Expert Finding System using Latent Effort Ranking in Academic Social Networks

Author: Sobha K. Rani, KVSVN Raju, V. Valli Kumari
Journal: International Journal of Information Technology and Computer Science(IJITCS) @ijitcs
Article in issue: 2 Vol. 7, 2015.
Free access
The dynamic nature of social network and the influence it has on the provision of immediate solutions to a simple task made their usage prominent and dependable. Whether it is a task of getting a solution to a trivial problem or buying a gadget online or any other task that involves collaborative effort, interacting with people across the globe, the immediate elucidation that comes into anyone’s mind is the social network. Question Answer systems, Feedback systems, Recommender systems, Reviewer Systems are some of the frequently needed applications that are used by people for taking a decision on performing a day to day task. Experts are needed to maintain such systems which will be helpful for the overall development of the web communities. Finding an expert who can do justice for a question involving multiple domain knowledge is a difficult task. This paper deal with an expert finding approach that involves extraction of expertise that is hidden in the profile documents and publications of a researcher who is a member of academic social network. Keywords extracted from an expert’s profile are correlated against index terms of the domain of expertise and the experts are ranked in the respective domains. This approach emphasizes on text mining to retrieve prominent keywords from publications of a researcher to identify his expertise and visualizes the result after statistical analysis.
Expertise Matching, Latent Semantic Analysis, Text Mining, Social Networks, Information Retrieval Systems
Short address: https://sciup.org/15012229
IDR: 15012229
Text of the scientific article Expert Finding System using Latent Effort Ranking in Academic Social Networks
Published Online January 2015 in MECS
Academic Social networks like Arnetminer[14], Microsoft Research[15] etc. are playing major role in simulating the collaborative effort offered by experts across the globe. They offer services like topic search, journal search, person search and represent the relation amongst them using graphs. A social network is represented as a graph G(V,E), where the vertices/nodes are the members and the edge represents the relation of co-authorship as depicted by Academic Research of Microsoft [15], is shown in Fig.1. The edge weight represents the frequency of co-authorship.
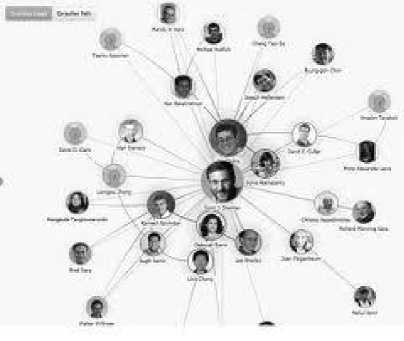
Fig.1. Co-authorship of an Academic Social Network
The authors are sorted by indices like h-index, g-index based on their publications and their citations. However, relevance of publications with a specific domain is not exactly identified, but will be categorized based on their keywords. Different research works [3], [4], [5] were made to identify multi-domain experts based on their profile pages, and their specified research interests. With a thorough analysis made on the concept of publications and versatile research domains, it is found necessary to clearly define the correlation of expertise of each individual and the concept hierarchy of abstract research domains.
Information Retrieval Systems and Search Engines have their own strategies for identifying relevancy of objects i.e. documents and people with respect to the given query. The basic statistical principles of frequency and co-occurrence will be used to measure the similarity of web documents. Text documents are represented by Vector Space Model [16] as an array of valid tokens or index terms. The model is best suited for information filtering, retrieval, indexing and relevancy ranking. The dimension of the vector is the number of distinct words on the vocabulary.
M
^ sim ( p CI ) (1) i = 1
Where d j represents the document vector and w i,j represents the weight of each distinct term in the document containing t terms. The weight can simply be replaced by the word’s frequency or the weightage based on the importance to the current context like inverse document frequency.
The idea of Latent Semantic Analysis is that text has a higher order structure which is obscured by word usage due to polysemy[12]. In order to identify the relevancy of publications with the concept hierarchy of domains, our proposed method uses Term Frequency and Inverse Document Frequency [17] and [19]. These factors reflect the importance of given word with respect to a document in the entire corpus. Term frequency tf(t,d) is the number of times the term t occurs in document d . To prevent bias towards longer documents, the value is normalized and the augmented frequency is used to measure the term frequency. Inverse Document Frequency idf(t,D) is a measure whether the term is common or rare across the document corpus D. This is calculated by dividing the total number of documents by the number of documents containing the term. The product of TF and IDF will tend to filter out common terms in the document dataset.
Computing Document Similarity is another important phase in the proposed architecture as publications and their authors can be clustered based on their specific research domains. The publications are computed for similarity with respect to the concept hierarchy. Expertise Ranking is derived by computing the similarity of an expert’s publications with concept hierarchy of the research domains. The similarity of document vectors is measured by using Cosine Similarity [8] and [18].
The preprocessing and graphical analysis of results of this approach is performed by using the environment of R[12][13], an integrated suite of software facilities for data manipulation, calculation and graphical display. Text Mining and Social Network Analysis modules provided by R gave us a flexibility to perform our experimentation and visualize results in an effective manner. Building of Term-Document Matrix from a given corpus of text documents and creating a word cloud from the frequent words is made so simple with the command line interface provided by R.
Rest of the paper is organized as follows: Collaboration Analysis in Social Networks is discussed in Section III, architecture of proposed Expert Finding System is described in Section IV. Latent Effort Ranking is discussed in Section V, the relevant experimentation along with results is presented in Section VI and the final conclusions are given in Section VII.
-
II. Related Work
Language modeling by [1] uses various textual data sources to build a framework for expert finding given a particular topic. Propagation based expert scoring mechanism proposed by [2] has shown a method to analyze dense social network and use of personal profile document to initialize the process of ranking. Expert scoring started by probability based information retrieval, later uses personal relation of co-authorship to propagate the scores- across the academic social network.
Team formation problem addressed by [3] has started with the belief that effective communication among team members is an important factor for the successful completion of any task. Pool of individuals that are members of a social network and their skill set is considered for building an expertise team. The communication cost incurred towards graph analysis is also considered.
Wikipedia based Expert Finding System built by [4] extracts expert-expertise information from their publications, ranks them and provides multi-disciplinary search using link pattern analysis from Wikipedia. Author-topic model devised by [5] have shown the methods of identifying a reviewer for peer review of research publications. A methodology to create an author Persona per topic which enhances the search process is also shown. Multi-dimensional social recommender systems developed by [6] have projected different layers of social networks in a photo sharing system based on objects they access and their social connections.
Collaborative recommender systems developed by [7] have shown the use of similarity measures like Cosine Similarity and Pearson Correlation Coefficient to analyze product reviews by people on internet. Word similarity computed by [8] has dealt with vector space model of words based on semantic similarity used for document clustering. They have shown the importance of choosing an appropriate co-occurrence measure to compute the similarity of words. Social search systems developed by [9][10] have projected the importance of information seeking from peer group during search process. Answering systems and feedback systems are gaining focus due to the large attention from different categories of people. The importance of understanding the relation between data, information and representation in data storage and retrieval systems is analyzed in [26].
-
III. Collaboration Analysis in Social Networks
Academic social networks, an offshoot of social network create a platform for researchers to publish their work and share knowledge with their peer group. Any technical reference can be had through them by referring to the current research trends, existing publications, people collaboration etc. They also rank researchers based on their effort, but is only quantitative. Different measures like h-index etc. are computed based on publications and citations [20]. However, the computation purely depends on count of publications and coauthors. There is an immense need of analysis of research trends and other technical details, which can only be acquired from the qualitative analysis of the contents of publications.
Current research of expert finding is trying to build the gap between the need of the user and the availability of huge volumes of data. When a user is supplied with the most suitable answer within a short of span or a single click of a mouse, the satisfaction levels will be much better. When a novice wants to get some information, more belief would be on the statements given by an expert who is proven so in the domain. A common user can be transformed as an expert by spending effective time in acquiring knowledge and sharing with peer group. In applications like social search and social feedback systems, always a suggestion from an expert is given more weight. Collaborative effort analysis on the academic social network results in a team of experts who can be productive for solving issues dealing with multiple domains. Whether it is identifying a reviewer for a research publication, contacting a domain expert from industry or University is a task that will be made easy by this approach of collaborative expert matching system. This system tries to extract the latent expertise of a member of network that is hidden in his research publications. Standard Information Retrieval techniques make this approach superior to existing techniques of expert finding. It is predictable that the analysis of existing association between experts of different domains will result in a faster and stronger collaborative effort.
-
IV. Architecture of Expert Finding System (EFS)
-
A. Keyword Extraction from Publications
A research publication contain title, abstract, introduction, architecture, experimentation, results and concluding remarks followed by citations. Out of all these, the prominent zone that emphasizes the concept of the publication is the “Abstract”. Existing research methods like [4] perform the concept matching using title and Wikipedia, but the abstract contain more information about the concept. Also, for almost all publications, the abstract part will be made accessible to a common user and even a web crawler. Hence, this approach tries to perform information extraction and visualization of expertise in a different perspective.
Fig.2 shows a sample abstract along with the tokens extracted from the abstract. Only the frequent terms are shown here after eliminating stop words like “ an ”, “ the ”, “ is ” etc.
-
B. Referencing Concept Hierarchy
Information retrieval systems have an important phase of indexing which makes the entire system effective [21]. Indexing is the oldest technique that helps in identifying contents of an item to assist retrieval. Due to the evolution of digital libraries, storage capability and retrieval efficiency are increased to cater to the needs of current digital environment. Different automatic indexing algorithms exist that create index terms for every domain and provide access points for users through search engines. Relevance ranking strategies that involve feedback mechanism enhance the quality of retrieval which is measured using Precision and Recall.
This paper studies the problem of latent community topic analysis in text-associated graphs. With the development of social media, a lot of user-generated content is available with user networks. Along with rich information in networks, user graphs can be extended with text information associated with nodes. Topic modeling is a classic problem in text mining and it is interesting to discover the latent topics in text-associated graphs. Different from traditional topic modeling methods considering links, we incorporate community discovery into topic analysis in text-associated graphs to guarantee the topical coherence in the communities so that users in the same community are closely linked to each other and share common latent topics. We handle topic modeling and community discovery in the same framework. In our model we separate the concepts of community and topic, so one community can correspond to multiple topics and multiple communities can share the same topic. We compare different methods and perform extensive experiments on two real datasets. The results confirm our hypothesis that topics could help understand community structure, while community structure could help model topics.
-
[1] "analys" "can" "communit" "differ" "discover"
-
[6] "graph" "help" "inform" "latent" "method"
-
[11] "model" "multipl" "problem" "share" "text"
-
[16] "text-assoc""topic" "user"
Artificial Intelligence
Fig. 2. Frequent Terms extracted from abstract of given publication (After Stemming and Stopword Removal)
Database
Data Mining
Databases
Databases E-Commerce
Data Mining
Text Mining
Artificial Intelligence Pattern Recognition

Artificial Intelligence Data Mining
Pattern Recognition
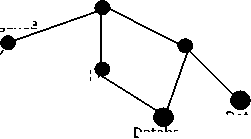
Fig. 3. Reference Concept Hierarchy of Research Domains
Fig. 3 depicts a sample hierarchy of concepts that are branches and siblings of computer science domain. Some terms are related to a specific domain and some terms cannot be decided to which they belong to. Hence, not only keyword extraction, but also contiguous phrase extraction has to be performed to identify domain is some scenarios. Each domain will be having a set of index terms and the relevancy of the terms w.r.t. the domain is measured quantitatively. Words and then documents are clustered based on the semantic similarity to refine the search process. Terms extracted in previous phase of 4A are matched against this concept hierarchy and its respective index terms to identify the expertise and rank the expert based his expertise in every domain.
As explained in the above phases, the complete architecture is shown in Fig. 4 which demonstrates the flow of information extraction and ranking followed by expertise derivation.
Social Network
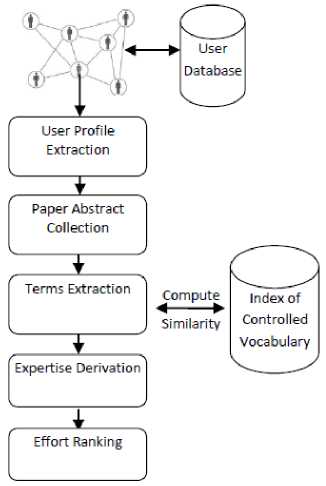
Fig. 4. Architecture of Expertise Finding System
Step 1: For each publications, P j c P, perform tokenization i.e. extract tokens from Title and Abstract.
Step 2: Remove Stop Words, the set of insignificant words
Step 3: Perform stemming i.e. conflate tokens into their root form
Step 4: Compute Term Frequency (TF(t,d)) where t is the term/token, d is the document and w is the set of words/tokens in the document.
TF ( t , d ) = 0.5 +----- 0.5* f ( t , d ) ----- (3)
max{ f ( w, d ): w e D}
Step 5: Compute Inverse Document Frequency (IDF), where numerator, |D| is the total # documents in the document set and the denominator is the # documents containing term t.
IDF = log
D
|{ d ' e D 1 1 e d '}|
Step 6: Compute TF-IDF Weight i.e. product of TF-IDF
-
V. Latent Effort Ranking
-
A. Algorithm 1
To Compute Expertise Ranking
Input: Author Profile and Publications, P Output: Author Expertise Index/Domain
Step 1: From a given set of Researchers, R, for each
Researcher, R i c R, extract profile document
Step 2: Extract set of Publications P for Ri
Step 3: For each Publication, P j , create TF-IDF vector, using Algorithm2.
Step 4: Compute Cosine Similarity between TF-IDF weight Vector and the Concept Hierarchy of index terms i.e. controlled vocabulary, using the equation p j.CI sim p , CI ) =
^
N
S w,. j W i , ci i =1 _________________________
NN
S W2„,E w CI i =1 i=1
-
VI. Experimentation and Result Analysis
-
A. KeyWords /Controlled Vocabulary Identification
Several researchers are selected per each domain of an academic social network, and their publications are collected from Google Scholar, CiteSeer and other open access journals for this analysis. 20 researchers from 8 research domains of “Data Mining”, “Information Retrieval”, “Social Network Analysis”, “Text Mining” etc. are selected for analysis and for each researcher 30 publications in the last two years are analyzed.
Some of the sample keywords that can be used as glossary terms for refereeing concept hierarchy in the domains of “Data Mining” and “Artificial Intelligence” [23],[24] are given in Table 1a and 1b. Such a set of finite index terms is referred to as the controlled vocabulary [21]. This index simplifies the search process at the cost of time. The format of index even supports the process of ranking to decide relevance of the word with reference to the specific domain.
Step 5: Compute cumulative similarity for R i in each Domain D l , build a feature vector and rank them in descending order per each research domain.
M
S sim (p , CI) (1)
i = 1
Step 6: Compute Correlation measures between documents in the corpus to identify their semantic similarity and to refine the controlled vocabulary.
-
B. Algorithm 2
To Compute TF-IDF weight vector for a given document
Input: Title and Abstract of Publication
Output: TF-IDF weight vector
Table 1a. Concept Keywords in “Data Mining”
|
Accuracy |
Association Rule |
Back Propagation |
|
Binning |
Brute Forcing |
Cardinality |
|
CART |
Clustering |
Cross Validation |
|
Decision Trees |
Entropy |
Error Rate |
|
Expert System |
Data Analysis |
Field |
|
Fuzzy Logic |
Genetic algorithm |
Gini Index |
|
Hypothesis |
Intelligent Agent |
KDD |
|
Knowledge Discovery |
Lift |
Machine Learning |
|
Model |
Nearest Neighbor |
Neural Network |
|
OLAP |
Outlier Analysis |
Overfitting |
|
Prediction |
PCA |
Regression |
|
Reinforcement learning |
Sampling |
Segmentation |
|
Supervised learning |
Support |
Visualization |
Table 1b. Concept Keywords in “Artificial Intelligence”
|
ALICE |
artificial intelligence |
autonomic computing |
|
backward chaining |
Bot |
CAPTCHA |
|
chat bot |
Cobot |
computational linguistics |
|
expert systems |
forward chaining |
4GL |
|
character recognition |
KQML |
natural language |
|
neural network |
NLP |
pervasive computing |
|
robotics |
rule-based system |
Turing |
-
B. Significance of “R” in the pre-process
Word cloud represents most frequent words occurring in a given text and those frequent terms can be used to refer to the concept hierarchy for expertise matching.
using
^expert ,u| $. to we 3 for ^
thlS | I Cl an T ® eofand80031 fhpir '^ 'show
Fig. 5b. Wordcloud with stopwords
problem expertise papersfinding taskWC inshow social 0xp0 [-{network information g model
Fig. 5a. Wordcloud without stopwords
Sample wordcloud[12] created from 15 abstracts of research publications collected in the domain of “Expertise Search” are shown in Fig.5. Stop word Elimination, punctuation eliminations, graph plotting are some functionalities in the package of R.
Sample syntax to perform the preprocessing is given below.
library (tm)
library (wordcloud)
TermDocumentMatrix(corpus,control=list(word
Lengths=c(2,Inf)) ) findFreqTerms(tdm,lowfreq=4) newcorpus ^ tm_map(corpus, removePunctuation)
newcorpus ^ tm_map(corpus, removeWords, stopwords("english"))
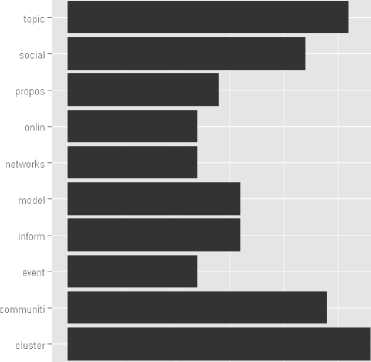
Properties of Term-document Matrix and its equivalent bar plot is shown in Fig.6
0 5 10
termFrequency
Fig. 6 Bar Plot of Term Frequency
> inspect(tdm[35:40,])
A term-document matrix (1275 terms, 14 documents)
Non-/sparse entries: 338/762
Sparsity: 69%
Maximal term length: 16
-
C. Computation of Latent Semantic Similarity:
Semantic analysis is performed on the text documents to identify their domains and computation of similarity with the concept index further. The correlation measures computed between some documents of the corpora shows that the correlation between some set of documents is negative, implying that those are not relevant to a single domain.
Table 2 Correlation measures b/w documents in corpus
|
Kendall Corr. Coeff |
Text1 |
Text2 |
Text3 |
Text4 |
|
Text1 |
1 |
0.66 |
-0.44 |
-0.23 |
|
Text2 |
0.66 |
1 |
-0.11 |
0.11 |
|
Text3 |
-0.44 |
-0.11 |
1 |
0.79 |
|
Text4 |
-0.23 |
0.11 |
0.79 |
1 |
|
Kendall Corr. Coeff |
Text1 |
Text2 |
Text3 |
Text4 |
|
Text1 |
1 |
0.66 |
-0.44 |
-0.23 |
|
Text2 |
0.66 |
1 |
-0.11 |
0.11 |
|
Text3 |
-0.44 |
-0.11 |
1 |
0.79 |
|
Text4 |
-0.23 |
0.11 |
0.79 |
1 |
|
Spearman Corr.Coeff. |
Text1 |
Text2 |
Text3 |
Text4 |
|
Text1 |
1 |
0.74 |
-0.50 |
-0.21 |
|
Text2 |
0.74 |
1 |
-0.01 |
0.29 |
|
Text3 |
-0.50 |
-0.01 |
1 |
0.88 |
|
Text4 |
-0.21 |
0.29 |
0.88 |
1 |
|
Pearson Corr. Coeff |
Text1 |
Text2 |
Text3 |
Text4 |
|
Text1 |
1 |
0.78 |
0.11 |
0.42 |
|
Text2 |
0.78 |
1 |
0.71 |
0.90 |
|
Text3 |
0.11 |
0.71 |
1 |
0.95 |
|
Text4 |
0.42 |
0.90 |
0.95 |
1 |
Table 3. TF-IDF values in corpus
|
Document/ TF IDF |
Cluster |
commun |
heterogeneous |
Purpose |
|
Text1 |
0.000 |
0.007 |
0.007 |
0.000 |
|
Text2 |
0.000 |
0.013 |
0.000 |
0.000 |
|
Text3 |
0.012 |
0.000 |
0.006 |
0.012 |
|
Text4 |
0.012 |
0.000 |
0.000 |
0.006 |
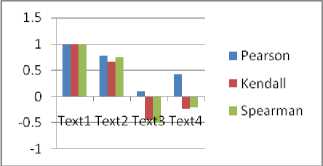
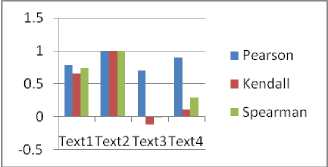
The computed values of Inverse Document Frequency for a set of sample text documents, is shown in Table 3, which depicts the overall impact of the terms in the document corpus. The importance of IDF[18] lies in the fact that the influence of keyword w.r.t. the entire document corpus related to a specific research domain that comprises the controlled vocabulary. It can be observed that the non-occurrence of a word in a document is represented by 0.
-
D. Ranking of Author Association in a specific domain
Based on the process described in the above sections, an author’s cumulative relevance factor w.r.t. a specific research domain is computed using the cosine similarity with reference to the bag of words from the controlled vocabulary.
M
Е sim ( p , CI ) l = 1
Where M is the #publications and sim() computes the Cosine Similarity of each publication w.r.t. the controlled vocabulary of research domain. A feature vector is built for each researcher with the ranking in each research. When our interface queries for a researcher in a set of domains, the aggregate similarity of each domain for the particular researcher is computed and the resultant list is displayed. Each vector represents one publication (P) of author and column represent research domains(R) and sim i,j gives the Cosine Similarity of the publication w.r.t. the specific domain, where i varies from 1 to # domains and j varies from 1 to #publications. Final aggregation of all publications is the summation of the similarity values per each domain.
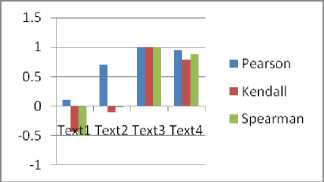
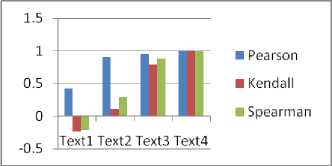
Fig. 7 Correlation Measures of Text Documents w.r.t. Text 1 to Text4
VII Conclusions
Expertise Matching is an important task that satisfies the need of reviewer systems, collaborative recommender systems or even question answer systems. This approach of publication analysis and retrieval of hidden expertise is proven to be the better approach in identifying the exact expertise of an individual in different research domains. Further analysis is required to simplify the information retrieval process that suits to any social networks, not only academic social networks. Text mining of information retrieval strategy chosen for this analysis has made this approach faster to process large corpus of text documents.
References Expert Finding System using Latent Effort Ranking in Academic Social Networks
- Balog, Krisztian, Leif Azzopardi, and Maarten de Rijke. "A language modeling framework for expert finding." Information Processing & Management 45.1 (2009): 1-19.
- Zhang, Jing, Jie Tang, and Juanzi Li. "Expert finding in a social network." Advances in Databases: Concepts, Systems and Applications. Springer Berlin Heidelberg, 2007. 1066-1069.
- Lappas, Theodoros, Kun Liu, and Evimaria Terzi. "Finding a team of experts in social networks." Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2009.
- Yang, Kai-Hsiang, et al. "EFS: Expert finding system based on Wikipedia link pattern analysis." Systems, Man and Cybernetics, 2008. SMC 2008. IEEE International Conference on. IEEE, 08.
- Mimno, David, and Andrew McCallum. "Expertise modeling for matching papers with reviewers." Proceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2007.
- Kazienko, Przemyslaw, Katarzyna Musial, and Tomasz Kajdanowicz. "Multidimensional social network in the social recommender system." Systems, Man and Cybernetics, Part A: Systems and Humans, IEEE Transactions on 41.4 (2011): 746-759.
- Munoz-Organero, Mario, et al. "A collaborative recommender system based on space-time similarities." Pervasive Computing, IEEE 9.3 (2010): 81-87.
- Bordag, Stefan. "A comparison of co-occurrence and similarity measures as simulations of context." Computational Linguistics and Intelligent Text Processing. Springer Berlin Heidelberg, 2008. 52-63.
- Chi, Ed H. "Information seeking can be social." Computer 42.3 (2009): 42-46.
- Trier, Matthias, and Annette Bobrik. "Social search: exploring and searching social architectures in digital networks." Internet Computing, IEEE 13.2 (09): 51-59.
- Maybury, Mark T. "Expert finding systems." MITRE Cente_for_Integrated_Intelligence_Systems, MIT, (2006).
- http://cran.r-project.org/
- http://www.rdatamining.com/
- www.aminer.org
- www.academic.research.microsoft.com
- Santos, Igor, et al. "Enhanced Topic-based Vector Space Model for semantics-aware spam filtering." Expert Systems with applications 39.1(12): 437-444.
- Chow, Tommy WS, Haijun Zhang, and M. K. M. Rahman. "A new document representation using term frequency and vectorized graph connectionists with application to document retrieval." Expert Systems with Applications 36.10 (2009): 12023-12035.
- http://en.wikipedia.org/wiki/Tf/idf
- http://nlp.stanford.edu/IR-book/html/htmledition/inverse-document-frequy-1.html
- Jie Tang, Jing Zhang , Limin Yao, Juanzi Li , Li Zhang and Zhong Su, “ArnetMiner: Extraction and Mining of Academic Social Networks”, Knowledge Discovery & Datamining’08, August 24–27, 2008, Las Vegas, Nevada, USA.
- Gerald Kowalski, “Information Retrieval Systems”, Kluwer Academic Press
- Zhao, Ying, and Falk Scholer, "Predicting query performance for user-based search tasks." Australian Database Conference, Vol.7. 2007.
- http://www.thearling.com/glossary.htm
- http://www.webopedia.com/ ComputerScience/AI
- Becker, J., & Kuropka, D. (2003). “Topic-based vector space model”, in Proc. of the 6th Intnl Conf. on Business Information Systems (p 7–12).
- Lin Liu,Junkang Feng,"A Semantic Approach to the Notion of Representation and Its Application to Information Systems", IJITCS, vol.3, no.5, pp.39-50, 2011.
