Development of a Phishing Website Detection Model Using Classification Algorithm

Author: Olugbenga A. Madamidola, Ilobekemen. P. Oladoja, Peace B. Falola, Matthew W. Omojola
Journal: International Journal of Wireless and Microwave Technologies @ijwmt
Article in issue: 5 Vol.14, 2024.
Free access
In the contemporary digital landscape, the proliferation of malware presents a significant threat to the security and integrity of computer systems and networks. Traditional signature-based detection methods are increasingly ineffective against the evolving landscape of sophisticated malware variants. Consequently, there is a pressing need for innovative approaches to malware detection that can adapt to emerging threats in real-time. This research aims to develop a malware detection system using machine learning algorithms. Random Forest classifier and Logistic regression were deployed for the classification of malware based on the features extracted from the CIC-MalMem-2022 dataset. The Malware detection system model was implemented using the Python programming language and evaluated using major performance metrics like F1-score, precision, recall, and accuracy to assess the model’s performance. A comparison between the logistic regression model and the random forest model showed that the Random Forest model approach performed better than the logistic model in detecting malware, achieving accuracies of 98% and 94% respectively. In summary, the report concludes that the developed Malware Detection System using Machine Learning, specifically the Random Forest and Logistic regression models, shows promise in effectively detecting malware and highlights the importance of leveraging Artificial Intelligence for combating malware threats in the computing community.
Phishing, Classification Algorithm, Website Detection, Machine Learning, Regression Analysis, Malware
Short address: https://sciup.org/15019533
IDR: 15019533 | DOI: 10.5815/ijwmt.2024.05.03
Text of the scientific article Development of a Phishing Website Detection Model Using Classification Algorithm
The internet is an invaluable resource for information, knowledge, and learning, as well as a platform for conducting legitimate and convenient transactions. However, it also harbors cybercriminals who engage in malicious activities such as phishing, which has caused significant harm to private businesses and large industries. To protect users from these threats, developers and white-hat hackers continuously seek effective solutions. As cybersecurity attacks increase in both scope and sophistication, social engineering remains a primary method for accessing confidential information. [1] Phishing, as defined by the United States Computer Emergency Preparedness Team
(US-CERT), is a type of social engineering attack where personal information is solicited through malicious emails or websites that impersonate trusted organizations. It is one of the most prevalent and dangerous illegal activities conducted online.
The growth of internet usage for services provided by governments and financial organizations has led to a significant rise in phishing attempts in recent years. Phishers, motivated by financial gain, employ various techniques such as voice over IP (VoIP), spoofed links, chat, and fraudulent websites to deceive unsuspecting users. [2] Creating fake websites is relatively simple; they mimic legitimate sites in layout and information but aim to harvest personal data, including account numbers, debit and credit card passwords, and login credentials. One objective of phishing is to obtain sensitive information for identity theft or financial fraud. Attackers may also pose security questions to gain high-level security answers from users, thereby tricking them into divulging their details. [3]
Additionally, hackers install malicious software on computers to steal login credentials, exploiting these systems to capture users' online account information. Phishers use multiple methods, including text messages, phone calls, forum posts, emails, Uniform Resource Locators (URLs), and instant messages, to steal user information. Phishing content often closely resembles legitimate content, misleading users into accessing these malicious sites and unknowingly providing their private information. For an average internet user, identifying phishing sites can be challenging unless they know the specific URL, which can be time-consuming. To address this issue, this work aims to develop a machine-learning algorithm to help users and business organizations identify malicious URLs effectively.
2. Literature Review
In order to examine how well machine learning can detect phishing attempts. websites, [4] developed and examined four models. Additionally, it compared the four models' most accurate models with solutions that had already been published. These models were developed using random forest (RF), decision trees (DTs), support vector machines (SVMs), and artificial neural networks (ANNs). Furthermore, the models were evaluated against the UCI Phishing Domains dataset obtained from the Universal Resource Locator (URL) as a benchmark. Their findings showed that, among the four approaches, the random forest technique-based model is the most accurate and outperforms other solutions found in the literature.
Authors in [5] introduced the Phish-Sight framework, a machine-learning-based system that uses a visual inspection method to detect phishing websites. Phish-Sight use machine learning techniques well-known brand names injected into URLs' web pages to identify fraudulent websites. The most common color attributes as well as well-known trademarks from websites were predicted using five machine learning techniques. With a 99.13% accuracy rate and 98.43% of genuine positives, the Random Forest algorithm surpassed the competition in phishing scam detection. With an estimated execution time of 7.6 seconds per web page, Phish-Sight could have real-time applications.
In [6] authors compared and examined phishing websites with authentic ones using information gathered through an assessment of open-source platforms. The authors also suggested employing Decision Tree and Random Forest techniques to identify bogus websites. The poll, which had 30 participants, was conducted using Microsoft Form. The majority of participants lack basic knowledge, are vulnerable to phishing attacks, and do not review the interface's features before using the search browser. As part of the data collection for the survey, Decision Tree and Random Forest were trained and assessed to determine the best phishing website detection. The outcomes demonstrated that Random Forest performs the most favorable in regards of obtaining high rates of accuracy and feature importance identification.
In [7], authors incorporated hybrid URL and hyperlink-based elements into a machine learning-based approach for real-time phishing website detection, achieving high accuracy without requiring any external systems. Heuristic, visual similarity, blacklist, and whitelist-based anti-phishing solutions cannot detect newly launched websites or zero-hour phishing attempts. Furthermore, because they rely on external sources like search engines, older systems are complicated and inappropriate for real-time environments. Therefore, a significant difficulty in the field of cybersecurity is identifying recently created phishing websites in a real-time setting. They also generate a new dataset for testing using popular machine-learning categorization methods. Their test findings showed that the suggested phishing detection approach performed better than more established techniques, with an XG Boost technique-based detection accuracy of 99.17%.
Authors in [8] examined the use of feature selection algorithms for the fast and precise identification of phishing websites. A comparison of machine learning algorithms was done based on how effective they were both with and without feature selection. A phishing dataset of 30 attributes, 4898 phishing pages, and 6157 benign sites was used in the trials. The best results were achieved by combining several machine learning techniques. After that, a feature selection technique was used to increase the models' effectiveness. With a large reduction in model construction time, random forest was able to achieve the best accuracy both before and after feature selection.The result showed that using feature selection techniques in addition to Machine learning methods have the potential to accelerate the creation of phishing detection classification models while maintaining their accuracy.
In order to identify phishing assaults, authors in [9] used a number of machine learning algorithms. It is suggested to use two priority-based algorithms. The ultimate fusion classifier was selected in accordance with the output of these algorithms. They employed a novel fusion classifier on a information from the University of California, Irvine, and got a 97% accuracy rate. For the implementation of our experiments, they employed Python .
In 2020, authors in [10] suggested a method to use a stacking model to identify phishing websites. Feature selection algorithms such as information gain, gain ratio, Relief-F, and recursive feature elimination (RFE) are employed to analyze the attributes of phishing datasets. Two features were created by combining the best and worst attributes. Principal component analysis was performed on the recommended and residual features using a range of machine learning techniques, such as bagging, support vector machines, random forests, neural networks, k-nearest neighbor, and support vector machines. In order to improve classification accuracy, the top-scoring classifiers were then combined to apply two stacking models: Stacking1 (RF + NN + Bagging) and Stacking2 (kNN + RF + Bagging).The accuracy of each classifier was much improved by the suggested features. The results showed how important RFE is for eliminating the least important feature from the set of data. In terms of classification accuracy, Stacking1 (RF + NN + Bagging) performed better than any other classifier, identifying phishing websites with a 97.4% accuracy rate.
Authors in [11] evaluated the ability of six machine learning methods to recognize between phishing and trustworthy websites: Multi-Layer Perceptron (MLP), Support Vector Machine (SVM), Random Forest (RF), Decision Tree (DT), Logistic Regression (LR), and Naive Bayes (NB). There were two distinct training groups used to train these algorithms in the WEKA platform. Three different datasets with different percentages of phishing and non-phishing cases were used to assess the algorithms' accuracy, precision, TP rate, and FP rate. Results showed that Multi-Layer Perceptron had the lowest results in terms of detection accuracy, whereas Nave Bayes classifier had the best detection accuracy among other classifiers for detecting phishing websites. Additionally, the outcome demonstrated that Support Vector Machines have a higher FP rate than other classifiers. Additionally, all phishing websites may be accurately classified as phishing using Random Forest, Decision Tree, and Naive Bayes. This indicates that the TP rate for these classifiers is 100%. This study recommended utilizing NB as the top classifier for distinguishing between legitimate and fraudulent websites.
3. Methodology 3.1 Language
Python was used as the primary language in the development of this model. Python is a programming language that emphasizes machine learning extensively. It offers many libraries for machine learning that can be used directly by importing them. Due to its vast collection of machine learning libraries, Python is utilized all over the world to handle with machine learning.
-
3.2 Dataset
-
3.3 Data Preprocessing
The dataset was downloaded from kaggle ,and this dataset was used to train the machine learning models with 549,346 good and malicious URL. The dataset is split into training and testing sets to evaluate the model's performance. A split ratio is 70% for training and 30% for testing. This ensures that the model is trained on a subset of the data and tested on unseen data to assess its generalization ability.
Data pre-processing cleans up raw, unstructured data to create well-structured data. and tidy datasets. Preprocessing will be carried out on the dataset to ensure a good training accuracy.
In the context of malware detection, the following steps were likely involved:
-
a. Data Cleaning: This step involves handling missing values, outliers, and inconsistencies in the dataset to ensure data quality.
-
b. Data Transformation: Converting non-numeric data into a numeric format suitable for machine learning algorithms.
-
c. Normalization: Scaling the data to a standard range to prevent features with larger scales from dominating the model training process.
-
d. Feature Encoding: Converting categorical variables into numerical representations for model compatibility.
-
e. Feature Selection: Identifying and selecting relevant features that have a significant impact on the target variable to improve model performance.
-
3.4 Feature Extraction
-
3.5 Machine Learning Models
Feature extraction involves selecting and transforming raw data into a format that is suitable for model training. In the context of malware detection, features related to file behavior, system calls, API calls, and other characteristics of malware samples may have been extracted from the dataset to train the machine learning models.. e.g To reduce the length of malicious URL ,attackers always use URL shortening service. In the case of Random Forest and Logistic Regression models, hyperparameters such as the number of trees in the Random Forest, maximum depth of trees, regularization parameter in Logistic Regression, etc., is tuned using techniques like grid search or random search to find the best combination for optimal model performance. Table 1 below shows features that will be used for this study. These features are important for detecting phishing domains.
Table 1. Features for detecting phishing domains
|
Address based Features |
Domain of the URL URL IP Address Redirection of the URL(“//’) Http/Https in the Domain name Use of URL shortening Service Prefix or Suffix in the domain “-” Length of the URL Depth of the URL “@” Symbol in the URL |
|
Domain based features |
|
|
HTML &Java script based Features |
|
Two supervised machine learning algorithms were used in this study, which are as follows:
-
1 . Logistic Regression (LR)
-
2 .Multinomial Naives bayes
-
3 .5.1 Logistic Regression
-
3 .5.2 Multinomial Naives Bayes
-
3.6 Architecture of The System
Within the framework of Supervised Learning, among the most widely used Machine Learning algorithms is logistic regression. It is employed to predict, from a set of independent variables, the categorical dependent variable utilizing logistic regression to predict results of a dependent variable that is categorical. Consequently, the output needs to be discrete or categorical. It can be anything from True to False to Yes or No, and so on, but rather than providing exact values between 0 and 1, The probabilistic values it offers fall between 0 and 1. Observations can be categorized using a variety of data types, and logistic regression can be used to quickly identify the variables that work best for classification.
The well-known logistic regression machine learning technique is a component of the supervised learning methodology. This approach uses a series of independent variables to forecast the category dependent variable. The result of a categorical dependent variable is predicted using logistic regression. For this reason, the outcome needs to be discrete or categorical. Instead than giving the precise values of 0 and 1, it gives the probability values that fall between 0 and 1. It can be True or False, Yes or No, 0 or 1, and so on. Logistic regression is a useful tool for classifying observations based on different kinds of data. This approach finds the variables that are most useful for categorization quickly.
The foundation of the Nave Bayes method, which is applied to several classification applications, is the Bayes Theorem. A straightforward mathematical formula for estimating conditional probabilities is the Bayes theorem. Conditional probability is the likelihood that an event will occur in light of the likelihood that another event has already occurred (based on an assumption, inference, claim, or piece of evidence).
Figure 1 shows the arcitecture of the system.
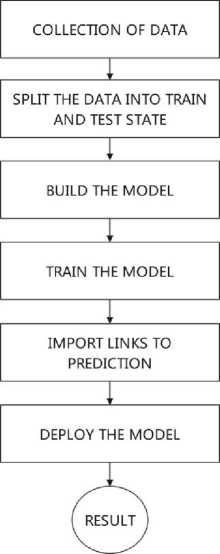
Fig. 1. Architecture of the system
4. Results and Discussion
The dataset was downloaded from Kaggle. It was in a csv (Comma-separated Values) format .There were 549,346 legitimate and malicious URL in the datasets. Then the dataset was preprocessed. Figure 4 shows a part of the processed data. Dataset was tokenized by dividing the long links or text into smaller pieces and also got the text stemmed by mapping a group of word to the same stem. Figure 2 shows a part of the dataset after it was tokenized. Figure 3 shows a part of the word stem. A graph was then drawn to differentiate the amount of good and bad URLs in the datasets. In the feature extraction file, the recovered features from the genuine and phishing URL datasets were simply concatenated, with no shuffling. To balance the distribution, the data was shuffled while dividing it into training and testing sets. This reduces the potential of the model over-fitting during training. Visualization was done using word cloud
In [12]: print('Getting words tokenized ...')
Getting words tokenized ...
Time taken 3.598875489000079 sec
Out[13]:
URL Label text tokenized
[pastehtml, com. view, bvu, fs, vc, html]
[paypula, altervista, org. login, doR. index. ...
[en, Wikipedia, org, wiki, Montreal, Expos, se...
good [amazon, com. Eye, Every, Storm, Neurosis, dp,...
[en, Wikipedia, org, wiki, Pedal, to, the, Met...
Fig. 2. Tokenized word
The process of breaking down text data into individual tokens or words for analysis. The input to the tokenization process is raw text data, which is in the form of sentences, paragraphs, or documents.
-
•w«M w*mmm»*m«*« *м» |>м*маммма. мму («хммшмаь и*м| ммаммит «мм
VKuMor। of ша i muMm wr# трмше key u«g werddoud
|20| bad sites, head О #b^:nginp out the already tc*enl/ed and stcaaed text for intent: tying the bed url
UHL UM teal MttMUiM IM МММ Ml MM
-
• шатмжтйммвамммпгт» м !«»< •*><»«<<« J h*# < * 4 eca «< t «r ^«•#«a»My*>»e
■ жолфипччиапмусгммкк мл С—«эт«* «" >чи^* (—^р/«" iw^»* —arw
J .»»«.<»«№,).,»>* м Н—п«чч*2«Г 1""“-“»»'"**чм« -~=»<=nW«4t-je«

Fig. 3. Word Stemmed
The process of reducing words to their root or base form to normalize the text data, aiming to reduce inflected or derived words to their root form to capture the core meaning of words.
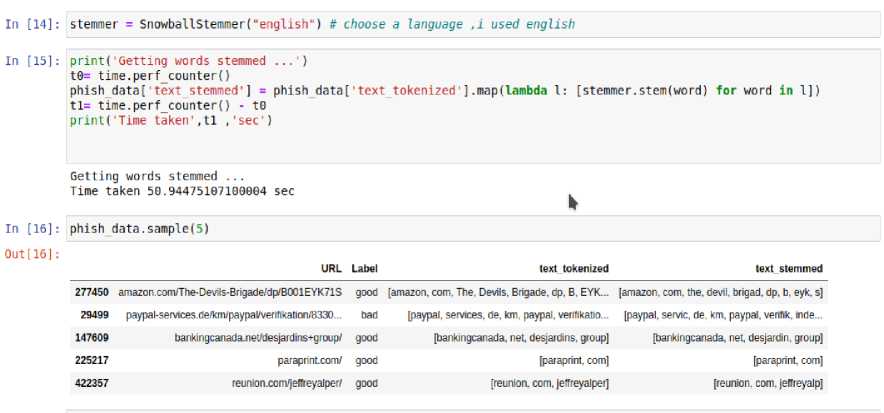
Fig. 4. Data Preprocessing
The data is further fed into the logistic regression and naive bayes models. Figures 5 and 6 show the training of the logistic regression and the result respectively. The training and testing accuracies for the logistic regression model were 96% and 97% respectively
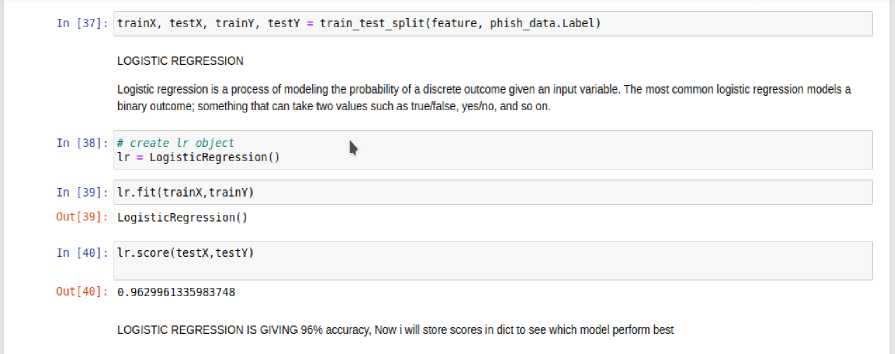
Fig. 5. Training of Logistic Regression model
The training of a Logistic Regression model involves preprocessing the data, normalizing the features, fitting the model to the training data, optimizing the cost function through gradient descent, and evaluating the model's performance on unseen data. This process helps in building a predictive model for classification tasks in the malware detection,
In [41]:
In [42] :
Scores ml = {}
con mat = pd.DataFrame(confusionmatrixflr.predict(testX), testY), columns = ['Predicted:Bad', 'Predicted:Good1], index = ['Actual:Bad1, 'Actual:Good'])
print{'\nCLASSIFICATION REP0RT\n') ^
print(classification report(lr.predict(testX), testY, ta rget_names =['Bad',1 Good' ]))
print('\nCONFUSION MATRIX1)
sns.heatmap(con_mat, annot = True,fmt='d ,cmap="YLGnBu")
Training Accuracy : O.9773063209784252
Testing Accuracy : O.9629961335983748
-
Fig. 6. Testing and training accuracies for logistic regression
For Naive Bayes Classifier, the training and testing accuracies were 95% and 97%. Figures 7 and 8 show the training of the model and the result respectively.
In [43]: # create mnb object mnb = MultinomialNBO
0ut[44]: MultinomialNBO
Out[45]: 0.9573312363019434
multinomial naives bayes gave me 95% accuracy
-
Fig. 7. Training of Naïve Bayes model
The training of a Naïve Bayes model involves preprocessing the data, feature engineering, estimating class and feature probabilities, building a predictive model based on these probabilities, and evaluating the model's performance on unseen data. This process helps in building a probabilistic classifier for classification tasks,
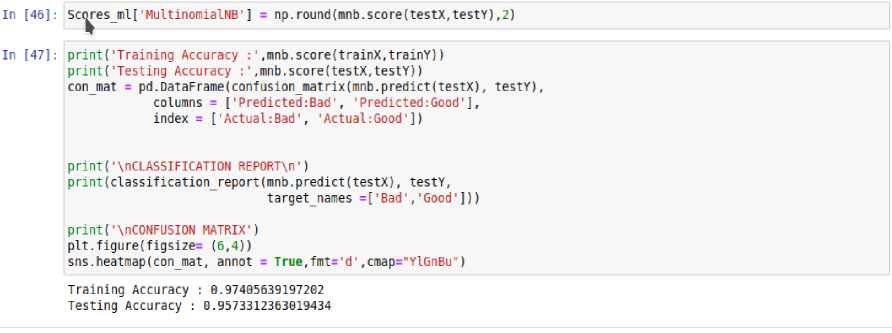
Fig. 8. Testing and training accuracies for Naïve Bayes
The accuracy of the individual models on the training and test datasets is as shown in figure 9. The F1-score, Precision and Recall of Logistic regression is as shown in figure 10.
Out[48]:
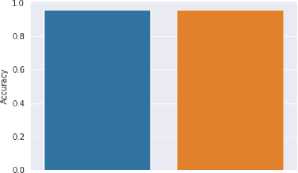
So, Logistic Regression is the best fit model, Now we make skleam pipeline using Logistic Regression
Fig. 9. Accuracies of the models
The Random Forest model outperformed the Logistic Regression model in terms of accuracy, with a training accuracy of 99.99% and a validation accuracy of 98%. On the other hand, the Logistic Regression model achieved a validation accuracy of 94.04%. These accuracies indicate the performance of the models in detecting malware based on the features extracted from the CIC-MalMem-2022 dataset. The higher accuracy of the Random Forest model suggests its effectiveness in classifying malware instances compared to the Logistic Regression model.
precision recall fl-score support
Bad 6.91 6.97 6.94 36763
Good 0.99 6.97 6.98 100574
accuracy 8.97 137337
macro avg 0.95 6.97 6.96 137337
weighted avg 0.97 6.97 6.97 137337
CONFUSION MATRIX
0ut[53]:
PnedictedzBad

Fig. 10. F1-score, Precision and Recall of logistic regression
Logistic Regression has a higher accuracy as compared to Naïve Bayes. A pipeline was created for logistic regression model as shown in figure 11, it significantly improved the readability and comprehension of the process. It ensured the implementation and sequencing of the different phases in this study.
In [49]: pipelinels = make_pipeline(CountVectorizer(tokenizer = RegexpTokenizer(r'[A-Za-z]+1).tokenize,stop_words='english
##(r ' lbf?;ftttp| ftp) 5?.7/15*| w|)w+| ГЛ11У| sj+' ) ( [a-zA-Z]+) ( [G-9] + ) -- these tolenizers giving me low accuray
Out[51]: Pipeline(steps-[('countvectorizer',
Out[52]: 0.9052242294501846
к
print(1\nCLASSIFICATION REPORT\n')
print(classification report(pipeline Is.predict(testX), testY
Fig. 11. Scikit-Learn Pipelines
After building the model, it was dumped using (pickle). Dumping is the process of converting a Python object into a byte stream so that it can be saved to a file or database, kept in memory between sessions, or sent over a network. Then the model was loaded again to check the accuracy which was 96.5% as seen in figure 12. The dumped model in the operating system used is as shown in figure 13

Fig. 12. Dumping model using Pickle
Dumping a model using Pickle in Python is the process of serializing (converting) a machine learning model object into a byte stream that can be saved to a file. This serialized object can then be stored persistently on disk for later use, sharing with others, or deployment in production systems. Pickle is a built-in Python module that provides a convenient way to serialize and deserialize Python objects.

venv

Final year project.-ipynb
phishing, pkl
Fig. 13. The dumped model
To aid a good interaction between users and the system, a graphical interface was created. The Graphical interface was created using uvicorn and the pkl file was imported as shown in figure 14.
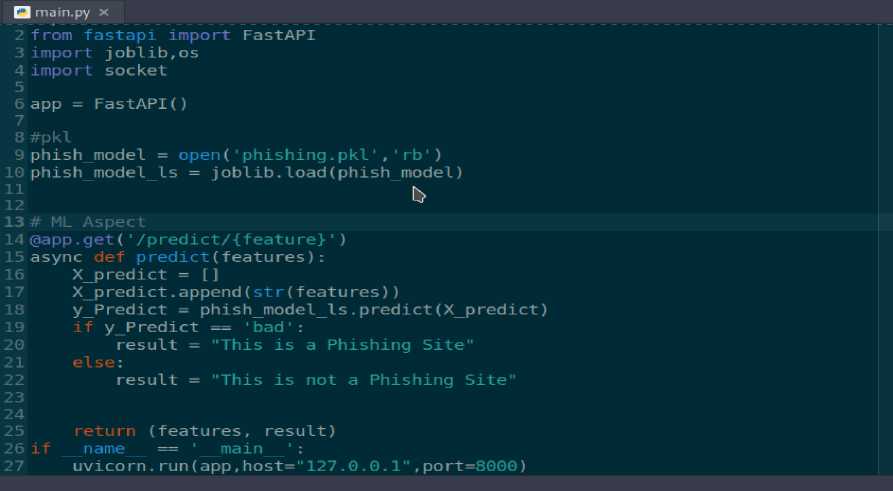
Fig. 14. Code of the graphical user interface
The model was tested with a non-phishing website. The model predicted well that “” is not a phishing website as shown in figure 15. A phishing website as shown in figure 16 was also used to test our model. The result showed that the website is a phishing site as seen in figure 17.
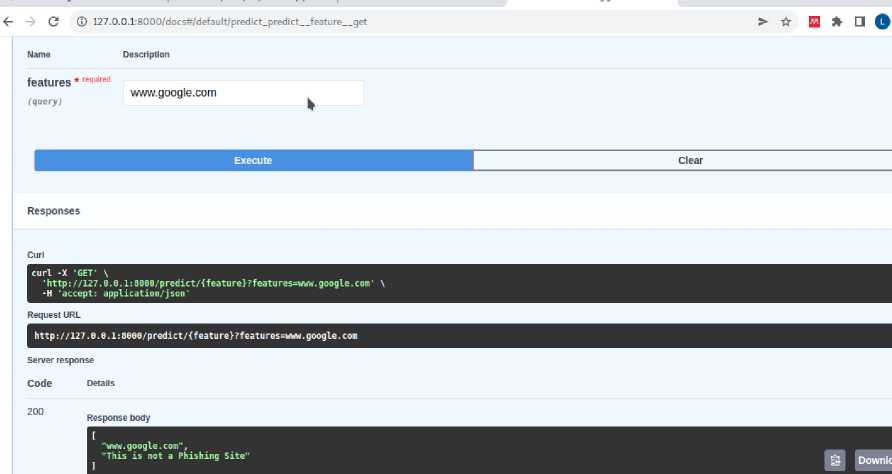
Fig. 15. Non-phishing web prediction
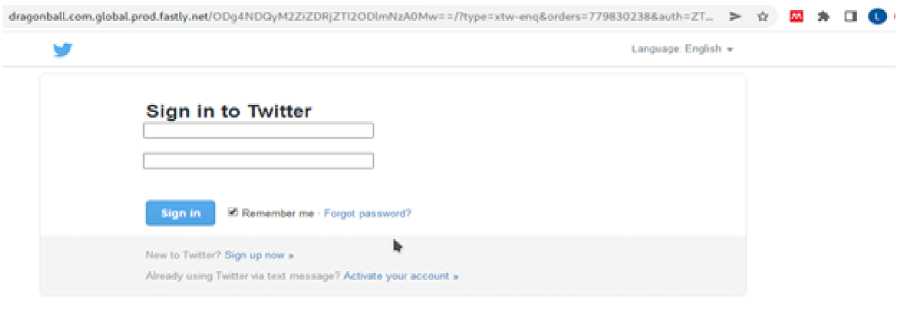
Fig. 16. Twitter phishing site
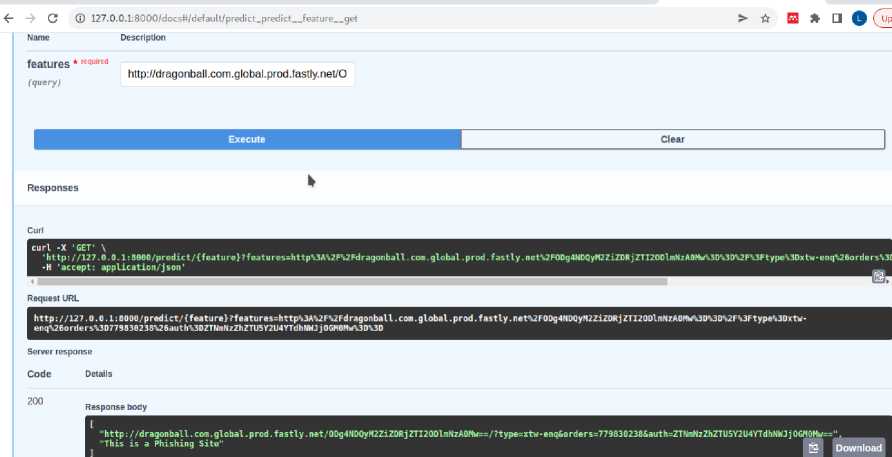
Fig. 17. Phishing site prediction
5. Conclusion
The machine-learning algorithms utilized in this study can be used to determine the legitimacy of a website or not. It can be concluded that logistic regression did better with high accuracy by including 16 features. The training accuracy was 97% and the testing accuracy was 96%. This study will help prevent the user from accessing deceptive sites. We recommend that more work be done to block the user from accessing the phishing site by auto-detecting it instead of the URL being input by the user to the model interface before it can be verified.
The work adopted Pearson correlation coefficient for feature selection. However, this method may overlook nonlinear relationships between features. Utilizing more advanced feature selection techniques like recursive feature elimination or Lasso regularization could improve model performance. Also the paper does not explicitly address the issue of imbalanced data, which can lead to biased models. Implementing techniques such as oversampling, under sampling, or using algorithms like SMOTE to handle imbalanced classes could enhance model robustness.
While the paper highlighted evaluating the models using accuracy, incorporating additional metrics like precision, recall, F1-score, and ROC-AUC can provide a more comprehensive assessment of model performance, especially in the context of malware detection. However, these limitations can be improving by combining multiple models such as Random Forest, Gradient Boosting, or Neural Networks through ensemble techniques like stacking or blending could potentially enhance the overall predictive power of the system. Exploring advanced feature engineering techniques like polynomial features, interaction terms, or domain-specific feature creation could help extract more relevant information from the dataset and improve model performance.
Also, incorporating techniques for model explain ability, such as SHAP values or LIME, could provide insights into how the models make predictions, especially in critical applications like malware detection where interpretability is essential, Finally, implementing robust cross-validation strategies like k-fold cross-validation or stratified crossvalidation can provide a more reliable estimate of model performance and generalization to unseen data.
Suggested ways for further research could be extended by xploring of different algorithms by:
-
a. investigating the use of deep learning architectures such as Convolutional Neural Networks (CNNs) or Recurrent Neural Networks (RNNs) for malware detection. These models can capture complex patterns in malware behavior and improve detection accuracy.
-
b. Explore ensemble methods like AdaBoost, XGBoost, or stacking multiple models to leverage the strengths of different algorithms and enhance overall performance.
-
c. Consider incorporating anomaly detection algorithms like Isolation Forest or One-Class SVM to identify novel and previously unseen malware patterns.
Also Utilization of Larger Datasets by
-
a. Acquire and utilize larger and more diverse malware datasets from real-world sources to improve the model's ability to generalize to different types of malware.
-
b. Explore techniques for handling streaming data in real-time to adapt the model to evolving malware threats and ensure continuous monitoring and detection.
Addressing Real-Time Implementation Challenges by:
-
a. Address scalability challenges to deploy the model in real-time systems, ensuring efficient processing of large volumes of data without compromising performance.
-
b. Optimize the model for low latency to enable real-time detection of malware threats, especially in timesensitive environments like network security.
-
c. Develop lightweight models that can operate efficiently on resource-constrained devices or systems, such as IoT devices or edge computing platforms.
-
d. Incorporate techniques for explaining model decisions, such as SHAP values, LIME, or model-specific interpretability methods, to enhance trust and understanding of the detection system.
-
e. Investigate methods to enhance the model's robustness against adversarial attacks specifically designed to evade malware detection systems.
-
f. Implement techniques for incremental learning to adapt the model to new malware variants and continuously improve detection accuracy over time.
References Development of a Phishing Website Detection Model Using Classification Algorithm
- Gururaj Harinahalli Lokesh & Goutham BoreGowda (2021). Phishing website detection based on effective machine learning approach. Journal of Cyber Security Technology. Vol 5, issue 1, pp 1-14, DOI: 10.1080/23742917.2020.1813396
- Kiruthiga, R., & Akila, D. (2019). Phishing websites detection using machine learning. International Journal of Recent Technology and Engineering, 8(2 Special Issue 11), 111–114. https://doi.org/10.35940/ijrte.B1018.0982S1119
- Dutta, A. K. (2021). Detecting phishing websites using machine learning technique. PLoS ONE, 16(10 October), 1–17. https://doi.org/10.1371/journal.pone.0258361
- Alnemari Shouq, and Majid Alshammari (2023). Detecting Phishing Domains Using Machine Learning. Applied Sciences. Vol 13, No 8. https://doi.org/10.3390/app13084649
- Pankaj Pandey & Nishchol Mishra (2023). Phish-Sight: a new approach for phishing detection using dominant colors on web pages and machine learning. International Journal of Information Security. https://doi.org/10.1007/s10207-023-00672-4
- Mohammed Hazim Alkawaz, Stephanie Joanne Steven, Omar Farook Mohammad, Md Gapar Md Johar (2022). Identification and Analysis of Phishing Website based on Machine Learning Methods. 2022 IEEE 12th Symposium on Computer Applications & Industrial Electronics (ISCAIE). 10.1109/ISCAIE54458.2022.9794467
- Sumitra Das Guptta, Khandaker Tayef Shahriar, Hamed Alqahtani, Dheyaaldin Alsalman & Iqbal H. Sarker (2022). Modeling Hybrid Feature-Based Phishing Websites Detection Using Machine Learning Techniques. Annals of Data Science. https://doi.org/10.1007/s40745-022-00379-8
- Gandotra, E., Gupta, D. (2021). An Efficient Approach for Phishing Detection using Machine Learning. In: Giri, K.J., Parah, S.A., Bashir, R., Muhammad, K. (eds) Multimedia Security. Algorithms for Intelligent Systems. Springer, Singapore. https://doi.org/10.1007/978-981-15-8711-5_12
- A. Lakshmanarao, P.Surya Prabhakara Rao & M M Bala Krishna (2021). 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS). 10.1109/ICAIS50930.2021.9395810
- Zamir, A., Khan, H.U., Iqbal, T., Yousaf, N., Aslam, F., Anjum, A. and Hamdani, M. (2020). Phishing web site detection using diverse machine learning algorithms. The Electronic Library, vol. 38, No. 1, pp. 65-80. https://doi.org/10.1108/EL-05-2019-0118
- Zamani, H., & Mohammed Amin, M. K. (2016). Classification of phishing websites using machine learning techniques. Journal of Advanced Research in Applied Sciences and Engineering Technology Journal Homepage, 5(2), 12–19. www.akademiabaru.com/araset.html
