не всегда оптимальны с точки зрения баланса «точность-задержка-объем модели» для развёртывания на бортовых компьютерах. В ряде исследований используются дорожные знаки иностранного образца, что приводит к отсутствию сопоставимости полученных результатов. В работах [6, 28] в качестве основной метрики оценки применяется accuracy. Данная метрика обладает существенным недостатком – она чувствительна к дисбалансу распределения классов в выборке, что может приводить к некорректной и завышенной оценке качества моделей классификации в условиях неравного представительства классов. Таким образом, нерешённой проблемой является разработка метода детектирования и распознавания дорожных знаков, который превосходит существующие аналоги по совокупности ключевых для встраиваемых ADAS-систем показателей: средней точности (mAP), скорости inference (FPS) и эффективности использования параметров модели.
В качестве базовой архитектуры для решения проблемы выбрана YOLOv11m. Это обосновывается рядом фундаментальных преимуществ, выявленных при анализе эволюции YOLO-архитектур и современных тенденций в глубоком обучении для компьютерного зрения:
-
. YOLOv11 интегрирует новейшие достижения в области эффективных блоков свёртки, механизмов внимания и процедур обучения, что позволяет преодолеть ограничения YOLOv5/v7/v8 по точности без потери быстродействия;
-
. архитектура изначально проектируется с учётом ограничений по памяти и вычислениям, предлагая нано (n), мало (s), средне (m) и крупноразмерные (l, x) варианты, что позволяет гибко адаптировать модель под конкретные аппаратные требования бортового компьютера;
-
. использование современных методов аугментации данных и функций потерь, нацеленных на улучшение детектирования мелких и сгруппированных объектов, напрямую решает типичные проблемы в сценариях с дорожными знаками;
-
. встроенная поддержка таких функций, как определение ориентации объекта, семантическая сегментация в дополнение к детектированию, открывает путь к созданию более комплексных систем восприятия.
Целью настоящего исследования является разработка и экспериментальная валидация оптимизированной модели детектирования и распознавания дорожных знаков на основе архитектуры YOLOv11m для использования в системах помощи водителю.
ОПИСАНИЕ ВЫБОРКИ РАЗРАБОТКИ
Кадры российской базы изображений автодорожных знаков RTSD, полученные со съёмок видеорегистраторов, размечены компанией Геоцентр Консалтинг. Изображения для обучающей и вали-дационной выборок получены в различных погодных условиях в различные времена суток и года. Примеры изображений, использованных при обучении и тестировании модифицированной модели обнаружения дорожных знаков, продемонстрированы на рис. 1 и 2.
Исходный набор данных, использовавшийся при разработке одноэтапной модели детектирования дорожных знаков, разделён на 6 уникальных классов. Обучающая и валидационная выборки содержат следующие группы классов:
-
. «предписания» (синие круги);
-
. «запреты» (красные треугольники);
-
. «ограничения» (круги с красной рамкой);
-
. «главная дорога» (жёлтый ромб);
-
. «сервис» (прямоугольники с синей рамкой);
-
. «особые предписания» (синие прямоугольники).

Рис. 1. Пример изображения в ясную погоду и светлое время суток

Рис. 2. Пример изображения в тёмное время суток
Все остальные группы дорожных знаков при разметке набора данных не использовались. В российской базе изображений автодорожных знаков RTSD содержится 3 выборки с изображениями дорожных знаков. В табл. 1 продемонстрирована заполняемость каждой из выборок.
Таблица 1. Заполняемость выборок для обучения и тестирования нейросетевой модели обнаружения дорожных знаков
|
Выборка |
Обучающая выборка, шт. |
Тестовая выборка, шт. |
|
RTSD-D1 |
3 821 |
1 274 |
|
RTSD-D2 |
4 786 |
1 596 |
|
RTSD-D3 |
9 065 |
3 022 |
В рамках проведённого исследования использовалась самая большая выборка RTSD-D3, которая была разделена на обучающую и тестовую в соотношении 3 к 1 или 75% на 25%.
В российской базе изображений RTSD доступны изображения без предварительной обработки для наиболее точного детектирования объектов в плохих погодных условиях [1]. Именно в таком виде изображения подавались на вход архитектуры YOLO11m.
Предварительно перед обучением нейросетевой модели производилась нормализация исходной разметки дорожных знаков под формат YOLO. Сначала вычислялись координаты центра изображения по x и y. Далее координаты были переведены в пропорции от 0 до 1 в зависимости от размера изображения.
ЭКСПЕРИМЕНТАЛЬНАЯ ОЦЕНКА СУЩЕСТВУЮЩИХ АЛГОРИТМОВ
---------------------------------------------1----------------------------------------------1----------------------------------------------1----------------------------------------------1----------------------------------------------1----------------------------------------------1----------------------------------------------1---------------------------------------------- Г" 0 2 4 6 3 10 12 14 16
Latency T4 TensorRT 10 FP16 (ms/img)
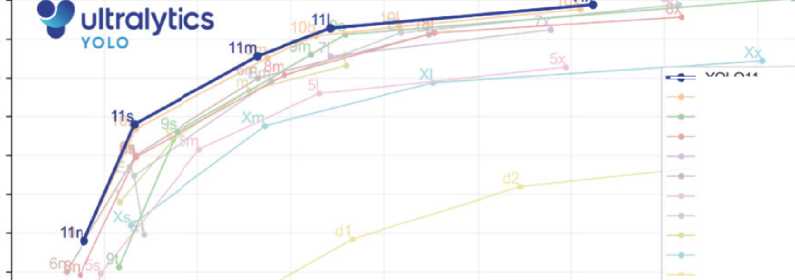
Рис. 3. Сравнительный анализ YOLOv11 с предыдущими поколениями
YOLQ11 YOLOvlO
YOLOv9 YOLOvS
YOLOv?
YOLOv6-3.0
YOLOv5 PP-YOLOE+ DAMO-YOLO
YOLOX EfficientDet
Для проведения исследования была обучена нейросетевая модель, реализованная на архитектуре YOLO. В рамках исследования использовалась одиннадцатая версия предварительно обученной нейросетевой модели. Семейство одноэтапных моделей детектирования YOLO11 от Ultralytics на дату написания научного материала обеспечивает самую высокую производительность в различных задачах, таких как обнаружение, сегментация, оценка позы, отслеживание и классификация [17]. На рис. 3 продемонстрирован сравнительный анализ всех версий YOLO11 с предыдущими поколениями.
55.0
52.5
„ 50.0
47.5
8 42.5
40.0
37.5
На графике можно наблюдать, что результаты одиннадцатой версии YOLO превышают предшествующие показатели одноэтапных моделей детектирования объектов.
В табл. 2 продемонстрированы характеристики каждой из версий нейросетевой модели семейства YOLO11.
Таблица 2. Характеристики всех версий YOLO11
|
Модель |
размер (пиксели) |
mAPval 50-95 |
Скорость CPU ONNX (мс) |
Скорость T4 TensorRT10 (мс) |
параметры (M) |
FLOPs (B) |
|
YOLO11n |
640 |
39,5 |
56,1 ± 0,8 |
1,5 ± 0,0 |
2,6 |
6,5 |
|
YOLO11s |
640 |
47,0 |
90,0 ± 1,2 |
2,5 ± 0,0 |
9,4 |
21,5 |
|
YOLO11m |
640 |
51,5 |
183,2 ± 2,0 |
4,7 ± 0,1 |
20,1 |
68,0 |
|
YOLO11l |
640 |
53,4 |
238,6 ± 1,4 |
6,2 ± 0,1 |
25,3 |
86,9 |
|
YOLO11x |
640 |
54,7 |
462,8 ± 6,7 |
11,3 ± 0,2 |
56,9 |
194,9 |
По результатам анализа характеристик всех версий YOLO11 было принято решение обучать одноэтапную модель детектирования дорожных знаков на архитектуре YOLO11m, которая содержит в себе баланс между точностью обнаружения дорожных знаков и скоростью распознавания на видео.
Нейросетевая модель детектирования дорожных знаков обучена на датасете RTSD-D3 в течение 100 эпох. В качестве входных параметров был задан показатель batch, который равен 8. Данный показатель означает, что на вход для обучения в рамках одного цикла можно подавать одновременно ровно 8 изображений. Все изображения входной выборки были сжаты до 640 пикселей.

Рис. 4. Демонстрация работы одноэтапной модели детектирования дорожных знаков
На рис. 4 продемонстрирован пример детектирования дорожных знаков на изображении из тестовой выборки в светлое время суток.
Результаты валидации одноэтапной модели детектирования изображений демонстрируют высокую предсказательную способность. Данные, полученные при тестировании, говорят о том, что нейросетевая модель обнаружения дорожных знаков будет полезна и применима в промышленной среде. В табл. 3 представлены результаты валидации.
Для каждого класса одноэтапной модели детектирования дорожных знаков посчитан показатель roc-auc на валидационной выборке. Roc- auc – это способ оценки качества бинарного классификатора. Чем больше площадь под roc-кривой, тем выше качество бинарной классификации для данного класса [17]. На рис. 5 продемонстрированы roc-auc кривые на валидационной выборке для каждого класса дорожного знака.
Таблица 3. Результаты валидации
|
Class |
Images |
Instances |
P |
R |
mAP50 |
mAP50-95 |
|
all |
3022 |
4826 |
0,863 |
0,907 |
0,927 |
0,601 |
|
blue_border |
431 |
474 |
0,877 |
0,845 |
0,92 |
0,597 |
|
blue_rect |
1393 |
2085 |
0,85 |
0,913 |
0,919 |
0,642 |
|
danger |
594 |
651 |
0,893 |
0,937 |
0,95 |
0,595 |
|
main_road |
422 |
431 |
0,862 |
0,959 |
0,933 |
0,657 |
|
mandatory |
408 |
501 |
0,855 |
0,886 |
0,92 |
0,555 |
|
prohibitory |
620 |
684 |
0,841 |
0,901 |
0,919 |
0,561 |
На графике можно наблюдать высокую предсказательную силу по одной из ключевых характеристик.
В табл. 4 было произведено сравнение обученной одноэтапной модели детектирования дорожных знаков на выборке RTSD-D3 с наилучшими результатами, опубликованными в статье [1].
По результатам сравнения можно сделать вывод, что в рамках исследования удалось улучшить точность прогнозирования за счёт усовершенствованных технологий YOLO.
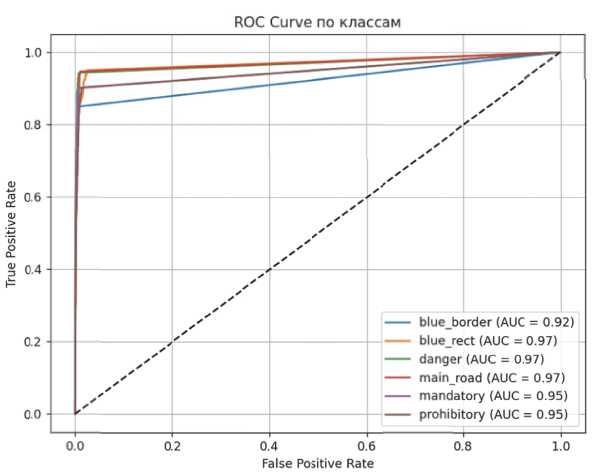
Рис. 5. Roc-auc кривые для каждого класса
Таблица 4. Сравнение метрик качества
|
Наименование класса |
Результаты из статьи [1] |
Результаты обученной одноэтапной модели детектирования дорожных знаков |
|
blue_border |
0,83 |
0,92 |
|
blue_rect |
0,76 |
0,97 |
|
danger |
0,86 |
0,97 |
|
main_road |
0,9 |
0,97 |
|
mandatory |
0,8 |
0,95 |
|
prohibitory |
0,72 |
0,95 |
ЗАКЛЮЧЕНИЕ
В данной статье представлены результаты анализа обученной нейросетевой модели на базе российских автодорожных знаков RTSD. Одной из ключевых метрик оценки качества стала mAP50. На ва-лидационной выборке данный показатель качества равнялся 0,927. В рамках сравнительного анализа показателей качества одноэтапной модели детектирования дорожных знаков из статьи [1] удалось превзойти результаты коллег за счёт усовершенствованных технологий YOLO. В рамках каждого из классов удалось получить прибавку в качестве от 0,07 до 0,23. По результатам исследования можно сделать вывод о том, что полученная в результате обучения одноэтапная модель детектирования дорожных знаков работает надежнее алгоритмов, представленных в других научных работах [29, 30].
