Entity Extraction from Business Emails

Author: Juan Li, Souvik Sen, Nazia Zaman
Journal: International Journal of Information Technology and Computer Science(IJITCS) @ijitcs
Article in issue: 9 Vol. 7, 2015.
Free access
Email still plays an important role in today's business communication thanks to its simplicity, flexibility, low cost, and compatibility of diversified types of information. However processing the large amount of emails received consumes tremendous time and human power for a business. In order to quickly deciphering information and locate business-related information from emails received from a business, a computerized solution is required. In this paper, we have proposed a comprehensive mechanism to extract important information from emails. The proposed solution integrates semantic web technology with natural language processing and information retrieval. It enables automatic extraction of important entities from an email and makes batch processing of business emails efficient. The proposed mechanism has been used in a Transportation company.
Email, entity extraction, natural language processing
Short address: https://sciup.org/15012366
IDR: 15012366
Text of the scientific article Entity Extraction from Business Emails
Published Online August 2015 in MECS
Over the past five decades, email has become one of the easiest and reliable modes of communication, mainly because of its efficiency, low cost and support for wide range of information [1]. Recent studies show that email is still number one online activity though there are new concepts like social networking [3]. Corporate users send and receive about 110 messages [5] per day in average and out of them one third are messages sent. Those statistics are quite constant and has not been changed too much in last decade [6]. According to a report [7], about 80% of the business users prefer email communication over others for their work purpose. While another report [8] says that 62% of the employees in United States can be considered as Networked Workers as they use Internet and email on their work on daily basis.
Information generated by business entities can be considered as highly useful asset based on how well it is managed. Email is not different here [9]. Email is now essential for many of the common industrial [9, 10, 11]
functions such as task management, collaboration, generating alerts, archiving and interoperability. It is pretty common for many of the organizations to receive product or service requests via email. To process the requests, employees of the organization have to read the emails and manually extracted important information from the emails. Normally, a company may receive thousands of such business emails every day. Therefore, to process emails quickly, an automated system is essential. This automatic processing will extract and store the featured information to provide the necessary business service.
For example, a freight company provides trucking and freight services for both residential and commercial shippers. Although they provide a web page for shippers to register their fright, they still receive thousands of freight shipping requests by emails every day. Therefore, it is important for the company to serve these email requests promptly to ensure their freight gets to its destination safely and on time. To serve the clients better and faster, the company needs to know the details about the request such as freight size, location, destination, and timeline. An email information extraction program should extract all of these important information as correctly as possible and save the extracted information in the company database for further service. Time is another issue here. Manual reading emails and providing service can take a long time and user can suffer because of that. Hence an automatic email extraction procedure will surely solve that time delay issue. Many ecommerce companies record email receipts of online transactions which are full of essential product information including product category, price, date of purchase etc. If this information can be extracted and saved in a good manner, it can be used for several purposes including a recommendation system [2]. If the system can identify the type of product a specific user is buying, then the system can suggest further products to that user using extracted information.
In this paper, we propose an effective entity extraction mechanism to locate and retrieve important information from business emails. The retrieved entities can be utilized for business management solutions to make business processes more efficient, effective, and predictable. The proposed work integrates rich semantics, text mining machine learning, and natural language processing technologies.
The rest of the paper is organized as follows. In Section II, we describe the details of our methodologies. In Section III, we evaluate the proposed methods and show the effectiveness of this model with a set of experiments. Related work and concluding remarks are provided in Sections IV and V, respectively.
-
II. S ystem D esign
-
A. Overivew
The content of business email is normally different from general text data in many documents. As pointed out by Tang et al. [22], emails are often much shorter and more briefly written compared with documents such as stories and user manuals. In addition, emails often contain some faddish words or abbreviations that may not appear in traditional dictionaries. Moreover, business emails also include domain specific terms/jargons. Furthermore, besides textual data, attachment of business emails also contains very important information which should not be ignored. Standard natural language processing and text mining techniques may not be effective when they are applied to business email mining tasks.
To address the aforementioned challenges, we propose a domain knowledge-assisted information extraction mechanism to retrieve important information from business emails. Prior to the inception of email information extraction and subsequent processing, it is essential to acquire a concrete domain knowledge which captures specific information about the business. This domain knowledge can be used in direct the entity extraction process and also in creating rules to extract information. In our work, the domain knowledge is encoded as ontology, which is represented as OWL/RDF format [18]. Besides entities defined in an ontologies, named entities and noun phrases referring to specific individuals like persons, organizations, location, date, and time are generally important regardless of domains. Therefore, we should locate and extract these named entities as well.
An email contains multiple parts as shown in Fig. 1. We are processing each module at a time to extract important information from each of them. The process flow for the entire system has been depicted in Fig. 2. Before extracting important entities, we first extract information from the attachments of an email. We separate the email attachments based on their file extension such as Excel attachments, and Word attachments. As graphs and figures do not contain textual information, we do not process this kind of attachment. According to their types successive processing is performed. Attachment content can be divided into two types: unstructured content and structured content. For unstructured textual information, we simply convert it into simple text. For structured information, for example tables, we try to keep their structure. For example, we use Apache’s PDFBox [29] library methods to convert the PDF files to text files.
To:
Dear Bob
Date
Sender \
\ Receiver Subject Body ' Attachement
IN-CONhDENCE.
Alice User Bob User
Important information [SEOIN-CONflDENCE]
This is important IN-CONFIDENCE information for you ...
Fig. 1. Example email.
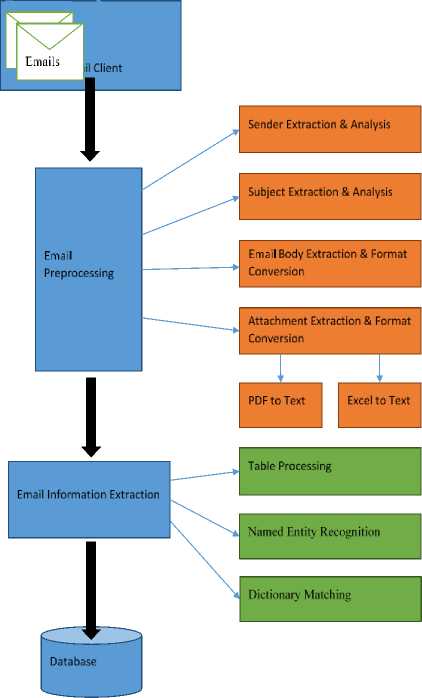
Fig. 2. System diagram for flow of the processes in the system
-
B. Entity Extraction from Unstrucuted Data
As most emails are written using informal natural language, therefore, as the first step, we deal with entity extraction from unstructured email text. Before extraction, we first try to remove noisy information from the unstructured text and obtain key features of the email. First, the text are cleaned from any unnecessary information such as HTML tags. And then data is segmented into sentences. We have used the Punkt sentence segmenter [42] to segment sentences. Then a tokenizer is used to divide text into a sequence of tokens, i.e., words in our case. We adopted the Penn Treebank Tokenization [43]. We have converted all tokens to lowercase to simplify the later semantic entity extraction process. Some of the most common, short function words, such as “the”, “a”, “is”, “which”, are useless in text analysis. We remove these words from the text to reduce the data size and improve efficiency and effectiveness of analysis. Stemming, the process of reducing a word to its root or simpler form by removing inflectional endings, is also performed in the text.
After pre-processing of the email text, we work on automatically extracting important entities from unstructured natural language. Key entities include person names, organizations, locations, dates, specialized terms and product terminology from free-form text. Existing Named Entity Extraction (NER) systems use linguistic grammar-based techniques [31], statistical models [32], i.e. machine learning, or and gazetteer based entity recognizer [23] to recognize entities. We adopt the machine leering based model – the linear chain Conditional Random Field (CRF) sequence model [44] to extract general entities. CRF (Lafferty et al., 2001) are undirected graphical models, a special case of which correspond to conditionally-trained finite state machines. Like the maximum entropy models, CRF is also based on the same exponential form, but CRF is more efficient for complete, non-greedy finite-state inference and training [44].
A CRF model is defined on observations X and random variables Y as follows:
Let G=(V,E) be a graph such that
Y=Y(Y v ) v £V , so that Y is indexed by the vertices of G .
Then ( X,Y) is a conditional random field when the random variables Y v , conditioned on X , obey the Markov property with respect to the graph:
p(Y v IX,Y w ,w^v) = p(Y v lX,Y w ,w~v)
where w~v means that w and v are neighbors in G .
In this definition, a CRF is an undirected graphical model whose nodes can be divided into exactly two disjoint sets X and Y , the observed and output variables, respectively; the conditional distribution p(Y/X) is then modeled.
Feature selection is very important for named entity extraction. We choose word features, such as current word, previous word, next word, and all words within a window, orthographic features, prefixes and suffixes, label sequences, and feature conjunctions.
Using the CRF model, we can extract general named entities such as persons, organizations, locations, times, etc. To effectively extract special entities defined in the domain ontology, we proposed an ontology-guided entity extraction mechanism. Although these entities are defined in the domain ontology, locating them from emails is not as easy as it appears. This is because business terms/entities used in emails tend to be information, and they may differ from what is defined in the ontology. People may use abbreviations, may write typos, and may omit word(s) from a multi-word phases in their emails.
To address the aforementioned problems, we propose a fuzzy string matching mechanism to effectively locate domain-related special entities from emails. We use the well-known string-based dissimilarity measure – edit distance to measure the distance between two strings. Edit distance is the number of operations, such as deletions, insertions, or substitutions, required to transform one string to another. It can effectively capture typographic errors, words with alternative spellings, and does not rely on the separation of word boundaries [35]. Therefore, edit distance can be applied in our system for string matching and comparing.
In this paper, we propose an effective entity extraction algorithm. In this algorithm the longest multi-word expressions that appear in the email text are mapped to the most specific concepts in the ontology. We first locate all of the noun phrases in the email, as most of the entities (class and instances) in a domain ontology are noun phrases. This noun phrase tagging process can be realized by the part-of-speech (POS) tagging [18]. For terms appeared in noun phrases, we search the semantic entities associated to the terms. Besides exact match, we also provide fuzzy search to find similar matches using edit distance. If there’s a hit (i.e., exact match or edit distance smaller than a predefined threshold), we will tag the word in the email with the ontology entity ID. One word may belong to multiple ontology concepts. In such case, we tag the word with IDs of all associated semantic concepts. After we have finished the keyword-entity matching and tagging phase, we try to identify potential semantic entities in the email. This is done by scanning the tags of the terms in the same noun phrase: if multiple words in the noun phrase point to the same semantic entity, they should be considered as belonging to the same entity. The rationale of this approach is based on the observation that some words tend to be omitted and the orders of the words may be switched in phrases used in the informal emails. Through these steps, semantic entities are recognized and extracted.
-
C. Information Extraction from Structured Data
Many business emails include structured data. The most popular format for structured data is tabular data. Due to the lack of common schema, emails from different people or organization may use different table format. Therefore, we also need an effective strategy to extract information from the structured table data.
As shown in Algorithm 1, in the first step, we extract table header and then match the header with the domain schema. To extract those table headers, we start reading the whole text and look for a row with some header matching. After we get that header row. We start reading other rows and enter those column values under their respected column header. We continue this work until we get the end of the file or we get another table header. We use a Map to map table headers to our required information name.
Algorithm1 Entity extraction from tables
Input : email m={l1, l2, …, ln}, schema s={s1,s2, …,st}, patterns p={p 1 ,p 2 , …,p t }, ontology o={ e 1 , e 2 , …, e m }, tableHeader TH={} entity set ES={}
/* li: lines, ei: ontology entity */ for each wj in l1 do if si=match(wi, s) then create tableHeader h h.caption=wj h.column=j insert h toTH if TH.length>0 then for each li after l1 in e do for each h in tableHeader create entity s s.type=h.caption s.value=w(h.colum) insert s to ES else for each li in e do for each wj in li do if pm=match (wj, p) create entity s s.type=pm.type s.value=wj insert s to ES else if et=match (wj, o) create entity s s.type=et.lable s.value=wj insert s to ES return ES
It is possible that a table does not include a header. If that is the case, we use the data pattern of the domain schema and the domain ontology to match the data column. For example, to extract date format, we need to summarize all date format. Some of the commonly used date formats are represented as “Month-Date-Year”, “Date-Month-Year”, “Month-Date-Year”, “Date/Month/ Year”, “Month/Date/Year”, “Month Date, Year”, etc. We can use techniques such as regular expression to match such format. For columns defined in the domain ontology, we can use the fuzzy matching techniques mentioned previously to match the column data with the entity defined in the domain ontology.
-
III. E valuation
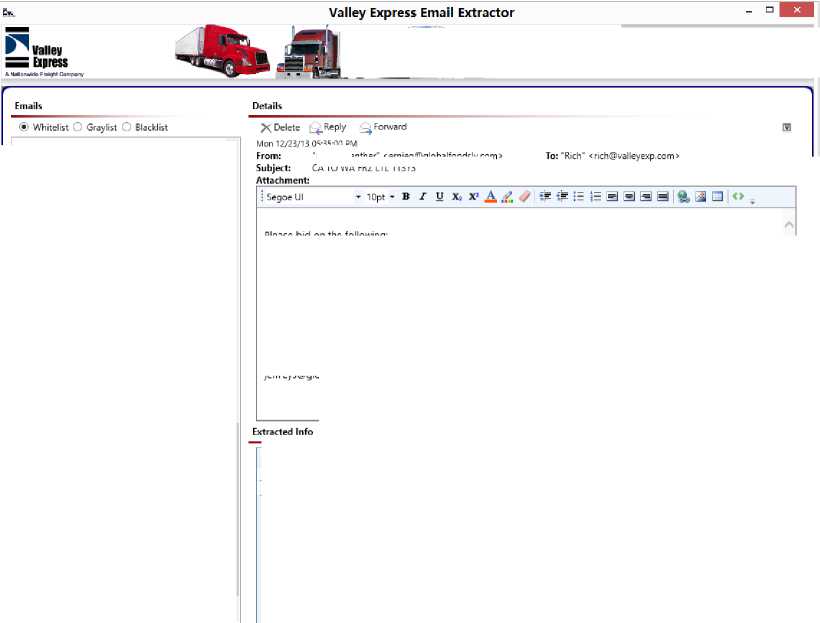
The proposed system has been deployed to a freight company and been evaluated using their real emails. Fig. 3 shows the screenshot of the interface of the proposed system. We can see that entities have been automatically retrieved from the email. We have taken 2431 of emails
which contains Natural language email body content, PDF Word or Excel files as attachments. We try to extract information such as freight size, location, destination, and timeline, and required vehicle type, etc.
We have used our system on 1110 emails as Natural Language text as email body, 554 emails with PDF with Text as attachment, 542 emails as PDF with tables as attachment and 225 emails as Excel files as attachment. We have counted the number of Desired Fields that appears in the email content and the number of fields that we have managed to capture. Based on the result found, we have calculated Precision and Recall. The definition of recall and precisions are defined as follows:
I relevantEntries n retrievedEntries I recall =-----------------------------------
| relevantEntries |
. . I relevantEntries n retrievedEntries I precision =J------------------------------------
| retrievedEntries |
Precision represents fraction of retrieved items which are relevant i.e. the number of correct results delivered divided by the number of all items retrieved. Recall represents fraction of relevant items that has been retrieved i.e. number of correct results achieved divided by the number of correct results that were supposed to be returned. [38].
The results are illustrated in Table 1. From Table 1, we can see that our entity extraction scheme achieves good recall and precision for natural language email and almost perfect recall and precision for tabular data.
Table1. Performance of the Entity Extraction Mechanism
|
Type of Content |
Precision |
Recall |
|
Natural Language |
86.2% |
83.3% |
|
Tabular Data |
100% |
96.5% |
IV. R elated W ork
As we have discussed earlier that emails are very common medium of electronic communication for almost last 40 years, a considerable amount of research has been done on email analysis and mining to get benefit from those email data. Richardson and Domingos presented an efficient algorithm to extract product information from Emails Receipts [27]. The proposed algorithm is based on Markov Logic [26]. Markov logic is the combination or probability and logic. In their work, the authors have encountered many challenges: for example, E-receipts can be generated from different templates. Making a generalized rule is always challenging. Maximum of the E-receipts are based on plain text instead of HTML tagging and that makes the process of information extraction much more complex as data representation is с» Valley Express Email Extractor

|
® Whitelist О Graylist О Blacklist |
Details ^Delete Reply <2^ Forward |
-- 0 |
|||||||||||
|
Don Cosby 12/23 (out look EM Land MSG con verier Tria I Version Imp Nathan Ross 12/23 (outlookEMLandMSGconverterTrial Version Imp Bryan C. Dawson .,,„ Load Aurora, ILto Aurora, CO- 972 Wheel Load! 3 Don Cosby 12/23 (outlookEMLandMSGconverterTrial Version Imp |
Mon 12/23/13 06:10:16 PM From: "Nathan Ross" < Nathan.Ross@keentransport.com > To: 'Nathan Ross" < Nathan.Ross@keentransport.com > Subject: (outlookEMLandMSGconverter Trial Version Import) (outlookEMLandMSGconverter Trial Version Import) 12/23 load Attachment: KeenBrokeraqeNew Nate.pdf |
||||||||||||
|
: SegoeUl ^ 10pt - В I U X= X2 A ^ ^/ *^ *^ := |= В S S ё! ^ 1Л □ <> - |
|||||||||||||
|
; Nathan Ross 12/23 : (outlookEMLandMSGconverterTrial Version Imp : |
|||||||||||||
|
Ernie Guenther 12/23 CA TO TN DRY TL 11383 ' Ernie Guenther 12/74 CA TO TXFRZ LTL 11381 Ernie Guenther 12/24 CA TO WAFRZ LTL 11373 Westphal, Anita M. 1 ? ^g Carrier needed Potlatch Elwood IL 60421 to В Nathan Ross 12/19 (outlookEMLandMSGconverterTrial Version Imp Pam Courchaine ю/04 Pam Courchaine 07/12 Portage. Wl Pam Courchaine 06/28 |
|||||||||||||
|
Extracted Info |
|||||||||||||
|
OriginCity Brunswick |
OriginState |
DestinationCity Raleigh |
DestinationState |
Rate |
AvailableDateTime Sun Dec 17 00:00:00 CST 13 |
Weight |
|||||||
|
Brunswick |
GA |
Raleigh |
NC |
'23" C |
Sun Dec 17 00:00:00 CST 13 |
31482.0 |
|||||||
|
Brunswick |
GA |
Raleigh |
NC |
1200.0 |
Sun Dec 17 00:00:00 CST 13 |
29733.0 |
|||||||
|
Brunswick |
GA |
Raleigh |
NC |
1200.0 |
Sun Dec 17 00:00:00 CST 13 |
31482.0 |
|||||||
|
Brunswick |
GA |
Raleigh |
NC |
1200.0 |
Sun Dec 17 00:00:00 CST 13 |
29733.0 |
|||||||
|
Pooler |
GA |
Sanford |
NC |
2C3 3 |
Tue Dec 19 00:00:00 CST 13 |
'1J:-3 |
|||||||
|
Pooler |
GA |
Sanford |
NC |
0.0 |
Tue Dec 19 00:00:00 CST 13 |
'1?:43 |
|||||||
|
Pooler |
GA |
Sanford |
NC |
0.0 |
Tue Dec 19 00:00:00 CST 13 |
11354.0 |
|||||||
|
Savannah |
GA |
Morton |
2600.0 |
Sun Dec 17 00:00:00 CST 13 |
11020.0 |
||||||||
|
Pooler |
GA |
Indianapolis |
IN |
0.0 |
Sat Dec 23 00:00:00 CST 13 |
17000.0 |
|||||||
|
Creve Coeur |
Columbus |
C H |
5? |
Wed Dec 20 00:00:00 CST 13 |
4400.0 |
||||||||
|
Pooler |
GA |
Cobb |
Wl |
2750.0 |
Sat Dec 23 00:00:00 CST 13 |
17000.0 |
|||||||
|
Pooler |
GA |
Milwaukee |
Wl |
0.0 |
Sat Dec 23 00:00:00 CST 13 |
22430.0 |
|||||||
|
Pooler |
GA |
Bridgeville |
■ Д |
2200.0 |
Tue Dec 19 00:00:00 CST 13 |
11380.0 |
|||||||
|
Pooler |
GA |
Prospect |
0.0 |
Wed Dec 20 00:00:00 CST 13 |
15979.0 |
||||||||
|
Charleston |
SC |
Leetsdale |
Тч |
0.0 |
Mon Dec 18 00:00:00 CST 13 |
364.0 |
|||||||
|
Oswego |
Greencastle |
PA |
5100.0 |
Tue Dec 19 00:00:00 CST 13 |
|||||||||
|
^yMove l о иraylist |
La Grange |
GA |
Hopkinton |
NH |
4600.0 |
Tue Dec 19 00:00:00 CST 13 |
39624.0 |
||||||
won ииуи ииьюо
C.ATOWA FR7 IT1 11374
OriginCity
OriginState
DestinationCity
Destin a t ion State
Weight
VERNON.
PASCO
Rate AvailableDateTime
। 22744,01 Thu Jan 02 00:00:00 CST20141
|
Г |
^^^ ^^^^^^^^ |
Report Admin Email Login |
|
Nathan Ross 11 .^ 11/7 LOAD LIST DonCmby щз (outlookEMLandMSGconverterTrial Version Imp Nathan Ross 12^ (outlookEMLandMSGconverterTrial Version Imp Bryan C. Dawson 12/24 Load Aurora, IL to Aurora, CO- 972 Wheel Load! Don Cosby 12/23 (outlookEMLandMSGconverterTrial Version Imp Nathan Ross 12/23 (outlookEMLandMSGconverterTrial Version Imp Ernie Guenther 12/24 CA TO TN DRY TL 11383 Ernie Guenther 12/24 CATOTXFRZ LTL 11381 |
|
|
Ernie Guenther 12/23 CATO WAFRZ LTL 11373 Westphal, Anita M. 12/19 Carrier needed Potlatch Elwood IL 60421 to В Nathan Ross 12/19 (outlookEMLandMSGconverterTrial Version Imp Pam Courchaine ю/04 Pam Courchaine 07/12 Portage. Wl Pam Courchaine 06/28 |
^^ Move To Graylist
P/U: 01/02/2014
LD# 11372
SCHOOL DISTRICT, DELIVERY APPT. REQUIRED, BLIND NEED A BOL
Please reply ASAP
Ernie Guenther
Global foods
702 212-4557 direct
Fig. 3. Screenshot of a prototype system. (The upper figure shows the tabular data extraction and the lower figure shows the natural language data extraction)
irregular. They have created a corpus of unlabeled Ereceipts and they have identified all possible templates by jointly clustering all those E-receipts [27].
In another study [28] Boufaden et al. have used semantic tagging and domain knowledge for the enterprise to extract information form an outgoing email in a company. They use the extracted data to detect the privacy risk of an organization by matching the extracted data against a set of compliance rules. Laclavík et al. present how email analysis and extraction can benefit an enterprise. They have proposed a light-weight process using various natural language processing techniques such as Named Entity Recognition (NER), Coreference Resolution (CO), Template Element Construction (TE), Template Relation Construction (TR) and Scenario Template Production (ST), then Key-Value pair based information extraction to get the important information regarding enterprise emails. The extracted information has been processed using Semantic Trees, Email Social Networks, and Graph Inference respectively. Bird et al.
Appavu et.al., proposed an classification algorithm called Ad Infinitum [39]. Ad Infinitum is an extension of the decision tree induction algorithm. This algorithm aims to classify the threatening messages in emails. For the same purpose of detecting threat emails, Shekar et al. proposed a Naïve Bayesian filter for classification of threat e-mails [40]. They applied three different Naïve Bayesian filter approaches i.e. single keywords, weighted multiple keywords and weighted multiple keywords with keyword context matching.
Stolfo presents the Email Mining Toolkit (EMT) [41], a data mining system that computes behavior profiles or models of user email accounts. These models may be used for a multitude of tasks including forensic analyses and detection tasks of value to law enforcement and intelligence agencies, as well for as other typical tasks such as virus and spam detection.
-
V. C onclustions
Emails are really important in our daily life as well as in the industry world. There are numerous businesses, where emails are the only way of getting information from their clients and the only way of communication with their clients. In many times, companies have to provide service through emails. Therefore, it is crucial to automatically extract all of the important information from the emails accurately.
In this paper, we propose a series of mechanisms to exact important entities from emails, especially from business emails. In particular, we first preprocess the email data. Then we utilize the domain ontology of the business to guide effective extraction. We designed different mechanism to deal with different email content format. Our mechanism integrates rich semantics, text mining machine learning, and natural language processing technologies together. The retrieved entities can be utilized for business management solutions to make business processes more efficient, effective, and predictable. We have implemented a prototype system.
This system have been deployed to a freight company. Using this system can safe employee’s time and energy to manually read and process emails. The performance of the proposed system has been evaluated with the email samples from the company.
There are many ongoing and future works for this project. Often emails are associated with signatures of the sender, including their name, title, address, phone number, emails etc. Sometimes email signature information create confusion in the information data extraction. It is possible that signature information gets extracted as part of the service information and that is not desired. So it is significant to remove the email signature before we start information extraction from the email. This will produce better result. Similarly, we can see quoted information from previous correspondence. This quotation should be removed as well before the entity extraction process.
Many emails contain images or other icons. As part of important information extraction, these icons and images are often not required. These unnecessary icons can be removed during the pre-processing of the emails. This will keep the information extraction process simple and easy. In some aspect, images or icons can appear into the required information that the organization wants to extract. Then processing and extracting those icons, images and storing them will be required.
